np.argsort排序问题(关于位次)-含GitHub上在numpy项目下提问的回复-总结可行方案
np.argsort 与获取位相关问题
位次: 数组中的数据在其排序之后的另一个数组中的位置
[1,0,2,3] 中 0的位次是1 1的位次是2 2的位次是3 3的位次是4
这里先直接给出结论,np.argsort()返回的索引排序与实际位次在确实在某些情况下会出现一致,但后来numpy的开发人员给我举例回复这是巧合,如果想获取位次,可以考虑使用scipy.stats.rankdata()方法,也组合numpy中其他函数。
- 如果你是想解决问题的开发人员直接根据目录跳转到最后方法总结查看示例代码,或者按照函数名直接搜索官方文档即可
- 如果你有相关问题的思考想直接看一下我和开发人员的探讨内容,直接点击链接去GitHub中查看即可
链接: https://github.com/numpy/numpy/issues/25601
我当时以为没有重复数据的时候就可以返回位次,但是有重复数据的时候不行,所以提问的标题是当时以为的情况,但后续讨论就是我这篇博客标题说的内容了
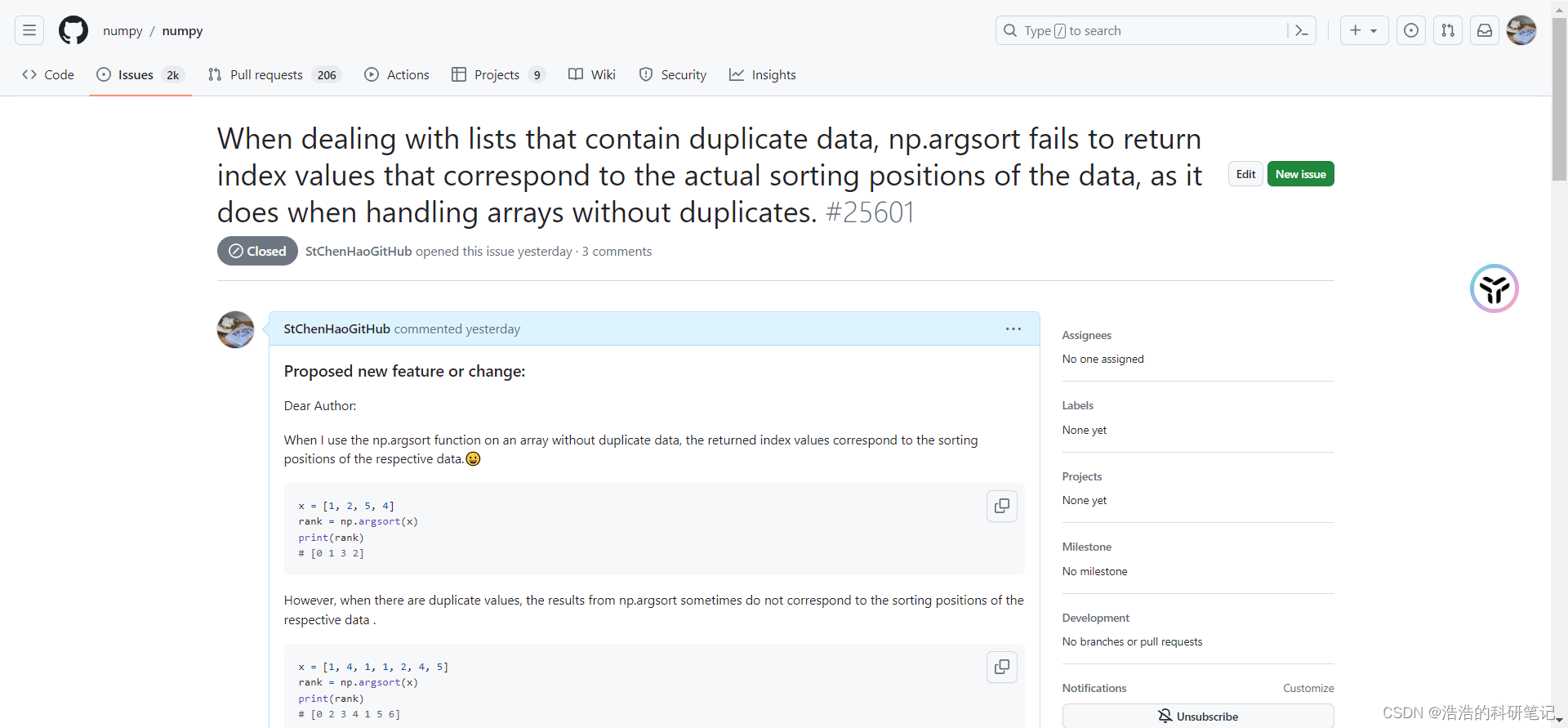
- 如果你想了解一下问题产生的原因和和听我絮叨拆解补充分析一下一下我俩对话的内容,可以扫一下下面的内容,或者根据经验自己跳着读。
1.问题的产生
事情是这样的在做项目的时候我遇到了这样一个问题,我要对某一个对象的收入进行分析,emmmm, 还是要举一个实际的例子,假设我要对一种奶茶店的收入进行分析,例如我要分析10个店面的这个月的收入情况,每个店面的收入由三部分组成,奶茶,果茶,冰淇淋。
| 店铺编号 | 总收入 | 果茶收入 | 奶茶收入 | 冰淇淋收入 |
|---|---|---|---|---|
| 店铺1 | 1954 | 100 | 911 | 754 |
| 店铺2 | 1663 | 300 | 949 | 705 |
| 店铺3 | 1765 | 200 | 822 | 388 |
| 店铺4 | 1437 | 500 | 911 | 252 |
| 店铺5 | 1410 | 400 | 105 | 932 |
首先先根据总收入这一列的数据对每一行进行排序
以下是常用的代码
# 原始列表
original_list = [['店铺1', 1954, 100, 911, 754],['店铺2', 1663, 300, 949, 705], ['店铺3', 1765, 200, 822, 388], ['店铺4', 1437, 500, 911, 252],['店铺5', 1410, 400, 105, 932]
]# 使用.sort()方法根据总收入对列表进行排序
original_list.sort(key=lambda x: x[1], reverse=True)
那么从大到小的排序结果如下,按照顺序其实就是总收入的排名
| 店铺编号 | 总收入 | 果茶收入 | 奶茶收入 | 冰淇淋收入 |
|---|---|---|---|---|
| 店铺1 | 1954 | 100 | 911 | 754 |
| 店铺3 | 1765 | 200 | 822 | 388 |
| 店铺2 | 1663 | 300 | 949 | 705 |
| 店铺4 | 1437 | 500 | 911 | 252 |
| 店铺5 | 1410 | 400 | 105 | 932 |
好那接下来我想在这个表里在果茶收入,奶茶收入,冰淇淋收入前面各加一列,分别为果茶收入排名,奶茶收入排名,冰淇淋收入排名。
| 店铺编号 | 总收入 | 果茶收入排名 | 果茶收入 | 奶茶收入排名 | 奶茶收入 | 冰淇淋收入排名 | 冰淇淋收入 |
|---|---|---|---|---|---|---|---|
| 店铺1 | 1954 | 待计算 | 100 | 待计算 | 911 | 待计算 | 754 |
| 店铺3 | 1765 | 待计算 | 200 | 待计算 | 822 | 待计算 | 388 |
| 店铺2 | 1663 | 待计算 | 300 | 待计算 | 949 | 待计算 | 705 |
| 店铺4 | 1437 | 待计算 | 500 | 待计算 | 911 | 待计算 | 252 |
| 店铺5 | 1410 | 待计算 | 400 | 待计算 | 105 | 待计算 | 932 |
那这个排名怎么得到,首先拿出奶茶这一列的数据。
然后就想用什么函数, 这时候忽然依稀的想起,数据对应的位置就是索引+1, 例如索引为0的数据实际上是列表的第1个数据,也就是位置为1,然后好像记得np.argsort()就是返回排序的索引,索引+1表示的应该就是他的位置,又排序了又有位置,虽然下意识有点怀疑感觉哪里不对,但是决定还是直接用一下再说,
然后我就使用了类似于果茶排名的数据进行了下面的操作(默认从小到大)
import numpy as np
data = [100, 200, 300, 500, 400]
rank = np.argsort(data) + 1
print(rank)
# [1 2 4 5 3]
呀(二声)!?
从小到大的看∑( 口 ||好像是对的哈,是位次
然后我就对所有的列都这样操作了将返回结果作为了位序的结果,由于收入数据很少有一样的而且数量很多所以其实不太好一眼看出逻辑错误,可能就观察了前几个,发现相对关系好像没问题就没再仔细检查了,但是在后续实际数据中由于有一些数据不存在,所以我直接都给赋值成了-1我认为这样的话他会被排在两边,但是存在大量的-1之后发现了问题。
如果按照位次的逻辑,下面的结果不就是胡排八排吗
默认是从小到大排的-1对应的位置是4,和3 在中间是怎么回事,1,2才是对的把,或者两个都是1
import numpy as np
data = [1, -1, 3, -1, 4]
rank = np.argsort(data) + 1
print(rank)
# [2 4 1 3 5]
在浏览了各种资料之后,有人说可能是排序方式选择的问题,默认是快速排序,快速排序有可能有问题,我就把文档里的np.argsort()的四种排序方式实验了一遍,加上好像其他人好像也都是对有重复数据的排序结果产生了质疑。此时我把我同样做算法的也是刚毕业的研究生航宝(昵称)叫了过来,让其帮我在stackflow上也简单搜索了下,也有人提出了这个问题,但是但是没有能直接一眼瞄到的问题的答案(也不排除看的不认真)。我俩也是鬼使神差的觉得这应该是由于有重复数据的问题。
之后我开始尝试写了一个可以实现返回位序的代码。
import numpy as np
data = [1, -1, 3, -1, 4]def my_sort(x):arg_x = np.sort(x)rank = [np.where(arg_x == i)[0][0] for i in x]return np.array(rank)rank = my_sort(data) + 1
print(rank)
