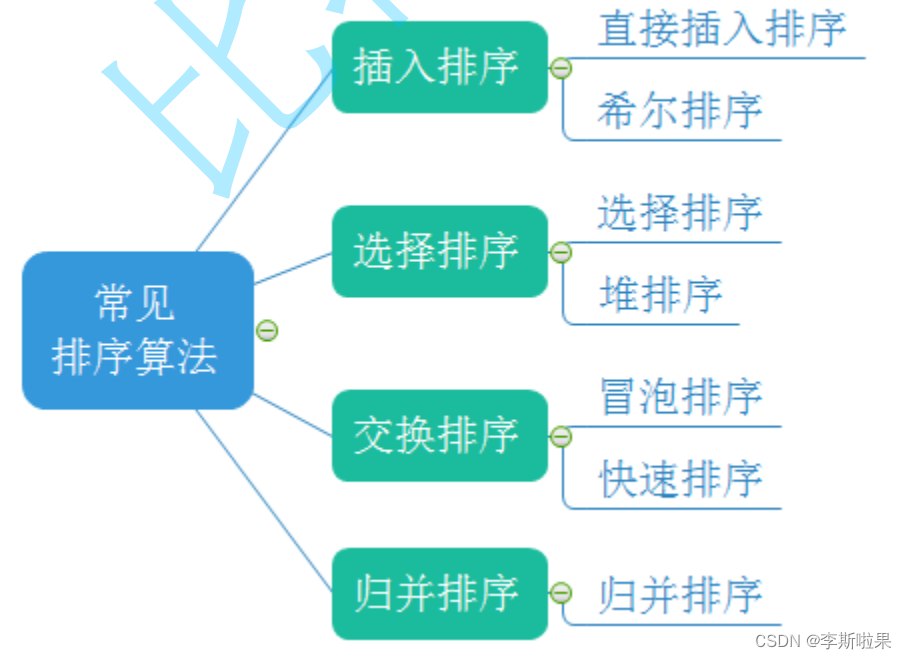
【数据结构】常见八大排序算法总结
目录
前言
1.直接插入排序
2.希尔排序
3.选择排序
4.堆排序
5.冒泡排序
6.快速排序
6.1Hoare版本
6.2挖坑法
6.3前后指针法
6.4快速排序的递归实现
6.5快速排序的非递归实现
7.归并排序
8.计数排序(非比较排序)
9.补充:基数排序
10.总结:排序算法的复杂度及稳定性分析
前言
排序 :排序就是使一串记录按照其中某个或某些关键字的大小,递增或者递减的排列起来的操作
内部排序:数据元素全部存放在内存中的排序
外部排序:数据元素太多而不能同时放在内存中,根据排序过程的要求不断在内外存之间移动数据的排序
常见的排序算法:
以上排序算法都是比较排序,还有计数排序这类非比较排序算法,一下我们对各个排序算法进行代码实现
1.直接插入排序
直接插入排序是一种简单的插入排序算法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列
过程:当插入第i(i>=1)个元素时,前面的array[0],...,array[i-1]已经有序,此时用array[i]的排序码与array[i-1],array[i-2],...的排序码依次比较,找到插入位置后将原来位置上的元素顺序后移,将array[i]插入
📖Note:
对于数组中的第一个数据,不需要进行比较,因此第一步操作的是a[1]处的数据,区间[0,0]上的数据即a[0]这一个数据是有序的,因此外层循环只需要对n-1次,对a[1]到a[n-1]共n-1个数据进行处理
对于要处理的a[i],依次与a[i-1],a[i-2]比较,如果大于a[i]则交换(升序排列的情况)
优化:备份i处的数据,依次与a[i-1],a[i-2]比较,大于a[i]则向后移动一个位置,否则在小于a[i]的数据元素的后一个位置插入a[i]
时间复杂度与空间复杂度:
插入排序是在存放原数据的数组上进行操作,所以直接插入排序算法的空间复杂度是O(1)
1️⃣当原数据的序列是逆序时,为最坏情况,此时直接插入排序算法的时间复杂度是O(N^2)
如上图,序列逆序时,数据的挪动次数为1+2+3+...+n-1 = n(n-1)/2
所以时间复杂度为O(N^2)
2️⃣当原数据的序列有序时,为最好情况,此时直接插入排序算法的时间复杂度是O(N)
如上图:序列顺序排列时,总共进行了n-1次比较,没有数据的挪动
因此时间复杂度为O(N)
总结:元素集合越接近有序,直接插入排序算法的时间效率越高


