第13章 1 进程和线程
文章目录
- 程序和进程的概念 p173
- 函数式创建子进程
- Process类常用的属性和方法1 p175
- Process类中常用的属性和方法2 p176
- 继承式创建子进程 p177
- 进程池的使用 p178
- 并发和并行 p179
- 进程之间数据是否共享 p180
- 队列的基本使用 p180
- 使用队列实现进程之间的通信 p182
- 函数式创建线程 p183
- 继承式创建线程 p184
- 线程之间数据共享 p185
程序和进程的概念 p173
进程是运行态的程序
函数式创建子进程
fork可以用于unix类的操作系统:linux,macos
但是在windows系统中,只能使用Process,详见下
第一种创建进程的语法结构:
Process(group=None,target,name,args,kwargs)
参数说明:
1、group:表示分组,实际上不使用,值默认为None即可;可不写
2、target:表示子进程要执行的任务,支持函数名
3、name:表示子进程的名称;可不写
4、args:表示调用函数的位置参数,以元组的形式进行传递;有就写
5、kwargs:表示调用函数的关键字参数,以字典的形式进行传递;有就写
代码实例1:
import multiprocessing
import os
import timedef test():print(f'我是子进程,我的PID是:{os.getpid()},我的父进程是{os.getppid()}')time.sleep(1)if __name__=='__main__':print('主进程开始执行')lst=[]# 创建五个子进程for i in range(5):# 创建单个子进程p=multiprocessing.Process(target=test) # 返回值类型为:<class 'multiprocessing.context.Process'>print(type(p))# 启动子进程p.start()# 启动中的进程加到列表中lst.append(p)print('主进程执行结束')
上面的运行结果是主进程先结束,子进程在逐个结束
若要求所有子进程中的代码执行结束,主进程在结束,可以使用join()方法,阻塞,见下面:
import multiprocessing
import os
import timedef test():print(f'我是子进程,我的PID是:{os.getpid()},我的父进程是{os.getppid()}')time.sleep(1)if __name__=='__main__':print('主进程开始执行')lst=[]# 创建五个子进程for i in range(5):# 创建单个子进程p=multiprocessing.Process(target=test) # 返回值类型为:<class 'multiprocessing.context.Process'># 启动子进程p.start()# 启动中的进程加到列表中lst.append(p)for item in lst:item.join() # 阻塞主进程print('主进程执行结束')
Process类常用的属性和方法1 p175
| 方法/属性名称 | 功能描述 |
|---|---|
name | 当前进程实例别名,默认为Process-N |
pid | 当前进程对象的PID值 |
is_alive() | 进程是否执行完,没执行完结果为True,否则为False |
join(timeout) | 等待结束或传入了参数就是等待timeout秒 |
start() | 启动进程 |
run() | 若没有指定target参数,则启动进程后,会调用父类中的run方法 |
terminate() | 强制终止进程 |
代码实例:
import os,multiprocessing,timedef sub_process(name):print(f'子进程pid:{os.getpid()},父进程的pid:{os.getppid()},入参name={name}')time.sleep(1)def sub_process2(name):print(f'子进程pid:{os.getpid()},父进程的pid:{os.getppid()},入参name={name}')time.sleep(1)if __name__ == '__main__': # 直接写main# 主进程print('父进程开始执行')for i in range(5):# 创建第一个子进程p1=multiprocessing.Process(target=sub_process,args=('ysj',))# 创建第二个子进程p2=multiprocessing.Process(target=sub_process2,args=(18,))# 调用Process类的start方法启动子进程p1.start()p2.start()# 调用进程对象的类属性print(p1.name,'是否执行完毕:',not p1.is_alive())print(p2.name, '是否执行完毕:', not p2.is_alive())p1.join() # 主程序阻塞等待p1结束p2.join() # 主程序阻塞等待p2结束print('父进程执行结束')
Process类中常用的属性和方法2 p176
代码实例1:
import os,multiprocessing,timeif __name__ == '__main__': # 直接写main# 主进程print('父进程开始执行')for i in range(5):# 创建第一个子进程p1=multiprocessing.Process() # 没有给定taget参数,会调用执行Process类中的run方法# 创建第二个子进程p2=multiprocessing.Process()p1.start() # 调用Process类中的run方法去执行p2.start()print('父进程执行结束')
代码实例2:
import os,multiprocessing,timedef sub_process(name):print(f'子进程pid:{os.getpid()},父进程的pid:{os.getppid()},入参name={name}')time.sleep(1)def sub_process2(name):print(f'子进程pid:{os.getpid()},父进程的pid:{os.getppid()},入参name={name}')time.sleep(1)if __name__ == '__main__': # 直接写main# 主进程print('父进程开始执行')for i in range(5):# 创建第一个子进程p1=multiprocessing.Process(target=sub_process,args=('ysj',)) # 没有给定taget参数,会调用执行Process类中的run方法# 创建第二个子进程p2=multiprocessing.Process(target=sub_process2,args=(18,))p1.start()p2.start()# 强制终止进程p1.terminate()p2.terminate()print('父进程执行结束')
