cuda二进制文件中到底有些什么
大家好。今天我们来讨论一下,相比gcc编译器编译的二进制elf文件,包含有 cuda kernel 的源文件编译出来的 elf 文件有什么不同呢?
之前研究过一点 tvm。从 BYOC 的框架中可以得知,前端将模型 partition 成 host 和 accel(accel 表示后端,比如加速卡,NPU或者其他AI加速模块) 两部分,对 accel 部分,会切分成多个 regions,对应到多个子图,这部分每一个 regions 会被封装成一个独立的 function 进行处理,这些 function 都带有 annotation,附带硬件相关的标签信息,能知道由哪个 accel 后端来处理,在 host 侧对这些函数的处理,仅仅是简单的封装成对一个外部函数的调用,而实际的编译是由 accel-specific 的编译器来编译和 codegen 的。而每一个 sub-graph 会编译成一个 sub-module,最终与 host sub-module 一起封装成一个 heterogenous blob。
而 nvcc 应该也是类似的道理。
在 《Cuda Compiler Driver NVCC.pdf》中,有这么一段介绍
Dispatching GPU jobs by the host process is supported by the CUDA Toolkit in the form of remote procedure calling. The GPU code is implemented as a collection of functions in a language that is essentially C, but with some annotations for distinguishing them from the host code, plus annotations for distinguishing different types of data memory that exists on the GPU. Such functions may have parameters, and they can be called using a syntax that is very similar to regular C function calling, but slightly extended for being able to specify the matrix of GPU threads that must execute the called function. During its life time, the host process may dispatch many parallel GPU tasks.
大致意思就是说,CUDA ToolKit 可以支持主机端程序通过 RPC 的方式调度 GPU 任务。GPU 代码与 C 代码类似,但是带有一些额外的 annotations 信息来做区分。而GPU 代码实现的函数的调用也与传统 c 函数调用相同。
直接来编译一个 helloword 程序
/*
*hello_world.cu
*/
#include<stdio.h>
__global__ void hello_world(void)
{printf("GPU: Hello world!\n");
}
int main(int argc,char **argv)
{printf("CPU: Hello world!\n");hello_world<<<1,10>>>();cudaDeviceReset();//if no this line ,it can not output hello world from gpureturn 0;
}
编译
nvcc --cudart shared -o device helloworld.cu --verbose
使用 --cudart shared 而不使用静态链接的方式,是为了不将 libcudart.a 链接到二进制文件中,使得目标程序大小偏大。
objdump -ds device
观察 hello_world 函数

