C++17新特性(四)已有标准库的拓展和修改
这一部分介绍C++17对已有标准库组件的拓展和修改。
1. 类型特征拓展
1.1 类型特征后缀_v
自从C++17起,对所有返回值的类型特征使用后缀_v,例如:
std::is_const_v<T>; // C++17
std::is_const<T>::value; // C++11
这适用于所有返回值的类型特征,也可以用作运行时的条件表达式。
1.2 新的类型特征
| 特征 | 效果 |
|---|---|
| is_aggregate | 是否是聚合体类型 |
| is_swappable | 该类型是否能调用swap() |
| is_nothrow_swapable | 该类型是否能调用swap()并且不会抛出异常 |
| is_swappable_with<T1,T2> | 特定的两个类型是否能交换(swap()) |
| is_nothrow_swappable_with<T1,T2> | 特定的两个类型是否能交换(swap())并不会抛出异常 |
| has_unique_object_representations | 是否该类型的两个值相等的对象在内存中的表示也一样 |
| is_invocable<T,Args…> | 是否可以用Args...调用 |
| is_nothrow_invocable<T,Args…> | 是否可以用Args...调用并不会抛出异常 |
| is_invocable_r<RT,T,Args…> | 该类型是否可以用Args...调用,且返回RT类型 |
| is_nothrow_invocable_r<RT,T,Args…> | 该类型是否可以用Args...调用,且返回RT类型并且不会抛出异常 |
| invoke_result<T,Args…> | 用Args...作为实参进行调用会返回的类型 |
| conjunction<B…> | 对bool特征B...进行逻辑与 |
| disjunction<B…> | 对bool特征B...进行逻辑或运算 |
| negation | 对bool特征B进行非运算 |
| is_execution_policy | 是否执行策略类型 |
另外,is_literal_type<>和result_of<>自从C++17起被废弃。
template<typename T>
struct D : string, complex<T>
{string data;
};struct C
{bool operator()(int) const{return true;}
};string foo(int);using T1 = invoke_result_t<decltype(foo), int>; // string// 是否是指针
template<typename T>
struct IsPtr : disjunction<is_null_pointer<T>, // 空指针is_member_pointer<T>, // 成员函数指针is_pointer<T>> // 原生指针
{};int main()
{D<float> s{ {"hello"},{4.5,6.7},"world" };cout << is_aggregate_v<decltype(s)> << endl; // 1cout << is_swappable_v<int> << endl; // 1cout << is_swappable_with_v<int, int> << endl; // 1cout << is_invocable_v<C> << endl; // 0cout << is_invocable_v<C,int> << endl; // 1cout << is_invocable_v<int(*)()> << endl; // 1cout << is_invocable_r_v<bool, C, int> << endl; // 1}
2. 并行STL算法
为了从现代的多核体系中受益,C++17标准库引入了并行STL算法来使用多个线程并行处理元素。
许多算法扩展了一个新的参数来指明是否要并行运行算法。
一个简单的计时器辅助类:
设计一个计算器来测量算法的速度。
#include <chrono>/*****************************************
* timer to print elapsed time
******************************************/class Timer
{
private:chrono::steady_clock::time_point last;
public:Timer() : last{ chrono::steady_clock::now() }{}void printDiff(const std::string& msg = "Timer diff: "){auto now{ chrono::steady_clock::now() };chrono::duration<double, milli> diff{ now - last };cout << msg << diff.count() << "ms\n";last = chrono::steady_clock::now();}
};
2.1 使用并行算法
2.1.1 使用并行的for_each()
#include <numeric>
#include <execution> // 执行策略,包含并行模式
#include <cmath>int main()
{int numElems = 1000000;struct Data{double value; // 初始值double sqrt; // 计算平方根};// 初始化numElems个还没有计算平方根的值vector<Data> coll;coll.reserve(numElems);for (int i = 0; i < numElems; ++i)coll.push_back(Data{ i * 4.37,0 });for (int i = 0; i < 5; ++i){Timer t;// 顺序计算平方根for_each(execution::seq, coll.begin(), coll.end(), [](auto& val){val.sqrt = sqrt(val.value);});t.printDiff("sequential: ");// 并行计算平方根for_each(execution::par, coll.begin(), coll.end(), [](auto& val){val.sqrt = sqrt(val.value);});t.printDiff("parallel: ");cout << endl;}
}
测试结果中,只有少量元素的时候,串行算法明显快得多。这是因为启动和管理线程占用了太多的事件。但是当元素很大的时候,并行执行的效率就大大提升。
值得使用并行算法的关键在于:
- 操作很长(复杂)
- 有很多元素
2.1.2 使用并行sort()
排序是另一个并行算法的例子。
int main()
{int numElems = 100000;vector<string> coll;for (int i = 0; i < numElems / 2; ++i){coll.emplace_back("id" + to_string(i));coll.emplace_back("ID" + to_string(i));}for (int i = 0; i < 5; ++i){Timer t;// 顺序排序sort(execution::seq, coll.begin(), coll.end(), [](const auto& a,const auto& b){return string_view{ a }.substr(2) < string_view{ b }.substr(2);});t.printDiff("sequential: ");// 并行排序sort(execution::par, coll.begin(), coll.end(), [](const auto& a, const auto& b){return string_view{ a }.substr(2) < string_view{ b }.substr(2);});t.printDiff("parallel: ");// 并行化乱序排序sort(execution::par_unseq, coll.begin(), coll.end(), [](const auto& a, const auto& b){return string_view{ a }.substr(2) < string_view{ b }.substr(2);});t.printDiff("parallel unsequential: ");cout << endl;}
}
2.2 执行策略
你可以像并行STL算法传递不同的执行策略作为第一个参数。定义在头文件<execution>中。
| 策略 | 含义 |
|---|---|
| std::execution::seq | 顺序执行 |
| std::execution::par | 并行化顺序执行 |
| std::execution::par_unseq | 并行化乱序执行(保证不会出现死锁) |
2.3 异常处理
当处理元素的函数因为未捕获的异常而退出时所有的并行算法会调用terminate()。
并行算法本身也可能会抛出异常。比如它们申请并行执行所需的临时内存资源时失败了,可能会抛出bad_alloc异常。
2.4 并行算法概述
无限制的并行算法:
find_end(),adjacent_find()search(),search_n()swap_ranges()replace(),replace_if()fill()generate()remove(),remove_if(),unique()reverse(),rotate()partition(),stable_sort(),partial_sort()is_sorted(),is_sorted_until()nth_element()inplace_merge()is_heap(),is_heap_until()min_element(),max_element(),min_max_element()
无并行版本的算法:
accmulate()partial_sum()inner_product()search()copy_backward(),move_backward()sample(),shuffle()partition_point()lower_bound(),upper_bound(),equal_range()binary_serach()is_permutation()next_permutation(),prev_permutation()push_heap(),pop_hep(),make_heap(),sort_heap()
对于一下算法,可以使用对应的并行算法来替代:
accumulate(),使用reduce()或者transform_reduce()inner_product(),使用transform_reduce()
2.5 并行编程的新算法的动机
C++17还引入了一些补充的算法来实现从C++98就可以的标准算法的并行执行。
2.5.1 reduce()
reduce是accumulate()的并行化版本,但是也有所不同,下面分几个场景介绍:
可结合可交换操作的并行化(例如加法):
void printSum(long num)
{vector<long> coll;coll.reserve(num * 4);for (long i = 0; i < num; ++i){coll.insert(coll.end(), { 1,2,3,4 });}Timer t;auto sum = reduce(execution::par, coll.begin(), coll.end(), 0L);t.printDiff("reduce: ");sum = accumulate(coll.begin(), coll.end(), 0L);t.printDiff("accumulate: ");cout << "sum: " << sum << endl;
}int main()
{printSum(1);printSum(1000);printSum(1000000);
}
不可交换操作的并行化(浮点数相加):
void printSum(long num)
{vector<double> coll;coll.reserve(num * 4);for (long i = 0; i < num; ++i){coll.insert(coll.end(), { 0.1,0.3,0.00001 });}Timer t;double sum1 = reduce(execution::par, coll.begin(), coll.end(), 0.0);t.printDiff("reduce: ");double sum2 = accumulate(coll.begin(), coll.end(), 0.0);t.printDiff("accumulate: ");cout << (sum1 == sum2 ? "equal\n" : "differ\n");
}int main()
{cout << setprecision(5); // 浮点数精度printSum(1); // equalprintSum(1000); // equalprintSum(1000000); // differ
}
不可结合操作的并行化(累积操作改为加上每个值的平方):
void printSum(long num)
{vector<long> coll;coll.reserve(num * 4);for (long i = 0; i < num; ++i){coll.insert(coll.end(), { 1,2,3,4 });}auto squareSum = [](auto sum, auto val) {return sum + val * val;};auto sum = accumulate(coll.begin(), coll.end(), 0L, squareSum);cout << "accumulate(): " << sum << endl;auto sum1 = reduce(execution::par,coll.begin(), coll.end(), 0L, squareSum);cout << "reduce(): " << sum << endl;
