Kafka-多线程消费及分区设置
目录
- 一、Kafka是什么?
- 消息系统:Publish/subscribe(发布/订阅者)模式
- 相关术语
- 二、初步使用
- 1.yml文件配置
- 2.生产者类
- 3.消费者类
- 4.发送消息
- 三、减少分区数量
- 1.停止业务服务进程
- 2.停止kafka服务进程
- 3.重新启动kafka服务
- 4.重新启动业务服务
- 参考文章
一、Kafka是什么?
Kafka是一种高吞吐量、分布式、基于发布/订阅的消息系统。可满足每秒百万级的消息生产和消费;有一套完善的消息存储机制,确保数据高效安全且持久化;Kafka作为一个集群运行在一个或多个服务器上,可以跨多个机房,当某台故障时,生产者和消费者转而使用其他的Kafka。
消息系统:Publish/subscribe(发布/订阅者)模式
1.消息发布者发布消息到主题中,有多个订阅者消费该消息。
2.当发布者发布消息时,不管是否有订阅者都不会报错。
3.一定要先有消息发布者,后有消息订阅者。
相关术语
1.Broker:Kafka服务器,负责创建topic、消息存储和转发。
2.Topic:消息类别(主题),用于区分消息。
3.Partition:分区,真正的存储数据单元。每个Topic包含一个或多个分区,用于保存消息和维护偏移量。(一般为kafka节点数CPU的总核心数量)
4.offset:分区消息此时被消费的位置。分区中消息的唯一id。
5.Producer:消息生产者。
6.Consumer:消息消费者。
7.Consumer Group:消费者组。由消费不同的分区的多个消费者实例组成,共用同一个Group-id。
8.Message:消息,由offset(分区上的消息id)、MessageSize(消息内容data大小)、data(消息具体内容)组成。
二、初步使用
1.yml文件配置
spring:kafka:bootstrap-servers: http://127.0.0.1:9002properties:security:protocol: SASL_PLAINTEXTsasl:mechanism: PLAINjaas:config: org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="123456";producer:# 发生错误后,消息重发的次数。retries: 0#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。batch-size: 16384# 设置生产者内存缓冲区的大小。buffer-memory: 33554432# 键的序列化方式key-serializer: org.apache.kafka.common.serialization.StringSerializer# 值的序列化方式value-serializer: org.apache.kafka.common.serialization.StringSerializer# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。acks: 1consumer:# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5Dauto-commit-interval: 1S# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录auto-offset-reset: earliest# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量enable-auto-commit: false# 键的反序列化方式key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 值的反序列化方式value-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 消费者超时时间 6秒properties:max:poll:interval:ms: 6000listener:# 在侦听器容器中运行的线程数。消费者组中的实例数量。 【本次重点】concurrency: 5#listner负责ack,每调用一次,就立即commitack-mode: manual_immediatemissing-topics-fatal: false
2.生产者类
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;@Component
@Slf4j
public class KafkaProducer {// 消费者组public static final String TOPIC_GROUP2 = "topic.group2";@Autowiredprivate KafkaTemplate<String, Object> kafkaTemplate;public void send(String topic,Object obj) {String obj2String = JSONObject.toJSONString(obj);log.info("准备发送消息为:{}", obj2String);//发送消息ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, obj);future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {@Overridepublic void onFailure(Throwable throwable) {//发送失败的处理log.info(topic + " - 生产者 发送消息失败:" + throwable.getMessage());}@Overridepublic void onSuccess(SendResult<String, Object> stringObjectSendResult) {//成功的处理log.info(topic + " - 生产者 发送消息成功:" + stringObjectSendResult.toString());}});}
}3.消费者类
使用注解的方式来创建主题和分区。
package com.lezhi.szxy.oa.core.kafka;import com.alibaba.fastjson.JSON;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.protobuf.ServiceException;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.poi.ss.formula.functions.T;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.boot.autoconfigure.kafka.ConcurrentKafkaListenerContainerFactoryConfigurer;
