【RT-DETR有效改进】遥感旋转网络 | LSKNet动态的空间感受野网络(轻量又提点)
前言
大家好,我是Snu77,这里是RT-DETR有效涨点专栏。
本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。
专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持ResNet32、ResNet101和PPHGNet版本,其中ResNet为RT-DETR官方版本1:1移植过来的,参数量基本保持一致(误差很小很小),不同于ultralytics仓库版本的ResNet官方版本,同时ultralytics仓库的一些参数是和RT-DETR相冲的所以我也是会教大家调好一些参数和代码,真正意义上的跑ultralytics的和RT-DETR官方版本的无区别
一、本文介绍
本文给大家带来的改进内容是LSKNet(Large Kernel Selection, LK Selection),其是一种专为遥感目标检测设计的网络架构,其核心思想是动态调整其大的空间感受野,以更好地捕捉遥感场景中不同对象的范围上下文。实验部分我在一个包含三十多个类别的数据集上进行实验,其中包含大目标检测和小目标检测,mAP的平均涨点幅度在0.04-0.1之间(也有极个别的情况没有涨点),同时官方的版本只提供了一个大版本,我在其基础上提供一个轻量化版本给大家选择,本文会先给大家对比试验的结果,供大家参考,该网络的mAP提高大概在2个点,参数量也有一定程度上的下降可以起到轻量化的作用。

专栏链接:RT-DETR剑指论文专栏,持续复现各种顶会内容——论文收割机RT-DETR
目录
一、本文介绍
二、LSKNet原理
2.1 LSKNet的基本原理
2.2 大型核选择(LK Selection)子块
2.3 前馈网络(FFN)子块
三、LSKNet核心代码
四、手把手教你添加LSKNet机制
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
4.5 修改五
4.6 修改六
4.7 修改七
4.8 修改八
4.9 RT-DETR不能打印计算量问题的解决
4.10 可选修改
五、LSKNet的yaml文件
5.1 yaml文件
5.2 运行文件
5.3 成功训练截图
六、全文总结
二、LSKNet原理

论文地址: 官方论文地址
代码地址: 官方代码地址

2.1 LSKNet的基本原理
LSKNet(Large Selective Kernel Network)是一种专为遥感目标检测设计的网络架构,其核心优势在于能够动态调整其大的空间感受野,以更好地捕捉遥感场景中不同对象的范围上下文。这是第一次在遥感目标检测领域探索大型和选择性核机制。
LSKNet(大型选择性核网络)的基本原理包括以下关键组成部分:
1. 大型核选择(LK Selection)子块:这个子块能够动态地调整网络的感受野,以便根据需要捕获不同尺度的上下文信息。这使得网络能够根据遥感图像中对象的不同尺寸和复杂性调整其处理能力。
2. 前馈网络(FFN)子块:该子块用于通道混合和特征精炼。它由一个完全连接的层、一个深度卷积、一个GELU激活函数以及第二个完全连接的层组成。这些组件一起工作,提高了特征的质量并为分类和检测提供了必要的信息。
这两个子块共同构成LSKNet块,能够提供大范围的上下文信息,同时保持对细节的敏感度,这对于遥感目标检测尤其重要。
下面我将为大家展示四种不同的选择性机制模块的架构比较:

对于LSK模块:
1. 有一个分解步骤,似乎是用来处理大尺寸的卷积核(Large K)。
2. 接着是一个空间选择*步骤,可能用于选择或优化空间信息的特定部分。
这与其他三种模型的架构相比较,显示了LSK模块在处理空间信息方面可能有其独特的方法。具体来说,LSK模块似乎强调了在大尺寸卷积核上进行操作,这可能有助于捕获遥感图像中较大范围的上下文信息,这对于检测图像中的对象特别有用。空间选择步骤可能进一步增强了模型对于输入空间特征的选择能力,从而使其能够更加有效地聚焦于图像的重要部分。
