循环神经网络的变体模型-LSTM、GRU
一.LSTM(长短时记忆网络)
1.1基本介绍
长短时记忆网络(Long Short-Term Memory,LSTM)是一种深度学习模型,属于循环神经网络(Recurrent Neural Network,RNN)的一种变体。LSTM的设计旨在解决传统RNN中遇到的长序列依赖问题,以更好地捕捉和处理序列数据中的长期依赖关系。
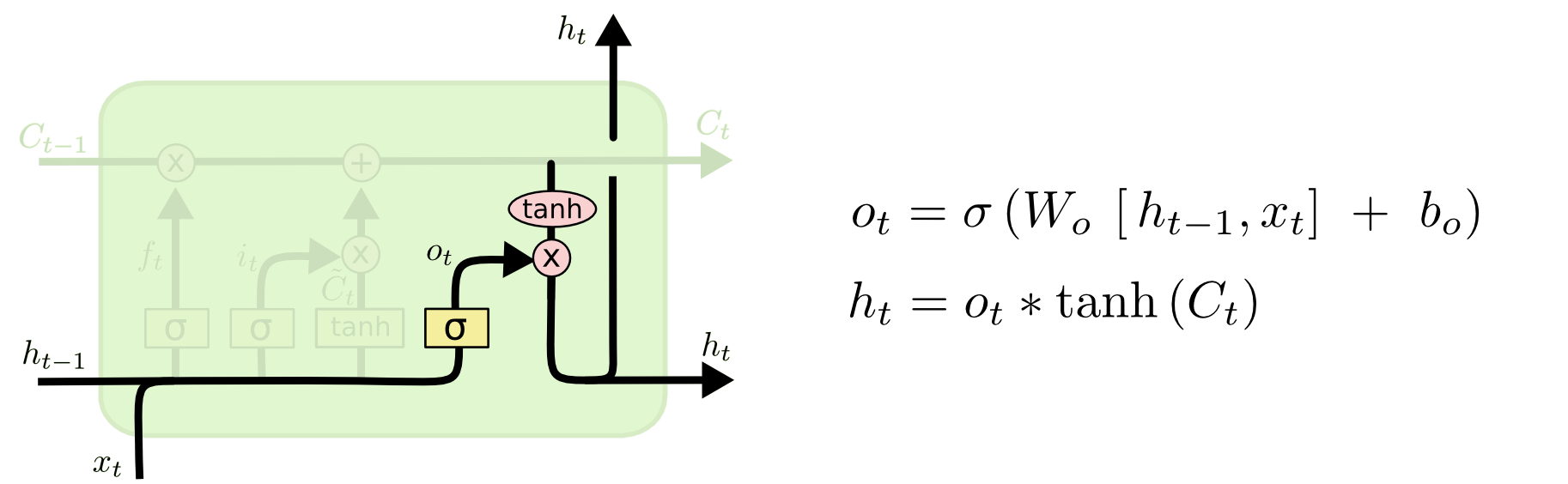
下面是LSTM的内部结构图
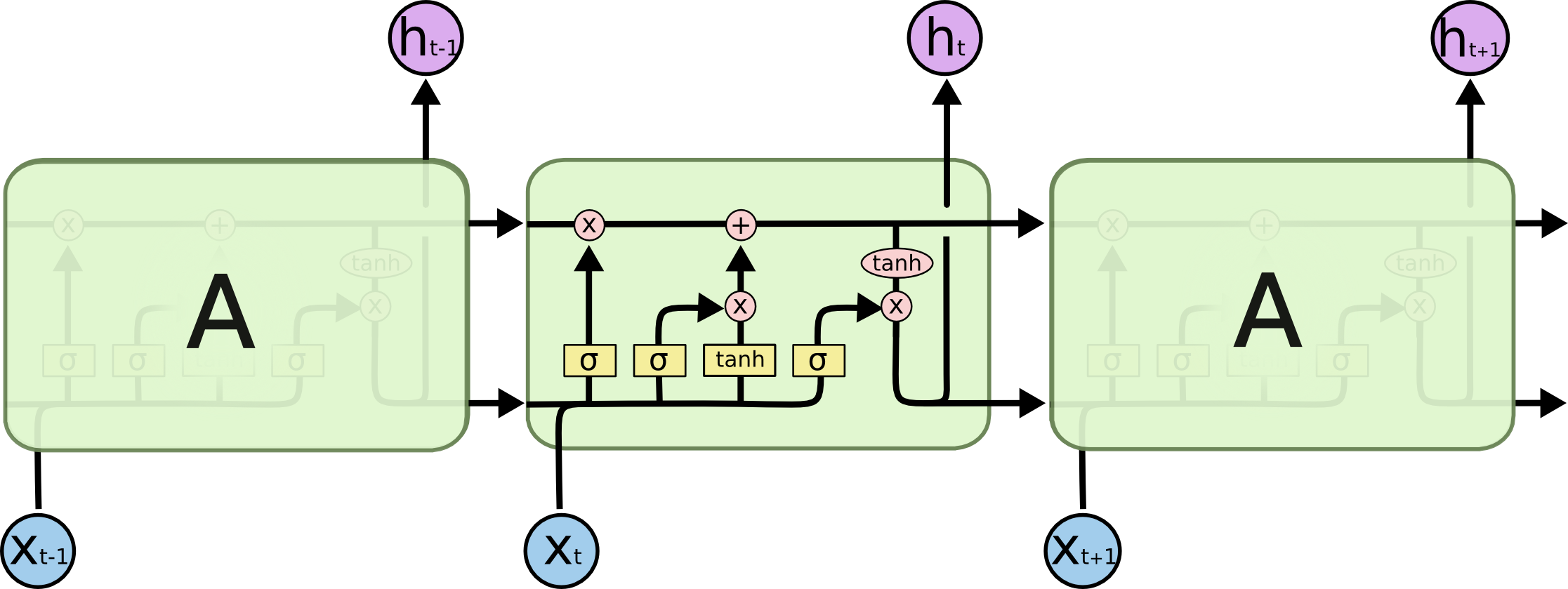
LSTM为了改善梯度消失,引入了一种特殊的存储单元,该存储单元被设计用于存储和提取长期记忆。与传统的RNN不同,LSTM包含三个关键的门(gate)来控制信息的流动,这些门分别是遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。
LSTM的结构允许它有效地处理和学习序列中的长期依赖关系,这在许多任务中很有用,如自然语言处理、语音识别和时间序列预测。由于其能捕获长期记忆,LSTM成为深度学习中重要的组件之一。
1.2 主要组成部分和工作原理
首先我们先弄明白LSTM单元中的每个符号的含义。每个黄色方框表示一个神经网络层,由权值,偏置以及激活函数组成;每个粉色圆圈表示元素级别操作;箭头表示向量流向;相交的箭头表示向量的拼接;分叉的箭头表示向量的复制。