import org.springframework.context.annotation.Bean;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.listener.ConsumerRecordRecoverer;
import org.springframework.kafka.listener.RetryingBatchErrorHandler;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Component;
import org.springframework.util.backoff.FixedBackOff;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.TimeUnit;@Component
@Slf4j
public class KafkaConsumer {@Resourceprivate addService addService;@Resourceprivate RedisLockUtil redisLockUtil;@ResourceRedissonClient redissonClient;@ResourceRedisTemplate<String,String> redisTemplate;private static final String ADD_LOCK_PREFIX = "ADD_LOCK_PREFIX";ObjectMapper objectMapper = new ObjectMapper();/*** 初始化主题分区* @return*/@Beanpublic NewTopic batchTopic() {log.info("初始化主题分区batchTopic : add_topic,分区:5,副本数:1 >>>>>>>>>>>>>>>>>>>>>>>>>>>>> ");return new NewTopic("add_topic", 5, (short) 1);}/*** 添加消息* @param ack*/@KafkaListener(topics = "add_topic"C,groupId = KafkaProducer.TOPIC_GROUP2)public void handleAddMessage(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {log.info("add_topic-队列消费端 topic:{}, 收到消息>>>>>>>>>>>>>>>>>", topic);Optional message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();try {ParamImport param = objectMapper.readValue(String.valueOf(msg) , ParamImport .class);String fullKey = redisLockUtil.getFullKey(ADD_LOCK_PREFIX , String.valueOf(msg));if(redisLockUtil.getLock(fullKey , 10000)){// 业务代码...log.info("add_topic 消费了: Topic:" + topic + ",Message:" + String.valueOf(msg));}else {log.info("add_topic 已经被消费: Topic:" + topic + ",Message:" + String.valueOf(msg));}ack.acknowledge();} catch (Exception e) {e.printStackTrace();log.error("解析 <"+OaConstant.SALARY_SEND_MESSAGE_KAFKA_TOPIC+"> 数据异常");}}}
}
配置消费端主题分区启动后,查看kafka,add_topic主题生成五个分区实例

注意:一个消费线程,可以对应若干分区。但是为了保证数据的一致性,同一个分区同时只能备一个消费者实例消费,所以超过分区数量的消费者实例个数是多余的,会被闲置。
将消费者实例(消费线程)比为一个人,分区消息相当于一个办公位。办公位数>人数时,哪个办公位有消息待消费,人就到哪一个工位处理消息。当办公位数<人数时,后面的人数需要排队等待前面的人离开,才可以进入办公位消费。
当人再多时,只有一个办公位,人也得排队办公,属于同步消费;当办公位有多个时,才能实现多人同时操作。
单机kafka分区最好不超过5。默认使用轮询策略。
4.发送消息
public void addTopicMsg(ParamImport param) throws ServiceException {String json;try {json = objectMapper.writeValueAsString(param);} catch (JsonProcessingException e) {log.error("addTopicMsg-发送消息,kafka消息转换失败:{}", e);throw new ServiceException("发送失败");}log.info("addTopicMsg-发送消息,发送kafka请求>>>>>>>>>>>>>>>>>>>>>>>");kafkaTemplate.send("add_topic", json);}
三、减少分区数量
上文中,我们使用了new NewTopic()的方式创建分区,分区数量只能动态增加不能减少。所以我们需要根据以下步骤来重新生成分区,达成减少分区的目的。
1.停止业务服务进程
停止业务服务进程,使得不会重复生成分区。修改代码内配置的new NewTopic()配置分区数。
2.停止kafka服务进程
停止kafka服务进程,清空分区、主题等数据。
3.重新启动kafka服务
4.重新启动业务服务
此时就会根据修改后的分区设置重新生成分区。
参考文章
【SpringBoot】在Springboot中怎么设置Kafka自动创建Topic
SpringBoot+Kafka之如何优雅的创建topic
想弄明白Kafka到底是什么吗?看完这篇你就知道了!(概念、数据存储、生产者、消费者)
图解Kafka,看本篇就足够啦!
相关文章:
Kafka-多线程消费及分区设置
目录 一、Kafka是什么?消息系统:Publish/subscribe(发布/订阅者)模式相关术语 二、初步使用1.yml文件配置2.生产者类3.消费者类4.发送消息 三、减少分区数量1.停止业务服务进程2.停止kafka服务进程3.重新启动kafka服务4.重新启动业…...
