深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度?
深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度?

目录
- 深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度?
- 引言
- 1 数据预处理
- 2 数据集增强
- 3 特征选择
- 4 模型选择
- 5 模型正则化与泛化
- 6 优化器
- 7 学习率
- 8 超参数调优
- 9 性能评估与模型解释
引言
在非时间序列的回归任务中,深度学习和机器学习都是常用的方法。为了进一步提升模型的性能,可以通过改进数据处理、数据增强、特征选择、模型选择、模型正则化与泛化、优化器、学习率、超参数调优等方面,来提升模型的性能和可解释性。
1 数据预处理
提高数据质量和进行恰当的数据预处理对提升模型性能至关重要。
- 异常值处理:检测和处理异常值,防止对模型造成影响。
- 数据清洗:纠正在数据中的不一致性和错误。
- 处理不平衡数据:重采样策略,如SMOTE或随机过/欠采样。
- 缺失值处理:填补缺失值或使用模型处理缺失数据。
- 数据规范化:归一化或标准化数据。
- 数据离散化:对连续变量进行分桶操作。
- 特征编码:对类别型特征使用独热编码或标签编码。
- 多尺度特征:创建不同尺度的特征表示形式。
- 特征构造:创建新特征来增强现有数据集。
- 特征交互:考虑特征之间的交互作用。
2 数据集增强
通过生成合成数据或变形现有数据来拓展数据集,使模型能够从更多样的情况中学习。
- 数据扩张:人工生成新样本(基于已知样本特征的数据生成技术)。
- 过采样:复制少数类样本。
- 欠采样:减少多数类样本。
- 加权重采样:依据类的不平衡程度加权样本。
- 生成对抗网络(GAN):生成新的数据点增强数据集。
- 模拟数据生成:使用已知分布生成新数据点。
- 多样本合成:融合现有数据点生成新样本。
- 自动数据增强:使用算法来自动找到最优的数据增强方式。
- 交叉验证数据扩增:在交叉验证的每个循环中使用不同的数据增强。
- 引入外部数据集:结合其他资源扩展数据集。
3 特征选择
- 相关性分析:采用皮尔逊相关系数、斯皮尔曼等级相关系数等方法筛选与目标变量相关性高的特征。
- 主成分分析(PCA):减少维度,保留最有信息的特征分量。
- 特征重要性评分:基于树模型(如随机森林、XGBoost)评估特征重要性。
- 递归特征消除(RFE):递归减少特征集规模,找到最有影响的特征。
- 基于模型的选择:使用L1正则化(Lasso)自动进行特征选择。
- 群体方法(Ensemble methods):结合多种特征选择方法的结果。
- 互信息和最大信息系数(MIC):选取与目标变量互信息大的特征。
- 使用过滤方法:例如方差分析(ANOVA),通过统计测试进行特征选择。
- 时间序列特征工程:从日期中提取信息,如月份、星期等。
- 地理空间特征:如果数据包含地理信息,可以提取地理空间特征,如人口密度、流动性模式等。
4 模型选择
- 线性模型:逻辑回归、岭回归等,作为基线模型。
- 决策树:CART、ID3、C4.5作为非线性基准模型。
- 集成方法:随机森林、梯度提升机(GBM)、XGBoost、LightGBM、CatBoost等,提高模型的稳定性和准确性。
- 支持向量机(SVM):尝试不同的核函数。
- 神经网络:深度学习模型,能够捕获复杂非线性关系。
- K-最近邻(KNN):调整邻居数量。
- 朴素贝叶斯:对条件独立性假设下的快速模型。
- 实例学习方法:基于实例的学习可以用于捕捉异常点或进行小样本学习。
- 混合模型或堆叠(Stacking):结合多个不同的模型的预测以提高准确率。
5 模型正则化与泛化
正则化技术可以减少过拟合,提升模型的泛化能力。
- L1/L2正则化:加入惩罚项限制模型复杂度。
- 早停法(Early Stopping):防止训练过度。