//直接插入排序
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; ++i){// [0,end]有序,end+1处的数据找到正确位置后,[0, end+1]有序int end = i;int tmp = a[end + 1];while (end >= 0){//升序排列if (a[end] > tmp){a[end + 1] = a[end];--end;}else{break;}}//此时,a[end]<=tmpa[end + 1] = tmp;}
}2.希尔排序
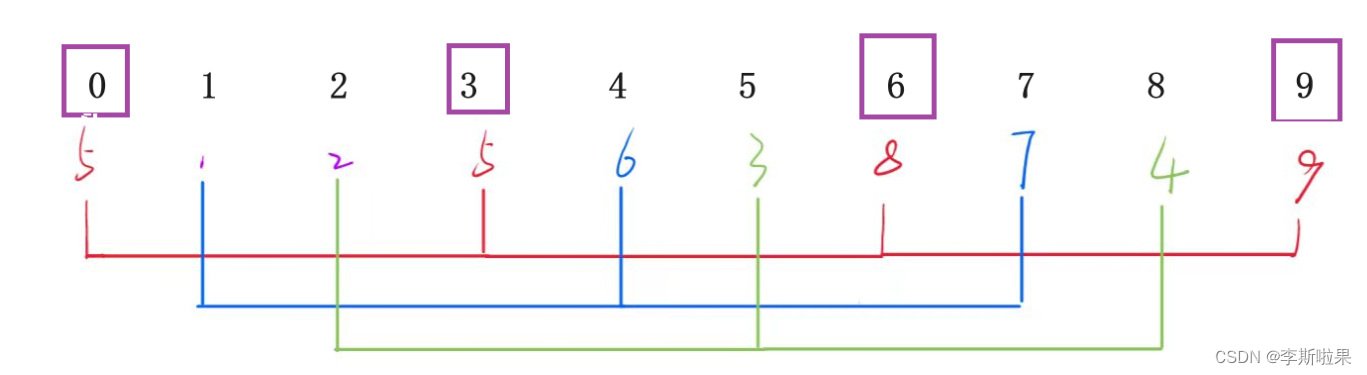
希尔排序又称为缩小增量排序,希尔排序的基本思想:先选定一个整数gap,把待排序文件中的所有记录分成n/gap个组,每一组内的记录进行排序,然后更新(缩小)gap,重复上述分组和排序的操作,当gap=1时,所有记录在同一组内排序,即使所有记录有序
以下以初始增量为3为例
第一次分组如下图
每一组内的记录进行排序,使用直接插入排序算法
缩小gap=1,即对序列:5 1 2 5 6 3 8 7 4 9进行排序
每一组记录使用直接插入排序算法,当gap不为1时,每组记录的数据元素并不是连续排列的,而是间隔gap,因此需要对直接插入排序算法进行改造
for (int i = 0; i < n - gap; ++i) {int end = i;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp; }优化:for循环调整部分为i++时,每次直接插入排序排一组记录,当改为i+=gap时,可以实现多组记录同时排序
📖Note:
希尔排序是对直接插入排序的优化,当gap>1时都是预排序,目的是使数据集合接近有序,当数据集合接近有序时,直接插入排序的时间效率较高
gap的选择:
gap的取法有多种,最初Shell提出取gap = n/2,gap = gap/2,直到gap = 1;后来Knuth提出取gap = gap/3 + 1。我们采用Knuth提出的方式取值。
gap越大,大数可以越快的跳到后面;gap越小,跳的越慢,但数据集合越接近有序
时间复杂度和空间复杂度:
希尔排序算法不额外开辟空间,其空间复杂度为O(1)
对希尔排序的时间复杂度分析很困难,在特定情况下可以准确估算关键码的比较次数和对象移动次数,但想要弄清楚关键码的比较次数和对象移动次数与增量选择之间的依赖关系,目前还没有较完整的数学分析,Knuth在《计算机程序设计技巧》中的结论是:在n很大时,关键码的平均比较次数和对象平均移动次数大约在n^1.25到1.6*n^1.25范围内,这是在利用直接插入排序作为子序列排序方法的情况下得到的。

//希尔排序
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;//更新增量//for (int i = 0; i < n - gap; ++i)for (int i = 0; i < n - gap; i += gap){int end = i;int tmp = a[end + gap];while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}3.选择排序
选择排序的基本思想:每一次从待排的数据元素中选出最小或最大的一个元素,存放在序列的起始位置,直到所有待排序的数据元素排完
直接选择排序的步骤:
1️⃣在元素集合array[i]到array[n-1]中选择关键码最大(小)的数据元素
2️⃣若它不是这组元素中的最后一个或第一个元素,则将它与这组元素中的最后一个或第一个元素交换
3️⃣在剩余的array[i]到array[n-2](array[i+1]到array[n-1])集合中,重复上述步骤,直到集合剩余一个元素
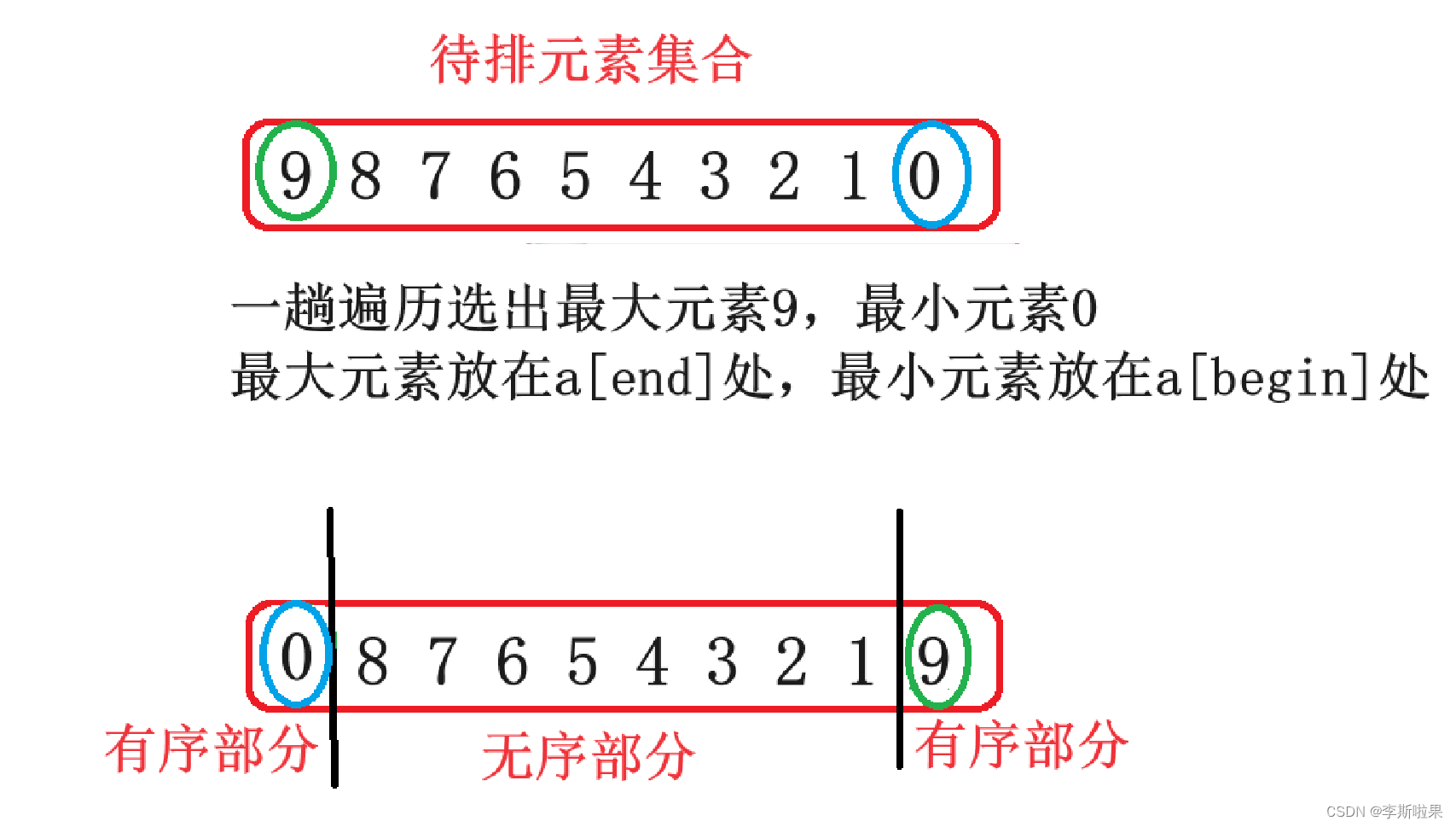
简单来说,直接选择排序将数据集合分成两部分,有序部分和无序部分
以排升序为例,每次选取待排数据集合即无序部分中的最大数放到无序部分的第一个位置即有序部分之后的第一个位置,就完成了一个数据元素的排序
优化:选择元素时选取最大元素和最小元素的操作同时进行,一趟比较选出最大的元素放在a[end]位置,选出最小的元素放在a[begin]位置,begin++,end--,重复上述操作
优化之后数组的两端有序部分,中间为无序部分
时间复杂度和空间复杂度:
直接选择排序算法不额外开辟空间,其空间复杂度为O(1)
1️⃣当原数据的序列是逆序时,为最坏情况,此时选择排序算法的时间复杂度是O(N^2)
遍历待排数据元素集合,共n个数据,选出最大值和最小值,需要比较n-1次
遍历待排数据元素集合,共n-2个数据,选出最大值和最小值,需要比较n-3次
综上所述,当原序列的数据元素逆序时,总共比较的次数为
(n-1)+(n-3)+...+1 = (n/2) *n / 2
所以直接选择排序的时间复杂度为O(N^2)
2️⃣当原数据的序列有序时,为最好情况,此时直接插入排序算法的时间复杂度是O(N^2)
对于直接选择排序算法来说,逆序和顺序的时间复杂度相同,因为进行数据选择的操作是相同的,都是进行遍历选数,因此效率不高】

