计算机二级Python基本排序题-序号45(补充)
1. 文件"singup.txt”中保存了若干条参加运动会学生的报名记录,每条记录的形式为“班级号_学号”,例如"A1_12”,将每个班级报名情按参加运动会人数从多到少排列(假设不存在人数相同的情况)并输出,输出结果如下:
A1->[‘12’,‘05’,‘07’,‘04’]
A4->[‘23’,‘03’,‘11’]
A3 ->[‘12’,‘01’]
A2->[‘07’]
def proc(stu_list): #定义函数d = {}for item in stu_list:r = item.split("_") #以"_"进行分隔a, b = r[0], r[1].strip() #提取出班级号和学号的信息if a in d:d[a] += [b] #"+"号用于组合列表else:d[a] = [b]lst = sorted(d.items(), key = lambda d:len(d[1]), reverse = True)return lstf = open("signup.txt","r")
stu_list = f.readlines() #返回列表类型
result = proc(stu_list) #调用函数
for item in result:print(item[0], '->', item[1])
f.close()
2. 在已定义好的字典pdict里有一些人名及其电话号码。请用户输入一个人的姓名,在字典中查找该用户的信息,如果找到,生成一个四位数字的验证码,并将名字、电话号码和验证码输出在屏幕上,如示例所示。如果查找不到该用户信息,则显示“对不起,您输入的用户信息不存在。”示例如下:
输入:
Bob
输出: Bob 234567891 1926
输入: bob
输出:
对不起,您输入的用户信息不存在。
import random
random.seed(2)pdict= {'Alice':['123456789'],'Bob':['234567891'],'Lily':['345678912'],'Jane':['456789123']}name = input('请输入一个人名:')
if name in pdict:print(name,pdict[name][0],random.randint(1000,9999))
else:print('对不起,您输入的用户信息不存在。')
pdict[name]返回的是键对应的值,即列表[‘xxx’]
pdict[name][0]返回的是列表中的第一个元素,此时返回的是字符串
- print()函数的标准格式:
print(value1, value2, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
value1, value2, … 是要打印的值,可以是任意数量的参数。
sep 是用于分隔多个值的字符串,默认是一个空格。
end 是打印结束时要添加的字符串,默认是换行符 \n。
file 是指定输出的文件对象,默认是标准输出流 sys.stdout。
flush 是一个布尔值,用于指定是否刷新输出缓冲区,默认为 False。
3. 在考生文件夹下有个文件PY202.py,定义了一个6个浮点数的一维列表lt1和一个包含3个数的一维列表lt2。
示例如下:
lt1 = [0.69,0.292,0.33,0.131,0.61,0.254]
lt2 = [0.1,0.8,0.2]
在横线处填写代码,完成如下功能。计算lt1列表跟lt2列表的向量内积,两个向量X=[x1,x2,x3]和Y= [y1,y2,y3]的内积计算公式如下:
k=x1*y1 + x2*y2 + x3*y3
将每次计算的两组对应元素的值、以及对应元素乘积的累计和(k)的值显示在屏幕上,格式如下所示:
k=0.069 ,lt2[0]=0.100 ,lt1[0+0]=0.690
k=0.303 ,lt2[1]=0.800 ,lt1[0+1]=0.292
k=0.369 ,lt2[2]=0.200 ,lt1[0+2]=0.330
…(略)
计算方式如下:
第一步计算第一个k,分为3次累加计算:
k=lt2[0]*lt1[0+0];
k=lt2[0]*lt1[0+0]+lt2[1]*lt1[0+1];
k=llt2[0]*lt1[0+0]+lt2[1]*lt1[0+1]+lt2[2]*lt1[0+2]
最终得到最后一个k值保存
第二步计算第二个k,分为3次累加计算:
k=lt2[0]*lt1[1+0];
k=lt2[0]*lt1[1+0]+lt2[1]*lt1[1+1];
k=llt2[0]*lt1[1+0]+lt2[1]*lt1[1+1]+lt2[2]*lt1[1+2]
最终得到最后一个k值保存,依照此规律依次计算。