可以看到,本质上是一个函数调用,对 _Z30__device_stub__Z11hello_worldvv 函数的一个调用。
推测: 对 device 设备端的函数,也是封装成一个 external function 的函数调用,而该函数实际是通过 device设备端(也就是GPU) 的code gen 来生成的,最终会将其合并成一个二进制文件。而在编写 cuda 代码的过程中,所使用的这些 c++ 扩展,就类似于 annotation 的作用,注明了这属于 device 设备端的代码。
compile process
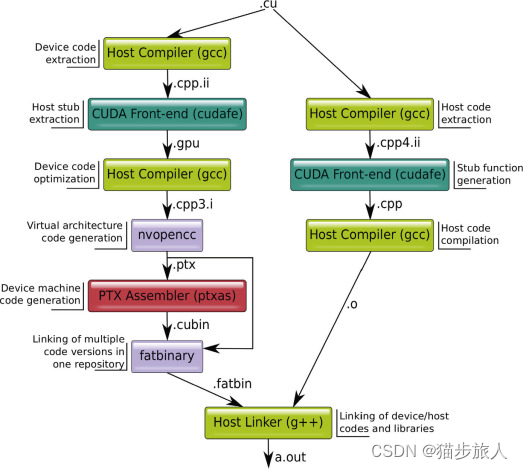
a CUDA executable can exist in two forms:
- a binary one that can only target specific devices and an intermediate assembly one that can target any device by JIT compilation.
- a PTX Assembler (ptxas) performs the compilation during execution time, adding a start-up overhead, at least during the first invocation of a kernel.
cuda 可执行文件可以有两种形式,一种是针对特定设备的二进制文件和一种中间表示的汇编形式,可以通过 JIT 的方式运行与任何设备上。JIT 也就是 Just In Time,java 虚拟机,python,v8 都有 JIT 机制。而另一种,就是 PTX 汇编,这种形式是通过 cuda runtime 在运行时加载编译然后执行的,第一次加载编译时会比较耗时。
A CUDA program can still target different devices by embedding multiple cubins into a single file (called a fat binary ). The appropriate cubin is selected at run-time.
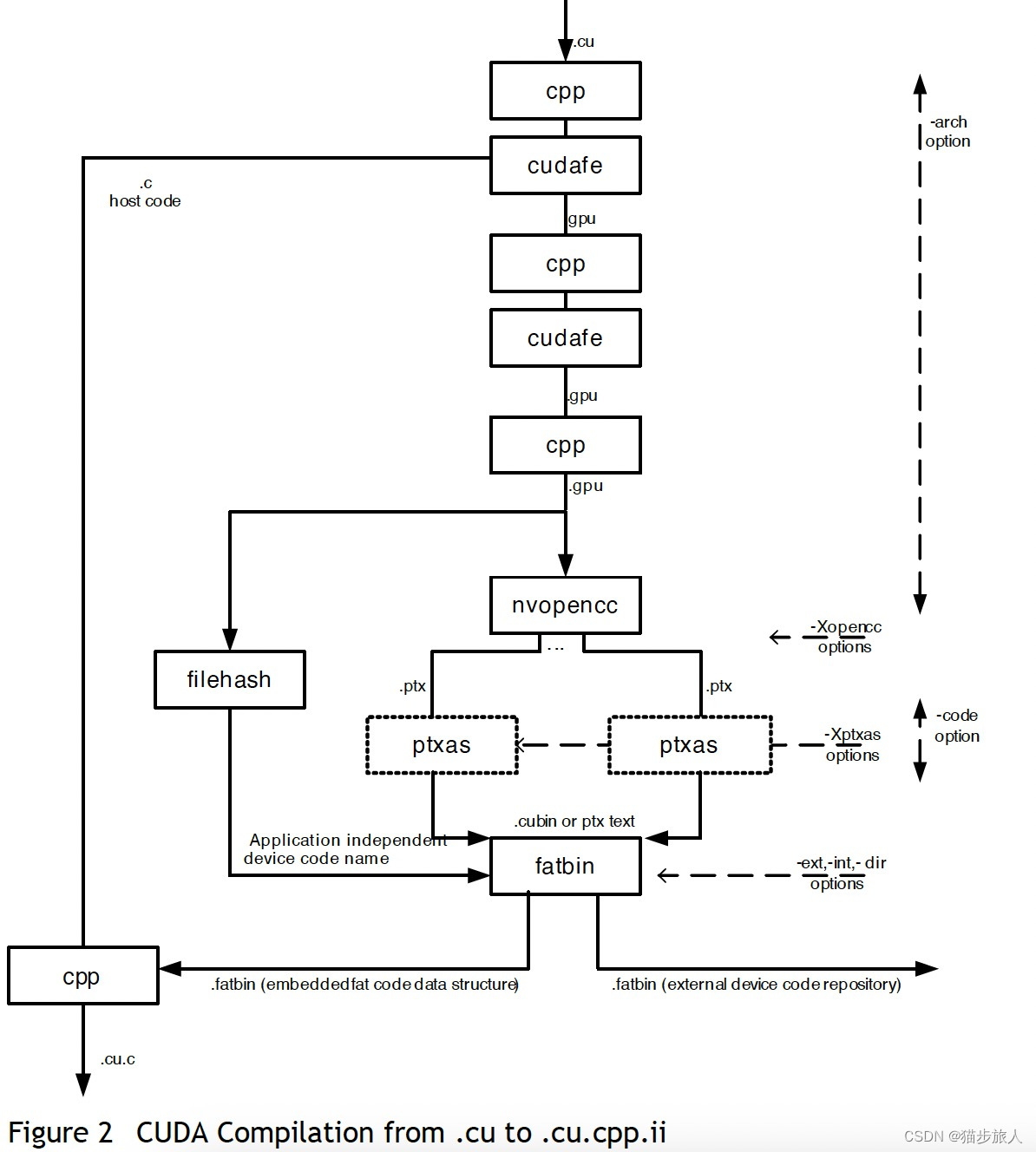
从上面可以发现,使用nvcc进行编译,将包含有cuda kernel 的 c++ 代码,分成了 device 的代码和 host 的代码,host 代码通过 clang/gcc 以传统 c++ 代码的方式进行编译,而 device 代码以 nvcc cuda 编译的流程进行编译。我们使用 --verbose 的方式来观察一下具体的编译流程。
$ nvcc --cudart shared -o device helloworld.cu --verbose ---keep

