Python爬虫---scrapy框架---当当网管道封装
项目结构:
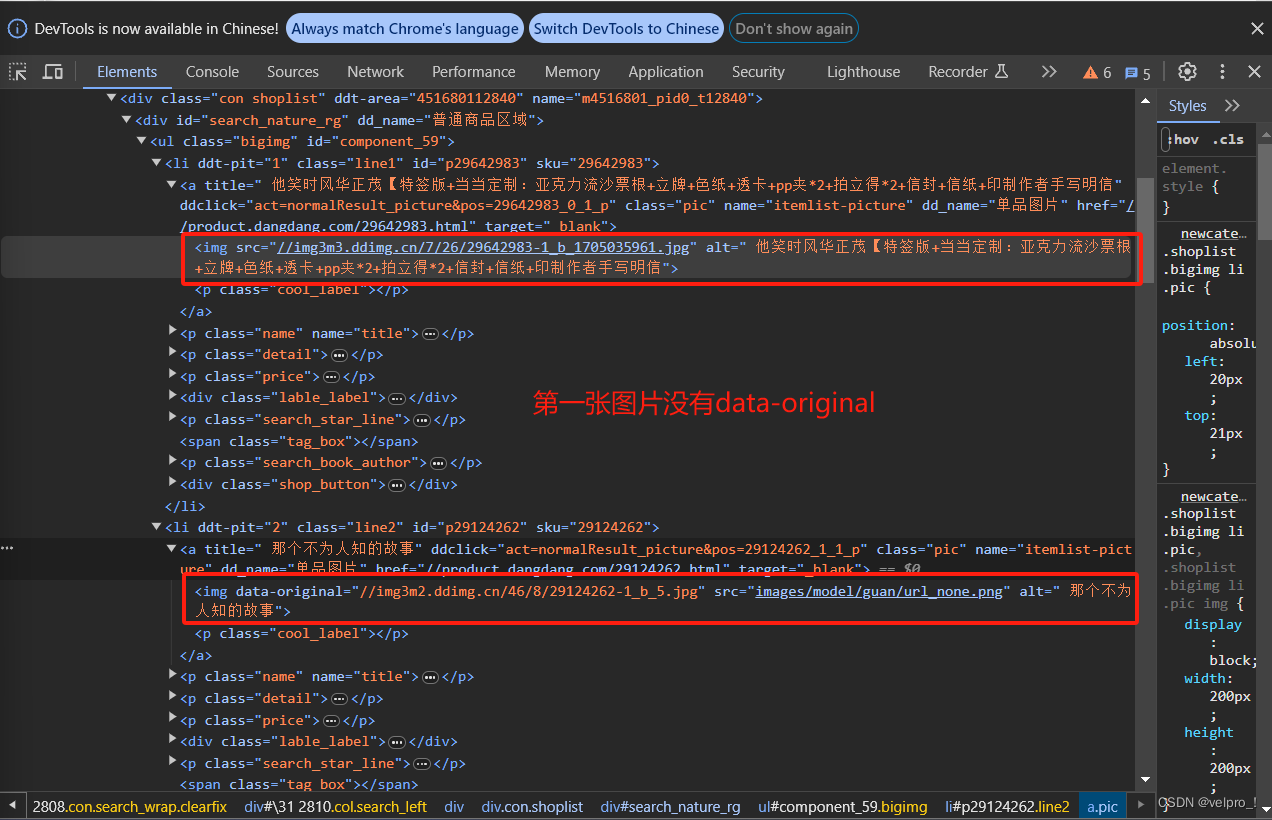
dang.py文件:自己创建,实现爬虫核心功能的文件
import scrapy
from scrapy_dangdang_20240113.items import ScrapyDangdang20240113Itemclass DangSpider(scrapy.Spider):name = "dang" # 名字# 如果是多页下载的话, 那么必须要调整的是allowed_domains的范围 一般情况下只写城名# allowed_domains = ["https://category.dangdang.com/cp01.01.00.00.00.00.html"]allowed_domains = ["category.dangdang.com"]start_urls = ["https://category.dangdang.com/cp01.01.00.00.00.00.html"]# 第1页:"https://category.dangdang.com/cp01.01.00.00.00.00.html"# 第2页: "https://category.dangdang.com/pg2-cp01.01.00.00.00.00.html"# 第3页: "https://category.dangdang.com/pg3-cp01.01.00.00.00.00.html"base_url = "https://category.dangdang.com/pg"page = 1def parse(self, response):print("========================================================================")# pipelines: 下载数据# items: 定义数据结构# xpath语法# src = //ul[@id='component_59']/li/a/img/@src# 除了第一张,其他做了懒加载 所以不能使用src,要使用这个data-original# src = //ul[@id='component_59']/li/a/img/@data-original# alt = //ul[@id='component_59']/li/a/img/@alt# price = //ul[@id='component_59']/li/p[@class='price']/span[1]/text()# 所有的seletor的对象都可以再次调用xpath语法li_list = response.xpath("//ul[@id='component_59']/li")for li in li_list:src = li.xpath(".//img/@data-original").extract_first()if src:src = srcelse:src = li.xpath(".//img/@src").extract_first()name = li.xpath(".//img/@alt").extract_first()price = li.xpath(".//p[@class='price']/span[1]/text()").extract_first()print(src, name, price)# 将爬取的数据放在对象里book = ScrapyDangdang20240113Item(src=src, name=name, price=price)# 获取一个book将book交给pipelines,将对象放在管道里yield book# 每一页的爬取业务的逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用if self.page < 100:self.page = self.page + 1url = self.base_url + str(self.page) + "-cp01.01.00.00.00.00.html"# 调用parse万法# scrapy.Request就是scrpay的get请求 url就是请求地址# callback是你要执行的那个函数注意不需要加()yield scrapy.Request(url=url, callback=self.parse)items文件:定义数据结构的地方