void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
//选择排序
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){// 选出最小的放begin位置// 选出最大的放end位置int mini = begin, maxi = begin;for (int i = begin + 1; i <= end; ++i){if (a[i] > a[maxi]){maxi = i;}if (a[i] < a[mini]){mini = i;}}Swap(&a[begin], &a[mini]);// 修正maxi:特殊情况begin和maxi重叠时,执行一次交换,maxi记录的是最小值if (maxi == begin)maxi = mini;Swap(&a[end], &a[maxi]);++begin;--end;}
}4.堆排序
冒泡排序详解可以参考:CSDN
5.冒泡排序
冒泡排序详解可以参考:CSDN
6.快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,快速排序的基本思想为:任取待排元素序列中的某个元素作为基准值,按照该排序码将待排序集合分割成两个子序列,左子序列中的所有元素均小于基准值,右子序列中的所有元素均大于基准值,然后左右序列重复该过程,直到所有元素都排列在相应的位置上为止
快速排序递归实现与二叉树的前序遍历规则类似,需要注意的是如何按照基准值来对区间中数据进行划分,常见的方式有以下几种:
6.1Hoare版本
单趟排序:选定一个基准值key,一般情况下为第一个或最后一个元素,设置两个变量left和right分别指向数据元素集合的头和尾,left向后找大数,right向前找小数,找到则交换,直到二者相遇,将相遇位置的数与key交换。
单趟排序结束后,数据元素的排列为:小数 key 大数,其中小(大)数是指小(大)于key的数。key的位置已经确定,不需要再更改,分割出了两个子区间,若这两个子区间有序,则整体有序,因此递归对两个子区间进行排序即可使整体有序。
以下为单趟排序的参考代码:
int keyi = left;//选取第一个数作为关键值while (left < right){//right找小数while (left < right && a[right] >= a[keyi]){--right;}//left找大数while(left < right && a[left] <= a[keyi]){++left;}//判断left和right的关系,防止错过if (left < right){Swap(&a[left], &a[right]);}}//left和right相遇,交换相遇位置的值和关键值Swap(&a[left], &a[keyi]);📖Note:
1️⃣与关键值比较大小时,需要注意与关键值相等的特殊情况
对left,找大数,遇到小于key的值时继续向后走;遇到等于key的值时,也应该向后继续寻找,如果不过滤等于key的值,则会产生死循环
当数据元素集合中为单值时,如果不过滤等于的情况,right找小数的循环将会是一个死循环;或者当key == a[right]时,也会陷入死循环
2️⃣当选取第一个数据元素作为key,left与right相遇时,交换相遇位置的数据与key,如何保证相遇的位置比key小?(key是第一个数据元素,属于小数区间)
left和right相遇有两种情况:
- right停下来,left撞到right相遇,相遇位置比key小:right找小数,所以right停下来的位置为小于key的数,即相遇位置为小于key的数,属于小数区间。因此若选取第一个数据元素做key,则right先走
- left停下来,right撞到left相遇,相遇位置比key大:left找大数,所以left停下来的位置为大于key的数,即相遇位置为大于key的数,属于大数区间。因此若选取最后一个数据元素做key,则left先走