2.2 大型核选择(LK Selection)子块
LSKNet的大型核选择(Large Kernel Selection, LK Selection)子块是其架构的核心组成部分之一。这个子块的功能是根据需要动态调整网络的感受野大小。通过这种方式,LSKNet能够根据遥感图像中不同对象的大小和上下文范围,调整处理这些对象所需的空间信息范围。
大型核选择子块与前馈网络(Feed-forward Network, FFN)子块一起工作。FFN子块用于通道混合和特征细化,它包括一个序列,这个序列由一个全连接层、一个深度卷积、一个GELU激活函数以及第二个全连接层组成。这种设计允许LSKNet块进行特征深度融合和增强,进一步提升了遥感目标检测的性能。
下面我将通过LSK(Large Selective Kernel)模块的概念性插图,展示LSKNet如何通过大型核选择子块和空间选择机制来处理遥感数据,从而使网络能够适应不同对象的长范围上下文需求。
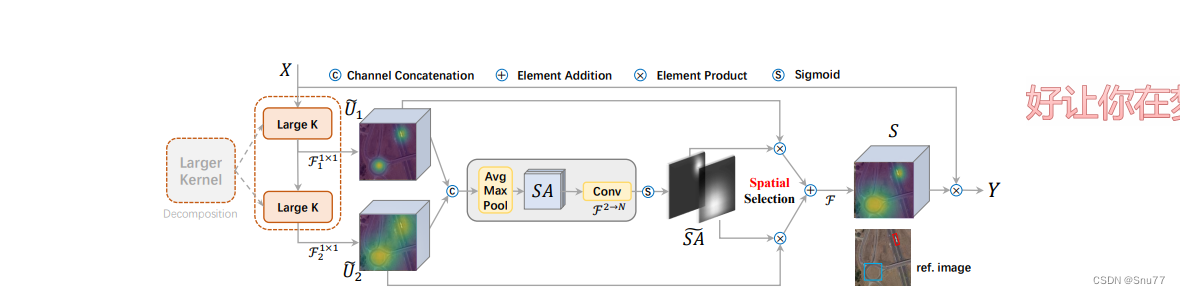
1. Large Kernel Decomposition:原始输入经过大核分解,使用两种不同的大型卷积核(Large K)进行处理,以捕获不同尺度的空间信息。
2. Channel Concatenation:两个不同的卷积输出和
通过通道拼接组合在一起,这样可以在后续步骤中同时利用不同的空间特征。
3. Mixed Pooling:拼接后的特征图经过平均池化和最大池化的组合操作,然后与自注意力(SA)机制一起使用,以进一步强化特征图的关键区域。
4. Convolution and Spatial Selection:通过卷积操作和自注意力(SA)生成新的特征图,然后通过空间选择机制进一步增强对目标区域的关注。
5. Element Product and Sigmoid:使用Sigmoid函数生成一个掩码,然后将这个掩码与特征图
进行元素乘积操作,得到最终的输出特征图
。这一步骤用于加权特征图中更重要的区域,以增强网络对遥感图像中特定对象的检测能力。
整个LSK模块的设计强调了对遥感图像中不同空间尺度和上下文信息的有效捕获,这对于在复杂背景下准确检测小型或密集排布的目标至关重要。通过上述步骤的复合操作,LSK模块能够提升遥感目标检测的性能。
2.3 前馈网络(FFN)子块
LSKNet的前馈网络(Feed-forward Network, FFN)子块用于通道混合和特征精炼。该子块包含以下组成部分:
1. 全连接层:用于特征变换,提供网络额外的学习能力。
2. 深度卷积(depth-wise convolution):用于在通道间独立地应用空间滤波,减少参数量的同时保持效果。
3. GELU激活函数:一种高斯误差线性单元,用于引入非线性,提高模型的表达能力。
4. 第二个全连接层:进一步变换和精炼特征。
这个FFN子块紧随LK Selection子块之后,作用是在保持特征空间信息的同时,增强网络在特征通道上的表示能力。通过这种设计,FFN子块有效地对输入特征进行了深度加工,提升了最终特征的质量,从而有助于提高整个网络在遥感目标检测任务中的性能。
三、LSKNet核心代码
将此代码复制粘贴到''ultralytics/nn/modules''目录下新建一个py文件我这里起名字为LSKNet.py,然后把代码复制粘贴进去即可,使用教程看章节四。
import torch
import torch.nn as nn
from torch.nn.modules.utils import _pair as to_2tuple
from timm.models.layers import DropPath, to_2tuple
from functools import partial
