kafka参数配置参考和优化建议 —— 筑梦之路
对于Kafka的优化,可以从以下几个方面进行思考和优化:
硬件优化:使用高性能的硬件设备,包括高速磁盘、大内存和高性能网络设备,以提高Kafka集群的整体性能。
配置优化:调整Kafka的配置参数,包括消息存储、副本数、日志段大小、缓冲区大小等,以提高Kafka的吞吐量和稳定性。
网络优化:优化Kafka集群的网络设置,包括网络带宽、延迟和可靠性,以确保消息能够快速、可靠地传输。
分区优化:合理划分分区,避免分区过多或过少,以充分利用集群资源并提高消息的并发处理能力。
监控优化:建立完善的监控系统,及时发现和解决Kafka集群的性能瓶颈和故障,以保障Kafka的稳定运行。
客户端优化:优化生产者和消费者的配置和代码,以提高消息的生产和消费效率。
总的来说,Kafka的优化需要综合考虑硬件、配置、网络、分区、监控和客户端等多个方面,以达到提高性能和稳定性的目的。下面我将主要从Kafka使用参数设置来说明优化的主要思路,其基本核心思想就是提高Kafka的吞吐量和降低网络延迟。
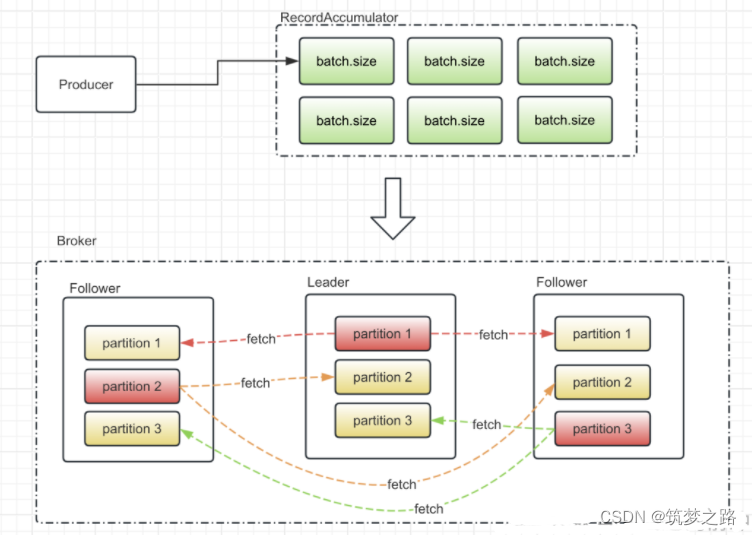
生产者端(Producer)的参数
acks:默认值为1,表示指定分区中成功写入消息的副本数量。一般不需要修改。
max.request.size:默认值为1048576,即1M1。这个参数比较重要,表示生产端能够发送的最大消息大小。为了避免因消息过大导致发送失败,建议适当调大,比如调到10485760即10M。
retries:默认值为0,表示生产端消息发送失败时的重试次数。为了解决因瞬时故障导致的消息发送失败,比如网络抖动、leader换主,其中瞬时的leader重选举是比较常见的。因此这个参数的设置显得非常重要。建议设置为一个大于0的值,比如3或者更大值。
compression.type:默认值为none,表示生产端是否对消息进行压缩。一般不需要修改。
buffer.memory:默认值为33554432,即32M。表示生产端消息缓冲池或缓冲区的大小。一般不需要修改。
batch.size:默认值为16384,即16KB。发送到缓冲区中的消息会被分为一个一个的batch,分批次的发送到broker 端,这个参数就表示batch批次大小。可以根据实际情况或者压测情况来更改这个值,这个值太小,会导致频繁的网络请求,从而导致吞吐量下降,这个值太大会导致一条消息需要等待很长的时间才能发送出去,会增加网络的延迟。
linger.ms:默认值为0。用来控制batch最大的空闲时间,超过该时间的batch也会被发送到broker端。建议修改范围10~100之间,影响结果可以参考batch.size.
request.timeout.ms:默认值为30000,即30s。这个参数表示生产端发送请求后等待broker端响应的最长时间。一般不需要修改。
max.in.fight.requests.per.connection:默认值为5。这个参数非常重要,表示生产端与broker之间的每个连接最多缓存的请求数。一般不需要修改。
代理端(Broker)的参数
broker.id:默认值为0。每个broker都可以用一个唯一的非负整数id进行标识。你可以选择任意你喜欢的数字作为id,只要id是唯一的即可。
log.dirs:默认值为/tmp/kafka-logs。kafka存放数据的路径。这个路径并不是唯一的,可以是多个,路径之间只需要使用逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进行。
port:默认值为6667。server接收客户端连接的端口。根据实际网络环境和安全需求进行设置。
zookeeper.connect:默认值为null。ZooKeeper连接字符串的格式为:hostname:port。为了当某个host宕掉之后你能通过其他ZooKeeper节点进行连接,你可以按照以下方式制定多个hosts:hostname1:port1, hostname2:port2, hostname3:port33。
message.max.bytes:默认值为1000000。server可以接收的消息最大尺寸。重要的是,consumer和producer有关这个属性的设置必须同步,否则producer发布的消息对consumer来说太大。
num.network.threads:默认值为3。server用来处理网络请求的网络线程数目。一般你不需要更改这个属性。
num.io.threads:默认值为8。server用来处理请求的I/O线程的数目。这个线程数目至少要等于硬盘的个数。
background.threads:默认值为4。用于后台处理的线程数目,例如文件删除。你不需要更改这个属性。
queued.max.requests:默认值为500。在网络线程停止读取新请求之前,可以排队等待I/O线程处理的最大请求个数。根据实际业务需求进行设置。
fetch.min.bytes:表示Broker端积攒了多少数据就可以返回给consumer端
fetch.max.bytes: 默认值:50MB 消费者获取服务端一批数据最大的字节数, 这个参数主要受到下面两个参数的限制
message.max.bytes = broker配置 max.message.bytes = topic配置
消费者端(Consumer)的参数
fetch.min.bytes:默认值为1。消费者从服务器获取的最小数据量。如果设置为1,则消费者尽可能地从服务器获取数据;如果设置为1MB,则消费者会等待直到1MB的数据可用才从服务器获取。
fetch.max.wait.ms:默认值为500。消费者等待从服务器获取数据的最长时间。
max.partition.fetch.bytes:默认值为1048576,即1MB。消费者一次从服务器获取每个分区的最大字节数。
session.timeout.ms:默认值为30000,即30s。消费者在被认为死亡之前可以与服务器断开连接的时间。
auto.offset.reset:默认值为latest。消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该如何做。
原文链接:Kafka主要参数设置及优化建议
作为搜集。
相关文章:
kafka参数配置参考和优化建议 —— 筑梦之路
对于Kafka的优化,可以从以下几个方面进行思考和优化: 硬件优化:使用高性能的硬件设备,包括高速磁盘、大内存和高性能网络设备,以提高Kafka集群的整体性能。 配置优化:调整Kafka的配置参数,包括…...
如何本地搭建Splunk Enterprise数据平台并实现任意浏览器公网访问
文章目录 前言1. 搭建Splunk Enterprise2. windows 安装 cpolar3. 创建Splunk Enterprise公网访问地址4. 远程访问Splunk Enterprise服务5. 固定远程地址 前言 本文主要介绍如何简单几步,结合cpolar内网穿透工具实现随时随地在任意浏览器,远程访问在本地…...
FlinkAPI开发之状态管理
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048 Flink中的状态 概述 有状态的算子 状态的分类 托管状态(Managed State)和原始状态&…...