img = [0.244, 0.832, 0.903, 0.145, 0.26, 0.452]
filter = [0.1,0.8,0.1]
res = []
for i in range(len(img)-2):k=0for j in range(len(filter)):k+=filter[j]*img[j+i]print("k={:.3f} ,filter[{}]={:.3f} ,img[{}{}{}]={:.3f}".format(k,j,filter[j],i,'+',j,img[i+j]))res.append(k)
for r in res:print('{:<10.3f}'.format(r),end = '')
4. 获得用户的非数字输入,如果输入中存在数字,则要求用户重新输入,直至满足条件为止,并输出用户输入字符的个数,完善PY202.py文件中的代码。
while True:s = input("请输入不带数字的文本:")for i in range(10):if str(i) in s:breakelse:break
print(len(s))
5. 使用字典和列表型变量完成最有人气的明星的投票数据分析。投票信息由考生文件夹下文件vote.txt给出,一行只有一个明星姓名的投票才是有效票。有效票中得票最多的明星当选最有人气的明星。
问题1:请统计有效票张数。
f = open("vote.txt")
names = f.readlines()
f.close()
n = 0
for name in names:num = len(name.split())if num==1:n+=1
print("有效票{}张".format(n))
问题2:请给出当选最有人气明星的姓名和票数
f = open("vote.txt")
names = f.readlines()
f.close()
D = {}
for name in names:if len(name.split())==1:D[name[:-1]]=D.get(name[:-1],0) + 1
l = list(D.items())
l.sort(key=lambda s:s[1],reverse=True)
name = l[0][0]
score = l[0][1]
print("最具人气明星为:{},票数为:{}".format(name,score))
6. 在考生文件夹下有个文件PY202.py,在省略号处填写一行或多行代码,完成如下功能。同时,在考生文件夹下有个文件data.txt,其中记录了2019年QS全球大学排名前20名的学校信息,示例如下:
1,麻省理工学院,美国
2,斯坦福大学,美国
3,哈佛大学,美国
…
第一列为排名,第2列为学校名称,第3列为学校所属的国家,字段之间用逗号’,',隔开
程序读取data.txt文件内容,统计出现的国家个数以及每个国家上榜大学的数量及名称,输出结果格式示例如下:
英国: 5:牛津大学 剑桥大学 帝国理工学院 伦敦大学学院 爱丁堡大学
瑞士: 1:苏黎世联邦理工学院
…
f = open('data.txt','r')
dic = {}
for line in f:line = line.strip().split(',')if len(line)<3:continuedic[line[-1]] = dic.get(line[-1],[])+[line[1]]
unis = list(dic.items())
f.close()
for d in unis:print('{:>4}: {:>4} : {}'.format(d[0],len(d[1]),' '.join(d[1])))
7. 考生文件夹下有个文件PY202.py,在省略号处填写一行或多行代码,完成如下功能。同时,在考生文件夹下有个文件out.txt,其中有一些数据库操作功能的执行时间信息,如下所示:
starting 0.000037 2102
After opening tables 0.000008 0.455
System lock 0.000004 0.227
Table lock 0.000008 0.455
其中第1列是操作的名字,第2列是操作所花费的时间,单位是秒,第3列是操作时间占全部过程的百分比,字段之间用逗号’,'隔开
修改考生文件夹下的文件PY202.py,读取out.txt文件里的内容,统计所有操作所花费的时间总和,并输出操作时间百分比最多的三个操作所占百分比的值,及其对应的操作名称,显示在屏幕上,如下所示:
the total execute time is 0.0017
the top 0 percentage time is 46.023,spent in “Filling schema table” operation
sumtime = 0
percls = []