helloworld.cu 编译后生成了 hellworld.cpp1.ii 和 helloworld.ptx,ptx 也就是 cuda 汇编代码。然后 helloworld.ptx 编译成了 cubin 二进制文件,而 fatbinary 最终会被嵌入到最终的 elf 二进制文件 devicde 中。
elf 二进制文件分析
使用 readelf 观察一下 device 这个文件
readelf -a device
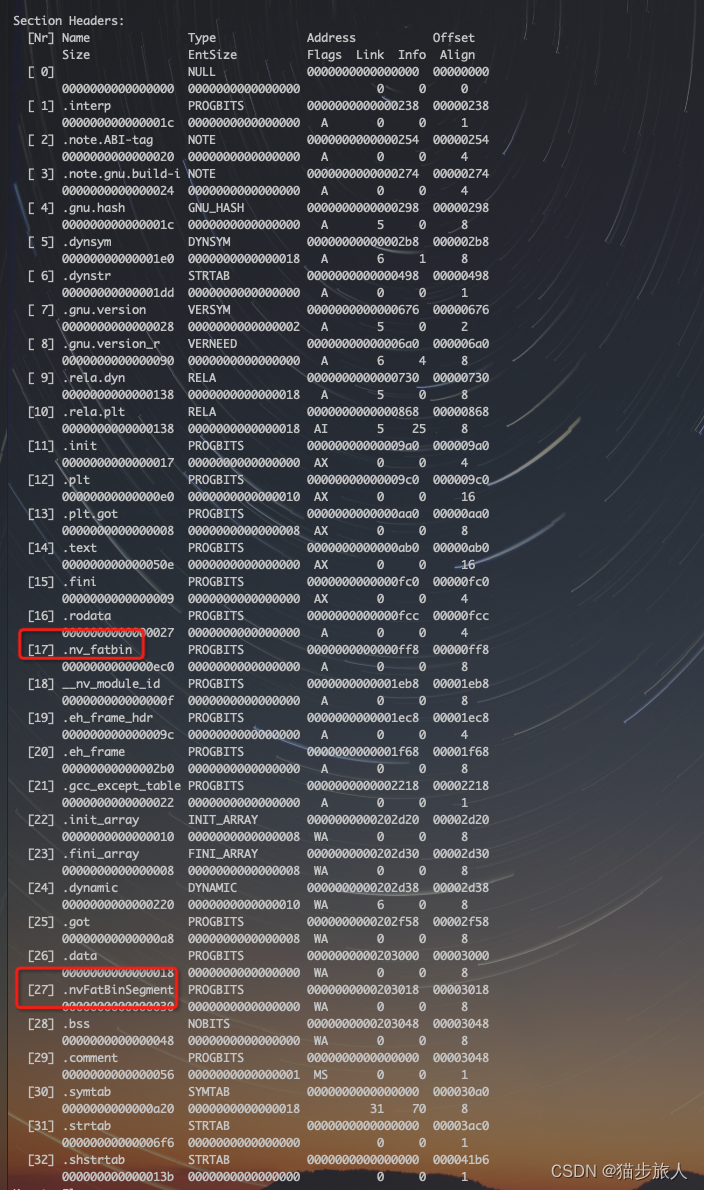
在该 elf 文件中,多了两个段 .nv_fatbin 和 .nvFatBinSegment
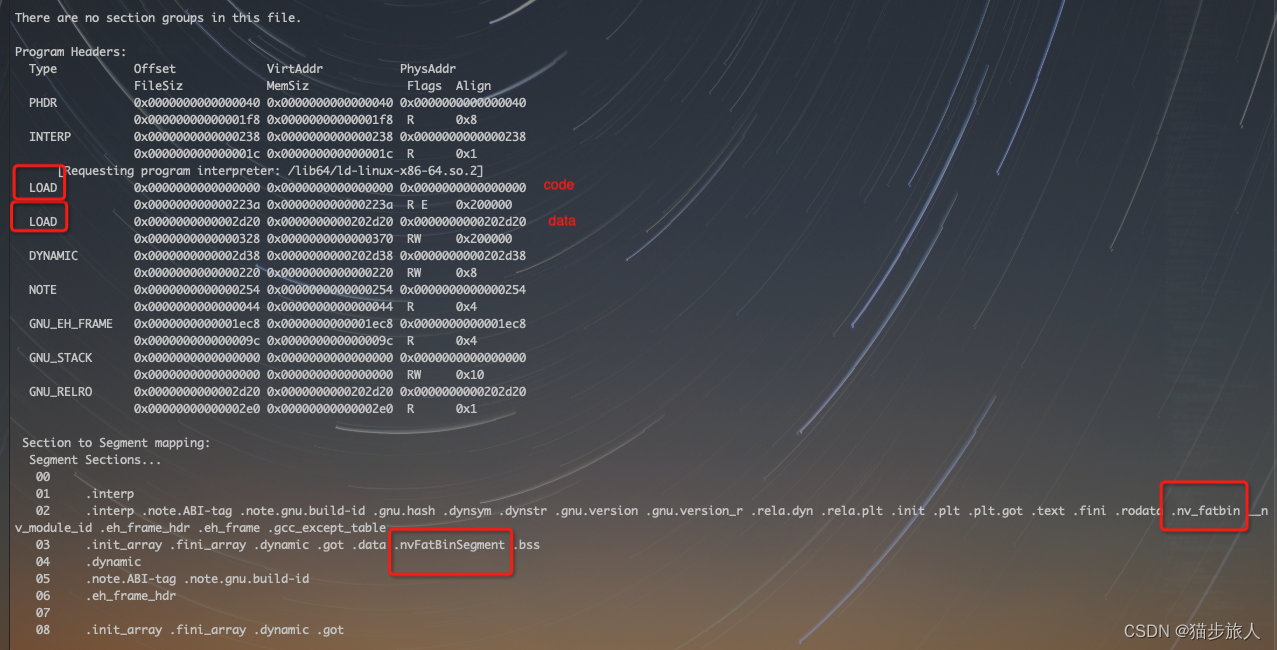
从 Program Headers 中可以发现,这两个段分别位于代码段和数据段中。
第一个 LOAD 属性为 RE,表示可读可执行表示代码段,而第二个 LOAD 属性为 RW,表示可读可写,为数据段。从上往下索引分别是 02 和 03,所以 .nv_fatbin 位于代码段,而 .nvFatBinSegment 位于数据段中。
.nv_fatbin
It is split into an arbitrary number of distinct regions, each of which contains one or more GPU ELF files, PTX code files, and/or cubin files .
该段中保存的通常是 PTX 汇编代码或者 cubin 二进制代码,正好与上面的分析相符,位于代码段中。
.nvFatBinSegment
It contains metadata about the .nv_fatbin section , such as the starting addresses of its regions. Its size is a multiple of six words (24 bytes), where the third word in each group of six is an address inside of the .nv_fatbin section. If we modify the .nv_fatbin, then these addresses need to be changed to match it.
该段保存的是 .nv_fatbin 的一些 metadata。
文件分析
先来看下 device 文件头的信息,可以通过 readelf -h 的方式查看
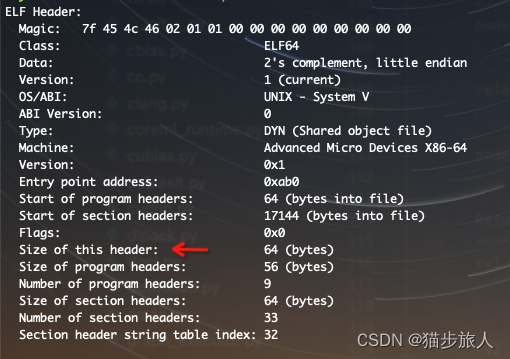
文件头是 64 个字节,program headers 是 56 个字节,共有 9 个 program headers,每一个 section header 是 64 字节。
先看下 elf.h 中 Elf64_Ehdr 文件的数据结构
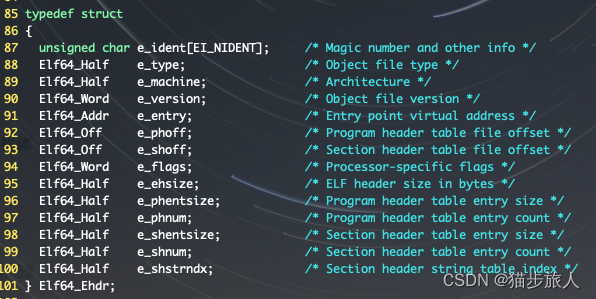
e_ident 就是上面 readelf -h 结果中的 Magic,也就是 elf 格式的魔数。
文件头大小是 64 字节,使用 od 来分析一下。
od -Ax -tx1 -N 64 deviceß
解释一下这里的参数
- -Ax: 显示地址的时候,用十六进制来表示。如果使用 -Ad,意思就是用十进制来显示地址;
- -t -x1: 显示字节码内容的时候,使用十六进制(x),每次显示一个字节(1);
- -N 64:只需要读取 64 个字节;
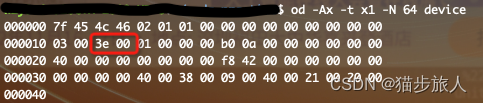
e_type 为 0x0003(小端),e_type 的取值可以在 elf.h 中查看
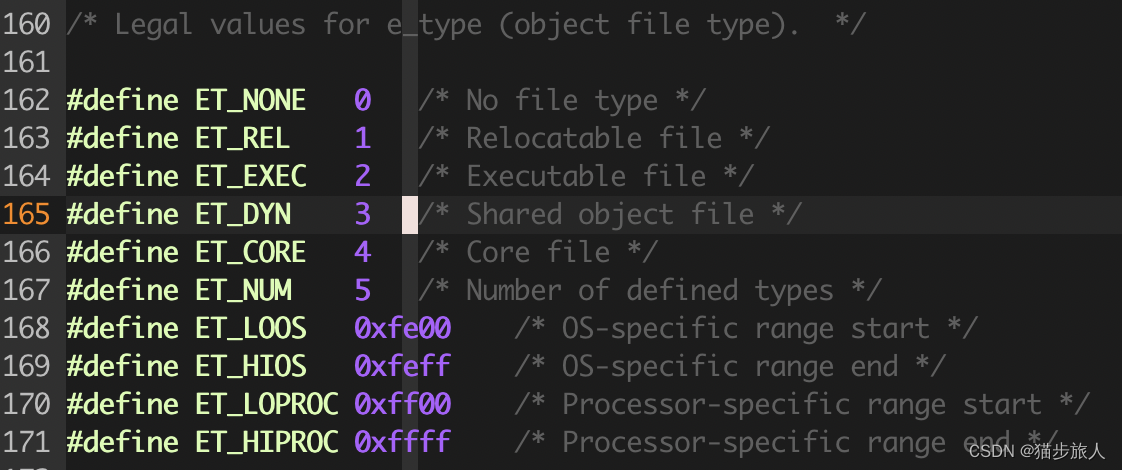
3 表示该文件是 shared object file。
而 e_machine 为 0x003e,

