python 正则表达式学习(1)
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
1. 特殊符号
1.1 符号含义
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式(任意个) |
| re+ | 匹配1个或多个的表达式(至少一个) |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re{ n} | 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 “Bob” 中的 “o”,但是能匹配 “food” 中的两个 o。 |
| re{ n,} | 匹配至少n个前面表达式 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a | b |
| (re) | 对正则表达式分组并记住匹配的文本 |
(.*?) | 表示匹配任意个字符(除了换行符),? 表示尽可能少地匹配, 即使用非贪婪匹配 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域 |
| (?: re) | 类似 (…), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#…) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [ \t\n\r\f] |
| \S | 匹配非字母数字及下划线 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1…\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
模式字符串使用特殊的语法来表示一个正则表达式:
多数字母和数字前加一个反斜杠时会拥有不同的含义。- 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义
- 反斜杠本身需要使用反斜杠转义
- 由于正则表达式通常都包含
反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如r'\t',等价于'\\t')匹配相应的特殊字符
1.2 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:

1.3 简单实例
(1) 字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 “Python” 或 “python” |
| rub[ye] | 匹配 “ruby” 或 “rube” |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
2. 正则表达式函数
re模块使 Python 语言拥有全部的正则表达式功能。compile函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
2.1 re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
2.1.1 函数语法
re.match(pattern, string, flags=0)
- 函数参数说明:

我们可以使用group(num)或groups()匹配对象函数来获取匹配表达式。

2.1.2 实例
实例1
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
运行结果
(0, 3)
None
实例2
import reline = "Cats are smarter than dogs"matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)if matchObj:print ("matchObj.group() : ", matchObj.group())print ("matchObj.group(1) : ", matchObj.group(1))print ("matchObj.group(2) : ", matchObj.group(2))
else:print ("No match!!")
运行结果
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter解析:
- 首先,这是一个字符串,前面的一个 r 表示字符串为非转义的原始字符串,让编译器忽略反斜杠,也就是忽略转义字符。但是这个字符串里没有反斜杠,所以这个 r 可有可无。
- (.) 第一个匹配分组,. 代表匹配除换行符之外的所有字符。
- (.?) 第二个匹配分组,.? 后面多个问号,代表非贪婪模式,也就是说只匹配符合条件的最少字符
后面的一个 .* 没有括号包围,所以不是分组,匹配效果和第一个一样,但是不计入匹配结果中。- matchObj.group() 等同于 matchObj.group(0),表示匹配到的完整文本字符
matchObj.group(1) 得到第一组匹配结果,也就是(.)匹配到的
matchObj.group(2) 得到第二组匹配结果,也就是(.?)匹配到的
因为只有匹配结果中只有两组,所以如果填 3 时会报错。
案例3
‘(?P…)’ 分组匹配
例:身份证 1102231990xxxxxxxx
import re
s = '1102231990xxxxxxxx'
res = re.search('(?P<province>\d{3})(?P<city>\d{3})(?P<born_year>\d{4})',s)
print(res.groupdict())
此分组取出结果为:
{'province': '110', 'city': '223', 'born_year': '1990'}
接将匹配结果直接转为字典模式,方便使用
2.2 re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
- 通过
?P<key>, 指定匹配value的键
2.1 函数语法
re.search(pattern, string, flags=0)
函数参数说明:

- 匹配成功re.search方法返回一个匹配的对象,否则返回None
- 我们可以使用
group(num)或groups()匹配对象函数来获取匹配表达式

2.2 实例
案例1
import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
输出结果为:
(0, 3)
(11, 14)
实例2
import reline = "Cats are smarter than dogs";searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)if searchObj:print ("searchObj.group() : ", searchObj.group())print ("searchObj.group(1) : ", searchObj.group(1))print ("searchObj.group(2) : ", searchObj.group(2))
else:print ("Nothing found!!")
以上实例执行结果如下:
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
searchObj.group(2) : smarterre.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
实例
import reline = "Cats are smarter than dogs";matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:print ("match --> matchObj.group() : ", matchObj.group())
else:print ("No match!!")matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:print ("search --> searchObj.group() : ", matchObj.group())
else:print ("No match!!")
结果如下:
No match!!
search --> searchObj.group() : dogs
2.3 re.sub方法
Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
2.3.1 语法
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
repl: 替换的字符串,也可为一个函数。- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
2.3.2 实例
实例1
import rephone = "2004-959-559 # 这是一个国外电话号码"# 删除字符串中的 Python注释
num = re.sub(r'#.*$', "", phone)
print "电话号码是: ", num# 删除非数字(-)的字符串
num = re.sub(r'\D', "", phone)
print "电话号码是 : ", num
运行结果如下:
电话号码是: 2004-959-559
电话号码是 : 2004959559
实例2
repl 参数是一个函数
以下实例中将字符串中的匹配的数字乘以 2
import re# 将匹配的数字乘以 2
def double(matched):value = int(matched.group('value'))return str(value * 2)s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
输出结果为:
A46G8HFD1134
2.4 re.compile 函数
compile 用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
2.4.1 语法
re.compile(pattern[, flags])
参数:
-
pattern : 一个字符串形式的正则表达式
-
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I忽略大小写- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
2.4.2 案例
案例1
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个 Match 对象,其中:
(1)group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
(2) start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
(3) end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
-
span([group])方法返回(start(group), end(group))。 -
案例2
>>>import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print m # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):File "<stdin>", line 1, in <module>
IndexError: no such group
2.5 findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
2.5.1 语法
findall(string[, pos[, endpos]])
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度
2.5.2 案例
案例1
import repattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)print(result1)
print(result2)
输出结果:
['123', '456']
['88', '12']
案例2
import reresult = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result)
输出结果
[('width', '20'), ('height', '10')]
2.6 re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回
2.6.1 语法
re.finditer(pattern, string, flags=0)
2.6.2 案例
import reit = re.finditer(r"\d+","12a32bc43jf3")
for match in it: print (match.group() )
输出:
12
32
43
3
2.7 re.split
2.7.1 语法
re.split(pattern, string[, maxsplit=0, flags=0])

2.7.2 案例
>>>import re
>>> re.split('\W+', 'runoob, runoob, runoob.')
['runoob', 'runoob', 'runoob', '']
>>> re.split('(\W+)', ' runoob, runoob, runoob.')
['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
>>> re.split('\W+', ' runoob, runoob, runoob.', 1)
['', 'runoob, runoob, runoob.']>>> re.split('a*', 'hello world') # 对于一个找不到匹配的字符串而言,split 不会对其作出分割
['hello world']
3. 项目案例
案例1
def clean_str(s):"""Cleans a string by replacing special characters with underscore _Args:s (str): a string needing special characters replacedReturns:(str): a string with special characters replaced by an underscore _"""return re.sub(pattern="[|@#!¡·$€%&()=?¿^*;:,¨´><+]", repl="_", string=s)
-
将字符串
s中的出现在[|@#!¡·$€%&()=?¿^*;:,¨´><+]中的字符,替换为_符号 -
案例2
def check_yolov5u_filename(file: str, verbose: bool = True):"""Replace legacy YOLOv5 filenames with updated YOLOv5u filenames."""if "yolov3" in file or "yolov5" in file:if "u.yaml" in file:file = file.replace("u.yaml", ".yaml") # i.e. yolov5nu.yaml -> yolov5n.yamlelif ".pt" in file and "u" not in file:original_file = filefile = re.sub(r"(.*yolov5([nsmlx]))\.pt", "\\1u.pt", file) # i.e. yolov5n.pt -> yolov5nu.ptfile = re.sub(r"(.*yolov5([nsmlx])6)\.pt", "\\1u.pt", file) # i.e. yolov5n6.pt -> yolov5n6u.ptfile = re.sub(r"(.*yolov3(|-tiny|-spp))\.pt", "\\1u.pt", file) # i.e. yolov3-spp.pt -> yolov3-sppu.ptif file != original_file and verbose:LOGGER.info(f"PRO TIP 💡 Replace 'model={original_file}' with new 'model={file}'.\nYOLOv5 'u' models are "f"trained with https://github.com/ultralytics/ultralytics and feature improved performance vs "f"standard YOLOv5 models trained with https://github.com/ultralytics/yolov5.\n")return file
参考
https://www.runoob.com/python/python-reg-expressions.html
相关文章:
python 正则表达式学习(1)
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 1. 特殊符号 1.1 符号含义 模式描述^匹配字符串的开头$匹配字符串的末尾.匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包…...