ts = {}
with open('out.txt', 'r') as f:for i in f:i=i.strip().split(',')ts[i[0]]=eval(i[2])sumtime+=eval(i[1])
print('the total execute time is ', sumtime)tns = list(ts.items())
tns.sort(key=lambda x: x[1], reverse=True)
for i in range(3):print('the top {} percentage time is {}, spent in "{}" operation'.format(i, tns[i][1],tns[i][0]))
8. 让用户输入一首诗的文本,内部包含中文逗号和向号。
(1)用jieba库的精确模式对输入文本分词。将分词后的词语输出并以"/"分隔;统计中文词语数并输出:
(2)以逗号和句号将输入文本分隔成单句并输出,每句一行,每行20个字符宽,居中对齐。在(1)和(2)的输出之间,增加一个空行。示例如下:
输入:月亮河宽宽的河,一天我从你身旁过,
输出:月亮/河/宽宽的/河/一天/我/从/你/身旁/过
中文词语数是:10
月亮河宽宽的河
一天我从你身旁过
import jieba
s = input("请输入一段中文文本,句子之间以逗号或句号分隔:")
slist = jieba.lcut(s)
m = 0for i in slist:if i in ",。":continuem += 1print(i,end='/') print("\n中文词语数是:{}\n".format(m))ss = ''
for i in s:if i in ',。':print('{: ^20}'.format(ss))ss = ''continuess += i
9. 在考生文件夹下存在一个Python源文件PY202.py,请编写代码替换省略号,不可以修改已有代码,实现以下功能:
(1)定义一个列表persons,里面有一些名字字符串;
(2)在该列表中查找用户输入的一个名字字符串,如果找到,则生成一个四位数字的随机数组成的验证码,输出找到的名字字符串和验证码;如果找不到该字符串,则输出提示信息“对不起,您输入的名字不存在。”;如果用户输入一个字母“q,则退出程序;
(3)显示提示信息后,再次显示“请输入一个名字:”,提示用户输入,重复执行步骤2,执行3次后自动退出程序。
import random as r
r.seed(0)
persons = ['Aele', 'Bob','lala', 'baicai']
flag = 3
while flag>0:flag -= 1name = input('请输入一个名字:')if name == 'q':breakelif name in persons:num = r.randint(1000,9999)print('{} {}'.format(name, num))else:print('对不起,您输入的名字不存在。')
10. 在考生文件夹下存在一个Python源文件PY202.py和一个介绍玫瑰花的文本文件data1.txt。请编写代码替换省略号,可修改其他代码,实现下面功能:
从data1.txt中读入文本,去掉文中的中文号、分号、双引号、句号和双引号;用ieba库精确模式分词,分词后的结果以"/"分隔,输出到屏幕上;统计分词结果中长度大于1的中文词语出现的词频,并将最高词频的前5个词及其词频,输出到屏幕上,每词一行,词和词频之间以英文冒号分隔。
import jieba
fuhao=[",",":","、","。",";","“","”"]
with open("data1.txt","r",encoding="utf-8") as f:all_txt=f.read()for ch in fuhao:all_txt=all_txt.replace(ch,'')data=jieba.lcut(all_txt)
print('/'.join(data))
print('高频词top5如下:')
d={}
for i in data:if len(i)>=2:d[i]=d.get(i,0)+1
ls=list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
for s in ls[:5]:print('{}:{}'.format(s[0],s[1]))
相关文章:
)
计算机二级Python基本排序题-序号45(补充)
1. 文件"singup.txt”中保存了若干条参加运动会学生的报名记录,每条记录的形式为“班级号_学号”,例如"A1_12”,将每个班级报名情按参加运动会人数从多到少排列(假设不存在人数相同的情况)并输出,…...