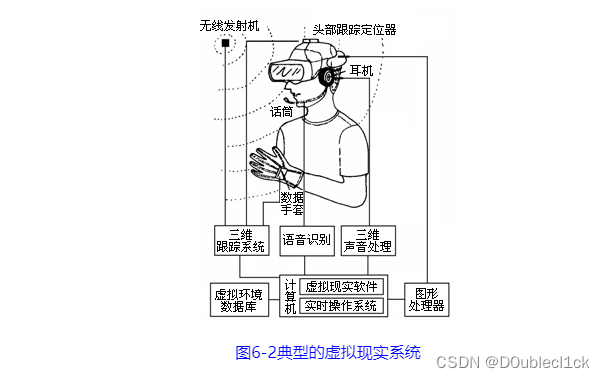
计算机导论06-人机交互
文章目录 人机交互基础人机交互概述人机交互及其发展人机交互方式人机界面 新型人机交互技术显示屏技术跟踪与识别(技术)脑-机接口 多媒体技术多媒体技术基础多媒体的概念多媒体技术及其特性多媒体技术的应用多媒体技术发展趋势 多媒体应用技术文字&…...
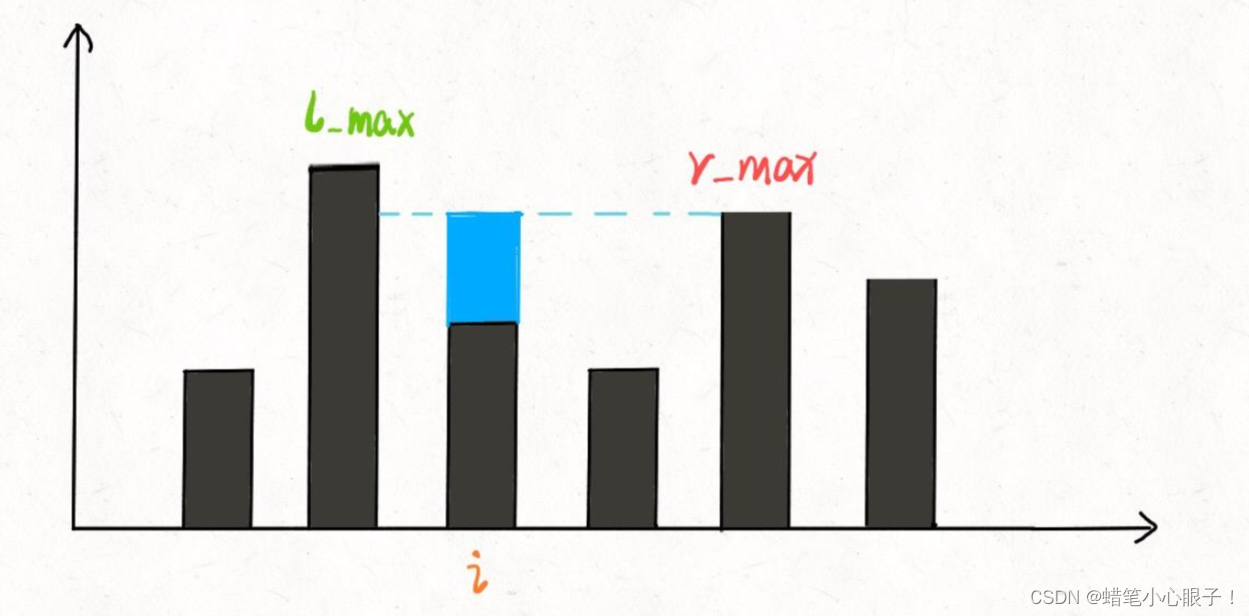
hot100:07接雨水
题目链接: 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 算法思想: 这里采取的是暴力解法和双指针的解法,但是这个题目还有其他的两种解法(单调栈和动态规划,同学可以自行了解ÿ…...
)
Docker安装MySQL教程分享(附MySQL基础入门教程)
docker安装MySQL Docker可以通过以下命令来安装MySQL容器: 首先确保已经在计算机上安装了Docker。如果没有安装,请根据操作系统的不同进行相应的安装。 打开终端或命令提示符,并运行以下命令拉取最新版本的MySQL镜像: docker pu…...
