全网最详细!!Python 爬虫快速入门
1. 背景
最近在工作中有需要使用到爬虫的地方,需要根据 Gitlab + Python 实现一套定时爬取数据的工具,所以借此机会,针对 Python 爬虫方面的知识进行了学习,也算 Python 爬虫入门了。
需要了解的知识点:
- Python 基础语法
- Python 网络请求,requests 模块的基本使用
- BeautifulSoup 库的使用
- 正则表达式
- Selenium 的基本使用
下面针对上面的每部分做个简单的介绍。
小编给大家整理了全套Python爬虫入门资料,点击下方链接或者扫描二维码直接领取。
最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
 2\. Python 基础语法 ---------------
2\. Python 基础语法 ---------------
学习任何一门编程语言都必须掌握其语法知识,Python 也不例外。如果有其它变成语言基础,上手 Python 还是非常快的。
2.1 变量
在 Python 中,定义一个变量的操作分为两步:首先要为变量起一个名字,称为变量的命名;然后要为变量指定其所代表的数据,称为变量的赋值。这两个步骤在同一行代码中完成。
version = '1'Python 中的变量命名规范与其它开发语言差不多,基本的规则如下:
- 变量名可以由任意数量的字母、数字、下划线组合而成,但是必须以字母或下划线开头,不能以数字开头。
- 不要用 Python 的保留字或内置函数来命名变量。例如,不要用 import 来命名变量,因为它是 Python 的保留字,有特殊的含义。
- 变量名对英文字母区分大小写。例如,D 和 d 是两个不同的变量。
2.2 数据类型
Python 中有 6 种基本数据类型:数字(Numbers)、字符串(String)、列表(List)、字典(Dictionary)、元组(Tuple)和集合。
2.2.1 数据类型
在 Python 中定义变量后需要及时指明对应的数据类型。同时也可以使用 del 变量名 删除对象引用。
num = 0
pi = 3.14
name = "abc"
# 定义列表 [],列表元素可以修改
list = [12, 2, 212, 44, 5, 6]
dic = {"k1": "v1","k2": "v2",
}
# 集合类型用 set 标识, 创建使用 { } 或者 set()
s1 = {1, 2, 3, 3, 2, 2, 2, 1, "1"}
# 元组用 () 表示,元组的元素不能修改
tuple = ( 'runoob', 786 , 2.23, 'john', 70.2 )del s1对于每种数据类型,都有一些常用的方法:
| 数据类型 | 方法 |
|---|---|
| 字符串 | |
| - [ : ]:截取字符串中的一部分(切片),遵循左闭右开原则; | |
| - []:通过索引获取字符串中字符; | |
| - in:如果字符串中包含给定的字符返回 True; | |
| - not in:成员运算符 - 如果字符串中不包含给定的字符返回 True | |
| - capitalize():将字符串的第一个字符转换为大写; | |
| - endswith(suffix, beg=0, end=len(string)):检查字符串是否以指定的字符串结束,如果是,返回 True,否则返回 False; | |
| - find(str, beg=0, end=len(string)):检测 str 是否包含在字符串中,如果包含,返回开始的索引值,否则返回-1; | |
| - index(str, beg=0, end=len(string)):跟find()方法一样,只不过如果str不在字符串中会报一个异常; | |
| - len(string):返回字符串长度; | |
| - replace(old, new [, max]):把将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次; | |
| - rstrip():删除字符串末尾的空格或指定字符; | |
| - split(str=“”, num=string.count(str)):以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串。 | |
| 列表/元组 | |
| - len(list):列表元素个数; | |
| - list(seq):将序列(元组,集合等)转换为列表; | |
| - list.append(obj):在列表末尾添加新的对象; | |
| - list.index(obj):从列表中找出某个值第一个匹配项的索引位置; | |
