Elasticsearch+Kibana 学习记录
文章目录
- 安装
- Elasticsearch 安装
- Kibana 安装
- Rest风格API
- 操作索引
- 基本概念
- 示例
- 创建索引
- 查看索引
- 删除索引
- 映射配置(不配置好像也行、智能判断)
- 新增数据
- 随机生成ID
- 自定义ID
- 修改数据
- 删除数据
- 查询
- 基本查询
- 查询所有(match_all)
- 匹配查询(match)
- 多字段查询(multi_match)
- 词条匹配(term)
- 多词条精确匹配(terms)
- 结果过滤
- 高级查询
- 过滤(filter)
- 排序
- 聚合aggregations
- 测试数据准备
- 聚合为桶
- 桶内度量
- 桶内嵌套桶
- 划分桶的其它方式
- 阶梯分桶Histogram Aggregation
- 范围分桶Range Aggregation
- 不同语言客户端代码
其实很早之前在大学学习Java的时候学习过ES,做日志存储用,不过后来在项目里面没被采用,很多年没用过逐渐淡忘了,如今工作需要用到,又得重新看一遍,还是简单再记一下流程及一些使用,方便以后查看~~
【Elasticsearch中文文档-简介】https://elasticsearch.bookhub.tech/set_up_elasticsearch/configuring_elasticsearch/
安装
Elasticsearch 安装
下载网址:https://www.elastic.co/cn/downloads

两个软件下载的版本最好相同
另外注意 Elasticsearch 的版本需要和你电脑上安装的JAVA JDK版本对应
像我电脑是是jdk1.8 对应es版本是7.6.1
进入elasticsearch-7.6.1\bin,双击elasticsearch.bat即可运行,访问http://localhost:9200/,得到如下内容:
{"name" : "HOULJ12","cluster_name" : "elasticsearch","cluster_uuid" : "hWbuydGRQLKKHia_KUVTjA","version" : {"number" : "7.6.1","build_flavor" : "default","build_type" : "zip","build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b","build_date" : "2020-02-29T00:15:25.529771Z","build_snapshot" : false,"lucene_version" : "8.4.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"
}
运行成功!
另外如果需要修改配置,基本上都在config文件夹下,可自行百度或看文档
Kibana 安装
进入kibana-7.6.1-windows-x86_64\bin,双击kibana.bat即可运行,访问http://localhost:5601/
【注】如果需要安装分词器,可参考文章尾部参考文章中有提到
Rest风格API
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
操作索引
基本概念
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的,对应关系如下:
索引(indices)--------------------------------Databases 数据库类型(type)---------------------------------Table 数据表文档(Document)--------------------------Row 行字段(Field)---------------------------Columns 列
示例
创建索引
Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求
创建索引的请求格式:
请求方式:PUT
请求路径:/索引库名
请求参数:json格式
PUT /索引库名

查看索引
GET /索引库名

可以用*来查看所有的索引库名:

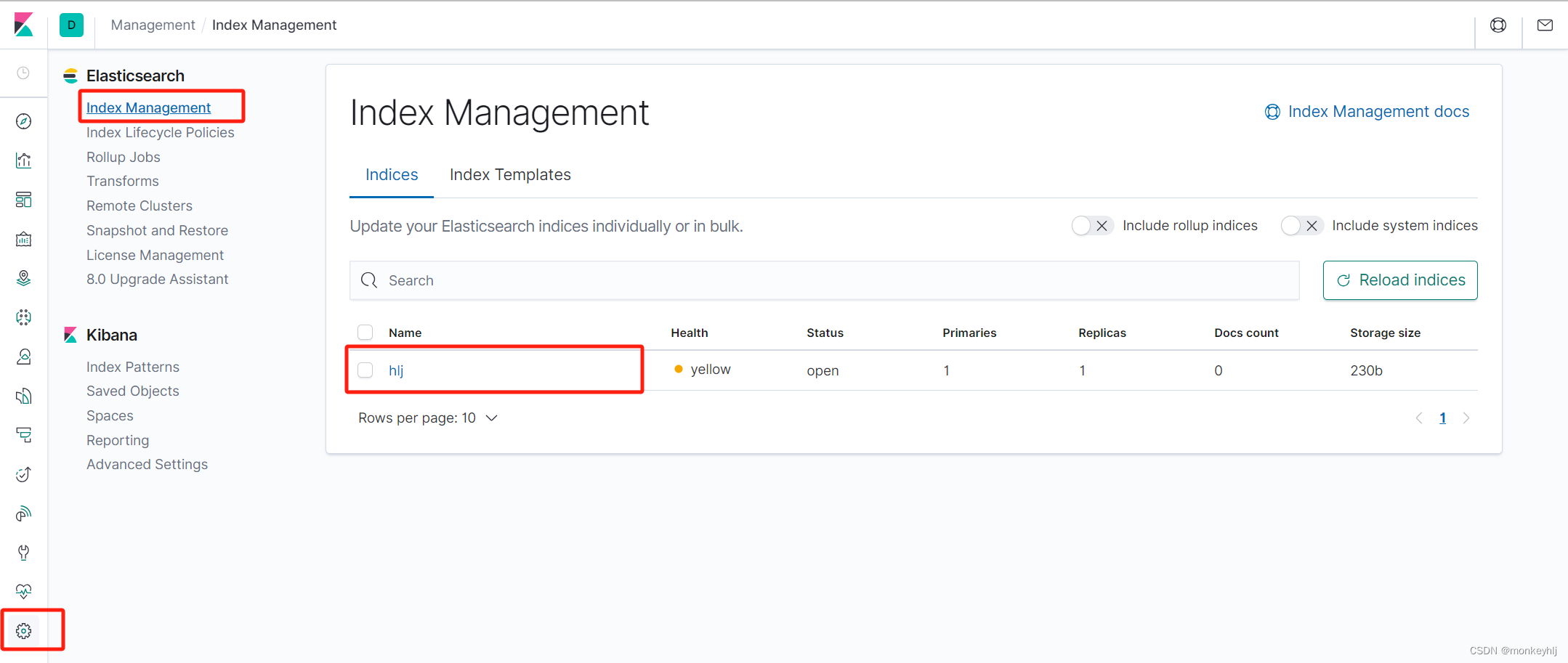
kibana中也可以查看到:
删除索引
DELETE /索引库名
映射配置(不配置好像也行、智能判断)
创建映射字段
PUT /索引库名/_mapping/类型名称
{"properties": {"字段名": {"type": "类型","index": true,"store": true,"analyzer": "分词器"}}
}
类型名称:就是前面将的type的概念,类似于数据库中的不同表字段名:任意填写 ,可以指定许多属性,例如:type:类型,可以是text、long、short、date、integer、object等index:是否索引,默认为truestore:是否存储,默认为falseanalyzer:分词器,这里的ik_max_word即使用ik分词器
示例:
PUT bysl/_mapping/goods
{"properties": {"title": {"type": "text","analyzer": "ik_max_word"},"images": {"type": "keyword","index": "false"},"price": {"type": "float"}}
}
【参考】字段类型:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
响应结果:
{"acknowledged": true
}
查看映射关系
GET /索引库名/_mapping
新增数据
随机生成ID
通过POST请求,可以向一个已经存在的索引库中添加数据
POST /索引库名/类型名
{"key1":"value1","key2":"value2"
}
示例:
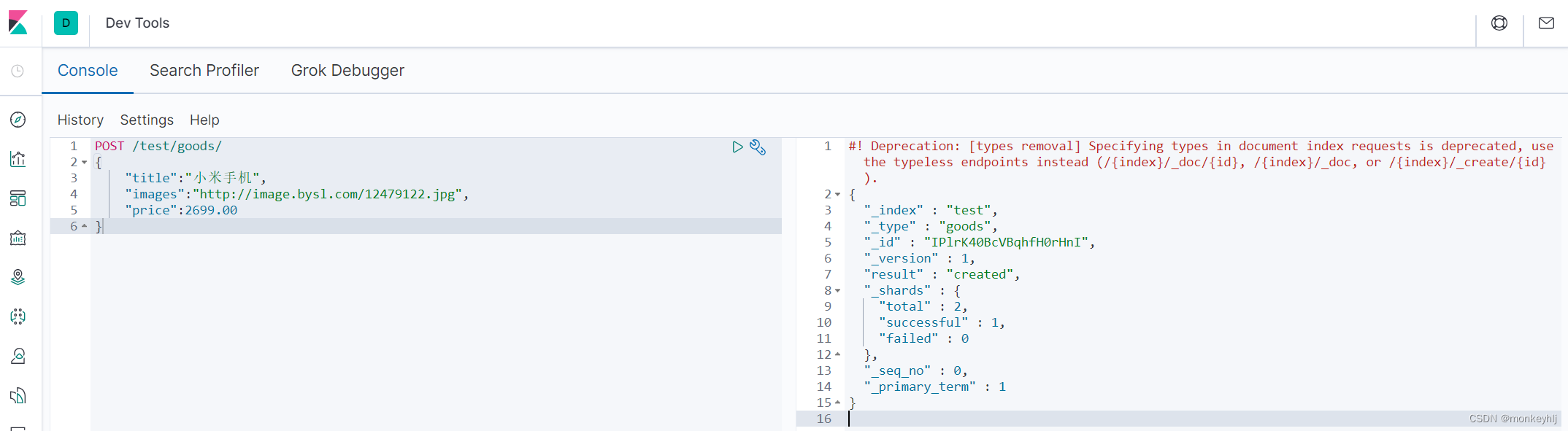
POST /test/goods/
{"title":"小米手机","images":"http://image.bysl.com/12479122.jpg","price":2699.00
}
查看数据:
GET test/_search
{"query":{"match_all":{}}
}
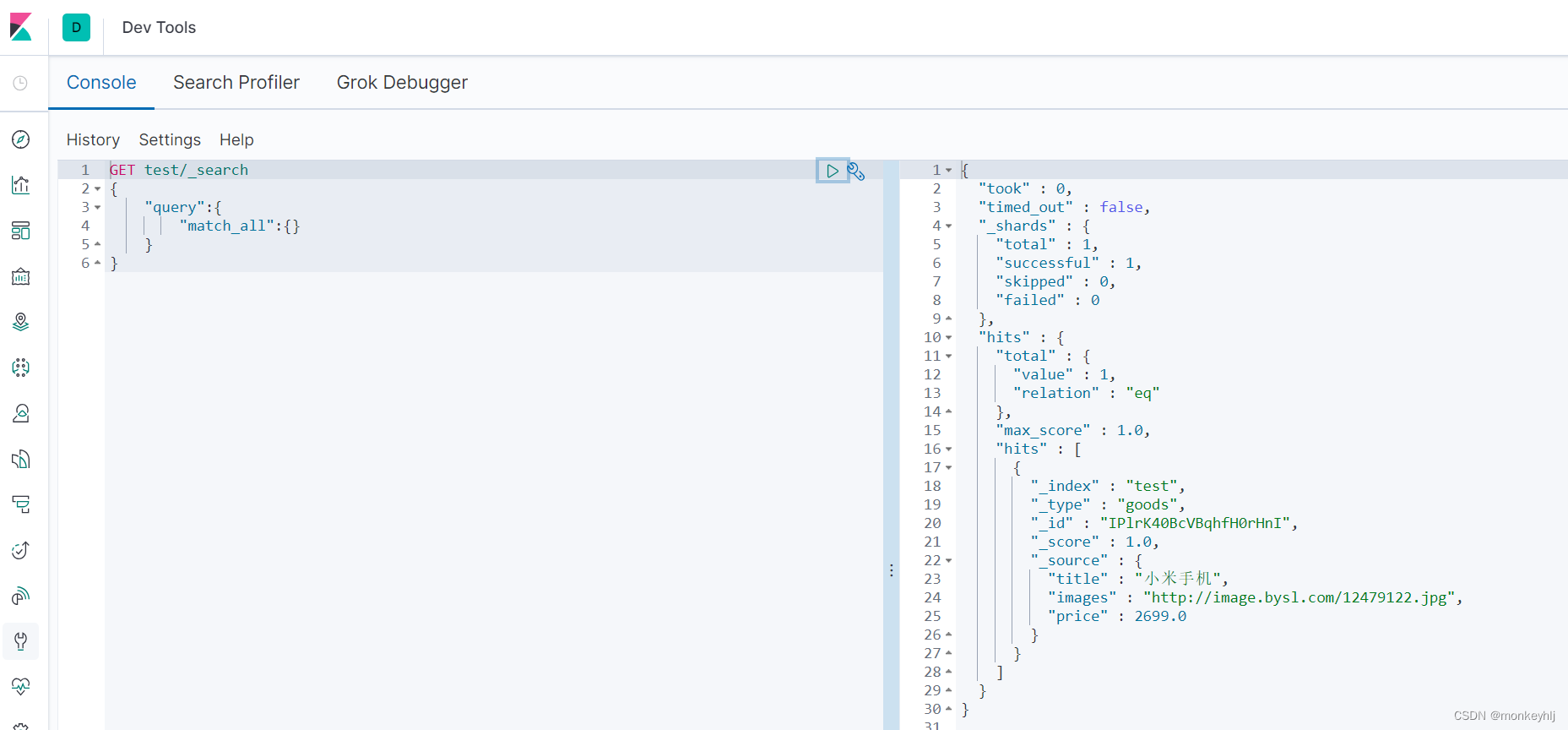
_source:源文档信息,所有的数据都在里面。
_id:这条文档的唯一标示,与文档自己的id字段没有关联
自定义ID
POST /索引库名/类型/ID值
{"key1":"value1","key2":"value2"
}
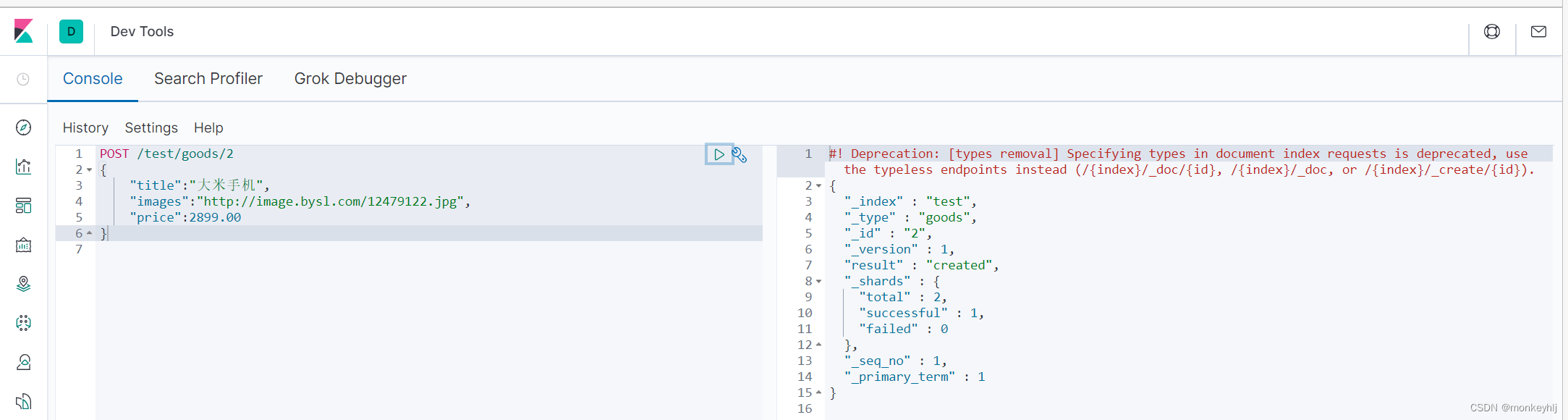

