李沐深度学习-d2lzh_pytorch模块实现
d2lzh_pytorch 模块
import random
import torch
import matplotlib_inline
from matplotlib import pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets
import sys
from collections import OrderedDict# ---------------------------------------------------------------------------------------------
# 图表展示
def use_svg_display():# 用矢量图表示matplotlib_inline.backend_inline.set_matplotlib_formats('svg')def set_figsize(figsize=(3.5, 2.5)):use_svg_display()# 设置图的尺寸plt.rcParams['figure.figsize'] = figsize# ---------------------------------------------------------------------------------------------
# 读取数据
# 获取总的样本数量,然后打乱顺序,用batch-size获取每一部分索引去索引对应样本中的数据,使用yield返回
'''
函数详解:
torch.linspace(start, end, steps, dtype) → Tensor 从start开始到end结束,生成steps个数据点,数据类型为dtype
torch.index_select(input, dim, index) 索引张量中的子集
**input:需要进行索引操作的输入张量dim:张量维度 0,1index:索引号,是张量类型
**
yield: 使用yield的函数返回迭代器对象,每次使用时会保存变量信息,使用next()或者使用for可以循环访问迭代器中的内容
'''def data_iter(batch_size, features, labels):num_examples = len(features) # features nxmindices = list(range(num_examples)) # 借助range生成索引序列random.shuffle(indices) # 把list列表中的值打乱顺序for i in range(0, num_examples, batch_size):j = torch.LongTensor(indices[i:min(i + batch_size, num_examples)]) # 这里的i是对标乱序表中的下标索引号yield features.index_select(0, j), labels.index_select(0, j) # 0维度,有1000个样本,j就是他们的下标# ---------------------------------------------------------------------------------------------# 定义模型
def linreg(X, w, b):return torch.mm(X, w) + b # 传进来的参数和样本特征都符合矩阵形式 w,b都是列矩阵 X:1000x2 w:2x1 b:1x1# 这里使用了广播# ---------------------------------------------------------------------------------------------# 定义损失函数
def square_loss(y_hat, y):# 保证y_hat和y同型,pytorch中的MSELoss没有除以2的操作return (y_hat - y.view(y_hat.size())) ** 2 / 2# 这里的得到的也是一个小批量的样本的损失张量# ---------------------------------------------------------------------------------------------
# 定义优化算法
# 这里使用的是sgd算法,使用小批量梯度和(参数求导后的和:梯度会自动累加,不用自己加和梯度)除以小批量样本个数来求小批量平均值
def sgd(params, lr, batch_size):for param in params:param.data -= lr * param.grad / batch_size # 这里更改param时使用的是param.data,这样就不会影响反向梯度# 这里的param指的是w1,w2,b# 这里应该是小批量中的每个loss运行完,得到小批量每个样本的梯度然后pytorch自动进行了梯度累加,之后一个小批量得到一个累加和后的
# 梯度w1,w2,b
# ---------------------------------------------------------------------------------------------'''
FashionMNIST 数据集
'''# ----------------------------------------------------------将数值标签转换成文本标签
def get_fashion_mnist_labels(labels):text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal','shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]# -----------------------------------------------------在一行里画出多张图像和对应标签的函数
def show_fashion_mnist(images, labels):use_svg_display()# 这里的_表示忽略(不使用)的变量_, figs = plt.subplots(1, len(images), figsize=(12, 12)) # 设置一行 len(images)个数量,每个figsize大小的画布# figs 返回的是一个画布对象,这个对象有imshow,set_tittle,axes_get_xasis().set_visible,# axes.get_yaxis().set_visible()这几种函数调用方式,用来给figs里面添加图像for f, img, lbl, in zip(figs, images, labels): # 这个画布对象循环往里面添加图像信息f.imshow(img.view((28, 28)).numpy()) # img承接图像信息,将tensor转化为numpy 这里参数为数组元素f.set_title(lbl)f.axes.get_xaxis().set_visible(False)f.axes.get_yaxis().set_visible(False)plt.savefig("路径")# ----------------------------------------------------------------获取并读取FashionMNIST数据集函数,返回小批量train,test