从 elf.h 中可以看出,0x3e 的 10 进制为 62,也就是 ADM x86_64架构。而 cuda 的 e_machine 应该是 190,也就是 0xbe。
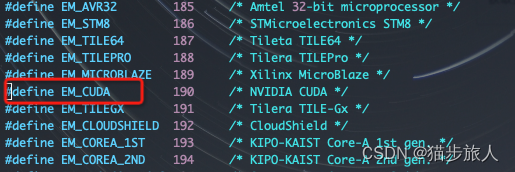
也就是说如果是 cuda bin,Elf64_Ehdr 中 e_machine 成员的值,应该是 190,16 进制就是 0xbe。
我们在最上面分析 device 文件时,使用 readelf -a 查看,发现 .nv_fatbin 在 Section Header 中的索引是 17,section header 的起始偏移是 0x42f8 = 17144,从 elf 文件中获取 nv_fatbin 这个 section 的信息,计算偏移为 0x42f8 + 17 * 64,64 就是 e_shentsize 的大小,为 0x40,即每一个 section header item 的大小为 64 字节

而 section header 的数据结构为
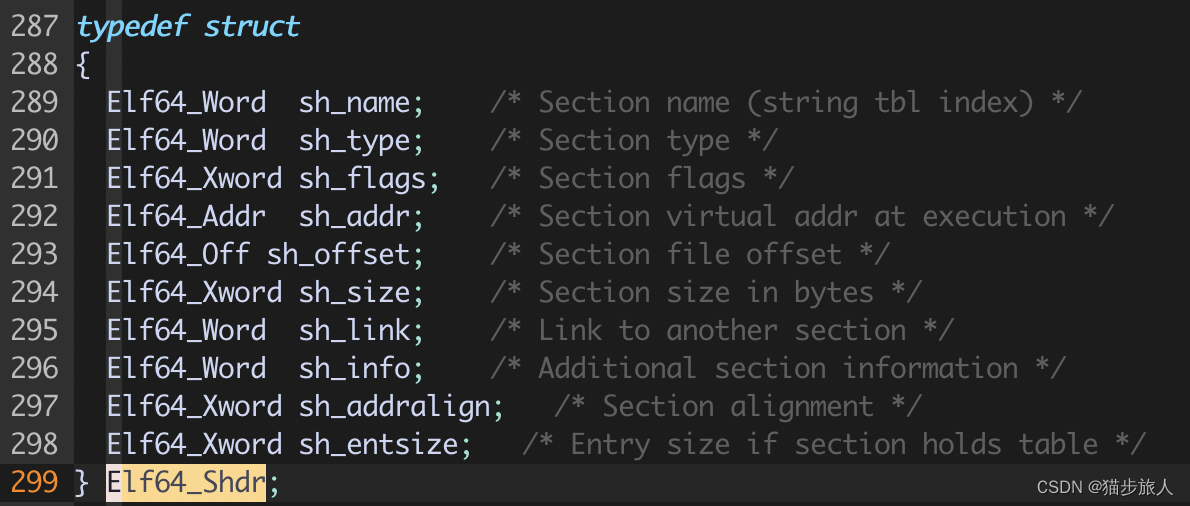
该 section 的大小和偏移与在 readelf -S 中看到的一致,看下内容 .nvfatbin 段的内容
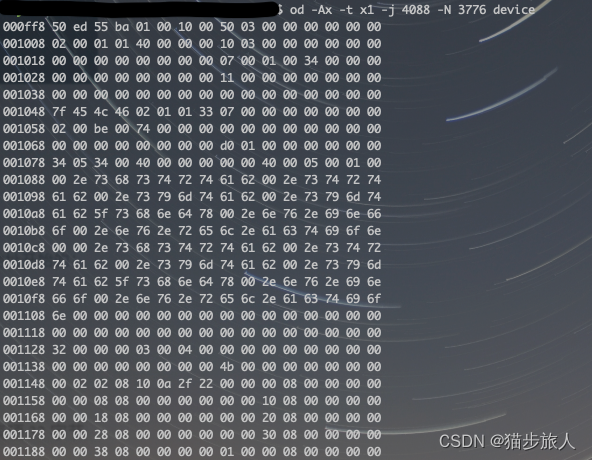
nvcc 编译时,–keep 将临时文件保存下来,device_dlink.fatbin 与上面的内容一致