# [3 1 4 1 5] 现结果
# [2 4 1 3 5] 原结果
然后找航宝来帮我验证,发现确实可以实现获得位序的功能,然后航宝提议,去GitHub上问一问,顺便搜一搜,我俩在问题里输入argsort同样也是简单翻了一翻,我俩认为这应该是个应该比较常见的问题,应该一搜就能搜到所以也没怎么往后面翻,发现没有之后,我俩就开始着手准备提问,点开了issue,在写issue中,我们又看了一遍np.argsort(data)官方文档的描述,述其描述如下
np.argsort performs an indirect sort on an array, returning the indices that would sort the array.
我们两个人又重新理解了一遍这个意思,np.argsort 返回一个不是对一个array直接排序结果,返回的是indices(索引们),而这些indices会对这个数组进行排序。
我们翻译成土话,可以理解的就是你按照np.argsort(data)的返回结果(一个有顺序的包含索引值的列表),把列表中的索引值替换为data[索引值],最后你会得到一个有序的数组。
嗯,真适合作为一道面试题,之前的话我可能会脱口而出他返回的是排序之后的索引(其实对不懂的人来说这句话可能并不清晰)
此时我们理解了np.argsort()的功能但是依旧认为他对非包含重复值的数组依然可以返回位序但是只不过如果含重复数值的话可能由于其使用的算法关系失去了这个功能
因此我们关闭了提出issue的选项,因为np.argsort()本身没有问题不是BUG,转而选择了一个给numpy增添新功能的选项,写完正文发送了之后,又给邮箱发了一遍邮件。以下是邮件内容
不敢兴趣可以跳过
2.鄙人给numpy讨论邮箱发送的邮件内容
汉语是我本来的意思,英语是连机翻再改的结果,可能有点对不上但是大致是一个意思
尊敬的作者:
Dear Author:
当我使用np.argsort 函数处理具有非重复数据的数组的时候,他返回的索引值,与其排序之后所处的位置有关联
When I use the np.argsort function on an array without duplicate data, the returned index values correspond to the sorting positions of the respective data.😀
x = [1, 2, 5, 4]
rank = np.argsort(x)
print(rank)
# [0 1 3 2]
但当数组中包含重复数据时,np.argsort函数有时就无法返回与数据位置相关的信息了。
However, when there are duplicate values, the results from np.argsort sometimes do not correspond to the sorting positions of the respective data .
x = [1, 4, 1, 1, 2, 4, 5]
rank = np.argsort(x)
print(rank)
# [0 2 3 4 1 5 6]
有可能一个人经常使用np.argsrot处理具有非重复数据的数组来获取位置信息,有重复数据的话,可能会产生一些不易察觉的错误,如果数据长度非常大的话发现这个问题可能更具有挑战性。
Assuming a person frequently uses np.argsort to obtain positions by sorting data without duplicates, introducing duplicate values in the data may lead to inconspicuous errors in positions that are difficult to detect. Moreover, as the dataset grows, identifying such issues may become even more challenging.
可能对于有这种需求的用户来说,他们想要得到的结果可以由以下函数实现
For users in this situation, the desired results might be achieved using the following function:
def my_sort(x):arg_x = np.sort(x)rank = [np.where(arg_x == i)[0][0] for i in x]return np.array(rank)x = [1, 4, 1, 1, 2, 4, 5]
rank_arg = np.argsort(x)
rank_position = my_sort(x)
print("rank_arg",rank_arg)
print("rank_position",rank_position)
# rank_arg [0 2 3 4 1 5 6]
# rank_position [0 4 0 0 3 4 6]这个方法在处理具有非重复数据的时候与np.argsort函数的返回结果一致(补充:后来证明这是巧合)
This method produces results consistent with np.argsort when applied to arrays without duplicate values.
x = [1, 2, 5, 4]
rank_arg = np.argsort(x)
rank_position = my_sort(x)
print("rank_arg",rank_arg)
print("rank_position",rank_position)
# rank_arg [0 1 3 2]
# rank_position [0 1 3 2]
尽管其实np.argsort函数文档本身描述的内容没有问题,但是这种需求可能是广泛存在的,因此能不能考虑新加一个功能,例如np.position(data),去提升numpy功能性
Although there is no issue with the documentation of np.argsort itself, the need you’ve highlighted may be widespread. Therefore, it might be worth considering the addition of a function, for example, np.position(data), to enhance the functionality of numpy.
我的设备
My device:
系统
system: win10 64x
python版本
python version: 3.9.11
numpy 版本
numpy version: 1.21.2
真诚的期待您的回复
Sincerely, Looking forward to your response! ❤❤❤❤
3. numpy 官方人员的回复
回复我的是 Robert Kern 职位尚不清楚 所属机构是 Enthought(开发numpy 和 scipy的公司) line_profiler 库的开发者,该项目有3.6K个星,该大佬第一次在半个小时内回复了我,由于我是中午发的,所以他在美丽国的半夜十一点给我回复了邮件/(ㄒoㄒ)/~~,美丽国大佬恐怖如斯。

