FlinkAPI开发之状态管理
案例用到的测试数据请参考文章:
Flink自定义Source模拟数据流
原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
Flink中的状态
概述
有状态的算子
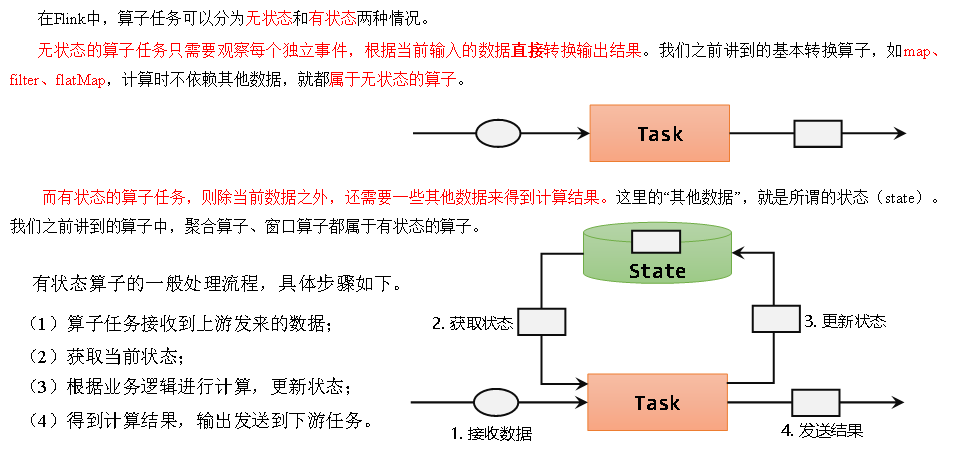
状态的分类
托管状态(Managed State)和原始状态(Raw State)
Flink的状态有两种:托管状态(Managed State)和原始状态(Raw State)。托管状态就是由Flink统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由Flink实现,我们只要调接口就可以;而原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。
通常我们采用Flink托管状态来实现需求。
算子状态(Operator State)和按键分区状态(Keyed State)
接下来我们的重点就是托管状态(Managed State)。
我们知道在Flink中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(task slot)。由于不同的slot在计算资源上是物理隔离的,所以Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。
而很多有状态的操作(比如聚合、窗口)都是要先做keyBy进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前key有效,所以状态也应该按照key彼此隔离。在这种情况下,状态的访问方式又会有所不同。
基于这样的想法,我们又可以将托管状态分为两类:算子状态和按键分区状态。
算子状态
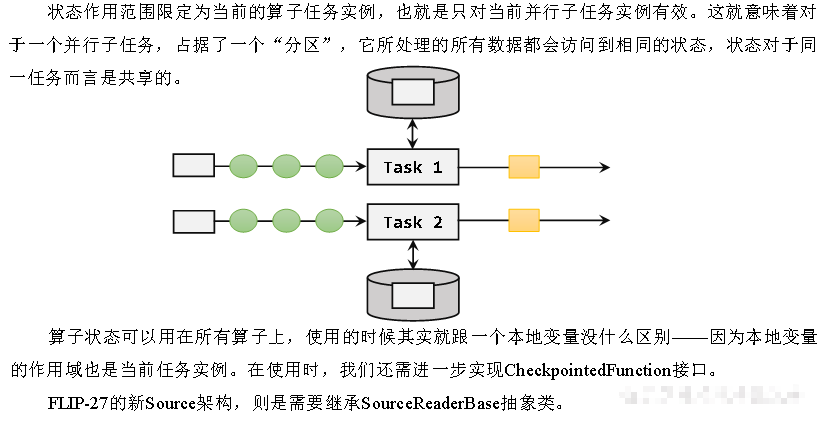
按键分区状态
另外,也可以通过富函数类(Rich Function)来自定义Keyed State,所以只要提供了富函数类接口的算子,也都可以使用Keyed State。所以即使是map、filter这样无状态的基本转换算子,我们也可以通过富函数类给它们“追加”Keyed State。比如RichMapFunction、RichFilterFunction。在富函数中,我们可以调用.getRuntimeContext()获取当前的运行时上下文(RuntimeContext),进而获取到访问状态的句柄;这种富函数中自定义的状态也是Keyed State。从这个角度讲,Flink中所有的算子都可以是有状态的。
无论是Keyed State还是Operator State,它们都是在本地实例上维护的,也就是说每个并行子任务维护着对应的状态,算子的子任务之间状态不共享。
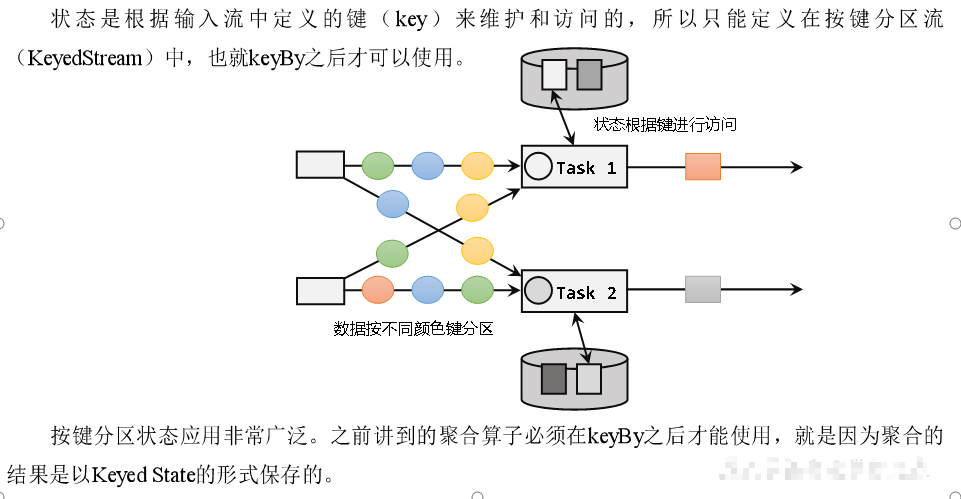
按键分区状态(Keyed State)
按键分区状态(Keyed State)顾名思义,是任务按照键(key)来访问和维护的状态。它的特点非常鲜明,就是以key为作用范围进行隔离。
需要注意,使用Keyed State必须基于KeyedStream。没有进行keyBy分区的DataStream,即使转换算子实现了对应的富函数类,也不能通过运行时上下文访问Keyed State。
值状态(ValueState)
顾名思义,状态中只保存一个“值”(value)。ValueState本身是一个接口,源码中定义如下:
public interface ValueState<T> extends State {T value() throws IOException;void update(T value) throws IOException;
}
这里的T是泛型,表示状态的数据内容可以是任何具体的数据类型。如果想要保存一个长整型值作为状态,那么类型就是ValueState。
我们可以在代码中读写值状态,实现对于状态的访问和更新。
T value():获取当前状态的值;
update(T value):对状态进行更新,传入的参数value就是要覆写的状态值。
在具体使用时,为了让运行时上下文清楚到底是哪个状态,我们还需要创建一个“状态描述器”(StateDescriptor)来提供状态的基本信息。例如源码中,ValueState的状态描述器构造方法如下:
public ValueStateDescriptor(String name, Class<T> typeClass) {super(name, typeClass, null);
}
这里需要传入状态的名称和类型——这跟我们声明一个变量时做的事情完全一样。
import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;public class KeyedValueStateDemo {public static void main(String[] args) throws Exception {// TODO: 2024/1/15 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/15 设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/15 设置水位线WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))// TODO: 2024/1/15 指定水位线中对应的时间字段.withTimestampAssigner((orders, l) -> orders.getOrder_date())// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力.withIdleness(Duration.ofSeconds(3));// TODO: 2024/1/15 添加水位线SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);SingleOutputStreamOperator<String> streamOperator = operator.keyBy(orders -> orders.getProduct_id()).process(new KeyedProcessFunction<Integer, Orders, String>() {// TODO 1.定义状态ValueState<Integer> lastVcState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// TODO 2.在open方法中,初始化状态// 状态描述器两个参数:第一个参数,起个名字,不重复;第二个参数,存储的类型lastVcState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("lastVcState", Types.INT));}@Overridepublic void processElement(Orders orders, KeyedProcessFunction<Integer, Orders, String>.Context context, Collector<String> out) throws Exception {//lastVcState.value(); // 取出 本组 值状态 的数据//lastVcState.update(); // 更新 本组 值状态 的数据//lastVcState.clear(); // 清除 本组 值状态 的数据// 1. 取出上一条数据的水位值(Integer默认值是null,判断)int lastVc = lastVcState.value() == null ? 0 : lastVcState.value();// 2. 求差值的绝对值,判断是否超过10Integer vc = orders.getOrder_amount();if (Math.abs(vc - lastVc) > 10) {out.collect("传感器=" + orders.getProduct_id() + "==>当前商品最大销售额=" + vc + ",与上一次记录=" + lastVc + ",相差超过10!!!!");}// 3. 更新状态里的水位值lastVcState.update(vc);}});ordersDataStreamSource.print();streamOperator.print();environment.execute();}
}
列表状态(ListState)
将需要保存的数据,以列表(List)的形式组织起来。在ListState接口中同样有一个类型参数T,表示列表中数据的类型。ListState也提供了一系列的方法来操作状态,使用方式与一般的List非常相似。
Iterable<T> get():获取当前的列表状态,返回的是一个可迭代类型Iterable<T>;
update(List<T> values):传入一个列表values,直接对状态进行覆盖;
add(T value):在状态列表中添加一个元素value;
addAll(List<T> values):向列表中添加多个元素,以列表values形式传入。
类似地,ListState的状态描述器就叫作ListStateDescriptor,用法跟ValueStateDescriptor完全一致。
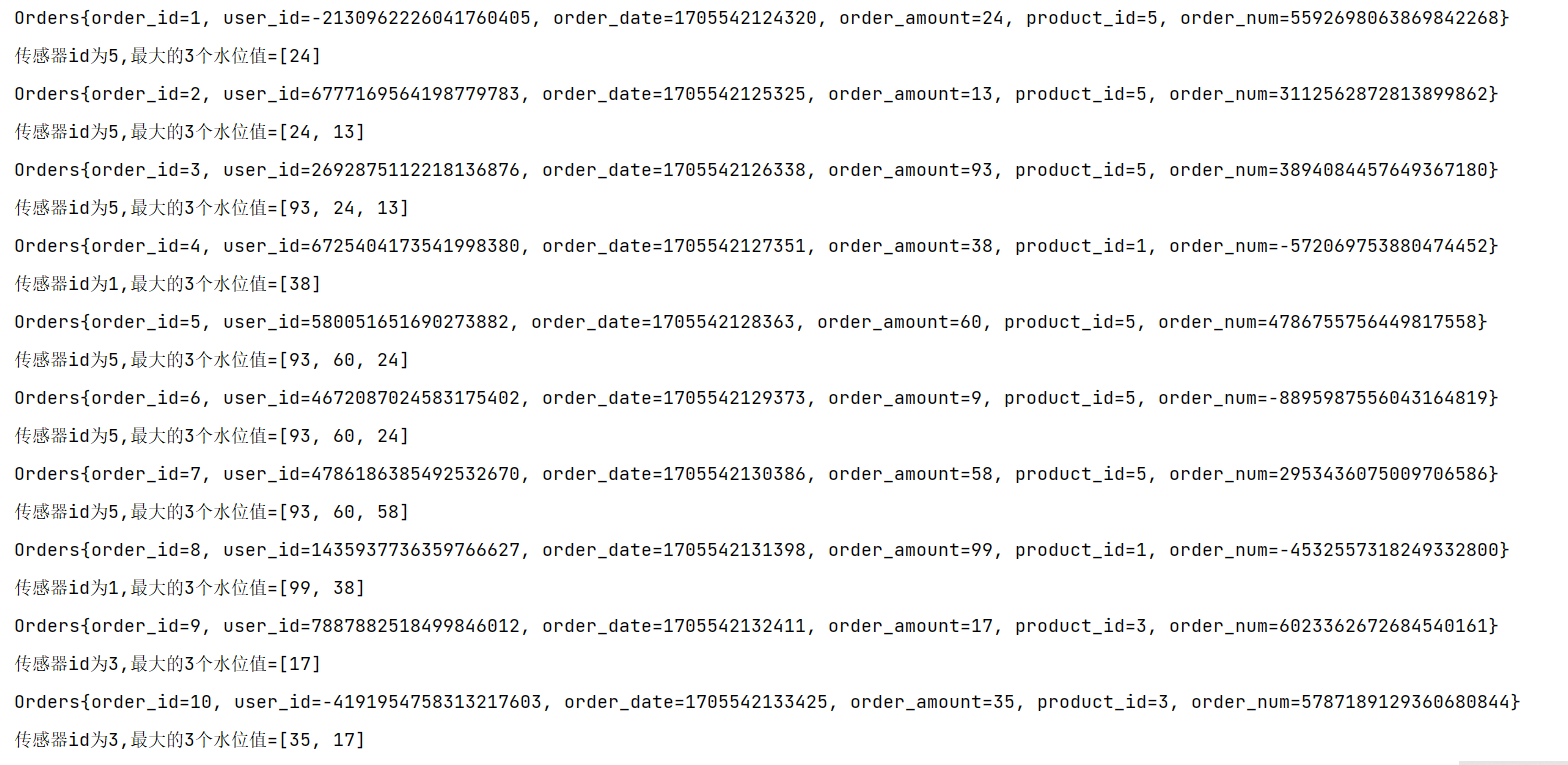
案例:针对每种传感器输出最高的3个水位值
package com.zxl.state;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;
import java.util.ArrayList;
import java.util.List;public class KeyedListStateDemo {public static void main(String[] args) throws Exception {// TODO: 2024/1/15 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/15 设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/15 设置水位线WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))// TODO: 2024/1/15 指定水位线中对应的时间字段.withTimestampAssigner((orders, l) -> orders.getOrder_date())// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力.withIdleness(Duration.ofSeconds(3));// TODO: 2024/1/15 添加水位线SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);SingleOutputStreamOperator<String> streamOperator = operator.keyBy(orders -> orders.getProduct_id()).process(new KeyedProcessFunction<Integer, Orders, String>() {// TODO 1.定义状态ListState<Integer> vcListState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// TODO 2.在open方法中,初始化状态// 状态描述器两个参数:第一个参数,起个名字,不重复;第二个参数,存储的类型vcListState = getRuntimeContext().getListState(new ListStateDescriptor<Integer>("vcListState", Types.INT));}@Overridepublic void processElement(Orders orders, KeyedProcessFunction<Integer, Orders, String>.Context context, Collector<String> out) throws Exception {// 1.来一条,存到list状态里vcListState.add(orders.getOrder_amount());// 2.从list状态拿出来(Iterable), 拷贝到一个List中,排序, 只留3个最大的Iterable<Integer> vcListIt = vcListState.get();// 2.1 拷贝到List中List<Integer> vcList = new ArrayList<>();for (Integer vc : vcListIt) {vcList.add(vc);}// 2.2 对List进行降序排序vcList.sort((o1, o2) -> o2 - o1);// 2.3 只保留最大的3个(list中的个数一定是连续变大,一超过3就立即清理即可)if (vcList.size() > 3) {// 将最后一个元素清除(第4个)vcList.remove(3);}out.collect("传感器id为" + orders.getProduct_id() + ",最大的3个水位值=" + vcList.toString());// 3.更新list状态vcListState.update(vcList);// vcListState.get(); //取出 list状态 本组的数据,是一个Iterable// vcListState.add(); // 向 list状态 本组 添加一个元素// vcListState.addAll(); // 向 list状态 本组 添加多个元素// vcListState.update(); // 更新 list状态 本组数据(覆盖)// vcListState.clear(); // 清空List状态 本组数据}});ordersDataStreamSource.print();streamOperator.print();environment.execute();}
}
Map状态(MapState)
把一些键值对(key-value)作为状态整体保存起来,可以认为就是一组key-value映射的列表。对应的MapState<UK, UV>接口中,就会有UK、UV两个泛型,分别表示保存的key和value的类型。同样,MapState提供了操作映射状态的方法,与Map的使用非常类似。
UV get(UK key):传入一个key作为参数,查询对应的value值;
put(UK key, UV value):传入一个键值对,更新key对应的value值;
putAll(Map<UK, UV> map):将传入的映射map中所有的键值对,全部添加到映射状态中;
remove(UK key):将指定key对应的键值对删除;
boolean contains(UK key):判断是否存在指定的key,返回一个boolean值。
另外,MapState也提供了获取整个映射相关信息的方法;
Iterable<Map.Entry<UK, UV>> entries():获取映射状态中所有的键值对;
Iterable<UK> keys():获取映射状态中所有的键(key),返回一个可迭代Iterable类型;
Iterable<UV> values():获取映射状态中所有的值(value),返回一个可迭代Iterable类型;
boolean isEmpty():判断映射是否为空,返回一个boolean值。
案例需求:统计每种传感器每种水位值出现的次数。
package com.zxl.state;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;
import java.util.Map;public class KeyedMapStateDemo {public static void main(String[] args) throws Exception {// TODO: 2024/1/15 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/15 设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/15 设置水位线WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))// TODO: 2024/1/15 指定水位线中对应的时间字段.withTimestampAssigner((orders, l) -> orders.getOrder_date())// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力.withIdleness(Duration.ofSeconds(3));// TODO: 2024/1/15 添加水位线SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);SingleOutputStreamOperator<String> streamOperator = operator.keyBy(orders -> orders.getProduct_id()).process(new KeyedProcessFunction<Integer, Orders, String>() {// TODO 1.定义状态MapState<Integer, Integer> vcCountMapState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// TODO 2.在open方法中,初始化状态// 状态描述器两个参数:第一个参数,起个名字,不重复;第二个参数,存储的类型vcCountMapState = getRuntimeContext().getMapState(new MapStateDescriptor<Integer, Integer>("vcCountMapState", Types.INT, Types.INT));}@Overridepublic void processElement(Orders orders, KeyedProcessFunction<Integer, Orders, String>.Context context, Collector<String> out) throws Exception {// 1.判断是否存在vc对应的keyInteger vc = orders.getProduct_id();if (vcCountMapState.contains(vc)) {// 1.1 如果包含这个vc的key,直接对value+1Integer count = vcCountMapState.get(vc);vcCountMapState.put(vc, ++count);} else {// 1.2 如果不包含这个vc的key,初始化put进去vcCountMapState.put(vc, 1);}// 2.遍历Map状态,输出每个k-v的值StringBuilder outStr = new StringBuilder();outStr.append("======================================\n");outStr.append("传感器id为" + orders.getProduct_id() + "\n");for (Map.Entry<Integer, Integer> vcCount : vcCountMapState.entries()) {outStr.append(vcCount.toString() + "\n");}outStr.append("======================================\n");out.collect(outStr.toString());// vcCountMapState.get(); // 对本组的Map状态,根据key,获取value
// vcCountMapState.contains(); // 对本组的Map状态,判断key是否存在
// vcCountMapState.put(, ); // 对本组的Map状态,添加一个 键值对
// vcCountMapState.putAll(); // 对本组的Map状态,添加多个 键值对
// vcCountMapState.entries(); // 对本组的Map状态,获取所有键值对
// vcCountMapState.keys(); // 对本组的Map状态,获取所有键
// vcCountMapState.values(); // 对本组的Map状态,获取所有值
// vcCountMapState.remove(); // 对本组的Map状态,根据指定key,移除键值对
// vcCountMapState.isEmpty(); // 对本组的Map状态,判断是否为空
// vcCountMapState.iterator(); // 对本组的Map状态,获取迭代器
// vcCountMapState.clear(); // 对本组的Map状态,清空}});ordersDataStreamSource.print();streamOperator.print();environment.execute();}
}