initdb: command not found【PostgreSQL】
如果您遇到 “initdb: command not found” 错误,说明 initdb 命令未找到,该命令用于初始化新的 PostgreSQL 数据库群集。这通常是因为 PostgreSQL 相关的工具未正确安装或者安装路径不在系统的 PATH 变量中。 以下是解决这个问题的一些建议:…...
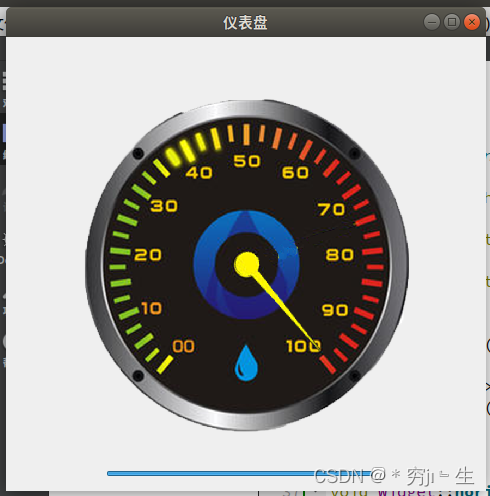
QT第六天
要求:使用QT绘图,完成仪表盘绘制,如下图。 素材 运行效果: 代码: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QPainter> #include <QPen>QT_BEGIN_NAMESPACE name…...