// Hoare
int PartSort1(int* a, int left, int right)
{//取第一个数据元素为关键值int keyi = left;while (left < right){// R找小while (left < right && a[right] >= a[keyi]){--right;}// L找大while (left < right && a[left] <= a[keyi]){++left;}if (left < right)Swap(&a[left], &a[right]);}//相遇位置为meetiint meeti = left;Swap(&a[meeti], &a[keyi]);return meeti;
}快速排序的优化:主要是对关键值key选取的优化
key的选择有三种方法:
- 随机选key
- 针对有序序列,先key为最中间位置的数据
- 三数取中:即第一个元素,中间位置元素,最后一个位置元素三数取中位数
三数取中的函数接口如下:
int GetMidIndex(int* a, int left, int right) {int mid = left + (right - left) / 2;if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[left] > a[right]){return left;}else{return right;}}// a[left] >= a[mid]else{if (a[mid] > a[right]){return mid;}else if (a[left] < a[right]){return left;}else{return right;}} }对key的选择优化之后,可以减少递归的层数,有效避免栈溢出
关键值key的选择优化之后,Hoare版本的单趟排序可以优化:通过三数取中的方法确定关键值key后,将key与第一个数据交换,此时关键值key仍为第一个数据,因此其他地方不需要修改
// Hoare
int PartSort1(int* a, int left, int right)
{// 三数取中int mid = GetMidIndex(a, left, right);Swap(&a[left], &a[mid]);int keyi = left;while (left < right){// R找小while (left < right && a[right] >= a[keyi]){--right;}// L找大while (left < right && a[left] <= a[keyi]){++left;}if (left < right)Swap(&a[left], &a[right]);}//相遇位置为meetiint meeti = left;Swap(&a[meeti], &a[keyi]);return meeti;
}6.2挖坑法
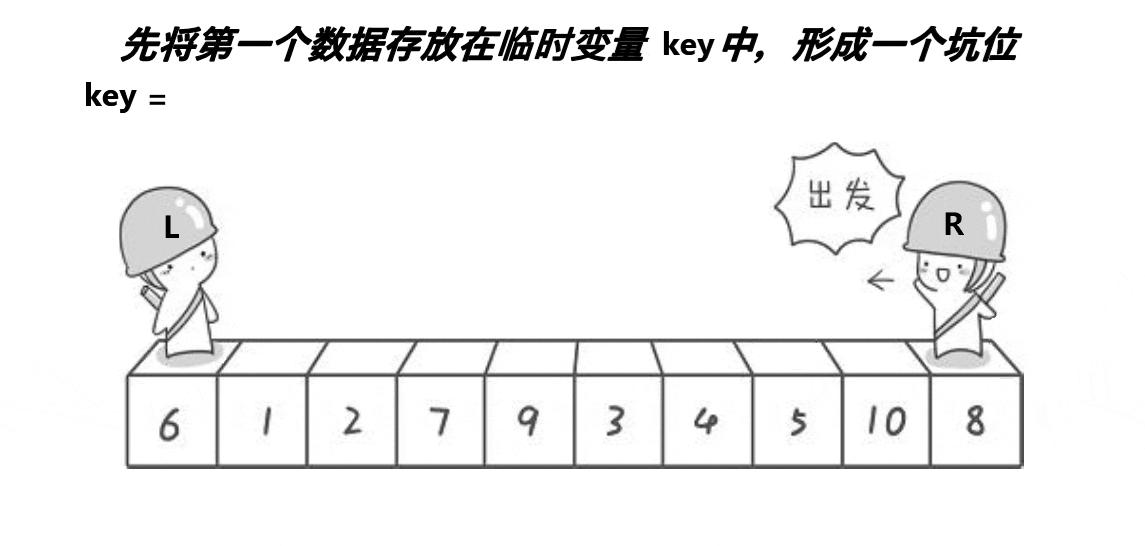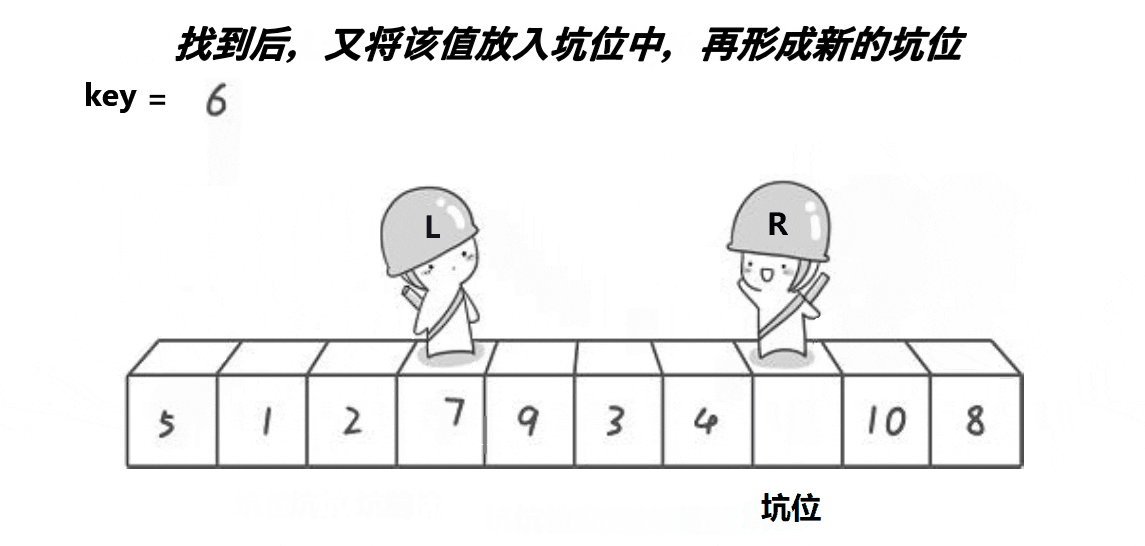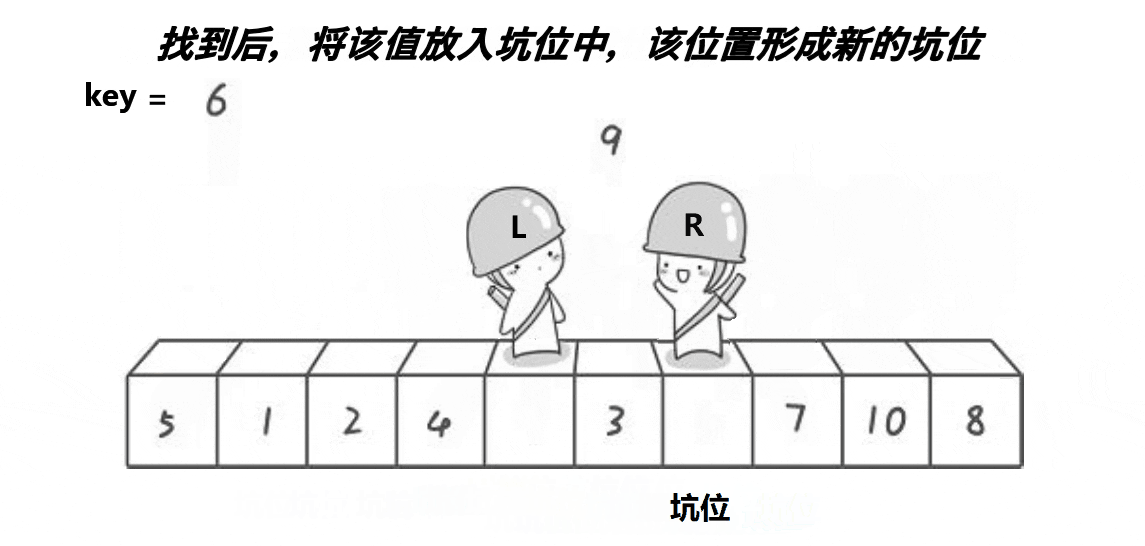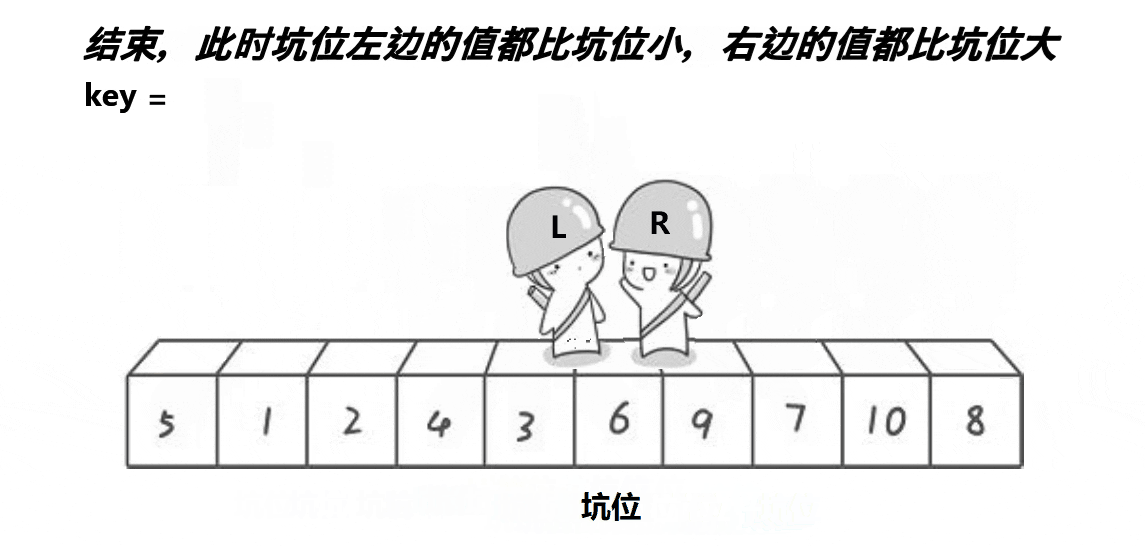
挖坑法是对Hoare版本的改进,确定关键值key之后,将其备份,并将其作为一个坑位(数据集合中的第一个元素),right先走找小数,找到则将该小数填到坑位中,并更新该小数的位置为新的坑位,left再走找大数,找到后将该大数填到坑位中,并更新该大数的位置为新的坑位,重复上述操作,直到left和right相遇,相遇位置为一个坑位,填入关键值key
具体过程如下图所示;
// 挖坑法
int PartSort2(int* a, int left, int right)
{// 三数取中int mid = GetMidIndex(a, left, right);Swap(&a[left], &a[mid]);int key = a[left];int hole = left;while (left < right){// 右边找小,填到左边坑while (left < right && a[right] >= key){--right;}a[hole] = a[right];hole = right;// 左边找大,填到右边坑while (left < right && a[left] <= key){++left;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}6.3前后指针法
前后指针法也是对Hoare版本的改进,确定关键值key(数据元素集合的第一个元素)并备份,设置两个指针,prev和cur,prev初始化为第一个数据元素,cur初始化为prev的下一个数据元素,当cur没有越界时,cur向后找小数,找到则交换prev指向的数据和cur指向的元素,prev++,cur++,重复上述操作,直到cur越界时,交换prev指向的数据元素和关键值key
📖Note:prev++的操作在交换操作之前,cur++的操作在交换操作之后
在cur找到小数时,prev指向的也为小数,其下一个位置为大数,所以prev需要先加1再交换
具体过程如下图所示:
特殊情况:++prev == cur时,会产生自己和自己交换的情况,因此需要过滤