归约状态(ReducingState)
类似于值状态(Value),不过需要对添加进来的所有数据进行归约,将归约聚合之后的值作为状态保存下来。ReducingState这个接口调用的方法类似于ListState,只不过它保存的只是一个聚合值,所以调用.add()方法时,不是在状态列表里添加元素,而是直接把新数据和之前的状态进行归约,并用得到的结果更新状态。
归约逻辑的定义,是在归约状态描述器(ReducingStateDescriptor)中,通过传入一个归约函数(ReduceFunction)来实现的。这里的归约函数,就是我们之前介绍reduce聚合算子时讲到的ReduceFunction,所以状态类型跟输入的数据类型是一样的。
public ReducingStateDescriptor(String name, ReduceFunction<T> reduceFunction, Class<T> typeClass) {...}
这里的描述器有三个参数,其中第二个参数就是定义了归约聚合逻辑的ReduceFunction,另外两个参数则是状态的名称和类型。
案例:计算每种传感器的水位和
package com.zxl.state;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;public class ReducingStateDemo {public static void main(String[] args) throws Exception {// TODO: 2024/1/15 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/15 设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/15 设置水位线WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))// TODO: 2024/1/15 指定水位线中对应的时间字段.withTimestampAssigner((orders, l) -> orders.getOrder_date())// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力.withIdleness(Duration.ofSeconds(3));// TODO: 2024/1/15 添加水位线SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);SingleOutputStreamOperator<String> streamOperator = operator.keyBy(orders -> orders.getProduct_id()).process(new KeyedProcessFunction<Integer, Orders, String>() {// TODO 1.定义状态private ReducingState<Integer> sumVcState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// TODO 2.在open方法中,初始化状态// 状态描述器两个参数:第一个参数,起个名字,不重复;第二个参数,存储的类型sumVcState = this.getRuntimeContext().getReducingState(new ReducingStateDescriptor<Integer>("sumVcState", Integer::sum, Integer.class));}@Overridepublic void processElement(Orders orders, KeyedProcessFunction<Integer, Orders, String>.Context context, Collector<String> out) throws Exception {sumVcState.add(orders.getOrder_amount());out.collect(sumVcState.get().toString());}});ordersDataStreamSource.print();streamOperator.print();environment.execute();}
}