- 丢弃法(Dropout):神经网络中随机丢弃节点以增加鲁棒性。
- 集成学习:多模型集成平均预测。
- 交叉验证:更可靠地评估模型表现。
- 堆叠通用化(Stacking Generalization):模型的堆叠组合。
- 引导聚合(Bagging):减少方差,如随机森林。
- 梯度提升:如GBM、XGBoost,增加模型鲁棒性。
- 噪声鲁棒性:对输入添加噪声以提高鲁棒性。
- 模型蒸馏(Knowledge Distillation):从复杂模型到简单模型的知识转移。
6 优化器
pytorch手册:https://pytorch.org/docs/stable/optim.html
- 梯度下降(GD):基础的优化算法。
- 随机梯度下降(SGD):每次更新只使用一个样本,速度快。
- 批量梯度下降(BGD):每次更新使用全部样本,稳定性好。
- 动量(Momentum):加速SGD在相关方向上前进,抑制震荡。
- Adagrad:自适应学习率优化算法。
- RMSprop:解决Adagrad学习率急剧下降问题。
- Adam:结合了RMSprop和Momentum的优点。
- AdaDelta:改进的Adagrad以防止学习率过早下降。
- Nesterov 加速梯度(NAG):提前调整梯度方向以增加速度。
- AdamW:在Adam的基础上加入权重衰减,提高模型泛化能力。
7 学习率
学习率的调整对模型训练效果影响巨大,以下是一些调整学习率的方法:
- 固定学习率:最基本的策略,全程使用固定学习率。
- 按时间衰减:随着迭代次数增加,学习率逐渐减小。
- 步长衰减:每隔一定的epoch,学习率衰减一次。
- 指数衰减:学习率按指数函数衰减。
- 自适应学习率:根据模型在训练集上的表现来动态调整学习率。
- 余弦退火(Cosine Annealing):周期性调整学习率的一种策略。
- 线性预热(Warm-up):先小学习率预热,逐渐增加到正常值。
- 周期性学习率:学习率在较高值和较低值之间周期性变动。
- 学习率范围测试:快速地迭代多个学习率以找到最好的范围。
- 使用学习率查找算法:例如学习率查找器,快速找到适合当前数据集的学习率。
8 超参数调优
通过调整模型超参数来优化模型表现。
- 网格搜索:系统性地遍历多种超参数的组合。
- 随机搜索:在超参数空间中随机搜索。
- 贝叶斯优化:基于贝叶斯模型的优化方法。
- 基于遗传算法的优化:模拟自然选择过程来选择超参数。
- 模拟退火:启发式搜索技术,优化复杂空间中的超参数选择。
- 超参数空间约减:通过预先分析减少搜索空间的范围。
- 自动化机器学习(AutoML):自动化超参数的选择和模型的训练。
- 超参数重要性分析:分析各个超参数对模型表现的影响大小。
- 进化算法:利用进化策略寻找最佳超参数。
- 零成本代理指标:使用低成本指标来预测较高成本指标的表现。
9 性能评估与模型解释
了解模型在哪些方面表现良好或不足,可以进一步改进模型。
- 混淆矩阵分析:查看模型在不同类别的预测性能。
- ROC曲线与AUC:评估模型的区分能力。
- 精度-召回曲线:了解精度与召回率的权衡关系。
- Brier分数:评估概率预测的准确性。
- 查看模型权重:分析特征权重对结果的影响。
- SHAP值:解释模型的预测以关联特征的重要性。
- 部分依赖图(Partial Dependence Plots):可视化特征影响。
- 局部可解释模型的敏感性分析(LIME):解释单个预测结果。
- 累积增益图和提升图:分析营销策略效果。
- 泛化误差分析:分析模型在新数据上的预测性能。
相关文章:
深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度?
深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度? 目录 深度学习和机器学习中针对非时间序列的回归任务,有哪些改进角度?引言1 数据预处理2 数据集增强3 特征选择4 模型选择5 模型正则化与泛化6 优化器7 学习率8 超…...