继承式创建子进程 p177
第二种创建进程的语法结构:
class 子进程(Process): # 继承Process类,然后去重写run方法pass
代码实例:
import multiprocessing,time,os# 自定义一个类
class SubProcess(multiprocessing.Process): # 继承Process类# 编写一个初始化方法def __init__(self,name):# 调用父类的初始化方法super().__init__()self.name=name# 重写父类的run方法def run(self):print(f'子进程的名称:{self.name},PID是:{os.getpid()},父进程的PID是:{os.getppid()}')if __name__ == '__main__':print('父进程开始执行')lst=[]for i in range(1,6):p1=SubProcess(f'进程:{i}')# 启动进程p1.start() # 没有参数会调用run方法lst.append(p1)# 阻塞主进程,等待子进程执行完毕for item in lst:item.join()print('父进程执行结束')
进程池的使用 p178
若要创建、管理的进程有上百个,创建、销毁线程要消耗大量的时间。进程池可以解决这个问题
进程池的原理:
创建一个进程池,并设置进程池中最大的进程数量。假设进程池中最大的进程数为3,现在有10个任务需要执行,name进程池一次可以执行3个任务,4次即可完成全部任务的执行。
创建进程池的语法结构:
进程池对象=Pool(N)
| 方法名 | 功能描述 |
|---|---|
apply_async(func,args,kwargs) | 使用非阻塞方式调用函数func |
apply(func,args,kwargs) | 使用阻塞方式调用函数func |
close() | 关闭进程池,不再接受新任务 |
terminate() | 不管任务是否完成,立即终止 |
join() | 阻塞主进程,必须在terminate()或close()之后使用 |
代码实例:非阻塞运行进程池
import multiprocessing,os,time# 编写任务
def task(name):print(f'子进程的PID:{os.getpid()},父进程的PID:{os.getppid()},执行的任务:{name}')time.sleep(1)if __name__ == '__main__':# 主进程start=time.time() # 返回时间戳,单位是秒print(start,':父进程开始执行')# 创建进程池p=multiprocessing.Pool(3)# 创建任务for i in range(10):# 以非阻塞方式p.apply_async(func=task,args=(i,))# 关闭进程池不再接收新任务p.close()# 阻塞主进程等待子进程执行完毕p.join()print(time.time()-start)print('父进程执行结束')
代码实例:阻塞运行进程池
import multiprocessing,os,time# 编写任务
def task(name):print(f'子进程的PID:{os.getpid()},父进程的PID:{os.getppid()},执行的任务:{name}')time.sleep(1)if __name__ == '__main__':# 主进程start=time.time() # 返回时间戳,单位是秒print(start,':父进程开始执行')# 创建进程池p=multiprocessing.Pool(3)# 创建任务for i in range(10):# 非阻塞方式p.apply(func=task,args=(i,))# 关闭进程池不再接收新任务p.close()# 阻塞主进程等待子进程执行完毕p.join()print(time.time()-start) # 非阻塞用了4秒多,阻塞方式用了10秒多print('父进程执行结束')
并发和并行 p179
并发:
是指两个或多个事件在 同一时间间隔 发生,多个任务被交替轮换着执行,比如A事件在吃苹果,在吃苹果的过程中有快递员敲门让你收下快递,收快递就是B事件,name收完快递继续吃没吃完的苹果。就是并发。
并行:
指两个或多个事件在同一时刻发生,多个任务在同一时刻在多个处理器上同时执行。比如A事件是泡脚,B事件是打电话,C事件是记录电话内容,这三件事则可以在同一时刻发生,这就是并行。
进程之间数据是否共享 p180
Python当中的并行对应多进程
代码实例:
import multiprocessing,osa=100def add():print('子进程1开始执行')global aa+=30print('a=',a)print('子进程1执行完毕')def sub():print('子进程2开始执行')global aa-=50print('a=',a)print('子进程2执行完毕')if __name__ == '__main__':# 父进程print('父进程开始执行')# 创建加的子进程p1=multiprocessing.Process(target=add)# 创建减的子进程p2=multiprocessing.Process(target=sub())# 启动子进程p1.start()p2.start()# 主进程阻塞,等待子进程执行完成p1.join()p2.join()print('父进程结束执行')
发现结果分别为 130和50,由此发现多进程之间的数据不是共享的,子进程1中有一份a,子进程2中还有另一份a
如何解决进程之间的数据共享,见下一节
队列的基本使用 p180
进程之间可以通过队列(queue)进行通信
队列是一种先进先出的数据结构
创建队列的语法结构:
队列对象=Queue(N)
| 方法名称 | 功能描述 |
|---|---|
qsize() | 获取当前队列包含的消息数量 |
empty() | 判断队列是否有空,为空结果为True,否则为False |
full() | 判断队列是否满了,满结果为True,否则为False |
get(block=True) | 获取队列中的一条消息,然后从队列中移除,block默认值为True(队列为空时会阻塞等待消息) |
get_nowait() | 相当于 get(block=False) ,消息队列为空时,抛出异常 |