修改数据
把刚才新增的请求方式改为PUT,就是修改了。不过修改必须指定id:
- id对应文档存在,则修改
- id对应文档不存在,则新增
PUT /test/goods/IPlrK40BcVBqhfH0rHnI
{"title":"小米手机","images":"http://image.bysl.com/12479122.jpg","price":2688.00
}

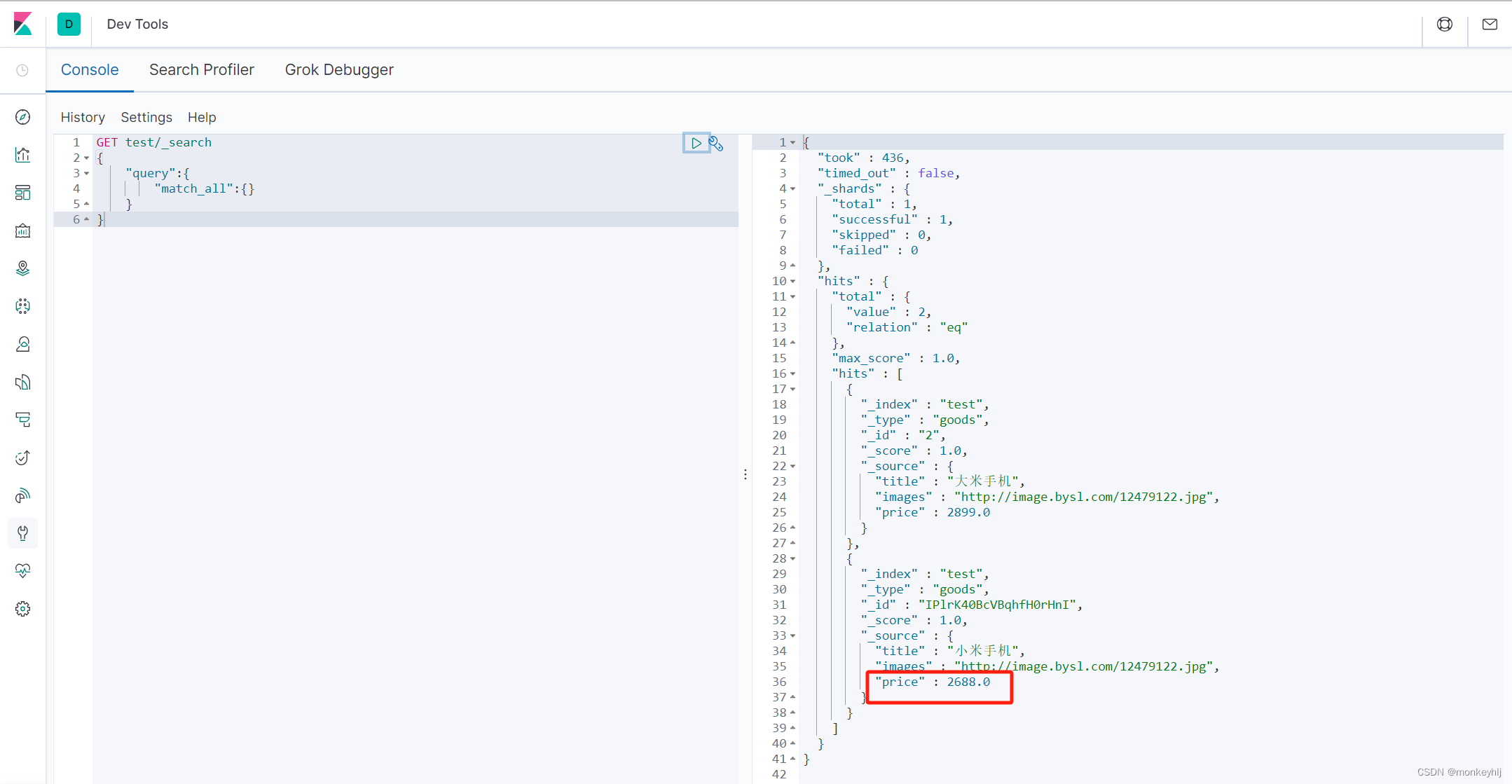
删除数据
删除使用DELETE请求,同样,需要根据id进行删除:
DELETE /索引库名/类型名/ID值

查询
基本查询
GET /索引库名/_search
{"query":{"查询类型":{"查询条件":"查询条件值"}}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:
- 例如:
match_all,match,term,range等等
- 例如:
- 查询条件:查询条件会根据类型的不同,写法也有差异,后面详细讲解
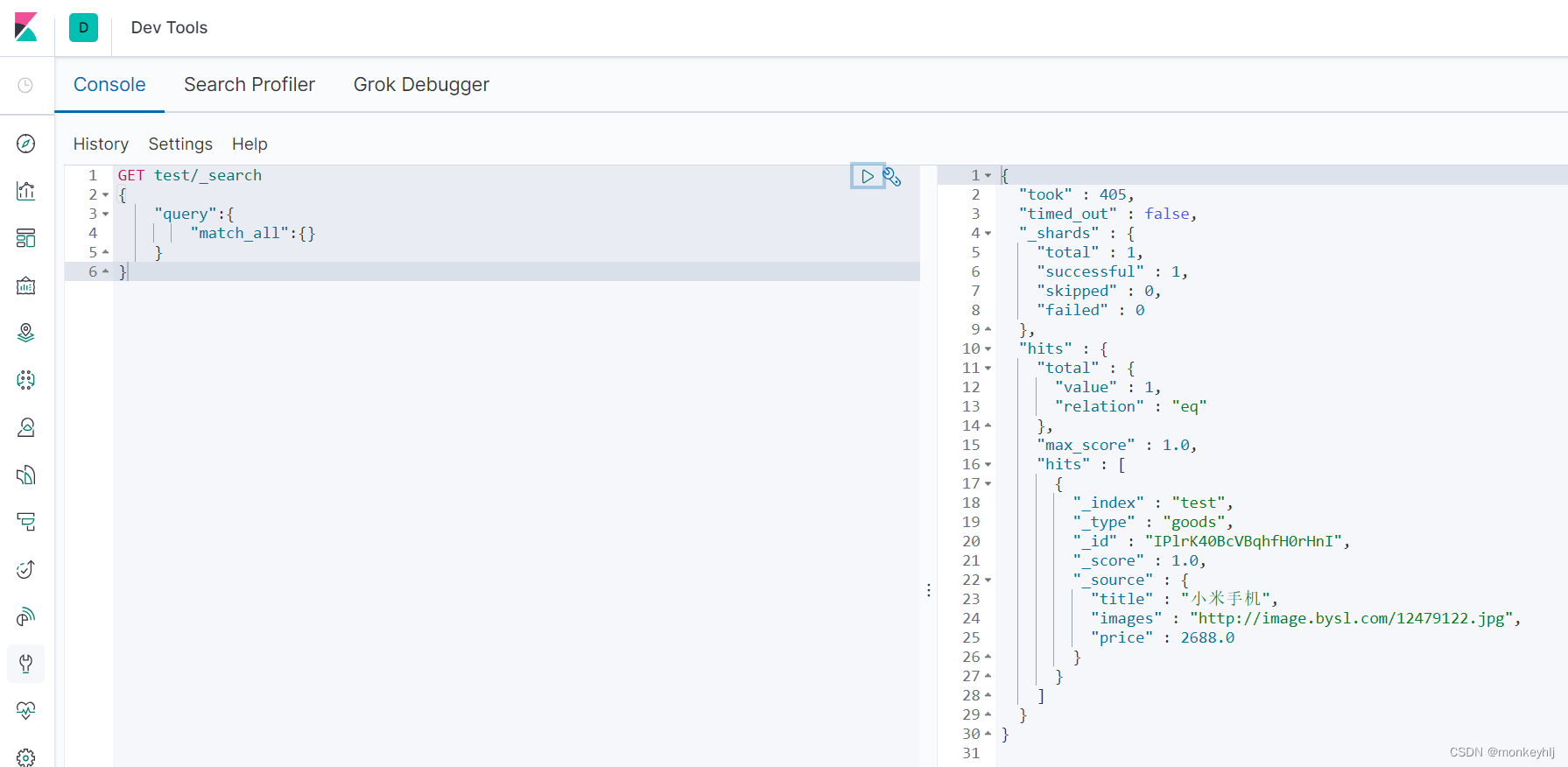
查询所有(match_all)
GET /test/_search
{"query":{"match_all": {}}
}
查询结果:
{"took" : 774,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "test","_type" : "goods","_id" : "IPlrK40BcVBqhfH0rHnI","_score" : 1.0,"_source" : {"title" : "小米手机","images" : "http://image.bysl.com/12479122.jpg","price" : 2688.0}},{"_index" : "test","_type" : "goods","_id" : "2","_score" : 1.0,"_source" : {"title" : "小米手机222222","images" : "http://image.bysl.com/133.jpg","price" : 3999.0}},{"_index" : "test","_type" : "goods","_id" : "3","_score" : 1.0,"_source" : {"title" : "联想小新","images" : "http://image.bysl.com/17777.jpg","price" : 6999.0}}]}
}
took:查询花费时间,单位是毫秒time_out:是否超时_shards:分片信息hits:搜索结果总览对象total:搜索到的总条数max_score:所有结果中文档得分的最高分hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息_index:索引库_type:文档类型_id:文档id_score:文档得分_source:文档的源数据
匹配查询(match)
or关系
match类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系
GET /test/_search
{"query":{"match":{"title":"联想"}}
}
搜索结果:
{"took" : 12,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 2.0253944,"hits" : [{"_index" : "test","_type" : "goods","_id" : "3","_score" : 2.0253944,"_source" : {"title" : "联想小新","images" : "http://image.bysl.com/17777.jpg","price" : 6999.0}}]}
}
在上面的案例中,多个词之间是or的关系:如果我输入联想小米,则包含联想或小米的都会查出来:

and关系
某些情况下,我们需要更精确查找,我们希望这个关系变成and,可以这样做:
GET /test/_search
{"query":{"match": {"title": {"query": "手机小米","operator": "and"}}}
}
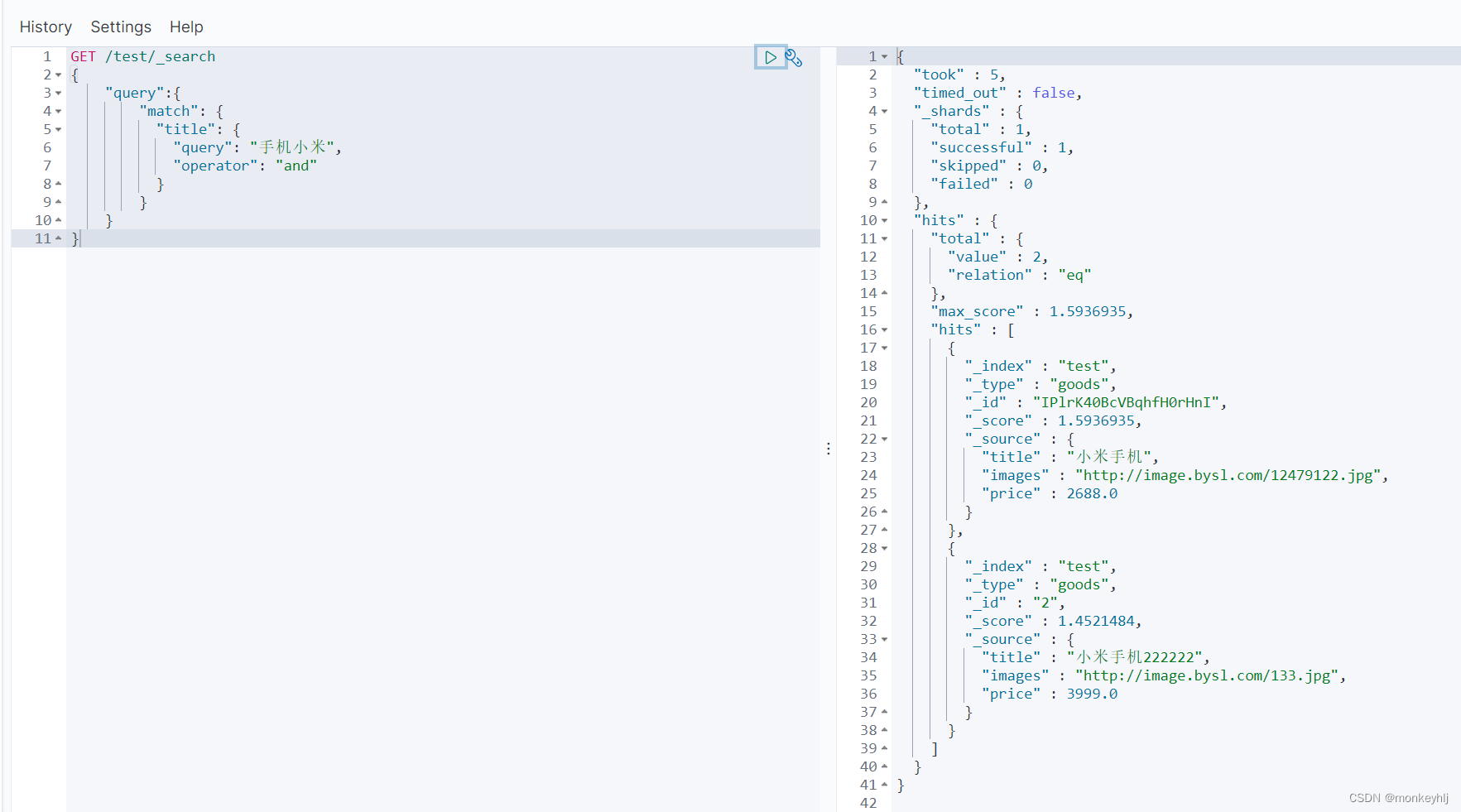
本例中,只有同时包含小米和手机的词条才会被搜索到
or和and之间?
在 or 与 and 间二选一有点过于非黑即白。 如果用户给定的条件分词后有 5 个查询词项,想查找只包含其中 4 个词的文档,该如何处理?将 operator 操作符参数设置成 and 只会将此文档排除。
有时候这正是我们期望的,但在全文搜索的大多数应用场景下,我们既想包含那些可能相关的文档,同时又排除那些不太相关的。换句话说,我们想要处于中间某种结果。
match 查询支持 minimum_should_match 最小匹配参数, 这让我们可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量:
GET /test/_search
{"query":{"match":{"title":{"query":"小米曲面电视","minimum_should_match": "75%"}}}
}
本例中,搜索语句可以分为3个词,如果使用and关系,需要同时满足3个词才会被搜索到。这里我们采用最小品牌数:75%,那么也就是说只要匹配到总词条数量的75%即可,这里3*75% 约等于2。所以只要包含2个词条就算满足条件了
多字段查询(multi_match)
multi_match与match类似,不同的是它可以在多个字段中查询
GET /test/_search
{"query":{"multi_match": {"query": "小米","fields": [ "title", "images" ]}}
}
词条匹配(term)
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串
GET /test/_search
{"query":{"term":{"price":2699.00}}
}
多词条精确匹配(terms)
GET /test/_search
{"query":{"terms":{"price":[2699.00,2899.00,3899.00]}}
}
结果过滤
直接指定字段_source
默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source的过滤
GET /test/_search
{"_source": ["title","price"],"query": {"term": {"price": 2688}}
}
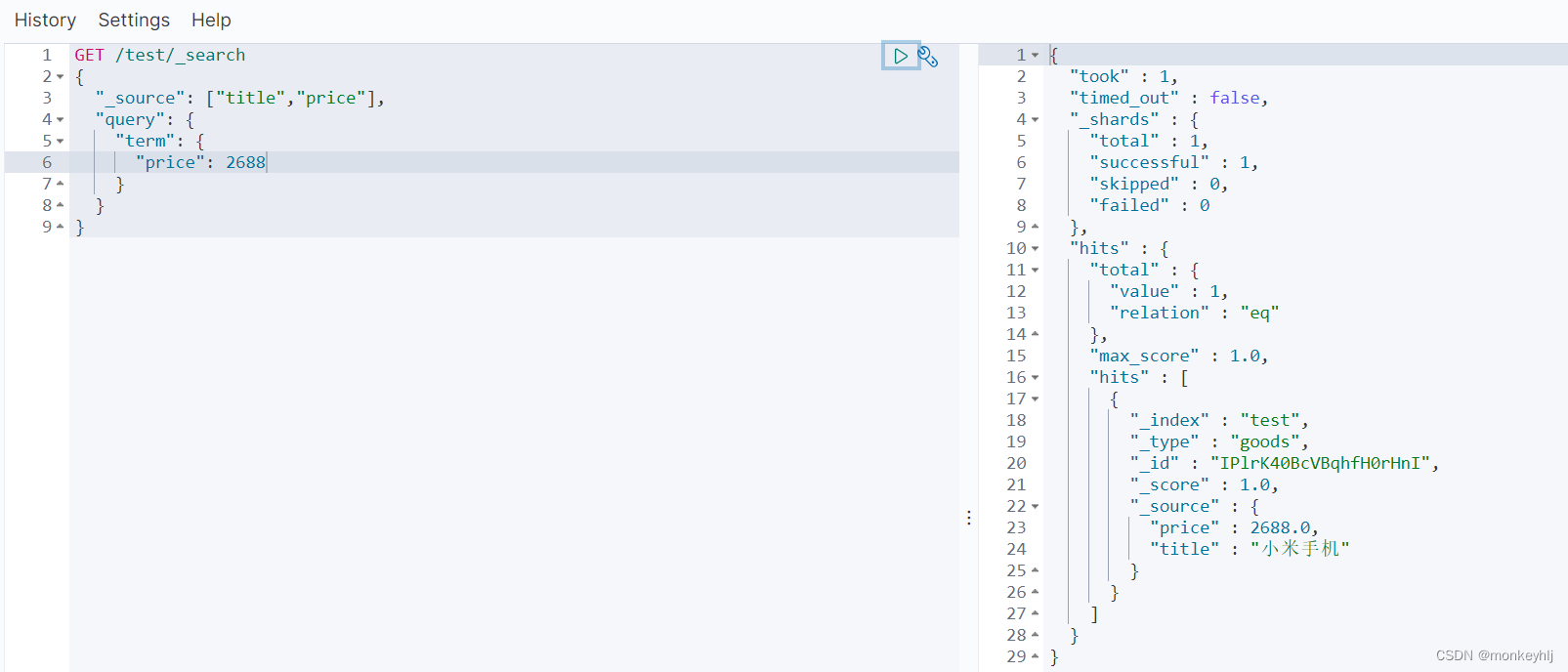
指定includes和excludes
includes:来指定想要显示的字段excludes:来指定不想要显示的字段
GET /test/_search
{"_source": {"includes":["title","price"]},"query": {"term": {"price": 2688}}
}
高级查询
布尔组合(bool)
bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合
GET /test/_search
{"query":{"bool":{"must": { "match": { "title": "大米" }},"must_not": { "match": { "title": "电视" }},"should": { "match": { "title": "手机" }}}}
}
范围查询(range)
range 查询找出那些落在指定区间内的数字或者时间
GET /test/_search
{"query":{"range": {"price": {"gte": 1000.0,"lt": 2800.00}}}
}
range查询允许以下字符:
| 操作符 | 说明 |
|---|---|
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
模糊查询(fuzzy)
fuzzy 查询是 term 查询的模糊等价。它允许用户搜索词条与实际词条的拼写出现偏差,但是偏差的编辑距离不得超过2:
GET /test/_search
{"query": {"fuzzy": {"title": "米"}}
}
可以通过fuzziness来指定允许的编辑距离:
GET /test/_search
{"query": {"fuzzy": {"title": {"value":"米","fuzziness":1}}}
}
过滤(filter)
所有的查询都会影响到文档的评分及排名。如果我们需要在查询结果中进行过滤,并且不希望过滤条件影响评分,那么就不要把过滤条件作为查询条件来用。而是使用filter方式:
GET /test/_search
{"query":{"bool":{"must":{ "match": { "title": "小米手机" }},"filter":{"range":{"price":{"gt":2000.00,"lt":3800.00}}}}}
}
【注意】filter中还可以再次进行bool组合条件过滤!
如果一次查询只有过滤,没有查询条件,不希望进行评分,我们可以使用constant_score取代只有 filter 语句的 bool 查询。在性能上是完全相同的,但对于提高查询简洁性和清晰度有很大帮助
GET /test/_search
{"query":{"constant_score": {"filter": {"range":{"price":{"gt":2000.00,"lt":3000.00}}}}
}
排序
单字段排序
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式
GET /test/_search
{"query": {"match": {"title": "小米手机"}},"sort": [{"price": {"order": "desc"}}]
}
多字段排序
假定我们想要结合使用 price和 _score(得分,假设有) 进行查询,并且匹配的结果首先按照价格排序,然后按照相关性得分排序:
GET /goods/_search