无限商机、拓全国、赢未来!2024上海国际轴承展重磅来袭!
中国设备管理协会主办的“2024上海国际轴承及其专用装备展览会”将于2024年7月24日至26日在“国家会展中心(虹桥)”举办。展会预计展出面积55000平方米,汇聚来自世界各地的近1000家企业与60000多人次的国内外观众齐聚一堂。为期三天的展览会是…...

PPT 编辑模式滚动页面不居中
PPT 编辑模式滚动页面不居中 目标:编辑模式下适应窗口大小、切换页面居中显示 调整视图大小,编辑模式通过Ctrl 鼠标滚轮 或 在视图菜单中点击适应窗口大小。 2. 翻页异常,调整视图大小后,PPT翻页但内容不居中或滚动,…...

笨蛋学设计模式结构型模式-享元模式【13】
结构型模式-享元模式 7.7享元模式7.7.1概念7.7.2场景7.7.3优势 / 劣势7.7.4享元模式可分为7.7.5享元模式7.7.6实战7.7.6.1题目描述7.7.6.2输入描述7.7.6.3输出描述7.7.6.4代码 8.1.7总结享元模式 7.7享元模式 7.7.1概念 享元模式是通过共享对象减少内存使用,来…...

磁盘的分区与文件系统的认识
磁盘的认识 了解磁盘的结构: 1、盘片 硬盘首先会有多个盘片构成,类似很多个独立的光盘合并在一起,每个盘片都有2个面,每个盘片都有一个对应的磁头,我们的磁头横移和盘面的旋转就可以读写到盘面的每一个位置,…...

韩国访问学者如何申请?
作为访问学者,前往韩国学术机构进行研究是一项令人期待的经历。首先,申请者需要查找目标学术机构的官方网站,下面知识人网小编带大家了解其访问学者计划的具体要求和申请流程。 通常,申请程序包括填写在线申请表格,提交…...
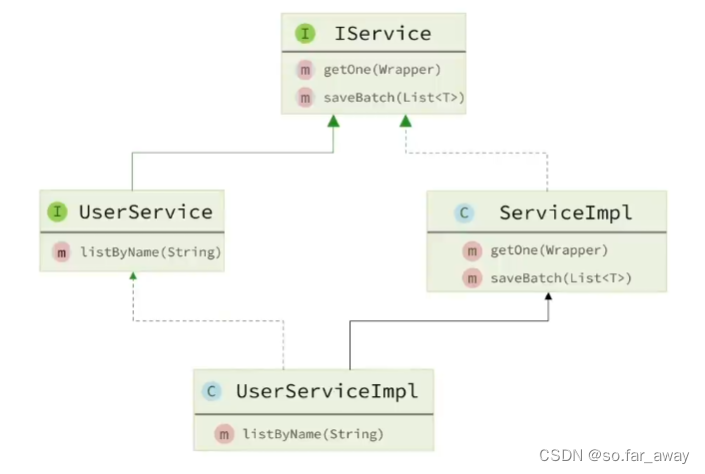
MybatisPlus框架入门级理解
MybatisPlus 快速入门入门案例常见注解常用配置 核心功能条件构造器自定义SQLService接口 快速入门 入门案例 使用MybatisPlus的基本步骤: 1.引入MybatisPlus的起步依赖 MybatisPlus官方提供了starter,其中集成了Mybatis和MybatisPlus的所有功能&#…...
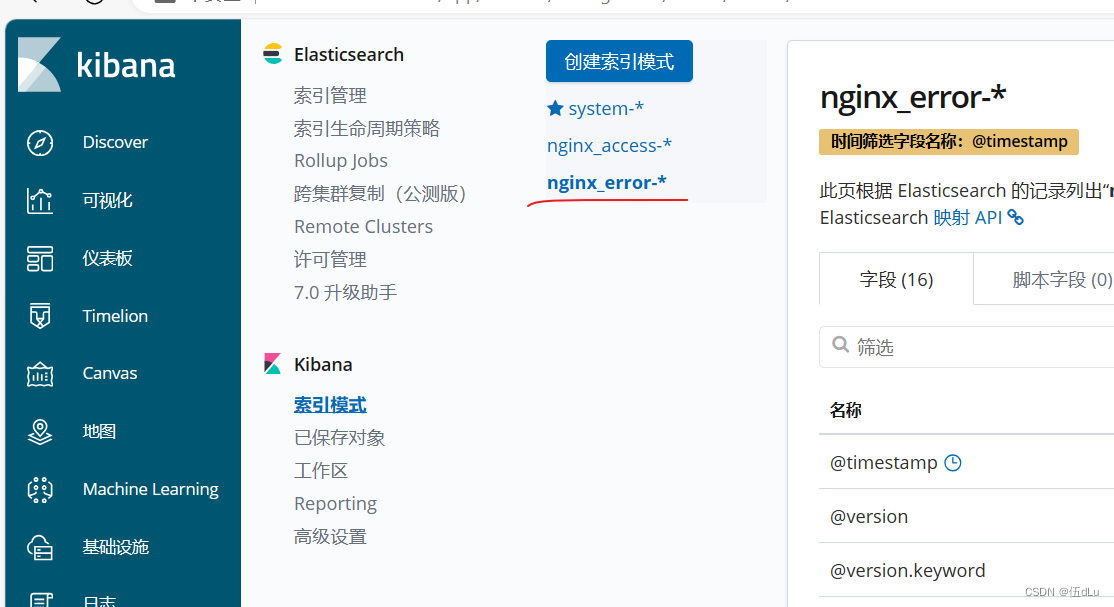
ELK 分离式日志(1)
目录 一.ELK组件 ElasticSearch: Kiabana: Logstash: 可以添加的其它组件: ELK 的工作原理: 二.部署ELK 节点都设置Java环境: 每台都可以部署 Elasticsearch 软件: 修改elasticsearch主配置文件&…...