安全防御-基础认知
目录 安全风险能见度不足: 常见的网络安全术语 : 常见安全风险 网络的基本攻击模式: 病毒分类: 病毒的特征: 常见病毒: 信息安全的五要素: 信息安全的五要素案例 网络空间:…...

各省税收收入、个人和企业所得税数据,Shp、excel格式,2000-2021年
基本信息. 数据名称: 各省税收收入、个人和企业所得税数据 数据格式: Shp、excel 数据时间: 2000-2021年 数据几何类型: 面 数据坐标系: WGS84 数据来源:网络公开数据 数据字段: 序号字段名称字段说明1sssr_2021税收收入(亿元&am…...

Vue记录
vue2、vue3记录,参考地址:尚硅谷Vue项目实战硅谷甄选,vue3项目TypeScript前端项目一套通关_哔哩哔哩_bilibili vue2记录 经典vue2结构 index.vue: <template><div>...</div> </template><script>…...

【JavaEE进阶】 Spring Boot⽇志
文章目录 🎋关于日志🚩为什么要学习⽇志🚩⽇志的⽤途🚩日志的简单使用 🎄打印⽇志🚩程序中得到⽇志对象🚩使⽤⽇志对象打印⽇志 🎍⽇志格式的说明🚩⽇志级别的作用&#…...
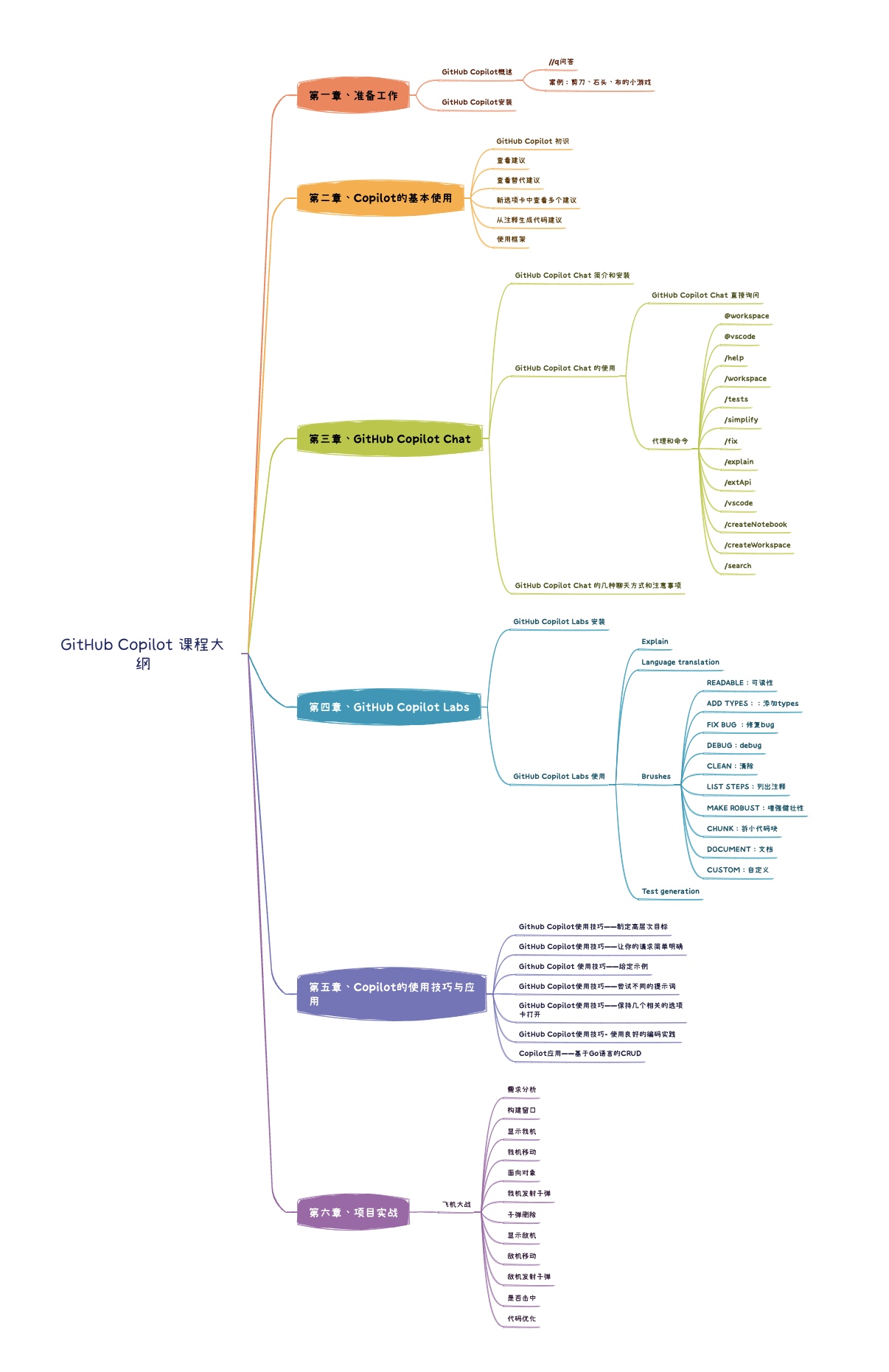