}int main()
{printSum(1);printSum(1000);printSum(10000000);
}
reduce()有可能会导致结果不正确。因为这个操作是不可结合的。假设有三个元素1、2、3。在计算过程中可能导致计算的是:
(0 + 1 * 1) + (2 + 3 * 3) * (2 + 3 * 3)
解决这个问题的方法是用另一个新算法transform_reduce()。把我们对每一个元素的操作和可交换的结果的累计都并行化。
void printSum(long num)
{vector<long> coll;coll.reserve(num * 4);for (long i = 0; i < num; ++i){coll.insert(coll.end(), { 1,2,3,4 });}auto sq = [](auto val) {return val * val;};auto sum = transform_reduce(execution::par, coll.begin(), coll.end(), 0L, plus{}, sq);cout << "transform_reduce(): " << sum << endl;
}
transform_reduce的参数:
- 运行并行执行的策略
- 要处理的值范围
- 外层累积的初始值
- 外层累积的操作
- 在累积之前处理每个值的lambda表达式
2.5.2 transform_reduce()
使用transform_reduce()进行文件系统操作:
int main(int argc, char* argv[])
{if (argc < 2){cout << "Usage: " << argv[0] << " <path> \n";return EXIT_FAILURE;}namespace fs = filesystem;fs::path root{ argv[1] };// 初始化文件树中所有文件路径的列表vector<fs::path> paths;try{fs::recursive_directory_iterator dirpos{ root };copy(begin(dirpos), end(dirpos), back_inserter(paths));}catch (const exception& e){cerr << "EXCEPTION: " << e.what() << endl;return EXIT_FAILURE;}// 累积所有普通文件的大小auto sz = transform_reduce(execution::par,paths.cbegin(), paths.cend(),uintmax_t{ 0 },plus<>(),[](const fs::path& p){return is_regular_file(p) ? file_size(p) : uintmax_t{ 0 };});cout << "size of all " << paths.size()<< "regular files: " << sz << endl;
}
3. 新的STL算法详解
3.1 for_each_n()
作为并行STL算法的一部分,原本的for_each_n又有了一个新的并行版本。类似于copy_n()、fill_n()、generate_n(),这个算法需要一个整数参数指出要对范围内多少个元素进行操作。
InputIterator
for_each_n (ExecutionPolicy&& pol,InputIterator beg,Size count,UnaryProc op);
- 以beg为起点的前count个元素调用op。
- 返回最后一个调用op元素的下一个位置。
- 调用者必须保证有足够多的元素。
- op返回的任何值都会被忽略。
- 如果没有传递执行策略,其他参数按顺序传递即可。
- 如果传入了第一个可选的执行策略参数:
- 对所有元素调用的op的顺序没有任何保证。
- 调用者要保证并行操作不会产生数据竞争。
- 迭代器必须至少是前向迭代器。
例如:
int main()
{vector<string> coll;for (int i = 0; i < 10000; ++i){coll.push_back(to_string(i));}// 修改前五个元素for_each_n(coll.begin(), 5,[](auto& elem){elem = "value " + elem;});for_each_n(coll.begin(), 10,[](const auto& elem){cout << elem << endl;});
}
3.2 新的STL数值算法
这些算法都定义在<numeric>中。
3.2.1 reduce()
typename iterator_traits<InputIterator>::value_type
reduce (ExecutionPolicy&& pol, // 可选的InputIterator beg, InputIterator end);T
reduce (ExecutionPolicy&& pol, // 可选的InputIterator beg, InputIterator end,T initVal);T
reduce (ExecutionPolicy&& pol, // 可选的InputIterator beg, InputIterator end,T initVal,BinaryOp op);
3.2.2 transform_reduce()
变种一:
T
transform_reduce (ExecutionPolicy&& pol, // 可选的InputIterator beg,InputIterator end,T initVal,BinaryOp op2,UnaryOp op1)
initVal op2 op1(a1) op2 op1(a2) op2 op1(a3) op2 ...
变种二:
T
transform_reduce (ExecutionPolicy&& pol, // 可选的InputIterator beg1, InputIterator end1,InputIterator beg2,T initVal);T
transform_reduce (ExecutionPolicy&& pol, // 可选的InputIterator beg1, InputIterator end1,InputIterator beg2,T initVal,BinaryOp1 op1, BinaryOp2 op2);
- 第一个形式计算范围beg1和beg2开始的元素相乘再加上
initVal。initVal += elem1 * elem2。 - 第二个形式是对beg1和beg2开始的元素调用
op2,然后对initVal和上一步的结果调用op1。initVal = op1(initVal, op2(elem1, elem2))。
3.2.3 inclusive_scan()和exclusive_scan()
OutputIterator
inclusive_scan (ExcutionPolicy&& pol, // 可选的InputIterator inBeg, InputIterator inEnd,OutputIterator outBeg,BinaryOp op, // 可选的T initVal // 可选的);OutputIterator
exclusive_scan (ExcutionPolicy&& pol, // 可选的InputIterator inBeg, InputIterator inEnd,OutputIterator outBeg,T initVal, // 必须的BinaryOp op // 可选的);
- 所有的形式是在计算范围
[inBeg, inEnd)内每个元素和之前所有元素组合之后的值并写入以outBeg开头的目标范围。 - 对于值
a1 a2 a3 ... aN,inclusive_scan()计算initVal op a1, initVal op a1 op a2, initVal op a1 op a2 op a3, ...aN - 对于值
a1 a2 a3 ... aN,exclusive_scan()计算initVal, initVal op a1, initVal op a1 op a2, ... aN-1 - 所有的形式都返回最后一个被写入的位置的下一个位置。
- 如果没有传递op,会使用
plus。 - 如果没有传递
initVal,将不会添加初始值。第一个输出的值将直接是第一个输入的值。 op不能修改传入的参数。
int main()
{array coll{ 3,1,7,0,4,1,6,3 };cout << " inclusive scan(): ";inclusive_scan(coll.begin(), coll.end(),ostream_iterator<int>(cout, " "));cout << "\n exclusive_scan(): ";exclusive_scan(coll.begin(), coll.end(),ostream_iterator<int>(cout, " "),0);cout << "\n inclusive scan(): ";inclusive_scan(coll.begin(), coll.end(),ostream_iterator<int>(cout, " "),plus{},100);cout << "\n exclusive_scan(): ";exclusive_scan(coll.begin(), coll.end(),ostream_iterator<int>(cout, " "),100, plus{});
}
输出结果:
inclusive scan(): 3 4 11 11 15 16 22 25exclusive_scan(): 0 3 4 11 11 15 16 22inclusive scan(): 103 104 111 111 115 116 122 125exclusive_scan(): 100 103 104 111 111 115 116 122
3.2.4 transform_inclusive_scan()和transform_exclusive_scan()
OutputIterator
transform_inclusive_scan (ExcutionPolicy&& pol, // 可选的InputIterator inBeg, InputIterator inEnd,OutputIterator outBeg,BinaryOp op2, // 必须的UnaryOp op1, // 必须的T initVal // 可选的);OutputIterator
transform_exclusive_scan (ExcutionPolicy&& pol, // 可选的InputIterator inBeg, InputIterator inEnd,OutputIterator outBeg,T initVal, // 必须的BinaryOp op2, // 必须的UnaryOp op1, // 必须的 );
- 对于值
a1 a2 a3 ... aN,transform_inclusive_scan计算initVal op2 op1(a1), initVal op2 op1(a1) op2 op1(a2), ... op2 op1(aN)。 - 对于值
a1 a2 a3 ... aN,transform_exclusive_scan计算initVal, initVal op2 op1(a1), initVal op2 op1(a1) op2 op1(a2), ... op2 op1(aN-1)。
int main()
{array coll{ 3,1,7,0,4,1,6,3 };auto twice = [](int v) { return v * 2; };cout << " source: ";copy(coll.begin(), coll.end(), ostream_iterator<int>(cout, " "));cout << "\n transform_inclusive_scan(): ";transform_inclusive_scan(coll.begin(), coll.end(),ostream_iterator<int>(cout, " "),plus{}, twice);cout << "\n transform_inclusive_scan(): ";transform_inclusive_scan(coll.begin(), coll.end(),ostream_iterator<int>(cout, " "),plus{}, twice, 100);cout << "\n transform_exclusive_scan(): ";transform_exclusive_scan(coll.begin(), coll.end(),ostream_iterator<int>(cout, " "),100, plus{}, twice);
}
4. 子串和子序列搜索器
4.1 使用子串搜索器
新的搜索器主要是用来在长文本中搜索字符串(例如单词或者短语)。因此首先演示一下在什么情况下使用它们,以及带来的改变。
4.1.1 通过search()使用搜索器
-
字符串成员函数
find()size_t idx = text.find(sub); -
算法
search()auto pos = std::search(text.begin(), text.end(), sub.begin(), sub.end()); -
并行算法