import scrapyclass ScrapyDangdang20240113Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 通俗的说就是你要下载的数据都有什么src = scrapy.Field()name = scrapy.Field()price = scrapy.Field()settings文件:配置文件,例如开启管道
# 开启管道
ITEM_PIPELINES = {# 管道可以有很多个,那么管道是有优先级的,优先级的范围是1到1000,值越小优先级越高"scrapy_dangdang_20240113.pipelines.ScrapyDangdang20240113Pipeline": 300,"scrapy_dangdang_20240113.pipelines.DangdangDownloadPipeline": 301,
}pipelines.py文件:管道文件,里面只有一个类,用于处理下载数据的,值越小优先级越高
# 下载数据# 如果想使用管道的话 那么就必须在settings中开启管道
class ScrapyDangdang20240113Pipeline:# item就是yield后面的book对象# 方式一:# 以下这种模式不推荐,因为每传递过来一个对象,那么就打开一次文件,对文件的作过于频繁# def process_item(self, item, spider):# (1)write万法必须要写一个字符串,而不能是其他的对象,使用str()强转# (2)w模式 会每一个对象都打开一次文件 覆盖之前的内容# with open("book.json","a",encoding="utf-8")as fp:# fp.write(str(item))# return item# 方式二:# 在爬虫文件开始之前就执行的方法def open_spider(self, spider):print("++++++++++++++++++++++++++++++++++++++++++++++++++")self.fp = open("book.json", "w", encoding="utf-8")def process_item(self, item, spider):self.fp.write(str(item))return item# 在爬虫文件开始之后就执行的方法def close_spider(self, spider):print("----------------------------------------------------")self.fp.close()# 多条管道同时开启
# (1)定义管道类
# (2)在settings中开启管道
import urllib.request
class DangdangDownloadPipeline:def process_item(self, item, spider):# 下载图片url = "https:" + item.get("src")filename = "./books/" + item.get("name")[0:6] + ".jpg"urllib.request.urlretrieve(url=url, filename=filename)return item相关文章:
Python爬虫---scrapy框架---当当网管道封装
项目结构: dang.py文件:自己创建,实现爬虫核心功能的文件 import scrapy from scrapy_dangdang_20240113.items import ScrapyDangdang20240113Itemclass DangSpider(scrapy.Spider):name "dang" # 名字# 如果是多页下载的话, …...