import warningsclass Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Conv2d(in_features, hidden_features, 1)self.dwconv = DWConv(hidden_features)self.act = act_layer()self.fc2 = nn.Conv2d(hidden_features, out_features, 1)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.dwconv(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass LSKblock(nn.Module):def __init__(self, dim):super().__init__()self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)self.conv1 = nn.Conv2d(dim, dim // 2, 1)self.conv2 = nn.Conv2d(dim, dim // 2, 1)self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)self.conv = nn.Conv2d(dim // 2, dim, 1)def forward(self, x):attn1 = self.conv0(x)attn2 = self.conv_spatial(attn1)attn1 = self.conv1(attn1)attn2 = self.conv2(attn2)attn = torch.cat([attn1, attn2], dim=1)avg_attn = torch.mean(attn, dim=1, keepdim=True)max_attn, _ = torch.max(attn, dim=1, keepdim=True)agg = torch.cat([avg_attn, max_attn], dim=1)sig = self.conv_squeeze(agg).sigmoid()attn = attn1 * sig[:, 0, :, :].unsqueeze(1) + attn2 * sig[:, 1, :, :].unsqueeze(1)attn = self.conv(attn)return x * attnclass Attention(nn.Module):def __init__(self, d_model):super().__init__()self.proj_1 = nn.Conv2d(d_model, d_model, 1)self.activation = nn.GELU()self.spatial_gating_unit = LSKblock(d_model)self.proj_2 = nn.Conv2d(d_model, d_model, 1)def forward(self, x):shorcut = x.clone()x = self.proj_1(x)x = self.activation(x)x = self.spatial_gating_unit(x)x = self.proj_2(x)x = x + shorcutreturn xclass Block(nn.Module):def __init__(self, dim, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU, norm_cfg=None):super().