【文本到上下文 #2】:NLP 的数据预处理步骤

一、说明
欢迎阅读此文,NLP 爱好者!当我们继续探索自然语言处理 (NLP) 的广阔前景时,我们已经在最初的博客中探讨了它的历史、应用和挑战。今天,我们更深入地探讨 NLP 的核心——数据预处理的复杂世界。
这篇文章是我们的“完整 NLP 指南:文本到上下文”博客系列的第二部分。我们的重点非常明确:我们深入研究为 NLP 任务奠定基础所必需的关键数据预处理步骤。虽然 NLP 的进步使得能够开发能够感知和理解人类语言的应用程序,但仍然存在一个关键的先决条件——以机器可以理解的格式准备并向机器提供数据。这个过程涉及一系列多样化且重要的预处理步骤。
以下是本次深入研究中的预期内容:
- 标记化和文本清理:探索将文本分解为有意义的单元并确保原始且易于理解的语言的艺术。这包括处理标点符号和细化文本以进行进一步处理。
- 停用词删除:了解为什么删除某些单词对于关注数据集中更有意义的内容至关重要。
- 词干提取和词形还原:深入研究文本规范化技术,了解何时以及如何使用词干提取或词形还原将单词简化为词根形式。
- 词性标注 (POS):探索为每个单词分配语法类别如何有助于更深入地理解句子结构和上下文。
- 命名实体识别 (NER):通过识别和分类文本中的实体,揭示 NER 在增强语言理解方面的作用。
其中每个步骤都是将原始文本翻译成机器可以理解的语言的关键构建块,为更高级的 NLP 任务奠定了基础。
在本次探索结束时,您不仅会牢牢掌握这些基本的预处理步骤,而且还会为我们旅程的下一阶段——探索高级文本表示技术做好准备。让我们深入了解 NLP 数据预处理的要点并增强自己的能力。快乐编码!
二. 分词和文本清理
NLP 的核心是将文本分解为有意义的单元的艺术。标记化是将文本分割成单词、短语甚至句子(标记)的过程。这是为进一步分析奠定基础的第一步。与文本清理(我们删除不必要的字符、数字和符号)相结合,标记化可确保我们使用原始的、可理解的语言单元。
#!pip install nltk
# Example Tokenization and Text Cleaning
text = "NLP is amazing! Let's explore its wonders."
tokens = nltk.word_tokenize(text)
cleaned_tokens = [word.lower() for word in tokens if word.isalpha()]
print(cleaned_tokens)['nlp', 'is', 'amazing', 'let', 'explore', 'its', 'wonders']三、 停用词删除:
并非所有单词对句子的含义都有同等的贡献。像“the”或“and”这样的停用词通常会被过滤掉,以专注于更有意义的内容。
# Example Stop Words
from nltk.corpus import stopwords
stop_words = set(stopwords.words("english"))
filtered_sentence = [word for word in cleaned_tokens if word not in stop_words]
print(filtered_sentence)['nlp', 'amazing', 'let', 'explore', 'wonders']四、词干提取和词形还原
词干提取和词形还原都是自然语言处理 (NLP) 中使用的文本规范化技术,用于将单词还原为其基本形式或词根形式。虽然他们的共同目标是简化单词,但他们在应用语言知识方面的运作方式有所不同。
词干提取:还原为根形式
词干提取涉及切断单词的前缀或后缀以获得其词根或基本形式,称为词干。目的是将具有相似含义的单词视为相同的单词。词干提取是一种基于规则的方法,并不总是产生有效的单词,但计算量较小。
词形还原:转换为字典形式
另一方面,词形还原涉及将单词减少为其基本形式或字典形式,称为词条。它考虑了句子中单词的上下文并应用形态分析。词形还原会产生有效的单词,并且与词干提取相比在语言学上更具信息性。
何时使用词干提取与词形还原:
词干提取:
- 优点:简单且计算成本较低。
- 缺点:可能并不总是产生有效的单词。
词形还原:
- 优点:产生有效的单词;考虑语言背景。
- 缺点:比词干提取的计算强度更大。
在词干提取和词形还原之间进行选择:

Day 4: Stemming and Lemmatization - Nomidl
词干提取和词形还原之间的选择取决于 NLP 任务的具体要求。如果您需要一种快速而直接的文本分析方法,词干提取可能就足够了。然而,如果语言准确性至关重要,特别是在信息检索或问答等任务中,则通常首选词形还原。
在实践中,选择通常取决于基于 NLP 应用程序的具体特征的计算效率和语言准确性之间的权衡。
# Example Stemming, and Lemmatization
from nltk.stem import PorterStemmer, WordNetLemmatizerstemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()stemmed_words = [stemmer.stem(word) for word in filtered_sentence]
lemmatized_words = [lemmatizer.lemmatize(word) for word in filtered_sentence]print(stemmed_words)
print(lemmatized_words)['nlp', 'amaz', 'let', 'explor', 'wonder']
['nlp', 'amazing', 'let', 'explore', 'wonder']五、词性标注:
词性标注(词性标注)是一种自然语言处理任务,其目标是为给定文本中的每个单词分配语法类别(例如名词、动词、形容词等)。这可以更深入地理解句子中每个单词的结构和功能。
Penn Treebank POS 标签集是一种广泛使用的标准,用于在英语文本中表示这些词性标签。
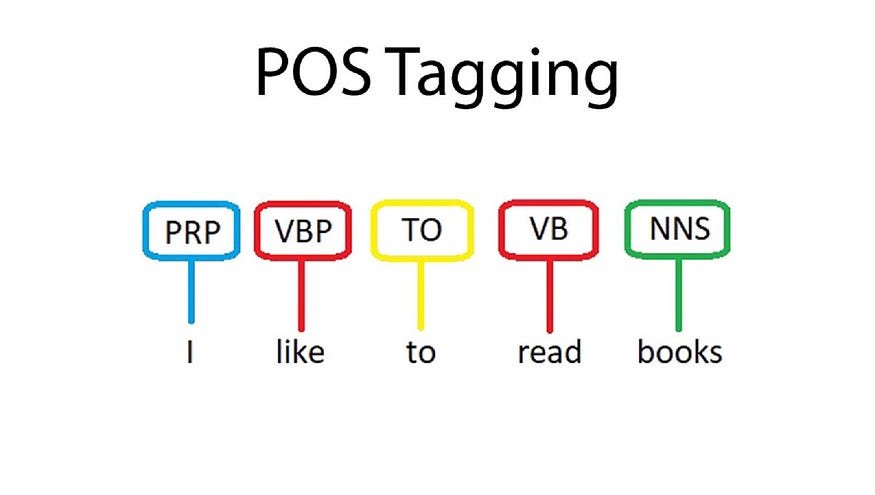
# Example Part-of-Speech Tagging
from nltk import pos_tag
pos_tags = nltk.pos_tag(filtered_sentence)
print(pos_tags)[('nlp', 'RB'), ('amazing', 'JJ'), ('let', 'NN'), ('explore', 'NN'), ('wonders', 'NNS')]六、命名实体识别(NER):
NER 通过对给定文本中的名称、位置、组织等实体进行识别和分类,将语言理解提升到一个新的水平。这对于从非结构化数据中提取有意义的信息至关重要。
# Example Named Entity Recognition (NER)
from nltk import ne_chunkner_tags = ne_chunk(pos_tags)
print(ner_tags)(S nlp/RB amazing/JJ let/NN explore/NN wonders/NNS)七、NLP 预处理步骤的实际应用
虽然我们深入研究了 NLP 预处理的技术方面,但了解如何在现实场景中应用这些步骤也同样重要。让我们探讨一些值得注意的例子:
社交媒体情感分析中的标记化和文本清理
在社交媒体情感分析中,标记化和文本清理至关重要。例如,在分析推文以评估公众对新产品的看法时,标记化有助于将推文分解为单个单词或短语。文本清理用于消除社交媒体文本中常见的话题标签、提及和 URL 等噪音。
import re