【机器学习】机器学习四大类第01课
一、机器学习四大类 有监督学习 (Supervised Learning) 有监督学习是通过已知的输入-输出对(即标记过的训练数据)来学习函数关系的过程。在训练阶段,模型会根据这些示例调整参数以尽可能准确地预测新的、未见过的数据点的输出。 实例&#x…...

下述默认构造函数有什么问题?
12.4 // points to string allocated by new // holds length of string 独立的、相同的数据,而不会重叠。由于同样的原因,必须定义赋值操作符。对于每一种情况,最终目的 都是执行深度复制,也就是说,复制实际的数据,而不仅仅是复制指向数据的指针。 对象的存储持续性为自动或…...

vite和mockjs配合使用
vite mockjs 当后端还没准备完成之前,前端可以使用 mock 模拟后端响应,提高开发效率 1、安装插件 使用 vite-plugin-mock 插件,配合mockjs完成项目的 mock 配置 npm install mockjs vite-plugin-mock2、vite配置插件 在 vite.config.js…...
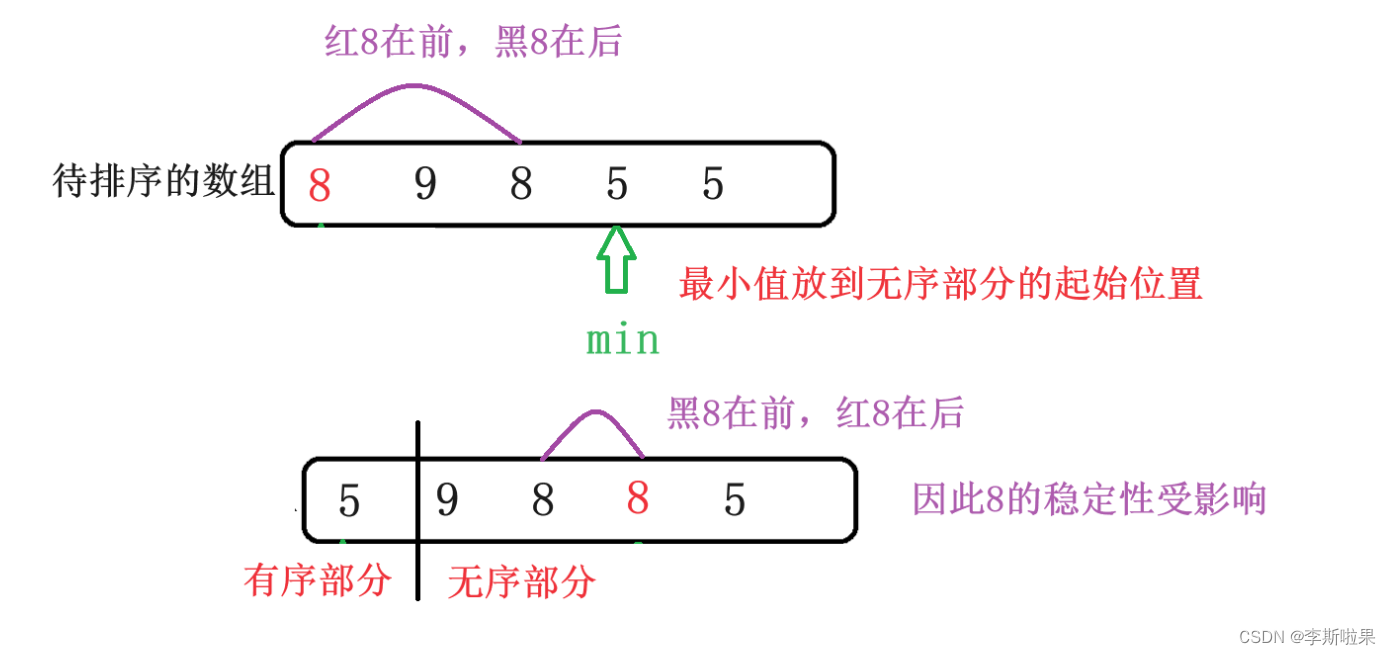
【数据结构】常见八大排序算法总结
目录 前言 1.直接插入排序 2.希尔排序 3.选择排序 4.堆排序 5.冒泡排序 6.快速排序 6.1Hoare版本 6.2挖坑法 6.3前后指针法 6.4快速排序的递归实现 6.5快速排序的非递归实现 7.归并排序 8.计数排序(非比较排序) 9.补充:基数排序 10.总结…...