linux 安装 grafana
Ubuntu 和 Debian(64 位)SHA256: e551434e9e3e585633f7b56a33d8f49cda138d92ad69c2c29dcec2c3ede84607 sudo apt-get install -y adduser libfontconfig1 muslwget https://dl.grafana.com/enterprise/release/grafana-enterprise_10.2.3_amd64.debsudo dpkg -i gra…...
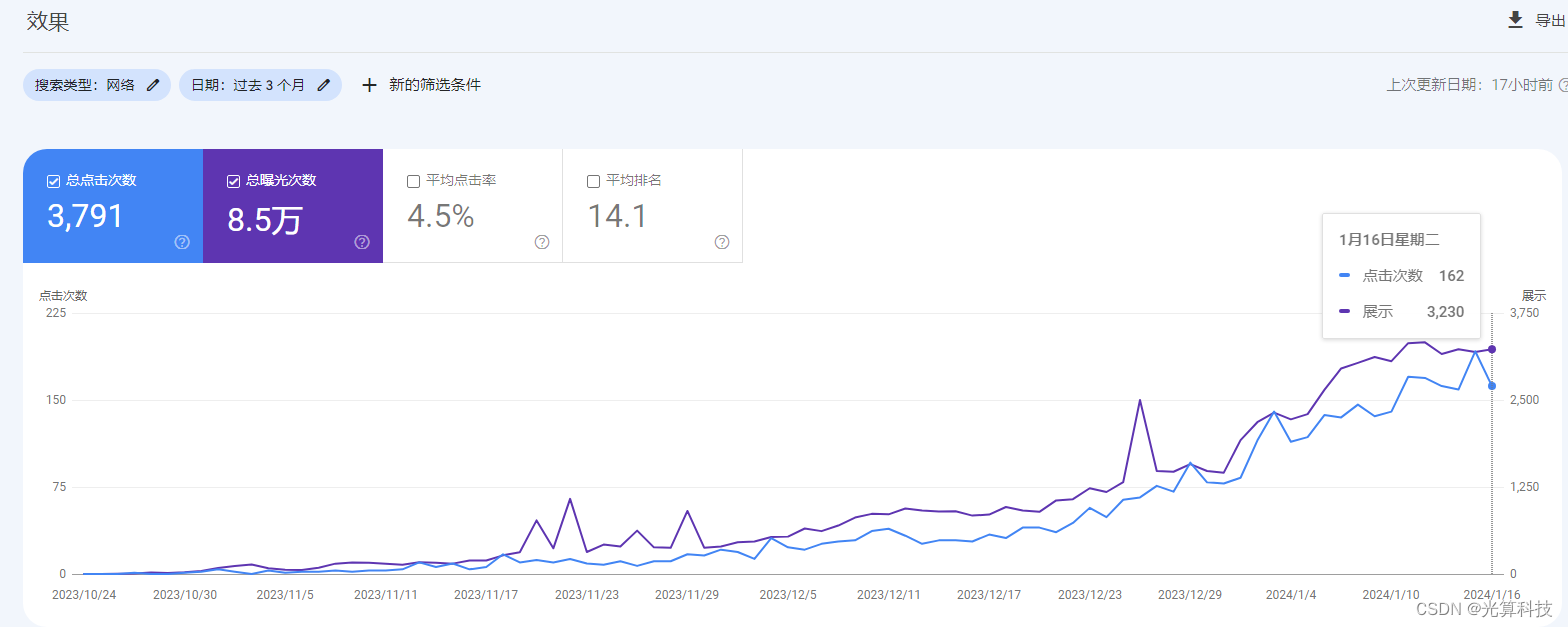
“GPC爬虫池有用吗?
作为光算科技的独有技术,在深入研究谷歌爬虫推出的一种吸引谷歌爬虫的手段 要知道GPC爬虫池是否有用,就要知道谷歌爬虫这一概念,谷歌作为一个搜索引擎,里面有成百上千亿个网站,对于里面的网站内容,自然不可…...