// 前后指针法
int PartSort3(int* a, int left, int right)
{// 三数取中int mid = GetMidIndex(a, left, right);Swap(&a[left], &a[mid]);int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){// cur找小if (a[cur] < a[keyi] && ++prev != cur)Swap(&a[cur], &a[prev]);++cur;}Swap(&a[keyi], &a[prev]);return prev;
}6.4快速排序的递归实现
快速排序的递归实现:
单趟排序结束后,数据元素的排列为:小数 key 大数
小数区间为[begin ,keyi -1],大数区间为[keyi+1,end]
按照单趟排序的方法递归对这两个区间排序即可
递归结束的条件:区间中只有一个值时递归调用结束,begin==end;或者begin>end,区间无效时递归调用结束
//快速排序
void QuickSort(int* a, int begin, int end)
{if (begin >= end){return;}//每趟排序区间的划分:Hoare,挖坑法,前后指针法//调用相应接口即可int keyi = PartSort1(a, begin, end);QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}6.5快速排序的非递归实现
函数的调用需要在开辟栈帧,如果递归调用的层数太深,可能会造成栈溢出
我们可以借助数据结构中的栈来优化快速排序,数据结构中的栈是在堆区开辟空间,堆区的空间要远远大于栈区空间
实际上,快速排序的非递归是借助数据结构中的栈模拟递归的过程
非递归实现思路:每次将区间的左右区间压栈,当栈不为空时,取栈顶两个元素分别作为一趟排序的区间的左右端点进行排序
📖Note:
如果先定义right,则需要区间左端点begin要先入栈,区间右端点end后入栈,这样才能保证right被区间右端点赋值,left被区间左端点赋值
//快速排序的非递归实现
void QuickSortNonR(int* a, int begin, int end)
{ST st;StackInit(&st);StackPush(&st, begin);StackPush(&st, end);while (!StackEmpty(&st)){//区间右端点int right = StackTop(&st);StackPop(&st);//区间左端点int left = StackTop(&st);StackPop(&st);//区间划分,单趟排序int keyi = PartSort3(a, left, right);//右区间if (keyi + 1 < right){StackPush(&st, keyi + 1);StackPush(&st, right);}//左区间if (left < keyi - 1){StackPush(&st, left);StackPush(&st, keyi - 1);}}StackDestroy(&st);
}7.归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的典型应用。将已经有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序,若将两个有序表合并成一个有序表,称为二路归并。
二路归并排序的步骤如下图:
由如下动态图,可以更好的理解二路归并排序的过程
归并排序的递归实现类似于二叉树的后续遍历,采用二叉树的后续遍历框架,递归结束的条件是begin>=end;区间的划分为 [begin, mid] 和 [mid+1, end],mid为中间位置
归并排序的时间复杂度和空间复杂度:
归并排序需要额外开辟一个长度为N的数组,因此其空间复杂度为O(N)
归并排序的时间复杂度为O(N*logN)