聚合状态(AggregatingState)
与归约状态非常类似,聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。与ReducingState不同的是,它的聚合逻辑是由在描述器中传入一个更加一般化的聚合函数(AggregateFunction)来定义的;这也就是之前我们讲过的AggregateFunction,里面通过一个累加器(Accumulator)来表示状态,所以聚合的状态类型可以跟添加进来的数据类型完全不同,使用更加灵活。
同样地,AggregatingState接口调用方法也与ReducingState相同,调用.add()方法添加元素时,会直接使用指定的AggregateFunction进行聚合并更新状态。
案例需求:计算每种传感器的平均水位
package com.zxl.state;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;public class KeyedAggregatingStateDemo {public static void main(String[] args) throws Exception {// TODO: 2024/1/15 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/15 设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/15 设置水位线WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))// TODO: 2024/1/15 指定水位线中对应的时间字段.withTimestampAssigner((orders, l) -> orders.getOrder_date())// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力.withIdleness(Duration.ofSeconds(3));// TODO: 2024/1/15 添加水位线SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);SingleOutputStreamOperator<String> streamOperator = operator.keyBy(orders -> orders.getProduct_id()).process(new KeyedProcessFunction<Integer, Orders, String>() {// TODO 1.定义状态AggregatingState<Integer, Double> vcAvgAggregatingState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// TODO 2.在open方法中,初始化状态// 状态描述器两个参数:第一个参数,起个名字,不重复;第二个参数,存储的类型vcAvgAggregatingState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<Integer, Tuple2<Integer, Integer>, Double>("vcAvgAggregatingState",new AggregateFunction<Integer, Tuple2<Integer, Integer>, Double>() {@Overridepublic Tuple2<Integer, Integer> createAccumulator() {return Tuple2.of(0, 0);}@Overridepublic Tuple2<Integer, Integer> add(Integer value, Tuple2<Integer, Integer> accumulator) {return Tuple2.of(accumulator.f0 + value, accumulator.f1 + 1);}@Overridepublic Double getResult(Tuple2<Integer, Integer> accumulator) {return accumulator.f0 * 1D / accumulator.f1;}@Overridepublic Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {
// return Tuple2.of(a.f0 + b.f0, a.f1 + b.f1);return null;}},Types.TUPLE(Types.INT, Types.INT)));}@Overridepublic void processElement(Orders orders, KeyedProcessFunction<Integer, Orders, String>.Context context, Collector<String> out) throws Exception {// 将 水位值 添加到 聚合状态中vcAvgAggregatingState.add(orders.getOrder_amount());// 从 聚合状态中 获取结果Double vcAvg = vcAvgAggregatingState.get();out.collect("传感器id为" + orders.getProduct_id() + ",平均水位值=" + vcAvg);// vcAvgAggregatingState.get(); // 对 本组的聚合状态 获取结果
// vcAvgAggregatingState.add(); // 对 本组的聚合状态 添加数据,会自动进行聚合
// vcAvgAggregatingState.clear(); // 对 本组的聚合状态 清空数据}});ordersDataStreamSource.print();streamOperator.print();environment.execute();}
}