search()auto pos = std::search(execution::par, text.begin(), text.end(), sub.begin(), sub.end()); -
使用
default_searcherauto pos = search(text.begin(), text.end(), default_searcher{ sub.begin(),sub.end() }); -
使用
boyer_moore_searcherauto pos = search(text.begin(), text.end(), boyer_moore_searcher{ sub.begin(),sub.end() }); -
使用
boyer_moore_horspool_searcherauto pos = search(text.begin(), text.end(), boyer_moore_horspool_searcher{ sub.begin(),sub.end() });
Boyer-Moore和Boyer-Moore-Horspool搜索器是非常著名的在搜索之前预计算“表”(存放哈希值)的算法,当搜索区间非常大时可以显著加快搜索速度。算法需要随机访问迭代器。
搜索器的性能:
- 只使用非并行版本的
search()通常是最慢的方法,因为对于text中的每个字符,我们都要查找以它开头的子串是否匹配搜索目标。 - 使用默认搜索器应该与上一周方法差不多,但是实际最差能比上一种慢三倍。
- 使用
find()可能会更快。这依赖于标准库实现的质量。 - 如果文本或者要搜索的子串非常长,
boyer_moore_searcher应该是最快的方法。和search()相比,甚至可能提供50倍到100倍左右的性能。 boyer_moore_horspool_searcher用时间换空间,虽然比boyer_moore_searcher慢,但占用的内存会更少。- 使用并行
search()的速度是普通的三倍,但远远小于新增的搜索器。
4.1.2 直接使用搜索器
另一个使用Boyer-Moore搜索器的方法是:你可以直接使用搜索器的函数调用运算符,会返回一个匹配子序列开头和尾后迭代器的pair。
boyer_moore_searcher bmsearch{ sub.begin(),sub.end() };for (auto begend = bmsearch(text.begin(), text.end()); begend.first != text.end(); begend = bmsearch(begend.second, text.end()))
{cout << "found " << sub << " at index "<< begend.first - text.begin() << " - "<< begend.second - text.begin() << endl;
}
4.2 使用泛型子序列搜索器
原本这种算法使作为字符串搜索器开发的。然而,C++17将它们改进为泛型算法,因此,你可以在一个容器或者范围内搜索子序列。
int main()
{vector<int> coll;deque<int> sub{ 0,8,15,... };auto pos = search(coll.begin(), coll.end(), boyer_moore_searcher{ sub.begin(),sub.end() });// 或者下面:boyer_moore_searcher bm{ sub.begin(),sub.end() };auto [beg, end] = bm(coll.begin(), coll.end());if (beg != coll.end())cout << "found subsequence at " << beg - coll.begin() << endl;
}
想要能够使用该算法,元素必须能用在哈希表中,也就是必须提供默认的哈希函数和==比较符。否则,使用搜索器谓词。
4.3 搜索器谓词
当使用搜索器时,你可以使用谓词。出于两个原因:
- 你想自定义两个元素的比较方式
- 你想提供一个自定义的哈希函数,也是Boyer-Moore搜索器必须的。
例如,这里用一个大小写不敏感的搜索器来搜索子串:
boyer_moore_searcher bmic { sub.begin(), sub.end(),[](char c){return hash<char>{}(toupper(c));},[](char c1,char c2){return toupper(c1) == toupper(c2);}};
5. 其他工具函数和算法
5.1 size()/empty()/data()
C++新增加了三个辅助函数:size()、empty()、data()。都定义在<iterator>头文件中。
5.1.1 泛型size()函数
该函数允许我们查任何范围的大小,前提是由迭代器接口或者是原生数组。
template<typename T>
void printLast5(const T& coll)
{auto size{ size(coll) };cout << size << " elems: ";auto pos{ begin(coll) };// 将迭代器递增到倒数第五个元素处if (size > 5){advance(pos, size - 5);cout << "...";}// 打印剩下的元素for (; pos != end(coll); ++pos){cout << *pos << " ";}cout << endl;
}
5.1.2 泛型empty()函数
类似size(),empty()可以检查容器、原生数组、initializer_list是否为空。
5.1.3 泛型data()函数
data()函数允许我们访问集合的原始数据。
5.2 as_const()
新的辅助函数as_const()可以在不使用static_cast<>或者add_const_t<>类型特征的情况下把值转换为响应的const类型。
vector<string> coll;foo(coll); // 调用非常量版本
foo(as_const(coll)); // 调用常量版本
5.2.1 以常量引用捕获
例如:
int main()
{vector<int> coll{ 8,5,7,42 };auto printColl = [&coll = as_const(coll)]{cout << "coll: ";for (int elem : coll){cout << elem << " ";}cout << endl;};
}
5.3 clamp()
C++17提供了一个新的工具函数clamp(),找出三个值大小居中的那个。
int main()
{for (int i : {-7, 0, 8, 15}){cout << clamp(i, 5, 13) << endl;}
}
5.4 sample()
C++17提供了sample()算法来从一个给定的范围内提取一个随机的子集。有时候也被称为水塘抽样或者选择抽样。
#include <random>int main()
{vector<string> coll;for (int i = 0; i < 10000; ++i){coll.push_back("value" + to_string(i));}sample(coll.begin(), coll.end(),ostream_iterator<string>(cout, "\n"),10,default_random_engine{});
}
该函数有以下保证和约束:
- 源范围迭代器至少是输入迭代器,目标迭代器至少是输出迭代器。如果源迭代器表示输入迭代器,那么目标迭代器必须是随机访问迭代器。
- 如果目标区间大小不够有没有使用插入迭代器,那么写入目标迭代器可能会导致未定义行为。
- 算法返回最后一个被拷贝元素的下一个位置。
- 目标迭代器指向的区间不能在源区间中。
- num可能是整数类型。如果源区间的元素数量不足,将会提取源区间的所有元素。
- 只要源区间的迭代器不只是输入迭代器,那么提取的子集中的顺序保持稳定。
int main()
{vector<string> coll;for (int i = 0; i < 10000; ++i){coll.push_back("value" + to_string(i));}// 用一个随机数种子初始化Mersenne Twister引擎:random_device rd;mt19937 eng{ rd() };vector<string> subset;subset.resize(100);auto end = sample(coll.begin(), coll.end(),subset.begin(),10,eng);for_each(subset.begin(), end, [](const auto& s){cout << "random elem:" << s << endl;});
}
6. 容器和字符串扩展
6.1 节点句柄
C++17引入把某个节点从关联或无需容器中移除或移入的功能。
6.1.1 修改key
int main()
{map<int, string> m{ {1,"mango"},{2,"papaya"},{3,"guava"} };auto nh = m.extract(2); // nh的类型为decltype(m)::node_typenh.key() = 4;m.insert(move(nh));for (const auto& [key, value] : m){cout << key << " : " << value << endl;}
}
这段代码是把key为2的的元素结点移除了容器,然后修改了key,最后有移进了容器。C++17之前,如果想修改一个key,必须删除旧结点然后再插入一个value相同的新节点。如果我们使用节点句柄,将不会发送内存分配。
6.1.2 在容器之间移动节点句柄
你也可以使用节点句柄把一个元素从一个容器move到另一个容器。
template<typename T1,typename T2>
void print(const T1& coll1, const T2& coll2)
{cout << "values:\n";for (const auto& [key, value] : coll1){cout << " [" << key << " : " << value << "]";}cout << endl;for (const auto& [key, value] : coll2){cout << " [" << key << " : " << value << "]";}cout << endl;
}int main()
{multimap<double, string> src{ {1.1,"one"},{2.2,"two"},{3.3,"three"} };map<double, string> dst{ {3.3,"old data"} };print(src, dst);dst.insert(src.extract(src.find(1.1)));dst.insert(src.extract(2.2));print(src, dst);
}
6.1.3 合并容器
以节点句柄API为基础,现在所有的关联和无需容器都提供了成员函数merge(),可以把一个容器中的所有元素合并到另一个容器中。如果源容器中的某个元素和目标容器的元素的key值相同,那么它仍然保留在源容器中。
template<typename T1,typename T2>
void print(const T1& coll1, const T2& coll2)
{cout << "values:\n";for (const auto& [key, value] : coll1){cout << " [" << key << " : " << value << "]";}cout << endl;for (const auto& [key, value] : coll2){cout << " [" << key << " : " << value << "]";}cout << endl;
}int main()
{multimap<double, string> src{ {1.1,"one"},{2.2,"two"},{3.3,"three"} };map<double, string> dst{ {3.3,"old data"} };print(src, dst);// 把src的所有元素和并到dst中dst.merge(src);print(src, dst);
}
6.2 emplace改进
6.2.1 emplace函数的返回类型
对于顺序容器vector<>、deque<>、list<>、forward_list<>,还有容器适配器stack<>和queue<>。他们的emplace函数现在返回新插入的对象的引用。例如:
foo(myVector.emplace_back(...));
// 等同于
myVector.emplace_back(...);
foo(myVector.back());
6.2.2 map的try_emplace()和insert_or_assign()
try_emplace()用移动语义构造了一个新的值。insert_or_assign()稍微改进了插入/更新元素的方法。
6.2.3 try_emplace()
考虑如下代码:
map<int,string> m;
m[42] = "hello";
string s{"world"};
m.emplace(42,move(s)); // 可能移动,但42已经存在了可能不会移动
这样调用之后s是否保持原本的值是未定义的。同样使用insert()之后也可能是这样。
m.insert({42,move(s))});
新的成员函数try_emplace()保证在没有已经存在元素时才会move走传入的值:
m.try_emplace(42,move(s)); // 如果插入失败不会move
6.2.4 insert_or_assign()
另外,新的成员函数insert_or_assign()保证把值移动道一个新的元素或者已经存在的元素中。
m.insert_or_assgin(42,move(s)); // 总是会move