| - list.remove(obj):移除列表中某个值的第一个匹配项; | |
| - list.clear():清空列表。 | |
| 字典 | |
| - len(dict):计算字典元素个数,即键的总数; | |
| - key in dict:如果键在字典dict里返回true,否则返回false; | |
| - radiansdict.items():以列表返回可遍历的(键, 值) 元组数组; | |
| - radiansdict.keys():以列表返回一个字典所有的键; | |
| - radiansdict.values():以列表返回字典中的所有值。 | |
2.2.2 类型转换
字符串类型转换通过 str() 函数可以将一个变量转换为字符串类型。
- int(x) 将x转换为一个整数。
- float(x) 将x转换到一个浮点数。
- complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
- complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
- str(x) 将对象 x 转换为字符串。
2.3 基础运算符
在 Python 中运算符基本与其它开发语言一致,常用的运算符有算术运算符、字符串运算符、比较运算符、赋值运算符和逻辑运算符。
算术运算符
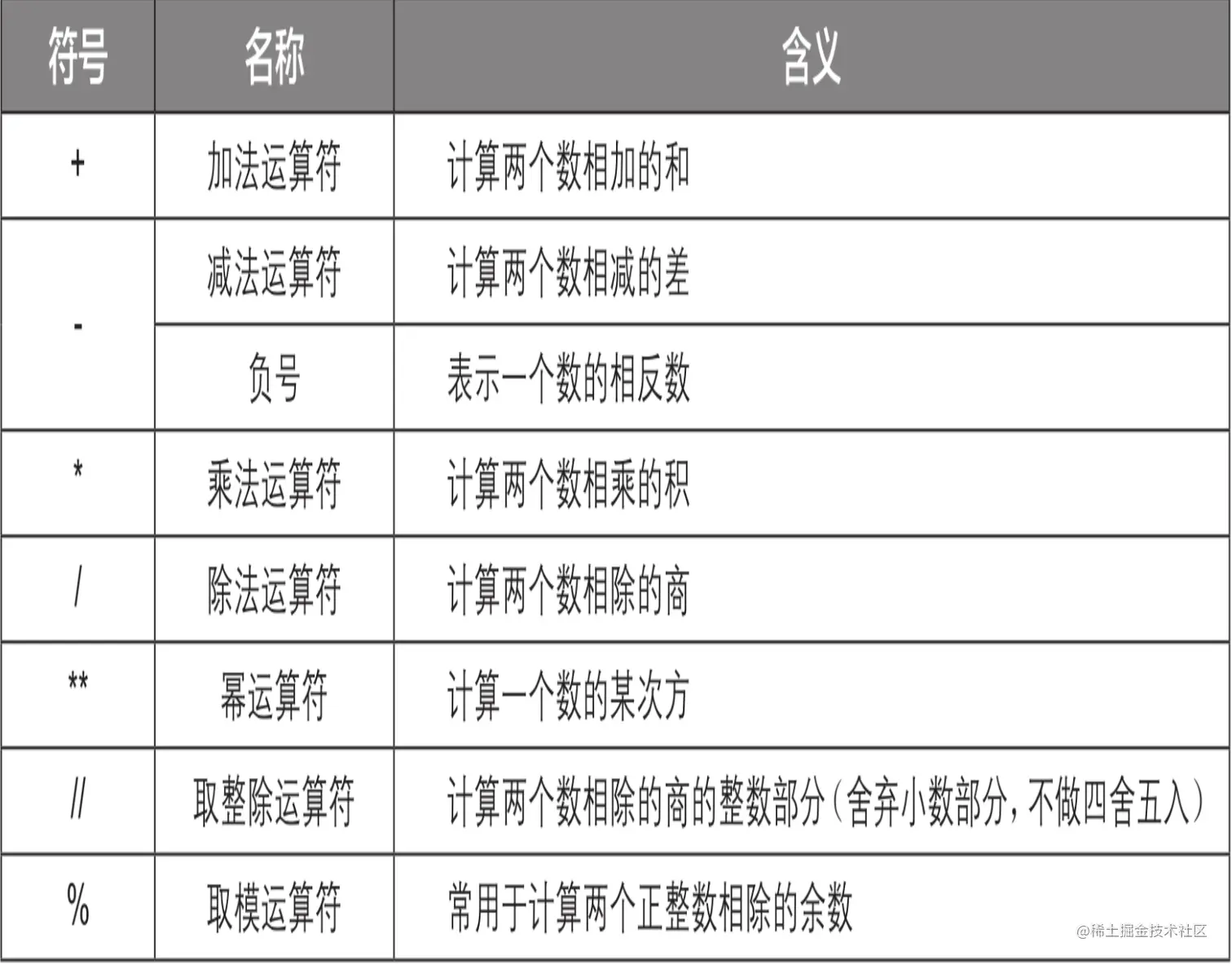
比较运算符
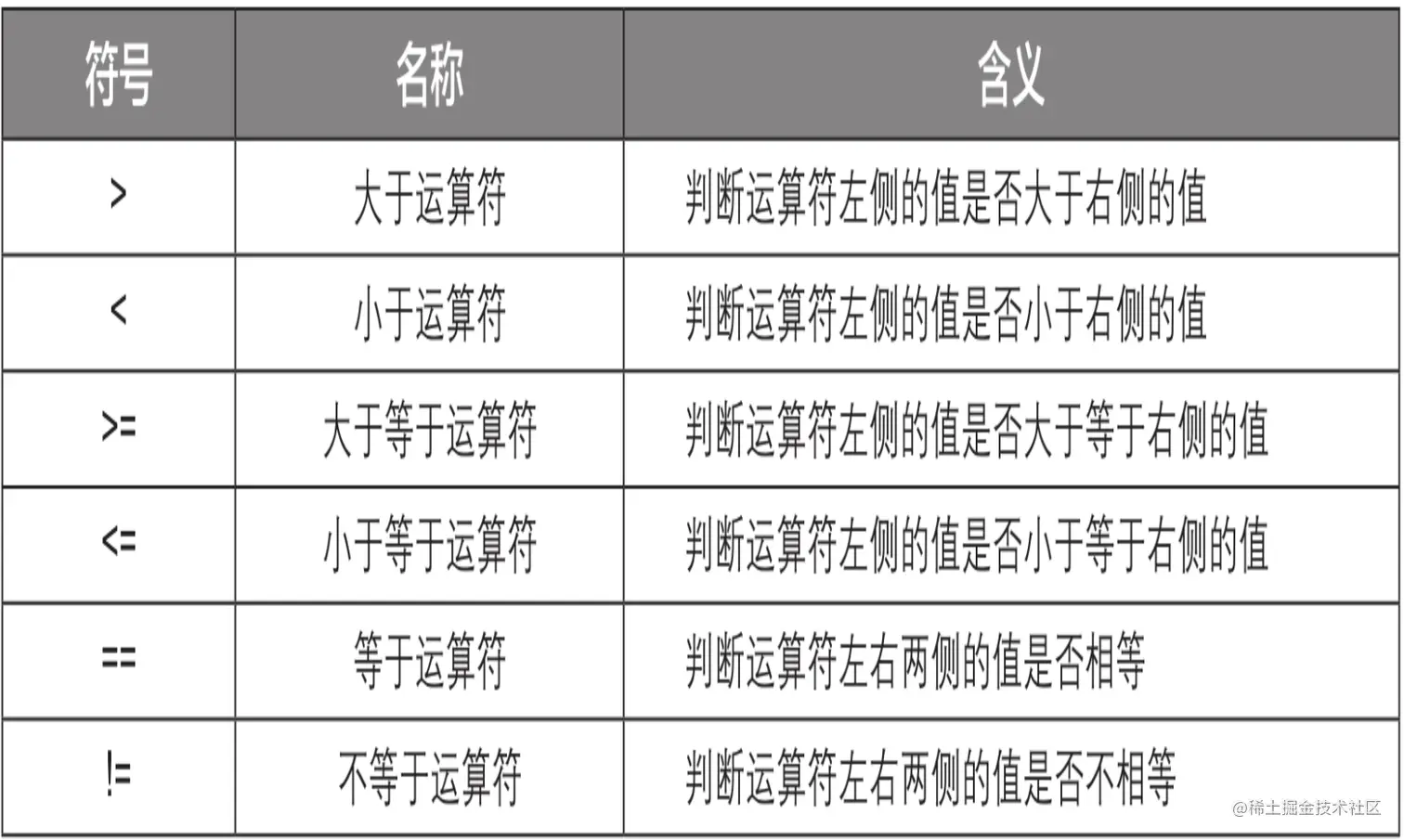
逻辑运算符
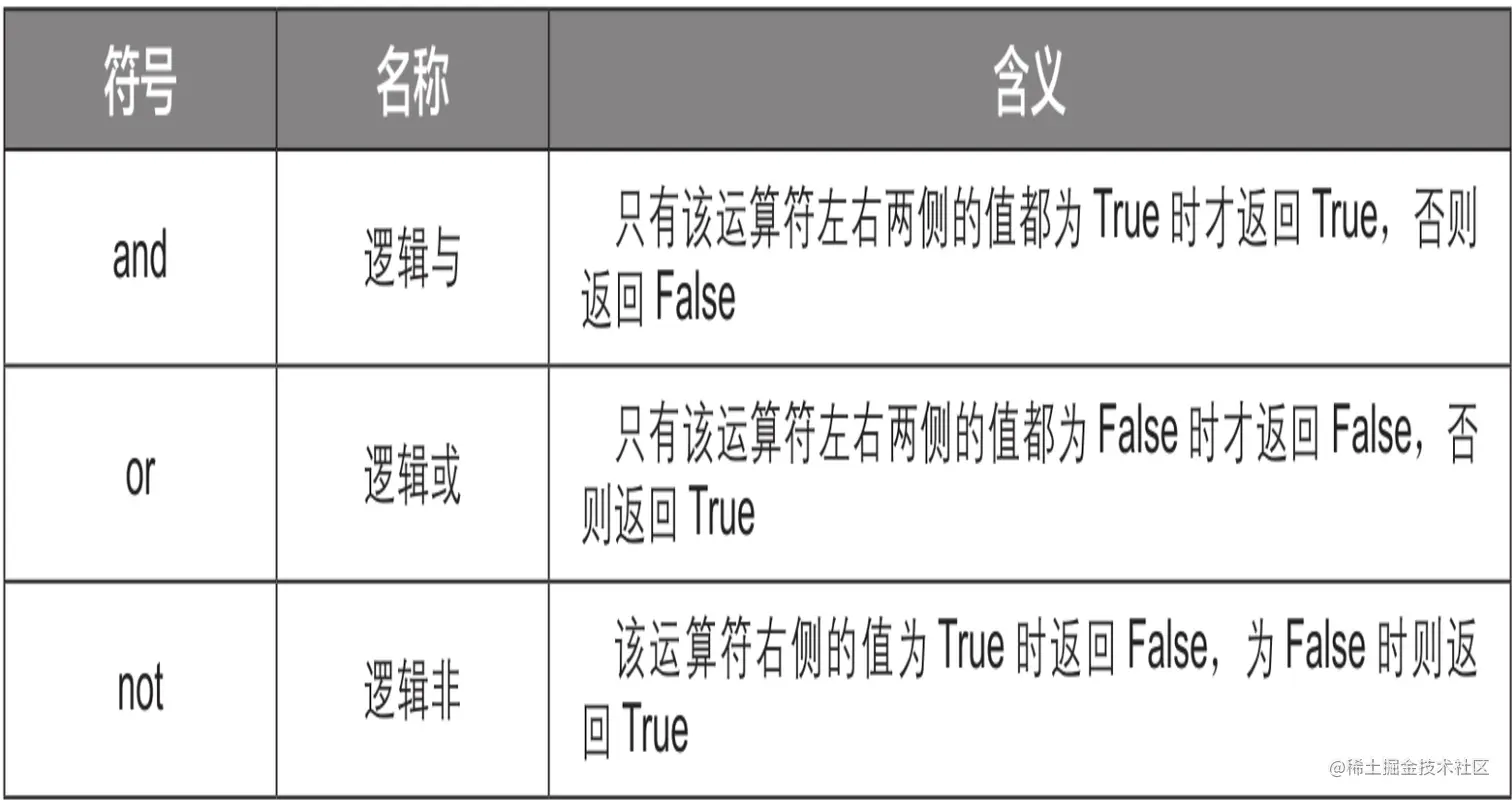
2.4 控制语句
Python 的控制语句分为条件语句和循环语句,前者为 if 语句,后者为 for 语句和 while 语句。
2.4.1 if 语句
if 语句主要用于条件判断,满足特定条件执行语句。
if 条件: # 注意不要遗漏冒号代码1 # 注意代码前要有缩进
else: # 注意不要遗漏冒号代码2 # 注意代码前要有缩进一个简单的示例:
grade = 60
if grade >= 60:print("及格")
else:print("不及格")2.4.2 for 循环
for 语句常用于完成指定次数的重复操作
for i in 序列: # 注意不要遗漏冒号要重复执行的代码 # 注意代码前要有缩进简单示例:
numbers = [12, 2, 212, 44, 5, 6]
for item in numbers:print(item)2.4.3 while 语句
while 语句用于在指定条件成立时重复执行操作。
while 条件: # 注意不要遗漏冒号要重复执行的代码 # 注意代码前要有缩进简单示例:
a = 60
while a < 70:print(a)a = a + 12.5 函数
Python 提供了诸多的内置函数,比如 str()、int() 等,但是在开发时,也需要经常用到自定义函数。
在 Python 中使用 def 关键字定义一个函数。
def 函数名(参数):实现函数功能的代码如果需要返回值,则需要使用 return 进行返回。
def data_transform():# 具体的实现逻辑return True2.6 模块导入
要使用模块,就需要安装和导入模块。模块的两种导入方法:import 语句导入法和 from语句导入法。
- import 语法会导入模块内所有方法,一般如果用包的方法较多可以选择;
- from 模块名 import 函数名:导入某块中某个函数,
import math # 导入math模块
import turtle # 导入turtle模块from math import sqrt # 导入math模块中的单个函数
from turtle import forward, backward, right, left # 导入turtle模块中的多个函数模块的安装使用 pip install 指令:
pip install "SomeProject"3. 网络请求与数据解析
爬虫肯定需要了解基础的网络请求和基础的 HTML 知识,能够认识基础的 HTML 标签。
3.1 requests 包
requests 包可以模拟浏览器发起 HTTP 或 HTTPS 协议的网络请求,从而获取网页源代码。
使用也比较简单,先安装模块:pip3 install requests.
get 请求
比如抓取百度首页的信息。
import requests
response = requests.get(url='https://www.baidu.com')
print(response.text)输出如下:

**post **请求
# 测试请求地址
req_url = "https://juejin.org/post"# 表单数据
formdata = {'username': 'admin','password': 'a123456',
}# 添加请求头
req_header = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
# 发起请求
response = requests.post(req_url,data=formdata,headers=req_header
)print(response.text)通过 requests 模块发送网络请求,非常简单,容易上手。
3.2 BeautifulSoup 数据解析
BeautifulSoup 模块是一个 HTML/XML 解析器,主要用于解析和提取 HTML/XML 文档中的数据。该模块不仅支持 Python 标准库中的 HTML 解析器 lxml,而且支持许多功能强大的第三方解析器。
在使用前先通过 pip 指令安装模块:pip install beautifulsoup4 。
3.2.1 简单使用
以请求百度首页为例。
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')print(soup.prettify())打印输出以下信息:
<!DOCTYPE html>
<!--STATUS OK-->
<html><head><meta content="text/html;charset=utf-8" http-equiv="content-type"/><meta content="IE=Edge" http-equiv="X-UA-Compatible"/><meta content="always" name="referrer"/><link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css"/><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“</title></head><body link="#0000cc"><div id="wrapper"><div id="head"><div class="head_wrapper"><div class="s_form"><div class="s_form_wrapper"><div id="lg"><img height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270"/></div><form action="//www.baidu.com/s" class="fm" id="form" name="f"><input name="bdorz_come" type="hidden" value="1"/><input name="ie" type="hidden" value="utf-8"/><input name="f" type="hidden" value="8"/><input name="rsv_bp" type="hidden" value="1"/><input name="rsv_idx" type="hidden" value="1"/><input name="tn" type="hidden" value="baidu"/><span class="bg s_ipt_wr"><input autocomplete="off" autofocus="autofocus" class="s_ipt" id="kw" maxlength="255" name="wd" value=""/></span><span class="bg s_btn_wr"><input autofocus="" class="bg s_btn" id="su" type="submit" value="百度一下"/></span></form></div></div>...</div></div></div></body>
</html>通过 BeautifulSoup 库可以将请求的网址信息按照标签进行转换展示。下面学习 BeautifulSoup 提供的标签操作方法。
3.2.2 查找标签
依照上一节中的百度首页为例,下面分别介绍 BeautifulSoup 中常用的方法。
查找指定标签名
在网页源码中,存在很多类型的标签。通过标签名进行定位只能返回其中的第一个标签。
比如我们查找定位 标签。
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')print(soup.input)输出结果:
<input name="bdorz_come" type="hidden" value="1"/>查找指定属性的标签
标签的属性有:name、class、id 等,我们使用 find 或 find_all 方法查找标签对应的所有属性。
import requests
from bs4 import BeautifulSoupif __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')# print(soup.prettify())# 查找 class 属性为 bg s_ipt_wr 的标签bg_tags = soup.find_all(class_='bg s_ipt_wr')for tag in bg_tags:print(tag) # 输出 <span class="bg s_ipt_wr"><input autocomplete="off" autofocus="autofocus" class="s_ipt" id="kw" maxlength="255" name="wd" value=""/></span># 查找 name = rsv_idxidx = soup.find(attrs={'name': 'rsv_idx'})print(idx) # 输出 <input name="rsv_idx" type="hidden" value="1"/>在上面的示例中,我们通过 find_all 方法查找所有 class_= 'bg s_ipt_wr'的标签。因为 class 这个单词本身是 Python 的保留字,所以 BeautifulSoup 模块中的 class 属性在末尾添加了下划线来进行区分。其他标签属性,如 id 属性,则没有添加下划线。
通过标签名+属性查找
通过指定标签名 + 属性值可以实现更准确的查找。
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')# print(soup.prettify())# 查找 input 标签且属性 name = rsv_idxidx = soup.find('input', attrs={'name': 'rsv_idx'})print(idx) # 输出 <input name="rsv_idx" type="hidden" value="1"/>3.2.3 选择标签
在上一小节中介绍了 find 方法用于查找标签,使用 select() 函数可以根据指定的选择器返回所有符合条件的标签。常用的选择器有 id 选择器、class 选择器、标签选择器和层级选择器。
1. 标签选择器
根据指定的标签进行筛选。在 find 中根据指定标签名查找时只会返回第一个匹配项。使用 select 标签返回所有。
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')# print(soup.prettify())input_tag = soup.select('input')print(input_tag)# 输出 [<input name="bdorz_come" type="hidden" value="1"/>, <input name="ie" type="hidden" value="utf-8"/>]在 select 中直接查找对应的标签名,会输出所有的标签。
2. id 选择器
id 选择器是根据 id 值查找对应的标签。格式 ‘#id值’
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')# print(soup.prettify())input_tag = soup.select('#kw')print(input_tag)# 输出 [<input autocomplete="off" autofocus="autofocus" class="s_ipt" id="kw" maxlength="255" name="wd" value=""/>]上面的示例中,查找 id 值为 kw 的标签。注意输出是列表形式。
3. class 选择器
class 选择器根据 class 属性值查找对应的标签,格式为 ‘.class属性值’