void _MergeSort(int* a, int begin, int end, int* tmp)
{if (begin >= end)return;int mid = (end + begin) / 2;_MergeSort(a, begin, mid, tmp);_MergeSort(a, mid + 1, end, tmp);// 两两归并成有序序列:取小的尾插// [begin, mid] [mid+1, end]int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}//左区间中还有数据while (begin1 <= end1){tmp[i++] = a[begin1++];}//右区间中还有数据while (begin2 <= end2){tmp[i++] = a[begin2++];}// 拷贝回原数组:归并哪部分就拷贝哪部分回去memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}_MergeSort(a, 0, n - 1, tmp);free(tmp);tmp = NULL;
}8.计数排序(非比较排序)
计数排序又称为鸽巢原理,是对哈希定址法的直接应用
计数排序的操作步骤:
- 统计相同元素出现的次数
- 根据统计的结果将序列回收到原来的序列中
📖Note:
计数排序中的相对映射:
1.统计个数,得到个数记录数组C
2.将数组C转换成C[i]中存放的是值小于等于i的数据的个数
3.为A数组从前向后的每个元素找到对应的B中的位置,每次从A中复制一个元素到B中,C中相应的计数减一
4.当A中的所有数据都复制到B之后,B中存放的就是有序的数据
总结:计数排序在数据范围集中时,效率很高,但其适用范围有限




void CountSort(int* a, int n)
{int max = a[0], min = a[0];for (int i = 1; i < n; i++){if (a[i] > max){max = a[i];}if (a[i] < min){min = a[i];}}int range = max - min + 1;//统计计数int* countA = (int*)malloc(sizeof(int) * range);if (countA == NULL){perror("malloc fail");return;}memset(countA, 0, sizeof(int) * range);for (int i = 0; i < n; i++){countA[a[i] - min]++;//映射的相对位置}//排序int j = 0;for (int i = 0; i < range; i++){while (countA[i]--){a[j] = i + min;j++;}}
}9.补充:基数排序
基数排序也属于非比较排序
基数排序的操作步骤:
- 分发数据
- 回收数据
多关键字排序有两种方式:MSD(最高位优先)和LSD(最低位优先)
基数排序的步骤如下图:



10.总结:排序算法的复杂度及稳定性分析
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,a[i] = a[j],且a[i] 在 a[j]之前,而在排序后的序列中,a[i] 仍在 a[j]之前,则称这种排序算法是稳定的,否则称之为不稳定的
1️⃣直接插入排序:稳定
关键码相同则不调整,继续向后排序
2️⃣希尔排序:不稳定
预排序时,相同的数据可能分到不同的组,不能保证稳定性
3️⃣选择排序:不稳定
4️⃣堆排序:不稳定
当一个堆为单值时,向下调整会影响该值的稳定性,因此堆排序不稳定
5️⃣冒泡排序:稳定
关键码相同则不调整,继续向后排序
6️⃣快速排序:不稳定
7️⃣归并排序:稳定
关键码相同则不调整,继续向后排序
时间复杂度与空间复杂度总结:
算法 平均情况 最好情况 最坏情况 辅助空间 稳定性 冒泡排序 O(N^2) O(N) O(N^2) O(1) 稳定 简单选择排序 O(N^2) O(N^2) O(N^2) O(1) 不稳定 直接插入排序 O(N^2) O(N) O(N^2) O(1) 稳定 希尔排序 O(N*logN)~O(N^2) O(N^1.3) O(N^2) O(1) 不稳定 堆排序 O(N*logN) O(N*logN) O(N*logN) O(1) 不稳定 归并排序 O(N*logN) O(N*logN) O(N*logN) O(N) 稳定 快速排序 O(N*logN) O(N*logN) O(N^2) O(logN)~O(N) 不稳定
相关文章:
【数据结构】常见八大排序算法总结
目录 前言 1.直接插入排序 2.希尔排序 3.选择排序 4.堆排序 5.冒泡排序 6.快速排序 6.1Hoare版本 6.2挖坑法 6.3前后指针法 6.4快速排序的递归实现 6.5快速排序的非递归实现 7.归并排序 8.计数排序(非比较排序) 9.补充:基数排序 10.总结…...

系统学英语 — 句法 — 常规句型
目录 文章目录 目录5 大基本句型复合句型主语从句宾语从句表语从句定语从句状语从句同位语从句补语从句 谓语句型 5 大基本句型 主谓:主语发出一个动作,例如:He cried.主谓宾:we study English.主系表:主语具有某些特…...
Github操作网络异常笔记
Github操作网络异常笔记 1. 源由2. 解决2.1 方案一2.2 方案二 3. 总结 1. 源由 开源技术在国内永远是“蛋疼”,这些"政治"问题对于追求技术的我们,形成无法回避的障碍。 $ git pull ssh: connect to host github.com port 22: Connection ti…...
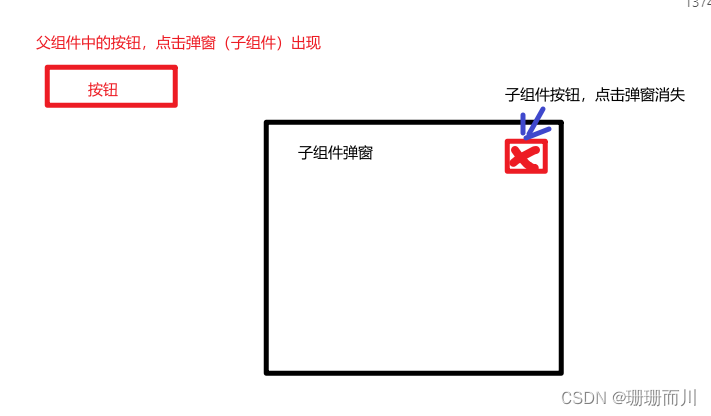
Vue3新特性defineModel()便捷的双向绑定数据
官网介绍 传送门 配置 要求: 版本: vue > 3.4(必须!!!)配置:vite.config.js 使用场景和案例 使用场景:父子组件的数据双向绑定,不用emit和props的繁重代码 具体案例 代码实…...

vue列表飞入效果
效果 实现代码 <template><div><button click"add">添加</button><TransitionGroup name"list" tag"ul"><div class"list-item" v-for"item in items" :key"item.id">{{ i…...

C语言·预处理详解
1. 预定义符号 C语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的 __FILE__ 进行编译的源文件 __LINE__ 文件当前的行号 __DATE__ 文件被编译的日期 __TIME__ 文件被编译的时间 __STDC__ 如果编译器遵循ANSI C,…...

