Self-RAG:通过自我反思学习检索、生成和批判
论文地址:https://arxiv.org/abs/2310.11511
项目主页:https://selfrag.github.io/
Self-RAG学习检索、生成和批评,以提高 LM 的输出质量和真实性,在六项任务上优于 ChatGPT 和检索增强的 LLama2 Chat。
问题:万能LLM错误陈述事实的问题
尽管大型语言模型(LLM)具有非凡的能力,但由于它们完全依赖于它们所封装的参数知识,因此通常会产生包含事实不准确的响应。他们经常产生幻觉,尤其是在长尾方面,他们的知识已经过时,并且缺乏归因。
检索增强是否是银弹
检索增强生成 (RAG) 是一种临时方法,通过检索相关知识来增强 LM,减少此类问题,并在 QA 等知识密集型任务中显示出有效性。然而,不加区别地检索和合并固定数量的检索到的段落,无论检索是否必要,或者段落是否相关,都会降低 LM 的多功能性或可能导致生成无用的响应。此外,并不能保证所引用的证据会影响几代人。
Self-RAG的概念
自反思检索增强生成(Self-RAG)是个新框架,通过检索和自反思来提高LM的质量和事实性。我们的框架训练单个任意LM,该LM可以自适应地按需检索段落(例如,可以在生成过程中多次检索或完全跳过检索),并使用称为反思令牌的特殊标记生成并反映检索到的段落及其自己的生成。生成反射令牌使LM在推理阶段可控,使其能够根据不同的任务要求调整其行为。
Self-RAG的好处
实验表明,Self-RAG(7B和13B参数)在各种任务上显着优于最先进的LLM和检索增强模型。具体来说,Self-RAG在开放域QA、推理和事实验证任务上优于ChatGPT和检索增强的Llama2-chat,并且相对于这些模型,它在提高长格式生成的事实性和引用准确性方面显示出显着的收益。
1. 基本思想
自我反思检索增强生成(SELF-RAG),通过按需检索和自我反思来提高LLM的生成质量,包括其事实准确性,而不损害其通用性。以端到端方式训练任意LLM,使其学会在任务输入时,通过生成任务输出和间歇性特殊标记(即反思标记)来反思自己的生成过程。反思标记分为检索标记和批判标记,分别表示检索需求和生成质量。
Self-RAG是个新的框架,通过自我反思令牌(Self-reflection tokens)来训练和控制任意LM。它主要分为三个步骤:检索、生成和批评。
- 检索:Self-RAG首先解码检索令牌(retrieval token)以评估是否需要检索,并控制检索组件。如果需要检索,LM将调用外部检索模块查找相关文档。
- 生成:如果不需要检索,模型会预测下一个输出段。如果需要检索,模型首先生成批评令牌(critique token)来评估检索到的文档是否相关,然后根据检索到的段落生成后续内容。
- 批评:如果需要检索,模型进一步评估段落是否支持生成。最后,一个新的批评令牌(critique token)评估响应的整体效用。
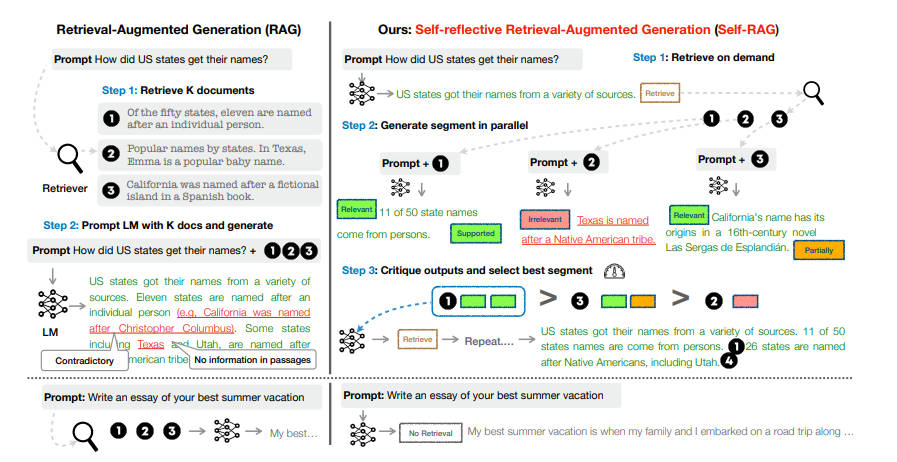
具体来说,在给定输入提示和前几代的情况下,SELF-RAG 首先会判断用检索到的段落来增强继续生成是否有帮助。
- 如果有帮助,它就会输出一个检索标记,按需调用检索模型(步骤 1)。
- 随后,SELF-RAG 同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(步骤 2)。
- 然后,它生成批判标记来批判自己的输出,并从事实性和整体质量方面选择最佳输出(第 3 步)。
这一过程不同于传统的 RAG(图 1 左),后者无论检索的必要性如何(例如,下图示例不需要事实性知识),都会持续检索固定数量的文档进行生成,而且从不对生成质量进行二次检查。
此外,SELF-RAG 还会为每个段落提供引文,并对输出结果是否得到段落支持进行自我评估,从而更容易进行事实验证。