状态生存时间(TTL)
在实际应用中,很多状态会随着时间的推移逐渐增长,如果不加以限制,最终就会导致存储空间的耗尽。一个优化的思路是直接在代码中调用.clear()方法去清除状态,但是有时候我们的逻辑要求不能直接清除。这时就需要配置一个状态的“生存时间”(time-to-live,TTL),当状态在内存中存在的时间超出这个值时,就将它清除。
具体实现上,如果用一个进程不停地扫描所有状态看是否过期,显然会占用大量资源做无用功。状态的失效其实不需要立即删除,所以我们可以给状态附加一个属性,也就是状态的“失效时间”。状态创建的时候,设置 失效时间 = 当前时间 + TTL;之后如果有对状态的访问和修改,我们可以再对失效时间进行更新;当设置的清除条件被触发时(比如,状态被访问的时候,或者每隔一段时间扫描一次失效状态),就可以判断状态是否失效、从而进行清除了。
配置状态的TTL时,需要创建一个StateTtlConfig配置对象,然后调用状态描述器的.enableTimeToLive()方法启动TTL功能。
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(10)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("my state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
这里用到了几个配置项:
.newBuilder()
状态TTL配置的构造器方法,必须调用,返回一个Builder之后再调用.build()方法就可以得到StateTtlConfig了。方法需要传入一个Time作为参数,这就是设定的状态生存时间。
.setUpdateType()
设置更新类型。更新类型指定了什么时候更新状态失效时间,这里的OnCreateAndWrite表示只有创建状态和更改状态(写操作)时更新失效时间。另一种类型OnReadAndWrite则表示无论读写操作都会更新失效时间,也就是只要对状态进行了访问,就表明它是活跃的,从而延长生存时间。这个配置默认为OnCreateAndWrite。
.setStateVisibility()
设置状态的可见性。所谓的“状态可见性”,是指因为清除操作并不是实时的,所以当状态过期之后还有可能继续存在,这时如果对它进行访问,能否正常读取到就是一个问题了。这里设置的NeverReturnExpired是默认行为,表示从不返回过期值,也就是只要过期就认为它已经被清除了,应用不能继续读取;这在处理会话或者隐私数据时比较重要。对应的另一种配置是ReturnExpireDefNotCleanedUp,就是如果过期状态还存在,就返回它的值。
除此之外,TTL配置还可以设置在保存检查点(checkpoint)时触发清除操作,或者配置增量的清理(incremental cleanup),还可以针对RocksDB状态后端使用压缩过滤器(compaction filter)进行后台清理。这里需要注意,目前的TTL设置只支持处理时间。
package com.zxl.state;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.*;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;public class StateTTLDemo {public static void main(String[] args) throws Exception {// TODO: 2024/1/15 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/15 设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/15 设置水位线WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))// TODO: 2024/1/15 指定水位线中对应的时间字段.withTimestampAssigner((orders, l) -> orders.getOrder_date())// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力.withIdleness(Duration.ofSeconds(3));// TODO: 2024/1/15 添加水位线SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);SingleOutputStreamOperator<String> streamOperator = operator.keyBy(orders -> orders.getProduct_id()).process(new KeyedProcessFunction<Integer, Orders, String>() {// TODO 1.定义状态ValueState<Integer> lastVcState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// TODO 2.在open方法中,初始化状态// 状态描述器两个参数:第一个参数,起个名字,不重复;第二个参数,存储的类型// TODO 1.创建 StateTtlConfigStateTtlConfig stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) // 过期时间5s// .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // 状态 创建和写入(更新) 更新 过期时间.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite) // 状态 读取、创建和写入(更新) 更新 过期时间.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 不返回过期的状态值.build();// TODO 2.状态描述器 启用 TTLValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("lastVcState", Types.INT);stateDescriptor.enableTimeToLive(stateTtlConfig);this.lastVcState = getRuntimeContext().getState(stateDescriptor);}@Overridepublic void processElement(Orders orders, KeyedProcessFunction<Integer, Orders, String>.Context context, Collector<String> out) throws Exception {// 先获取状态值,打印 ==》 读取状态Integer lastVc = lastVcState.value();out.collect("key=" + orders.getProduct_id() + ",状态值=" + lastVc);// 如果水位大于50,更新状态值 ===》 写入状态if (orders.getOrder_amount() > 50) {lastVcState.update(orders.getOrder_amount());}}});ordersDataStreamSource.print();streamOperator.print();environment.execute();}
}
算子状态(Operator State)
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。算子状态跟数据的key无关,所以不同key的数据只要被分发到同一个并行子任务,就会访问到同一个Operator State。
算子状态的实际应用场景不如Keyed State多,一般用在Source或Sink等与外部系统连接的算子上,或者完全没有key定义的场景。比如Flink的Kafka连接器中,就用到了算子状态。
当算子的并行度发生变化时,算子状态也支持在并行的算子任务实例之间做重组分配。根据状态的类型不同,重组分配的方案也会不同。
算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState和BroadcastState。
列表状态(ListState)
与Keyed State中的ListState一样,将状态表示为一组数据的列表。
与Keyed State中的列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
当算子并行度进行缩放调整时,算子的列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),与之前介绍的rebanlance数据传输方式类似,是通过逐一“发牌”的方式将状态项平均分配的。这种方式也叫作“平均分割重组”(even-split redistribution)。
算子状态中不会存在“键组”(key group)这样的结构,所以为了方便重组分配,就把它直接定义成了“列表”(list)。这也就解释了,为什么算子状态中没有最简单的值状态(ValueState)。
案例实操:在map算子中计算数据的个数。
package com.zxl.Operator;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.time.Duration;public class OperatorListStateDemo {public static void main(String[] args) throws Exception {// TODO: 2024/1/15 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/15 设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/15 设置水位线WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))// TODO: 2024/1/15 指定水位线中对应的时间字段.withTimestampAssigner((orders, l) -> orders.getOrder_date())// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力.withIdleness(Duration.ofSeconds(3));// TODO: 2024/1/15 添加水位线SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);operator.map(new MyCountMapFunction()).print();environment.execute();}// TODO 1.实现 CheckpointedFunction 接口public static class MyCountMapFunction implements MapFunction<Orders, Long>, CheckpointedFunction {private Long count = 0L;private ListState<Long> state;@Overridepublic Long map(Orders value) throws Exception {return ++count;}/*** TODO 2.本地变量持久化:将 本地变量 拷贝到 算子状态中,开启checkpoint时才会调用** @param context* @throws Exception*/@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {System.out.println("snapshotState...");// 2.1 清空算子状态state.clear();// 2.2 将 本地变量 添加到 算子状态 中state.add(count);}/*** TODO 3.初始化本地变量:程序启动和恢复时, 从状态中 把数据添加到 本地变量,每个子任务调用一次** @param context* @throws Exception*/@Overridepublic void initializeState(FunctionInitializationContext context) throws Exception {System.out.println("initializeState...");// 3.1 从 上下文 初始化 算子状态state = context.getOperatorStateStore().getListState(new ListStateDescriptor<Long>("state", Types.LONG));// 3.2 从 算子状态中 把数据 拷贝到 本地变量if (context.isRestored()) {for (Long c : state.get()) {count += c;}}}}
}