响应式Web开发项目教程(HTML5+CSS3+Bootstrap)第2版 例4-6 fieldset
代码 <!doctype html> <html> <head> <meta charset"utf-8"> <title>fieldset</title> </head><body> <form action"#"><fieldset><legend>学生信息</legend>姓名:&…...

html渲染优先级
在前端开发中,优先布局是指在设计和构建页面时,将页面的各个部分按照其重要性和优先级进行排序,并依次进行布局和开发。这种方法可以帮助开发团队在项目初期就确定页面结构的核心部分,从而更好地掌控项目的整体进度和优先级。且确…...

linux 更新镜像源
打开终端,备份一下旧的 源 文件,以防万一 cd /etc/apt/ ls sudo cp sources.list sources.list.bak ls然后打开清华大学开源软件镜像站 搜索一下你的linux发行版本,我这里是ubuntu发行版本 点击这个上面图中的问号 查看一下自己的版本号&a…...
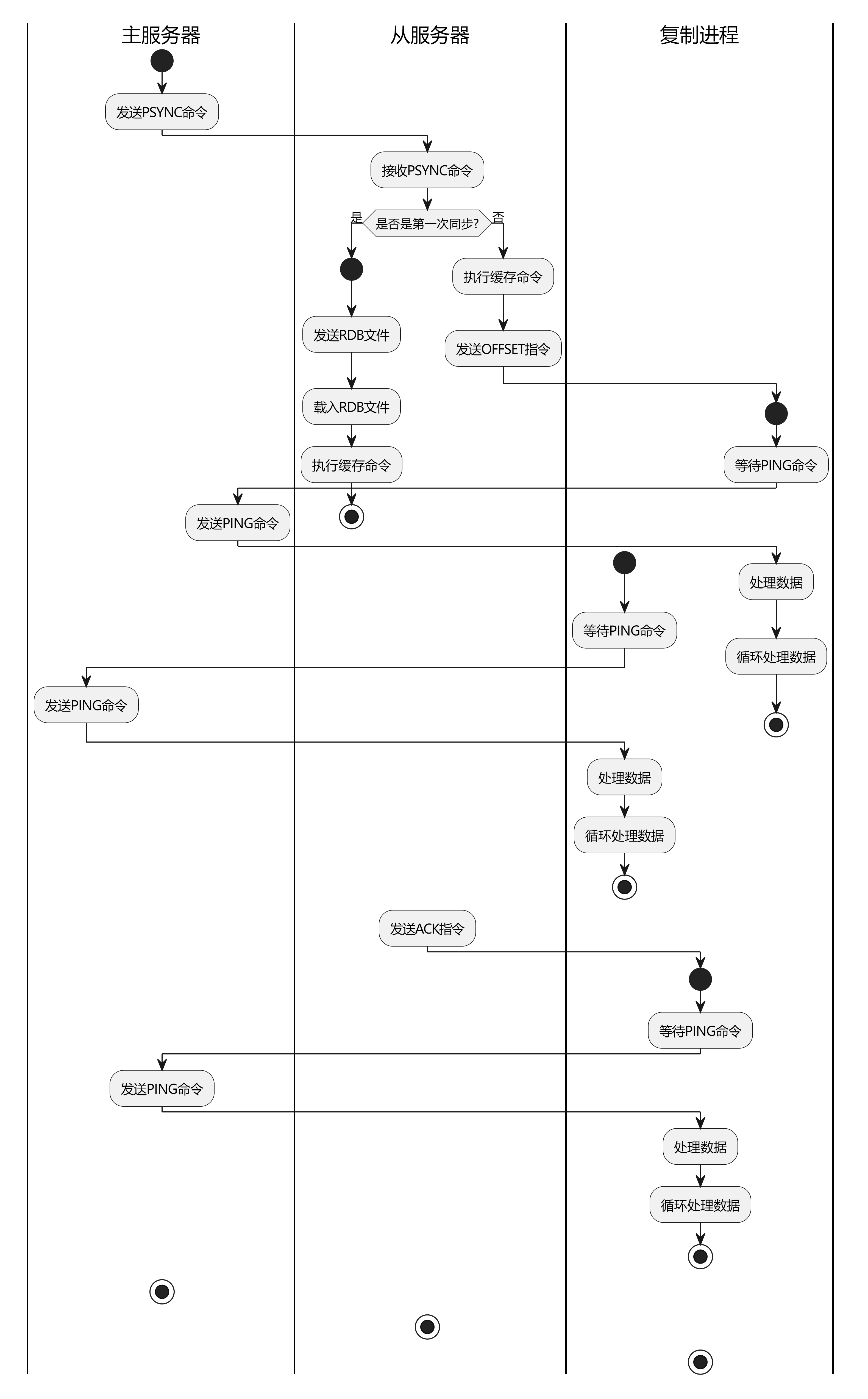
【征服Redis12】redis的主从复制问题
从现在开始,我们来讨论redis集群的问题,在前面我们介绍了RDB和AOF两种同步机制,那你是否考虑过这两个机制有什么用呢?其中的一个重要作用就是为了集群同步设计的。 Redis是一个高性能的键值存储系统,广泛应用于Web应用…...