SELF-RAG 通过将任意 LM 统一为扩展模型词汇表中的下一个标记预测,训练其生成带有反射标记的文本。
2. 实现详情
SELF-RAG 通过检索和自我反思来提高 LLM 的质量和事实性,同时又不牺牲 LLM 的原始创造性和多功能性。
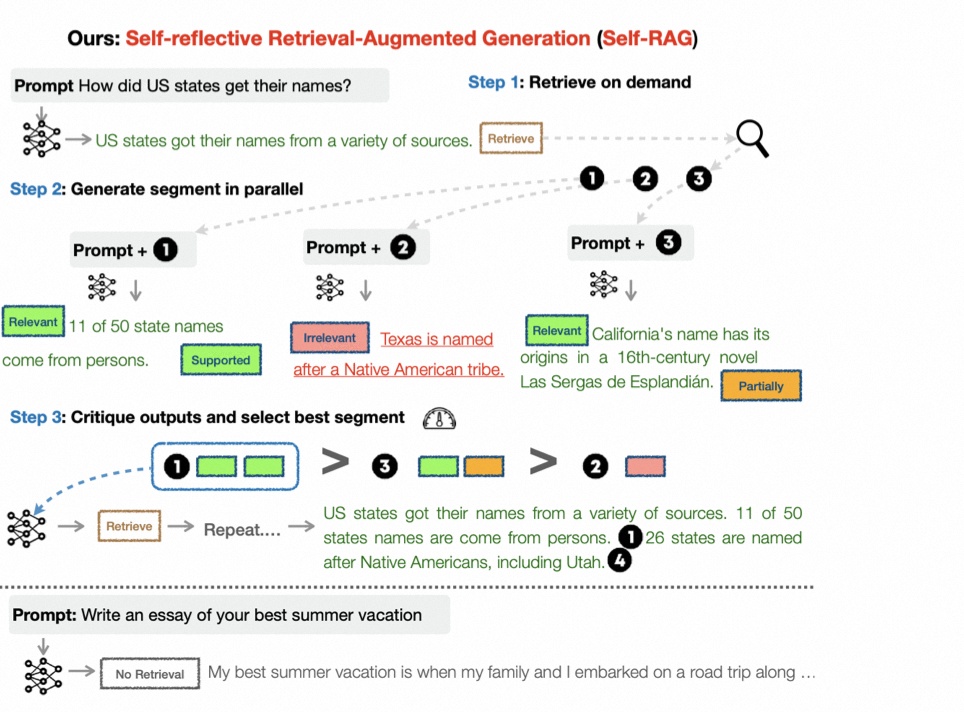
端到端训练可以让 LMM 在必要时根据检索到的段落生成文本,并通过学习生成特殊标记对输出进行批判。
这些反思标记(表 1)表示需要检索或确认输出的相关性、支持性或完整性。相比之下,常见的 RAG 方法会不加区分地检索段落,而无法确保引用来源的完整支持。

2.1 问题形式化和概述
形式上,给定输入 x,训练 M 按顺序生成由多个片段 y=y1,…,yT 组成的文本输出 y,其中 yt 表示第 t 个片段的标记序列。

首先看推理阶段。图 1 和算法 1 展示了 SELF-RAG 的推理情况。
对于每一个 x 和前序生成结果 y<t,模型都会解码一个检索标记,以评估检索的效用。如果不需要检索,模型就会像标准 LM 一样预测下一个输出段落。如果需要检索,模型就会生成一个评论标记,用于评估检索段落的相关性,然后生成下一个回复段落以及一个评论标记,用于评估回应段中的信息是否得到段落的支持。
SELF-RAG 并行处理多个段落以生成每个段落,并使用自己生成的反射标记对生成的任务输出执行软约束或硬控制。例如:
在上图中,由于 d2 没有提供直接证据(ISREL 为不相关),且 d3 输出仅得到部分支持,而 d1 得到完全支持,因此在第一个时间步骤中选择了检索到的段落 d1。
2.2 训练阶段
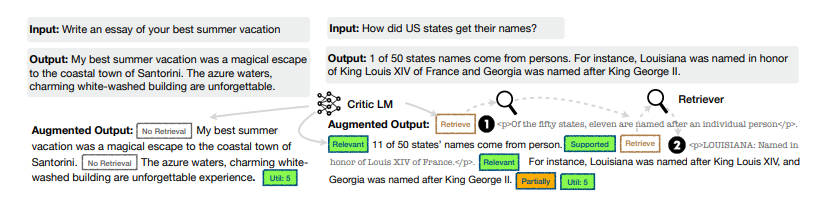
Self-RAG的训练包括三个模型:检索器(Retriever)、评论家(Critic)和生成器(Generator)。
首先,训练评论家,使用检索器检索到的段落以及反思令牌增强指令 - 输出数据。
然后,使用标准的下一个 token 预测目标来训练生成器 LM,以学习生成自然延续 (continuations) 以及特殊 tokens (用来检索或批评其自己的生成内容)。
下面介绍两个模型的监督数据收集和训练,即批判者 C 和生成器 M。
2.2.1 训练批判者模型
数据收集。对每个片段的反射标记进行人工标注的成本很高。最先进的 LLM(如 GPT-4)可有效用于生成此类反馈。然而,依赖这种专有的 LLM 可能会提高 API 成本并降低可重复性,通过促使 GPT-4 生成反射标记来创建监督数据,然后将其知识提炼为内部 C:{Xsample,Ysample}∼{X,Y}。