put(item,block=True) | 将item消息放入队列,block默认为True(队列满时会阻塞等待队列有空间) |
put_nowait(item) | 相当于 put(item,block=False) |
代码实例:
import multiprocessingif __name__ == '__main__':# 创建一个队列q=multiprocessing.Queue(3) # 这个队列最多可以接收3条信息print('队列是否有空?',q.empty())print('队列是否为满?',q.full())print('队列中的消息数?',q.qsize())print('-'*88)# 向队列中添加信息q.put('hello')q.put('world')print('队列是否有空?', q.empty())print('队列是否为满?', q.full())print('队列中的消息数?', q.qsize())print('-'*88)q.put('11111111')print('队列是否有空?', q.empty())print('队列是否为满?', q.full())print('队列中的消息数?', q.qsize())print('-' * 88)print(q.get())print('队列中的消息数?', q.qsize())print(q.get())print(q.get())print('队列中的消息数?', q.qsize())'''
队列的遍历:
for i in range(q.qsize()):q.get_nowait()
'''
使用队列实现进程之间的通信 p182
代码实例1:
import multiprocessingif __name__ == '__main__':q=multiprocessing.Queue(3)# 向队列中添加元素q.put('hello')q.put('world')q.put('python')q.put('html',block=True,timeout=2) # 阻塞等待,最多两秒,若到了两秒会报错返回
代码实例2:
import multiprocessing,timea=100# 入队
def write_msg(q):global a # 要在函数内使用全局变量,一定要先用此方法声明if not q.full():for i in range(6):a-=10q.put(a)print(f'a入队时的值:{a}')# 出队
def read_msg(q):time.sleep(1)while q.qsize()>0:print(f'出队时a的值:{q.get()}')if __name__ == '__main__':print('父进程开始执行')q=multiprocessing.Queue() # 不写参数表示队列接收的消息个数是没有上限的# 创建两个子进程p1=multiprocessing.Process(target=write_msg,args=(q,))p2=multiprocessing.Process(target=read_msg, args=(q,))# 启动两个子进程p1.start()p2.start()# 等待写的进程结束,再去执行主进程p1.join()p2.join()print('父进程执行完毕')
函数式创建线程 p183
线程是cpu可调度的最小单位,被包含在进程中,是进程中实际的运作单位。
一个进程可以拥有N多个线程并发执行,而每个线程并行执行不同的任务。
创建线程的方法有两种:函数式创建线程和继承式创建线程
函数式创建线程的语法结构:
t=Thread(group,target,name,args,kwargs)
参数说明:
1、group:创建线程对象的进程组
2、target:创建线程对象所要执行的目标函数
3、name:创建线程对象的名称,默认为 Thread-n
4、args:用元组以位置参数的形式传入target对应函数的参数
5、kwargs:用字典以关键字参数的形式传入target对应函数的参数
代码实例:
import threading,time# 编写线程执行函数
def test():for i in range(3):time.sleep(1)print(f'线程名:{threading.current_thread().name},正在执行{i}') # 获取当前的线程对象threading.current_thread()if __name__ == '__main__':start=time.time()print('主线程开始执行')# 线程lst=[threading.Thread(target=test) for i in range(2)]for item in lst: # item的数据类型就是Thread类型# 启动线程item.start()for item in lst:item.join()print('主线程执行完毕')print(f'一共耗时{time.time()-start}秒')# 一共有一个进程,三个线程(一个主线程,两个子线程)
继承式创建线程 p184
使用Thread子类创建线程的操作步骤:
1、自定义类继承threading模块下的Thread类
2、实现run方法
代码实例:
import threading,timeclass SubThread(threading.Thread):def run(self):for i in range(3):time.sleep(1)print(f'线程:{threading.current_thread().name}正在执行{i}')if __name__ == '__main__':print('主线程开始执行')# 使用列表生成式去创建线程对象lst=[SubThread() for i in range(2)]for item in lst:item.start()for item in lst:item.join()print('主线程执行完毕')
线程之间数据共享 p185
线程之间的数据可以共享吗?
import threadinga=100def add():print('加线程开始执行')global aa+=30print(f'a的值为{a}')print('加线程执行完成')def sub():print('减线程开始执行')global aa-=50print(f'a的值为{a}')print('减线程执行完成')if __name__ == '__main__':print('主线程开始执行')print(f'全局变量a的值为{a}')add=threading.Thread(target=add)sub=threading.Thread(target=sub)add.start() # a=130sub.start() # a=80add.join()sub.join()print('主线程执行完成')
由此可以得到结论:线程之间是可以共享数据的,进程之间不可以共享数据
相关文章:

第13章 1 进程和线程
文章目录 程序和进程的概念 p173函数式创建子进程Process类常用的属性和方法1 p175Process类中常用的属性和方法2 p176继承式创建子进程 p177进程池的使用 p178并发和并行 p179进程之间数据是否共享 p180队列的基本使用 p180使用队列实现进程之间的通信 p182函数式创建线程 p18…...
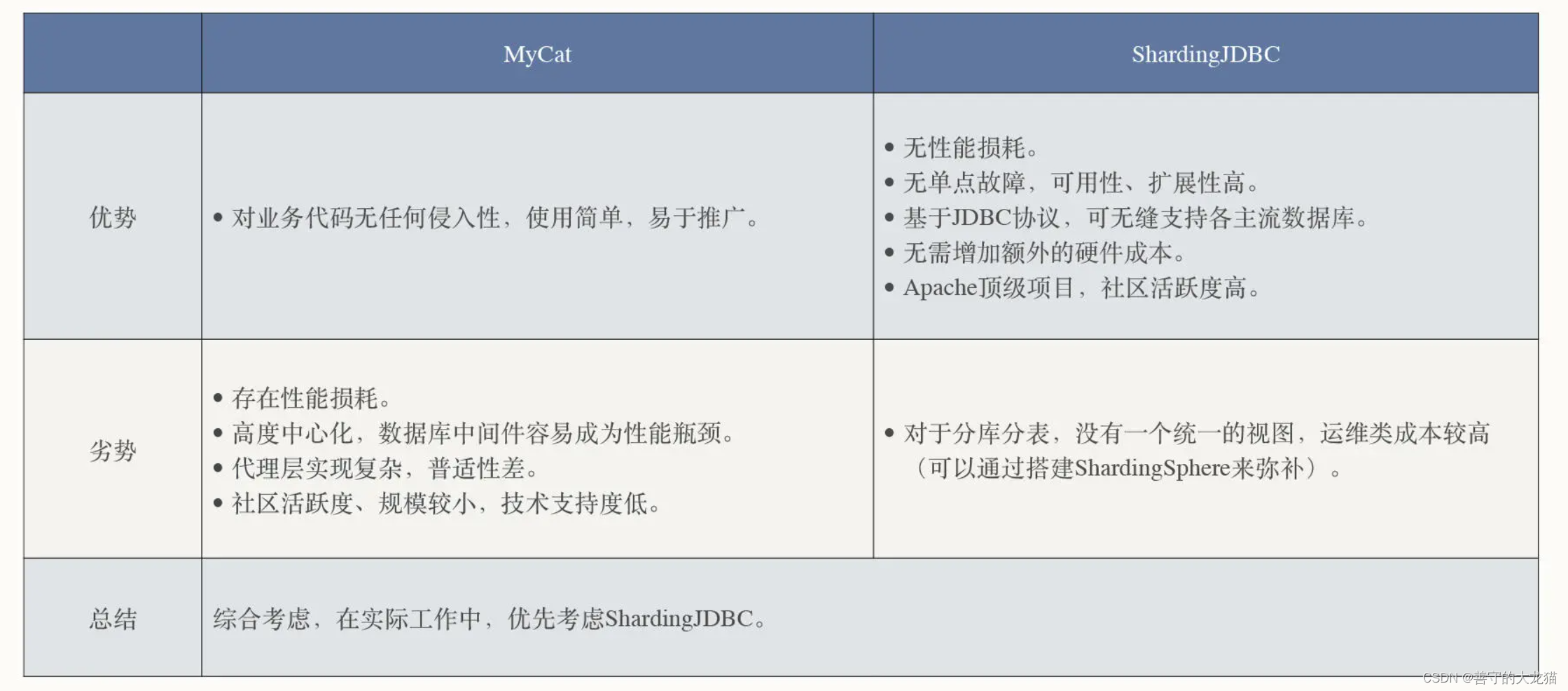
什么是中间件?
文章目录 为什么需要中间件?中间件生态漫谈数据库中间件读写分离分库分表引进数据库中间件MyCat 服务端代理模式ShardingJDBC 客户端代理模式 总结 IT 系统从单体应用逐渐向分布式架构演变,高并发、高可用、高性能、分布式等话题变得异常火热,…...

