微调(fine-tuning)
目录
一、微调
1、为什么需要微调
2、微调的步骤
二、代码实现
1、获取数据集
2、读取图像
3、数据增广
4、定义和初始化模型
5、定义训练函数
三、总结
一、微调
1、为什么需要微调
Fashion-MNIST有6万张图像,学术界当下使用最广泛的大规模图像数据集ImageNet有超过1000万的图像和1000类的物体。然而,我们平常接触到的数据集的规模通常在这两者之间。
假如我们想识别图片中不同类型的椅子,然后向用户推荐购买链接。一种可能的方法是首先识别100把普通椅子,为每把椅子拍摄1000张不同角度的图像,然后在收集的图像数据集上训练一个分类模型。尽管这个椅子数据集可能大于Fashion-MNIST数据集,但实例数量仍然不到ImageNet中的十分之一。适合ImageNet的复杂模型可能会在这个椅子数据集上过拟合。此外,由于训练样本数量有限,训练模型的准确性可能无法满足实际要求。
为了解决上述问题,一个显而易见的解决方案是收集更多的数据。但是,收集和标记数据可能需要大量的时间和金钱。例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究资金。尽管目前的数据收集成本已大幅降低,但这一成本仍不能忽视。
另一种解决方案是应用迁移学习(transfer learning)将从源数据集学到的知识迁移到目标数据集。例如,尽管ImageNet数据集中的大多数图像与椅子无关,但在此数据集上训练的模型可能会提取更通用的图像特征,这有助于识别边缘、纹理、形状和对象组合。这些类似的特征也可能有效地识别椅子。
其实总结一下就是:我们想将复杂模型用在数量较少的简单数据上面,因为复杂的模型可能有助于提取更多的特征,但是如果直接使用复杂模型在简单数据集上进行训练的话,很有可能导致过拟合,因此我们使用在复杂数据集上训练过的权重在简单数据集上再次训练(微调)。
2、微调的步骤
微调(fine-tuning)是迁移学习的常见步骤,微调包括以下四个步骤。
- 在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
- 向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。