php函数 一
一 自动加载 1.1 __autoload(string $class) 类自动加载,7.2版本之后废弃。可使用sql_autoload_register()注册方法实现。 类自动加载,无返回值。 #php7.2之前function __autoload($class) {if(strpos($class, CI_) ! 0){if (file_exists(APPPATH . …...
)
监督学习 - 梯度提升回归(Gradient Boosting Regression)
什么是机器学习 梯度提升回归(Gradient Boosting Regression)是一种集成学习方法,用于解决回归问题。它通过迭代地训练一系列弱学习器(通常是决策树)来逐步提升模型的性能。梯度提升回归的基本思想是通过拟合前一轮模…...
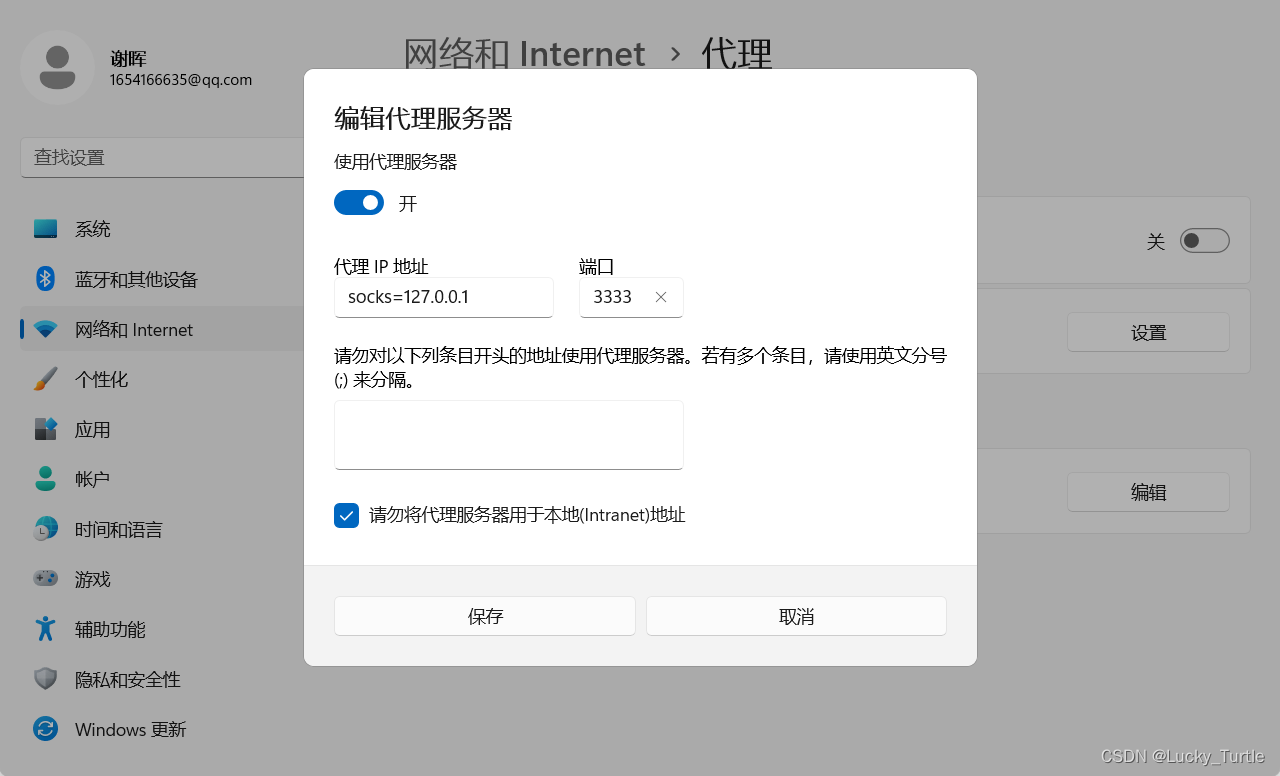
【工具】使用ssh进行socket5代理
文章目录 shellssh命令详解正向代理:反向代理:本地 socks5 代理 shell ssh -D 3333 root192.168.0.11 #输入密码 #3333端口已经使用远程机进行转发设置Windows全局代理转发 socks127.0.0.1 3333如果远程机为公网ip,可通过搜索引擎查询出网…...
 Object Pascal 学习笔记---第2章第六节(类型转换))
(delphi11最新学习资料) Object Pascal 学习笔记---第2章第六节(类型转换)
Object Pascal 学习笔记,Delphi 11 编程语言的完整介绍 作者: Marco Cantu 笔记:豆豆爸 2.6 类型转换和类型转换 正如我们所见,不能将一种数据类型的变量赋值给另一种类型的变量。原因在于,根据数据的实际表示,你…...