汽车售后服务客户满意度调查报告
本文由群狼调研(长沙旅行社满意度调查)出品,欢迎转载,请注明出处。汽车售后服务客户满意度调查报告通常包括以下内容: 1.调研概况:介绍调研的目的、背景和范围,包括调研的时间、地点和样本规模等…...

初始RabbitMQ(入门篇)
消息队列(MQ) 本质上就是一个队列,一个先进先出的队列,队列中存放的内容是message(消息),是一种跨进程的通信机制,用于上下游传递消息, 为什么使用MQ: 削峰填谷: MQ可以很好的做一个缓冲机制,例如在一个系统中有A和B两个应用,A是接收用户的请求的,然后A调用B进行处理. 这时…...
JVM:Java类加载机制
Java类加载机制的全过程: 加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,类型的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始, 这是为了支持Java…...

要经历痛苦,才能在赚钱路上觉醒!
新手赚钱,一个秘诀就够了! 黎明前的黑暗实际是最漫长的,就如同开发进度99%到100%这个过程尤其漫长。赚钱的路上起初就是黑暗,不断地摸索最终才能走出迷雾,真正的迎接朝阳。如果有一段路程,十来公里的路线&a…...

LeetCode 第381场周赛个人题解
目录 100191. 输入单词需要的最少按键次数 I 原题链接 题目描述 思路分析 AC代码 100188. 按距离统计房屋对数目 I 原题链接 题目描述 思路分析 AC代码 100192. 输入单词需要的最少按键次数 II 原题链接 题目描述 思路分析 AC代码 100213. 按距离统计房屋对数目…...