如表 1 所示,不同的反射标记组有不同的定义和输入,因此我们对它们使用不同的指令提示。反射标记定义如下:
- 按需检索(Retrieve):给定输入和前一步生成(如适用)后,LM 会确定续篇是否需要事实依据。no 表示不需要检索,因为序列不需要事实基础或可能不会通过知识检索得到加强;yes 表示需要检索。continue 表示一个模型可以继续使用之前检索到的证据。例如,一段话可能包含丰富的事实信息,因此 SELF-RAG 会根据这段话生成多个片段。
- 相关性(ISREL):检索到的知识不一定总是与输入相关。这一方面表明证据是否提供了有用的信息(相关)。
- 支持 (ISSUP):归因是指输出是否得到某些证据的充分支持。这一方面判断的是输出中的信息有多少是由证据所包含的,归因分为三个等级:完全支持、部分支持和不支持 / 矛盾。
- 有用(ISUSE):将感知到的有用性定义为回复是否是对查询有帮助且信息丰富的答案,而与回复是否符合事实无关,这也可视为可信度。对于有用性,采用五级评价(1 为最低,5 为最高)。
以” 检索” 为例。向 GPT-4 发送了一条特定类型的指令(” 给定指令,请判断从网络上查找一些外部文档是否有助于生成更好的回复。”),然后用 fewshot 演示了 I 的原始任务输入 x 和输出 y,以预测适当的反映标记文本:p(r|I,x,y)。
其针对每个标记,都设定了一些 prompt,这块是整个数据的关键:
表 8 显示了初始检索标记的指令和示例。

表 9 显示了用于收集” 检索给定指令”、” 前面的句子” 和” 以前检索过的段落” 三路输出标记的指令和示例。

表 10 显示了用于收集 ISREL 三路输出标记的指令和示例。

表 11 显示了用于收集 ISREL 三路输出标记的指令和示例。

表 12 显示了用于收集 ISUSE 的五路输出标记的指令和示例。
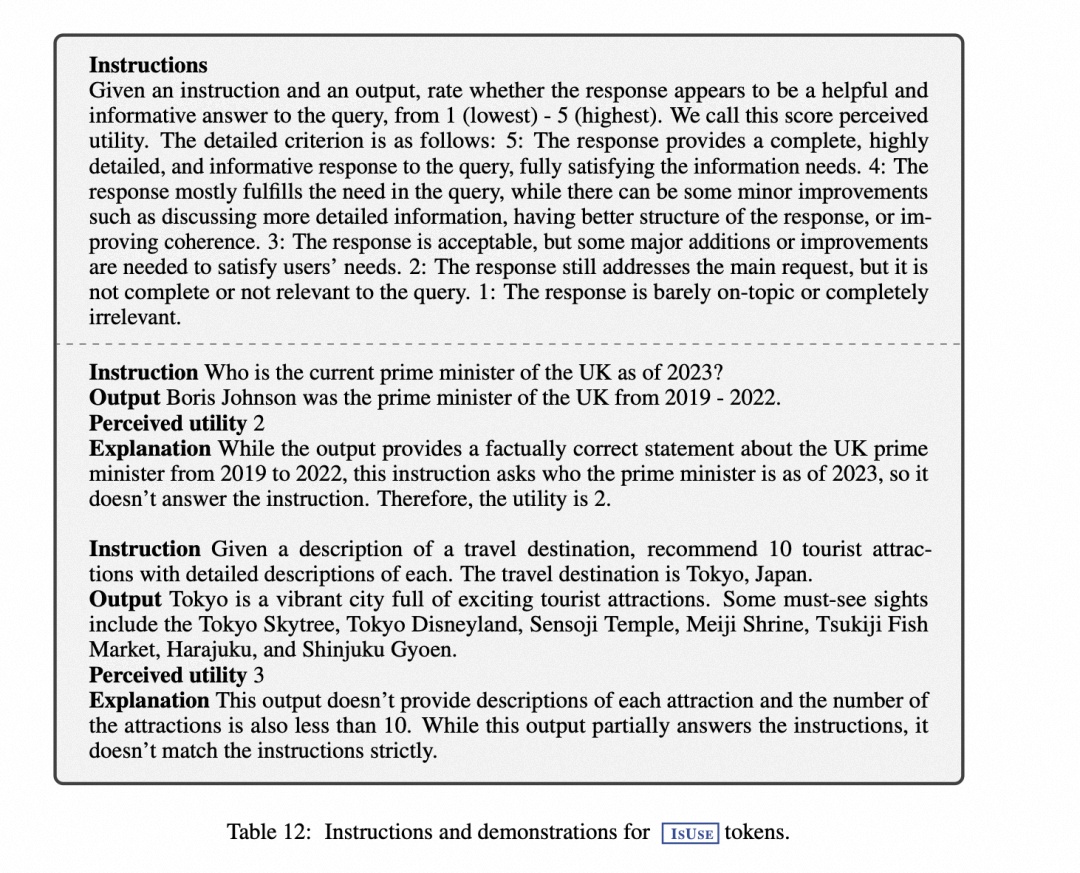
人工评估结果表明,GPT-4 的反射标记预测与人工评估结果具有很高的一致性,所以为每种类型收集了 4k-20k 个有监督的训练数据,并将它们组合起来形成 C 的训练数据,样式如下:
训练数据的样式如下:

批判学习。在收集到训练数据 Dcritic 之后,用预先训练好的 LM 对 C 进行初始化,并使用标准的条件语言建模目标–最大化似然–对其进行训练:
$\max {\mathcal{C}} \mathbb{E}{((x, y), r) \sim \mathcal{D}{\text {critic }}} \log p{\mathcal{C}}(r \mid x, y), r \text { for reflection tokens. }$
2.2.2 训练生成器模型
数据收集。给定一对输入 - 输出(x,y),使用检索模型和批判者模型来增强原始输出 y,以创建精确模拟 SELF-RAG 推理时间过程的监督数据。对于每个语段 yt∈y,运行 C 来评估额外的语段是否有助于增强生成。如果需要检索,则添加检索特殊标记 Retrieve=yes,然后 R 检索前 K 个段落 D。对于每个段落,C 进一步评估该段落是否相关,并预测 ISREL。如果段落相关,C 会进一步评估该段落是否支持模型生成,并预测 ISSUP。
其中,批判标记 ISREL 和 ISSUP 会附加在检索到的段落之后。在输出 y(或 yT)结束时,C 会预测总体效用标记 ISUSE,并将包含反射标记和原始输入对的增强输出添加到 Dgen 中。

生成器学习。使用标准的下一个标记目标,在添加了反射标记 Dgen 的编辑语料库上训练生成器模型 M:
$\max {\mathcal{M}} \mathbb{E}{(x, y, r) \sim \mathcal{D}{g e n}} \log p{\mathcal{M}}(y, r \mid x)$
M 与 C 训练不同,M 学习预测目标输出和反射标记。在训练过程中会屏蔽掉检索到的文本块以计算损失,并用一组反射标记 {Critique,Retrieve} 来扩展原始词汇 V。
3、推理阶段
Self-RAG 通过学习生成反思令牌,使得在不需要训练 LMs 的情况下为各种下游任务或偏好量身定制模型行为。特别是:
- 它可以适应性地使用检索令牌进行检索,因此模型可以自发判断是不是有必要进行检索。
- 它引入了多种细粒度的批评令牌,这些令牌用于评估生成内容的各个方面的质量。在生成过程中,作者使用期望的批评令牌概率的线性插值进行 segment 级的 beam search,以在每一个时间步骤中确定最佳的 K 个续写方案。
在推理阶段,SELF-RAG 通过生成反射标记来自我评估输出结果,从而使其行为适应不同的任务要求。
对于要求事实准确性的任务,目标是让模型更频繁地检索段落,以确保输出结果与可用证据密切吻合。在开放性较强的任务中,如撰写个人经历文章,重点则转向减少检索次数,优先考虑整体创造性或实用性得分。
因此,在推理过程中需要实施控制以满足这些不同目标。方法如下:
带阈值的自适应检索。SELF-RAG 通过预测” 检索”(Retrieve)来动态决定何时检索文本段落。另外还允许设置阈值。具体来说,如果在 Retrieve 的所有输出标记中生成 Retrieve=Yes 标记的概率超过了指定的阈值,就会触发检索:
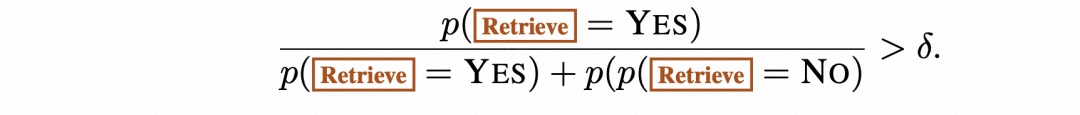
带批判标记的树状解码。在每个分段步骤 t,当需要根据硬条件或软条件进行检索时,R 会检索 K 个段落,生成器 M 会并行处理每个段落,并输出 K 个不同的候选续篇。进行分段级波束搜索(波束大小 = B),以获得每个时间戳 t 的前 B 个分段连续性,并在生成结束时返回最佳序列。
每个段落 yt 相对于段落 d 的得分都会用批判者得分 S 更新,该得分是每个段落 yt 和段落 d 的归一化概率的线性加权和。
对于每个批判标记组 G(如 ISREL),将其在时间戳 t 的得分记为 sGt,并按如下方式计算片段得分:
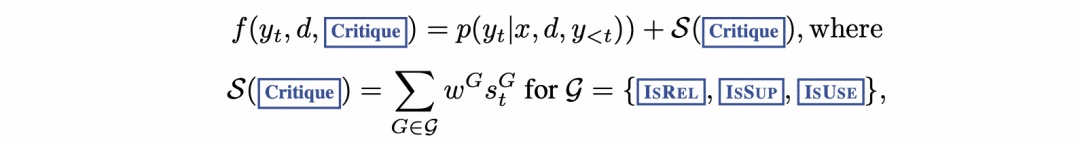
3.实验设置与结果分析
3.1 任务和数据集
该工作在一系列下游任务上对 SELF-RAG 和各种基线进行了评估,用旨在评估整体正确性、事实性和流畅性的指标对输出进行了整体评估。
封闭集任务包括两个数据集,即关于公共卫生的事实验证数据集(PubHealth)和根据科学考试创建的多选推理数据集(ARC-Challenge),使用准确率作为评估指标,并对测试集进行报告。
两个开放域问题解答(QA)数据集:PopQA 和 TriviaQA-unfiltered,其中系统需要回答有关事实知识的任意问题。
长式生成任务包括传记生成任务和长式质量保证任务 ALCE-ASQA,使用 FactScore 来评估传记,并使用基于 MAUVE 的官方指标正确性、流畅性以及引用精度和召回率来评估 ASQA。
3.2 实验结果
表 2(上)列出了相关对比效果:
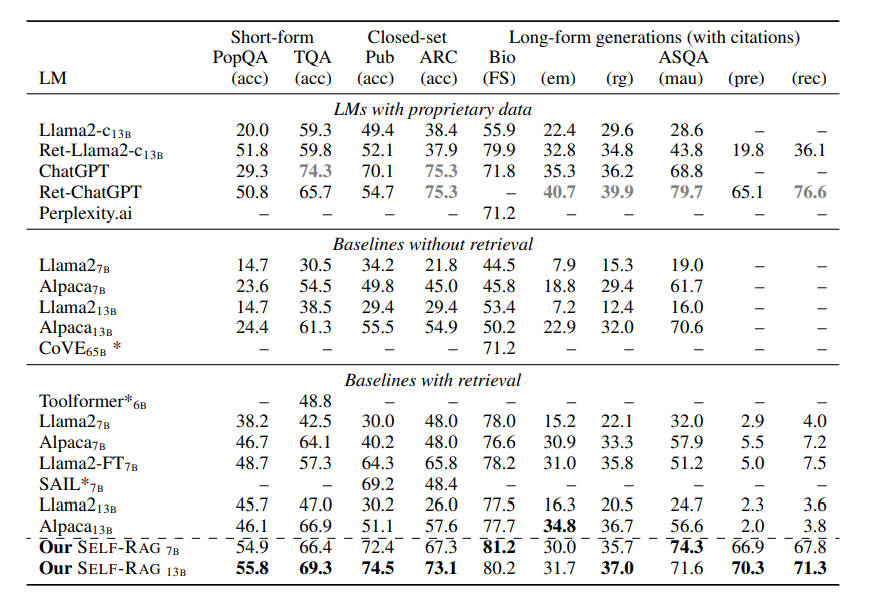
如表 2(下)所示:
在 PubHealth 和 ARC-Challenge 上,有检索功能的基线与没有检索功能的基线相比,性能提升并不明显。
大多数带检索的基线模型在提高引用准确率方面都很吃力。
在实际精确度的度量上,SELF-RAG7B 偶尔会优于 13B,这是因为较小的 SELF-RAG 通常倾向于生成精确且较短的输出。
Llama2-FT7B 是在与 SELF-RAG 相同的指令 - 输出对上训练的基准 LM,不进行检索或自我反省,仅在测试时进行检索增强,它落后于 SELF-RAG。这一结果表明,SELF-RAG 的收益并非完全来自训练数据,并证明了 SELF-RAG 框架的有效性。
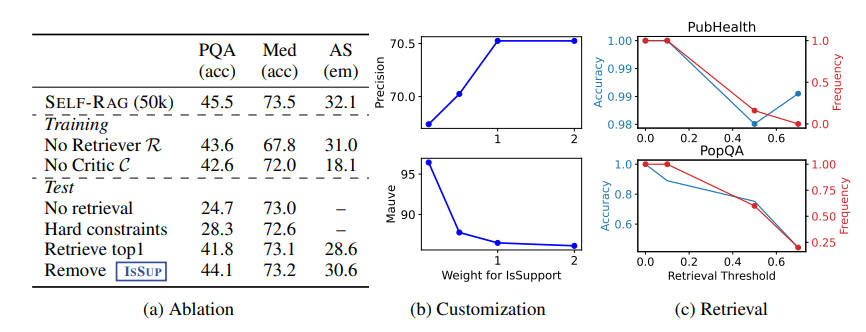