{"query":{"bool":{"must":{ "match": { "title": "小米手机" }},"filter":{"range":{"price":{"gt":200000,"lt":300000}}}}},"sort": [{ "price": { "order": "desc" }},{ "_score": { "order": "desc" }}]
}
聚合aggregations
测试数据准备
创建索引:
PUT /cars
存入数据:
POST /cars/transactions/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
聚合为桶
GET /cars/_search
{"size" : 0,"aggs" : { "popular_colors" : { "terms" : { "field" : "color.keyword"}}}
}
size: 查询条数,这里设置为0,因为我们不关心搜索到的数据,只关心聚合结果,提高效率aggs:声明这是一个聚合查询,是aggregations的缩写popular_colors:给这次聚合起一个名字,任意。terms:划分桶的方式,这里是根据词条划分field:划分桶的字段
结果:
{"took" : 7,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"popular_colors" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "red","doc_count" : 4},{"key" : "blue","doc_count" : 2},{"key" : "green","doc_count" : 2}]}}
}
hits:查询结果为空,因为我们设置了size为0aggregations:聚合的结果popular_colors:我们定义的聚合名称buckets:查找到的桶,每个不同的color字段值都会形成一个桶key:这个桶对应的color字段的值doc_count:这个桶中的文档数量
桶内度量
GET /cars/_search
{"size" : 0,"aggs" : { "popular_colors" : { "terms" : { "field" : "color.keyword"},"aggs":{"avg_price": { "avg": {"field": "price" }}}}}
}
aggs:我们在上一个aggs(popular_colors)中添加新的aggs。可见度量也是一个聚合avg_price:聚合的名称avg:度量的类型,这里是求平均值field:度量运算的字段
结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"popular_colors" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "red","doc_count" : 4,"avg_price" : {"value" : 32500.0}},{"key" : "blue","doc_count" : 2,"avg_price" : {"value" : 20000.0}},{"key" : "green","doc_count" : 2,"avg_price" : {"value" : 21000.0}}]}}
}
桶内嵌套桶
GET /cars/_search
{"size" : 0,"aggs" : { "popular_colors" : { "terms" : { "field" : "color.keyword"},"aggs":{"avg_price": { "avg": {"field": "price" }},"maker":{"terms":{"field":"make.keyword"}}}}}
}
- 原来的color桶和avg计算我们不变
maker:在嵌套的aggs下新添一个桶,叫做makerterms:桶的划分类型依然是词条filed:这里根据make字段进行划分
结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"popular_colors" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "red","doc_count" : 4,"maker" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "honda","doc_count" : 3},{"key" : "bmw","doc_count" : 1}]},"avg_price" : {"value" : 32500.0}},{"key" : "blue","doc_count" : 2,"maker" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "ford","doc_count" : 1},{"key" : "toyota","doc_count" : 1}]},"avg_price" : {"value" : 20000.0}},{"key" : "green","doc_count" : 2,"maker" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "ford","doc_count" : 1},{"key" : "toyota","doc_count" : 1}]},"avg_price" : {"value" : 21000.0}}]}}
}
- 我们可以看到,新的聚合
maker被嵌套在原来每一个color的桶中。 - 每个颜色下面都根据
make字段进行了分组 - 我们能读取到的信息:
- 红色车共有4辆
- 红色车的平均售价是 32500 美元。
- 其中3辆是 Honda 本田制造,1辆是 BMW 宝马制造。
划分桶的其它方式
划分桶的方式有很多,例如:
Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组Histogram Aggregation:根据数值阶梯分组,与日期类似Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
刚刚的案例中,我们采用的是Terms Aggregation,即根据词条划分桶
阶梯分桶Histogram Aggregation