def clean_tweet(tweet):tweet = re.sub(r'@\w+', '', tweet) # Remove mentionstweet = re.sub(r'#\w+', '', tweet) # Remove hashtagstweet = re.sub(r'http\S+', '', tweet) # Remove URLsreturn tweettweet = "Loving the new #iPhone! Best phone ever! @Apple"
clean_tweet(tweet)'Loving the new ! Best phone ever! ' 搜索引擎中的停用词删除
搜索引擎广泛使用停用词删除。在处理搜索查询时,通常会删除“the”、“is”和“in”等常用词,以重点关注更有可能与搜索结果相关的关键字。
文本分类中的词干提取和词形还原
新闻机构和内容聚合商经常使用词干提取和词形还原进行文本分类。通过将单词简化为基本形式或词根形式,算法可以更轻松地将新闻文章分类为“体育”、“政治”或“娱乐”等主题。
语音助手中的词性标记
亚马逊的 Alexa 或苹果的 Siri 等语音助手使用词性标记来提高语音识别和自然语言理解。通过确定单词的语法上下文,这些助手可以更准确地解释用户请求。
客户支持自动化中的命名实体识别 (NER)
NER 广泛用于客户支持聊天机器人。通过识别和分类产品名称、位置或用户问题等实体,聊天机器人可以对客户的询问提供更有效和量身定制的响应。
这些例子凸显了 NLP 预处理步骤在各个行业中的实际意义,使抽象概念更加具体、更容易掌握。了解这些应用程序不仅可以提供背景信息,还可以激发未来项目的想法。
八、结论
在本文中,我们仔细浏览了增强 NLP 任务文本所必需的各种数据预处理步骤。从最初通过标记化和清理对文本进行分解,到更高级的词干提取、词形还原、词性标记和命名实体识别过程,我们为有效理解和处理语言数据奠定了坚实的基础。
然而,我们的旅程并没有就此结束。处理后的文本虽然现在更加结构化和信息丰富,但仍需要进一步转换才能完全被机器理解。在下一部分中,我们将深入研究文本表示技术。这些技术,包括词袋模型、TF-IDF(词频-逆文档频率)以及词嵌入的介绍,对于将文本转换为机器不仅可以理解而且可以用于各种用途的格式至关重要。复杂的 NLP 任务。
因此,请继续关注我们,我们将继续揭开 NLP 的复杂性。我们的探索将为您提供将原始文本转换为有意义的数据的知识,为高级分析和应用做好准备。祝您编码愉快,我们下一篇文章再见!
相关文章:
【文本到上下文 #2】:NLP 的数据预处理步骤
一、说明 欢迎阅读此文,NLP 爱好者!当我们继续探索自然语言处理 (NLP) 的广阔前景时,我们已经在最初的博客中探讨了它的历史、应用和挑战。今天,我们更深入地探讨 NLP 的核心——数据预处理的复杂世界。 这篇文章是我们的“完整 N…...
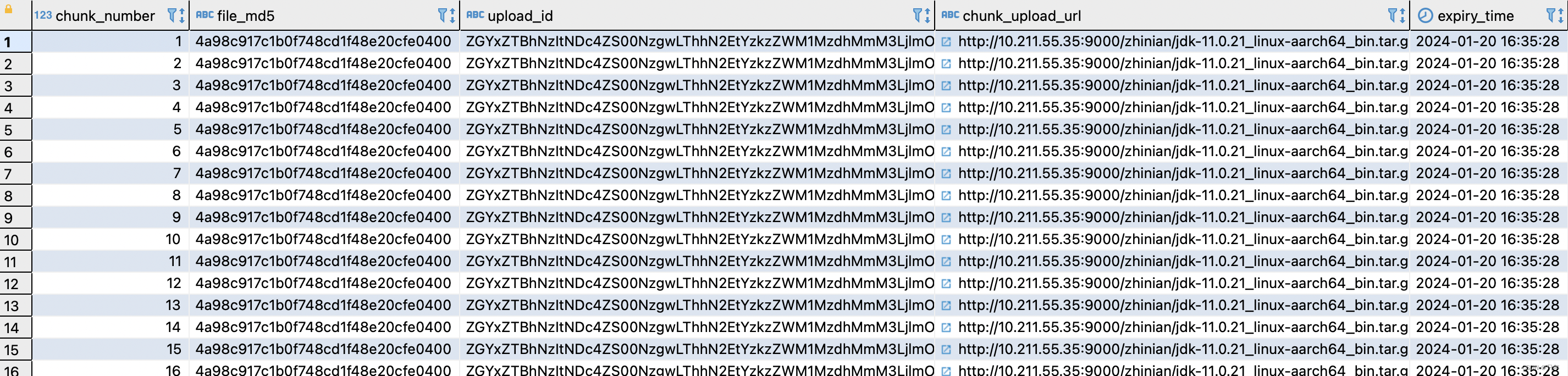
Minio文件分片上传实现
资源准备 MacM1Pro 安装Parallels19.1.0请参考 https://blog.csdn.net/qq_41594280/article/details/135420241 MacM1Pro Parallels安装CentOS7.9请参考 https://blog.csdn.net/qq_41594280/article/details/135420461 部署Minio和整合SpringBoot请参考 https://blog.csdn.net/…...
C语言总结十一:自定义类型:结构体、枚举、联合(共用体)
本篇博客详细介绍C语言最后的三种自定义类型,它们分别有着各自的特点和应用场景,重点在于理解这三种自定义类型的声明方式和使用,以及各自的特点,最后重点掌握该章节常考的考点,如:结构体内存对齐问题&…...