def load_data_fashion_mnist(batch_size):mnist_train = torchvision.datasets.FashionMNIST(root='路径',train=True, download=True, transform=transforms.ToTensor())mnist_test = torchvision.datasets.FashionMNIST(root='路径',train=False, download=True, transform=transforms.ToTensor())'''上面的mnist_train,mnist_test都是torch.utils.data.Dataset的子类,所以可以使用len()获取数据集的大小训练集和测试集中的每个类别的图像数分别是6000,1000,两个数据集分别有10个类别'''# mnist是torch.utils.data.dataset的子类,因此可以将其传入torch.utils.data.DataLoader来创建一个DataLoader实例来读取数据# 在实践中,数据读取一般是训练的性能瓶颈,特别是模型较简单或者计算硬件性能比较高的时候# DataLoader一个很有用的功能就是允许多进程来加速读取 使用num_works来设置4个进程读取数据if sys.platform.startswith('win'):num_workers = 0else:num_workers = 4train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True,num_workers=num_workers)test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False,num_workers=num_workers)return train_iter, test_iter# -------------------------------------------------------------查看mnist前10个图像和标签
def check_mnist():mnist_train = torchvision.datasets.FashionMNIST(root='路径',train=True, download=True, transform=transforms.ToTensor())mnist_test = torchvision.datasets.FashionMNIST(root='路径',train=False, download=True, transform=transforms.ToTensor())X, y = [], []for i in range(10):X.append(mnist_train[i][0]) # 循环获取图像张量矩阵y.append(mnist_train[i][1]) # 循环获取图像对应数值标签show_fashion_mnist(X, get_fashion_mnist_labels(y))# feature, label = mnist_train[0]# print(feature.shape, label) CxHxW# feature对应高和宽均为28像素的图像,因为使用了transforms.ToTensor(),所以每个像素的数值对应于【0.0,1.0】的32位浮点数# C 是通道数,RGB,灰色图像,通道数为1,H,W分别为高,宽# mnist_train[0] 是一个元祖,它包含两部分,图像数据结构和图像标签值,图像的数据结构是1x28x28结构,是一个浮点数矩阵,代表一个图像# -------------------------------------------------------------------------评价模型net在数据集data_iter上的准确率
def evaluate_accuracy(test_iter, net):acc_sum, n, x = 0.0, 0, 0.0for X, y in test_iter: # 返回一个批量的数据元组迭代对象acc_sum += (net(X).argmax(dim=1) == y).float().sum().item() # 将net模型的预测y与标签y进行了准确率比较n += y.shape[0] # 累加获得样本个数x = acc_sum / nreturn x# -------------------------------------------------------------------------训练模型函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, optimizer=None):for epochs in range(num_epochs): # 循环周期train_l_sum, train_acc_sum, n = 0.0, 0.0, 0 # 预先定义 训练损失,训练精度,批量个数for X, y in train_iter: # 批量更新y_hat = net(X)l = loss(y_hat, y).sum() # 损失计算# 梯度清零if optimizer is not None:optimizer.zero_grad()elif params is not None and params[0].grad is not None: # 权重存在并且权重的梯度存在for param in params:param.grad.data.zero_()l.backward() # 反向传播# 梯度更新操作if optimizer is None:sgd(params, lr, batch_size) # 调用sgd进行梯度下降操作else:optimizer.step() # softmax回归的简洁实现将要用到train_l_sum += l.item() # 损失累加train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item() # (y_hat.argmax(dim=1) == y)# 取出y_hat每一行中最大的概率索引和y比较,结果为tensor,元素值为0/1n += y.shape[0] # 计算一个批量中标签的个数test_acc = evaluate_accuracy(test_iter, net) # 一个循环之后进行测试集的准确度计算print(f'epoch %d,loss %.4f,train_acc %.3f,test_acc %.3f'% (epochs + 1, train_l_sum / n, train_acc_sum / n, test_acc))# x = torch.tensor([[0.1, 0.4, 0.2], [1, 0.06, 0.5]])
# print((x.argmax(dim=1)==torch.tensor([[1,1]])).float())# -------------------------------------------------------------------------x的形状转换功能函数
class FlattenLayer(torch.nn.Module):def __init__(self):super(FlattenLayer, self).__init__() # 初始化函数,自动调用forward函数def forward(self, x): # x shape: (batch,*,*,....)return x.view(x.shape[0], -1) # 转换成(batch_size,特征数)形状# 这样就方便定义模型
net = torch.nn.Sequential(# FlattenLayer()# torch.nn.Linear(num_inputs,num_outputs)OrderedDict([('flatten', FlattenLayer()),('linear', torch.nn.Linear(2, 3))])
)'''
-------------------------------------------------------------------作图函数
'''def semilogy(x_vals, y_vals, xlabel, ylabel, label, x2_vals=None, y2_vals=None, legend=None):plt.xlabel(xlabel)plt.ylabel(ylabel)plt.semilogy(x_vals, y_vals) # y轴使用对数尺度if x2_vals and y2_vals:plt.semilogy(x2_vals, y2_vals, linestyle=':')plt.legend(legend)plt.savefig("路径/多项式" + label + "模拟.png")
相关文章:

李沐深度学习-d2lzh_pytorch模块实现
d2lzh_pytorch 模块 import random import torch import matplotlib_inline from matplotlib import pyplot as plt import torchvision import torchvision.transforms as transforms import torchvision.datasets import sys from collections import OrderedDict# --------…...
什么是OSPF?为什么需要OSPF?OSPF基础概念
什么是OSPF? 开放式最短路径优先OSPF(Open Shortest Path First)是IETF组织开发的一个基于链路状态的内部网关协议(Interior Gateway Protocol)。 目前针对IPv4协议使用的是OSPF Version 2(RFC2328&#x…...

Java多线程并发篇----第二十六篇
系列文章目录 文章目录 系列文章目录前言一、什么是 Executors 框架?二、什么是阻塞队列?阻塞队列的实现原理是什么?如何使用阻塞队列来实现生产者-消费者模型?三、什么是 Callable 和 Future?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分…...
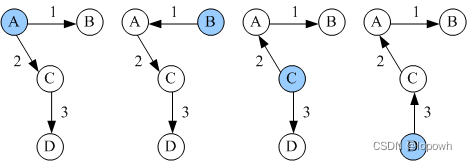
list下
文章目录 注意:const迭代器怎么写?运用场合? inserterase析构函数赋值和拷贝构造区别?拷贝构造不能写那个swap,为什么?拷贝构造代码 面试问题什么是迭代器失效?vector、list的区别? 完整代码 注…...
【Linux】进程间通信——system V 共享内存、消息队列、信号量
需要云服务器等云产品来学习Linux的同学可以移步/–>腾讯云<–/官网,轻量型云服务器低至112元/年,优惠多多。(联系我有折扣哦) 文章目录 写在前面1. 共享内存1.1 共享内存的概念1.2 共享内存的原理1.3 共享内存的使用1.3.1 …...

网络卡问题排查手段
问题 对后端来说,网络卡了问题,本身很难去排查,因为是 App 通过互联网连接服务 总结下,以往经验,网络卡,通常会有以下情况造成: 某地区网络问题某地区某运营商问题后端服务超载前端网络模块 …...

20240119-子数组最小值之和
题目要求 给定一个整数数组 arr,求 min(b) 的总和,其中 b 的范围涵盖 arr 的每个(连续)子数组。由于答案可能很大,因此返回答案模数 Example 1: Input: arr [3,1,2,4] Output: 17 Explanation: Subarrays are [3]…...

c# 释放所有嵌入资源, 到某个本地文件夹
版本号 .net 8 代码 using System.Reflection;namespace Demo;internal class Program {static void Main(string[] args){// 获取当前 执行exe 的目录 / 当前命令行所在的目录 var currentDir Directory.GetCurrentDirectory();Console.WriteLine(currentDir);Extract…...

Unity SnapScrollRect 滚动 匹配 列表 整页
展示效果 原理: 当停止滑动时 判断Contet的horizontalNormalizedPosition 与子Item的缓存值 相减,并得到最小值,然后将Content horizontalNormalizedPosition滚动过去 使用方式: 直接将脚本挂到ScrollRect上 注意:在创建Content子物体时…...