下面的翻译中(括号里的内容不是作者说的话是我的补充)翻译的不好请多见谅
3.1 第一次回复
这并不是argsort函数内容打算做的或者文档里描述的
这里指我说的在处里具有非重复数据中返回位次的功能
他返回的是一索引数组,他是指向(into)x的,如果你按照这个顺序从x中拿数的话你会得到一个有序的数组,如果说把x 排序成sorted_x,对于所有的i in range(len(x))会满足
x[rank[i]] == sorted_x[i],argsort返回的索引,是数据在x中的位置,而不是在sorted_x中的位置。你例子中的出现的关联情况,是在一些小的例子中偶然发生的(我:🤡),但是考虑一个例子[20, 30, 10, 40]
That is not what argsort is intended or documented to do. It returns an array of indices into x such that if you took the values from x in that order, you would get a sorted array. That is, if x were sorted into the array sorted_x, then x[rank[i]] == sorted_x[i] for all i in range(len(x)). The indices in rank are positions in x, not positions in sorted_x. They happen to correspond in this case, but that’s a coincidence that’s somewhat common in these small examples. But consider [20, 30, 10, 40]:
(他在下面的代码中对他提到的例子使用np.argsort()处理,发现虽然没有重复数据但是返回的仍然不正确的位次信息,然后大佬自己写写了一个position()内容和我的不同,但是返回了同样的结果,这里的np.searchsorted()的作用是查找数据在目标数组中的插入位置)
>>> x = np.array([20, 30, 10, 40])
>>> ix = np.argsort(x)
>>> def position(x):
... sorted_x = np.array(x)
... sorted_x.sort()
... return np.searchsorted(sorted_x, x)
...
>>> ip = position(x)
>>> ix
array([2, 0, 1, 3])
>>> ip
array([1, 2, 0, 3])
但也得注意的是:
But also notice:
>>> np.argsort(np.argsort(x))
array([1, 2, 0, 3])
用两次argsort你看,也能返回这个结果(当时我:啊😦(二声),这也行),这取决于你对重复项的处理想达到什么效果,你是想返回重复值在排序之后的数组中第一次出现的索引,还是想返回特定项被排序到的索引。
This double-argsort is what you seem to be looking for, though it depends on what you want from the handling of duplicates (do you return the first index into the sorted array with the same value as in my position() implementation, or do you return the index that particular item was actually sorted to).
不管怎么样,我们可能不打算把这个添加到我们的功能里,以上的两种目的都可以用现有的基础功能直接组合得到。
Either way, we probably aren’t going to add this as its own function. Both options are straightforward combinations of existing primitives.
3.2 第二次回复
在第二天凌晨2点,美丽国刚吃完午饭,我收到了第二次回复
也可以考虑一下使用 scipy.stats.rankdata(),它提供了许多处理重复值的选项
ties 其实实际意思是并列值,但是感觉还是翻译成重复值感觉更符合语境和之前探讨的内容