计算机服务器中了mallox勒索病毒怎么办,mallox勒索病毒解密数据恢复
企业的计算机服务器存储着企业重要的信息数据,为企业的生产运营提供了极大便利,但网络安全威胁随着技术的不断发展也在不断增加,近期,云天数据恢复中心接到许多企业的求助,企业的计算机服务器中了mallox勒索病毒&#…...

CPU相关专业名词介绍
CPU相关专业名词 1、CPU 中央处理器CPU(Central Processing Unit)是计算机的运算和控制核心,可以理解为PC及服务器的大脑CPU与内部存储器和输入/输出设备合称为电子计算机三大核心部件CPU的本质是一块超大规模的集成电路,主要功…...

VRRP协议负载分担
VRRP流量负载分担 VRRP负载分担与VRRP主备备份的基本原理和报文协商过程都是相同的。同样对于每一个VRRP备份组,都包含一个Master设备和若干Backup设备。与主备备份方式不同点在于:负载分担方式需要建立多个VRRP备份组,各备份组的Master设备可以不同;同一台VRRP设备可以加…...

maven 基本知识/1.17
maven ●maven是一个基于项目对象模型(pom)的项目管理工具,帮助管理人员自动化构建、测试和部署项目 ●pom是一个xml文件,包含项目的元数据,如项目的坐标(GroupId,artifactId,version )、项目的依赖关系、构建过程 ●生命周期&…...
【Java】HttpServlet类简单方法和请求显示
1、HttpServlet类简介🍀 Servlet类中常见的三个类有:☑️HttpServlet类,☑️HttpServletRequest类,☑️HttpResponse类 🐬其中,HttpServlet首先必须读取Http请求的内容。Servlet容器负责创建HttpServlet对…...