以下是LSTM的主要组成部分和工作原理:
-
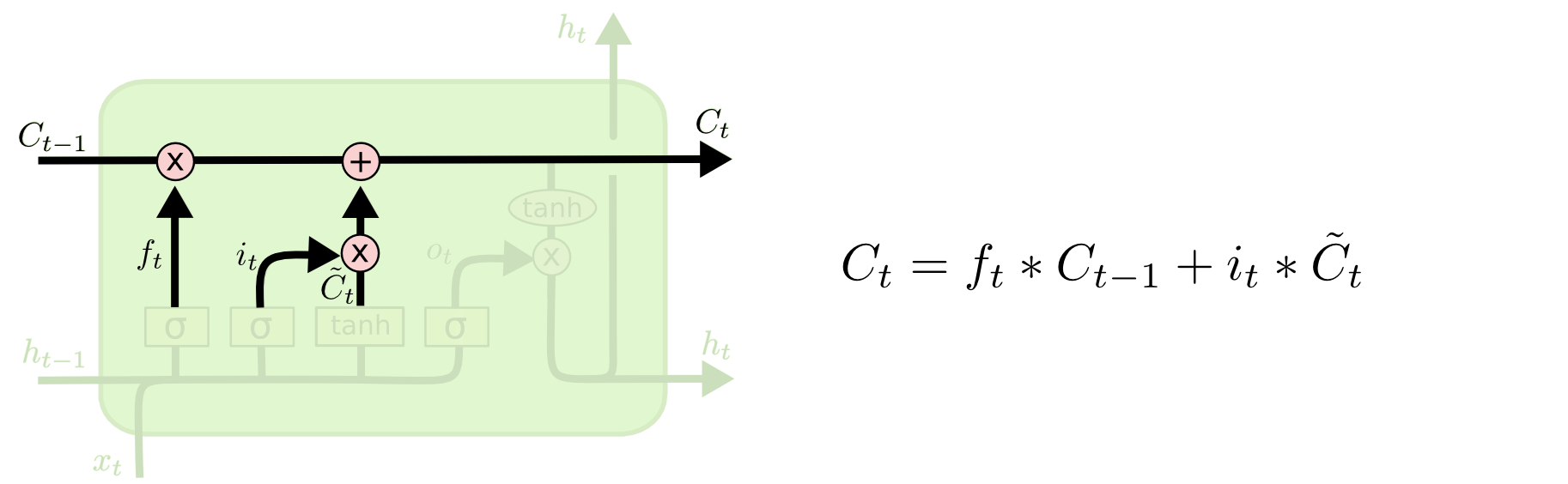
细胞状态(Cell State):
细胞状态是LSTM网络的主要存储单元,用于存储和传递长期记忆。细胞状态在序列的每一步都会被更新。在LSTM中,细胞状态负责保留网络需要记住的信息,以便更好地处理长期依赖关系。在每个时间步,LSTM通过一系列的操作来更新细胞状态。这些操作包括遗忘门、输入门和输出门的计算。细胞状态在这些门的帮助下动态地保留和遗忘信息。
-
遗忘门(Forget Gate):
遗忘门决定哪些信息应该被遗忘,从而允许网络丢弃不重要的信息。它通过一个sigmoid激活函数生成一个介于0和1之间的值,用于控制细胞状态中信息的丢失程度。
遗忘门的计算过程如下:
2.1 输入:
上一时刻的隐藏状态(或者是输入数据的向量)
当前时刻的输入数据
2.2 计算遗忘门的值:
将上一时刻的隐藏状态和当前时刻的输入数据拼接在一起。
通过一个带有sigmoid激活函数的全连接层(通常称为遗忘门层)得到介于0和1之间的值。
这个值表示细胞状态中哪些信息应该被保留(接近1),哪些信息应该被遗忘(接近0)。
2.3 遗忘操作:
将上一时刻的细胞状态与遗忘门的输出相乘,以决定保留哪些信息。
2.4数学表达式如下:
遗忘门的输出:
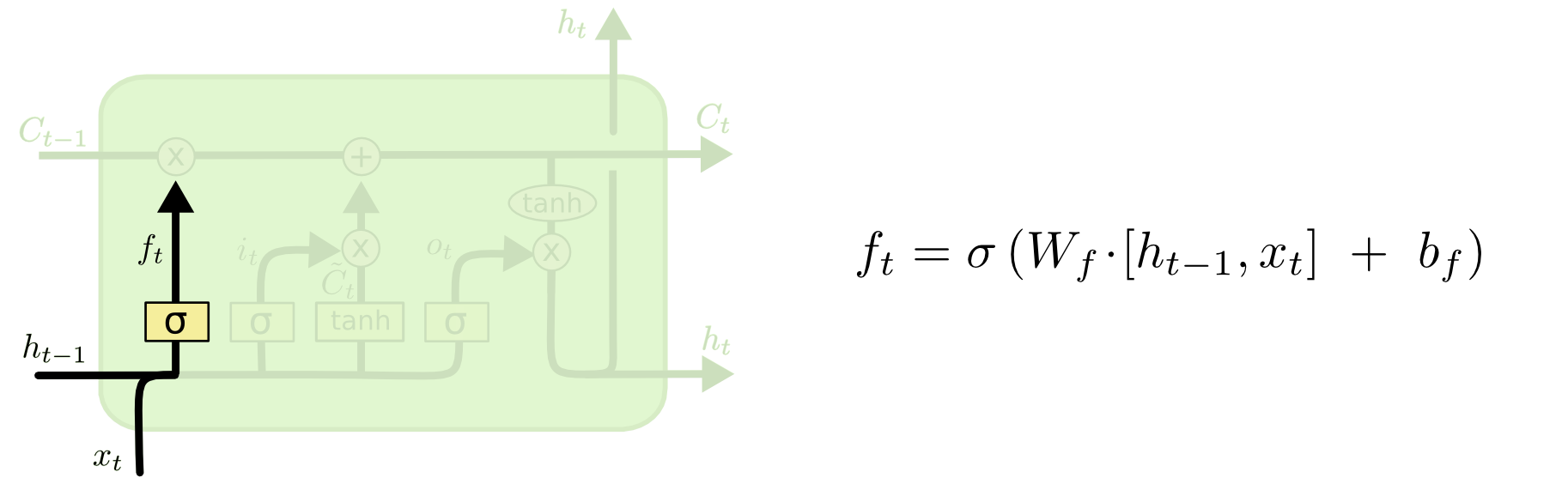
其中:
W f 和 b f 是遗忘门的权重矩阵和偏置向量。 W_f 和 b_f是遗忘门的权重矩阵和偏置向量。 Wf和bf是遗忘门的权重矩阵和偏置向量。
h t − 1 是上一时刻的隐藏状态。 h_{t−1} 是上一时刻的隐藏状态。 ht−1是上一时刻的隐藏状态。
x t 是当前时刻的输入数据。 x_t是当前时刻的输入数据。 xt是当前时刻的输入数据。
σ 是 s i g m o i d 激活函数。 σ 是sigmoid激活函数。 σ是sigmoid激活函数。
遗忘门的输出 ft 决定了细胞状态中上一时刻信息的保留程度。这个机制允许LSTM网络在处理时间序列数据时更有效地记住长期依赖关系。
- 输入门(Input Gate):
输入门负责确定在当前时间步骤中要添加到细胞状态的新信息。类似于遗忘门,输入门使用sigmoid激活函数产生一个介于0和1之间的值,表示要保留多少新信息,并使用tanh激活函数生成一个新的候选值。
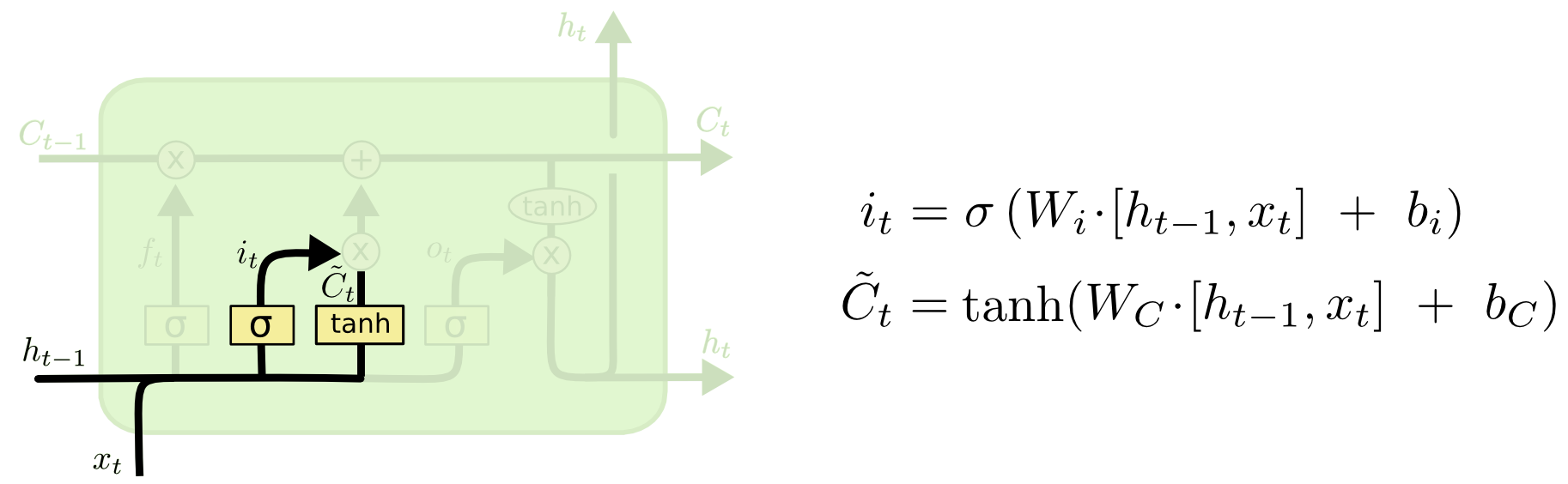 输入门的计算过程如下:
输入门的计算过程如下:
(1)输入门的输出计算:将上一时刻的隐藏状态(或者是输入数据)和当前时刻的输入数据拼接在一起。通过一个带有sigmoid激活函数的全连接层得到介于0和1之间的值。这个值表示要保留的新信息的程度。
(2)生成新的候选值:将上一时刻的隐藏状态(或者是输入数据)和当前时刻的输入数据拼接在一起。通过一个带有tanh激活函数的全连接层得到一个新的候选值(介于-1和1之间)。
(3)更新细胞状态的操作:将输入门的输出与新的候选值相乘,得到要添加到细胞状态的新信息。
- 输出门(Output Gate):
输出门(Output Gate)在LSTM中控制细胞在特定时间步上的输出。输出门使用sigmoid激活函数产生介于0和1之间的值,这个值决定了在当前时间步细胞状态中有多少信息被输出。同时,输出门的输出与细胞状态经过tanh激活函数后的值相乘,产生最终的LSTM输出。