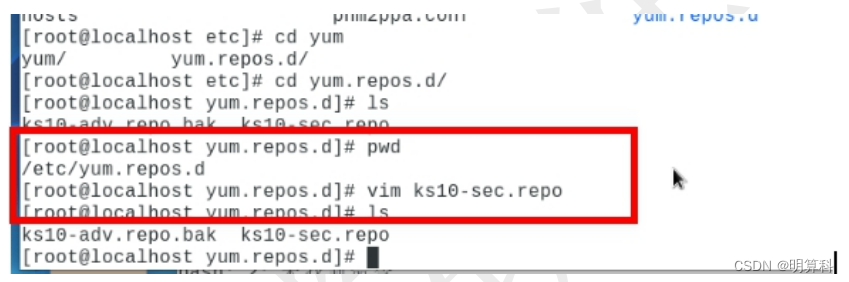
麒麟V10挂载iso,配置yum源
本文介绍yum 如何挂载本地镜像源 1) 拷贝镜像到本地 2) 执行以下命令: # mount -o loop 镜像路径及镜像名字 /mnt(或 media) 挂载前 挂载后 3) 进入/etc/yum.repos.d(yum.repos.d 是一个目录,该目录是分析 RPM 软件…...
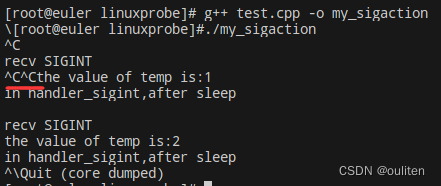
《Linux C编程实战》笔记:信号的捕捉和处理
Linux系统中对信号的处理主要由signal和sigaction函数来完成,另外还会介绍一个函数pause,它可以用来响应任何信号,不过不做任何处理 signal函数 #include <signal.h> void (*signal(int signum, void (*handler)(int)))(int);可以分解…...
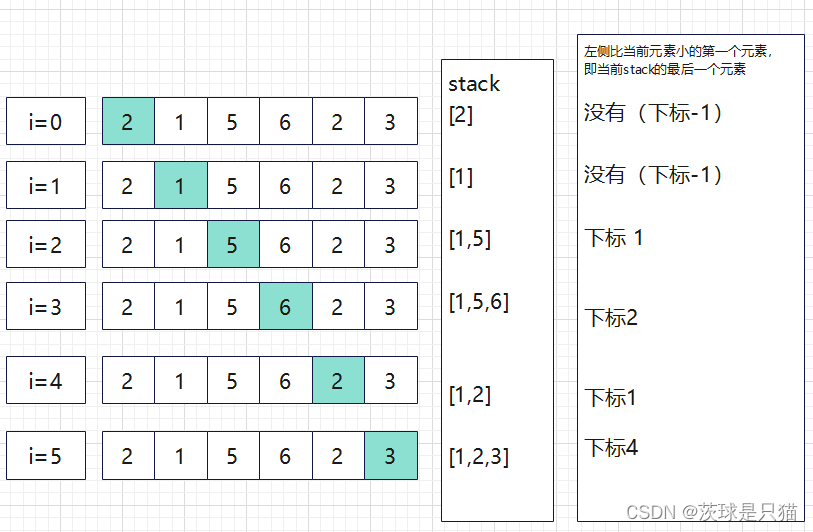
python算法与数据结构---单调栈与实践
单调栈 单调栈是一个栈,里面的元素的大小按照它们所在栈的位置,满足一定的单调性; 性质: 单调递减栈能找到左边第一个比当前元素大的元素;单调递增栈能找到左边第一个比当前元素小的元素; 应用场景 一般用…...

文心一言使用分享
ChatGPT 和文心一言哪个更好用? 一个直接可以用,一个还需要借助一些工具,还有可能账号会消失…… 没有可比性。 通用大模型用于特定功能的时候需要一些引导技巧。 import math import time def calculate_coordinate(c, d, e, f, g, h,…...