当目标数据集比源数据集小得多时,微调有助于提高模型的泛化能力。
二、代码实现
让我们通过具体案例演示微调:热狗识别。我们将在一个小型数据集上微调ResNet模型。该模型已在ImageNet数据集上进行了预训练。这个小型数据集包含数千张包含热狗和不包含热狗的图像,我们将使用微调模型来识别图像中是否包含热狗。
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l1、获取数据集
我们使用的热狗数据集来源于网络。该数据集包含1400张热狗的“正类”图像,以及包含尽可能多的其他食物的“负类”图像。含着两个类别的1000张图片用于训练,其余的则用于测试。
解压下载的数据集,我们获得了两个文件夹`hotdog/train`和`hotdog/test`。这两个文件夹都有`hotdog`(有热狗)和`not-hotdog`(无热狗)两个子文件夹,子文件夹内都包含相应类的图像。
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')data_dir = d2l.download_extract('hotdog')
print(data_dir)..\data\hotdog2、读取图像
我们创建两个实例来分别读取训练和测试数据集中的所有图像文件。
print(os.path.join(data_dir, 'train'))
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
print(train_imgs[0])
print(train_imgs[999])
print(train_imgs[1000])
print(train_imgs[1999])
print(train_imgs.classes)
print(train_imgs.class_to_idx)..\data\hotdog\train
(<PIL.Image.Image image mode=RGB size=122x144 at 0x217A3E10C70>, 0)
(<PIL.Image.Image image mode=RGB size=180x268 at 0x217A3E107F0>, 0)
(<PIL.Image.Image image mode=RGB size=133x183 at 0x217A3E10C10>, 1)
(<PIL.Image.Image image mode=RGB size=91x141 at 0x217A3E10AF0>, 1)
['hotdog', 'not-hotdog']
{'hotdog': 0, 'not-hotdog': 1}torchvision.datasets.ImageFolder()
torchvision.datasets.ImageFolder是PyTorch中用于加载图像数据集的类,它假定图像数据按照类别分组存储在文件夹中。
ImageFolder类提供了一种方便的方式来加载和处理这种按类别组织的图像数据集。它会自动将每个类别的图像分配一个标签,并提供了对图像数据进行预处理和转换的选项。
使用ImageFolder类加载图像数据集通常需要两个参数:
- root:数据集的根目录,包含按类别分组的子文件夹。
- transform(可选):对图像数据进行预处理和转换的操作。
ImageFolder类会自动根据子文件夹的名称为每个类别分配一个标签,并提供了方便的接口来访问图像数据和标签信息。可以通过dataset.classes属性获取所有类别的名称,通过dataset.class_to_idx属性获取类别与标签的对应关系。
下面显示了前8个正类样本图片和最后8张负类样本图片。正如所看到的,图像的大小和纵横比各有不同。
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)array([<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>],dtype=object)
3、数据增广
在训练期间,我们首先从图像中裁切随机大小和随机长宽比的区域,然后将该区域缩放为 输入图像。在测试过程中,我们将图像的高度和宽度都缩放到256像素,然后裁剪中央
区域作为输入。此外,对于RGB(红、绿和蓝)颜色通道,我们分别标准化每个通道。具体而言,该通道的每个值减去该通道的平均值,然后将结果除以该通道的标准差。
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # [0.485, 0.456, 0.406]和[0.229, 0.224, 0.225]是在ImageNet数据集上计算得出的均值和标准差train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(224), # 随机裁剪(随机大小和长宽比),然后缩放到224×224torchvision.transforms.RandomHorizontalFlip(), # 随机上下翻转torchvision.transforms.ToTensor(),normalize])test_augs = torchvision.transforms.Compose([torchvision.transforms.Resize([256, 256]), # 将图像的宽和高缩放到256×256torchvision.transforms.CenterCrop(224), # 裁剪图像中央224×224区域torchvision.transforms.ToTensor(),normalize])torchvision.transforms.Normalize()
在图像处理中,归一化(Normalization)是一种常见的预处理步骤,用于将图像数据缩放到一个合适的范围,以便更好地适应深度学习模型的训练。一种常见的归一化方法是将图像的每个像素值减去均值,然后除以标准差。