输出门的计算过程如下:
输出门的输出计算:将上一时刻的隐藏状态(或者是输入数据)和当前时刻的输入数据拼接在一起。通过一个带有sigmoid激活函数的全连接层得到介于0和1之间的值。这个值表示在当前时间步细胞状态中有多少信息要输出。
生成最终的LSTM输出:将当前时刻的细胞状态经过tanh激活函数,得到介于-1和1之间的值。将输出门的输出与tanh激活函数的细胞状态相乘,产生最终的LSTM输出。
1.3 LSTM的基础代码实现
以下是一个基础的实现,其中包括多层双向LSTM的前向传播。请注意,这个实现仍然是一个简化版本,实际应用中可能需要更多的调整和优化。
import numpy as npdef sigmoid(x):return 1 / (1 + np.exp(-x))def tanh(x):return np.tanh(x)def lstm_cell(xt, a_prev, c_prev, parameters):# 从参数中提取权重和偏置Wf = parameters["Wf"]bf = parameters["bf"]Wi = parameters["Wi"]bi = parameters["bi"]Wo = parameters["Wo"]bo = parameters["bo"]Wc = parameters["Wc"]bc = parameters["bc"]# 合并输入和上一个时间步的隐藏状态concat = np.concatenate((a_prev, xt), axis=0)# 遗忘门ft = sigmoid(np.dot(Wf, concat) + bf)# 输入门it = sigmoid(np.dot(Wi, concat) + bi)# 更新细胞状态cct = tanh(np.dot(Wc, concat) + bc)c_next = ft * c_prev + it * cct# 输出门ot = sigmoid(np.dot(Wo, concat) + bo)# 更新隐藏状态a_next = ot * tanh(c_next)# 保存计算中间结果,以便反向传播cache = (xt, a_prev, c_prev, a_next, c_next, ft, it, ot, cct)return a_next, c_next, cachedef lstm_forward(x, a0, parameters):n_x, m, T_x = x.shapen_a = a0.shape[0]a = np.zeros((n_a, m, T_x))c = np.zeros_like(a)caches = []a_prev = a0c_prev = np.zeros_like(a_prev)for t in range(T_x):xt = x[:, :, t]a_next, c_next, cache = lstm_cell(xt, a_prev, c_prev, parameters)a[:,:,t] = a_nextc[:,:,t] = c_nextcaches.append(cache)a_prev = a_nextc_prev = c_nextreturn a, c, cachesdef lstm_model_forward(x, parameters):caches = []a = xc_list = []for layer in parameters:a, c, layer_cache = lstm_forward(a, np.zeros_like(a[:, :, 0]), layer)caches.append(layer_cache)c_list.append(c)return a, c_list, cachesdef dense_layer_forward(a, parameters):W = parameters["W"]b = parameters["b"]z = np.dot(W, a) + ba_next = sigmoid(z)return a_next, zdef model_forward(x, parameters_lstm, parameters_dense):a_lstm, c_list, caches_lstm = lstm_model_forward(x, parameters_lstm)a_dense = a_lstm[:, :, -1]z_dense_list = []for layer_dense in parameters_dense:a_dense, z_dense = dense_layer_forward(a_dense, layer_dense)z_dense_list.append(z_dense)return a_dense, c_list, caches_lstm, z_dense_list# 示例数据和参数
np.random.seed(1)
x = np.random.randn(10, 5, 3) # 10个样本,每个样本5个时间步,每个时间步3个特征# LSTM参数
parameters_lstm = [{"Wf": np.random.randn(5, 8), "bf": np.random.randn(5, 1),"Wi": np.random.randn(5, 8), "bi": np.random.randn(5, 1),"Wo": np.random.randn(5, 8), "bo": np.random.randn(5, 1),"Wc": np.random.randn(5, 8), "bc": np.random.randn(5, 1)},{"Wf": np.random.randn(3, 8), "bf": np.random.randn(3, 1),"Wi": np.random.randn(3, 8), "bi": np.random.randn(3, 1),"Wo": np.random.randn(3, 8), "bo": np.random.randn(3, 1),"Wc": np.random.randn(3, 8), "bc": np.random.randn(3, 1)}
]# Dense层参数
parameters_dense = [{"W": np.random.randn(1, 5), "b": np.random.randn(1, 1)},{"W": np.random.randn(1, 5), "b": np.random.randn(1, 1)}
]# 进行正向传播
a_dense, c_list, caches_lstm, z_dense_list = model_forward(x, parameters_lstm, parameters_dense)# 打印输出形状
print("a_dense.shape:", a_dense.shape)二.GRU(门控循环单元)