联合列表状态(UnionListState)
与ListState类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于,算子并行度进行缩放调整时对于状态的分配方式不同。
UnionListState的重点就在于“联合”(union)。在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。这样,并行度缩放之后的并行子任务就获取到了联合后完整的“大列表”,可以自行选择要使用的状态项和要丢弃的状态项。这种分配也叫作“联合重组”(union redistribution)。如果列表中状态项数量太多,为资源和效率考虑一般不建议使用联合重组的方式。
使用方式同ListState,区别在如下标红部分:
package com.zxl.Operator;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.time.Duration;public class OperatorListStateDemo {public static void main(String[] args) throws Exception {// TODO: 2024/1/15 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/15 设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/15 设置水位线WatermarkStrategy<Orders> watermarkStrategy = WatermarkStrategy// TODO: 2024/1/15 设置最大乱序程度,数据流中乱序数据时间戳的最大差值.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3))// TODO: 2024/1/15 指定水位线中对应的时间字段.withTimestampAssigner((orders, l) -> orders.getOrder_date())// TODO: 2024/1/15 设置空闲等待时间,如果某个分区中有长时间无数据产生将放弃此分区的水位线选举权力.withIdleness(Duration.ofSeconds(3));// TODO: 2024/1/15 添加水位线SingleOutputStreamOperator<Orders> operator = ordersDataStreamSource.assignTimestampsAndWatermarks(watermarkStrategy);operator.map(new MyCountMapFunction()).print();environment.execute();}// TODO 1.实现 CheckpointedFunction 接口public static class MyCountMapFunction implements MapFunction<Orders, Long>, CheckpointedFunction {private Long count = 0L;private ListState<Long> state;@Overridepublic Long map(Orders value) throws Exception {return ++count;}/*** TODO 2.本地变量持久化:将 本地变量 拷贝到 算子状态中,开启checkpoint时才会调用** @param context* @throws Exception*/@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {System.out.println("snapshotState...");// 2.1 清空算子状态state.clear();// 2.2 将 本地变量 添加到 算子状态 中state.add(count);}/*** TODO 3.初始化本地变量:程序启动和恢复时, 从状态中 把数据添加到 本地变量,每个子任务调用一次** @param context* @throws Exception*/@Overridepublic void initializeState(FunctionInitializationContext context) throws Exception {System.out.println("initializeState...");// 3.1 从 上下文 初始化 算子状态state = context.getOperatorStateStore()// TODO: 2024/1/18 UnionListState .getUnionListState(new ListStateDescriptor<Long>("union-state", Types.LONG));// 3.2 从 算子状态中 把数据 拷贝到 本地变量if (context.isRestored()) {for (Long c : state.get()) {count += c;}}}}
}

广播状态(BroadcastState)
有时我们希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
因为广播状态在每个并行子任务上的实例都一样,所以在并行度调整的时候就比较简单,只要复制一份到新的并行任务就可以实现扩展;而对于并行度缩小的情况,可以将多余的并行子任务连同状态直接砍掉——因为状态都是复制出来的,并不会丢失。
案例实操:水位超过指定的阈值发送告警,阈值可以动态修改。
package com.zxl.Operator;import com.zxl.bean.Orders;
import com.zxl.bean.Payments;
import com.zxl.datas.OrdersData;
import com.zxl.datas.PaymentData;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;public class OperatorBroadcastStateDemo {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(2);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());ordersDataStreamSource.print();// TODO: 2024/1/6 支付数据DataStreamSource<Payments> paymentsDataStreamSource = environment.addSource(new PaymentData());paymentsDataStreamSource.print();// TODO 1. 将 配置流 广播MapStateDescriptor<String, Integer> broadcastMapState = new MapStateDescriptor<>("broadcast-state", Types.STRING, Types.INT);BroadcastStream<Payments> broadcast = paymentsDataStreamSource.broadcast(broadcastMapState);// TODO 2.把 数据流 和 广播后的配置流 connectBroadcastConnectedStream<Orders, Payments> connectedStream = ordersDataStreamSource.connect(broadcast);// TODO 3.调用 processconnectedStream.process(new BroadcastProcessFunction<Orders, Payments, String>() {// TODO: 2024/1/18 数据流的处理方法: 数据流 只能 读取 广播状态,不能修改@Overridepublic void processElement(Orders orders, BroadcastProcessFunction<Orders, Payments, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {// TODO 5.通过上下文获取广播状态,取出里面的值(只读,不能修改)ReadOnlyBroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);Integer threshold = broadcastState.get("threshold");// 判断广播状态里是否有数据,因为刚启动时,可能是数据流的第一条数据先来threshold = (threshold == null ? 0 : threshold);if (orders.getOrder_amount() > threshold) {out.collect(orders.getOrder_amount() + ",水位超过指定的阈值:" + threshold + "!!!");}}// TODO: 2024/1/18 广播后的配置流的处理方法: 只有广播流才能修改 广播状态@Overridepublic void processBroadcastElement(Payments payments, BroadcastProcessFunction<Orders, Payments, String>.Context ctx, Collector<String> collector) throws Exception {// TODO 4. 通过上下文获取广播状态,往里面写数据BroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);broadcastState.put("threshold", payments.getPayment_amount());}}).print();environment.execute();}
}