也就是其实scripy 中 已经实现了这个函数,但是可能并没有太被人们所熟知,以至于大佬第一次回复都没想到可能.
4.返回位序方法总结
以上就得到了四种返回位序的方法
4.1 scipy.stats.rankdata (推荐)
其中功能最强大的那就是scipy.stats 中的rankdata 方法了
import numpy as np
from scipy.stats import rankdata# 创建一个数组
x = np.array([40, 20, 30, 20, 40])# 使用 rankdata 对数组中的元素进行排名,分别使用四种不同的方法
ranks_average = rankdata(x, method='average') # 默认方法,平均排名
# [4.5, 1.5, 3. , 1.5, 4.5]
ranks_min = rankdata(x, method='min') # 最小排名
# [4, 1, 3, 1, 4]
ranks_max = rankdata(x, method='max') # 最大排名
# [5, 2, 3, 2, 5]
ranks_dense = rankdata(x, method='dense') # 密集排名
# [3, 1, 2, 1, 3]
ranks_ordinal = rankdata(x, method='ordinal') # 序数排名
# [4, 1, 3, 2, 5]- 平均排名(average):如果存在相同的元素,它们被赋予其排名的平均值。
- 最小排名(min):并列元素被赋予所有可能排名中的最小值。
- 最大排名(max):并列元素被赋予所有可能排名中的最大值。
- 密集排名(dense):并列元素被赋予相同的排名,且排名之间没有间隔。
- 序数排名(ordinal):每个元素被赋予一个唯一的排名,即使它们的值相同
4.2 double np.argsort()
这是第二种方法,其等效于scipy.stats.rankdata的序数排名模式,代码精简,看起来比较炫酷
import numpy as np
x = np.array([40, 20, 30, 20, 40])
rank = np.argsort(np.argsort(x))+1
print(x)
# [4 1 3 2 5]
4.3 Robert Kern Position
这是第三种,在邮件中Robert Kern回复我的position 函数
等效于scipy.stats.rankdata的最小排名模式,个人认为这个不是非常好的选择,首先他肯定不如scipy.stats.rankdata精简,而且又引入了一个新的知名度可能不是很高的函数np.searchsorted
import numpy as np
x = np.array([40, 20, 30, 20, 40])def position(x):sorted_x = np.array(x)# 排序sorted_x.sort()# 寻找插入位置return np.searchsorted(sorted_x, x)rank = position(x) + 1
print(rank)
# [4 1 3 1 4]
4.4 My Position
最后就是我的了,我写的吧,算法效率必然是最低又占内存运行的又慢,就是代码逻辑可能相对好理解一点(也许)
- My Position Min
等效于scipy.stats.rankdata的最小排名模式
import numpy as np
x = np.array([40, 20, 30, 20, 40])
def position_min(x):x = np.array(x)# 排序arg_x = np.sort(x)# 查找重复元素在排序数组中第一次出现的位置 # np.where() 返回的是元组 np.where()[0] 取元组里包含索引值的列表# np.where()[0][0] 第一次出现的索引 np.where()[0][-1]最后一次rank = [np.where(arg_x == i)[0][0] for i in x]return np.array(rank)rank = position_min(x) + 1
print(rank)
# [4 1 3 1 4]
- My Position Max
等效于scipy.stats.rankdata的最大排名模式
import numpy as np
x = np.array([40, 20, 30, 20, 40])
def position_max(x):x = np.array(x)# 排序arg_x = np.sort(x)# 查找重复元素在排序数组中第一次出现的位置 # np.where() 返回的是元组 np.where()[0] 取元组里包含索引值的列表# np.where()[0][0] 第一次出现的索引 np.where()[0][-1]最后一次rank = [np.where(arg_x == i)[0][-1] for i in x]return np.array(rank)rank = position_max(x) + 1
print(rank)
# [5 2 3 2 5]
结束语
我会专门想办法再去测试一个各个算法的运行效率,然后根据运行时间给出一个最终的结论
相关文章:
np.argsort排序问题(关于位次)-含GitHub上在numpy项目下提问的回复-总结可行方案
np.argsort 与获取位相关问题 位次: 数组中的数据在其排序之后的另一个数组中的位置 [1,0,2,3] 中 0的位次是1 1的位次是2 2的位次是3 3的位次是4 这里先直接给出结论,np.argsort()返回的索引排序与实际位次在确实在某些情况下会出现一致,但后来numpy的开…...