2.1 GRU的基本介绍
门控循环单元(GRU,Gated Recurrent Unit)是一种用于处理序列数据的循环神经网络(RNN)变体,旨在解决传统RNN中的梯度消失问题,并提供更好的长期依赖建模。GRU引入了门控机制,类似于LSTM,但相对于LSTM,GRU结构更加简单。
GRU包含两个门:更新门(Update Gate)和重置门(Reset Gate)。这两个门允许GRU网络决定在当前时间步更新细胞状态的程度以及如何利用先前的隐藏状态。
重置门(Reset Gate)的计算:
通过一个sigmoid激活函数计算重置门的输出。重置门决定了在当前时间步,应该忽略多少先前的隐藏状态信息。
更新门(Update Gate)的计算:
通过一个sigmoid激活函数计算更新门的输出。更新门决定了在当前时间步,应该保留多少先前的隐藏状态信息。
候选隐藏状态的计算:
通过tanh激活函数计算一个候选的隐藏状态。
新的隐藏状态的计算:
通过更新门和候选隐藏状态计算新的隐藏状态。
2.2 GRU的代码实现
以下是使用PyTorch库实现基本的门控循环单元(GRU)的代码。PyTorch提供了GRU的高级API,可以轻松实现和使用。下面是一个简单的例子:
import torch
import torch.nn as nn# 定义GRU模型
class SimpleGRU(nn.Module):def __init__(self, input_size, hidden_size):super(SimpleGRU, self).__init__()self.gru = nn.GRU(input_size, hidden_size)def forward(self, x, hidden=None):output, hidden = self.gru(x, hidden)return output, hidden# 示例数据和模型参数
input_size = 3
hidden_size = 5
seq_len = 1 # 序列长度
batch_size = 1# 创建GRU模型
gru_model = SimpleGRU(input_size, hidden_size)# 将输入数据转换为PyTorch的Tensor
x = torch.randn(seq_len, batch_size, input_size)# 前向传播
output, hidden = gru_model(x)# 打印输出形状
print("Output shape:", output.shape)
print("Hidden shape:", hidden.shape)以下是使用NumPy库实现基本的门控循环单元(GRU)的代码。这个实现是一个简化版本,其中包含更新门和重置门的计算,以及候选隐藏状态和新的隐藏状态的计算。
import numpy as npdef sigmoid(x):return 1 / (1 + np.exp(-x))def tanh(x):return np.tanh(x)def gru_cell(a_prev, x, parameters):# 从参数中提取权重和偏置W_r = parameters["W_r"]b_r = parameters["b_r"]W_z = parameters["W_z"]b_z = parameters["b_z"]W_a = parameters["W_a"]b_a = parameters["b_a"]# 计算重置门r_t = sigmoid(np.dot(W_r, np.concatenate([a_prev, x])) + b_r)# 计算更新门z_t = sigmoid(np.dot(W_z, np.concatenate([a_prev, x])) + b_z)# 计算候选隐藏状态tilde_a_t = tanh(np.dot(W_a, np.concatenate([r_t * a_prev, x])) + b_a)# 计算新的隐藏状态a_t = (1 - z_t) * a_prev + z_t * tilde_a_t# 保存计算中间结果,以便反向传播cache = (a_prev, x, r_t, z_t, tilde_a_t, a_t)return a_t, cache# 示例数据和参数
np.random.seed(1)
a_prev = np.random.randn(5, 1) # 上一时刻的隐藏状态
x = np.random.randn(3, 1) # 当前时刻的输入数据# GRU参数
parameters = {"W_r": np.random.randn(5, 8),"b_r": np.random.randn(5, 1),"W_z": np.random.randn(5, 8),"b_z": np.random.randn(5, 1),"W_a": np.random.randn(5, 8),"b_a": np.random.randn(5, 1)
}# 单个GRU单元的前向传播
a_t, cache = gru_cell(a_prev, x, parameters)# 打印输出形状
print("a_t.shape:", a_t.shape)本文参考了以下链接:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
相关文章:
循环神经网络的变体模型-LSTM、GRU
一.LSTM(长短时记忆网络) 1.1基本介绍 长短时记忆网络(Long Short-Term Memory,LSTM)是一种深度学习模型,属于循环神经网络(Recurrent Neural Network,RNN)的一种变体。…...