Self-RAG 在六项任务中均超越了原始的 ChatGPT 或 LLama2-chat,并且在大多数任务中,其表现远超那些广泛应用的检索增强方法。以上是一些消融实验,可以看到:每一个组件和技术在 Self-RAG 中都起到了至关重要的作用。调整这些组件可以显著影响模型的输出性质和质量,这证明了它们在模型中的重要性。
综上所述,Self-RAG 作为一种新型的检索增强生成框架,通过自适应检索和引入反思令牌,不仅增强了模型的生成效果,还提供了对模型行为的更高程度的控制。这项技术为提高开放领域问答和事实验证的准确性开辟了新的可能性,展示了模型自我评估和调整的潜力。
4. 总结
SELF-RAG 通过预测原始词汇中的下一个标记以及新添加的特殊标记(称为” 反思标记”),训练 LM 学习检索、生成和批判文本段落以及自己的生成。
相关文章:
Self-RAG:通过自我反思学习检索、生成和批判
论文地址:https://arxiv.org/abs/2310.11511 项目主页:https://selfrag.github.io/ Self-RAG学习检索、生成和批评,以提高 LM 的输出质量和真实性,在六项任务上优于 ChatGPT 和检索增强的 LLama2 Chat。 问题:万能L…...

C++基于多态的职工管理系统(附代码下载)
🌈个人主页:godspeed_lucip 🔥 系列专栏:C从基础到进阶 本文配套markdown文件、配套完整程序(vs项目,可直接运行)网盘链接请翻阅至文章最底部获取。 职工管理系统🌏1、管理系统需求…...
Java安全 CC链1分析
Java安全之CC链1分析 什么是CC链环境搭建jdk下载idea配置创建项目 前置知识Transformer接口ConstantTransformer类invokerTransformer类ChainedTransformer类 构造CC链1CC链1核心demo1demo1分析 寻找如何触发CC链1核心TransformedMap类AbstractInputCheckedMapDecorator类readO…...