<蓝桥杯软件赛>零基础备赛20周--第15周--快速幂+素数
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集 20周的完整安排请点击:20周计划 每周发1个博客,共20周。 在QQ群上交流答疑&am…...
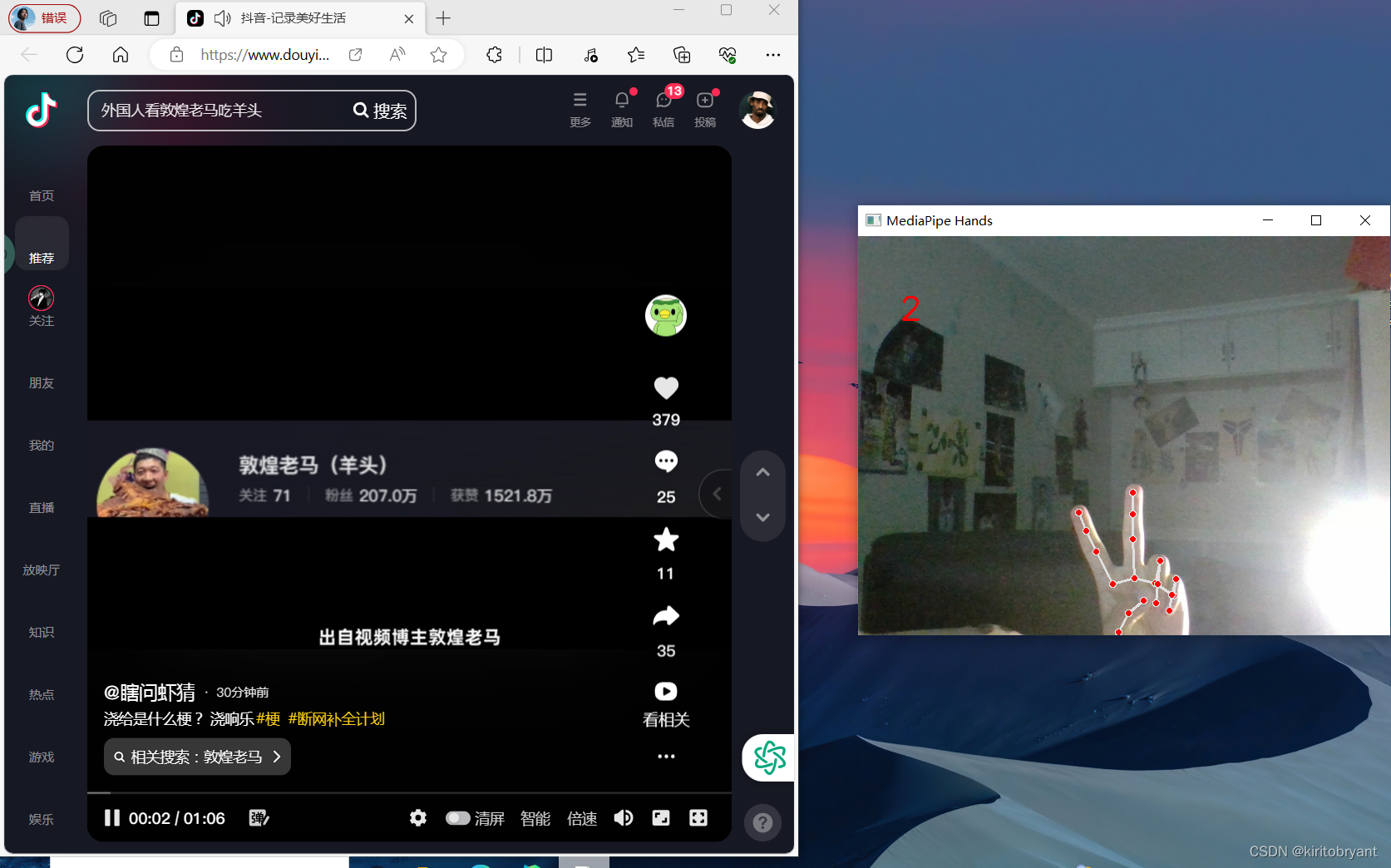
Opencv小项目——手势数字刷TIKTOK
写在前面: 很久没更新了,之前的实习的记录也算是烂尾了,但是好在自己的实习记录还是有的,最近也忙碌了很多,终于放假了,今天下午正好没事,闲来无事就随便做个小玩意吧。 思来想去ÿ…...
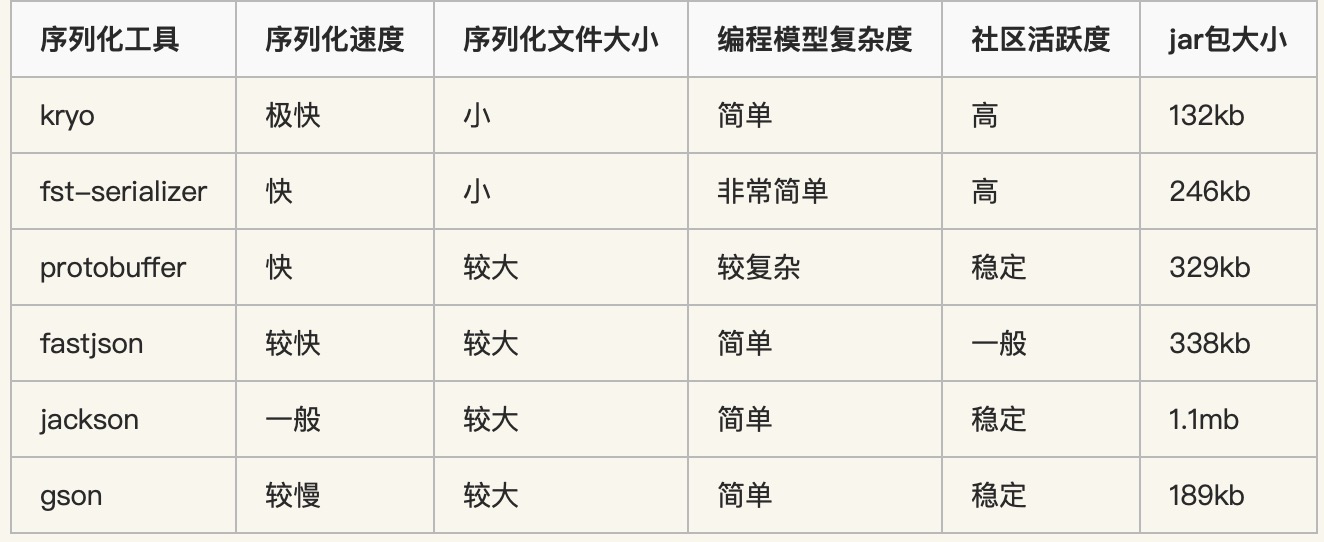