比如,我们对汽车的价格进行分组,指定间隔interval为5000:
GET /cars/_search
{"size":0,"aggs":{"price":{"histogram": {"field": "price","interval": 5000}}}
}
结果:
{"took" : 7,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"price" : {"buckets" : [{"key" : 10000.0,"doc_count" : 2},{"key" : 15000.0,"doc_count" : 1},{"key" : 20000.0,"doc_count" : 2},{"key" : 25000.0,"doc_count" : 1},{"key" : 30000.0,"doc_count" : 1},{"key" : 35000.0,"doc_count" : 0},{"key" : 40000.0,"doc_count" : 0},{"key" : 45000.0,"doc_count" : 0},{"key" : 50000.0,"doc_count" : 0},{"key" : 55000.0,"doc_count" : 0},{"key" : 60000.0,"doc_count" : 0},{"key" : 65000.0,"doc_count" : 0},{"key" : 70000.0,"doc_count" : 0},{"key" : 75000.0,"doc_count" : 0},{"key" : 80000.0,"doc_count" : 1}]}}
}
但是中间有大量的文档数量为0的桶,可以增加一个参数min_doc_count为1,来约束最少文档数量为1,这样文档数量为0的桶会被过滤:
GET /cars/_search
{"size":0,"aggs":{"price":{"histogram": {"field": "price","interval": 5000,"min_doc_count": 1}}}
}
结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"price" : {"buckets" : [{"key" : 10000.0,"doc_count" : 2},{"key" : 15000.0,"doc_count" : 1},{"key" : 20000.0,"doc_count" : 2},{"key" : 25000.0,"doc_count" : 1},{"key" : 30000.0,"doc_count" : 1},{"key" : 80000.0,"doc_count" : 1}]}}
}
可以在kibana中的visiualize中看图形化直观展示:
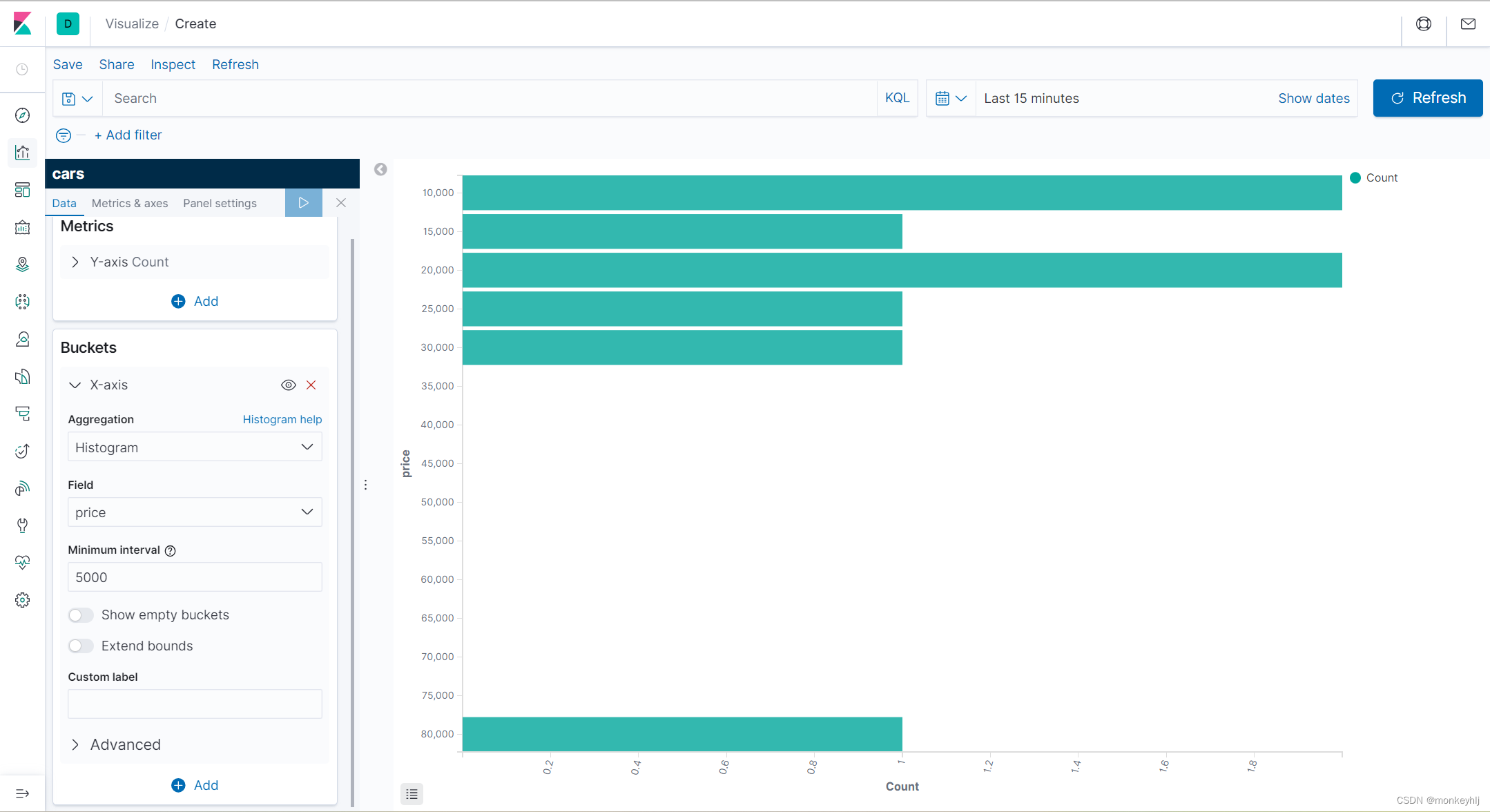
范围分桶Range Aggregation
范围分桶与阶梯分桶类似,也是把数字按照阶段进行分组,只不过range方式需要你自己指定每一组的起始和结束大小
GET /cars/_search
{"size":0,"aggs":{"sold":{"range": {"field": "sold","ranges" : [{ "from" : "2014-07-02", "to" : "2014-08-30" }]}}}
}
结果:
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 8,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"sold" : {"buckets" : [{"key" : "2014-07-02T00:00:00.000Z-2014-08-30T00:00:00.000Z","from" : 1.4042592E12,"from_as_string" : "2014-07-02T00:00:00.000Z","to" : 1.4093568E12,"to_as_string" : "2014-08-30T00:00:00.000Z","doc_count" : 2}]}}
}
【注意】这里差一点跟查时间范围内数据混淆了,查sold时间范围内数据如下:
GET /cars/_search
{"query": {"range": {"sold": {"gte": "2014-07-01","lte": "2014-09-01"}}}
}
结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "cars","_type" : "transactions","_id" : "JPmhLI0BcVBqhfH0_Xnk","_score" : 1.0,"_source" : {"price" : 15000,"color" : "blue","make" : "toyota","sold" : "2014-07-02"}},{"_index" : "cars","_type" : "transactions","_id" : "JfmhLI0BcVBqhfH0_Xnk","_score" : 1.0,"_source" : {"price" : 12000,"color" : "green","make" : "toyota","sold" : "2014-08-19"}}]}
}
不同语言客户端代码
【文档参考】https://www.elastic.co/guide/en/elasticsearch/client/index.html
【参考】https://zhuanlan.zhihu.com/p/649902671
【参考】https://blog.csdn.net/TinaCSDN/article/details/108290648
【参考】https://blog.csdn.net/mo_sss/article/details/133808562
【参考】https://blog.csdn.net/mijichui2153/article/details/126177041
相关文章:
Elasticsearch+Kibana 学习记录
文章目录 安装Elasticsearch 安装Kibana 安装 Rest风格API操作索引基本概念示例创建索引查看索引删除索引映射配置(不配置好像也行、智能判断)新增数据随机生成ID自定义ID 修改数据删除数据 查询基本查询查询所有(match_all)匹配查…...