Element中的el-input-number+SpringBoot+mysql
1、编写模板 <el-form ref"form" label-width"100px"><el-form-item label"商品id:"><el-input v-model"id" disabled></el-input></el-form-item><el-form-item label"商品名称&a…...

Jupyter Notebook五分钟基础速通
1 作用 常用于数据分析 2 安装 2.1 Anaconda 通过直接安装Anaconda,会自动安装Jupyter Notebook 2.2 命令行安装 ① 3.x版本 pip3 install --upgrade pip pip3 install jupyter ② 2.x版本 pip install --upgrade pip pip install jupyter 3 启动 cmd窗口下…...
基于SpringBoot的SSM整合案例
项目目录: 数据库表以及表结构 user表结构 user_info表结构 引入依赖 父模块依赖: <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.12.RELEASE</version>…...
[SS]语义分割_转置卷积
转置卷积(Transposed Convolution) 抽丝剥茧,带你理解转置卷积(反卷积) 目录 一、概念 1、定义 2、运算步骤 二、常见参数 一、概念 1、定义 转置卷积(Transposed Convolution)…...

面板小程序命令行工具介绍
Ray 体系提供配套的工程化解决方案。 由于多端构建的一些客观原因,在构建流程的设计上,必须将工程套件安装在项目内。 项目内的依赖至少包含以下内容: {"dependencies": {"ray-js/ray": "latest"},"de…...