服务器与普通电脑的区别,普通电脑可以当作服务器用吗?
服务器在我们日常应用中非常常见,手机APP、手机游戏、PC游戏、小程序、网站等等都需要部署在服务器上,为我们提供各种计算、应用服务。服务器也是计算机的一种,虽然内部结构相差不大,但是服务器的运行速度更快、负载更高、成本更高…...

数字身份所有权:Web3时代用户数据的掌控权
随着Web3时代的来临,数字身份的概念正焕发出崭新的光芒。在这个数字化的时代,用户的个人数据变得愈加珍贵,而Web3则为用户带来了数字身份所有权的概念,重新定义了用户与个人数据之间的关系。本文将深入探讨Web3时代用户数据的掌控…...

python爬虫如何写,有哪些成功爬取的案例
编写Python爬虫时,常用的库包括Requests、Beautiful Soup和Scrapy。以下是三个简单的Python爬虫案例,分别使用Requests和Beautiful Soup,以及Scrapy。 1. 使用Requests和Beautiful Soup爬取网页内容: import requests from bs4 …...

PLC物联网网关BL104实现PLC协议转MQTT、OPC UA、Modbus TCP
随着物联网技术的迅猛发展,人们深刻认识到在智能化生产和生活中,实时、可靠、安全的数据传输至关重要。在此背景下,高性能的物联网数据传输解决方案——协议转换网关应运而生,广泛应用于工业自动化和数字化工厂应用环境中。 无缝衔…...

explain工具优化mysql需要达到什么级别?
explain工具优化mysql需要达到什么级别? 一、explain工具是什么?二、explain查询后各字段的含义三、explain查询后type字段有哪些类型?四、type类型需要优化到哪个阶段? 一、explain工具是什么? explain是什么&#x…...

RHCE作业
架设一台NFS服务器,并按照以下要求配置 1、开放/nfs/shared目录,供所有用户查询资料 2、开放/nfs/upload目录,为192.168.xxx.0/24网段主机可以上传目录,并将所有用户及所属的组映射为nfs-upload,其UID和GID均为210 3、将/home/to…...
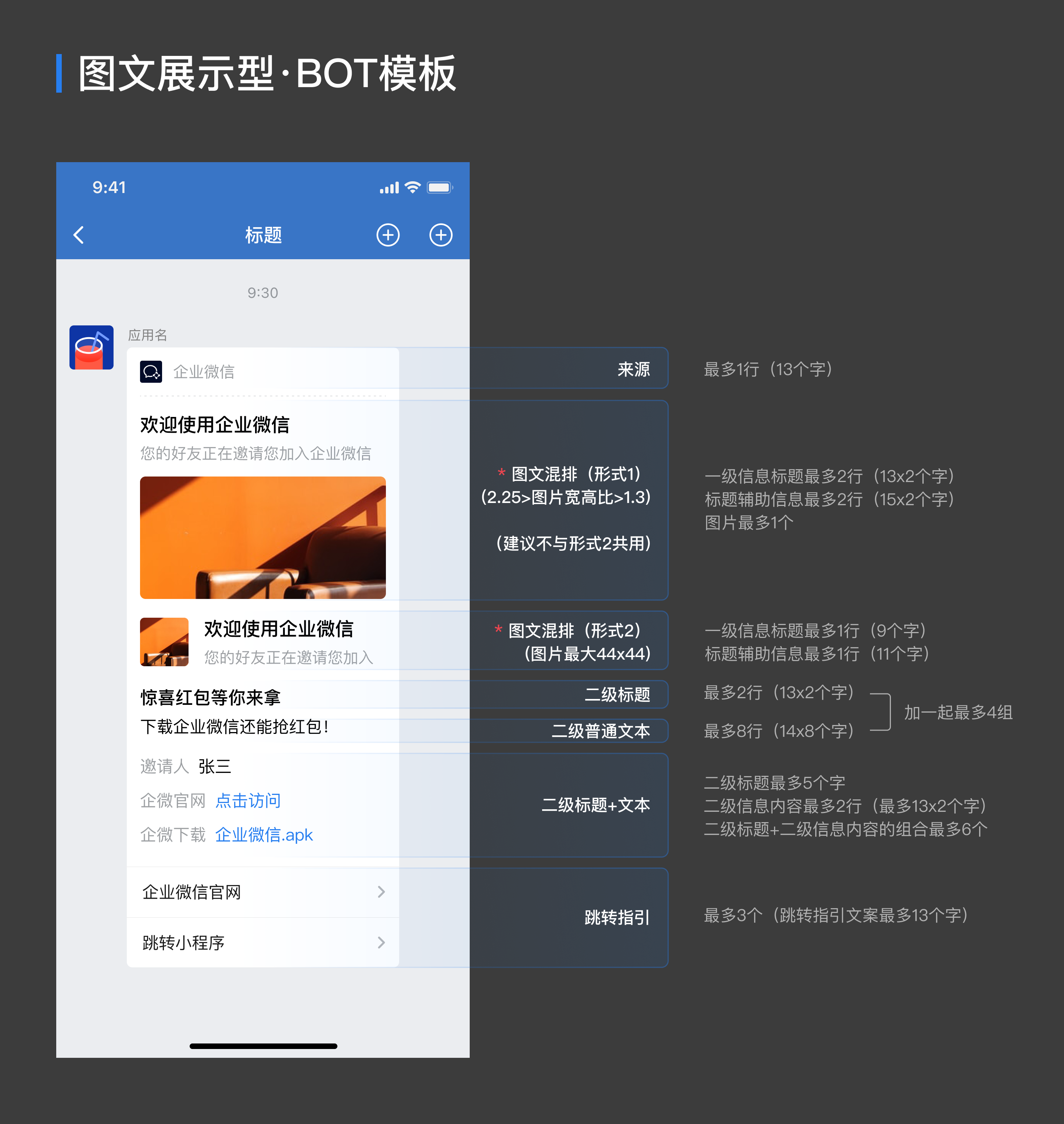
在Java中调企微机器人发送消息到群里
目录 如何使用群机器人 消息类型及数据格式 文本类型 markdown类型 图片类型 图文类型 文件类型 模版卡片类型 文本通知模版卡片 图文展示模版卡片 消息发送频率限制 文件上传接口 Java 执行语句 String url "webhook的Url"; String result HttpReque…...
鸿蒙开发(四)UIAbility和Page交互
通过上一篇的学习,相信大家对UIAbility已经有了初步的认知。在上篇中,我们最后实现了一个小demo,从一个UIAbility调起了另外一个UIAbility。当时我提到过,暂不实现比如点击EntryAbility中的控件去触发跳转,而是在Entry…...
K8s(七)四层代理Service
Service概述 Service在Kubernetes中提供了一种抽象的方式来公开应用程序的网络访问,并提供了负载均衡和服务发现等功能,使得应用程序在集群内外都能够可靠地进行访问。 每个Service都会自动关联一个对应的Endpoint。当创建一个Service时,Ku…...
鼎捷软件获评国家级智能制造“AAA级集成实施+AA级咨询设计”供应商
为贯彻落实《“十四五”智能制造发展规划》,健全智能制造系统解决方案供应商(以下简称“供应商”)分类分级体系,推动供应商规范有序发展,智能制造系统解决方案供应商联盟组织开展了供应商分类分级评定(第一批)工作,旨在遴选一批专…...