状态后端(State Backends)
在Flink中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端(state backend)。状态后端主要负责管理本地状态的存储方式和位置。
状态后端的分类(HashMapStateBackend/RocksDB)
状态后端是一个“开箱即用”的组件,可以在不改变应用程序逻辑的情况下独立配置。Flink中提供了两类不同的状态后端,一种是“哈希表状态后端”(HashMapStateBackend),另一种是“内嵌RocksDB状态后端”(EmbeddedRocksDBStateBackend)。如果没有特别配置,系统默认的状态后端是HashMapStateBackend。
哈希表状态后端(HashMapStateBackend)
HashMapStateBackend是把状态存放在内存里。具体实现上,哈希表状态后端在内部会直接把状态当作对象(objects),保存在Taskmanager的JVM堆上。普通的状态,以及窗口中收集的数据和触发器,都会以键值对的形式存储起来,所以底层是一个哈希表(HashMap),这种状态后端也因此得名。
内嵌RocksDB状态后端(EmbeddedRocksDBStateBackend)
RocksDB是一种内嵌的key-value存储介质,可以把数据持久化到本地硬盘。配置EmbeddedRocksDBStateBackend后,会将处理中的数据全部放入RocksDB数据库中,RocksDB默认存储在TaskManager的本地数据目录里。
RocksDB的状态数据被存储为序列化的字节数组,读写操作需要序列化/反序列化,因此状态的访问性能要差一些。另外,因为做了序列化,key的比较也会按照字节进行,而不是直接调用.hashCode()和.equals()方法。
EmbeddedRocksDBStateBackend始终执行的是异步快照,所以不会因为保存检查点而阻塞数据的处理;而且它还提供了增量式保存检查点的机制,这在很多情况下可以大大提升保存效率。
如何选择正确的状态后端
HashMap和RocksDB两种状态后端最大的区别,就在于本地状态存放在哪里。
HashMapStateBackend是内存计算,读写速度非常快;但是,状态的大小会受到集群可用内存的限制,如果应用的状态随着时间不停地增长,就会耗尽内存资源。
而RocksDB是硬盘存储,所以可以根据可用的磁盘空间进行扩展,所以它非常适合于超级海量状态的存储。不过由于每个状态的读写都需要做序列化/反序列化,而且可能需要直接从磁盘读取数据,这就会导致性能的降低,平均读写性能要比HashMapStateBackend慢一个数量级。
状态后端的配置
在不做配置的时候,应用程序使用的默认状态后端是由集群配置文件flink-conf.yaml中指定的,配置的键名称为state.backend。这个默认配置对集群上运行的所有作业都有效,我们可以通过更改配置值来改变默认的状态后端。另外,我们还可以在代码中为当前作业单独配置状态后端,这个配置会覆盖掉集群配置文件的默认值。
配置默认的状态后端
在flink-conf.yaml中,可以使用state.backend来配置默认状态后端。
配置项的可能值为hashmap,这样配置的就是HashMapStateBackend;如果配置项的值是rocksdb,这样配置的就是EmbeddedRocksDBStateBackend。
下面是一个配置HashMapStateBackend的例子:
默认状态后端
state.backend: hashmap
存放检查点的文件路径
state.checkpoints.dir: hdfs://hadoop102:8020/flink/checkpoints
这里的state.checkpoints.dir配置项,定义了检查点和元数据写入的目录。
为每个作业(Per-job/Application)单独配置状态后端
//通过执行环境设置,HashMapStateBackend。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new HashMapStateBackend());
//通过执行环境设置,EmbeddedRocksDBStateBackend。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new EmbeddedRocksDBStateBackend());
需要注意,如果想在IDE中使用EmbeddedRocksDBStateBackend,需要为Flink项目添加依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb</artifactId><version>${flink.version}</version>
</dependency>
而由于Flink发行版中默认就包含了RocksDB(服务器上解压的Flink),所以只要我们的代码中没有使用RocksDB的相关内容,就不需要引入这个依赖。
// TODO: 2024/1/18 创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();// TODO: 2024/1/18 配置状态后端 environment.setStateBackend(new RocksDBStateBackend("file:///E:/FlinkWorks/FlinkJoin/src/main/resources"));// TODO: 2024/1/18 每隔2秒启动一次检查点保存environment.enableCheckpointing(2000);
相关文章:
FlinkAPI开发之状态管理
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048 Flink中的状态 概述 有状态的算子 状态的分类 托管状态(Managed State)和原始状态&…...

initdb: command not found【PostgreSQL】
如果您遇到 “initdb: command not found” 错误,说明 initdb 命令未找到,该命令用于初始化新的 PostgreSQL 数据库群集。这通常是因为 PostgreSQL 相关的工具未正确安装或者安装路径不在系统的 PATH 变量中。 以下是解决这个问题的一些建议:…...
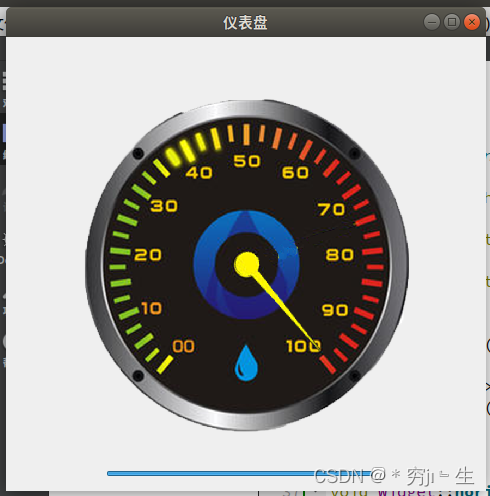
QT第六天
要求:使用QT绘图,完成仪表盘绘制,如下图。 素材 运行效果: 代码: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QPainter> #include <QPen>QT_BEGIN_NAMESPACE name…...

linux 安装 grafana
Ubuntu 和 Debian(64 位)SHA256: e551434e9e3e585633f7b56a33d8f49cda138d92ad69c2c29dcec2c3ede84607 sudo apt-get install -y adduser libfontconfig1 muslwget https://dl.grafana.com/enterprise/release/grafana-enterprise_10.2.3_amd64.debsudo dpkg -i gra…...
“GPC爬虫池有用吗?
作为光算科技的独有技术,在深入研究谷歌爬虫推出的一种吸引谷歌爬虫的手段 要知道GPC爬虫池是否有用,就要知道谷歌爬虫这一概念,谷歌作为一个搜索引擎,里面有成百上千亿个网站,对于里面的网站内容,自然不可…...