__init__()if norm_cfg:self.norm1 = nn.BatchNorm2d(norm_cfg, dim)self.norm2 = nn.BatchNorm2d(norm_cfg, dim)else:self.norm1 = nn.BatchNorm2d(dim)self.norm2 = nn.BatchNorm2d(dim)self.attn = Attention(dim)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)layer_scale_init_value = 1e-2self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)def forward(self, x):x = x + self.drop_path(self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.attn(self.norm1(x)))x = x + self.drop_path(self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x)))return xclass OverlapPatchEmbed(nn.Module):""" Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768, norm_cfg=None):super().__init__()patch_size = to_2tuple(patch_size)self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,padding=(patch_size[0] // 2, patch_size[1] // 2))if norm_cfg:self.norm = nn.BatchNorm2d(norm_cfg, embed_dim)else:self.norm = nn.BatchNorm2d(embed_dim)def forward(self, x):x = self.proj(x)_, _, H, W = x.shapex = self.norm(x)return x, H, Wclass LSKNet(nn.Module):def __init__(self, img_size=224, in_chans=3, dim=None, embed_dims=[64, 128, 256, 512],mlp_ratios=[8, 8, 4, 4], drop_rate=0., drop_path_rate=0., norm_layer=partial(nn.LayerNorm, eps=1e-6),depths=[3, 4, 6, 3], num_stages=4,pretrained=None,init_cfg=None,norm_cfg=None):super().__init__()assert not (init_cfg and pretrained), \'init_cfg and pretrained cannot be set at the same time'if isinstance(pretrained, str):warnings.warn('DeprecationWarning: pretrained is deprecated, ''please use "init_cfg" instead')self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)elif pretrained is not None:raise TypeError('pretrained must be a str or None')self.depths = depthsself.num_stages = num_stagesdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rulecur = 0for i in