6.3 对不完全类型的容器支持
自从C++17起,vector、list、forward_list被要求支持不完全类型。
你现在可以定义一个类型,内部递归的包含一个自身类型的容器。例如:
struct Node
{string value;vector<Node> children;
};
6.4 string的改进
- 对于非常量string(),你现在可以调用
data()吧底层的字符序列当做原生C字符串来访问。
auto cstr = mystring.data();
cstr[6] = 'w'; // OKchar *cstr = mystring.data(); // OK
7. 多线程和并发
7.1 补充的互斥量和锁
7.1.1 scoped_lock
C++11引入了一个简单的lock_guard来实现RAII风格的互斥量上锁:
- 构造函数上锁
- 析构函数解锁
不幸的是,没有标准化的可变参数模板可以用来在一条语句中同时锁住多个互斥量。
scoped_lock解决了这个问题。它允许我们同时锁住一个或多个互斥量,互斥量的类型可以不同。
int main()
{vector<string> alllssues;mutex alllssuesMx;vector<string> openlssues;timed_mutex openlssuesMx;// 同时锁住两个issue列表{scoped_lock lg(alllssuesMx, openlssuesMx);// .. 操作}
}
类似于一下C++11代码:
// 同时锁住两个issue列表
{lock(alllssuesMx, openlssuesMx); // 避免死锁的方式上锁lock_guard<mutex> lg1(alllssuesMx, adopt_lock);lock_guard<timed_mutex> lg2(openlssuesMx, adopt_lock);// .. 操作
}
因此,当传入的互斥量超过一个时,scoped_lock的构造函数会使用可变参数的快捷函数lock(),这个函数会保证不会导致死锁。
注意你也可以传递已经被锁住的互斥量
// 同时锁住两个issue列表
{lock(alllssuesMx, openlssuesMx); // 避免死锁的方式上锁scoped_lock lg{adpot_lock, alllssuesMx, openlssuesMx};// .. 操作
}
7.1.2 shared_mutex
C++14添加了一个shared_timed_mutex来支持读/写锁,它支持多个线程同时读一个值,偶尔会有一个线程更改值。现在引入了shared_mutex,定义在头文件<shared_mutex>。
支持以下操作:
- 对于独占锁:lock()、try_lock()、unlock()
- 对于共享的读访问:lock_shared()、try_lock_shared()、unlock_shared()
- native_handle()
假设你有一个共享的vector,被多个线程读取,偶尔会被修改:
vector<double> v; // 共享的资源
shared_mutex vMutex;int main()
{if (shared_lock sl(vMutex); v.size() > 0){// 共享读权限}{scoped_lock sl(vMutex);// 独占写权限}
}
7.2 原子类型的is_always_lock_free
你现在可以使用一个C++库的特性来检查一个特定的原子类型是否总是可以在无锁的情况下使用。例如:
if constexpr(atomic<int>::is_always_lock_free)
{// ...
}
else
{// ...
}
如果一个原子类型的is_always_lock_free返回true,那么该类型的对象is_lock_free()成员也一定会返回true:
if constexpr(atomic<T>::is_always_lock_free)
{assert(atomicT>{}.is_lock_free()); // 绝不会失败
}
在C++17之前,只能使用相应的宏来判断,例如当ATOMIC_INT_LOCK_FREE返回2的时候相当于is_always_lock_free返回true。
7.3 cache行大小
程序有时候需要处理cache行大小的能力有以下两种:
- 不同线程访问的不同对象不属于同一个cache是很重要的。否则,不同线程并行访问对象时cache行缓存的内存可能需要同步。
- 你可能会想把多个对象放在同一个cache行中,这样访问了第一个对象之后,访问接下来的对象就可以直接在cache行中访问。
C++标准库在头文件中引入了两个内联变量:
namespace std
{inline constexpr size_t hardware_destructive_interference_size; // 可能被不同线程并发访问的两个对象之间的最小偏移量inline constexpr size_t hardware_constructive_interference_size; // 两个想被放在同一个L1缓存行的对象合起来的最大大小
}
如果你想要在不同的线程里访问两个不同(原子)的对象:
struct Data
{alignas(std::hardware_destructive_interference_size) int valueForThreadA;alignas(std::hardware_destructive_interference_size) int valueForThreadB;
};
如果你想要在同一个线程里访问不同的(原子)对象
struct Data {int valueForThraedA;int otherValueForTheThreadA;
};
8. 标准库中其他微小的修改和特性
8.1 std::uncaught_exceptions()
C++中存在一个模式RAII,这是一种安全处理那些你必须要释放或清理的资源的方式。在构造一个对象的时候将所需要的资源分配给它,在析构中将分配的资源进行释放。
然而,有的时候资源的“释放操作”依赖于我们到底是正常执行离开了作用域还是因为异常离开了作用域。一个例子是事务性资源,如果我们正常执行离开了作用域,我们可能想进行提交操作,而当因为异常离开作用域时想进行回滚操作。为了达到这个目的,C++11引入了std::uncaught_expection(),用法如下:
class Request
{
public:~Request(){if(std::uncaught_expection()) rollback(); // 如果没有异常情况会调用rollback()else commit();}
};
然而,在如下场景中使用这个API不能正常工作,当我们正在处理异常时,如果创建了新的Request对象,那么即使在使用它的期间没有异常抛出,它的析构函数总是会调用rollback()。
try
{...
}
catch(...)
{Request r2{...};
}
C++17解决了这个问题,对Request类进行以下修改:
class Request
{
private:int initialUncaught{std::uncaught_expections()};
public:~Request(){if(std::uncaught_expections() > initialUncaught) rollback(); // 如果没有异常情况会调用rollback()else commit();}
};
旧的不带s的API自C++17起被废弃,不应该再被使用。
8.2 共享指针的改进
C++17添加了一些共享指针的改进,且成员函数unique()已经被废弃了。
8.2.1 对原生C数组的共享指针的特殊处理
自从C++17起可以对其使用特定的deleter函数,C++11unique_ptr已经可以做到了,例如:
std::shared_ptr<std::string> p{new std::string[10], [](std::string* p){delete[] p;
}};
当实例化是数组时,不再使用operator*,而是使用operator[]:
std::shared_ptr<std::string> ps{new std::string};
*ps = "hello"; // OK
ps[0] = "hello"; // ERRORstd::shared_ptr<std::string[]> parr{new std::string[10]};
*parr = "hello"; // ERROR
parr[0] = "hello"; // OK
8.2.2 共享指针的reinterpret_pointer_cast
除了static_pointer_cast、dynamic_pointer_cast、const_pointer_cast之外,可以调用reinterpret_pointer_cast。
8.2.3 共享指针的weak_type
为了支持在泛型代码中使用弱指针,共享指针提供了一个新的成员weak_type。例如:
template<typename T>
void ovserve(T sp)
{typename T::weak_type wp{sp};
}
8.2.4 共享指针的weak_from_this
C++17起,有一个额外的辅助函数可以返回一个指向对象的弱指针:
Person *pp = new Person{};
std::shared_ptr<Person> sp{pp};std::weak_ptr<Person> wp{pp->weak_from_this()}; // wp分享了sp拥有的所有权
8.3 数学拓展
C++17引入了以下的数学函数。
8.3.1 最大公约数和最小公倍数
在头文件<numeric>中:
- gcd(x, y) 返回x和y的最大公约数
- lcm(x, y) 返回x和y的最小公倍数
8.3.2 std::hypot()的三参数重载
在头文件<cmath>中:
- hypot(x, y, z) 返回三个参数的平方之和的平方根
8.3.3 数学中的特殊函数
| 名称 | 含义 |
|---|---|
| assoc_laguerre() | 关联Laguerre多项式 |
| assoc_legendre() | 关联Legendre函数 |
| beta() | beta函数 |
| comp_ellint_1() | 第一类完整椭圆积分 |
| comp_ellint_2() | 第二类完整椭圆积分 |
| comp_elint_3() | 第三类完整椭圆积分 |
| cyl_bessel_i() | 规则圆柱贝塞尔函数 |
| cyl_bessel_j() | 第一类圆柱贝塞尔函数 |
| cyl_bessel_k() | 不规则圆柱贝塞尔函数变体 |
| cyl_neumann() | 圆柱诺依曼函数 |
| ellint_1() | 第一类不完整椭圆积分 |
| elint_2() | 第二类不完整椭圆积分 |
| elint_3() | 第三类不完整椭圆积分 |
| expint() | 指数积分 |
| hermite() | Hermite多项式 |
| laguerre() | Laguerre多项式 |
| legendre() | Legendre多项式 |
| riemann_zeta() | 黎曼zeta函数 |
| sph_bessel() | 第一类球形贝塞尔函数 |
| sph_legendre() | 关联球形Legendre函数 |
| sph_neumann() | 球形诺依曼函数 |
8.3.4 chrono拓展
对于时间段和时间点添加了新的舍入函数:
- round(): 舍入到最近的整数值
- floor(): 向负无穷舍入到最近的整数值(向下取整)
- ceil(): 向正无穷舍入到最近的整数值(向上取整)
8.3.5 constexpr拓展和修正
最重要的修正有:
- 对于std::array,下面的函数是constexpr:
- begin()、end()、cbegin()、cend()、rbegin()、rend()、crbegin()、crend()
- 非常量数组的operator[]、at()、front()、back()
- data()
- 范围访问的泛型独立函数和辅助函数。
- 类std::reverse_iterator和std::move_iterator的所有操作
- C++标准库整个时间库的部分。
- 所有的std::char_traits特化的成员函数。
8.3.6 noexpect拓展和修正
最重要的修正有:
- std::vector<>和std::string,C++17保证下列操作不会抛出异常
- 默认构造函数
- 移动构造函数
- 以分配器为参数的构造函数
- 对于所有的容器,下列操作不会抛出异常:
- 移动赋值运算符
- swap函数
相关文章:
已有标准库的拓展和修改)
C++17新特性(四)已有标准库的拓展和修改
这一部分介绍C17对已有标准库组件的拓展和修改。 1. 类型特征拓展 1.1 类型特征后缀_v 自从C17起,对所有返回值的类型特征使用后缀_v,例如: std::is_const_v<T>; // C17 std::is_const<T>::value; // C11这适用于所有返回值的…...
软件是什么?前端,后端,数据库
软件是什么? 由于很多东西没有实际接触,很难理解,对于软件的定义也是各种各样。但是我还是不理解,软件开发中的前端,后端,数据库到底有什么关系呢! 这个问题足足困扰了三年半,练习时…...
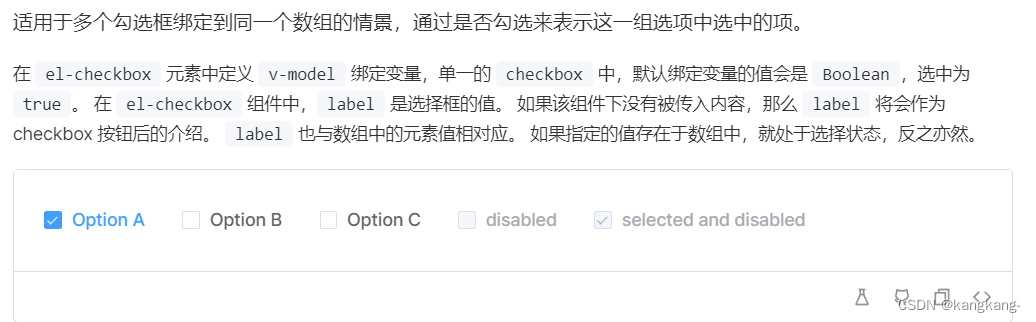
Vue3+ElementUI 多选框中复选框和名字点击方法效果分离
现在的需求为 比如我点击了Option A ,触发点击Option A的方法,并且复选框不会取消勾选,分离的方法。 <el-checkbox-group v-model"mapWork.model_checkArray.value"> <div class"naipTypeDom" v-for"item …...