解决Spring Boot应用打包后文件访问问题
在Spring Boot项目的开发过程中,一个常见的挑战是如何有效地访问和操作资源文件。这一挑战尤其显著当应用从IDE环境(如IntelliJ IDEA)迁移到被打包成JAR文件后的生产环境。开发者经常遇到的问题是,在IDE中运行正常的代码ÿ…...

循环神经网络的变体模型-LSTM、GRU
一.LSTM(长短时记忆网络) 1.1基本介绍 长短时记忆网络(Long Short-Term Memory,LSTM)是一种深度学习模型,属于循环神经网络(Recurrent Neural Network,RNN)的一种变体。…...

视频图像的color range简介
介绍 研究FFmpeg发现,在avcodec.h中有关于color的解释,主要有四个属性,primaries、transfer、space和range。 color primaries: 基于RGB空间对应的绝对颜色XYZ的变换,决定了最终三原色RGB分别是什么颜色;…...

tcp的三次握手
http 和 https 都是是基于 TCP 的请求,https 是 http 加上 tls 连接。TCP 是面向连接的协议。 对于 http1.1 协议chrome 限制在同一个域名下最多可以建立 6 个 tcp 连接,所以如果在同一个域名下,同时有超过 6 个请求发生,那么多余…...

unity 矩阵探究
public void MatrixTest1(){ ///Matrix4x4 是列矩阵,就是一个vector4表示一列,所以在c#中矩阵和Vector4只能矩阵右乘坐标。但是在shader中是矩阵左乘坐标,所以在shader中是行矩阵 Matrix4x4 moveMatrix1 new Matrix4x4(new Vector4(1,0,0,0)…...
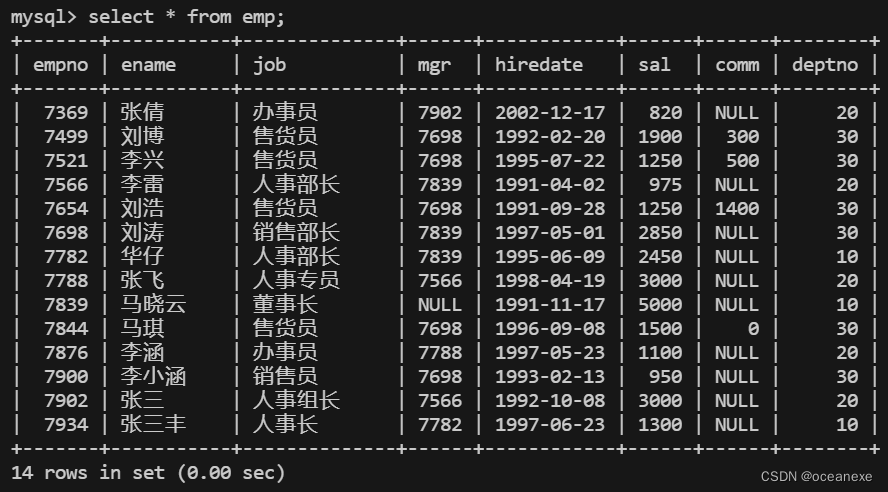
MySQL---单表查询综合练习
创建emp表 CREATE TABLE emp( empno INT(4) NOT NULL COMMENT 员工编号, ename VARCHAR(10) COMMENT 员工名字, job VARCHAR(10) COMMENT 职位, mgr INT(4) COMMENT 上司, hiredate DATE COMMENT 入职时间, sal INT(7) COMMENT 基本工资, comm INT(7) COMMENT 补贴, deptno INT…...