Cesium叠加超图二维服务、三维场景模型
前言 Cesium作为开源的库要加超图的服务则需要适配层去桥接超图与Cesium的数据格式。这个工作iClient系列已经做好,相比用过超图二维的道友们可以理解:要用Openlayer加载超图二维,那就用iClient for Openlayer库去加载;同样的要用…...

【低危】OpenSSL 拒绝服务漏洞
漏洞描述 OpenSSL 是广泛使用的开源加密库。 在 OpenSSL 3.0.0 到 3.0.12, 3.1.0 到 3.1.4 和 3.2.0 中 ,使用函数 EVP_PKEY_public_check() 来检查 RSA 公钥的应用程序可能会遇到长时间延迟。如果检查的密钥是从不可信任的来源获取的,这可能会导致拒绝…...

TDL-Tiny Synopsis-TED-ED 网络理论 Network Theory
Tiny Synopsis on TED-ED-Network Theory I) Webpage addressII)Context ExceptionIII) Diagram/Chart Research&Developement I) Webpage address URL Resource II)Context Exception what does “going viral” on Internet really mean? (网络…...

GIS项目实战08:JetBrains IntelliJ IDEA 2022 激活
为什么选择 IntelliJ IDEA 使用编码辅助功能更快地编写高质量代码,这些功能可在您键入时搜索可能的错误并提供改进建议,同时无缝地向您介绍编码、新语言功能等方面的社区最佳实践。 IntelliJ IDEA 了解您的代码,并利用这些知识通过在每种上…...
Linux 命令大全 CentOS常用运维命令
文章目录 1、Linux 目录结构2、解释目录3、命令详解3.1、shutdown命令3.1、文件目录管理命令ls 命令cd 命令pwd 命令tree 命令mkdir 命令touch 命令cat 命令cp 命令more 命令less 命令head 命令mv 命令rm 命令ln 命令tail 命令cut命令 3.2、用户管理useradd/userdel 命令用户的…...

6.3.5编辑视频
6.3.5编辑视频 除了上面的功能外,Camtasia4还能进行简单的视频编辑工作,如媒体的剪辑、连接、画中画等。 下面我们就利用Camtasia4的强大功能来实现一个画中画效果,在具体操作之前,需要准备好两个视频文件,一个作为主…...

同星多通道CAN FD转USB/WIFI设备,解决近距离无线通讯问题
新品发布/New products release 2024年1月,同星智能连续发布FlexRay系列产品TP1034和以太网系列产品TP1051,上周发布多通道总线记录仪产品TLog1004。1月19日,同星智能又推出一款2/4路CAN FD转USB和WIFI的工具,解决近距离无线通讯…...

wamp环境的组成
wamp环境介绍 简介 Wamp 就是 Windows Apache Mysql PHP集成安装环境,即在window下的apache、php和mysql的服务器软件。 w--windows Windows操作系统,是由美国微软公司(Microsoft)研发的操作系统,问世于1985年。起初…...
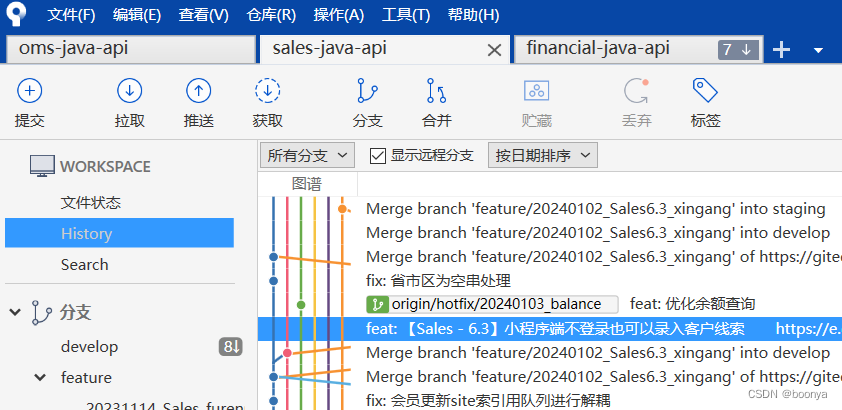
Idea 开发环境不断切换git代码分支导致冲掉别人代码
问题分析 使用git reflog查看执行命令,以下是发生事故的切换和提交动作 46f72622e1 HEAD{41}: commit: feat: 【Sales - 6.3】小程序端不登录也可以录入客户线索 c5e7d9f6e1 HEAD{42}: fetch origin feature/20240102_Sales6.3_xingang:feature/20240102_Sales6.3…...

GO 中如何防止 goroutine 泄露
文章目录 概述如何监控泄露一个简单的例子泄露情况分类chanel 引起的泄露发送不接收接收不发送nil channel真实的场景 传统同步机制MutexWaitGroup 总结参考资料 今天来简单谈谈,Go 如何防止 goroutine 泄露。 概述 Go 的并发模型与其他语言不同,虽说它…...