使用Rancher管理Kubernetes集群
部署前规划 整个部署包括2个部分,一是管理集群部署,二是k8s集群部署。管理集群功能主要提供web界面方式管理k8s集群。正常情况,管理集群3个节点即可,k8s集群至少3个。本文以3节点管理集群,3节点k8s集群为例 说明部署过…...
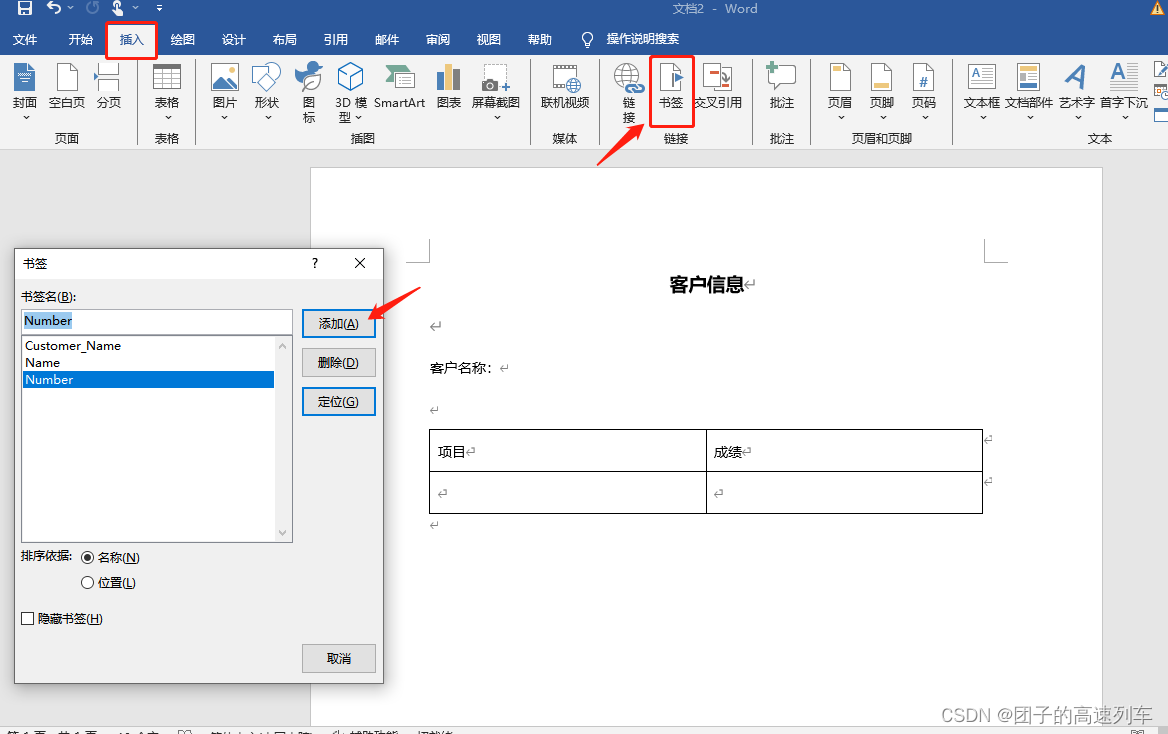
QT中操作word文档
QT中操作word文档: 参考如下内容: C(Qt) 和 Word、Excel、PDF 交互总结 Qt对word文档操作总结 QT中操作word文档 Qt/Windows桌面版提供了ActiveQt框架,用以为Qt和ActiveX提供完美结合。ActiveQt由两个模块组成: QAxContainer模…...

纯前端在线Office文档安全预览之打开Word文档后禁止打印、禁止另存为、禁止复制
在一些在线Office文档中,有很多重要的文件需要保密控制,比如:报价单、客户资料等数据,只能给公司成员查看,但是不能编辑,并且不能拷贝,打印、不能另存为,导致重要资料外泄。 可以通…...