《GitHub Copilot 操作指南》课程介绍
第1节:GitHub Copilot 概述 一、什么是 GitHub Copilot 什么是 GitHub Copilot GitHub Copilot是GitHub与OpenAI合作开发的编程助手工具,利用机器学习模型生成代码建议。它集成在开发者的集成开发环境(IDE)中,可以根…...
)
结构体(C语言)
结构体 1.结构体基础知识: //结构是一些值的集合,这些值称为成员变量. // 结构的每个成员可以是不同类型的变量. 2.结构的定义 struct peo { char name[10];//姓名 char tele[12];//电话 char gender[5];//性别 int high;//身高 }; struct stu { struct…...
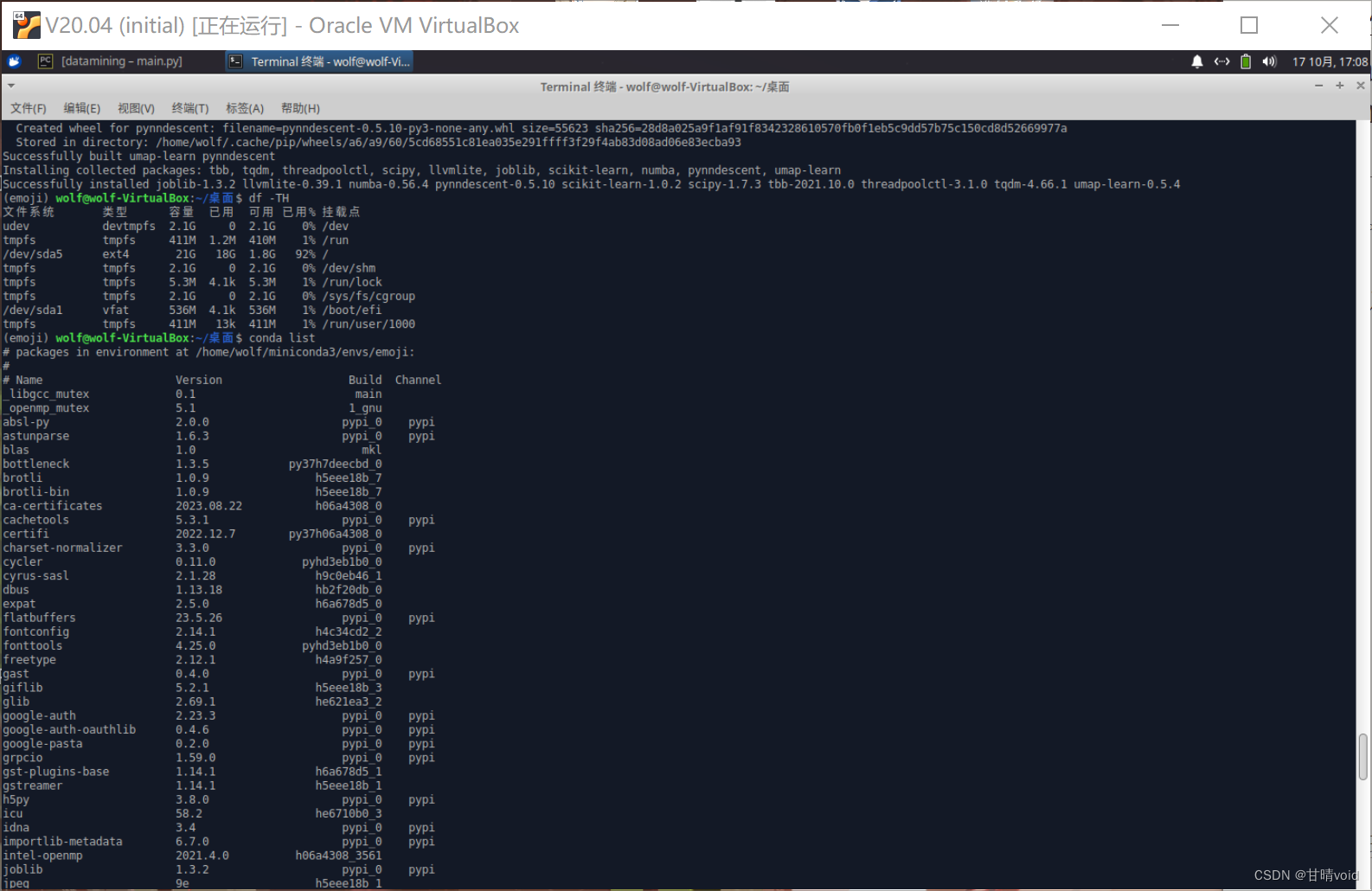
HNU-数据挖掘-实验1-实验平台及环境安装
数据挖掘课程实验实验1 实验平台及环境安装 计科210X 甘晴void 202108010XXX 文章目录 数据挖掘课程实验<br>实验1 实验平台及环境安装实验背景实验目标实验步骤1.安装虚拟机和Linux平台,熟悉Ubuntu环境。2.在Linux平台上搭建Python平台,并安装…...