range(num_stages):patch_embed = OverlapPatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),patch_size=7 if i == 0 else 3,stride=4 if i == 0 else 2,in_chans=in_chans if i == 0 else embed_dims[i - 1],embed_dim=embed_dims[i], norm_cfg=norm_cfg)block = nn.ModuleList([Block(dim=embed_dims[i], mlp_ratio=mlp_ratios[i], drop=drop_rate, drop_path=dpr[cur + j], norm_cfg=norm_cfg)for j in range(depths[i])])norm = norm_layer(embed_dims[i])cur += depths[i]setattr(self, f"patch_embed{i + 1}", patch_embed)setattr(self, f"block{i + 1}", block)setattr(self, f"norm{i + 1}", norm)self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def freeze_patch_emb(self):self.patch_embed1.requires_grad = False@torch.jit.ignoredef no_weight_decay(self):return {'pos_embed1', 'pos_embed2', 'pos_embed3', 'pos_embed4', 'cls_token'} # has pos_embed may be betterdef get_classifier(self):return self.headdef reset_classifier(self, num_classes, global_pool=''):self.num_classes = num_classesself.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):B = x.shape[0]outs = []for i in range(self.num_stages):patch_embed = getattr(self, f"patch_embed{i + 1}")block = getattr(self, f"block{i + 1}")norm = getattr(self, f"norm{i + 1}")x, H, W = patch_embed(x)for blk in block:x = blk(x)x = x.flatten(2).transpose(1, 2)x = norm(x)x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()outs.append(x)return outsdef forward(self, x):x = self.forward_features(x)# x = self.head(x)return xclass DWConv(nn.Module):def __init__(self, dim=768):super(DWConv, self).