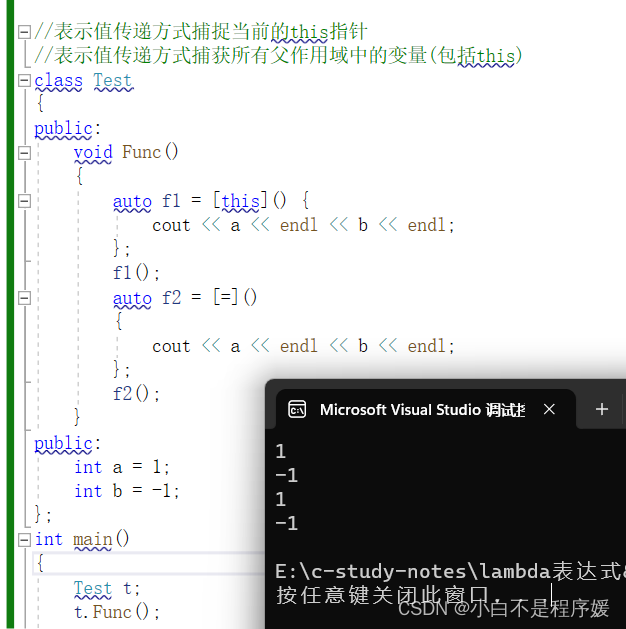
【C++干货铺】C++11新特性——lambda表达式 | 包装器
个人主页点击直达:小白不是程序媛 C系列专栏:C干货铺 代码仓库:Gitee 目录 C98中的排序 lambda表达式 lambda表达式语法 表达式中的各部分说明 lambda表达式的使用 基本的使用 [var]值传递捕捉变量var 编辑 [&var]引用传递捕…...

在 EggJS 中实现 Redis 上锁
配置环境 下载 Redis Windows 访问 https://github.com/microsoftarchive/redis/releases 选择版本进行下载 - 勾选 [配置到环境变量] - 无脑下一步并安装 命令行执行:redis-cli -v 查看已安装的 Redis 版本,能成功查看就表示安装成功啦~ Mac brew i…...

Unity-场景
创建场景 创建新的场景后: 文件 -> 生成设置 -> Build中的场景 -> 将项目中需要使用的场景拖进去 SceneTest public class SceneTest : MonoBehaviour {// Start is called before the first frame updatevoid Start(){// 两个类: 场景类、场…...
MATLAB R2023b for Mac 中文
MATLAB R2023b 是 MathWorks 发布的最新版本的 MATLAB,适用于进行算法开发、数据可视化、数据分析以及数值计算等任务的工程师和科学家。它包含了一系列新增功能和改进,如改进了数据导入工具,增加了对数据帧和表格对象的支持,增强…...
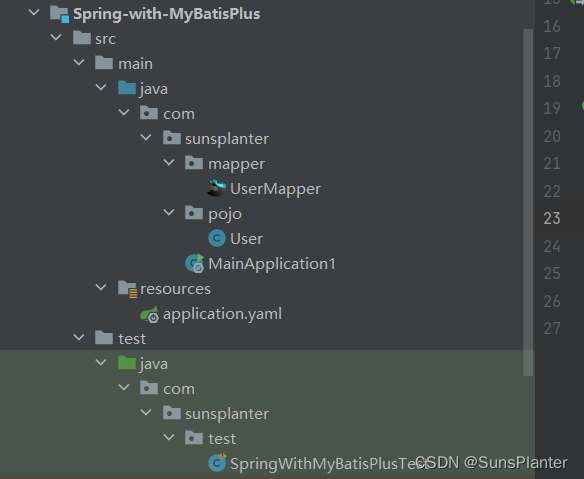
01 MyBatisPlus快速入门
1. MyBatis-Plus快速入门 版本 3.5.31并非另起炉灶 , 而是MyBatis的增强 , 使用之前依然要导入MyBatis的依赖 , 且之前MyBatis的所有功能依然可以使用.局限性是仅限于单表操作, 对于多表仍需要手写 项目结构: 先导入依赖,比之前多了一个mybatis-plus…...