【优化技术专题】「性能优化系列」针对Java对象压缩及序列化技术的探索之路
针对Java对象压缩及序列化技术的探索之路 序列化和反序列化为何需要有序列化呢?Java实现序列化的方式二进制格式 指定语言层级二进制格式 跨语言层级JSON 格式化类JSON格式化:XML文件格式化 序列化的分类在速度的对比上一般有如下规律:Java…...
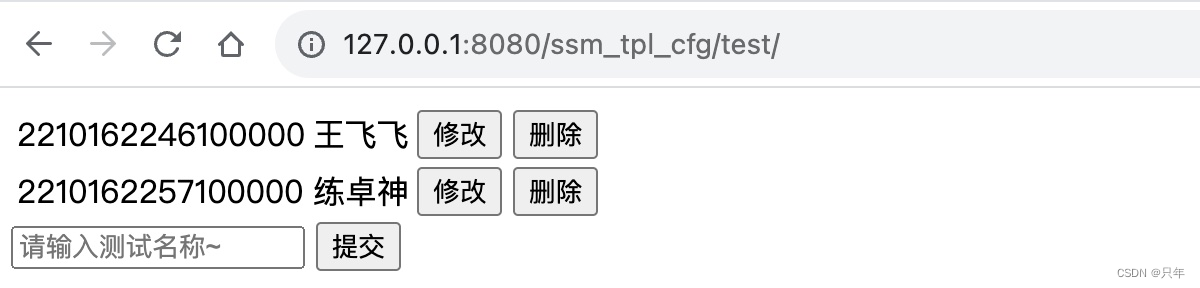
Spring+SprinMVC+MyBatis配置方式简易模板
SpringSprinMVCMyBatis配置方式简易模板代码Demo GitHub访问 ssm-tpl-cfg 一、SQL数据准备 创建数据库test,执行下方SQL创建表ssm-tpl-cfg /*Navicat