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')# print(soup.prettify())input_tag = soup.select('.s_ipt')print(input_tag)# 输出 [<input autocomplete="off" autofocus="autofocus" class="s_ipt" id="kw" maxlength="255" name="wd" value=""/>]上面的示例中,查找 class 值为 s_ipt 的标签。注意输出是列表形式。
4. 层级筛选器
在 HTML 中标签嵌套很常见,标签在不同的层级形成嵌套结构。通过 标签>标签这种指向结构来定位。
<div class="s_form_wrapper"><div id="lg"><img height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270"/></div><form action="//www.baidu.com/s" class="fm" id="form" name="f"><input name="bdorz_come" type="hidden" value="1"/><input name="ie" type="hidden" value="utf-8"/><input name="f" type="hidden" value="8"/><input name="rsv_bp" type="hidden" value="1"/><input name="rsv_idx" type="hidden" value="1"/><input name="tn" type="hidden" value="baidu"/><span class="bg s_ipt_wr"><input autocomplete="off" autofocus="autofocus" class="s_ipt" id="kw" maxlength="255" name="wd" value=""/></span><span class="bg s_btn_wr"><input autofocus="" class="bg s_btn" id="su" type="submit" value="百度一下"/></span></form>
</div>使用上面的示例数据,我们来验证。
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')# 查找所有 <div> 标签下 <div> 标签的 id 属性值为 lg 的标签div_tag = soup.select('div>div>#lg')# 输出结果 [<div id="lg"> <img height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270"/> </div>]print(div_tag)# 查找 <form> 标签下所有的 input 标签input_tag = soup.select('form>input')print(input_tag)# 输出结果 [<input name="bdorz_come" type="hidden" value="1"/>, <input name="ie" type="hidden" value="utf-8"/>, <input name="f" type="hidden" value="8"/>, <input name="rsv_bp" type="hidden" value="1"/>, <input name="rsv_idx" type="hidden" value="1"/>, <input name="tn" type="hidden" value="baidu"/>]form_tag = soup.select('div>form span')print(form_tag)“>” 在层级选择器中表示向下找一个层级,中间不能有其他层级。如果中间有空格表示中间可以有多个层级。
3.2.4 提取内容和属性
找到标签后,我们需要读取标签对应的内容或者属性。
提取标签内容
获取标签后我们需要查找标签中的内容,可以利用 string 或 text 来提取。string 属性返回的是指定标签的直系文本,即直接存在于该标签中的文本,而不是存在于该标签下的其他标签中的文本。text 属性返回的则是指定标签下的所有文本。
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')# 查找所有 <div> 标签下 <div> 标签的 id 属性值为 lg 的标签div_tag = soup.select('div>a')print(div_tag[0].string)print(div_tag[0].text)从标签中提取属性
对于找到的标签,提取属性直接使用 tag['属性表']即可。
if __name__ == '__main__':url = "https://www.baidu.com"response = requests.get(url)soup = BeautifulSoup(response.text, 'lxml')div_tag = soup.select('form>input') # [<input name="bdorz_come" type="hidden" value="1"/>]print(div_tag[0]['name']) # bdorz_come print(div_tag[0]['type']) # hidden至此,我们基本完成了对 beautifulSoup 库的学习。
4. 正则表达式
正则表达式是一种用于匹配和操作文本的强大工具,它是由一系列字符和特殊字符组成的模式,用于描述要匹配的文本模式。正则表达对网页源代码的字符串进行匹配,从而提取出需要的数据。
4.1 普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
| 符号 | 描述 |
|---|---|
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \w | 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。 |
| \d | 匹配一个数字字符。等价于[0-9]。 |
| \D | 匹配一个非数字字符。等价于[^0-9]。 |
示例代码:
if __name__ == '__main__':str = 'kdd199ok98 a123 343'print(re.findall('\W', str)) # 匹配任何非单词字符,[' ', ' ']print(re.findall('\w', str)) # 匹配任何单词字符,['k', 'd', 'd', '1', '9', '9', 'o', 'k', '9', '8', 'a', '1', '2', '3', '3', '4', '3']print(re.findall('\S', str)) # 匹配任何非空白字符,['k', 'd', 'd', '1', '9', '9', 'o', 'k', '9', '8', 'a', '1', '2', '3', '3', '4', '3']print(re.findall('\s', str)) # 匹配空白字符,[' ', ' ']print(re.findall('\D', str)) # 匹配非数字,['k', 'd', 'd', 'o', 'k', ' ', 'a', ' ']print(re.findall('\d', str)) # 匹配数字,['1', '9', '9', '9', '8', '1', '2', '3', '3', '4', '3']4.2 元字符
元字符是正则表达式中有特殊含义的字符,可以设置字符的匹配模式。
| 符号 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 也匹配′n′或′r′。要匹配也匹配 ‘\\n’ 或 ‘\\r’。要匹配也匹配′n′或′r′。要匹配 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。‘\n’ 匹配换行符。序列 ‘\\’ 匹配 “\”,而 ‘\(’ 则匹配 “(”。 |
| 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 | |
| {n} | n 是一个非负整数。匹配确定的 n 次。 |
| {n,} | n 是一个非负整数。至少匹配n 次。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。 |
示例代码:
if __name__ == '__main__':str = 'akdd1d199ok98 d123 3438'print(re.findall('8$', str)) # 匹配以 8 结尾的字符,['8']print(re.findall('3$', str)) # 匹配以 3 结尾的字符,[]print(re.findall('^a', str)) # 匹配以 a 开头的字符,['a']print(re.findall('^d', str)) # 匹配以 d 开头的字符,[]print(re.findall('(d1)?', str)) # 匹配 d1 零次或一次的字符,['', '', 'd1', '', '', '', '', '', '', '', 'd1', '', '', '', '', '', '', '', '']print(re.findall('(d1)+', str)) # 匹配 d1 一次或多次的字符,['d1', 'd1']print(re.findall('(d1)*', str)) # 匹配 d1 零次或多次的字符,['', '', 'd1', '', '', '', '', '', '', '', 'd1', '', '', '', '', '', '', '', '']print(re.findall('(d1){2,}', str)) # 匹配 d1 最少 2 次的字符,['d1']print(re.findall('(d1){1,2}', str)) # 匹配 d1 最少 1 次,最多 2 次的字符,['d1', 'd1']print(re.findall('(d.d)', str)) # 匹配 (d.d) 的字符,['d1d']print(re.findall('(d?d)', str)) # 匹配 (d?d) 的字符,['dd', 'd', 'd']print(re.findall('[ad]', str)) # 匹配字符集合 [ad] 的字符,['a', 'd', 'd', 'd', 'd']print(re.findall('(ad)', str)) # 匹配表达式 ad ,[]正在表达式基础,但是想灵活运用起来还需要多加练习,太灵活可以组装很多模式。
5. Selenium 的基本使用
通过 requests 模块可以实现对一些静态网页的请求,对于一些动态与浏览器需要交互的地址则不能满足。而 Selenium 模块则能控制浏览器发送请求,并和获取到的网页中的元素进行交互,因此,只要是浏览器发送请求能得到的数据,Selenium 模块也能直接得到。
5.1 环境安装
使用 Selenium 模块需要先下载和安装浏览器驱动程序,然后在编程时通过 Selenium 模块实例化一个浏览器对象,再通过浏览器对象访问网页和操作网页元素。
5.1.1 安装 Selenium 模块
安装比较简单,直接使用 pip install selenium安装就行了。比较重要的是安装浏览器驱动程序。
2.1.2 安装浏览器驱动程序
在网址 chromedriver.storage.googleapis.com/index.html 中可以下载对应版本的浏览器驱动程序。
查看自己浏览器版本,在浏览器中输入:chrome://version/
选择对应的电脑端系统,比如我是 Mac 系统,下载对应的即可。解压之后放到环境路径或者项目中都行,只要在使用时指定对应的环境即可。
5.1.3 打开页面
这里已打开百度网站为例。我将 webdriver 放到项目路径中。
from selenium import webdriverif __name__ == '__main__':browser = webdriver.Chrome(executable_path='./chromedriver_mac64/chromedriver')browser.get('https://www.baidu.com')5.2 常见 API
5.2.1 浏览器操作
webdriver 返回的 browser 对象中,提供了丰富的 API 用于操作浏览器。
| browser.maximize_window() | 最大化浏览器 |
|---|---|
| browser.current_url | 当前网页 url |
| browser.get_cookie() | 当前网页用到的 cookie 信息 |
| browser.name | 当前浏览器驱动名称 |
| browser.title | 当前网页标题 |
| browser.page_source | 获取当前网页源代码 |
| browser.current_window_handle | 获取当前网页的窗口 |
| browser.refresh() | 刷新当前网页 |
| browser.quit() | 关闭浏览器 |
| browser.close() | 关闭当前网页 |
| browser.back() | 返回上一页 |
5.2.2 查找标签
完成了网页的访问后,如果需要模拟用户操作网页元素,则需要先通过标签来定位网页元素。
find_element(self, by=By.ID, value=None)� 查找元素,其中 By.ID 是枚举类型:
- ID:通过元素 id 定位;
- XPATH:通过 xpath 表达式定位;
- LINK_TEXT:通过完整超链接定位;
- PARTIAL_LINK_TEXT:通过模糊超链接定位;
- NAME:通过元素 name 定位;
- TAG_NAME:通过标签定位;
- CLASS_NAME:通过 class 进行定位;
- CSS_SELECTOR:通过 css 选择器进行定位。
使用示例:
from selenium import webdriver
from selenium.webdriver.common.by import Byif __name__ == '__main__':browser = webdriver.Chrome(executable_path='./chromedriver_mac64/chromedriver')browser.get('https://www.baidu.com')tag1 = browser.find_element(by=By.ID, value='form')print(tag1.get_attribute("class"))找到标签后,就可以通过 get_attribute 方法获取对应的属性值。
5.3 模拟鼠标操作
常用的鼠标操作有单击、双击、右击、长按、拖动、移动等,模拟这些操作需要用到 Selenium 模块中的ActionChains 类。它提供了以下方法:
- click():模拟点击;
- double_click():模拟双击;
- click_and_hold():鼠标长按;
- click_and_hold():释放鼠标按;
下面以打开百度首页的图片链接为例:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import Byif __name__ == '__main__':browser = webdriver.Chrome(executable_path='./chromedriver_mac64/chromedriver')browser.get('https://www.baidu.com')# 找到图片链接alink = browser.find_element(by=By.LINK_TEXT, value='图片')print(alink.get_attribute("href"))actions = ActionChains(browser)actions.click(alink).perform()运行成功后,会首先打开百度首页,然后跳转到百度图片页面。
6. 总结
以上就是今天的全部内容分享,觉得有用的话欢迎点赞收藏哦!
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
小编为对Python感兴趣的小伙伴准备了以下籽料 !
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑培训的!
- 学习时间相对较短,学习内容更全面更集中
- 可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
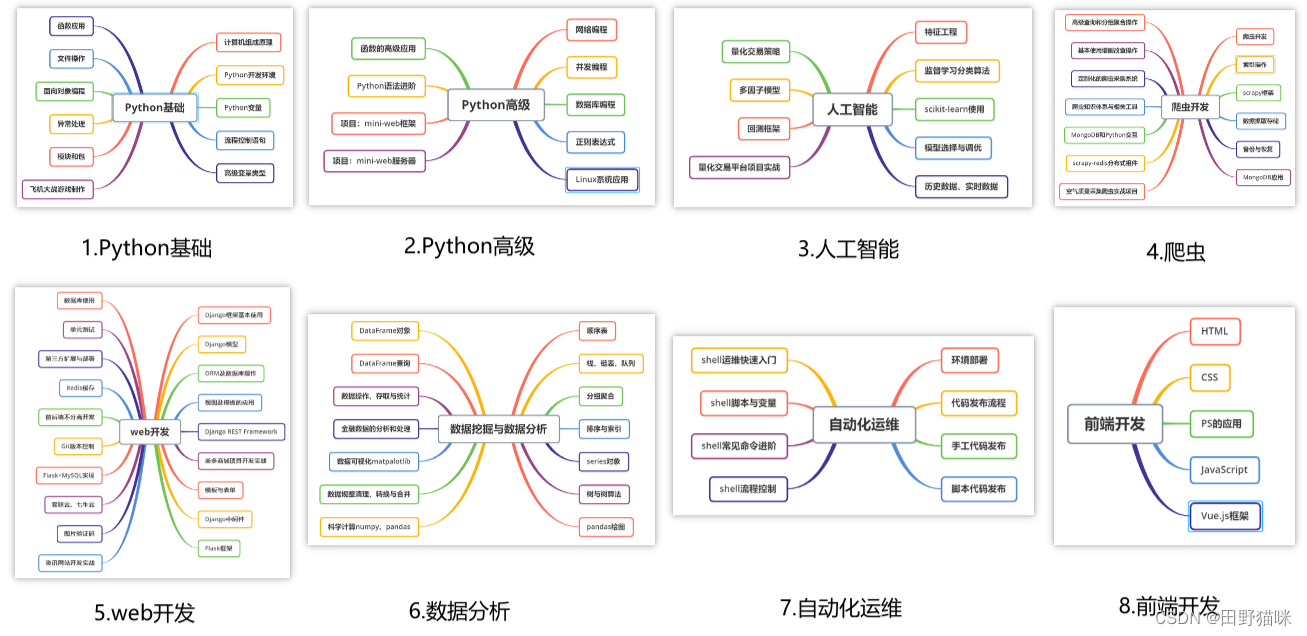
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !
相关文章:
全网最详细!!Python 爬虫快速入门
1. 背景 最近在工作中有需要使用到爬虫的地方,需要根据 Gitlab Python 实现一套定时爬取数据的工具,所以借此机会,针对 Python 爬虫方面的知识进行了学习,也算 Python 爬虫入门了。 需要了解的知识点: Python 基础语…...
gitgud.io+Sapphire注册账号教程
gitgud.io是一个仓库,地址 https://gitgud.io/,点进去之后会看到注册页面。 意思是需要通过注册这个Sapphire账户来登录。点击右边的Sapphire,就跳转到Sapphire的登陆页面,点击创建新账号,就进入注册页面。࿰…...