在PyTorch中,torchvision.transforms.Normalize用于执行这种归一化操作,它需要两个参数:
- mean:一个包含三个元素的列表或元组,表示图像在每个通道上的均值。
- std:一个包含三个元素的列表或元组,表示图像在每个通道上的标准差。
对于数据[0.485, 0.456, 0.406]和[0.229, 0.224, 0.225],它们是在ImageNet数据集上计算得出的经验值。ImageNet是一个大规模的图像分类数据集,包含超过100万张图像和1000个类别。这些值是通过对ImageNet数据集中所有图像的像素值进行计算得出的。
通过将图像数据集归一化到这些均值和标准差,可以使输入的图像数据分布接近于标准正态分布,有助于提高模型的训练效果和收敛速度。
需要注意的是,使用torchvision.transforms.Normalize进行归一化时,通常需要先将图像数据从整数范围(例如[0, 255])转换为浮点数范围(例如[0.0, 1.0]),然后再应用归一化操作。
torchvision.transforms.Resize()
torchvision.transforms.Resize是PyTorch中的一个数据转换函数,用于调整图像的大小。
该函数可以将输入的图像调整为指定的大小。它通常用于数据预处理或数据增强的过程中,以适应模型的输入要求或统一数据集中图像的尺寸。
Resize函数的主要参数包括:
- size:一个整数或元组,指定调整后的图像大小。如果是一个整数,则调整后的图像将是一个正方形,边长为该整数。如果是一个元组,可以指定图像的宽度和高度。
- interpolation:插值方法的名称,用于调整图像的大小。默认为PIL.Image.BILINEAR。
torchvision.transforms.RandomResizedCrop()
torchvision.transforms.RandomResizedCrop是PyTorch中的一个数据转换函数,它用于随机裁剪和调整图像的大小。
该函数可以在图像上进行随机裁剪,并将裁剪后的图像调整为指定的大小。它通常用于数据增强(data augmentation)的过程中,以增加训练数据的多样性,提高模型的泛化能力。
RandomResizedCrop函数的主要参数包括:
- size:一个整数或元组,指定裁剪后的图像大小。如果是一个整数,则裁剪后的图像将是一个正方形,边长为该整数。如果是一个元组,可以指定图像的宽度和高度。
- scale:一个范围在(0, 1]之间的浮点数或元组。指定随机裁剪的尺度范围。如果是一个浮点数,则裁剪尺度的范围为[0.08, 1.0]乘以给定的浮点数。如果是一个元组,则裁剪尺度的范围为包含两个浮点数的元组。
- ratio:一个范围在(0, 1]之间的浮点数或元组。指定随机裁剪的宽高比范围。如果是一个浮点数,则宽高比的范围为[3/4, 4/3]乘以给定的浮点数。如果是一个元组,则宽高比的范围为包含两个浮点数的元组。
- interpolation:插值方法的名称,用于调整图像的大小。默认为PIL.Image.BILINEAR。
torchvision.transforms.CenterCrop()
torchvision.transforms.CenterCrop是PyTorch中的一个数据转换函数,用于对图像进行中心裁剪。
该函数可以从输入的图像中心位置开始裁剪出指定大小的图像区域。它通常用于数据预处理或数据增强的过程中,以提取感兴趣的图像区域或将图像调整为模型所需的输入大小。
CenterCrop函数的主要参数包括:
- size:一个整数或元组,指定裁剪后的图像大小。如果是一个整数,则裁剪后的图像将是一个正方形,边长为该整数。如果是一个元组,可以指定图像的宽度和高度。
需要注意的是,中心裁剪会从图像的中心位置开始裁剪。如果裁剪的目标大小大于原始图像的尺寸,那么裁剪将不会进行,而是返回原始图像。
torchvision.transforms.Compose()
torchvision.transforms.Compose是PyTorch中的一个数据转换函数,用于将多个数据转换操作组合成一个序列。
该函数允许用户将多个数据转换操作按顺序组合起来,以便在数据预处理或数据增强的过程中一次性应用多个转换操作。
Compose函数的主要参数是一个转换操作列表,其中每个元素都是一个数据转换函数。转换操作按照列表中的顺序依次应用。
4、定义和初始化模型
我们使用在ImageNet数据集上预训练的ResNet-18作为源模型。在这里,我们指定pretrained=True以自动下载预训练的模型参数。如果首次使用此模型,则需要连接互联网才能下载。
pretrained_net = torchvision.models.resnet18(pretrained=True)Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to C:\Users\32343/.cache\torch\hub\checkpoints\resnet18-f37072fd.pth
100.0%预训练的源模型实例包含许多特征层和一个输出层`fc`。此划分的主要目的是促进对除输出层以外所有层的模型参数进行微调。下面给出了源模型的成员变量`fc`。
print(pretrained_net)
print(pretrained_net.fc)ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer2): Sequential((0): BasicBlock((conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer3): Sequential((0): BasicBlock((conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer4): Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(fc): Linear(in_features=512, out_features=1000, bias=True)