__init__()self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)def forward(self, x):x = self.dwconv(x)return xdef _conv_filter(state_dict, patch_size=16):""" convert patch embedding weight from manual patchify + linear proj to conv"""out_dict = {}for k, v in state_dict.items():if 'patch_embed.proj.weight' in k:v = v.reshape((v.shape[0], 3, patch_size, patch_size))out_dict[k] = vreturn out_dictdef LSKNET_Tiny():model = LSKNet(depths = [2, 2, 2, 2])return modelif __name__ == '__main__':model = LSKNet()inputs = torch.randn((1, 3, 640, 640))for i in model(inputs):print(i.size())四、手把手教你添加LSKNet机制
下面教大家如何修改该网络结构,主干网络结构的修改步骤比较复杂,我也会将task.py文件上传到CSDN的文件中,大家如果自己修改不正确,可以尝试用我的task.py文件替换你的,然后只需要修改其中的第1、2、3、5步即可。
⭐修改过程中大家一定要仔细⭐
4.1 修改一
首先我门中到如下“ultralytics/nn”的目录,我们在这个目录下在创建一个新的目录,名字为'Addmodules'(此文件之后就用于存放我们的所有改进机制),之后我们在创建的目录内创建一个新的py文件复制粘贴进去 ,可以根据文章改进机制来起,这里大家根据自己的习惯命名即可。

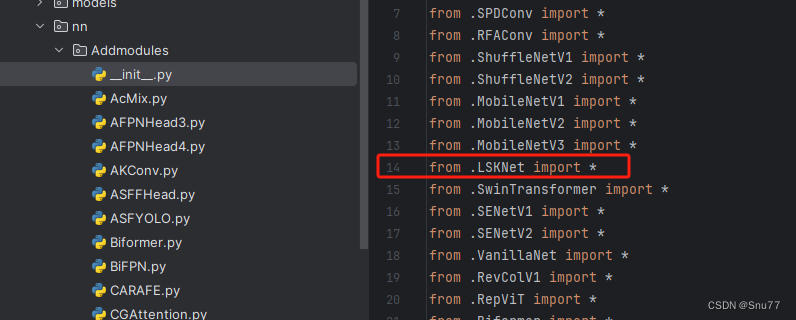
4.2 修改二
第二步我们在我们创建的目录内创建一个新的py文件名字为'__init__.py'(只需要创建一个即可),然后在其内部导入我们本文的改进机制即可,其余代码均为未发大家没有不用理会!。
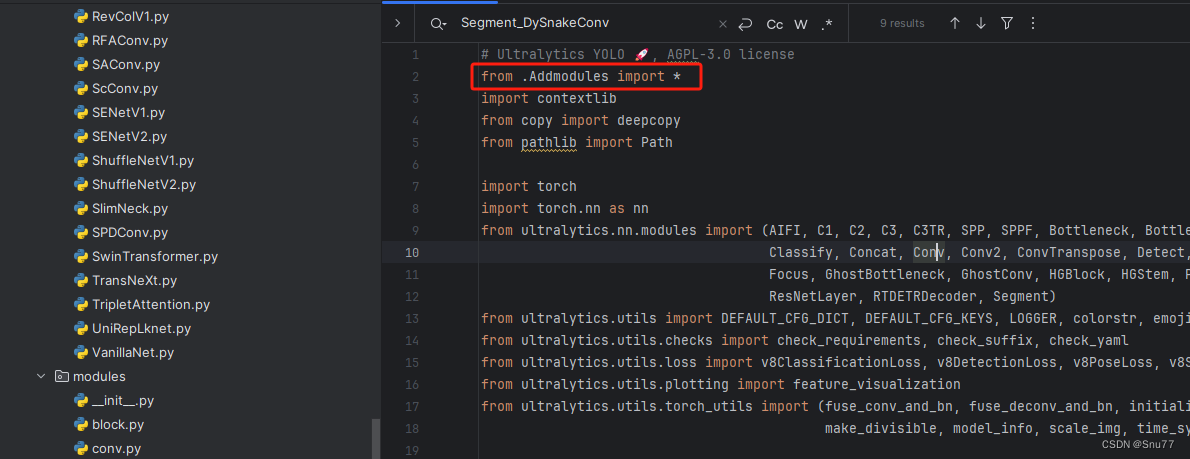
4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'然后在开头导入我们的所有改进机制(如果你用了我多个改进机制,这一步只需要修改一次即可)。
4.4 修改四
添加如下两行代码!!!

4.5 修改五
找到七百多行大概把具体看图片,按照图片来修改就行,添加红框内的部分,注意没有()只是函数名(此处我的文件里已经添加很多了后期都会发出来,大家没有的不用理会即可)。
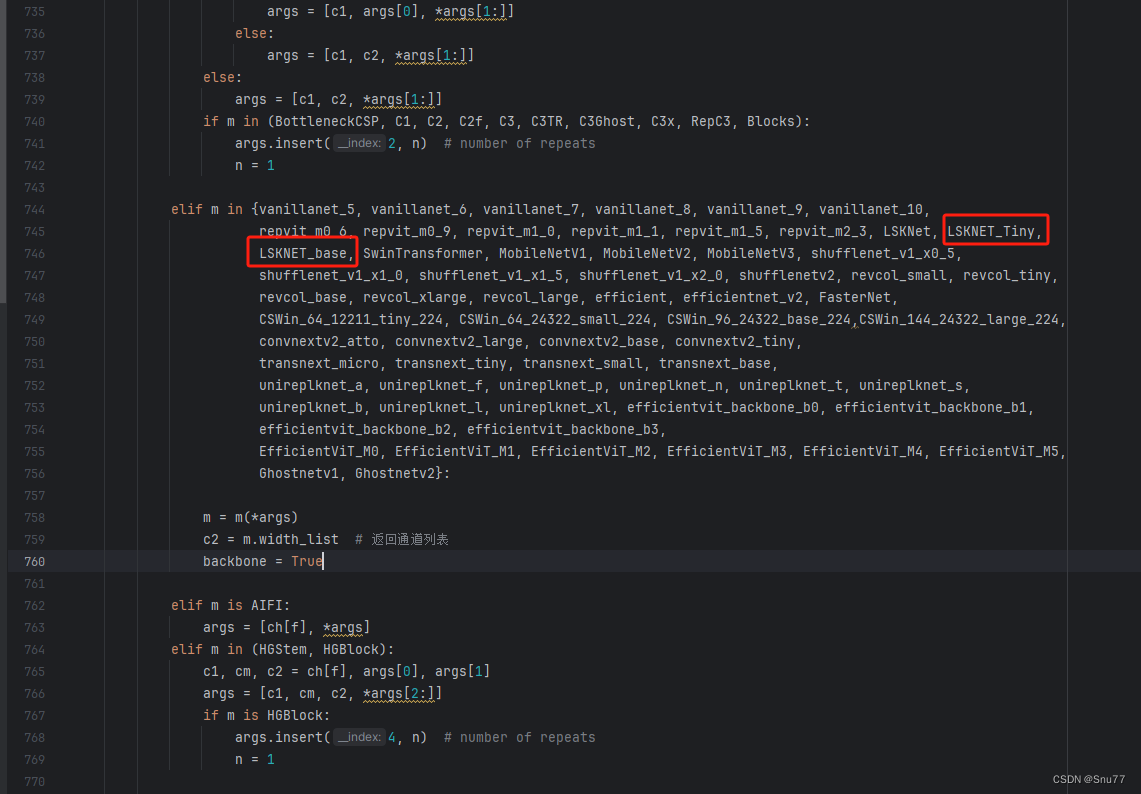
elif m in {自行添加对应的模型即可,下面都是一样的}:m = m(*args)c2 = m.width_list # 返回通道列表backbone = True4.6 修改六
用下面的代码替换红框内的内容。
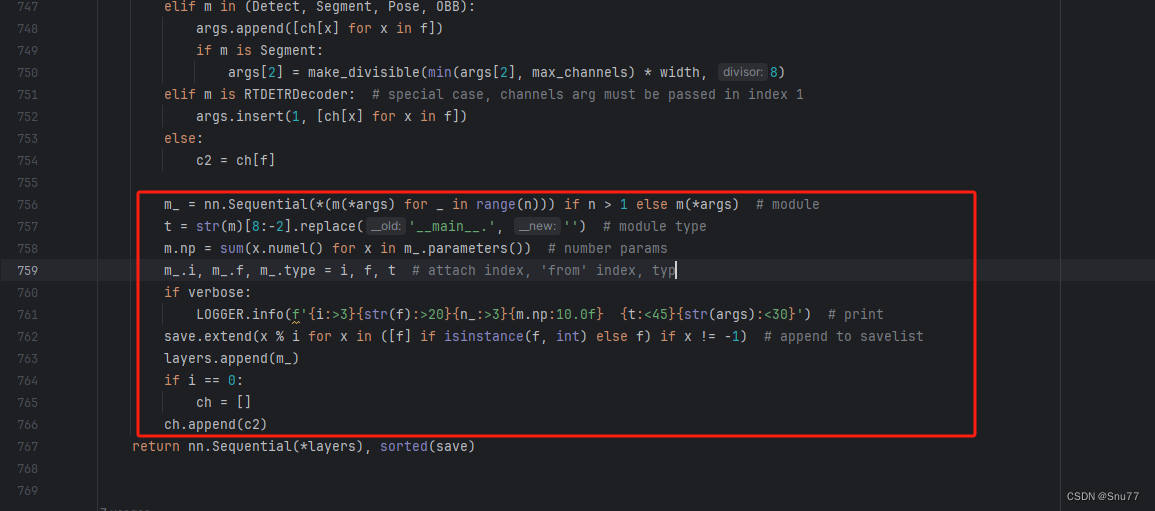
if isinstance(c2, list):m_ = mm_.backbone = True
else:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type
if verbose:LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
save.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:ch = []
if isinstance(c2, list):ch.extend(c2)if len(c2) != 5:ch.insert(0, 0)
else:ch.append(c2)4.7 修改七
修改七这里非常要注意,不是文件开头YOLOv8的那predict,是400+行的RTDETR的predict!!!初始模型如下,用我给的代码替换即可!!!