网络命令ping和telnet
1. 请解释ping和telnet的工作原理。 ping和telnet是两种常用的网络工具,其工作原理分别如下: ping: 目的:ping主要用于检查网络是否通畅以及测量网络连接速度。工作原理:ping是基于ICMP(Internet Control …...
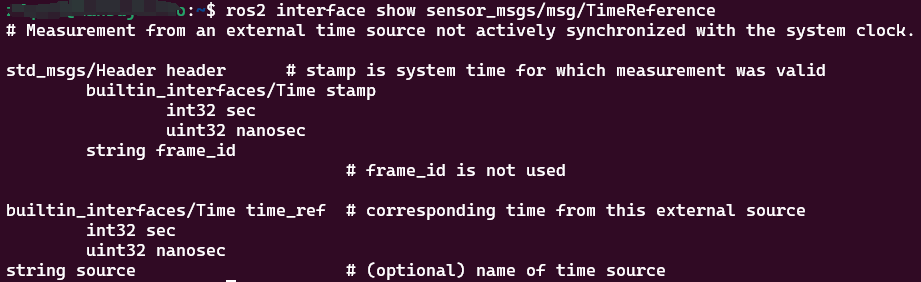
ros2学习笔记-CLI工具,记录命令对应操作。
目录 环境变量turtlesim和rqt以初始状态打开rqt node启动节点查看节点列表查看节点更多信息命令行参数 --ros-args topic话题列表话题类型话题列表,附加话题类型根据类型查找话题名查看话题发布的数据查看话题的详细信息查看类型的详细信息给话题发布消息࿰…...

自然语言处理的发展
自然语言处理的发展大致经历了四个阶段:萌芽期、快速发展期、低谷的发展期和复苏融合期。 萌芽期(1956年以前):这个阶段可以看作自然语言处理的基础研究阶段。人类文明经过了几千年的发展,积累了大量的数学、语言学和…...
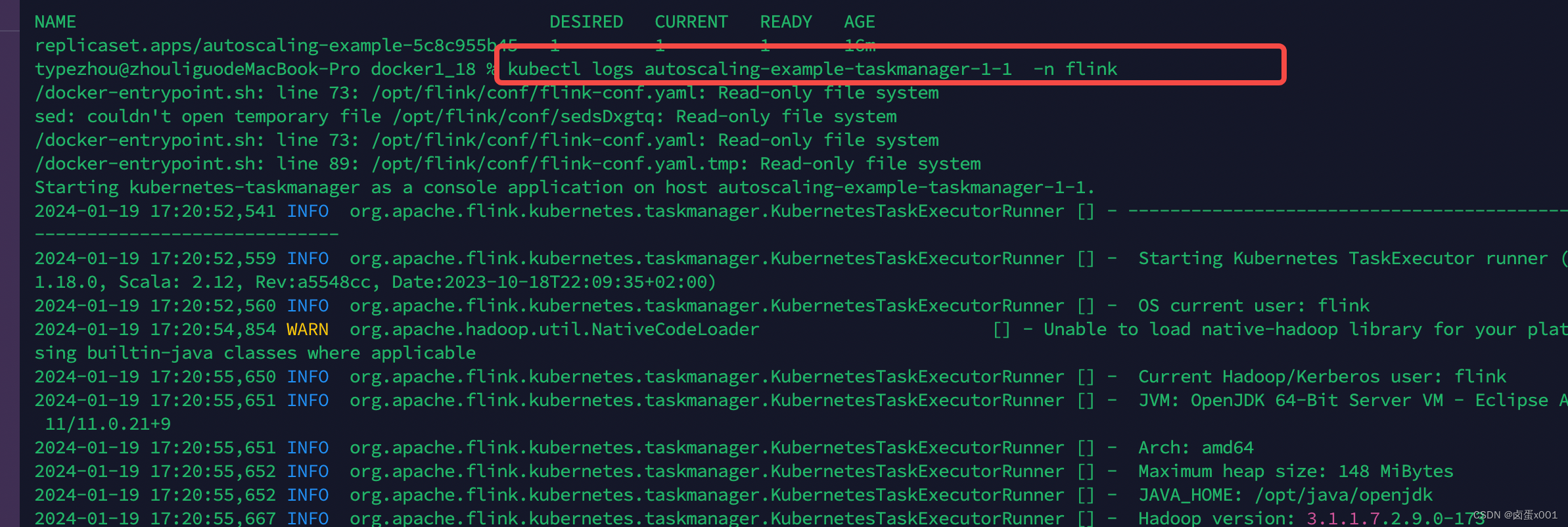
flink operator 拉取阿里云私有镜像(其他私有类似)
创建 k8s secret kubectl --namespace flink create secret docker-registry aliyun-docker-registry --docker-serverregistry.cn-shenzhen.aliyuncs.com --docker-usernameops_acr1060896234 --docker-passwordpasswd --docker-emailDOCKER_EMAIL注意命名空间指定你使用的 我…...