设计模式篇章(4)——十一种行为型模式
这个设计模式主要思考的是如何分配对象的职责和将对象之间相互协作完成单个对象无法完成的任务,这个与结构型模式有点像,结构型可以理解为静态的组合,例如将不同的组件拼起来成为一个更大的组件;而行为型更是一种动态或者具有某个…...
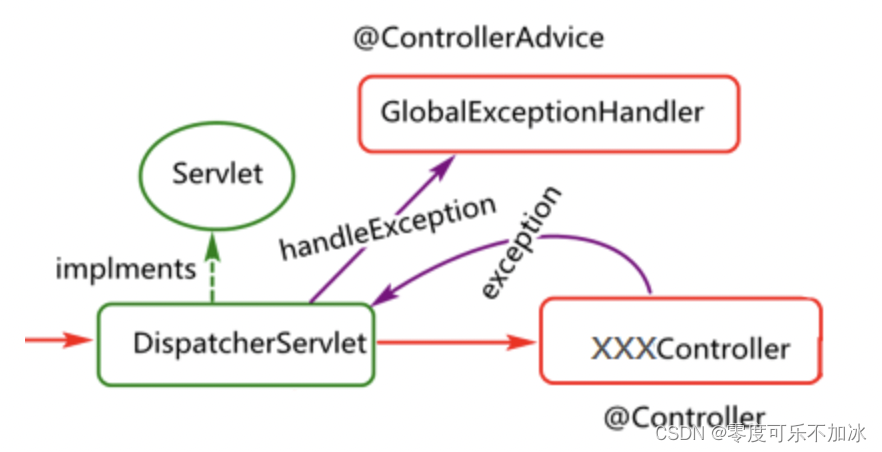
Spring成长之路—Spring MVC
在分享SpringMVC之前,我们先对MVC有个基本的了解。MVC(Model-View-Controller)指的是一种软件思想,它将软件分为三层:模型层、视图层、控制层 模型层即Model:负责处理具体的业务和封装实体类,我们所知的service层、poj…...
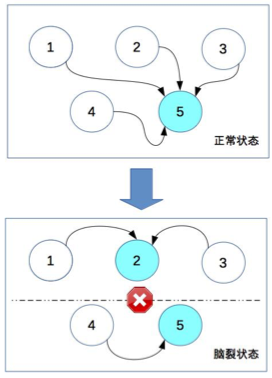
架构篇05-复杂度来源:高可用
文章目录 计算高可用存储高可用高可用状态决策小结 今天,我们聊聊复杂度的第二个来源高可用。 参考维基百科,先来看看高可用的定义。 系统无中断地执行其功能的能力,代表系统的可用性程度,是进行系统设计时的准则之一。 这个定义…...