Premium Data TransferSource Server : 127.0.0.1Source Server Type : MySQLSource Server Versio…...
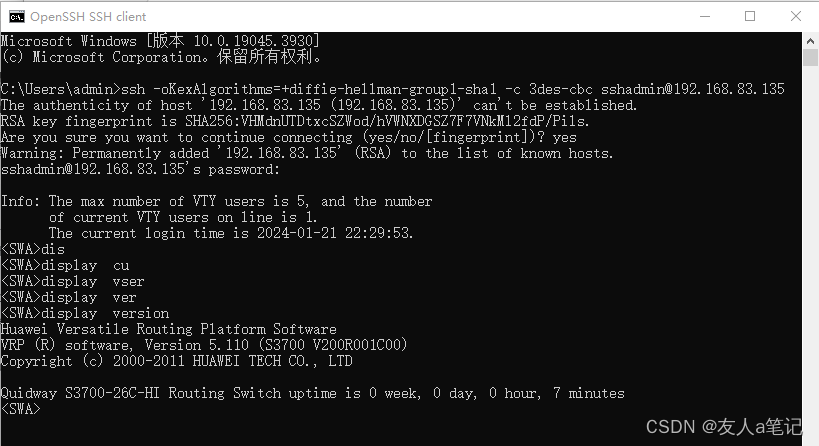
Windows ssh登录eNSP交换机
目录 1. Cloud IO配置1.1 创建UDP端口1.2 创建本地连接1.3 端口映射设置 2. 交换机配置2.1 配置vlanif2.2 配置vty2.3 配置ssh用户2.4 配置aaa2.5 使用Xshell工具登录2.6 用户和密码2.7 登录成功 3. 使用cmd 登录报错提示3.1 手动指定加密算法,提示密码长度无效3.2 …...