视频图像的color range简介
介绍 研究FFmpeg发现,在avcodec.h中有关于color的解释,主要有四个属性,primaries、transfer、space和range。 color primaries: 基于RGB空间对应的绝对颜色XYZ的变换,决定了最终三原色RGB分别是什么颜色;…...

tcp的三次握手
http 和 https 都是是基于 TCP 的请求,https 是 http 加上 tls 连接。TCP 是面向连接的协议。 对于 http1.1 协议chrome 限制在同一个域名下最多可以建立 6 个 tcp 连接,所以如果在同一个域名下,同时有超过 6 个请求发生,那么多余…...

unity 矩阵探究
public void MatrixTest1(){ ///Matrix4x4 是列矩阵,就是一个vector4表示一列,所以在c#中矩阵和Vector4只能矩阵右乘坐标。但是在shader中是矩阵左乘坐标,所以在shader中是行矩阵 Matrix4x4 moveMatrix1 new Matrix4x4(new Vector4(1,0,0,0)…...
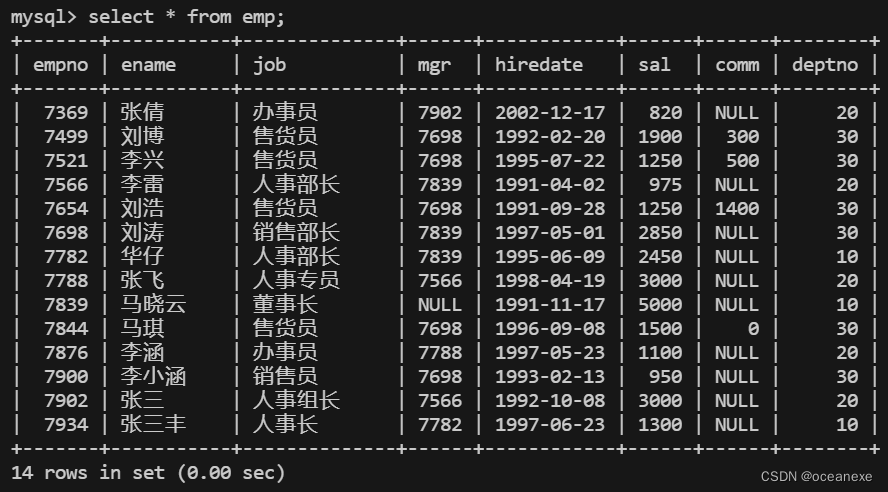
MySQL---单表查询综合练习
创建emp表 CREATE TABLE emp( empno INT(4) NOT NULL COMMENT 员工编号, ename VARCHAR(10) COMMENT 员工名字, job VARCHAR(10) COMMENT 职位, mgr INT(4) COMMENT 上司, hiredate DATE COMMENT 入职时间, sal INT(7) COMMENT 基本工资, comm INT(7) COMMENT 补贴, deptno INT…...

Python项目——搞怪小程序(PySide6+Pyinstaller)
1、介绍 使用python编写一个小程序,回答你是猪吗。 点击“是”提交,弹窗并退出。 点击“不是”提交,等待5秒,重新选择。 并且隐藏了关闭按钮。 2、实现 新建一个项目。 2.1、设计UI 使用Qt designer设计一个UI界面,…...

MySQL练习题
参考:https://blog.csdn.net/paul0127/article/details/82529216 数据表介绍 --1.学生表 Student(SId,Sname,Sage,Ssex) --SId 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别 --2.课程表 Course(CId,Cname,TId) --CId 课程编号,Cname 课程名称,TId 教师编号…...

vue-项目打包、配置路由懒加载
1. 简介 在现代前端开发中,Vue.js因其简洁、灵活和高效的特点,已经成为许多开发者的首选框架。 在Vue项目中,打包部署和路由懒加载是两个非常重要的环节。 打包Vue项目是为了将源代码转换为浏览器可以解析的JavaScript文件,以便…...

词语的魔力:语言在我们生活中的艺术与影响
Words That Move Mountains: The Art and Impact of Language in Our Lives 词语的魔力:语言在我们生活中的艺术与影响 Hello there, wonderful people! Today, I’d like to gab about the magical essence of language that’s more than just a chatty tool in o…...

android List,Set,Map区别和介绍
List 元素存放有序,元素可重复 1.LinkedList 链表,插入删除,非线性安全,插入和删除操作是双向链表操作,增加删除快,查找慢 add(E e)//添加元素 addFirst(E e)//向集合头部添加元素 addList(E e)//向集合…...
Mysql 编译安装部署
Mysql 编译安装部署 环境: 172.20.26.198(Centos7.6) 源码安装Mysql-5.7 大概步骤如下: 1、上传mysql-5.7.28.tar.gz 、boost_1_59_0.tar 到/usr/src 目录下 2、安装依赖 3、cmake 4、make && make install 5、…...