系统学英语 — 句法 — 常规句型
目录 文章目录 目录5 大基本句型复合句型主语从句宾语从句表语从句定语从句状语从句同位语从句补语从句 谓语句型 5 大基本句型 主谓:主语发出一个动作,例如:He cried.主谓宾:we study English.主系表:主语具有某些特…...
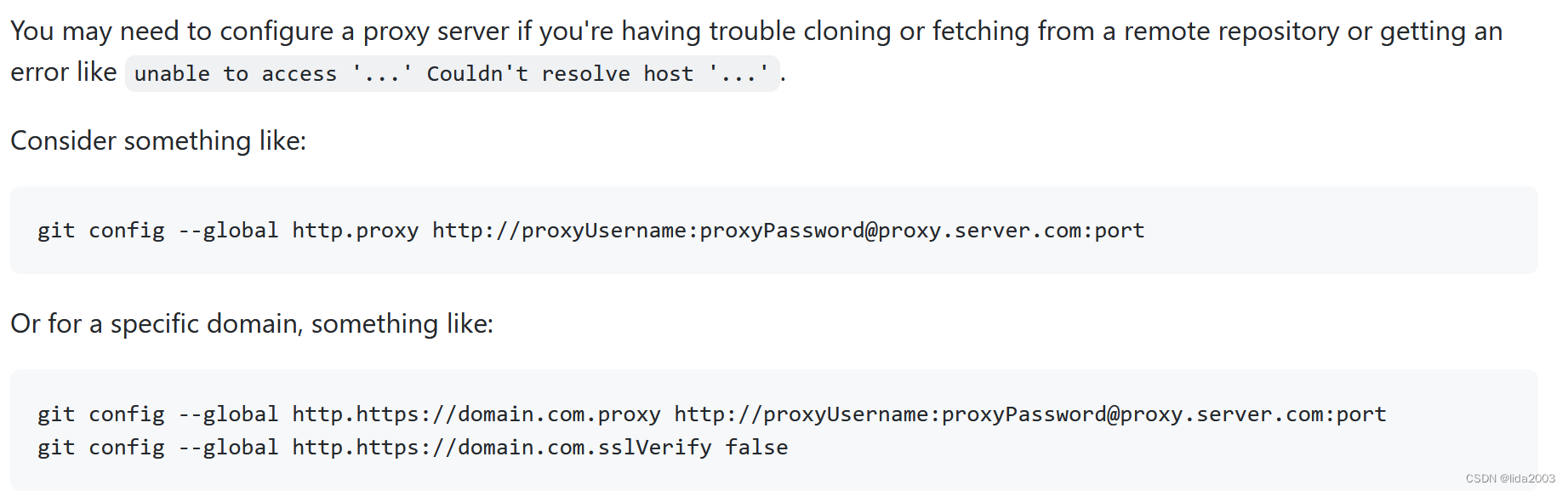
Github操作网络异常笔记
Github操作网络异常笔记 1. 源由2. 解决2.1 方案一2.2 方案二 3. 总结 1. 源由 开源技术在国内永远是“蛋疼”,这些"政治"问题对于追求技术的我们,形成无法回避的障碍。 $ git pull ssh: connect to host github.com port 22: Connection ti…...
Vue3新特性defineModel()便捷的双向绑定数据
官网介绍 传送门 配置 要求: 版本: vue > 3.4(必须!!!)配置:vite.config.js 使用场景和案例 使用场景:父子组件的数据双向绑定,不用emit和props的繁重代码 具体案例 代码实…...

vue列表飞入效果
效果 实现代码 <template><div><button click"add">添加</button><TransitionGroup name"list" tag"ul"><div class"list-item" v-for"item in items" :key"item.id">{{ i…...