C语言算法赛——蓝桥杯(省赛试题)
一、十四届C/C程序设计C组试题 十四届程序C组试题A#include <stdio.h> int main() {long long sum 0;int n 20230408;int i 0;// 累加从1到n的所有整数for (i 1; i < n; i){sum i;}// 输出结果printf("%lld\n", sum);return 0; }//十四届程序C组试题B…...
【文本到上下文 #2】:NLP 的数据预处理步骤
一、说明 欢迎阅读此文,NLP 爱好者!当我们继续探索自然语言处理 (NLP) 的广阔前景时,我们已经在最初的博客中探讨了它的历史、应用和挑战。今天,我们更深入地探讨 NLP 的核心——数据预处理的复杂世界。 这篇文章是我们的“完整 N…...
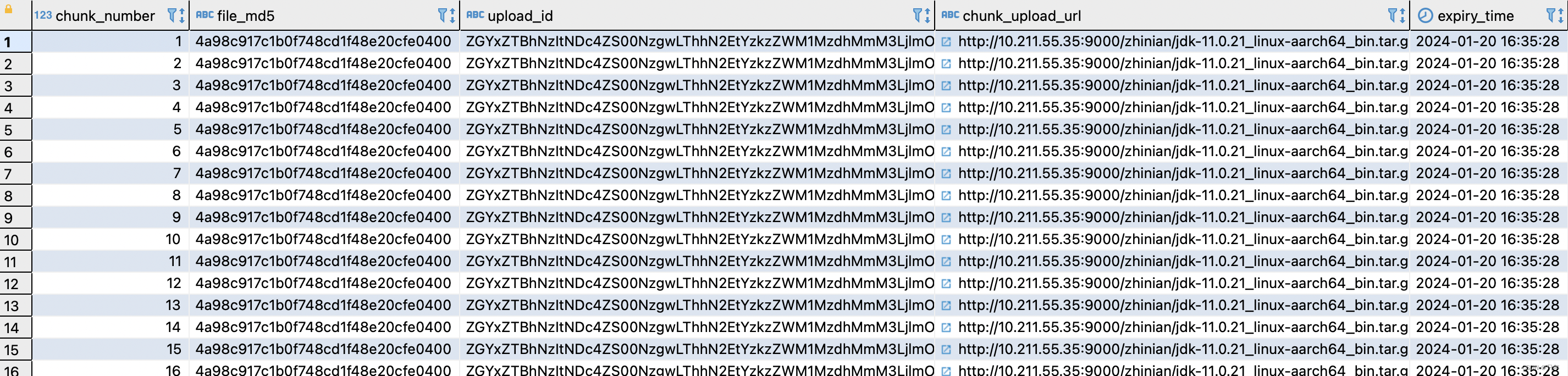
Minio文件分片上传实现
资源准备 MacM1Pro 安装Parallels19.1.0请参考 https://blog.csdn.net/qq_41594280/article/details/135420241 MacM1Pro Parallels安装CentOS7.9请参考 https://blog.csdn.net/qq_41594280/article/details/135420461 部署Minio和整合SpringBoot请参考 https://blog.csdn.net/…...
C语言总结十一:自定义类型:结构体、枚举、联合(共用体)
本篇博客详细介绍C语言最后的三种自定义类型,它们分别有着各自的特点和应用场景,重点在于理解这三种自定义类型的声明方式和使用,以及各自的特点,最后重点掌握该章节常考的考点,如:结构体内存对齐问题&…...