【目标检测】YOLOv5算法实现(九):模型预测
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。 本系列文章主要以YOLOv5为例完成算法的实现,后续修改、增加相关模…...

centos宝塔远程服务器怎么链接?
要远程连接CentOS宝塔服务器,可以按照以下步骤操作: 打开终端或远程连接工具,比如PuTTY。输入服务器的IP地址和SSH端口号(默认为22),点击连接。输入用户名和密码进行登录。 如果你已经安装了宝塔面板&…...
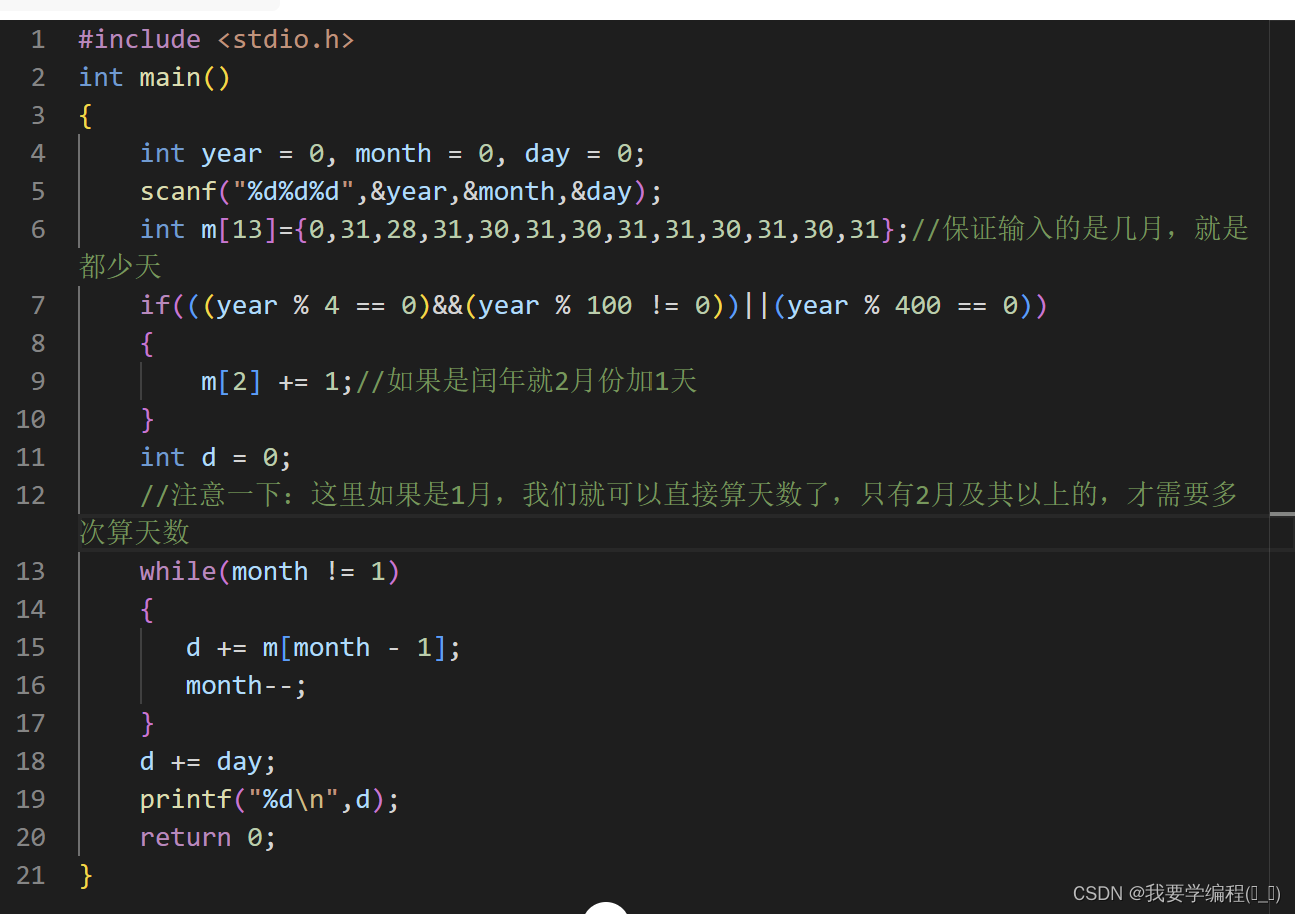
C语言练习day8
变种水仙花 变种水仙花_牛客题霸_牛客网 题目: 思路:我们拿到题目的第一步可以先看一看题目给的例子,1461这个数被从中间拆成了两部分:1和461,14和61,146和1,不知道看到这大家有没有觉得很熟…...

蓝凌OA-sysuicomponent-任意文件上传_exp-漏洞复现
0x01阅读须知 技术文章仅供参考,此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的…...

C#,入门教程(38)——大型工程软件中类(class)修饰词partial的使用方法
上一篇: C#,入门教程(37)——优秀程序员的修炼之道https://blog.csdn.net/beijinghorn/article/details/125011644 一、大型(工程应用)软件倚重 partial 先说说大型(工程应用)软件对源代码的文件及函数“…...

C++播放音乐:使用EGE图形库
——开胃菜,闲话篓子一大片 最近,我发现ege图形库不是个正经的图形库—— 那天,我又在打趣儿地翻代码时,无意间看到了这个: 图形库?!你哪来的音乐(Music)呢?…...