C语言·预处理详解
1. 预定义符号 C语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的 __FILE__ 进行编译的源文件 __LINE__ 文件当前的行号 __DATE__ 文件被编译的日期 __TIME__ 文件被编译的时间 __STDC__ 如果编译器遵循ANSI C,…...

服务器与普通电脑的区别,普通电脑可以当作服务器用吗?
服务器在我们日常应用中非常常见,手机APP、手机游戏、PC游戏、小程序、网站等等都需要部署在服务器上,为我们提供各种计算、应用服务。服务器也是计算机的一种,虽然内部结构相差不大,但是服务器的运行速度更快、负载更高、成本更高…...

数字身份所有权:Web3时代用户数据的掌控权
随着Web3时代的来临,数字身份的概念正焕发出崭新的光芒。在这个数字化的时代,用户的个人数据变得愈加珍贵,而Web3则为用户带来了数字身份所有权的概念,重新定义了用户与个人数据之间的关系。本文将深入探讨Web3时代用户数据的掌控…...

python爬虫如何写,有哪些成功爬取的案例
编写Python爬虫时,常用的库包括Requests、Beautiful Soup和Scrapy。以下是三个简单的Python爬虫案例,分别使用Requests和Beautiful Soup,以及Scrapy。 1. 使用Requests和Beautiful Soup爬取网页内容: import requests from bs4 …...

PLC物联网网关BL104实现PLC协议转MQTT、OPC UA、Modbus TCP
随着物联网技术的迅猛发展,人们深刻认识到在智能化生产和生活中,实时、可靠、安全的数据传输至关重要。在此背景下,高性能的物联网数据传输解决方案——协议转换网关应运而生,广泛应用于工业自动化和数字化工厂应用环境中。 无缝衔…...

explain工具优化mysql需要达到什么级别?
explain工具优化mysql需要达到什么级别? 一、explain工具是什么?二、explain查询后各字段的含义三、explain查询后type字段有哪些类型?四、type类型需要优化到哪个阶段? 一、explain工具是什么? explain是什么&#x…...