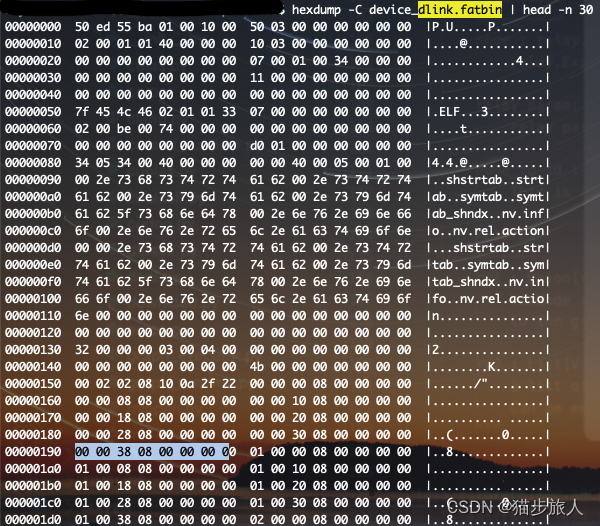
fatbin 是 device-only 的代码
上面这个 fatbin 文件其实是一个包裹着 elf 文件的二进制文件,
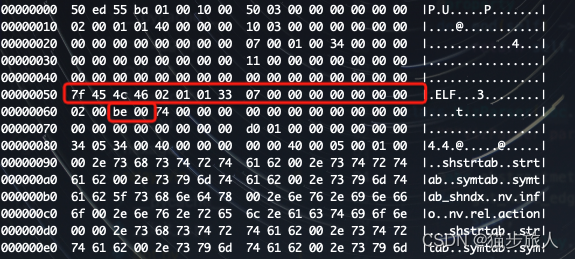
文件 e_machine 为 0xbe,就是 cuda elf 格式的文件。
总结
cuda 二进制文件,分成两部分,一个是 host 部分的代码,一个是 device 段的代码。device 段的代码,作为一个 section 的方式,以 fatbin 的方式或者 ptx 汇编代码的方式嵌入到了最终的 elf 文件中。这部分代码,有 cuda runtime 来负责编译运行。
reference
- PCI BARs and other means of accessing the GPU
- https://www.ofweek.com/ai/2021-05/ART-201721-11000-30500304_3.html
相关文章:
cuda二进制文件中到底有些什么
大家好。今天我们来讨论一下,相比gcc编译器编译的二进制elf文件,包含有 cuda kernel 的源文件编译出来的 elf 文件有什么不同呢? 之前研究过一点 tvm。从 BYOC 的框架中可以得知,前端将模型 partition 成 host 和 accel(accel 表…...