Python项目——搞怪小程序(PySide6+Pyinstaller)
1、介绍 使用python编写一个小程序,回答你是猪吗。 点击“是”提交,弹窗并退出。 点击“不是”提交,等待5秒,重新选择。 并且隐藏了关闭按钮。 2、实现 新建一个项目。 2.1、设计UI 使用Qt designer设计一个UI界面,…...

MySQL练习题
参考:https://blog.csdn.net/paul0127/article/details/82529216 数据表介绍 --1.学生表 Student(SId,Sname,Sage,Ssex) --SId 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别 --2.课程表 Course(CId,Cname,TId) --CId 课程编号,Cname 课程名称,TId 教师编号…...

vue-项目打包、配置路由懒加载
1. 简介 在现代前端开发中,Vue.js因其简洁、灵活和高效的特点,已经成为许多开发者的首选框架。 在Vue项目中,打包部署和路由懒加载是两个非常重要的环节。 打包Vue项目是为了将源代码转换为浏览器可以解析的JavaScript文件,以便…...

词语的魔力:语言在我们生活中的艺术与影响
Words That Move Mountains: The Art and Impact of Language in Our Lives 词语的魔力:语言在我们生活中的艺术与影响 Hello there, wonderful people! Today, I’d like to gab about the magical essence of language that’s more than just a chatty tool in o…...

android List,Set,Map区别和介绍
List 元素存放有序,元素可重复 1.LinkedList 链表,插入删除,非线性安全,插入和删除操作是双向链表操作,增加删除快,查找慢 add(E e)//添加元素 addFirst(E e)//向集合头部添加元素 addList(E e)//向集合…...
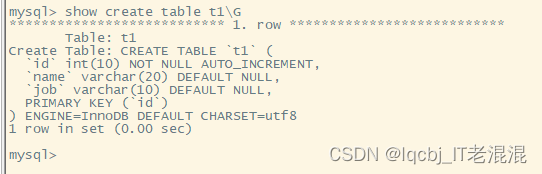
Mysql 编译安装部署
Mysql 编译安装部署 环境: 172.20.26.198(Centos7.6) 源码安装Mysql-5.7 大概步骤如下: 1、上传mysql-5.7.28.tar.gz 、boost_1_59_0.tar 到/usr/src 目录下 2、安装依赖 3、cmake 4、make && make install 5、…...

【目标检测】YOLOv5算法实现(九):模型预测
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。 本系列文章主要以YOLOv5为例完成算法的实现,后续修改、增加相关模…...