RHCE作业
架设一台NFS服务器,并按照以下要求配置 1、开放/nfs/shared目录,供所有用户查询资料 2、开放/nfs/upload目录,为192.168.xxx.0/24网段主机可以上传目录,并将所有用户及所属的组映射为nfs-upload,其UID和GID均为210 3、将/home/to…...
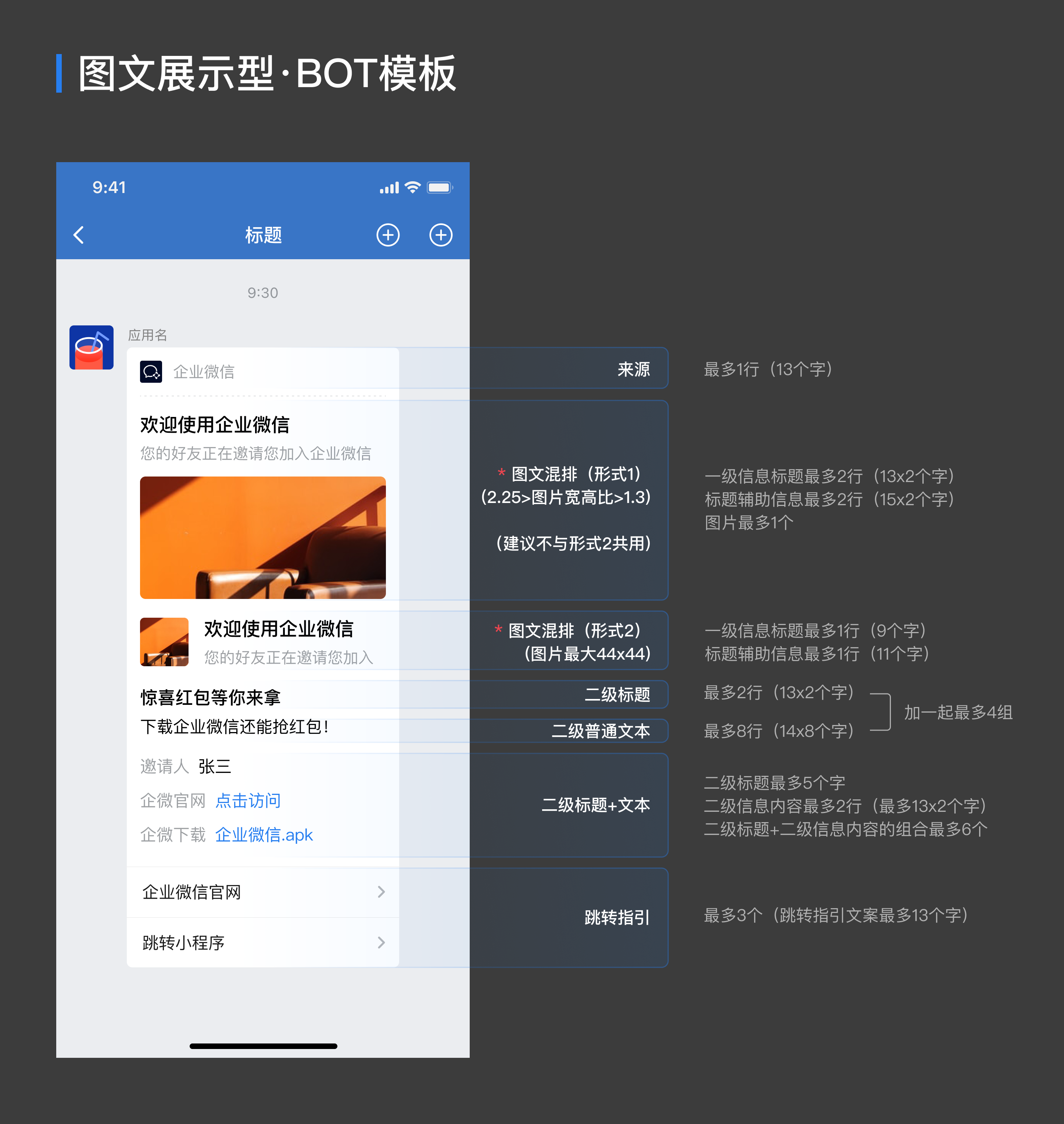
在Java中调企微机器人发送消息到群里
目录 如何使用群机器人 消息类型及数据格式 文本类型 markdown类型 图片类型 图文类型 文件类型 模版卡片类型 文本通知模版卡片 图文展示模版卡片 消息发送频率限制 文件上传接口 Java 执行语句 String url "webhook的Url"; String result HttpReque…...
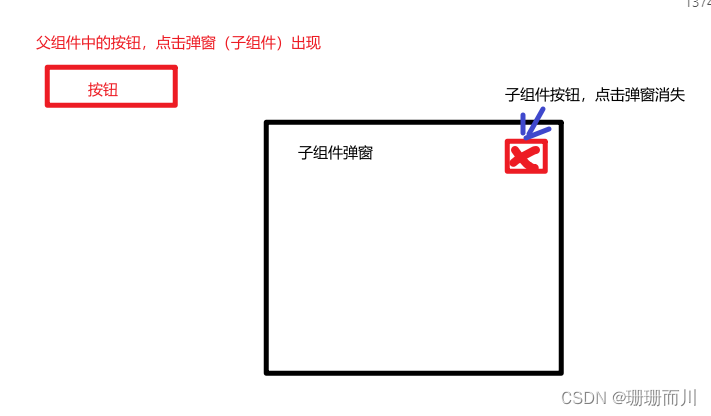
鸿蒙开发(四)UIAbility和Page交互
通过上一篇的学习,相信大家对UIAbility已经有了初步的认知。在上篇中,我们最后实现了一个小demo,从一个UIAbility调起了另外一个UIAbility。当时我提到过,暂不实现比如点击EntryAbility中的控件去触发跳转,而是在Entry…...
K8s(七)四层代理Service
Service概述 Service在Kubernetes中提供了一种抽象的方式来公开应用程序的网络访问,并提供了负载均衡和服务发现等功能,使得应用程序在集群内外都能够可靠地进行访问。 每个Service都会自动关联一个对应的Endpoint。当创建一个Service时,Ku…...
鼎捷软件获评国家级智能制造“AAA级集成实施+AA级咨询设计”供应商
为贯彻落实《“十四五”智能制造发展规划》,健全智能制造系统解决方案供应商(以下简称“供应商”)分类分级体系,推动供应商规范有序发展,智能制造系统解决方案供应商联盟组织开展了供应商分类分级评定(第一批)工作,旨在遴选一批专…...
)
从74LS00与非门到74LS86异或门:手把手教你用面包板搭建数字电路基础实验(附波形分析)
从74LS00与非门到74LS86异或门:面包板上的数字电路实战指南 在电子技术的浩瀚海洋中,数字电路犹如一座连接现实与虚拟的桥梁。对于初学者而言,从理论到实践的跨越往往充满挑战——实验室里昂贵的设备、复杂的接线、固定的实验流程,…...