)
Linear(in_features=512, out_features=1000, bias=True)在ResNet的全局平均池化层后,全连接层转换为ImageNet数据集的1000个类输出。之后,我们构建一个新的神经网络作为目标模型。它的定义方式与预训练源模型的定义方式相同,只是最终层中的输出数量被设置为目标数据集中的类数(而不是1000个)。
在下面的代码中,目标模型`finetune_net`中成员变量`features`的参数被初始化为源模型相应层的模型参数。由于模型参数是在ImageNet数据集上预训练的,并且足够好,因此通常只需要较小的学习率即可微调这些参数。
成员变量`output`的参数是随机初始化的,通常需要更高的学习率才能从头开始训练。假设`Trainer`实例中的学习率为 ,我们将成员变量`output`中参数的学习率设置为
。
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight)Parameter containing:
tensor([[-0.0457, -0.0440, -0.0474, ..., -0.0762, -0.0579, -0.0520],[ 0.0756, -0.0640, 0.0198, ..., -0.0638, 0.0664, -0.0262]],requires_grad=True)5、定义训练函数
首先,我们定义了一个训练函数`train_fine_tuning`,该函数使用微调,因此可以多次调用。
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),batch_size=batch_size, shuffle=True)test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),batch_size=batch_size)devices = d2l.try_all_gpus()loss = nn.CrossEntropyLoss(reduction="none") # 交叉熵损失if param_group:params_1x = [param for name, param in net.named_parameters()if name not in ["fc.weight", "fc.bias"]] # 保留非最后一层的权重trainer = torch.optim.SGD([{'params': params_1x}, # 特征提取层权重较小,全连接层权重较大,然后使用权重衰减{'params': net.fc.parameters(),'lr': learning_rate * 10}],lr=learning_rate, weight_decay=0.001)else:trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices) 关于net.named_parameters()的用法可参考:Pytorch神经网络的参数管理-CSDN博客文章浏览阅读230次。本文介绍了Pytorch中参数的访问与初始化,主要是权重与偏置参数的访问与初始化https://blog.csdn.net/m0_56312629/article/details/135058101 关于权重衰减(weight-decay)的用法可参考:
权重衰减(Weight Decay)-CSDN博客文章浏览阅读154次。本文讲了权重衰减(权重衰退)的数学原理和具体使用方法_权重衰减https://blog.csdn.net/m0_56312629/article/details/135034852 我们使用较小的学习率,通过微调预训练获得的模型参数。
train_fine_tuning(finetune_net, 5e-5)loss 0.220, train acc 0.915, test acc 0.939
999.1 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
为了进行比较,我们定义了一个相同的模型,但是将其所有模型参数初始化为随机值。由于整个模型需要从头开始训练,因此我们需要使用更大的学习率。
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)loss 0.374, train acc 0.839, test acc 0.843
1623.8 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]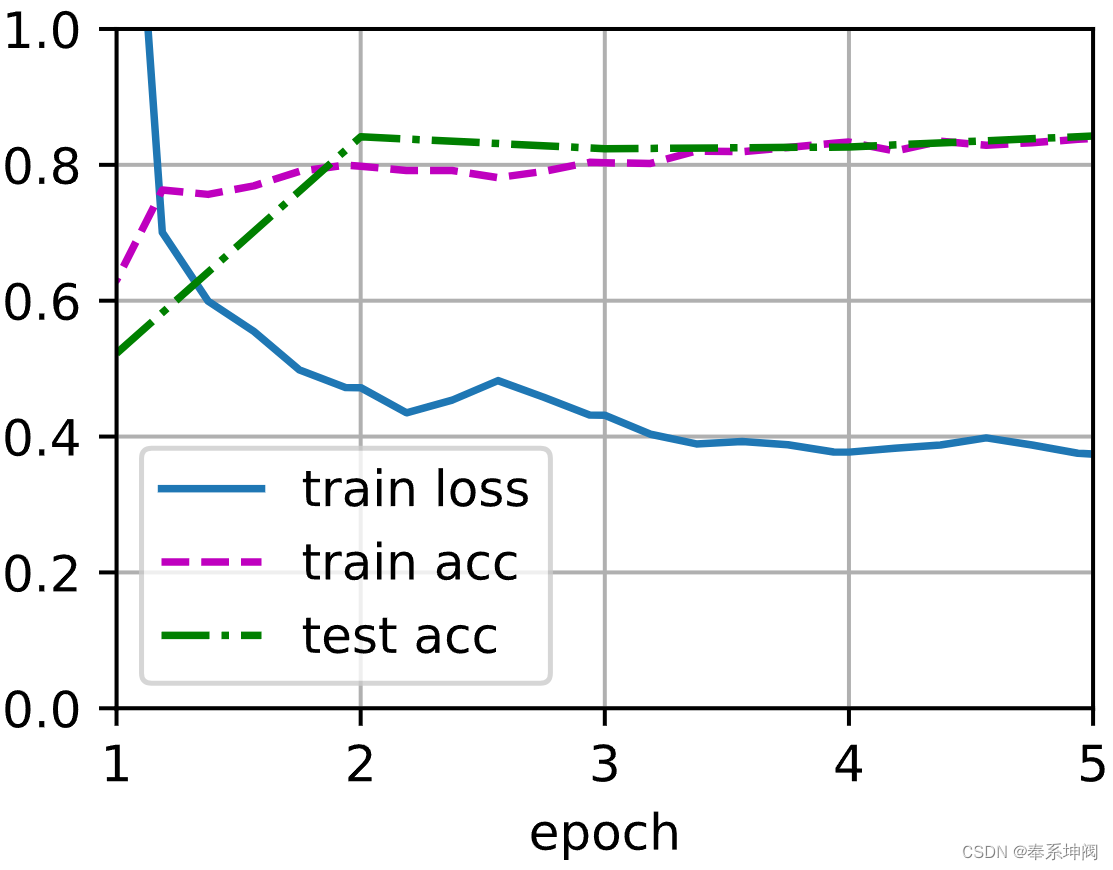
意料之中,微调模型往往表现更好,因为它的初始参数值更有效。
三、总结
- 迁移学习将从源数据集中学到的知识迁移到目标数据集,微调是迁移学习的常见技巧。
- 除输出层外,目标模型从源模型中复制所有模型设计及其参数,并根据目标数据集对这些参数进行微调。但是,目标模型的输出层需要从头开始训练。
- 通常,微调参数使用较小的学习率,而从头开始训练输出层可以使用更大的学习率。
相关文章:
微调(fine-tuning)
目录 一、微调 1、为什么需要微调 2、微调的步骤 二、代码实现 1、获取数据集 2、读取图像 3、数据增广 4、定义和初始化模型 5、定义训练函数 三、总结 一、微调 1、为什么需要微调 Fashion-MNIST有6万张图像,学术界当下使用最广泛的大规模图像数据集Ima…...
Find My卡片正成为消费电子香饽饽,伦茨科技ST17H6x可以帮到您
今年CES许多公司发布支持苹果Find My的卡片产品,这种产品轻薄可充电,放在钱包、背包或者手提包可以防丢查找,在智能化加持下,防丢卡片使得人们日益关心自行车的去向。最新的防丢卡片与苹果Find My结合,智能防丢&#x…...