解决Spring Boot应用打包后文件访问问题
在Spring Boot项目的开发过程中,一个常见的挑战是如何有效地访问和操作资源文件。这一挑战尤其显著当应用从IDE环境(如IntelliJ IDEA)迁移到被打包成JAR文件后的生产环境。开发者经常遇到的问题是,在IDE中运行正常的代码ÿ…...

循环神经网络的变体模型-LSTM、GRU
一.LSTM(长短时记忆网络) 1.1基本介绍 长短时记忆网络(Long Short-Term Memory,LSTM)是一种深度学习模型,属于循环神经网络(Recurrent Neural Network,RNN)的一种变体。…...

视频图像的color range简介
介绍 研究FFmpeg发现,在avcodec.h中有关于color的解释,主要有四个属性,primaries、transfer、space和range。 color primaries: 基于RGB空间对应的绝对颜色XYZ的变换,决定了最终三原色RGB分别是什么颜色;…...

常用工具清单
Mem Reduct — 免费内存优化器 https://mem-reduct.com/#system-requirements Redis — Github 安装地址 Another-Redis-Desktop-Managerhttps://github.com/qishibo/AnotherRedisDesktopManager/tags redishttps://github.com/tporadowski/redis/tags...

轴承‘健康体检’新思路:不用复杂公式,5步教你用CNN从振动信号中‘看’出故障先兆
轴承健康监测:用CNN像AI医生一样"听诊"振动信号 想象一下,医生通过听诊器捕捉心跳的微妙变化,就能预判潜在的健康风险。在工业设备的"健康管理"中,轴承的振动信号就像它的"心跳",而卷积…...

从PyTorch到边缘设备:手把手教你用OpenVINO优化YOLOv5模型并在Jetson Orin上部署
从PyTorch到边缘设备:OpenVINO优化YOLOv5模型与Jetson Orin部署实战 在工业质检、智慧零售等实时场景中,将YOLOv5这类目标检测模型部署到Jetson Orin等边缘设备时,开发者常面临三大挑战:模型体积臃肿导致内存不足、计算资源有限影…...

ubuntu服务器部署ai应用如何通过taotoken实现多模型稳定调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu 服务器部署 AI 应用如何通过 Taotoken 实现多模型稳定调用 在 Ubuntu 服务器上部署 AI 应用时,开发者常常面临一…...
)
STM32单片机引脚功能详解——从GPIO到AFIO的标准库配置指南(硬件总结四)
前言 在STM32的开发中,引脚是MCU与外部电路交互的物理桥梁。STM32F103C8T6这款经典的Cortex-M3单片机在LQFP48封装下仅有48个引脚,却能支持GPIO、ADC、USART、SPI、I2C、定时器、USB等多种外设功能——这得益于其灵活的多功能引脚复用机制。深入理解引脚…...

将JSON文件作为Python的配置文件,读取和使用的写法
import osimport json#获取配置path os.getcwd() os.sep "config.json"conf Nonewith open(path, "r", encoding"utf-8") as f:if conf is None:conf json.loads(f.read())heard {"_token": f"{conf[token]}"}...

STM32CUBEMX+Keil AC6编译提速实战:解决LWIP和绝对地址警告的坑
STM32CUBEMXKeil AC6编译提速实战:解决LWIP和绝对地址警告的坑 当STM32开发者从Keil AC5编译器切换到AC6时,往往会遇到两个典型问题:LWIP编译错误和绝对地址警告。本文将深入分析这些问题的根源,并提供经过验证的解决方案…...

深度解析Py-ART雷达数据处理:从数据校正到高级反演的全流程实战
深度解析Py-ART雷达数据处理:从数据校正到高级反演的全流程实战 【免费下载链接】pyart The Python-ARM Radar Toolkit. A data model driven interactive toolkit for working with weather radar data. 项目地址: https://gitcode.com/gh_mirrors/py/pyart …...
!)
AI大模型Agent面试,超详细(附答案)!
AI大模型Agent面试,超详细(➕答案)!假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。 接下来告诉你一条最快的邪修路线, 3个月即可成为模型大师,薪资直接起飞。阶段1:大模型基础阶段2:RA…...

极域电子教室破解指南:3步重获电脑控制权的终极方案
极域电子教室破解指南:3步重获电脑控制权的终极方案 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在机房上课时,被极域电子教室的全屏广播困住无…...