centos宝塔远程服务器怎么链接?
要远程连接CentOS宝塔服务器,可以按照以下步骤操作: 打开终端或远程连接工具,比如PuTTY。输入服务器的IP地址和SSH端口号(默认为22),点击连接。输入用户名和密码进行登录。 如果你已经安装了宝塔面板&…...
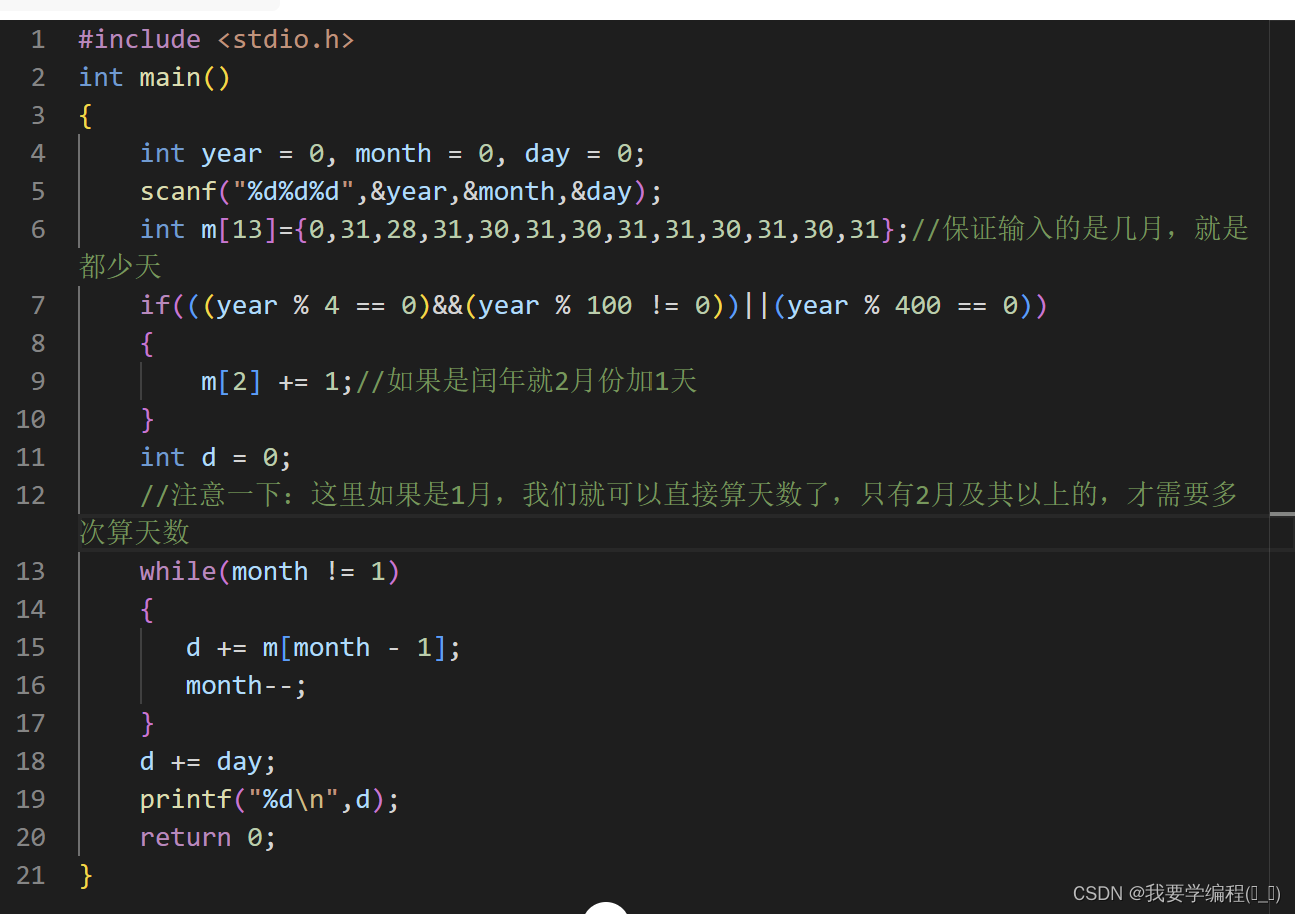
C语言练习day8
变种水仙花 变种水仙花_牛客题霸_牛客网 题目: 思路:我们拿到题目的第一步可以先看一看题目给的例子,1461这个数被从中间拆成了两部分:1和461,14和61,146和1,不知道看到这大家有没有觉得很熟…...