Es bulk批量导入数据(1w+以上)
最近在学习es的理论知识以及实际操作,随时更新~ 概要:首先你得有1w条数据的json,然后用java读取json文件导入 一. 创建Json数据 首先我生成1.5w条数据,是为了实践分页查询,用from-size和scroll翻页去实践 生成四个字段…...

#laravel 通过手动安装依赖PHPExcel#
场景:在使用laravel框架的时候,需要读取excel,使用 composer install XXXX 安装excel失败,根据报错提示,php不兼容。 因为PHPHExcel使用的php版本 和项目运所需要的php 版本不兼容,php8的版本 解决方法:下载手工安装&a…...
Webpack 基本使用 - 1
Webpack 是什么 webpack 的核心目的是打包,即把源代码一个一个的 js 文件,打包汇总为一个总文件 bundle.js。 基本配置包括mode指定打包模式,entry指定打包入口,output指定打包输出目录。 另外,由于 webpack默认只能打…...

要编译Android 12系统的开机Logo,你需要执行以下步骤:
目录 一、下载了AOSP 1.下载了AOSP 2. 创建一个新的设备制造商目录。 3. 在新创建的device/manufacturer目录中创建一个新的设备目录。 4. 在新创建的设备目录中,创建一个BoardConfig.mk文件。 5. 编辑BoardConfig.mk文件,添加以下内容:…...
【JS逆向学习】36kr登陆逆向案例(webpack)
在开始讲解实际案例之前,大家先了解下webpack的相关知识 WebPack打包 webpack是一个基于模块化的打包(构建)工具, 它把一切都视作模块 webpack数组形式,通过下标取值 !function(e) {var t {};// 加载器 所有的模块都是从这个…...
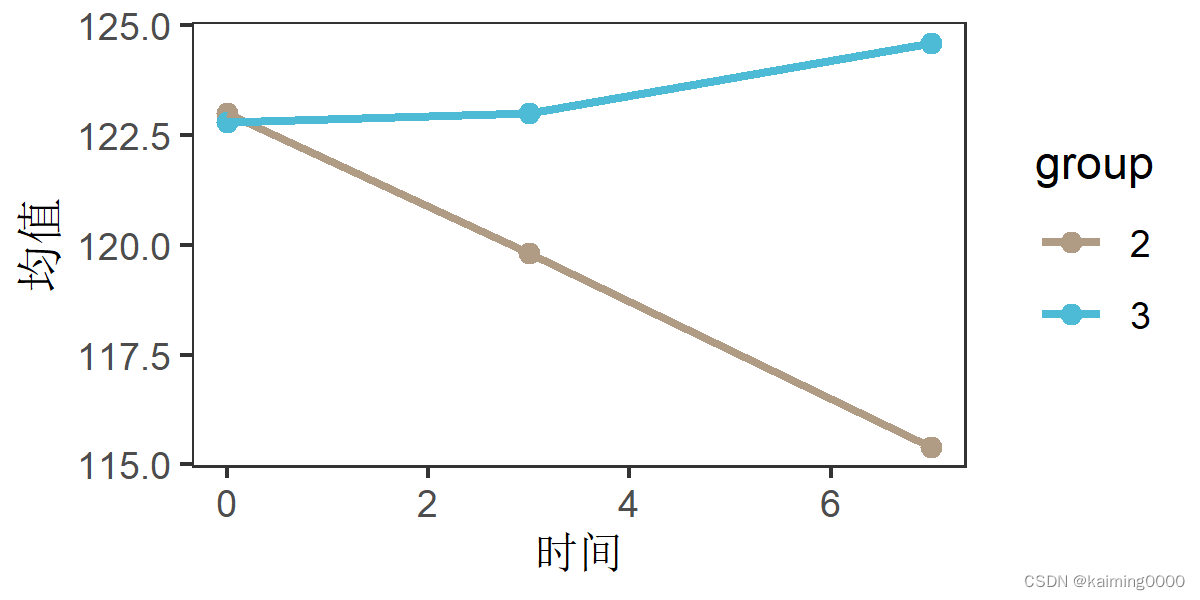
R语言的ggplot2绘制分组折线图?
R绘制分组折线图.R 首先看数据情况:group有3组。Time有3组,数据意思是在3组3个时间点测量了某指标,现在要绘制组1、组2、组3某指标y按时间的变化趋势 数据情况: 看看最终的效果图如下: 下面是本次使用的代码 .libPat…...