怎么从视频中提取动图?一个方法快速提取gif
视频以连续的方式播放一系列图像帧,通过每秒播放的帧数(帧率)来创做,由于GIF动图则以循环播放一系列静态图像帧的方式展现动画效果。由于视频的优势在于流畅的动画、丰富的细节和长时间播放,因此常用于电影、电视节目、…...

String字符串的比较和hash函数减少哈希冲突
1.为什么比较字符串通过hash值比通过字符串本身效率更高 比较两个字符串的哈希值相对于比较两个字符串本身的效率更高,原因如下: 哈希函数具有快速计算的特性:哈希函数可以将一个字符串转换为一个固定长度的哈希值。这个转换过程通常是非常…...

【数据库原理】(38)数据仓库
数据仓库(Data Warehouse, DW)是为了满足企业决策分析需求而设计的数据环境,它与传统数据库有明显的不同。 一.数据库仓库概述 定义: 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持企业管理和…...
已有标准库的拓展和修改)
C++17新特性(四)已有标准库的拓展和修改
这一部分介绍C17对已有标准库组件的拓展和修改。 1. 类型特征拓展 1.1 类型特征后缀_v 自从C17起,对所有返回值的类型特征使用后缀_v,例如: std::is_const_v<T>; // C17 std::is_const<T>::value; // C11这适用于所有返回值的…...
软件是什么?前端,后端,数据库
软件是什么? 由于很多东西没有实际接触,很难理解,对于软件的定义也是各种各样。但是我还是不理解,软件开发中的前端,后端,数据库到底有什么关系呢! 这个问题足足困扰了三年半,练习时…...
Vue3+ElementUI 多选框中复选框和名字点击方法效果分离
现在的需求为 比如我点击了Option A ,触发点击Option A的方法,并且复选框不会取消勾选,分离的方法。 <el-checkbox-group v-model"mapWork.model_checkArray.value"> <div class"naipTypeDom" v-for"item …...

设计模式篇章(4)——十一种行为型模式
这个设计模式主要思考的是如何分配对象的职责和将对象之间相互协作完成单个对象无法完成的任务,这个与结构型模式有点像,结构型可以理解为静态的组合,例如将不同的组件拼起来成为一个更大的组件;而行为型更是一种动态或者具有某个…...
Spring成长之路—Spring MVC
在分享SpringMVC之前,我们先对MVC有个基本的了解。MVC(Model-View-Controller)指的是一种软件思想,它将软件分为三层:模型层、视图层、控制层 模型层即Model:负责处理具体的业务和封装实体类,我们所知的service层、poj…...
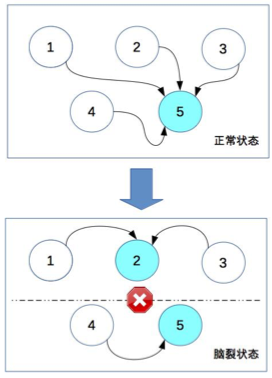
架构篇05-复杂度来源:高可用
文章目录 计算高可用存储高可用高可用状态决策小结 今天,我们聊聊复杂度的第二个来源高可用。 参考维基百科,先来看看高可用的定义。 系统无中断地执行其功能的能力,代表系统的可用性程度,是进行系统设计时的准则之一。 这个定义…...

C#调用Newtonsoft.Json将bool序列化为int
使用Newtonsoft.Json将数据对象序列化为Json字符串时,如果有布尔类型的属性值时,一般会将bool类型序列化为字符串,true值序列化为true,false值序列化为false。如下面的类型序列化后的结果如下: public class UserInfo…...

【Linux系统编程】环境变量详解
文章目录 1. 环境变量的基本概念2. 如何理解呢?(测试PATH)2.1 切入点1查看具体的环境变量原因剖析常见环境变量 2.2 切入点2给PATH环境变量添加新路径将我们自己的命令拷贝到PATH已有路径里面 2.3 切入点3 3. 显示所有环境变量4. 测试HOME5. …...

智能合约介绍
莫道儒冠误此生,从来诗书不负人 目录 一、什么是区块链智能合约? 二、智能合约的发展背景 三、智能合约的优势 四、智能合约的劣势 五、一些关于智能合约的应用 总结 一、什么是区块链智能合约? 智能合约,是一段写在区块链上的代码,一…...
Python自动化实战之接口请求的实现
在前文说过,如果想要更好的做接口测试,我们要利用自己的代码基础与代码优势,所以该章节不会再介绍商业化的、通用的接口测试工具,重点介绍如何通过 python 编码来实现我们的接口测试以及通过 Pycharm 的实际应用编写一个简单接口测…...

react和vue的区别
一、核心思想不同 Vue的核心思想是尽可能的降低前端开发的门槛,是一个灵活易用的渐进式双向绑定的MVVM框架。 React的核心思想是声明式渲染和组件化、单向数据流,React既不属于MVC也不属于MVVM架构。 如何理解React的单向数据流? React的单…...

Spring 中有哪些方式可以把 Bean 注入到 IOC 容器?
目录 1、xml方式2、CompontScan Component3、使用 Bean方式4、使用Import 注解5、FactoryBean 工厂 bean6、使用 ImportBeanDefinitionRegistrar 向容器中注入Bean7、实现 ImportSelector 接口 1、xml方式 使用 xml 的方式来声明 Bean 的定义,Spring 容器在启动的…...

客户需求,就是项目管理中最难管的事情
对于需求控制和管理 个人的观点是:首先要向客户传递开发流程,第二必须制作原型,需求确认时确认的是原型,而不是需求文档,第三,开发阶段要快速迭代,与客户互动。管人方面我想对于项目经理来讲&am…...