蓝凌OA-sysuicomponent-任意文件上传_exp-漏洞复现
0x01阅读须知 技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的…...

C#,入门教程(38)——大型工程软件中类(class)修饰词partial的使用方法
上一篇: C#,入门教程(37)——优秀程序员的修炼之道https://blog.csdn.net/beijinghorn/article/details/125011644 一、大型(工程应用)软件倚重 partial 先说说大型(工程应用)软件对源代码的文件及函数“…...

电力系统时序一致性保障:elec-ops-prediction的长时序稳定性约束实现
电力系统时序一致性保障:elec-ops-prediction的长时序稳定性约束实现 【免费下载链接】elec-ops-prediction elec-ops-prediction 是 CANN 社区 Electrical Engineering SIG(电力行业兴趣小组)旗下的电力负荷预测算子库, 聚焦于电…...

安达发|aps软件系统:塑料薄膜业数字化升级,破生产管理难题
安达发APS高级生产计划智能排产排程自动排单软件系统推荐_MES 在包装、农业、电子、医疗等产业高速发展的带动下,我国塑料薄膜行业市场规模持续扩张,行业竞争从单纯的产能比拼转向精细化、智能化管理竞争。当前塑料薄膜企业普遍面临多品种、小批量、定制…...
)
从零构建Sora 2-DaVinci双引擎协同工作站:Intel Xeon W9-3400系列+RTX 6000 Ada专属散热/供电/PCIe拓扑配置清单(附实测带宽衰减曲线)
更多请点击: https://codechina.net 第一章:Sora 2与DaVinci整合的架构演进与协同范式 Sora 2作为新一代多模态时序生成引擎,其核心能力已从单向视频合成跃迁至具备物理感知、因果推理与跨模态对齐的闭环生成范式。DaVinci则持续强化其在专业…...

VAP特效动画创作指南:3步打造跨平台炫酷视觉特效
VAP特效动画创作指南:3步打造跨平台炫酷视觉特效 【免费下载链接】vap VAP是企鹅电竞开发,用于播放特效动画的实现方案。具有高压缩率、硬件解码等优点。同时支持 iOS,Android,Web 平台。 项目地址: https://gitcode.com/gh_mirrors/va/vap 还在为…...
)
安卓用户专属福利:免费开源工具一键搞定.m3u8.sqlite视频提取与合并(附TS转MP4方法)
安卓用户专属:零门槛实现.m3u8.sqlite视频提取与格式转换全攻略 每次在手机上缓存了课程视频,却发现文件格式无法直接播放?作为安卓用户,你可能经常遇到.m3u8.sqlite这种特殊缓存格式的困扰。本文将为你揭秘这类文件的本质&#x…...

FanControl:Windows平台终极风扇控制解决方案
FanControl:Windows平台终极风扇控制解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCont…...

通过Taotoken CLI工具一键配置开发环境中的多工具API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境中的多工具API密钥 在团队协作开发或需要同时使用多个AI工具的项目中,手动为每个…...

六月学术盛宴启幕 | 2026年6月国际学术会议重磅来袭
2026年6月学术会议列表 | 会议亮点总结 顶尖大咖云集:学界领军人物、资深学者倾情助阵,汇聚全球科研力量现场分享前沿成果 顶尖院校强力赋能:北航、桂林电子科技大学、南方科技大学、华南理工大学等众多名校联合组织 正规出版渠道 & 高…...

Logback彩色日志进阶玩法:自定义颜色规则、区分环境开关,以及文件日志的‘去色’指南
Logback彩色日志进阶实战:从炫彩控制台到严谨生产环境的全链路配置 在软件开发的生命周期中,日志是我们最忠实的伙伴。想象一下深夜调试时,满屏灰白的日志中突然跳出一行醒目的红色ERROR信息——这就是彩色日志赋予我们的"视觉直觉"…...

一键解决Windows运行库问题:Visual C++ AIO完整安装指南
一键解决Windows运行库问题:Visual C AIO完整安装指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的困扰:新下载…...