[C#]winform部署官方yolov8-obb旋转框检测的onnx模型
【官方框架地址】 https://github.com/ultralytics/ultralytics 【算法介绍】 Yolov8-obb(You Only Look Once version 8 with Oriented Bounding Boxes)是一种先进的对象检测算法,它在传统的Yolov3和Yolov4基础上进行了优化,加…...

Git中config配置
文章目录 简介一、config级别二、config基本配置 简介 Git是一个开源的分布式版本控制系统,用于处理各种规模的项目版本管理。它由Linus Torvalds设计,主要用于Linux内核开发。Git的特点包括速度、简单的设计、对非线性开发模式的支持、完全的分布式能力…...

Java开发安全之:Unreleased Resource: Streams需确保流得到释放
Overview java 中的函数 getResponseBytes() 有时无法成功释放由 getInputStream() 函数分配的系统资源。 Details 程序可能无法成功释放某一项系统资源。 在这种情况下,在某些程序路径上,所分配的资源未释放。 资源泄露至少有两种常见的原因…...
【C++】文件操作
文件操作 一、文本文件(一)写文件读文件 二、二进制文件(一)写文件(二)读文件 程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放,通过文件可以将数据持久化ÿ…...

高效能方法 - 任务清单优先级
任务清单是有优先级的,首先要尽所能保证A级别的事项完成,或许不能估计B级或者C级,那这结果也是不错的。 博恩崔西在《吃掉那只青蛙》一书中指出:在你决定要做什么,并对其进行排序的时候,你首要解决那些最难…...

go 语言爬虫库goquery介绍
文章目录 爬虫介绍goquery介绍利用NewDocumentFromReader方法获取主页信息Document介绍通过查询获取文章信息css选择器介绍goquery中的选择器获取主页中的文章链接 爬取总结 爬虫介绍 爬虫,又称网页抓取、网络蜘蛛或网络爬虫,是一种自动浏览互联网并从网…...

解决 Navicat 在笔记本外接显示器分辨率自适应展示问题
前言 有时候我们使用自己的笔记本电脑会外接一个显示器,但是显示器的分辨率和笔记本又不一样,所以就会导致 Navicat 基于分辨率的问题变得字体很小。具体操作可点击这里: Navicat 分辨率调整...

网络安全产品之认识入侵检测系统
随着计算机网络技术的快速发展和网络攻击的不断增多,单纯的防火墙策略已经无法满足对安全高度敏感的部门的需要,网络的防卫必须采用一种纵深的、多样的手段。因此,入侵检测系统作为新一代安全保障技术,成为了传统安全防护措施的必…...