SwiftUI 纯手工打造 100% 可定制的导航栏
功能需求 何曾几时,我们是否也厌倦了 SwiftUI 界面中刻板守旧的导航栏外观,而想要自己动手充分展示灵动炸裂的创造力呢? 如上图所示:我们在 SwiftUI 中通过纯手工打造了一款 100 在本篇博文中,您将学到以下内容 功能需求1. 导航栏基本结构2. 如何感知当前发生用户拖拽行为…...

npm install 太慢?解决方法
在使用npm进行包管理时,有时会遇到安装速度缓慢的问题。这可能是由于网络原因或npm官方镜像服务器的繁忙导致的。下面介绍几种常见的解决方法: 使用淘宝镜像 淘宝镜像是一个提供npm包镜像的国内源,其速度较快且稳定。您可以通过以下命令将npm…...

DevOps系列文章之 GitLab CI/CD
CICD是什么? 由于目前公司使用的gitlab,大部分项目使用的CICD是gitlab的CICD,少部分用的是jenkins,使用了gitlab-ci一段时间后感觉还不错,因此总结一下 介绍gitlab的CICD之前,可以先了解CICD是什么 我们的开发模式…...
)
【CompletableFuture任务编排】游戏服务器线程模型及其线程之间的交互(以排行榜线程和玩家线程的交互为例子)
需求: 1.我们希望玩家的业务在玩家线程执行,无需回调,因此是多线程处理。 2.匹配线程负责匹配逻辑,是单独一个线程。 3.排行榜线程负责玩家的上榜等。 4.从排行榜线程获取到排行榜列表后,需要给玩家发奖修改玩家数…...
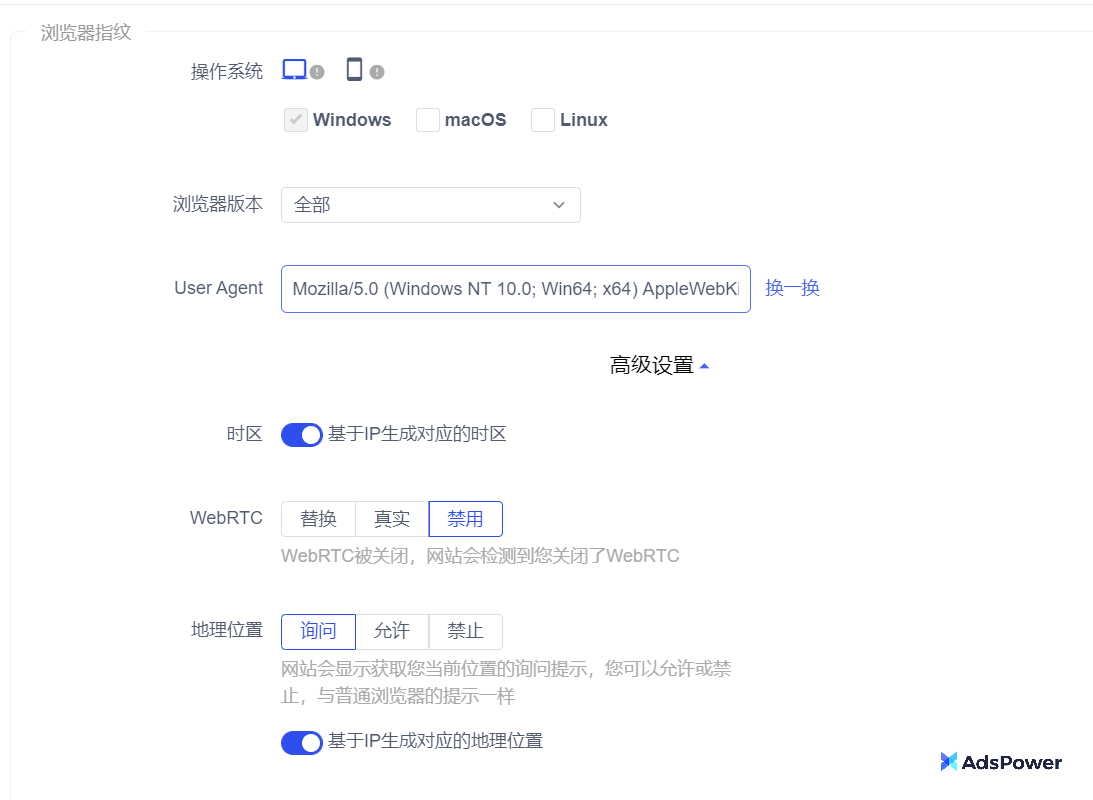
什么是浏览器指纹?详解浏览器指纹识别技术,教你防止浏览器指纹识别
在数字时代,我们的在线活动几乎总是留下痕迹。其中,浏览器指纹就像我们的数字身份证,让网站能够识别和追踪用户。对于跨境电商行业来说,了解这种追踪技术尤其重要,因为它可能影响账号的管理和安全。本文将详细介绍浏览…...

canvas绘制六芒星
查看专栏目录 canvas实例应用100专栏,提供canvas的基础知识,高级动画,相关应用扩展等信息。canvas作为html的一部分,是图像图标地图可视化的一个重要的基础,学好了canvas,在其他的一些应用上将会起到非常重…...