C++中const和constexpr的区别:了解常量的不同用法
C中const和constexpr的区别 一、C中的常量概念二、const关键字的用法和特点三、constexpr关键字的用法和特点四、const和constexpr的区别对比4.1、编译时计算能力4.2、可以赋值的范围4.3、对类和对象的适用性4.4、对函数的适用性4.5、性能和效率的差异 五、使用示例六、总结 一…...
高级架构师是如何设计一个系统的?
架构师如何设计系统? 系统拆分 通过DDD领域模型,对服务进行拆分,将一个系统拆分为多个子系统,做成SpringCloud的微服务。微服务设计时要尽可能做到少扇出,多扇入,根据服务器的承载,进行客户端负…...
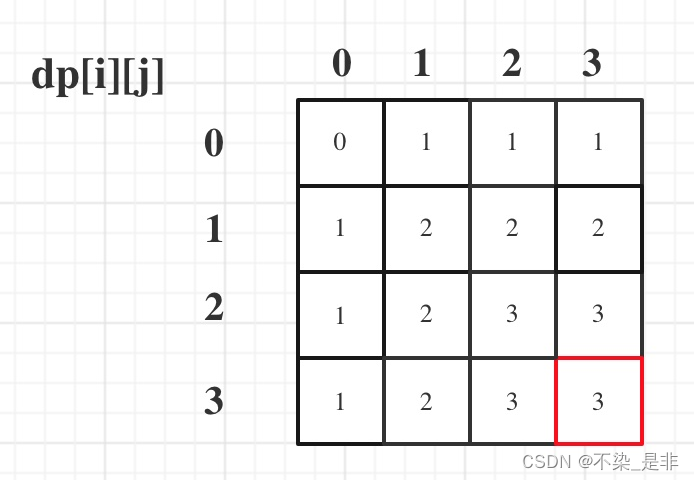
力扣:474. 一和零(动态规划)(01背包)
题目: 给你一个二进制字符串数组 strs 和两个整数 m 和 n 。 请你找出并返回 strs 的最大子集的长度,该子集中 最多 有 m 个 0 和 n 个 1 。 如果 x 的所有元素也是 y 的元素,集合 x 是集合 y 的 子集 。 示例 1: 输入&#…...

3分钟掌握:Windows电脑上安装安卓应用的终极解决方案
3分钟掌握:Windows电脑上安装安卓应用的终极解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接安装和运行安卓应用吗ÿ…...

终极指南:如何免费搭建专业的电子实验室笔记本系统
终极指南:如何免费搭建专业的电子实验室笔记本系统 【免费下载链接】elabftw :notebook: eLabFTW is the most popular open source electronic lab notebook for research labs. 项目地址: https://gitcode.com/gh_mirrors/el/elabftw eLabFTW是一款功能强大…...

ABAP 7.40+新语法实战:5个内表处理技巧让你告别LOOP和IF
ABAP 7.40新语法实战:5个内表处理技巧让你告别LOOP和IF 在SAP开发领域,ABAP语言随着7.40版本的发布迎来了一次重大革新。对于每天需要处理大量内表操作的中级开发者来说,这些新特性不仅能显著减少代码量,更能提升程序的可读性和执…...

云原生安全扫描:保护容器化应用的安全
云原生安全扫描:保护容器化应用的安全 引言 在云原生环境中,安全扫描是保障应用安全的重要手段。通过安全扫描,我们可以发现容器镜像和代码中的安全漏洞。 今天就来分享一下云原生安全扫描的最佳实践。 安全扫描类型 镜像扫描 扫描容器镜像中…...

Zynq-7000 Linux系统构建全流程:从Vivado硬件配置到内核启动调试
1. 项目概述:为什么要在Zynq上折腾Linux?如果你手头有一块Xilinx Zynq-7000系列(比如我用的黑金Zynq7020)开发板,并且想把它从一个单纯的FPGA逻辑验证平台,变成一个能跑完整操作系统、可以灵活编程、还能用…...

告别虚拟机卡顿:在Ubuntu 18.04上为ARM板交叉编译Qt5.12.9的完整配置流程
突破虚拟机性能瓶颈:Ubuntu 18.04下高效交叉编译Qt5.12.9的工程实践 当你在40GB磁盘空间的Ubuntu虚拟机上尝试编译Qt5.12.9时,解压后的2.8GB源码目录和漫长的编译等待时间可能已经让你抓狂。这不是个例——嵌入式开发工程师经常面临这样的困境࿱…...

MIT Cheetah-Software编译手记:搞定Qt5.10.0路径、LCM依赖与那些诡异的C++报错
MIT Cheetah-Software编译实战:Qt路径配置、LCM依赖与C报错深度解析 1. 环境准备与依赖管理 在Ubuntu 20.04环境下编译MIT Cheetah-Software,首先需要确保系统基础环境配置正确。不同于普通开源项目,这个四足机器狗的控制系统对Qt版本、LCM消…...

大麦网Python抢票脚本终极指南:告别手速焦虑,轻松获取心仪门票
大麦网Python抢票脚本终极指南:告别手速焦虑,轻松获取心仪门票 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为心仪演唱会门票秒光而烦恼吗?还在为黄牛高…...
图书管理系统)
基于C++实现(控制台)图书管理系统
♻️ 资源 大小: 1.70MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430290 图书管理系统 题目概述 首先认为大多数同学好像都计划设计游戏,我们想设计不一样的,再因为以前大家都做过一次手机的通讯录&#x…...

显卡驱动彻底清理指南:DDU工具拯救你的显示问题![特殊字符]
显卡驱动彻底清理指南:DDU工具拯救你的显示问题!🚀 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-d…...