牛客周赛 Round 10 解题报告 | 珂学家 | 三分模板 + 计数DFS + 回文中心扩展
前言 整体评价 T2真是一个折磨人的小妖精,写了两版DFS,第二版计数DFS才过。T3是三分模板,感觉也可以求导数。T4的数据规模才n1000,因此中心扩展的 O ( n 2 ) O(n^2) O(n2)当仁不让。 A. 游游的最长稳定子数组 滑窗经典题 从某个…...
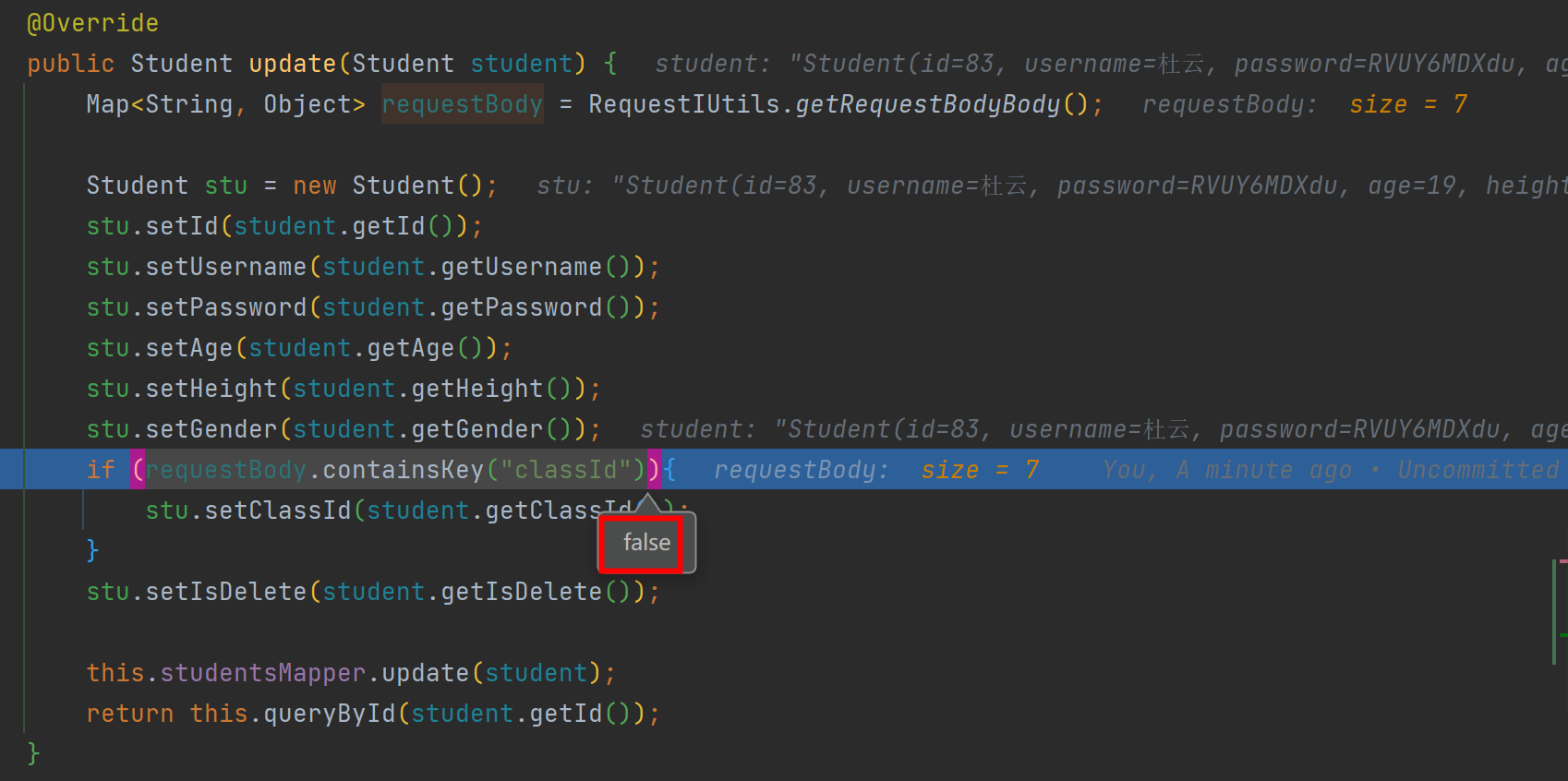
SpringBoot 更新业务场景下,如何区分null是清空属性值 还是null为vo属性默认值?
先看歧义现象 值为null 未传递此属性 所以此时如何区分null 时传递进来的的null,还是属性的默认值null? 引入方案 引入过滤器,中间截获requestBodyData并保存到HttpServletRequest,业务层从HttpServletRequest 获取到requestBodyData辅…...