数据结构之二叉树的性质与存储结构
数据结构之二叉树的性质与存储结构 1、二叉树的性质2、二叉树的存储结构 数据结构是程序设计的重要基础,它所讨论的内容和技术对从事软件项目的开发有重要作用。学习数据结构要达到的目标是学会从问题出发,分析和研究计算机加工的数据的特性,…...

机器视觉检测设备在连接器外观缺陷检测中的应用
作为传输电流或信号连接两个有源器件的器件,连接器被广泛应用于各个行业,从手机、平板、电脑,到冰箱、空调、洗衣机,再到汽车、国防、航空,处处是它的所在。每个电子产品少了连接器将无法运作,因此…...
)
ChatGPT vs 文心一言(AI助手全面比较)
随着人工智能的不断发展,ChatGPT(OpenAI)和文心一言都代表了当前先进的自然语言处理技术。它们在智能回复、语言准确性和知识库丰富度等方面都有各自的优势。在下面的比较中,我们将从多个角度探讨这两个AI助手,帮助你更…...
MSPM0L1306例程学习-UART部分(2)
MSPM0L1306例程学习系列 1.背景介绍 写在前边的话: 这个系列比较简单,主要是围绕TI官网给出的SDK例程进行讲解和注释。并没有针对模块的具体使用方法进行描述。所有的例程均来自MSPM0 SDK的安装包,具体可到官网下载并安装: https://www.ti…...
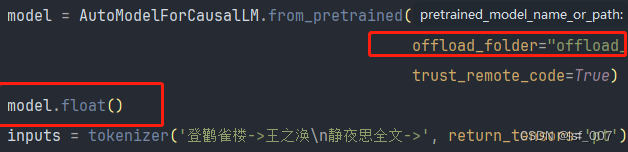
Baichuan2百川模型部署的bug汇总
1.4bit的量化版本最好不要在Windows系统中运行,大概原因报错原因是bitsandbytes不支持window,bitsandbytes-windows目前仅支持8bit量化。 2. 报错原因是机器没有足够的内存和显存,offload_folder设置一个文件夹来保存那些离线加载到硬盘的权…...
ChatGPT 如何解决 “Something went wrong. lf this issue persists ….” 错误
Something went wrong. If this issue persists please contact us through our help center at help.openai.com. ChatGPT经常用着用着就出现 “Something went wrong” 错误,不管是普通账号还是Plus账号,不管是切换到哪个节点,没聊两次就报…...