Kotlin协程的JVM实现源码分析(下)
协程 根据 是否保存切换 调用栈 ,分为: 有栈协程(stackful coroutine)无栈协程(stackless coroutine) 在代码上的区别是:是否可在普通函数里调用,并暂停其执行。 Kotlin协程&…...

js实现九九乘法表
效果图 代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><script type"text/javascript">// 输出乘法口诀表// document.write () 空格 " " 换行…...
HarmonyOS鸿蒙应用开发(三、轻量级配置存储dataPreferences)
在应用开发中存储一些配置是很常见的需求。在android中有SharedPreferences,一个轻量级的存储类,用来保存应用的一些常用配置。在HarmonyOS鸿蒙应用开发中,实现类似功能的也叫首选项,dataPreferences。 相关概念 ohos.data.prefe…...
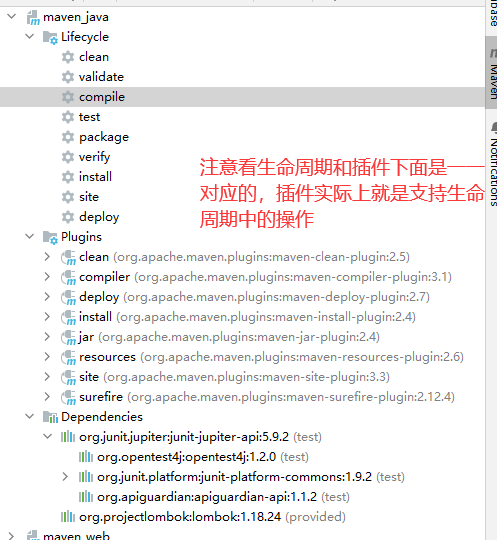
基于 IDEA 进行 Maven 工程构建
1. 构建概念和构建过程 项目构建是指将源代码、依赖库和资源文件等转换成可执行或可部署的应用程序的过程,在这个过程中包括编译源代码、链接依赖库、打包和部署等多个步骤。 项目构建是软件开发过程中至关重要的一部分,它能够大大提高软件开发效率&am…...

牛客周赛 Round 17 解题报告 | 珂学家 | 枚举贪心 + 二分最短路
前言 整体评价 其实T3最有意思, T4很典,是一道二分最短路径经典套路。 T3 如果尝试 增量差值最小 的最大梯度去贪心的话,会失败,需要切换思路。 珂朵莉 牛客周赛专栏 珂朵莉 牛客小白月赛专栏 A. 游游的正方形披萨 如果横竖差…...
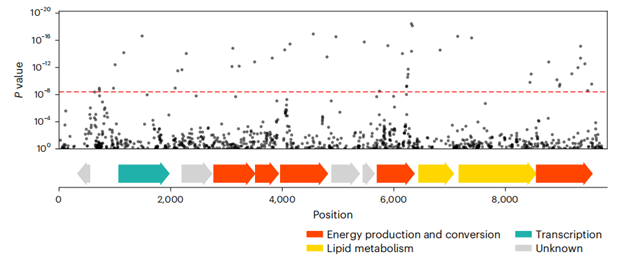
喝口水都长胖?原来是“胖菌”惹的祸?!
减肥是一个永恒的话题,而关于长胖的原因,已有研究很多都聚焦在肥胖人群中肠道菌群的种类和丰度,很少有研究关注肠道微生物的基因与宿主肥胖的关系。近期发表在《Nature Medicine》的这项研究,使用来GWAS研究人类肠道微生物组与宿主…...