C#调用Newtonsoft.Json将bool序列化为int
使用Newtonsoft.Json将数据对象序列化为Json字符串时,如果有布尔类型的属性值时,一般会将bool类型序列化为字符串,true值序列化为true,false值序列化为false。如下面的类型序列化后的结果如下: public class UserInfo…...

【Linux系统编程】环境变量详解
文章目录 1. 环境变量的基本概念2. 如何理解呢?(测试PATH)2.1 切入点1查看具体的环境变量原因剖析常见环境变量 2.2 切入点2给PATH环境变量添加新路径将我们自己的命令拷贝到PATH已有路径里面 2.3 切入点3 3. 显示所有环境变量4. 测试HOME5. …...

智能合约介绍
莫道儒冠误此生,从来诗书不负人 目录 一、什么是区块链智能合约? 二、智能合约的发展背景 三、智能合约的优势 四、智能合约的劣势 五、一些关于智能合约的应用 总结 一、什么是区块链智能合约? 智能合约,是一段写在区块链上的代码,一…...
Python自动化实战之接口请求的实现
在前文说过,如果想要更好的做接口测试,我们要利用自己的代码基础与代码优势,所以该章节不会再介绍商业化的、通用的接口测试工具,重点介绍如何通过 python 编码来实现我们的接口测试以及通过 Pycharm 的实际应用编写一个简单接口测…...