全网最详细!!Python 爬虫快速入门
1. 背景 最近在工作中有需要使用到爬虫的地方,需要根据 Gitlab Python 实现一套定时爬取数据的工具,所以借此机会,针对 Python 爬虫方面的知识进行了学习,也算 Python 爬虫入门了。 需要了解的知识点: Python 基础语…...

深入理解强化学习基础:价值函数、策略梯度与PPO算法核心原理
深入理解强化学习基础:价值函数、策略梯度与PPO算法核心原理 【免费下载链接】LLM-RL-Visualized 🌟100 原创 LLM / RL 原理图📚,《大模型算法》作者巨献!💥(100 LLM/RL Algorithm Maps &#x…...

Obsidian个性化首页终极指南:3种配置方案提升知识管理效率70%
Obsidian个性化首页终极指南:3种配置方案提升知识管理效率70% 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 在信息…...

CircuitJS1:如何在浏览器中免费创建电子电路仿真
CircuitJS1:如何在浏览器中免费创建电子电路仿真 【免费下载链接】circuitjs1 Electronic Circuit Simulator in the Browser 项目地址: https://gitcode.com/gh_mirrors/ci/circuitjs1 CircuitJS1是一款强大的开源电子电路仿真工具,让你直接在浏…...

如何将B站缓存视频永久保存?m4s-converter完整使用指南
如何将B站缓存视频永久保存?m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是不是也遇到过这样的情况&…...

3分钟拯救经典游戏:用DDrawCompat让Windows老游戏在现代系统上重生
3分钟拯救经典游戏:用DDrawCompat让Windows老游戏在现代系统上重生 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirro…...
)
从‘黑盒子’到清晰电路:用替代定理‘破译’未知网络N的VCR(图解+方程双解法)
从‘黑盒子’到清晰电路:用替代定理‘破译’未知网络N的VCR(图解方程双解法) 在电子工程实践中,工程师们常常会遇到一种令人头疼的"黑盒子"——那些内部结构不明、数据手册不全的电路模块。面对这样的未知网络ÿ…...

从配色灾难到视觉盛宴:手把手教你用Matlab Colormap编辑器定制专属散点图配色
从配色灾难到视觉盛宴:手把手教你用Matlab Colormap编辑器定制专属散点图配色 科研图表的美学设计往往被工程师们忽视,直到某天你发现自己的论文配图在学术海报展上显得格格不入。Matlab默认的parula或jet色图虽然经典,但早已无法满足现代数据…...

从Neuralangelo看多分辨率哈希编码:如何用‘数值梯度’和‘渐进优化’搞定高保真3D重建?
Neuralangelo与多分辨率哈希编码:高保真3D重建的技术革命 在数字孪生、虚拟制作和文化遗产保护等领域,对真实世界进行高保真3D重建的需求从未如此迫切。传统摄影测量技术受限于硬件成本和算法瓶颈,难以平衡细节精度与处理效率。而神经渲染技术…...

3步掌握CSDN博客下载器:革命性批量下载与智能离线阅读终极方案
3步掌握CSDN博客下载器:革命性批量下载与智能离线阅读终极方案 【免费下载链接】CSDNBlogDownloader 项目地址: https://gitcode.com/gh_mirrors/cs/CSDNBlogDownloader 在信息时代,技术博客是我们获取知识的重要窗口,但网络内容的不…...

别再手动贴图了!LOD1.3建模的智能纹理库怎么用?手把手教你配置大势智慧材质模板
LOD1.3建模革命:智能纹理库的实战配置指南 当清晨的第一缕阳光透过窗户洒在建模师的工作台上,那些曾经需要数小时手动贴图的建筑模型,如今只需几分钟就能自动完成纹理匹配。这不是未来场景,而是LOD1.3建模中智能纹理库技术带来的…...