JavaEE中的监听器的作用和工作原理
在JavaEE(Java Platform, Enterprise Edition)中,监听器(Listener)是一种重要的组件,用于监听和响应Web应用程序中的事件。监听器的作用是在特定的事件发生时执行一些自定义的逻辑。常见的监听器包括Servle…...

Webpack5入门到原理1:前言
为什么需要打包工具? 开发时,我们会使用框架(React、Vue),ES6 模块化语法,Less/Sass 等 css 预处理器等语法进行开发。 这样的代码要想在浏览器运行必须经过编译成浏览器能识别的 JS、Css 等语法…...
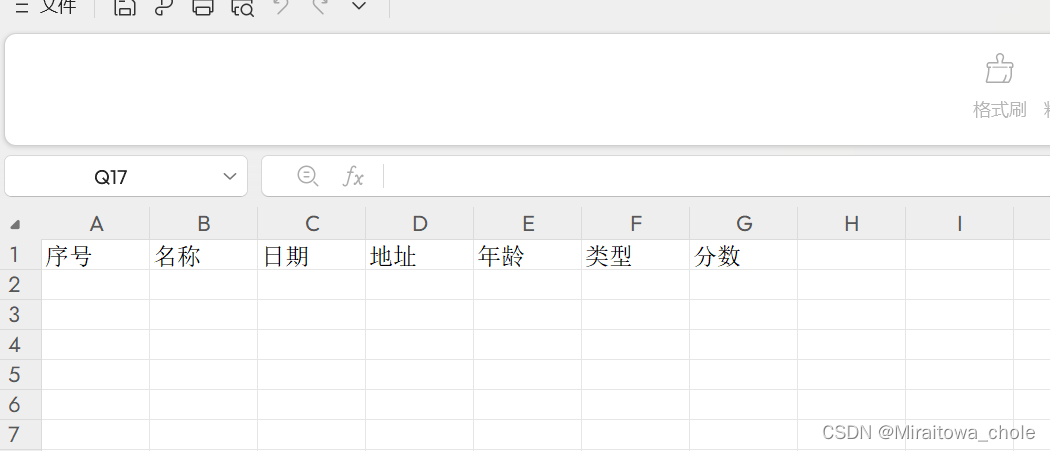
#vue3 实现前端下载excel文件模板功能
一、需求: 前端无需通过后端接口,即可实现模板下载功能。 通过构造一个 JSON 对象,使用前端常用的第三方库 xlsx,可以直接将该 JSON 对象转换成 Excel 文件,让用户下载模板 二、效果: 三、源码如下&…...
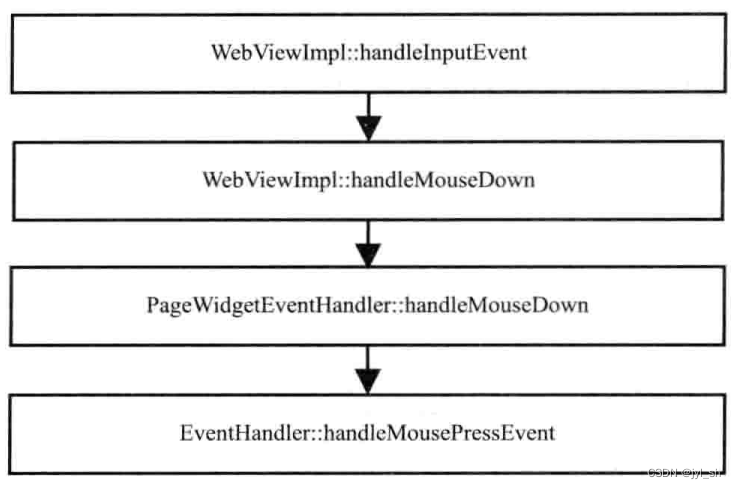
《WebKit 技术内幕》之五(3): HTML解释器和DOM 模型