react和vue的区别
一、核心思想不同 Vue的核心思想是尽可能的降低前端开发的门槛,是一个灵活易用的渐进式双向绑定的MVVM框架。 React的核心思想是声明式渲染和组件化、单向数据流,React既不属于MVC也不属于MVVM架构。 如何理解React的单向数据流? React的单…...

Spring 中有哪些方式可以把 Bean 注入到 IOC 容器?
目录 1、xml方式2、CompontScan Component3、使用 Bean方式4、使用Import 注解5、FactoryBean 工厂 bean6、使用 ImportBeanDefinitionRegistrar 向容器中注入Bean7、实现 ImportSelector 接口 1、xml方式 使用 xml 的方式来声明 Bean 的定义,Spring 容器在启动的…...

客户需求,就是项目管理中最难管的事情
对于需求控制和管理 个人的观点是:首先要向客户传递开发流程,第二必须制作原型,需求确认时确认的是原型,而不是需求文档,第三,开发阶段要快速迭代,与客户互动。管人方面我想对于项目经理来讲&am…...

条款28:避免返回 handles 指向对象的内部成分
创建一个矩形的类(Rectangle),为保持Rectangle对象较小,可以只在其对象中保存一个指针,用于指向辅助的结构体,定义其范围的点数据存放在辅助的结构体中: class Point { // 表示点的类 public:P…...
)
【人工智能】之深入理解 AI Agent:超越代码的智能助手(2)
人工智能(AI)正在以前所未有的速度迅猛发展,而AI Agent(智能代理)则是这一领域中备受瞩目的一环。AI Agent 不仅仅是程序的执行者,更是能够感知、学习和交互的智能实体。本文将深入探讨什么是 AI Agent&…...

如何将一个字符串转换为整数?
目录 1. 基本方法:int() 函数 2. 错误处理 3. 性能考虑 4. 实用技巧 结论 在Python中,将字符串转换为整数是一个常见且重要的操作。这种转换通常在处理用户输入、解析文本数据或在不同数据类型间进行转换时使用。以下是从几个方面对这个主题的详细介…...