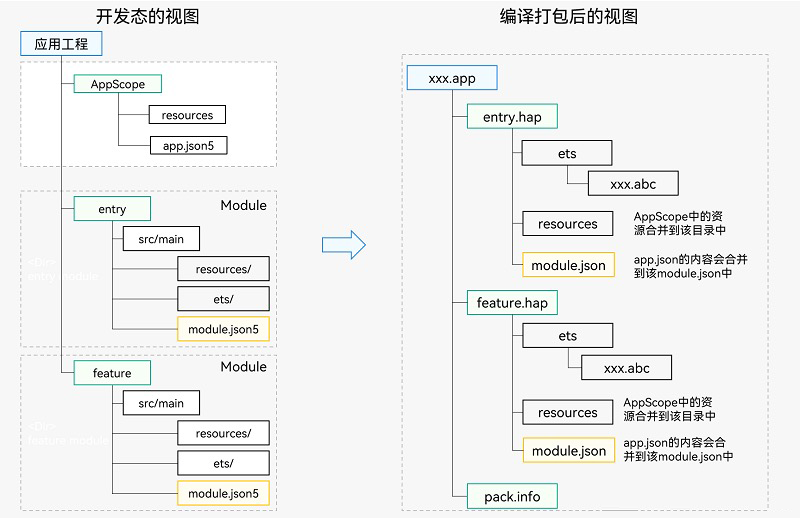
HarmonyOS 应用开发入门
HarmonyOS 应用开发入门 前言 DevEco Studio Release版本为:DevEco Studio 3.1.1。 Compile SDK Release版本为:3.1.0(API 9)。 构建方式为 HVigor,而非 Gradle。 最新版本已不再支持 (”Java、JavaScrip…...
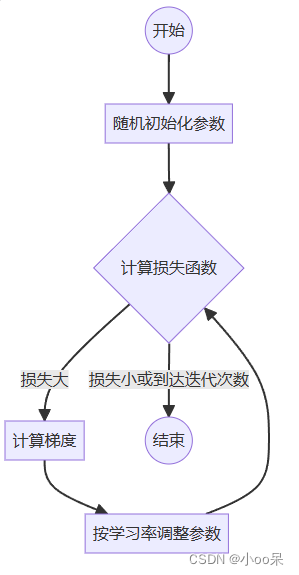
【机器学习300问】9、梯度下降是用来干嘛的?
当你和我一样对自己问出这个问题后,分析一下!其实我首先得知道梯度下降是什么,也就它的定义。其次我得了解它具体用在什么地方,也就是使用场景。最后才是这个问题,梯度下降有什么用?怎么用? 所以…...

第13章 1 进程和线程
文章目录 程序和进程的概念 p173函数式创建子进程Process类常用的属性和方法1 p175Process类中常用的属性和方法2 p176继承式创建子进程 p177进程池的使用 p178并发和并行 p179进程之间数据是否共享 p180队列的基本使用 p180使用队列实现进程之间的通信 p182函数式创建线程 p18…...
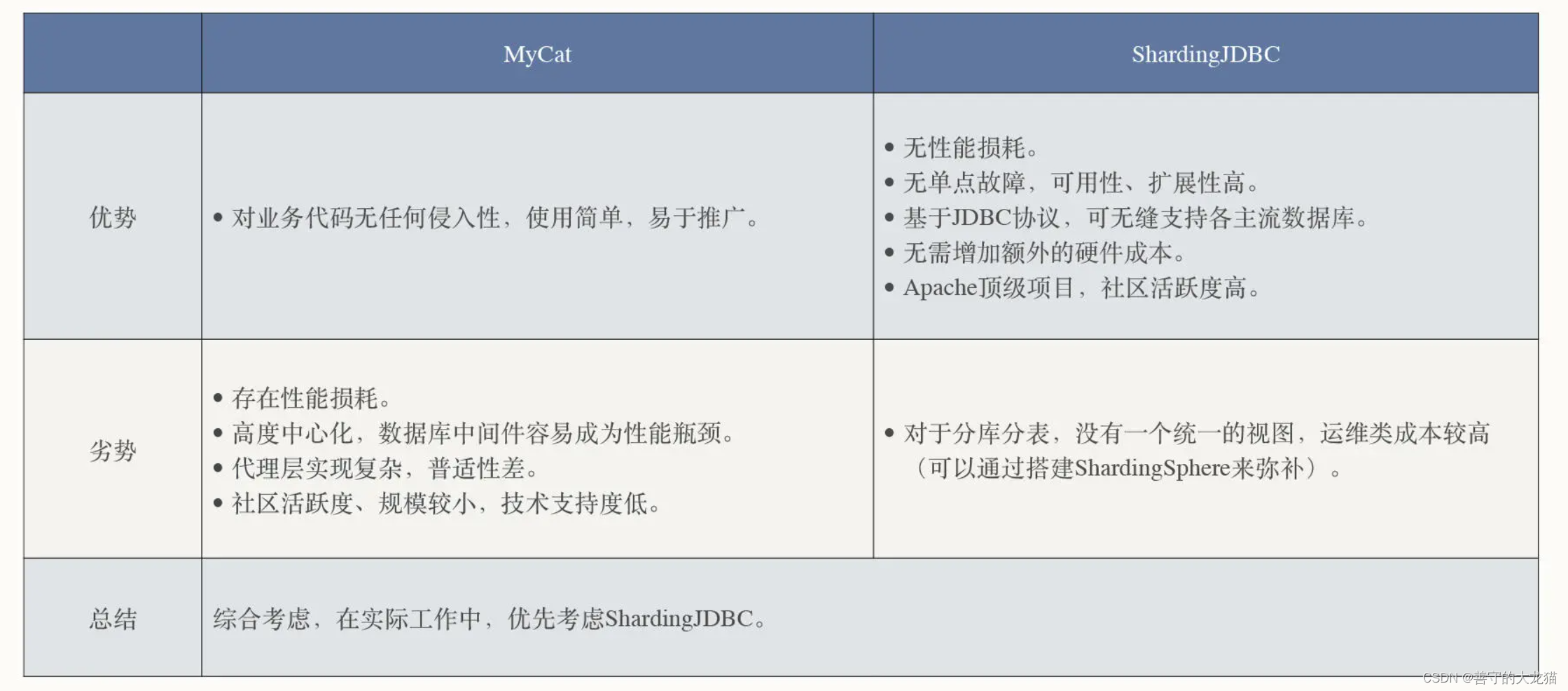
什么是中间件?