Kotlin协程的JVM实现源码分析(下)
协程 根据 是否保存切换 调用栈 ,分为: 有栈协程(stackful coroutine)无栈协程(stackless coroutine) 在代码上的区别是:是否可在普通函数里调用,并暂停其执行。 Kotlin协程&…...

js实现九九乘法表
效果图 代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><script type"text/javascript">// 输出乘法口诀表// document.write () 空格 " " 换行…...
HarmonyOS鸿蒙应用开发(三、轻量级配置存储dataPreferences)
在应用开发中存储一些配置是很常见的需求。在android中有SharedPreferences,一个轻量级的存储类,用来保存应用的一些常用配置。在HarmonyOS鸿蒙应用开发中,实现类似功能的也叫首选项,dataPreferences。 相关概念 ohos.data.prefe…...
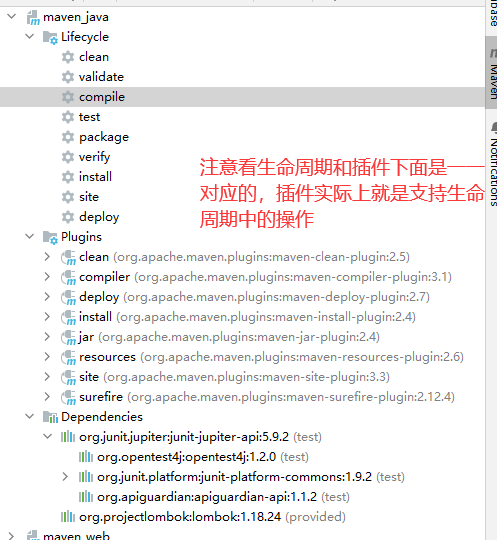
基于 IDEA 进行 Maven 工程构建
1. 构建概念和构建过程 项目构建是指将源代码、依赖库和资源文件等转换成可执行或可部署的应用程序的过程,在这个过程中包括编译源代码、链接依赖库、打包和部署等多个步骤。 项目构建是软件开发过程中至关重要的一部分,它能够大大提高软件开发效率&am…...

牛客周赛 Round 17 解题报告 | 珂学家 | 枚举贪心 + 二分最短路
前言 整体评价 其实T3最有意思, T4很典,是一道二分最短路径经典套路。 T3 如果尝试 增量差值最小 的最大梯度去贪心的话,会失败,需要切换思路。 珂朵莉 牛客周赛专栏 珂朵莉 牛客小白月赛专栏 A. 游游的正方形披萨 如果横竖差…...
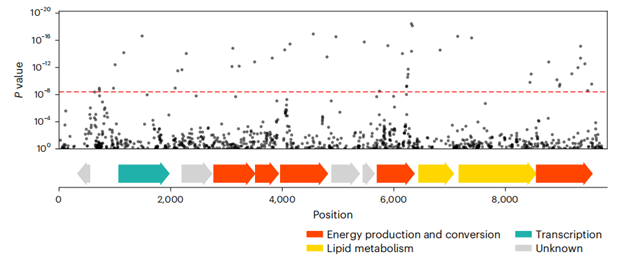
喝口水都长胖?原来是“胖菌”惹的祸?!
减肥是一个永恒的话题,而关于长胖的原因,已有研究很多都聚焦在肥胖人群中肠道菌群的种类和丰度,很少有研究关注肠道微生物的基因与宿主肥胖的关系。近期发表在《Nature Medicine》的这项研究,使用来GWAS研究人类肠道微生物组与宿主…...

【C++干货基地】namespace超越C语言的独特魅力(文末送书)
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 引入 哈喽各位铁汁们好啊,我是博主鸽芷咕《C干货基地》是由我的襄阳家乡零食基地有感而发,不知道各位的…...

做一个简单的倒计时
<div>距离过年还有:<span></span></div><script>let div document.querySelector("div");let span document.querySelector("span");// 获取未来时间戳let future new Date("2024-2-10 00:00:00");// 获取当下…...
微服务环境搭建:docker+nacos单机
nacos需要连接mysql,持久化相关配置。 1. 部署好mysql后,新建nacos数据库然后初始化nacos脚本 -- -------------------------------------------------------- -- 主机: 192.168.150.101 -- 服务器版本: …...