【动态规划】【广度优先搜索】【状态压缩】847 访问所有节点的最短路径
作者推荐 视频算法专题 本文涉及知识点 动态规划汇总 广度优先搜索 状态压缩 LeetCode847 访问所有节点的最短路径 存在一个由 n 个节点组成的无向连通图,图中的节点按从 0 到 n - 1 编号。 给你一个数组 graph 表示这个图。其中,graph[i] 是一个列…...

python基础小知识:引用和赋值的区别
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 1.引用 python中,赋值操作会产生相同对象的多个引用, 如果在原位置修改这个可变对象时,可能会影响程序其他位置对这个对象的…...
欧科云链与《警察技术》联合发布技术专题.pdf
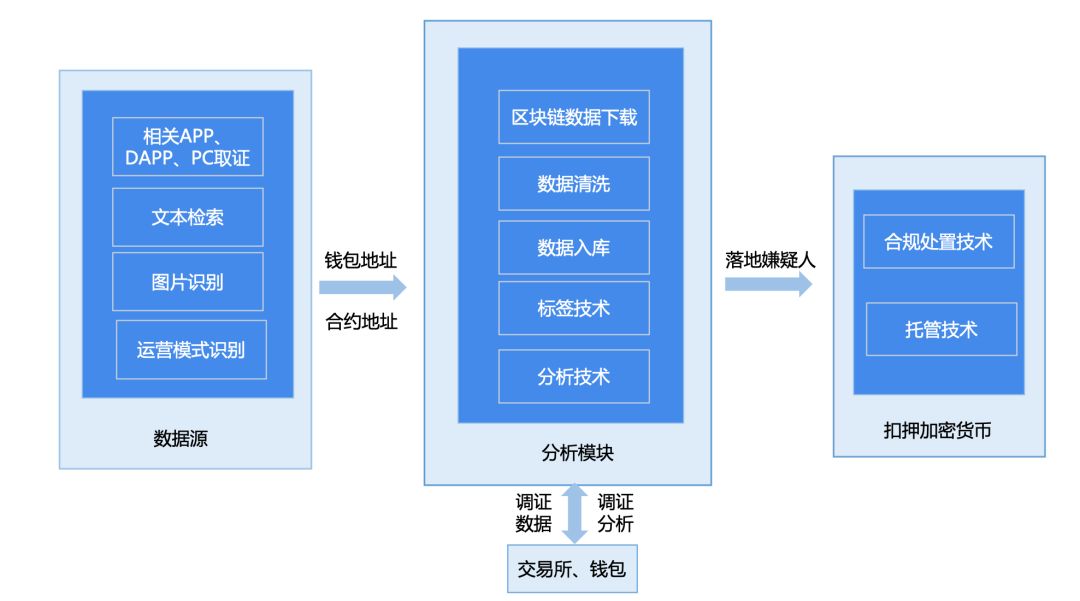
欧科云链受《警察技术》邀请,于第201期期刊正式刊登“区块链生态安全与虚拟货币犯罪治理”技术专题。欧科云链作为该技术专题主要作者,直接参与本次期刊2篇文章撰写,同时为多篇文章提供欧科云链的最新数据和研究成果。 《警察技术》期刊创办于…...
【QT+QGIS跨平台编译】之一:【sqlite+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、sqlite3介绍二、文件下载三、文件分析四、pro文件五、编译实践 一、sqlite3介绍 SQLite是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的&…...
websocket实现聊天室(vue2 + node)
通过websocket实现简单的聊天室功能 需求分析如图: 搭建的项目结构如图: 前端步骤: vue create socket_demo (创建项目)views下面建立Home , Login组件路由里面配置路径Home组件内部开启websocket连接 前端相关组件代码: Login…...
RabbitMQ-消息延迟
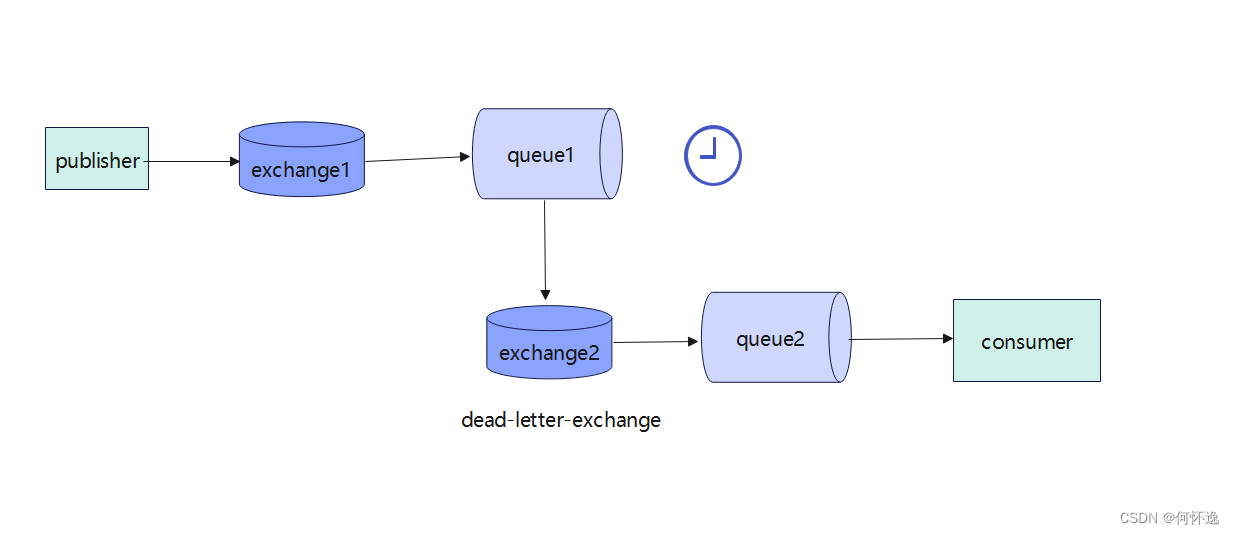
一、死信交换机 1、描述 一个队列接收到的消息有过期时间,消息过期之后,如果配置有死信队列,消息就会进去死信队列。 2、图解 3、过程 当生产者将消息发送到exchange1,然后交换机将消息路由到队列queue1,但是队列que…...