条款28:避免返回 handles 指向对象的内部成分
创建一个矩形的类(Rectangle),为保持Rectangle对象较小,可以只在其对象中保存一个指针,用于指向辅助的结构体,定义其范围的点数据存放在辅助的结构体中: class Point { // 表示点的类 public:P…...
)
【人工智能】之深入理解 AI Agent:超越代码的智能助手(2)
人工智能(AI)正在以前所未有的速度迅猛发展,而AI Agent(智能代理)则是这一领域中备受瞩目的一环。AI Agent 不仅仅是程序的执行者,更是能够感知、学习和交互的智能实体。本文将深入探讨什么是 AI Agent&…...

如何将一个字符串转换为整数?
目录 1. 基本方法:int() 函数 2. 错误处理 3. 性能考虑 4. 实用技巧 结论 在Python中,将字符串转换为整数是一个常见且重要的操作。这种转换通常在处理用户输入、解析文本数据或在不同数据类型间进行转换时使用。以下是从几个方面对这个主题的详细介…...

对比官方渠道Taotoken在Token计费与套餐上的成本优势感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方渠道Taotoken在Token计费与套餐上的成本优势感知 对于个人开发者和初创团队而言,在探索和集成大模型能力时&am…...

告别软件切换!用uTools的超级面板和插件,5分钟搞定你的日常效率工作流
告别软件切换!用uTools的超级面板和插件,5分钟搞定你的日常效率工作流 你是否经常在多个软件之间来回切换,只为完成一个简单的任务?复制一段文字需要翻译,得先打开浏览器;截图后想提取文字,又要…...
)
保姆级教程:在VMware上安装BCLinux for Euler 21.10最小化系统(附镜像校验与网络配置)
虚拟化环境实战:BCLinux for Euler 21.10最小化系统部署全指南 在云计算和容器化技术盛行的今天,本地虚拟化环境仍然是开发者进行系统测试、软件验证的重要工具。BCLinux for Euler作为一款针对企业级场景优化的Linux发行版,其21.10版本在性能…...

【SRC漏洞挖掘系列】第04期:文件上传与解析——把图片变成“特洛伊木马”
上期回顾:我们刚用 SQL 注入把数据库翻了个底朝天。本期我们来聊聊更暴力的漏洞——文件上传。如果说 SQL 注入是“偷”,那文件上传就是直接往人家服务器里安炸弹。💣一、为什么文件上传是“高危”?在 SRC 评级里,GetS…...

别再新建模型了!手把手教你用AVL Cruise自带实例,5分钟搞定纯电动车仿真
别再新建模型了!5分钟玩转AVL Cruise自带实例的电动车仿真秘籍 刚接触AVL Cruise的新手工程师们,你们是否经常陷入这样的困境:面对空白的建模界面无从下手,参数设置像走迷宫,好不容易建完模型却发现仿真结果离奇失真&a…...

5种文本切块策略大解析:从字符到语义,打造高效检索系统!
文本切块是构建向量索引前的重要环节,避免语义切断和检索效果冲淡。文章详细解析了五种常见切块策略:按字符长度切分、按Token长度切分、按句子语义切分、按段落结构切分(含默认语法和自定义语法)以及混合方式切分。每种策略都有其…...

1Remote终极指南:如何快速管理所有远程连接
1Remote终极指南:如何快速管理所有远程连接 【免费下载链接】1Remote One Remote Access Manager to Rule Them All 项目地址: https://gitcode.com/gh_mirrors/1r/1Remote 1Remote是一款现代化的个人远程会话管理器,专为IT专业人士和开发者设计&…...

VSLAM与VIO技术解析:从3D建图到重定位的工程实践
1. 项目概述:从传感器融合到环境认知的跨越在机器人、自动驾驶和增强现实这些前沿领域,让机器“看见”并“理解”它所处的三维世界,是赋予其自主行动能力的基石。这背后,视觉SLAM(Simultaneous Localization and Mappi…...

Beyond Compare 5密钥生成终极指南:从激活失败到完全使用
Beyond Compare 5密钥生成终极指南:从激活失败到完全使用 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 你是否也遇到过Beyond Compare 5弹出"评估模式错误"的困扰&#…...

【普中 51-Ai8051 开发攻略】-- 第 30 章 OLED 液晶显示实验-硬件 IIC
(1)实验平台: 普中 51-Ai8051 开发板https://item.taobao.com/item.htm?abbucket17&id1026052331067(2)资料下载 :普中科技-各型号产品资料下载链接 前面已经使用 IO 口软件模拟 IIC 时序与 OLED 通信实现字符汉字的显示。 本章学习使用 AI805…...