代码如下->
def predict(self, x, profile=False, visualize=False, batch=None, augment=False, embed=None):"""Perform a forward pass through the model.Args:x (torch.Tensor): The input tensor.profile (bool, optional): If True, profile the computation time for each layer. Defaults to False.visualize (bool, optional): If True, save feature maps for visualization. Defaults to False.batch (dict, optional): Ground truth data for evaluation. Defaults to None.augment (bool, optional): If True, perform data augmentation during inference. Defaults to False.embed (list, optional): A list of feature vectors/embeddings to return.Returns:(torch.Tensor): Model's output tensor."""y, dt, embeddings = [], [], [] # outputsfor m in self.model[:-1]: # except the head partif m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)if len(x) != 5: # 0 - 5x.insert(0, None)for index, i in enumerate(x):if index in self.save:y.append(i)else:y.append(None)x = x[-1] # 最后一个输出传给下一层else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)if embed and m.i in embed:embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flattenif m.i == max(embed):return torch.unbind(torch.cat(embeddings, 1), dim=0)head = self.model[-1]x = head([y[j] for j in head.f], batch) # head inferencereturn x4.8 修改八
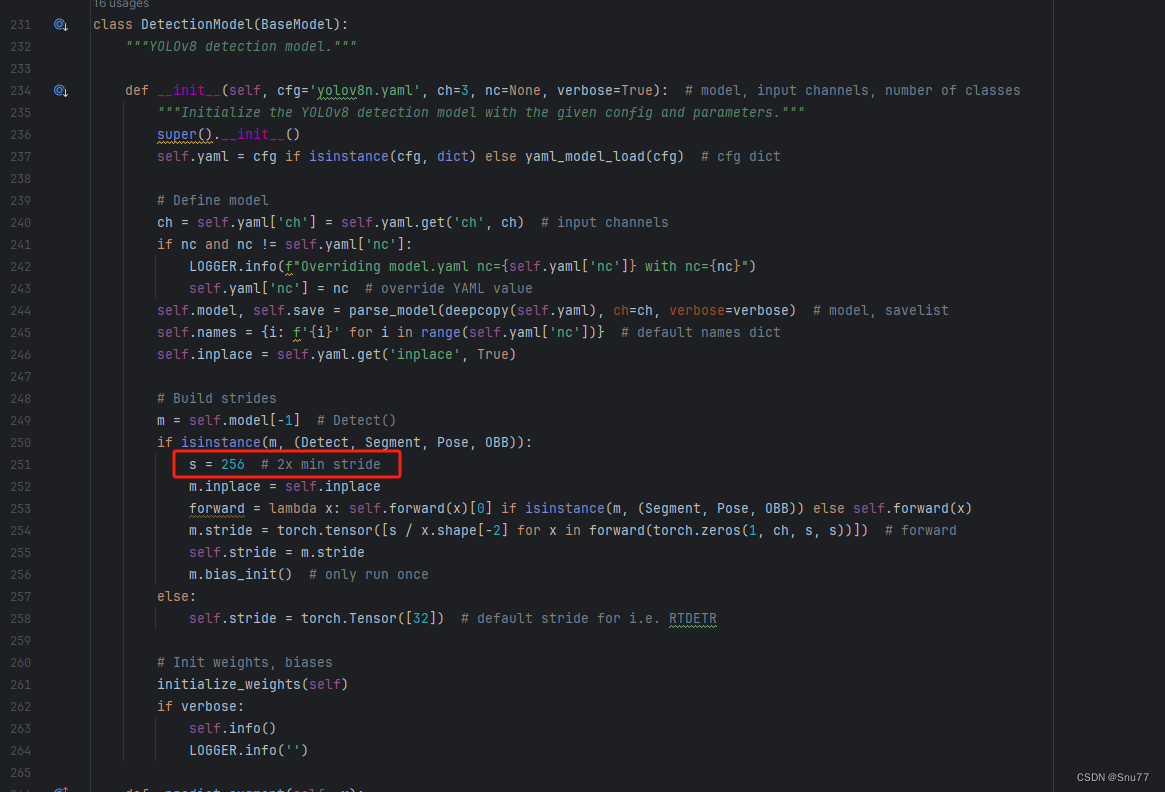
我们将下面的s用640替换即可,这一步也是部分的主干可以不修改,但有的不修改就会报错,所以我们还是修改一下。
4.9 RT-DETR不能打印计算量问题的解决
计算的GFLOPs计算异常不打印,所以需要额外修改一处, 我们找到如下文件'ultralytics/utils/torch_utils.py'文件内有如下的代码按照如下的图片进行修改,大家看好函数就行,其中红框的640可能和你的不一样, 然后用我给的代码替换掉整个代码即可。
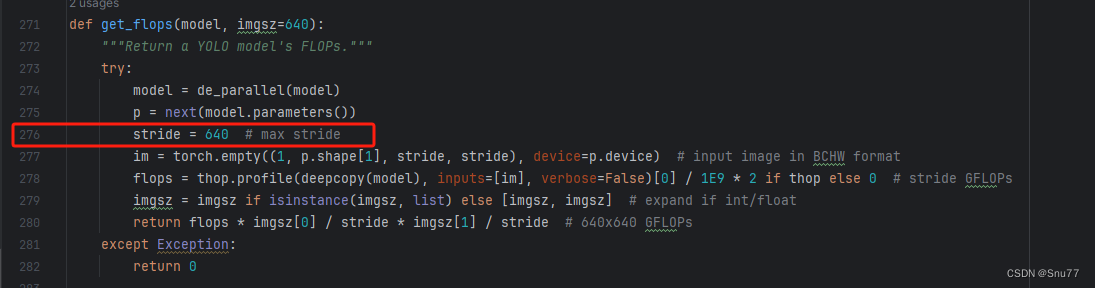
def get_flops(model, imgsz=640):"""Return a YOLO model's FLOPs."""try:model = de_parallel(model)p = next(model.parameters())# stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stridestride = 640im = torch.empty((1, 3, stride, stride), device=p.device) # input image in BCHW formatflops = thop.profile(deepcopy(model), inputs=[im], verbose=False)[0] / 1E9 * 2 if thop else 0 # stride GFLOPsimgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/floatreturn flops * imgsz[0] / stride * imgsz[1] / stride # 640x640 GFLOPsexcept Exception:return 0
4.10 可选修改