【C++干货基地】namespace超越C语言的独特魅力(文末送书)
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 引入 哈喽各位铁汁们好啊,我是博主鸽芷咕《C干货基地》是由我的襄阳家乡零食基地有感而发,不知道各位的…...

做一个简单的倒计时
<div>距离过年还有:<span></span></div><script>let div document.querySelector("div");let span document.querySelector("span");// 获取未来时间戳let future new Date("2024-2-10 00:00:00");// 获取当下…...
微服务环境搭建:docker+nacos单机
nacos需要连接mysql,持久化相关配置。 1. 部署好mysql后,新建nacos数据库然后初始化nacos脚本 -- -------------------------------------------------------- -- 主机: 192.168.150.101 -- 服务器版本: …...

Opencv轮廓检测运用与理解
目录 引入 基本理解 加深理解 ①比如我们可以获取我们的第一个轮廓,只展示第一个轮廓 ②我们还可以用一个矩形把我们的轮廓给框出来 ③计算轮廓的周长和面积 引入 顾名思义,就是把我们图片的轮廓全部都描边出来 也就是我们在日常生活中面部识别的时候会有一个框,那玩意就…...
)
Java 8的新特性简单分享(后续有系列篇~敬请期待)
Java 8的新特性分享 Java 8是Java语言迎来的一次革命性的更新,引入了众多强大的新特性,使得Java开发变得更加现代化和便捷。在这篇博客中,我们将深入探讨Java 8的一些主要特性,并通过丰富的案例演示展示它们的用法。 1. Lambda表…...
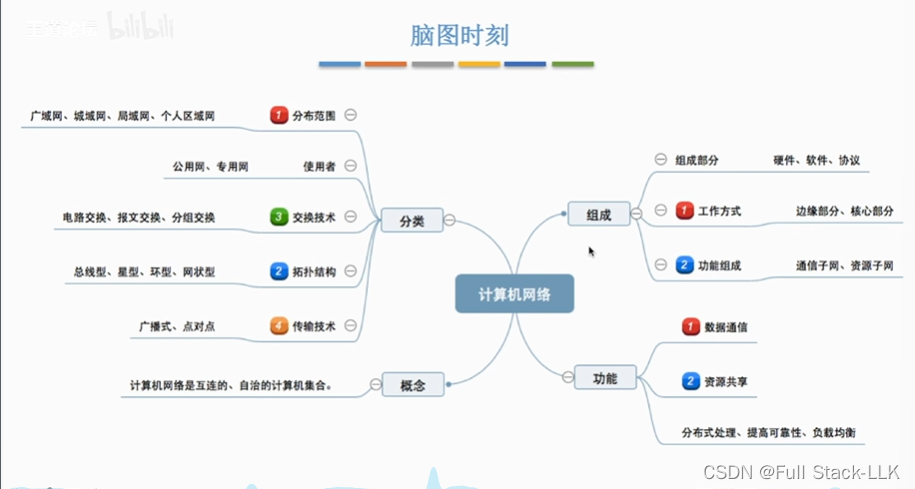
计算机网络-计算机网络的概念 功能 发展阶段 组成 分类
文章目录 计算机网络的概念 功能 发展阶段总览计算机网络的概念计算机网络的功能计算机网络的发展计算机网络的发展-第一阶段计算机网络的发展-第二阶段-第三阶段计算机网络的发展-第三阶段-多层次ISP结构 小结 计算机网络的组成与分类计算机网络的组成计算机网络的分类小结 计…...
】分月饼(动态规划-JavaPythonC++JS实现))
246.【2023年华为OD机试真题(C卷)】分月饼(动态规划-JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-分月饼二.解题思路三.题解代码Python题解代码J…...