【Oracle】如何给物化视图分区
文章目录 【Oracle】如何给物化视图分区给物化视图进行分区的例 【声明】文章仅供学习交流,观点代表个人,与任何公司无关。 编辑|SQL和数据库技术(ID:SQLplusDB) 收集Oracle数据库内存相关的信息 【Oracle】ORA-32017和ORA-00384错误处理 【Oracle】设置…...

10个常考的前端手写题,你全都会吗?
前言 📫 大家好,我是南木元元,热爱技术和分享,欢迎大家交流,一起学习进步! 🍅 个人主页:南木元元 今天来分享一下10个常见的JavaScript手写功能。 目录 1.实现new 2.call、apply、…...

vue组件间通信
Vue组件之间通信方式有哪些 一、父子组件通讯 1、props,emit 父组件可以通过props给子组件传递变量。子组件可以通过emit派发自定义事件,使父组件可以获得事件函数传递过来的形参。 2、$parent、$children、ref 父组件可以通过 c h i l d r e n 获取…...

编程框架概述:MVC, MVP, MVVM, Flux/Redux, 和 Clean Architecture
前言 在软件开发中,选择合适的编程框架和架构模式对于构建可维护和可扩展的应用程序至关重要。初学者在面对多种架构选项时可能会感到困惑。本文将详细介绍五种流行的编程框架:MVC、MVP、MVVM、Flux/Redux和Clean Architecture。 MVC(Model-V…...

多维时序 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆神经网络融合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆神经网络融合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现CNN-BiLSTM-Mutilhead-Attention卷积双向长短期记忆神经网络融合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计…...

np.argsort排序问题(关于位次)-含GitHub上在numpy项目下提问的回复-总结可行方案
np.argsort 与获取位相关问题 位次: 数组中的数据在其排序之后的另一个数组中的位置 [1,0,2,3] 中 0的位次是1 1的位次是2 2的位次是3 3的位次是4 这里先直接给出结论,np.argsort()返回的索引排序与实际位次在确实在某些情况下会出现一致,但后来numpy的开…...

Element中的el-input-number+SpringBoot+mysql
1、编写模板 <el-form ref"form" label-width"100px"><el-form-item label"商品id:"><el-input v-model"id" disabled></el-input></el-form-item><el-form-item label"商品名称&a…...