(循环依赖问题)学习spring的第九天
Bean实例的属性填充 Spring在属性注入时 , 分为如下几种情况 : 注入单向对象引用 : 如usersevice里注入userdao , userdao里没有注入其他属性 注入双向对象引用 : 如usersevice里注入userdao , userdao也注入usersevice属性 二 . 着重看循环依赖问题 (搞清原理即可) 问题提出…...

Kotlin的数据类
引言 我们在做项目中涉及到各种数据类的处理,很多很杂乱。难免一个人的知识点有盲点,所以想着做个整理。 定义 在平时的使用中,我们会用到一些类来保持一些数据或状态,我们习惯上成为bean或者entity,也有的定义为mod…...

PTA 7-13 统计工龄
给定公司N名员工的工龄,要求按工龄增序输出每个工龄段有多少员工。 输入格式: 输入首先给出正整数N(≤105),即员工总人数;随后给出N个整数,即每个员工的工龄,范围在[0, 50]。 输出格式: 按工…...
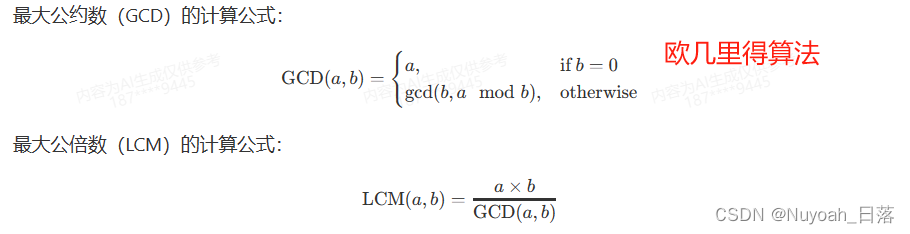
算法常用思路总结
思路 1. 求数组中最大最小值思路代码 2. 计算阶乘思路:代码: 3. 得到数字的每一位思路代码 4. 计算时间类型5. 最大公约数、最小公倍数6. 循环数组的思想题目:猴子选大王代码 补充经典例题1. 复试四则运算题目内容题解 2. 数列求和题目内容题…...

嵌入式GUI性能优化实战:LVGL贝塞尔曲线绘制中的定点数与移位运算避坑指南
嵌入式GUI性能优化实战:LVGL贝塞尔曲线绘制中的定点数与移位运算避坑指南 在嵌入式系统开发中,流畅的图形用户界面(GUI)往往需要面对资源受限的硬件环境。当我们在STM32或ESP32这类微控制器上实现复杂的动画效果时,贝塞尔曲线因其平滑的过渡…...

水文水资源、水生态与水环境领域必修技能暨 ArcGIS Pro全流程实践技术学习及AI融合应用
ArcGIS Pro 是一款集数据采集、处理、分析和可视化于一体的强大 GIS 工具,广泛应用于水文、水资源、水生态和水环境等领域。其全面的功能使得研究人员能够高效地处理各种水文和环境数据,从而为科学研究和决策支持提供强有力的技术保障。在水文分析方面&a…...

零成本获取全球股票数据:AKShare开源金融数据接口完整指南
零成本获取全球股票数据:AKShare开源金融数据接口完整指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/ak…...

一键获取九大网盘真实下载地址:LinkSwift网盘直链下载助手完整指南
一键获取九大网盘真实下载地址:LinkSwift网盘直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...

巡检记录分析不全面,导致安全隐患遗漏频发怎么办?揭秘实在Agent非侵入式提效方案
摘要:在2026年工业4.0与智慧安全深度融合的背景下,许多企业仍面临“巡检记录分析不全面,安全隐患遗漏频发”的顽疾。传统的纸质记录或初级数字化巡检,往往因数据孤岛、老旧系统无API接口、以及AI无法触达内网执行层等问题…...

别再滥用Promise.all了!聊聊Vue/React项目中用p-limit控制并发请求的实战心得
别再滥用Promise.all了!聊聊Vue/React项目中用p-limit控制并发请求的实战心得 在Vue/React项目中处理批量数据请求时,许多开发者会条件反射地使用Promise.all,认为这是最高效的方案。直到某次线上事故——用户尝试导出500条订单数据时浏览器直…...

DepHell与Docker集成:容器化Python应用开发的终极指南
DepHell与Docker集成:容器化Python应用开发的终极指南 【免费下载链接】dephell :package: :fire: Python project management. Manage packages: convert between formats, lock, install, resolve, isolate, test, build graph, show outdated, audit. Manage ven…...

Input Leap终极指南:3步实现跨设备键盘鼠标无缝共享
Input Leap终极指南:3步实现跨设备键盘鼠标无缝共享 【免费下载链接】input-leap Open-source KVM software 项目地址: https://gitcode.com/gh_mirrors/in/input-leap 你是否厌倦了在多台电脑之间频繁切换键盘和鼠标?Input Leap跨设备控制功能正…...
)
用C语言链表实现一个简易图书管理系统(附完整源码)
从零构建C语言链表图书管理系统:工程化实践指南 当你第一次在数据结构课本上看到链表时,是否觉得这些抽象的概念离实际开发很遥远?作为C语言初学者,我完全理解这种困惑——直到亲手用链表实现了一个真正的图书管理系统。本文将带你…...

MaterialSkin 2.0终极指南:3步解锁现代化WinForms界面设计
MaterialSkin 2.0终极指南:3步解锁现代化WinForms界面设计 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin 还在为传统WinForms应…...