Linux练习题
1 简答题:请列举你所知道的Linux发行版 常见的Linux发行版: Red Hat Enterprise Linux 6/7/8 CentOS 6/7/8 Suse Linux Enterprise 15 Debian Linux 11 Ubuntu Linux 20.04/21.04 Rocky Linux 8/9 2 简答题:Linux系统的根目录、/dev目录的作用是什么 /:linux文件系统的…...
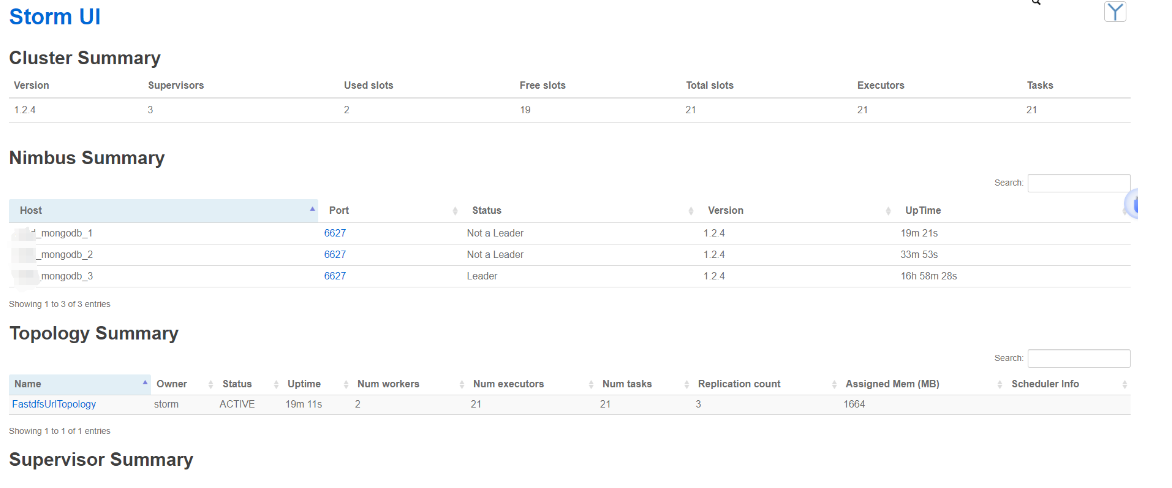
storm统计服务开启zookeeper、kafka 、Storm(sasl认证)
部署storm统计服务开启zookeeper、kafka 、Storm(sasl认证) 当前测试验证结果: 单独配置zookeeper 支持acl 设置用户和密码,在storm不修改代码情况下和kafka支持当kafka 开启ACL时,storm 和ccod模块不清楚配置用户和密…...

YOLOv8加入AIFI模块,附带项目源码链接
YOLOv8" 是一个新一代的对象检测框架,属于YOLO(You Only Look Once)系列的最新版本。YOLOv8中提及的AIFI(Attention-based Intrascale Feature Interaction)模块是一种用于增强对象检测性能的机制,它是…...
【设计模式】代理模式的实现方式与使用场景
1. 概述 代理模式是一种结构型设计模式,它通过创建一个代理对象来控制对另一个对象的访问,代理对象在客户端和目标对象之间充当了中介的角色,客户端不再直接访问目标对象,而是通过代理对象间接访问目标对象。 那在中间加一层代理…...

医学图像的图像处理、分割、分类和定位-1
一、说明 本报告全面探讨了应用于医学图像的图像处理和分类技术。开展了四项不同的任务来展示这些方法的多功能性和有效性。任务 1 涉及读取、写入和显示 PNG、JPG 和 DICOM 图像。任务 2 涉及基于定向变化的多类图像分类。此外,我们在任务 3 中包括了胸部 X 光图像…...
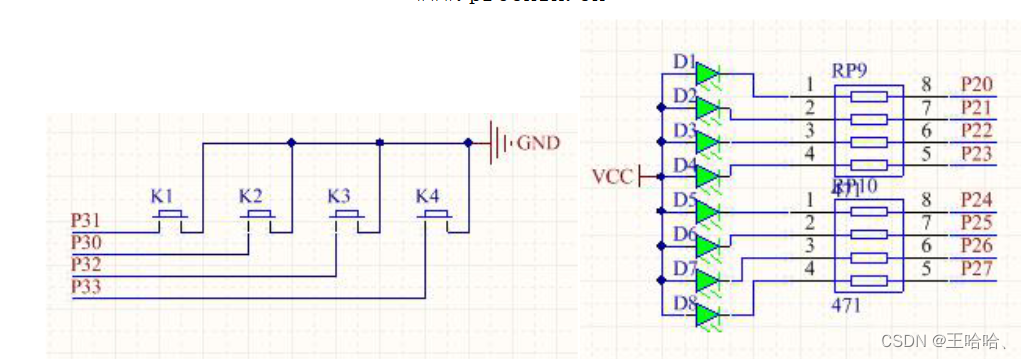
【51单片机】外部中断
0、前言 参考:普中 51 单片机开发攻略 第16章 及17章 1、硬件 2、软件 #include <reg52.h> #include <intrins.h> #include "delayms.h"typedef unsigned char u8; typedef unsigned int u16;sbit led P2^0; sbit key3 P3^2;//外部中断…...

fastapi框架
fastapi框架 fastapi,一个用于构建 API 的现代、快速(高性能)的异步web框架。 fastapi是建立在Starlette和Pydantic基础上的 Pydantic是一个基于Python类型提示来定义数据验证、序列化和文档的库。Starlette是一种轻量级的ASGI框架/工具包…...
2023 年顶级前端工具
谁不喜欢一个好的前端工具?在本综述中,您将找到去年流行的有用的前端工具,它们将帮助您加快开发工作流程。让我们深入了解一下! 在过去的 12 个月里,我在我的时事通讯 Web Tools Weekly 中分享了数百种工具。我为前端…...
html 会跳舞的时间动画特效
下面是是代码: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns"http://www.w3.org/1999/xhtml"> <head> <meta h…...

题解:洛谷 U327333 Max Sum Plus Plus 2
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...

Hermes Agent 任务追踪实战:3 类日志审计配置+2 步故障自愈触发流程
1. 日志审计不是“看日志”,而是让 Hermes Agent 自己学会写诊断报告 大多数人第一次配置 Hermes Agent 的任务追踪能力时,会下意识打开 logs/ 目录,用 tail -f 盯着滚动的文本发呆——这本质上还是在用人工方式做运维。真正的工程化日志审计,是让 Hermes Agent 在任务执行…...

企业级应用如何通过Taotoken实现API Key的精细化管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken实现API Key的精细化管理与审计 在构建基于大模型的企业级应用时,API Key的管理与安全审计…...

W5500 TCP客户端实战:从寄存器配置到网络调试助手,一步步打通你的第一个物联网连接
W5500 TCP客户端实战:从寄存器配置到网络调试助手,一步步打通你的第一个物联网连接 在嵌入式物联网开发中,网络通信模块的选择往往决定了项目的稳定性和开发效率。W5500作为一款全硬件TCP/IP协议栈芯片,以其稳定的性能和简单的开发…...

面试题目总结
面试心态 越是置自己于低位,就越难获得面试官的青睐。面试官其实更喜欢逻辑清晰,不卑不亢,带点锋芒的应聘者。 不要以通过面试为目的,不然很难摆脱被凝视的状态。要以自我成长与提升为中心。要记住,每一次面试不是成功…...

从OpenMV2到4代,我踩过的那些坑:画面变绿、传感器接触不良与内存擦除的避坑实录
从OpenMV2到4代:硬件升级中的稳定性挑战与实战解决方案 作为一名长期使用OpenMV系列开发视觉项目的工程师,我从OpenMV2一路升级到4代,见证了硬件性能的飞跃,也深刻体会到稳定性问题带来的困扰。其中最令人头疼的莫过于"画面变…...
)
零基础想学挖漏洞?普通人也能看懂的网络安全入门学习路线(建议收藏)
很多人对网络安全的第一印象:黑客、代码、入侵、黑框代码疯狂滚动、随手就能让ATM吐钱,随手一个漏洞几千上万,日进斗金!!! 但真实情况是:90%零基础新人不会挖漏洞,不是天赋不够&…...

抖音下载器完整指南:从零构建高效批量下载系统的技术实践
抖音下载器完整指南:从零构建高效批量下载系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

Mac用户必看:免费开源的NTFS读写神器,3分钟解决跨平台文件传输难题
Mac用户必看:免费开源的NTFS读写神器,3分钟解决跨平台文件传输难题 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, moun…...

如何高效下载B站视频:BiliDownloader终极使用教程
如何高效下载B站视频:BiliDownloader终极使用教程 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader 想要轻松保存B站上的精彩视频内容…...