Jupyter Notebook五分钟基础速通
1 作用 常用于数据分析 2 安装 2.1 Anaconda 通过直接安装Anaconda,会自动安装Jupyter Notebook 2.2 命令行安装 ① 3.x版本 pip3 install --upgrade pip pip3 install jupyter ② 2.x版本 pip install --upgrade pip pip install jupyter 3 启动 cmd窗口下…...
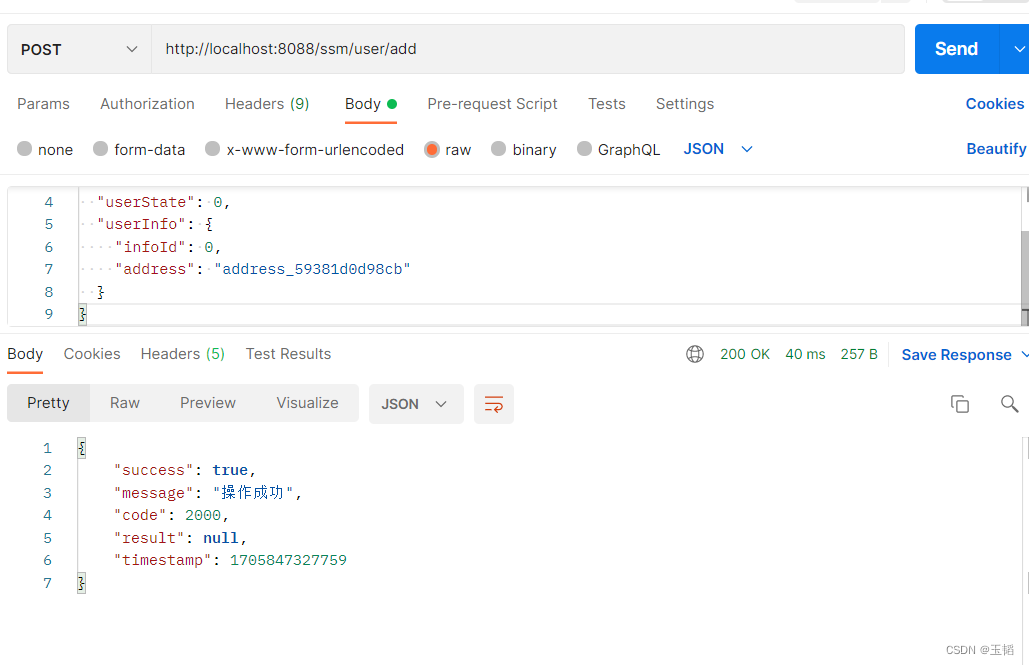
基于SpringBoot的SSM整合案例
项目目录: 数据库表以及表结构 user表结构 user_info表结构 引入依赖 父模块依赖: <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.12.RELEASE</version>…...
[SS]语义分割_转置卷积
转置卷积(Transposed Convolution) 抽丝剥茧,带你理解转置卷积(反卷积) 目录 一、概念 1、定义 2、运算步骤 二、常见参数 一、概念 1、定义 转置卷积(Transposed Convolution)…...

面板小程序命令行工具介绍
Ray 体系提供配套的工程化解决方案。 由于多端构建的一些客观原因,在构建流程的设计上,必须将工程套件安装在项目内。 项目内的依赖至少包含以下内容: {"dependencies": {"ray-js/ray": "latest"},"de…...

DBA技术栈MongoDB: 数据增改删除
该博文主要介绍mongoDB对文档数据的增加、更新、删除操作。 1.插入数据 以下案例演示了插入单个文档、多个文档、指定_id、指定多个索引以及插入大量文档的情况。在实际使用中,根据需求选择适合的插入方式。 案例1:插入单个文档 db.visitor.insert({…...

如何高效下载B站视频:3分钟掌握智能下载工具完整指南
如何高效下载B站视频:3分钟掌握智能下载工具完整指南 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader 你是否曾经遇到过这样的情况&a…...

3步打造专属Windows系统:tiny11builder精简方案终极指南
3步打造专属Windows系统:tiny11builder精简方案终极指南 【免费下载链接】tiny11builder Scripts to build a trimmed-down Windows 11 image. 项目地址: https://gitcode.com/GitHub_Trending/ti/tiny11builder 在当今数字时代,你是否经常感觉Wi…...

VMware Unlocker终极指南:如何在Windows/Linux上免费解锁macOS虚拟机支持
VMware Unlocker终极指南:如何在Windows/Linux上免费解锁macOS虚拟机支持 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 你是否曾经想在Windows或Linux电脑上运行macOS虚拟机,却…...

如何为FF14国际服实现完整中文汉化:FFXIVChnTextPatch实战指南
如何为FF14国际服实现完整中文汉化:FFXIVChnTextPatch实战指南 【免费下载链接】FFXIVChnTextPatch 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIVChnTextPatch 还在为《最终幻想14》国际服的英文界面而烦恼吗?FFXIVChnTextPatch项目为你提…...

免费扩展Windows虚拟显示器:5分钟打造高效多屏工作空间
免费扩展Windows虚拟显示器:5分钟打造高效多屏工作空间 【免费下载链接】virtual-display-rs A Windows virtual display driver to add multiple virtual monitors to your PC! For Win10. Works with VR, obs, streaming software, etc 项目地址: https://gitco…...

轻松解包网易游戏资源:unnpk工具完整使用指南
轻松解包网易游戏资源:unnpk工具完整使用指南 【免费下载链接】unnpk 解包网易游戏NeoX引擎NPK文件,如阴阳师、魔法禁书目录。 项目地址: https://gitcode.com/gh_mirrors/un/unnpk 想要探索网易游戏如《阴阳师》、《魔法禁书目录》中的精美角色立…...

LinuxCNC新手到专家:5个步骤打造你的完美数控系统
LinuxCNC新手到专家:5个步骤打造你的完美数控系统 【免费下载链接】linuxcnc LinuxCNC controls CNC machines. It can drive milling machines, lathes, 3d printers, laser cutters, plasma cutters, robot arms, hexapods, and more. 项目地址: https://gitcod…...

3分钟上手Awoo Installer:Switch游戏安装终极指南
3分钟上手Awoo Installer:Switch游戏安装终极指南 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装烦恼吗…...

告别iTunes!在Ubuntu 22.04上使用libimobiledevice管理你的iPhone文件
告别iTunes!在Ubuntu 22.04上使用libimobiledevice管理你的iPhone文件 当Linux用户第一次将iPhone连接到Ubuntu系统时,往往会遇到一个尴尬的现实——系统无法识别这个世界上最流行的移动设备。不同于Windows和macOS,Linux默认缺乏对iOS设备的…...
)
Labelme版本不兼容报错?手把手教你修改源码和JSON文件(附3.18.0与4.5.6对比)
Labelme版本兼容性实战:从源码修改到JSON批量处理的完整指南 当你正专注于一个重要的数据标注项目,突然遭遇"Error opening file lineColor"的红色报错框,整个团队的标注进度被迫停滞——这种场景对于使用Labelme进行图像标注的开发…...