怎么移除WordPress后台工具栏的查看站点子菜单?如何改为一级菜单?
默认情况下,我们在WordPress后台想要访问前端网站,需要将鼠标移动到左上角的站点名称,然后点击下拉菜单中的“查看站点”才行,而且还不是新窗口打开。那么有没有办法将这个“查看站点”子菜单变成一级菜单并显示在顶部管理工具栏中…...
WEB-前端 表格标签-合并单元格
目录 合并单元方式 : 跨行合并 : 跨列合并 : 目标单元格 : 跨行的话 跨列的话 合并的步骤 : 跨行合并 : 跨列合并 : 特殊情况下,可以把多个单元格合并为一个单元格,我们呢先…...
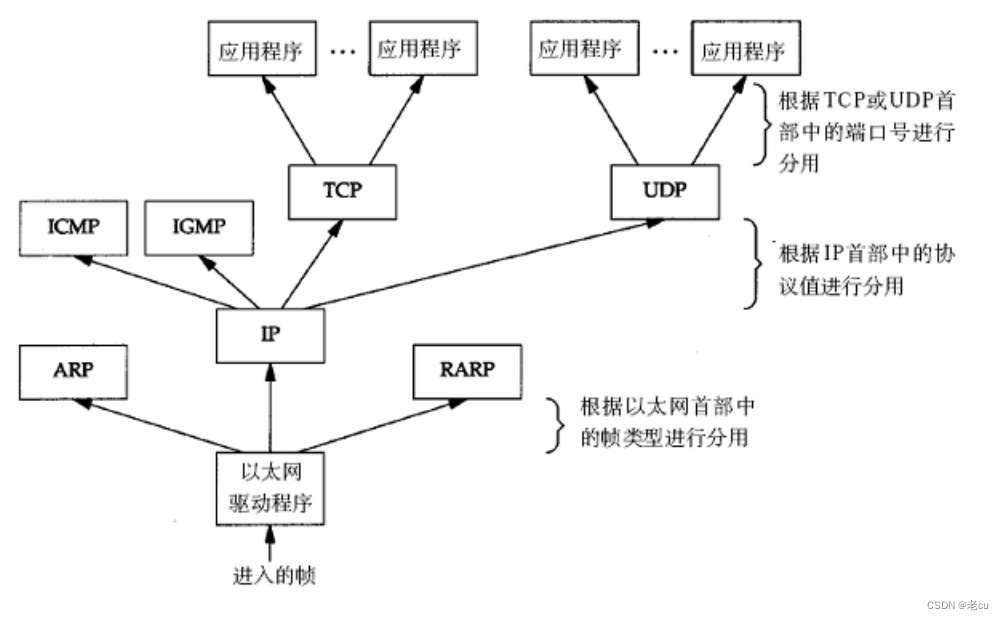
[计算机网络]基本概念
目录 1.ip地址和端口号 1.1IP地址 1.2端口号 2.认识协议 2.1概念: 2.2知名协议的默认端口 3.五元组 4.协议分层 4.1分层的作用 4.2OSI七层模型 4.3TCP/IP五层(四层)模型 编辑4.4网络设备对应的分层: 编辑以下为跨…...
Flutter 综述
Flutter 综述 1 介绍1.1 概述1.2 重要节点1.3 移动开发中三种跨平台框架技术对比1.4 flutter 技术栈1.5 IDE1.6 Dart 语言1.7 应用1.8 框架 2 Flutter的主要组成部分3 资料书籍 《Flutter实战第二版》Dart 语言官网Flutter中文开发者社区flutter 官网 4 搭建Flutter开发环境参考…...
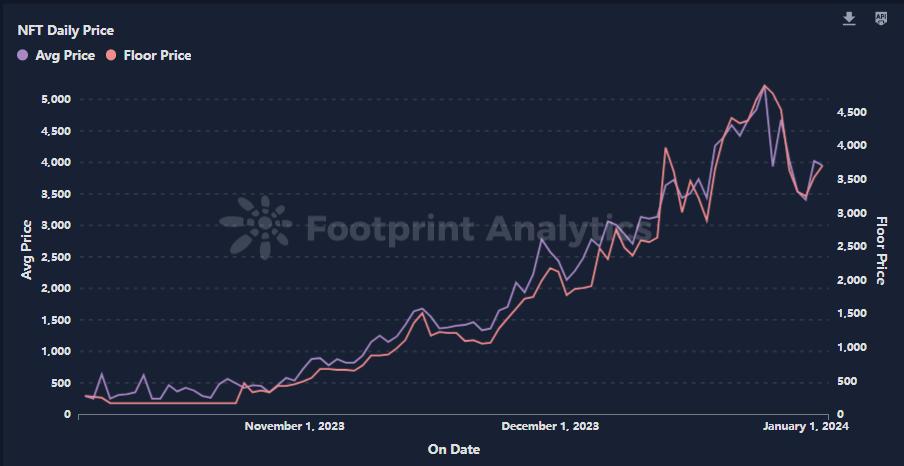
Pixels:重新定义游戏体验的区块链农场游戏
数据源:Pixels Dashboard 作者:lesleyfootprint.network 最近,Pixels 通过从 Polygon 转移到 Sky Mavis 旗下的 Ronin 网络,完成了一次战略性的转变。 Pixels 每日交易量 Pixels 在 Ronin 网络上的受欢迎程度急剧上升…...