3 DOM的事件机制 基于 WebKit 的浏览器事件处理过程:首先检测事件发生处的元素有无监听者,如果网页的相关节点注册了事件的监听者则浏览器会将事件派发给 WebKit 内核来处理。另外浏览器可能也需要处理这样的事件(浏览器对于有些事件必须响应…...
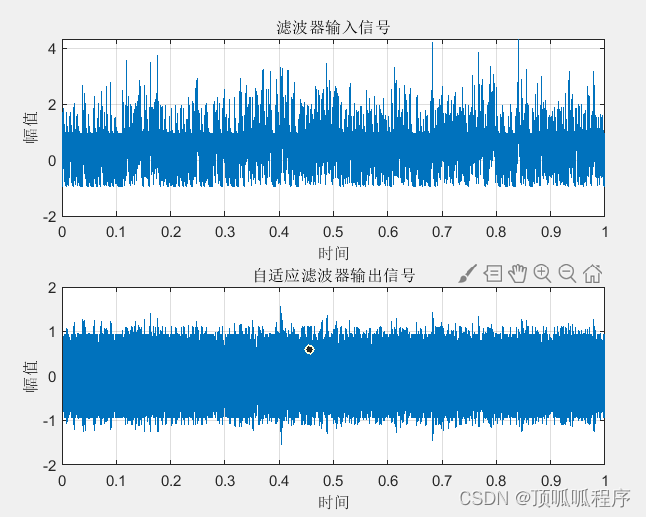
136基于matlab的自适应滤波算法的通信系统中微弱信号检测程序
基于matlab的自适应滤波算法的通信系统中微弱信号检测程序,周期信号加入随机噪声,进行滤波,输出滤波信号,程序已调通,可直接运行。 136 matlab自适应滤波算法LMS (xiaohongshu.com)...
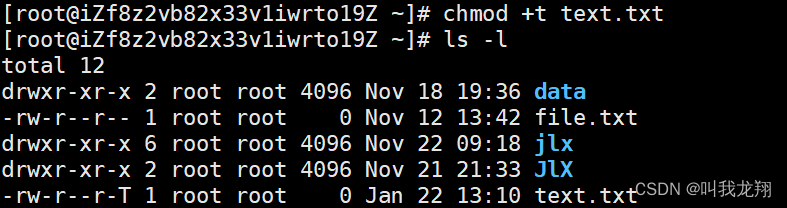
【Linux】权限 !
Linux 权限 Liunx Linux 权限1 什么是权限1.1 Linux用户1.2 切换用户 2 权限管理2.1 文件访问者的分类2.2 文件类型和访问权限2.3 文件权限的设置方法chmod 命令chown 命令chgrp 命令umask 命令file 指令 2.4 目录权限粘滞位 3 权限总结 1 什么是权限 关于Linux的权限问题&…...