DBA技术栈MongoDB: 数据增改删除
该博文主要介绍mongoDB对文档数据的增加、更新、删除操作。 1.插入数据 以下案例演示了插入单个文档、多个文档、指定_id、指定多个索引以及插入大量文档的情况。在实际使用中,根据需求选择适合的插入方式。 案例1:插入单个文档 db.visitor.insert({…...
Xcode查看APP文件目录
一、连接真机到MAC电脑上 二、打开Devices 点击window -> Devices and Simulatores 三、选中设备、选择app 四、选择下载内容 五、查看文件内容 得到的文件 右键显示包内容,获得APP内数据 六、分发证书无法下载 使用分发的证书无法下载文件内容…...
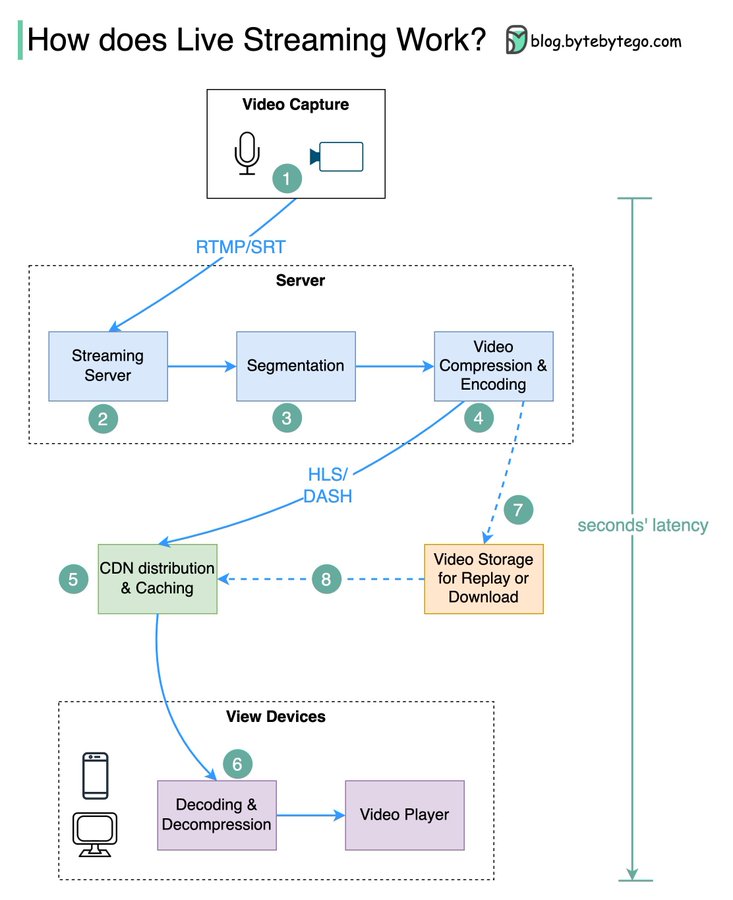
【视频媒体】深入了解直播视频流
深入了解直播视频流🎥 YouTube、TikTok live和Twitch上的直播视频是如何工作的? 直播视频流与常规流媒体不同,因为视频内容通过互联网近乎实时发送,通常只有几秒钟的延迟。 下图解释了实现这一目标背后所发生的事情。 步骤1&…...
【01】mapbox js api加载arcgis切片服务
需求: 第三方的mapbox js api加载arcgis切片服务,同时叠加在天地图上,天地图坐标系web墨卡托。 效果图: 形如这种地址去加载http://zjq2022.gis.com:8080/demo/loadmapboxtdt.html 思路: 需要制作一个和天地图比例…...
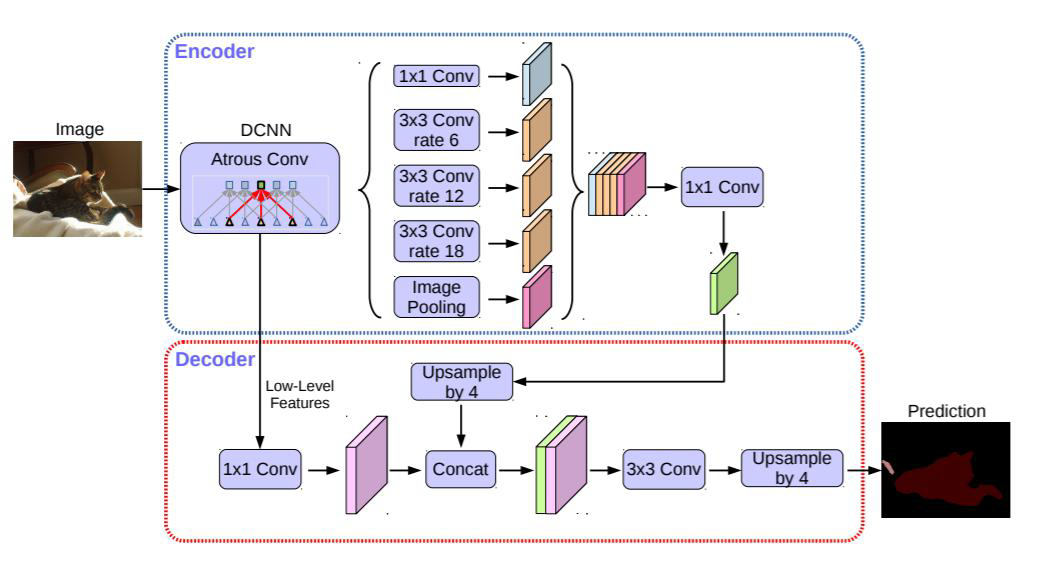
图像分割实战-系列教程15:deeplabV3+ VOC分割实战3-------网络结构1
🍁🍁🍁图像分割实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 deeplab系列算法概述 deeplabV3 VOC分割实战1 deeplabV3 VOC分割实战2 deeplabV3 VOC分割实战3 dee…...
【Docker】安装nacos以及实现负载均衡
🥳🥳Welcome 的Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于Docker的相关操作吧 目录 🥳🥳Welcome 的Huihuis Code World ! !🥳🥳 前言 一.nacos单个部署 1.镜像拉取 …...