李沐深度学习-d2lzh_pytorch模块实现
d2lzh_pytorch 模块 import random import torch import matplotlib_inline from matplotlib import pyplot as plt import torchvision import torchvision.transforms as transforms import torchvision.datasets import sys from collections import OrderedDict# --------…...
什么是OSPF?为什么需要OSPF?OSPF基础概念
什么是OSPF? 开放式最短路径优先OSPF(Open Shortest Path First)是IETF组织开发的一个基于链路状态的内部网关协议(Interior Gateway Protocol)。 目前针对IPv4协议使用的是OSPF Version 2(RFC2328&#x…...

Java多线程并发篇----第二十六篇
系列文章目录 文章目录 系列文章目录前言一、什么是 Executors 框架?二、什么是阻塞队列?阻塞队列的实现原理是什么?如何使用阻塞队列来实现生产者-消费者模型?三、什么是 Callable 和 Future?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分…...

手把手教你用网络分析仪调试CGH40010F:从S参数异常反推管子损坏原因与状态
深度解析CGH40010F氮化镓功率管故障诊断:从S参数异常到失效机理 在射频功率放大器设计中,CGH40010F作为一款经典的氮化镓(GaN)功率晶体管,因其高功率密度和高效率特性被广泛应用于基站、雷达等场景。然而在实际工程调试中,工程师们…...

CTF新手必看:一张图里藏了啥?手把手教你用010 Editor秒解BUUCTF图片隐写题
CTF新手入门:从图片隐写题中快速提取Flag的实战指南 当你第一次接触CTF比赛中的图片隐写题时,可能会感到无从下手。那些看似普通的图片背后,往往藏着关键的Flag信息。本文将带你一步步破解BUUCTF平台上的典型图片隐写题,使用010 E…...

利用Taotoken多模型能力为AIGC应用动态选择最佳模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken多模型能力为AIGC应用动态选择最佳模型 在构建内容生成类应用时,开发者常常面临一个核心挑战:…...

4.2% 稳健扩容!工业厂房从传统基建向智慧绿色赛道破局
一、全球工业厂房市场规模工业厂房作为工业生产的核心载体,是支撑制造业发展的重要基础设施,其市场规模变化与全球工业经济活跃度高度绑定。据恒州诚思最新调研统计,2025 年全球工业厂房市场规模已达62580 亿元,在全球工业经济复苏…...

别再只用在线版了!手把手教你用Docker在本地服务器搭建私有Draw.io图表库
私有化部署Draw.io:用Docker打造企业级安全图表库 当团队需要处理敏感数据时,将核心工具部署在本地环境已成为刚需。以Draw.io为例,虽然其在线版功能完善,但数据经过第三方服务器的风险始终存在。本文将带你用Docker构建一个完全自…...

openCode 是什么?你电脑里常驻的 AI 开发搭档
凌晨一点,你正在改一个棘手的 Bug。 控制台里报错信息刷了一屏,你盯着那段陌生的代码——是上周同事写的,没注释,没文档。你下意识选中代码,复制,打开浏览器,粘贴到 ChatGPT 的对话框里。 等等。…...

如何高效使用Alas:碧蓝航线自动化智能助手终极指南
如何高效使用Alas:碧蓝航线自动化智能助手终极指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 厌倦了每天重…...

5分钟掌握碧蓝航线自动化脚本:解放双手的智能游戏助手终极指南
5分钟掌握碧蓝航线自动化脚本:解放双手的智能游戏助手终极指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你…...

LinkSwift:九大网盘直链下载的终极解决方案,快速获取真实下载地址
LinkSwift:九大网盘直链下载的终极解决方案,快速获取真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘…...

tensorrt_demos性能对比分析:FP16 vs INT8 vs DLA核心的优劣对比
tensorrt_demos性能对比分析:FP16 vs INT8 vs DLA核心的优劣对比 【免费下载链接】tensorrt_demos TensorRT MODNet, YOLOv4, YOLOv3, SSD, MTCNN, and GoogLeNet 项目地址: https://gitcode.com/gh_mirrors/te/tensorrt_demos tensorrt_demos是一个支持MODN…...