axios原理
文章目录 axios基本概念axios多种方式调用工具函数axios的拦截器如何实现?用的设计模式是哪种?axios如何实现取消请求,和cancelToken如何使用 axios基本概念 axios是目前比较流行的一个js库,是一个基于promise的网络数据请求库&am…...

epoll
常用函数 //创建 /** * param size 告诉内核监听的数目 * * returns 返回一个epoll句柄(即一个文件描述符) */ int epoll_create(int size);//控制 /** * param epfd 用epoll_create所创建的epoll句柄 * param op 表示对epoll监控描述符控制的动作 * * …...

AEB滤镜再破碎,安全焦虑「解不开」?
不久前,理想L7重大交通事故,再次引发了公众对AEB的热议。 根据理想汽车公布的事故视频显示,碰撞发生前3秒,车速在178km/h时驾驶员采取了制动措施,但车速大幅超出AEB(自动紧急刹车系统)的工作范…...

深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度?
深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度? 目录 深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度?引言1 数据预处理2 数据集增强3 特征选择4 模型选择5 模型正则化与泛化6 优化器7 学习率8 超…...

无限商机、拓全国、赢未来!2024上海国际轴承展重磅来袭!
中国设备管理协会主办的“2024上海国际轴承及其专用装备展览会”将于2024年7月24日至26日在“国家会展中心(虹桥)”举办。展会预计展出面积55000平方米,汇聚来自世界各地的近1000家企业与60000多人次的国内外观众齐聚一堂。为期三天的展览会是…...