如何用数据赋能社媒营销决策?
在数字化时代,越来越多的商家开始意识到数据分析对于改善经营的重要性。 传统决策更多依赖过往经验、商业直觉、他人的思路模板等方法,或者依靠描述性统计、简单的数据分析。在数字时代,则通过精细化数据分析,做出更明智的营销决策…...

初识k8s(概述、原理、安装)
文章目录 概述由来主要功能 K8S架构架构图组件说明ClusterMasterNodekubectl 组件处理流程 K8S概念组成PodPod控制器ReplicationController(副本控制器)ReplicaSet (副本集)DeploymentStatefulSet (有状态副本集&#…...
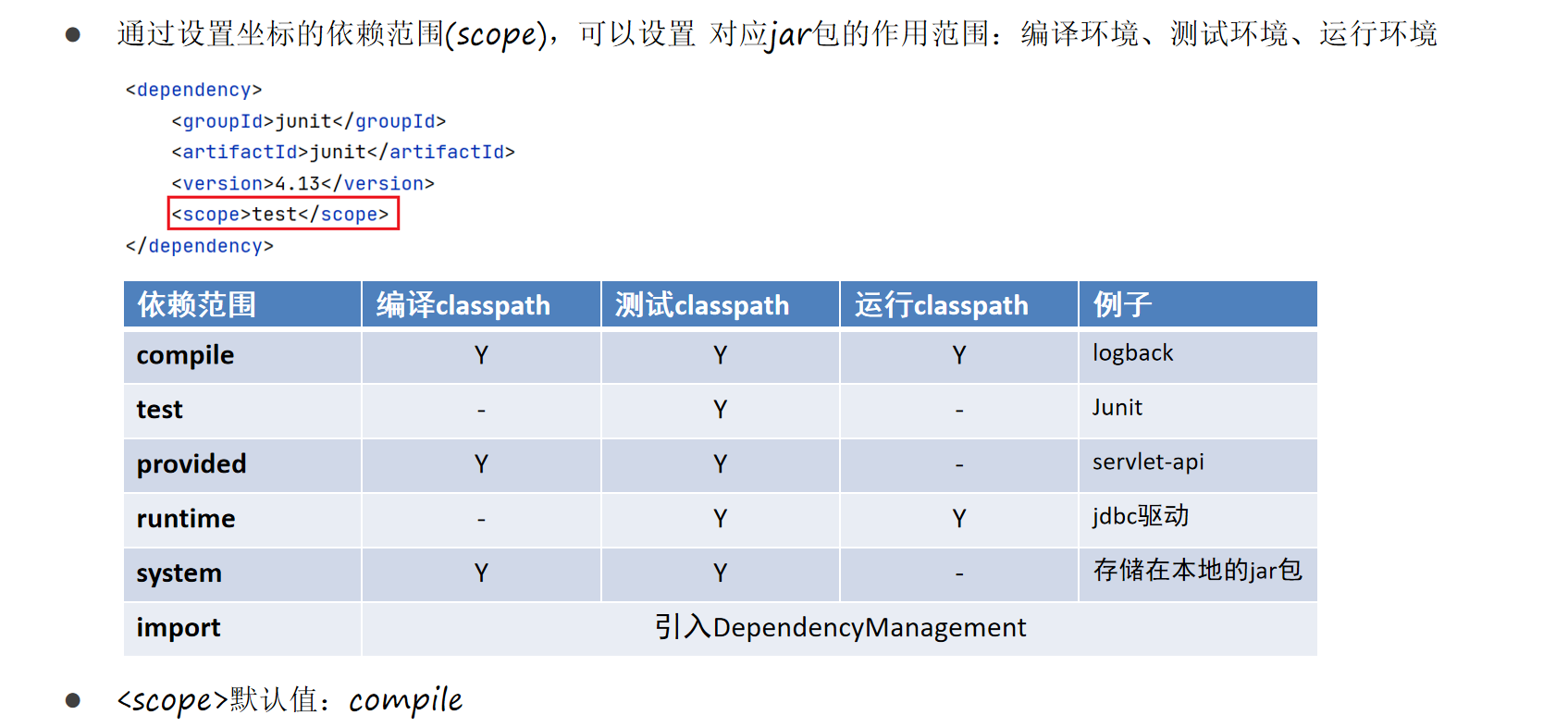
【Java】Maven的基本使用
Maven的基本使用 Maven常用命令 complie:编译clean:清理test:测试package:打包install:安装 mvn complie mvn clean mvn test mvn package mvn installMaven生命周期 IDEA配置Maven Maven坐标 什么是坐标?…...

【RT-DETR有效改进】遥感旋转网络 | LSKNet动态的空间感受野网络(轻量又提点)
前言 大家好,我是Snu77,这里是RT-DETR有效涨点专栏。 本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。 专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持Re…...