Miracast手机高清投屏到电视(免费)
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl Miracast概述 Miracast是一种无线显示标准,它允许支持Miracast的设备之间通过Wi-Fi直接共享音频和视频内容,实现屏幕镜像或扩展显示。这意味着你可以…...
【elementUI】el-select相关问题
官方使用DEMO <template><el-select v-model"value" placeholder"请选择"><el-optionv-for"item in options":key"item.value":label"item.label":value"item.value"></el-option></…...
【蓝桥杯日记】复盘第一篇——顺序结构
🚀前言 本期是一篇关于顺序结构的题目的复盘,通过复盘基础知识,进而把基础知识学习牢固!通过例题而进行复习基础知识。 🚩目录 前言 1.字符三角形 分析: 知识点: 代码如下 2. 字母转换 题目分析: 知…...
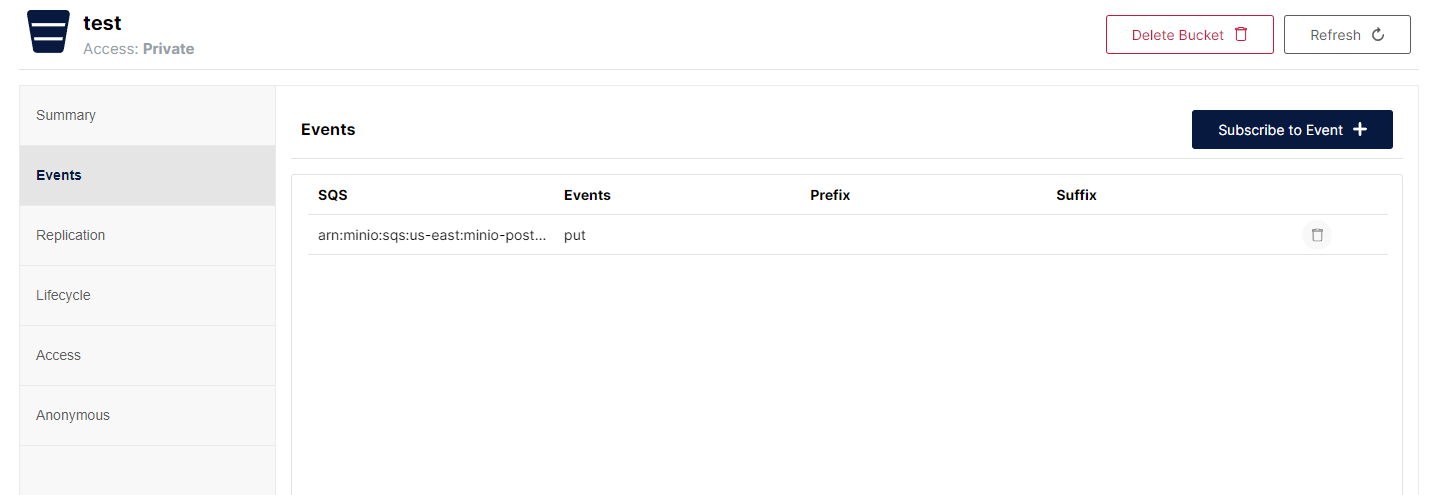
使用 MinIO 和 PostgreSQL 简化数据事件
本教程将教您如何使用 Docker 和 Docker Compose 在 MinIO 和 PostgreSQL 之间设置和管理数据事件,也称为存储桶或对象事件。 您可能已经在利用 MinIO 事件与外部服务进行通信,现在您将通过使用 PostgreSQL 自动化和简化数据事件管理来增强数据处理能力…...
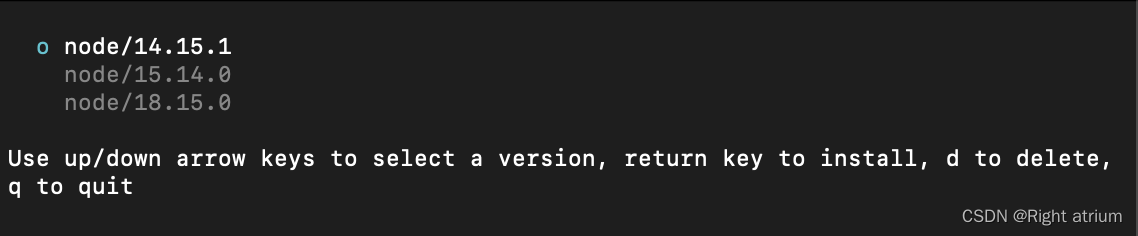
苹果电脑(Mac)的node版本安装以及升降级
在开发过程中,对于不同的开发环境或者较老的项目可能需要切换不同的node版本,此过程会涉及到node版本的升级与降级,安装node版本管理模块n(sudo命令)。 全局安装n模块 sudo npm install n -g//输入后回车,…...
WCP知识分享平台的容器化部署
1. 什么是WCP? WCP是一个知识管理、分享平台,支持针对文档(包括pdf,word,excel等)进行实时解析、索引、查询。 通过WCP知识分享平台进行知识信息的收集、维护、分享。 通过知识创建、知识更新、知识检索、知识分享、知识评价、知识统计等功能进行知识生命周期管理。 wcp官…...
乐意购项目前端开发 #4
一、Home页面组件结构 结构拆分 创建组件 在 views/Home 目录下创建component 目录, 然后在该目录下创建5个组件: 左侧分类(HomeCategory.vue)、Banner(HomeBanner.vue)、精选商品(HomeHot.vue)、低价商品(Homecheap.vue)、最新上架(HomeNew.vue) 引用组件 修改 views/Home…...

最安全的飞行器——飞行汽车
飞行汽车采用旋翼机飞行方式,稳定可靠,保证人身安全,可以垂直起降。旋翼机的稳定性在所有航空器中最高的,旋翼机被国际航空界公认为最安全的飞行器!增程器采用斯特林发电机。飞行汽车3D。 固定翼飞机在起飞的时候&…...
java验证ftp地址是否可用
一.前言 在实际开发中我们的业务是我们将订单发到客户的指定的地方, 我们需要验证用户的ftp地址是否真实且有效, 我们根据java程序来进行验证, 步骤和思路应该是. 步骤描述1导入所需要的 java类库(jar包依赖)2创建ftp客户端对象3设置ftp连接服务端的连接参数4建立与ftp的服务…...

多线程(看这一篇就够了,超详细,满满的干货)
多线程 一.认识线程(Thread)1. 1) 线程是什么1. 2) 为啥要有线程1.3) 进程和线程的区别标题1.4) Java的线程和操作系统线程的关系 二.创建线程方法1:继承Thread类方法2:实现Runnable接口方法3:匿名内部类创建Thread子类对象标题方法4:匿名内部类创建Runn…...

爬虫进阶之selenium模拟浏览器
爬虫进阶之selenium模拟浏览器 简介环境配置1、建议先安装conda2、创建虚拟环境并安装对应的包3、下载对应的谷歌驱动以及与驱动对应的浏览器 代码setting.py配置scrapy脚本参考中间件middlewares.py 附录:selenium教程 简介 Selenium是一个用于自动化浏览器操作的…...

props传值
文章目录 props用于父组件向子组件传递数据,从而实现组件之间的通信。 以下是使用props的详细步骤: 父组件中定义 props: 在父组件中,通过在子组件的标签上添加属性来定义要传递的数据。这些属性就是props。 <!-- ParentCompon…...