【JavaEE】文件操作 —— IO
文件操作 —— IO 1. 文件的属性 文件内容文件大小文件路径文件名称 2. 文件的管理 采用树形结构进行管理。 3. 文件路径 分为两种:相对、绝对路径。 相对路径:相对于当前位置的路径,以“./xxx.xxx”为标志绝对路径:以从盘符…...
推荐新版AI智能聊天系统网站源码ChatGPT NineAi
Nine AI.ChatGPT是基于ChatGPT开发的一个人工智能技术驱动的自然语言处理工具,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代…...

iPhone 14上跑出0.8ms延迟!SwiftFormer加性注意力实战:从论文到移动端部署避坑指南
iPhone 14上实现0.8ms延迟:SwiftFormer移动端部署全流程实战 当我在iPhone 14 Pro上首次看到SwiftFormer-L1模型以0.8毫秒完成图像分类时,手中的咖啡杯差点滑落——这个速度已经快于人眼单次眨动的1/10时长。作为长期奋战在移动端AI部署一线的工程师&am…...

彻底告别iPhone过热降频!thermalmonitordDisabler让你的设备性能满血释放
彻底告别iPhone过热降频!thermalmonitordDisabler让你的设备性能满血释放 【免费下载链接】thermalmonitordDisabler A tool used to disable iOS daemons. 项目地址: https://gitcode.com/gh_mirrors/th/thermalmonitordDisabler 你是否曾经在游戏激战中突然…...

避坑指南:在CentOS 7上部署泛微Ecology9 OA,我踩过的那些“内存不足”和“防火墙”的坑
CentOS 7部署泛微Ecology9 OA系统:从内存优化到防火墙配置的深度避坑指南 在Linux环境下部署企业级OA系统从来都不是一件简单的事情,尤其是像泛微Ecology9这样功能复杂的大型系统。表面上看,官方文档和网络上的教程似乎已经提供了完整的步骤&…...

企业级应用如何利用Taotoken实现稳定高效的多模型调度
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何利用Taotoken实现稳定高效的多模型调度 在构建基于大模型的企业级应用时,开发团队常常面临几个核心挑战…...

解密网易云音乐NCM文件:3分钟掌握ncmdump核心技术与实战应用
解密网易云音乐NCM文件:3分钟掌握ncmdump核心技术与实战应用 【免费下载链接】ncmdump 转换网易云音乐 ncm 到 mp3 / flac. Convert Netease Cloud Music ncm files to mp3/flac files. 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdump ncmdump作为C实…...

边缘网络:构建边缘计算的网络基础设施
边缘网络:构建边缘计算的网络基础设施 一、边缘网络概述 1.1 边缘网络的定义 边缘网络是指部署在网络边缘的网络基础设施,它将计算、存储和网络资源扩展到离用户更近的位置。边缘网络支持低延迟数据处理、实时响应和分布式计算,是边缘计算的关…...

AMD Ryzen嵌入式COM Express模块:工业边缘计算的高性能解决方案
1. 项目概述:当工业计算遇上“锐龙”芯在工业自动化、边缘计算和高端嵌入式领域,COM Express(Computer-On-Module Express)模块一直是构建紧凑、高性能、高可靠性系统的基石。它就像一台浓缩的、标准化的“电脑主板核心”…...

麒麟KylinOS 2303系统管理员必备:用模板为新用户批量配置统一电源策略
麒麟KylinOS 2303系统管理员实战:批量配置用户电源策略的模板化方案 在企业办公环境或学校机房中,麒麟KylinOS系统管理员经常面临统一管理多台电脑电源策略的需求。传统逐台配置的方式效率低下,而通过/etc/skel/用户模板目录的机制࿰…...
实战:从配置到调试,手把手教你防止程序‘饿死’)
ESP32任务看门狗(TWDT)实战:从配置到调试,手把手教你防止程序‘饿死’
ESP32任务看门狗深度实战:构建高可靠多任务系统的关键技巧 在物联网设备开发中,系统稳定性往往决定着产品的成败。想象一下这样的场景:你的智能家居网关在凌晨3点突然停止响应,或者工业传感器节点在关键时刻丢失数据——这些问题的…...

Air001实战指南:利用Arduino生态快速构建智能硬件原型
1. Air001芯片与Arduino生态的完美结合 第一次拿到Air001开发板时,我完全被它的小巧震惊了——这个只有指甲盖大小的芯片,居然内置了ARM Cortex-M0内核,还能跑48MHz主频。更让我惊喜的是,它完美兼容Arduino生态,这意味…...