【进阶之路】如何提升 Java 编程内力?
如何提升 Java 编程内力? 可能很多初学者在学完 SpringBoot 之后,做了 1-2 个项目之后,不知道该去学习什么了,其实这时候需要去学习的东西还有很多,接下来我会列举一下主要需要从哪些方面来对 Java 编程深入学习&#…...
Git一台电脑 配置多个账号
Git一台电脑 配置多个账号 Git一台电脑 配置多个账号 常用的Git版本管理有 gitee github gitlab codeup ,每个都有独立账号,经常需要在一个电脑上向多个代码仓提交后者更新代码,本文以ssh 方式为例配置 1 对应账号 公私钥生成 建议&#…...
)
2024年华为OD机试真题-素数之积-Java-OD统一考试(C卷)
题目描述: RSA加密算法在网络安全世界中无处不在,它利用了极大整数因数分解的困难度,数据越大,安全系数越高,给定一个32位正整数,请对其进行因数分解,找出是哪两个素数的乘积。 输入描述: 一个正整数num 0 < num <= 2147483647 输出描述: 如果成功找到,以单个空…...
)
汤姆·齐格弗里德《纳什均衡与博弈论》笔记(2)
第三章 纳什均衡——博弈论的基础 冯诺伊曼没有解决的问题 博弈论在其建立初始也显现出了严重的局限性。冯诺伊曼解决了二人零和博弈,但对多人博弈问题仍无法解决。如果只是鲁宾逊克鲁索和星期五玩游戏,博弈论可以很好地被应用,但它无法精确…...

合成孔径雷达干涉测量InSAR数据处理、地形三维重建、形变信息提取、监测等技术应用
合成孔径雷达干涉测量(Interferometric Synthetic Aperture Radar, InSAR)技术作为一种新兴的主动式微波遥感技术,凭借其可以穿过大气层,全天时、全天候获取监测目标的形变信息等特性,已在地表形变监测、DEM生成、滑坡…...

DWC_ether_qos驱动软复位实战:解决网络丢包与DMA死锁
1. 项目概述:从一次诡异的网络丢包说起最近在调试一块基于某款主流SoC的工控板卡时,遇到了一个让人头疼的问题:设备在长时间高负载运行后,网络会间歇性地出现严重丢包,甚至完全断连。重启网络服务能暂时恢复࿰…...
)
别再只用默认模型了!手把手教你用SnowNLP训练专属情感分析模型(附完整代码)
突破SnowNLP默认模型局限:打造高精度领域情感分析系统的实战指南 从"水土不服"到精准预测:为什么你需要自定义情感模型 去年夏天,我们的产品团队在分析用户反馈时遇到了一个诡异现象:明明用户留言中充斥着"卡顿严重…...

别再只调YOLOv8参数了!试试这个DWR注意力模块,让你的小麦病害检测mAP提升5%
突破YOLOv8性能瓶颈:DWR注意力模块在小麦病害检测中的实战应用 当农业遇上人工智能,计算机视觉技术正在彻底改变传统作物病害监测方式。作为目标检测领域的标杆算法,YOLOv8凭借其卓越的实时性能在农业病害检测中广受欢迎。然而,面…...
)
Apple Music断供后歌单全没?别慌!用iTunes导出的XML文件+Excel手动抢救歌单(保姆级图文教程)
Apple Music断供后歌单全没?别慌!用iTunes导出的XML文件Excel手动抢救歌单(保姆级图文教程) 当你发现Apple Music因断供导致精心收藏的歌单全部消失时,那种心情就像突然失去了多年的音乐记忆。别担心,这份…...

终极Python GUI设计器:Pygubu Designer完全指南
终极Python GUI设计器:Pygubu Designer完全指南 【免费下载链接】pygubu-designer A simple GUI designer for the python tkinter module 项目地址: https://gitcode.com/gh_mirrors/py/pygubu-designer 还在为Python GUI开发而烦恼吗?厌倦了手写…...

网络安全十大常见漏洞|原理 + 危害 + 防御,一篇讲透✅
一、弱口令【文末福利】 产生原因 与个人习惯和安全意识相关,为了避免忘记密码,使用一个非常容易记住 的密码,或者是直接采用系统的默认密码等。 危害 通过弱口令,攻击者可以进入后台修改资料,进入金融系统盗取钱财…...
)
蓝桥杯嵌入式备赛:手把手搞定AT24C02 EEPROM读写(附CubeMX配置与常见Bug修复)
蓝桥杯嵌入式竞赛实战:AT24C02 EEPROM高效读写全攻略 1. 赛前准备:理解I2C与EEPROM的核心机制 在蓝桥杯嵌入式竞赛中,AT24C02这类EEPROM器件常被用作非易失性存储解决方案。与常见Flash存储器不同,EEPROM支持字节级擦写…...

STM32F407 UART4串口DMA接收不定长数据与中断发送的实战配置与避坑指南
1. 为什么需要DMAUART组合方案 在嵌入式开发中,串口通信就像快递员送货上门。传统中断方式相当于每送一个包裹(字节)就按一次门铃,快递员(CPU)必须放下手头工作去开门。当数据量大时,这种频繁中…...

SteamAutoCrack终极指南:5步掌握游戏DRM自动移除技术
SteamAutoCrack终极指南:5步掌握游戏DRM自动移除技术 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack 你是否曾为Steam游戏的DRM保护而烦恼?每次运行游戏都需要启…...