CANN/asc-devkit SIMD排序函数文档
Sort 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...

Intel 14代酷睿接口更迭:技术推演与用户决策指南
1. 项目概述:一次关于“接口更迭”的深度技术推演最近,关于下一代酷睿处理器的传闻又开始在圈内流传,一个核心的焦点再次被推上风口浪尖:Intel 14代酷睿(Raptor Lake Refresh)可能又要更换CPU插槽接口了。这…...

GPT-4高考全真模拟测试:能力边界、技术原理与教育启示
1. 项目缘起与核心目标最近,我身边不少朋友,尤其是家里有考生的,都在讨论一个话题:现在这些大语言模型,比如GPT-4,到底有多“聪明”?它能不能像人一样思考,甚至去参加我们的高考&…...

如何在5分钟内为MASA模组全家桶安装中文汉化包:实用指南
如何在5分钟内为MASA模组全家桶安装中文汉化包:实用指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft中MASA模组的英文界面而烦恼吗?MASA模组…...

从零构建:基于YOLOv8/YOLOv10的智能游戏瞄准系统深度解析
从零构建:基于YOLOv8/YOLOv10的智能游戏瞄准系统深度解析 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot 你是否曾经好奇,人工智能技术如何精准识别游戏中的…...

避开FPGA除法器设计的那些‘坑’:恢复余数 vs. 不恢复余数 vs. SRT 实战选型指南
FPGA除法器设计实战:恢复余数、不恢复余数与SRT算法选型指南 在数字信号处理、图形渲染或科学计算等FPGA应用中,除法运算往往是性能瓶颈所在。不同于乘法器可通过流水线大幅提速,除法器的设计需要工程师在算法选择阶段就做出关键决策——恢复…...
的血泪史与终极方案)
树莓派3B上跑通Apriltag识别:老设备配置Python环境(OpenCV+pupil_apriltags)的血泪史与终极方案
树莓派3B上跑通Apriltag识别:老设备配置Python环境(OpenCVpupil_apriltags)的血泪史与终极方案 当你在二手市场淘到一台树莓派3B,满心欢喜地想用它搭建一个视觉导航机器人时,现实往往会给你当头一棒。这款2016年发布的…...

手把手改造libmad:将一次性加载改为流式解码,拯救你的内存不足嵌入式系统
嵌入式音频革命:libmad流式解码改造实战指南 在资源受限的嵌入式环境中处理MP3音频,就像试图用吸管喝光整个游泳池的水——传统的一次性加载方式会让你的系统瞬间窒息。当树莓派Pico这类微控制器只有264KB的RAM时,一个5MB的MP3文件就能让内存…...

FanControl终极指南:5步实现Windows风扇精准控制与静音优化
FanControl终极指南:5步实现Windows风扇精准控制与静音优化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendi…...