EPUBCheck测试框架深度解析:单元测试和集成测试最佳实践
EPUBCheck测试框架深度解析:单元测试和集成测试最佳实践 【免费下载链接】epubcheck The conformance checker for EPUB publications 项目地址: https://gitcode.com/gh_mirrors/ep/epubcheck EPUBCheck作为EPUB出版物的官方一致性检查工具,其强…...

【免费下载】 MobaXterm 专业版 - 无Session限制免费版
MobaXterm 专业版 - 无Session限制免费版 【下载地址】MobaXterm专业版-无Session限制免费版 MobaXterm 专业版 - 无Session限制免费版欢迎使用MobaXterm专业版特别资源 项目地址: https://gitcode.com/open-source-toolkit/9ce1a 欢迎使用MobaXterm专业版特别资源。此版…...

PL2303老芯片终极解决方案:3步让Windows 10/11识别你的停产串口设备
PL2303老芯片终极解决方案:3步让Windows 10/11识别你的停产串口设备 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否在Windows 10或Windows 11系统上…...

告别论文 “双杀” 困局:okbiye 如何用一套闭环方案,破解重复率与 AIGC 检测双重难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 当你对着导师的红笔批注,第三次修改论文时,有没有想过一个问题:为什么你改了又改的句子,重…...
)
解密冰蝎和蚁剑:在CTF流量分析中如何识别和还原WebShell攻击(含AES/Base64解密实操)
解密冰蝎与蚁剑:CTF流量分析中的WebShell识别与解密实战 在CTF竞赛和安全分析领域,WebShell流量分析一直是让许多选手头疼的高阶挑战。特别是当面对冰蝎(Behinder)、蚁剑(AntSword)这类采用强加密通信的Web…...

OpenHarmony与嵌入式Linux实战:从社区项目到深度开发指南
1. 项目概述:从社区精选到深度解析每周浏览技术社区,总能看到不少让人眼前一亮的项目分享,但信息往往比较零散,像是“嵌入式学习资料包”、“OpenHarmony挑战赛作品赏析”这类帖子,标题很吸引人,点进去却常…...

别只盯着SQL注入了!聊聊SRC挖掘中那些被忽视的‘低垂果实’:XSS与弱口令实战复盘
别只盯着SQL注入了!聊聊SRC挖掘中那些被忽视的‘低垂果实’:XSS与弱口令实战复盘 在安全圈摸爬滚打几年后,我发现一个有趣的现象:80%的新手挖洞者会像发现新大陆一样扑向SQL注入,却对触手可得的XSS和弱口令视而不见。这…...

从EfficientNetV1到V2:我是如何用PyTorch复现Fused-MBConv模块并验证其速度优势的
从EfficientNetV1到V2:我是如何用PyTorch复现Fused-MBConv模块并验证其速度优势的 去年在优化移动端图像分类模型时,我偶然发现EfficientNetV2论文中提到的Fused-MBConv模块在浅层网络中的推理速度比传统MBConv快30%以上。这个数字让我既兴奋又怀疑——毕…...
不加真不行)
别再踩坑了!Vue2项目里用Swiper5.4.5做轮播,这几个配置项(observer/observeParents)不加真不行
Vue2项目中Swiper5.4.5轮播图动态适配避坑指南 轮播图作为现代Web应用中最常见的交互组件之一,几乎成为每个前端项目的标配。在Vue2生态中,Swiper凭借其丰富的功能和灵活的配置,成为开发者实现轮播效果的首选库。然而,许多初中级开…...

Ultimate ASI Loader 专业指南:深入解析游戏MOD加载器的完整配置与开发
Ultimate ASI Loader 专业指南:深入解析游戏MOD加载器的完整配置与开发 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/U…...