Opencv轮廓检测运用与理解
目录 引入 基本理解 加深理解 ①比如我们可以获取我们的第一个轮廓,只展示第一个轮廓 ②我们还可以用一个矩形把我们的轮廓给框出来 ③计算轮廓的周长和面积 引入 顾名思义,就是把我们图片的轮廓全部都描边出来 也就是我们在日常生活中面部识别的时候会有一个框,那玩意就…...
)
Java 8的新特性简单分享(后续有系列篇~敬请期待)
Java 8的新特性分享 Java 8是Java语言迎来的一次革命性的更新,引入了众多强大的新特性,使得Java开发变得更加现代化和便捷。在这篇博客中,我们将深入探讨Java 8的一些主要特性,并通过丰富的案例演示展示它们的用法。 1. Lambda表…...
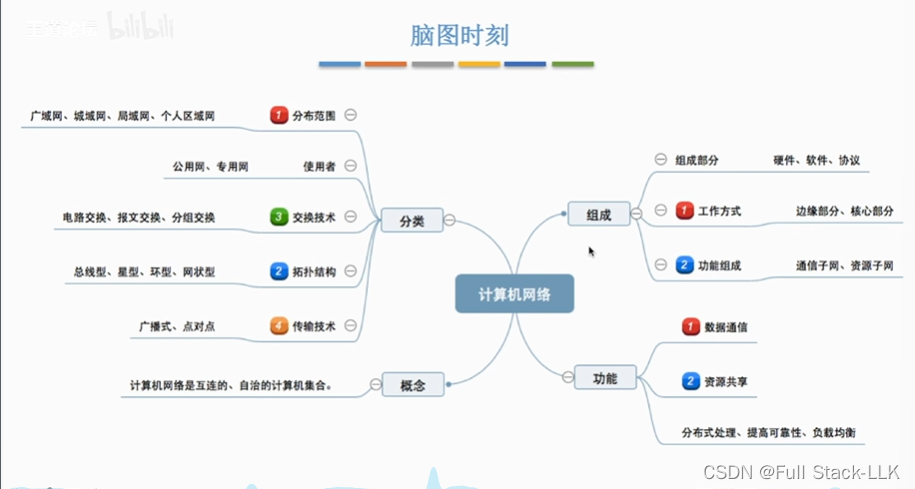
计算机网络-计算机网络的概念 功能 发展阶段 组成 分类
文章目录 计算机网络的概念 功能 发展阶段总览计算机网络的概念计算机网络的功能计算机网络的发展计算机网络的发展-第一阶段计算机网络的发展-第二阶段-第三阶段计算机网络的发展-第三阶段-多层次ISP结构 小结 计算机网络的组成与分类计算机网络的组成计算机网络的分类小结 计…...
】分月饼(动态规划-JavaPythonC++JS实现))
246.【2023年华为OD机试真题(C卷)】分月饼(动态规划-JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-分月饼二.解题思路三.题解代码Python题解代码J…...
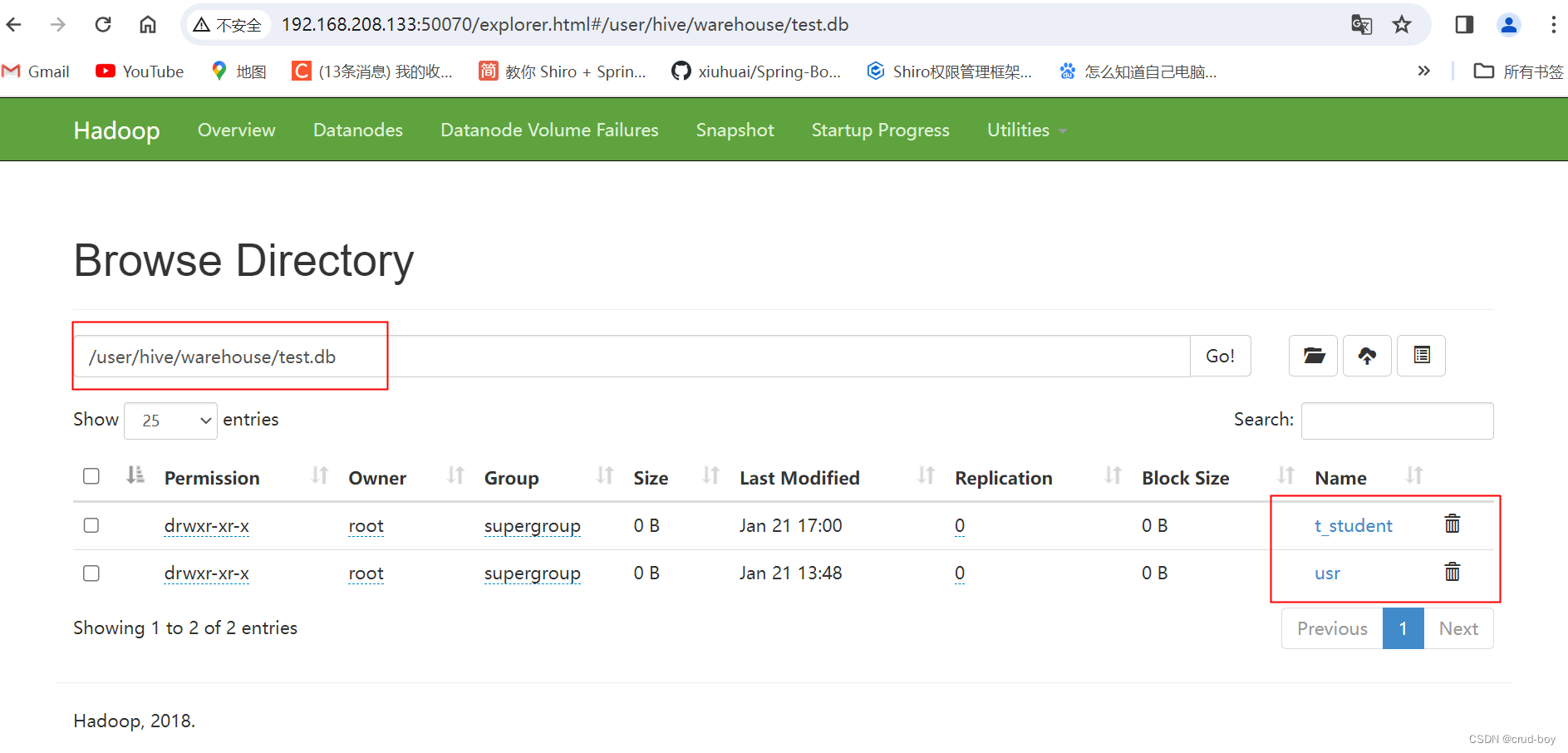
java大数据hadoop2.9.2 Linux安装mariadb和hive
一、安装mariadb 版本centos7 1、检查Linux服务器是否已安装mariadb yum list installed mariadb* 2、如果安装了,想要卸载 yum remove mariadb rm -rf /etc/my.cnf rm -rf /var/lib/mysql 才能完全删除 3、安装mariadb 在线网络安装 yum install -y mari…...

Docker部署微服务问题及解决
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习 🌌上期文章:Docker容器命令案例:Nginx容器修改,Redis容器持久化 📚订阅专栏:Docker 希望文章…...

如何快速上手SillyTavern:新手完整入门指南
如何快速上手SillyTavern:新手完整入门指南 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 还在为复杂的LLM前端配置而烦恼吗?SillyTavern作为一款专为高级用户设计…...

Mac视频预览终极指南:QuickLookVideo让你的Finder焕然一新
Mac视频预览终极指南:QuickLookVideo让你的Finder焕然一新 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gi…...

Spring Boot 面试题详解:Spring Boot 核心原理、自动配置、启动流程、IoC 容器、Web 请求链路、事务、Actuator 与 JVM 线上排障全攻略
1. Spring Boot 到底是什么?为什么 Java 后端几乎绕不开它?1.1 它不是新语言,也不是替代 Spring,而是 Spring 应用的工程化脚手架Spring Boot 的出现,本质上是为了解决传统 Spring 项目启动慢、配置多、依赖难配、上线…...

MCUXpresso for VS Code集成J-Link脚本的三种工程化方法详解
1. 项目概述:为什么要在IDE里折腾脚本?如果你是一位使用NXP MCU的嵌入式开发者,大概率对MCUXpresso IDE和SEGGER J-Link调试器这对黄金搭档不陌生。在传统的MCUXpresso IDE(基于Eclipse)里,通过图形界面配置…...

书匠策AI论文生存指南:降重降AIGC,2025届毕业生的“反内卷外挂“
🎬 开场:一场关于"论文能不能活着毕业"的生存实验 朋友们,今天咱不开学术讲座,咱开一场生存发布会。 2025年写毕业论文是什么体验?你辛辛苦苦码了两万字,满怀信心点了查重——好家伙࿰…...

NAS如何变身创作利器?基于绿联DX4600 Pro自建图床与Typora无缝协作
1. 为什么选择NAS自建图床? 作为一名长期使用Markdown写作的内容创作者,我深知图片管理的重要性。过去三年我先后尝试过七牛云、又拍云等第三方图床服务,虽然费用不高(每月约5-10元),但经常遇到两个致命问题…...

剪流AI事业大使是不是割韭菜?深度解析其真实运作细节与收益模型
近年来,“AI事业大使”成为一个热门话题,尤其是剪流AI推出的相关计划,引发了广泛讨论。其中,“AI事业大使是不是割韭菜”是许多观望者心中的核心疑问。本文将基于其公开的运作细节与权益体系,进行客观、深度的解析&…...

Windows电脑直接运行安卓应用:APK安装器完全指南
Windows电脑直接运行安卓应用:APK安装器完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾幻想过在Windows电脑上流畅运行安卓应用ÿ…...

别再只盯着业务代码了!SpringBoot应用层安全之Tomcat连接管理实战
SpringBoot应用层安全实战:Tomcat连接管理的三驾马车 当我们在讨论SpringBoot应用安全时,业务代码的漏洞修复往往占据了大部分注意力。然而,真正的安全防线远不止于此——应用层基础设施的配置与优化同样至关重要。想象一下,你的应…...
)
AI视频时间一致性失效的7种隐藏诱因(GPU显存碎片化、隐空间梯度漂移、跨模态时钟不同步…业内首次系统归因)
更多请点击: https://intelliparadigm.com 第一章:AI视频时间一致性失效的系统性归因框架 AI视频生成中,时间一致性失效并非孤立现象,而是多层级模型组件、训练范式与推理机制耦合失配的结果。其根源横跨数据建模、特征传播、时序…...