【深度学习每日小知识】NLP 自然语言处理
自然语言处理 (NLP) 是人工智能 (AI) 的一个子领域,处理计算机和人类(自然)语言之间的交互。它涉及使用算法和统计模型使计算机能够理解、解释和生成人类语言。 NLP 是人工智能领域的重要工具,广泛应用于语言翻译、文本分类和聊天…...

一文理解Python选择语句
在编程领域中,条件判断和选择是非常基础而且重要的一个部分。Python 作为一种被广泛应用的编程语言,提供了多种选择语句来满足不同的条件判断需求。本文将深入探讨 Python 中的选择语句,包括 if 语句、elif 语句、else 语句、简写的条件表达式…...
)
用C语言链表实现一个简易图书管理系统(附完整源码)
从零构建C语言链表图书管理系统:工程化实践指南 当你第一次在数据结构课本上看到链表时,是否觉得这些抽象的概念离实际开发很遥远?作为C语言初学者,我完全理解这种困惑——直到亲手用链表实现了一个真正的图书管理系统。本文将带你…...

还在为百度网盘Mac版龟速下载烦恼?3分钟破解SVIP限制,速度提升70倍!
还在为百度网盘Mac版龟速下载烦恼?3分钟破解SVIP限制,速度提升70倍! 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS …...

Escrcpy终极指南:5分钟掌握Android设备图形化控制与屏幕镜像
Escrcpy终极指南:5分钟掌握Android设备图形化控制与屏幕镜像 【免费下载链接】escrcpy 📱 Display and control your Android device graphically with scrcpy. 项目地址: https://gitcode.com/GitHub_Trending/es/escrcpy 你是否曾经为在电脑上控…...

3分钟快速上手Inter字体:免费开源字体如何提升你的数字产品体验
3分钟快速上手Inter字体:免费开源字体如何提升你的数字产品体验 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为屏幕显示设计的开源无衬线字体,凭借其出色的可读性和多语言…...

PPTXjs:如何在浏览器中免费预览PPTX文件的完整指南
PPTXjs:如何在浏览器中免费预览PPTX文件的完整指南 【免费下载链接】PPTXjs jquery plugin for convertation pptx to html 项目地址: https://gitcode.com/gh_mirrors/pp/PPTXjs 还在为PPT演示文稿的跨平台兼容性而烦恼吗?PPTXjs是一个革命性的…...

谷歌搜索重大更新:更智能个性化,多项新功能即将上线!
谷歌搜索迈向更智能、更个性化时代曾几何时,谷歌搜索简洁易用,只需在搜索框输入关键词,浏览蓝色链接列表即可。然而,如今人工智能已层层覆盖搜索模式。2026 年谷歌 I/O 大会上,谷歌宣布一系列搜索更新,使搜…...

CTF新手必看:一张图里藏了啥?手把手教你用010 Editor秒解BUUCTF图片隐写题
CTF新手入门:从图片隐写题中快速提取Flag的实战指南 当你第一次接触CTF比赛中的图片隐写题时,可能会感到无从下手。那些看似普通的图片背后,往往藏着关键的Flag信息。本文将带你一步步破解BUUCTF平台上的典型图片隐写题,使用010 E…...

智能车竞赛光电组核心技术解析:从图像处理到PID控制
1. 项目概述:从“智能车”到“光电组”的硬核竞技如果你对嵌入式、自动控制或者机器人竞赛感兴趣,那么“智能车竞赛”这个名字你一定不陌生。它远不止是几个大学生拿着遥控车在赛道上跑圈那么简单,而是一个融合了机械、电子、控制、算法和计算…...

查询不准?响应延迟?Perplexity阅读推荐失效全归因,一线SRE团队72小时压测实录
更多请点击: https://intelliparadigm.com 第一章:查询不准?响应延迟?Perplexity阅读推荐失效全归因,一线SRE团队72小时压测实录 问题爆发现场还原 凌晨2:17,Perplexity阅读推荐API的P99延迟突增至8.4s&a…...
大模型面试100问:从Transformer到RAG,互联网大厂AI岗位必备!
本文主要针对想要或者正在从事大语言模型、知识库、搜索增强生成(RAG)的研发、产品和测试同学,在面试中会遇到什么样的问题? 以下主要来自于各位从事大模型研发、产品和测试的伙伴、朋友在面试互联网大厂、AI科技公司的相关AI岗位…...