文章目录 为什么需要中间件?中间件生态漫谈数据库中间件读写分离分库分表引进数据库中间件MyCat 服务端代理模式ShardingJDBC 客户端代理模式 总结 IT 系统从单体应用逐渐向分布式架构演变,高并发、高可用、高性能、分布式等话题变得异常火热,…...

汽车售后服务客户满意度调查报告
本文由群狼调研(长沙旅行社满意度调查)出品,欢迎转载,请注明出处。汽车售后服务客户满意度调查报告通常包括以下内容: 1.调研概况:介绍调研的目的、背景和范围,包括调研的时间、地点和样本规模等…...

初始RabbitMQ(入门篇)
消息队列(MQ) 本质上就是一个队列,一个先进先出的队列,队列中存放的内容是message(消息),是一种跨进程的通信机制,用于上下游传递消息, 为什么使用MQ: 削峰填谷: MQ可以很好的做一个缓冲机制,例如在一个系统中有A和B两个应用,A是接收用户的请求的,然后A调用B进行处理. 这时…...
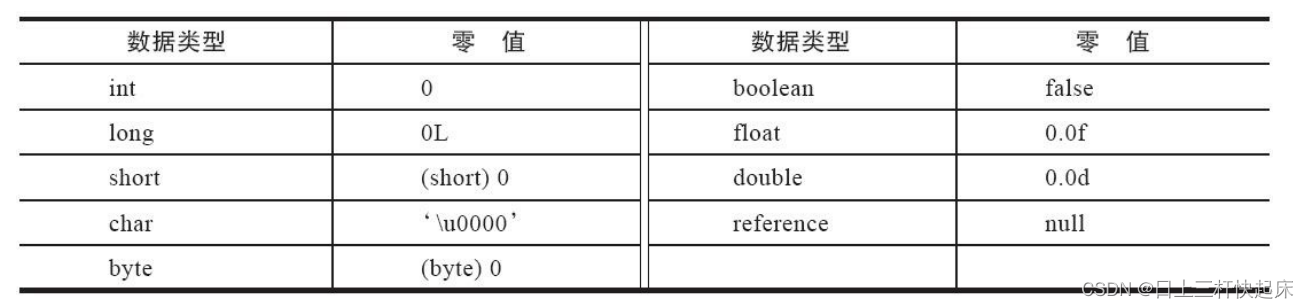
JVM:Java类加载机制
Java类加载机制的全过程: 加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,类型的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始, 这是为了支持Java…...