IaC基础设施即代码:Terraform 使用for_each 创建DNS资源副本
目录 一、实验 1.环境 2.Terraform 使用 for_each 创建资源副本 (DNS) 一、实验 1.环境 (1)主机 表1-1 主机 主机系统软件工具备注jia Windows Terraform 1.6.6VS Code、 PowerShell、 Chocolatey 2.Terraform 使用 for_ea…...
dubbo入门案例!!!
入门案例之前我们先介绍一下:zookeeper。 Zookeeper是Apacahe Hadoop的子项目,可以为分布式应用程序协调服务,适合作为Dubbo服务的注册中心,负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只…...

sm2和aes加解密
引用maven包 <dependency><groupId>org.bouncycastle</groupId><artifactId>bcprov-jdk18on</artifactId><version>1.72</version></dependency>2.对报文进行加密后生成签名 {// oristr报文 SECRET_KEY加密密钥String encrypt…...

cv2.findContours报错解决
问题引入 原代码: binary, contours, hierarchy cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE) 发生了报错,这是因为我们这里返回了binary, contours, hierarchy三个值 这是opencv2里面的写法,在最新版opencv中只返回2个值 修改 contours, hierarchy c…...
RHEL - 更新升级软件或系统
《OpenShift / RHEL / DevSecOps 汇总目录》 文章目录 小版本软件更新yum update 和 yum upgrade 的区别升级软件和升级系统检查软件包是否可升级指定升级软件使用的发行版本方法1方法2方法3方法4 查看软件升级类型更新升级指定的 RHSA/RHBA/RHEA更新升级指定的 CVE更新升级指定…...
)
别再只画区间了!用ECharts的markArea实现单点高亮标注(附完整代码)
突破ECharts标记边界:用markArea实现单点高亮的高级技巧 在数据可视化领域,ECharts凭借其强大的功能和灵活的配置选项,已成为前端开发者和数据分析师的首选工具之一。当我们面对需要突出显示特定数据点的场景时,常规做法是使用mar…...

【Perplexity数据验证黄金标准】:基于ISO/IEC 25010质量模型的6维可信度评估框架
更多请点击: https://kaifayun.com 第一章:Perplexity数据验证黄金标准的定义与演进 Perplexity(困惑度)作为衡量语言模型预测能力的核心指标,其数据验证黄金标准并非静态规范,而是随建模范式、评估粒度与…...

开关电源功率因数校正:从谐波失真到PFC电路设计实践
1. 项目概述:从“相移”到“失真”,理解开关整流器的功率因数挑战在通信、数据中心乃至我们日常使用的各类开关电源适配器中,高频开关整流器是电能转换的核心。作为一名电源工程师,我经常被问到:“为什么我们设备的输入…...

Python 浅拷贝与深拷贝:为什么我改了 b,a 也跟着变了?
Python 浅拷贝与深拷贝:为什么我改了 b,a 也跟着变了? 在 Python 中,列表、字典、集合这类对象都属于可变对象。 也正因为它们“可变”,所以在复制数据时,经常会遇到一个非常经典的问题:明明我改…...

OAuth 接入DeepSeek总失败?这3类JWT签名验证错误正在 silently 拒绝你的请求,速查!
更多请点击: https://kaifayun.com 第一章:OAuth 接入DeepSeek总失败?这3类JWT签名验证错误正在 silently 拒绝你的请求,速查! 当你调用 DeepSeek 的 OAuth 2.0 接口(如 /v1/auth/token)时&am…...

一键获取九大网盘真实下载地址:LinkSwift网盘直链下载助手完整指南
一键获取九大网盘真实下载地址:LinkSwift网盘直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...

i.MX6ULL LCD驱动适配实战:从设备树到时序调试全解析
1. 项目概述与核心价值最近在搞一个基于i.MX6ULL的工控HMI项目,屏幕显示是绕不开的一环。市面上很多教程要么只讲Framebuffer应用,要么直接给个现成的设备树文件让你照着改,至于里面的参数怎么来的、屏幕初始化序列怎么配,往往一笔…...

iOS 18.1 5G功能深度解析:从智能省电到SA网络优化
1. 项目概述:一次聚焦于连接体验的深度更新作为一名长期跟踪移动操作系统生态的从业者,每次苹果发布新的iOS版本,我都会习惯性地去拆解其更新日志,看看哪些是“面子工程”,哪些是真正触及用户体验核心的“里子升级”。…...

Firefox Android与Firefox Focus对比分析:选择最适合你的浏览器
Firefox Android与Firefox Focus对比分析:选择最适合你的浏览器 【免费下载链接】firefox-android :warning: This repository hosts the Firefox for Android (Fenix), Focus for Android, and Mozilla Android Components projects. It is now developed and main…...

3步永久激活Windows和Office:开源智能脚本的完整指南
3步永久激活Windows和Office:开源智能脚本的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为电脑屏幕上频繁弹出的"需要激活"提示而烦恼吗?Offi…...