【鸿蒙4.0】harmonyos Day 04
文章目录 一.Button按钮组件1.声明Button组件,label是按钮文字2.添加属性和事件 二.Slider滑动条组件 一.Button按钮组件 1.声明Button组件,label是按钮文字 Button(label?:ResourceStr) // ResourceStr:可以是普通字符串,也可以是引用定义…...
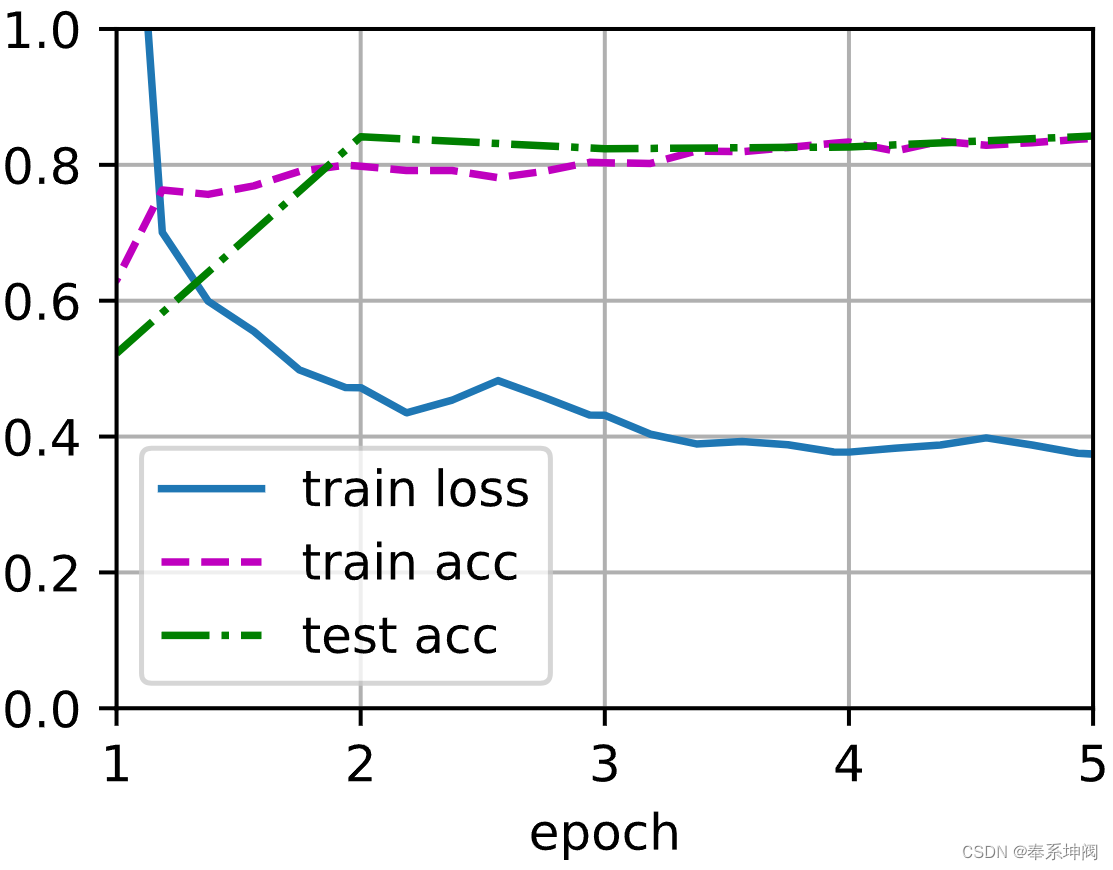
微调(fine-tuning)
目录 一、微调 1、为什么需要微调 2、微调的步骤 二、代码实现 1、获取数据集 2、读取图像 3、数据增广 4、定义和初始化模型 5、定义训练函数 三、总结 一、微调 1、为什么需要微调 Fashion-MNIST有6万张图像,学术界当下使用最广泛的大规模图像数据集Ima…...
Find My卡片正成为消费电子香饽饽,伦茨科技ST17H6x可以帮到您
今年CES许多公司发布支持苹果Find My的卡片产品,这种产品轻薄可充电,放在钱包、背包或者手提包可以防丢查找,在智能化加持下,防丢卡片使得人们日益关心自行车的去向。最新的防丢卡片与苹果Find My结合,智能防丢&#x…...

Es bulk批量导入数据(1w+以上)
最近在学习es的理论知识以及实际操作,随时更新~ 概要:首先你得有1w条数据的json,然后用java读取json文件导入 一. 创建Json数据 首先我生成1.5w条数据,是为了实践分页查询,用from-size和scroll翻页去实践 生成四个字段…...

社会风气何以如此?渡劫未彻底,继续渡劫。从为人民服务到为节点服务
社会风气何以如此?渡劫未彻底,继续渡劫。从为人民服务到为节点服务。 Jianbing Zhu 1 1 ECT-OS-JiuHuaShan 文明实践室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20302480 Email: ect-os-jiuhuashanzohomail.cn 预印本提交:202…...

物联网数据采集网关实战:从协议解析到边缘计算的完整指南
1. 项目概述:从“黑盒子”到“数据枢纽”的蜕变 在物联网的世界里,传感器是感知世界的“神经末梢”,而物联网网关,则是连接这些神经末梢与云端大脑的“神经中枢”。很多人觉得它像个神秘的黑盒子,插上线,数…...
)
遥感图像处理实战:用Python+OpenCV实现同态滤波与小波变换去薄云(附完整代码与效果对比)
遥感图像去云实战:Python实现同态滤波与小波变换的深度对比 薄云覆盖是遥感图像处理中的常见挑战,它会降低图像对比度、模糊地物细节,直接影响后续的地物分类和环境监测精度。本文将带您用Python实现两种经典的去云算法——同态滤波与小波变换…...

LeetCode 数据流中第K大元素题解
LeetCode 数据流中第K大元素题解 题目描述 设计一个数据流,找到数据流中第 k 大的元素。 示例: 输入:k 3, arr [4,6,5]输出:5 解题思路 方法:堆 思路: 使用最小堆维护前 k 大的元素。遍历数据流ÿ…...

FanControl:Windows平台终极风扇控制解决方案
FanControl:Windows平台终极风扇控制解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCont…...

保姆级教程:用Wireshark抓包搞定Velodyne VLP-16激光雷达的IP配置与网络调试
从数据包到点云:Wireshark深度解析Velodyne VLP-16网络配置全流程 当你第一次拿到Velodyne VLP-16激光雷达时,那种兴奋感很快会被网络配置的挫败感取代——明明按照教程设置了IP,却始终ping不通设备,浏览器访问后台更是天方夜谭。…...

从协议到实战:深度剖析WiFi Deauth攻击的底层原理与Kali工具链应用
1. WiFi Deauth攻击的本质:从协议层理解管理帧 当你用手机连接咖啡厅的WiFi时,背后其实在进行一场精密的无线协议对话。802.11标准中定义了三种关键帧类型:数据帧负责传输网页内容,控制帧协调信道占用,而管理帧则是连…...

Upscayl终极指南:如何用免费AI工具让模糊图片变高清
Upscayl终极指南:如何用免费AI工具让模糊图片变高清 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl 你是否曾因照…...

专业音频捕获终极指南:OBS-ASIO插件3步实现超低延迟录音
专业音频捕获终极指南:OBS-ASIO插件3步实现超低延迟录音 【免费下载链接】obs-asio ASIO plugin for OBS-Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-asio 在专业音频制作和直播领域,实现毫秒级延迟的音频捕获是确保音视频完美同步…...
)
用GNU Radio和USRP N310/X310手把手搭建一个雷达通信一体化系统(附完整GRC流程图)
从零构建基于GNU Radio与USRP的雷达通信融合系统实战指南 在软件定义无线电(SDR)技术蓬勃发展的今天,将雷达探测与无线通信功能集成到同一硬件平台已成为可能。这种一体化设计不仅能降低设备成本,还能实现频谱资源共享,…...