云端开发新体验:code-server部署与多场景应用指南
1. 为什么你需要一个云端开发环境? 记得去年我同时参与三个项目时,每天要在办公室台式机、家里笔记本和平板电脑之间来回切换。每次换设备最头疼的就是开发环境不一致——Node.js版本不同、Python包缺失、配置文件没同步...有次紧急修复线上bug时&#x…...
)
保姆级教程:用PHPStudy+Nginx一键部署新麦同城V3开源版(附数据库配置避坑点)
零基础30分钟部署新麦同城V3:PHPStudyNginx全流程避坑指南 第一次接触本地部署开源系统时,最怕的不是代码复杂,而是明明按教程操作却卡在某个配置环节。本文将以真实踩坑记录为核心,手把手带你在Windows环境下用PHPStudy快速搭建…...

8B模型榨出极限战力!本地LLM胜率狂飙86%
今天我们要讲的是一个工程方法,通过这个Forge框架来增强本地运行的8B模型,让这个小模型可以在复杂的agent任务上面有更好的表现。Q:本地小模型在做这些复杂任务的时候,经常会出现哪些让人抓狂的问题? A:在本…...

3步打造个人漫画库:BiliBili-Manga-Downloader完整使用指南
3步打造个人漫画库:BiliBili-Manga-Downloader完整使用指南 【免费下载链接】BiliBili-Manga-Downloader 一个好用的哔哩哔哩漫画下载器,拥有图形界面,支持关键词搜索漫画和二维码登入,黑科技下载未解锁章节,多线程下载…...
)
别再只用ROC了!用R语言ggplot2为你的Logistic回归模型画个校准曲线(附完整代码)
超越ROC:用R语言打造兼具诊断力与美学的Logistic回归校准曲线 当我们在医学统计或信用评分领域构建预测模型时,常常陷入一个认知陷阱——过度依赖ROC曲线和AUC值作为模型评估的唯一标准。这种单一视角可能掩盖了预测模型中更本质的问题:当模型…...

2026年计算机专业就业现状,不想35岁被淘汰?网络安全或许是程序员的最佳转型方向!
计算机专业虽进入分化阶段,但网络安全人才缺口达300万,高端领域供不应求。高校扩招与市场需求脱节导致供需失衡,未来"计算机行业"的复合型人才更具竞争力。建议早做规划,构建"T型能力体系",掌握前…...

全面配置指南:Excel MCP Server高效部署与专业运维实战
全面配置指南:Excel MCP Server高效部署与专业运维实战 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server Excel MCP Server是一个强大的模型…...

氨基酸表活洁面慕斯科普
一、什么是洁面慕斯洁面慕斯是一种预发泡型的洁面产品,和传统膏状、洗面奶不同,它从泵头挤出来就是细腻绵密的泡沫,不需要消费者手动打泡,使用起来更加方便快捷。从成分体系来看,洁面慕斯本质还是表面活性剂清洁产品&a…...
)
从零到一:用Air724UG 4G模块和Python,手把手教你搭建一个物联网数据上报系统(含完整代码)
从零构建物联网数据上报系统:Air724UG与Python实战指南 在万物互联的时代,物联网技术正悄然改变着我们的生活和工作方式。想象一下,您只需轻点手机,就能实时查看千里之外温湿度数据;或是远程监控设备运行状态ÿ…...

yolo26 pt转onnx
from ultralytics import YOLOdef main():# 加载你训练好的 YOLO26 模型model YOLO("D:\\ultralytics\\runs\\detect\\train-3\\weights\\best.pt") # 请将 best.pt 替换为你实际的文件路径# 导出为 ONNX 格式model.export(format"onnx",imgsz(640,384),…...