PPT 编辑模式滚动页面不居中
PPT 编辑模式滚动页面不居中 目标:编辑模式下适应窗口大小、切换页面居中显示 调整视图大小,编辑模式通过Ctrl 鼠标滚轮 或 在视图菜单中点击适应窗口大小。 2. 翻页异常,调整视图大小后,PPT翻页但内容不居中或滚动,…...

昇思大模型垂域模型
昇思 MindSpore 垂域模型是基于通用大模型基座 行业数据微调 领域技术增强构建的行业专用 AI 模型,依托 MindSpore Transformers 套件与昇腾硬件,在医疗、金融、电力、法律、工业等领域实现深度落地,兼顾通用能力与行业专业性,训…...

别再傻傻串联了!聊聊数字电路里移位器的三种实现:从简单开关到桶形和对数结构
数字电路设计中的移位器架构选择:从基础实现到性能优化 在数字电路设计中,移位操作是最基础却又最容易被低估的功能之一。许多刚入行的工程师往往会采用最简单的串联移位结构,直到项目遇到性能瓶颈才开始思考优化方案。实际上,移…...

好想来万店扩张背后的数据新底座
在中国量贩零食行业的版图上,好想来正以雷霆之势重塑市场格局。作为万辰集团旗下的头部品牌,好想来已在全国布局超过 1.5 万家门店,注册会员超过 1.5 亿,年营收突破 365 亿元,成为名副其实的零售巨擘。这些令人瞩目的数…...

初探Taotoken模型广场如何帮助开发者快速选型与切换模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初探Taotoken模型广场如何帮助开发者快速选型与切换模型 当开发者开始一个新的大模型应用项目时,面对市场上众多的模型…...

Ardupilot无人船新手必看:从遥控器开关到地面站,3档模式设置保姆级教程
Ardupilot无人船控制模式全解析:从基础配置到高阶应用实战 第一次接触Ardupilot无人船时,最让人困惑的莫过于各种控制模式的区别与适用场景。作为开源自动驾驶系统的标杆,Ardupilot为无人船提供了多达14种控制模式,每种模式都有其…...

如何在Inkscape中快速实现专业级光线追踪?终极免费光学设计指南
如何在Inkscape中快速实现专业级光线追踪?终极免费光学设计指南 【免费下载链接】inkscape-raytracing An extension for Inkscape that makes it easier to draw optical diagrams. 项目地址: https://gitcode.com/gh_mirrors/in/inkscape-raytracing Inks…...

机器学习_03_线性回归
线性回归一、概念与定位类型:监督学习、回归任务定义:用于建模【特征 X】与【连续标签 y】之间的【线性关系】核心思想:找一条直线(或超平面),让预测值 ŷ 与真实值 y 的【误差最小】二、模型形式一元线性回…...

惠普战66内存硬盘升级全攻略:从选条到安装,手把手教你避开新手常踩的坑
惠普战66内存硬盘升级全攻略:从选条到安装,手把手教你避开新手常踩的坑 当你发现电脑运行速度变慢,多开几个网页就开始卡顿,或是存储空间频频告急时,升级内存和硬盘可能是最具性价比的解决方案。作为惠普战66系列的用户…...

手把手教你用SWM34SRET6驱动4.3寸TFT屏:从LVGL图片加载到SDRAM缓存的完整流程
手把手教你用SWM34SRET6驱动4.3寸TFT屏:从LVGL图片加载到SDRAM缓存的完整流程 在嵌入式开发中,实现高性能的图形界面显示往往需要处理复杂的硬件资源分配和软件架构设计。SWM34SRET6作为一款内置8MB SDRAM的Cortex-M33微控制器,为TFT-LCD驱动…...

从机翼到飞行:空气动力学核心概念与应用解析
1. 翼型:飞机飞行的秘密藏在形状里 第一次看到飞机机翼横截面时,我盯着那个水滴状的形状看了足足十分钟。这个被称为翼型的二维轮廓,藏着人类百年航空史最精妙的设计智慧。就像鱼类的流线型身体决定了游泳效率,翼型的每个曲线转折…...