有些读者的数据集部分图片比较特殊,在验证的时候会导致形状不匹配的报错,如果大家在验证的时候报错形状不匹配的错误可以固定验证集的图片尺寸,方法如下 ->
找到下面这个文件ultralytics/models/yolo/detect/train.py然后其中有一个类是DetectionTrainer class中的build_dataset函数中的一个参数rect=mode == 'val'改为rect=False

五、LSKNet的yaml文件
5.1 yaml文件
大家复制下面的yaml文件,然后通过我给大家的运行代码运行即可,RT-DETR的调参部分需要后面的文章给大家讲,现在目前免费给大家看这一部分不开放。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'# [depth, width, max_channels]l: [1.00, 1.00, 1024]backbone:# [from, repeats, module, args]- [-1, 1, LSKNET_Tiny, []] # 4head:- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 5 input_proj.2- [-1, 1, AIFI, [1024, 8]] # 6- [-1, 1, Conv, [256, 1, 1]] # 7, Y5, lateral_convs.0- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 8- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 9 input_proj.1- [[-2, -1], 1, Concat, [1]] # 10- [-1, 3, RepC3, [256, 0.5]] # 11, fpn_blocks.0- [-1, 1, Conv, [256, 1, 1]] # 12, Y4, lateral_convs.1- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 13- [2, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.0- [[-2, -1], 1, Concat, [1]] # 15 cat backbone P4- [-1, 3, RepC3, [256, 0.5]] # X3 (16), fpn_blocks.1- [-1, 1, Conv, [256, 3, 2]] # 17, downsample_convs.0- [[-1, 12], 1, Concat, [1]] # 18 cat Y4- [-1, 3, RepC3, [256, 0.5]] # F4 (19), pan_blocks.0- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.1- [[-1, 7], 1, Concat, [1]] # 21 cat Y5- [-1, 3, RepC3, [256, 0.5]] # F5 (22), pan_blocks.1- [[16, 19, 22], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 3]] # Detect(P3, P4, P5)
5.2 运行文件
大家可以创建一个train.py文件将下面的代码粘贴进去然后替换你的文件运行即可开始训练。
import warnings
from ultralytics import RTDETR
warnings.filterwarnings('ignore')if __name__ == '__main__':model = RTDETR('替换你想要运行的yaml文件')# model.load('') # 可以加载你的版本预训练权重model.train(data=r'替换你的数据集地址即可',cache=False,imgsz=640,epochs=72,batch=4,workers=0,device='0',project='runs/RT-DETR-train',name='exp',# amp=True)5.3 成功训练截图
下面是成功运行的截图(确保我的改进机制是可用的),已经完成了有1个epochs的训练,图片太大截不全第2个epochs了。

六、全文总结
从今天开始正式开始更新RT-DETR剑指论文专栏,本专栏的内容会迅速铺开,在短期呢大量更新,价格也会乘阶梯性上涨,所以想要和我一起学习RT-DETR改进,可以在前期直接关注,本文专栏旨在打造全网最好的RT-DETR专栏为想要发论文的家进行服务。
专栏链接:RT-DETR剑指论文专栏,持续复现各种顶会内容——论文收割机RT-DETR

相关文章:
【RT-DETR有效改进】遥感旋转网络 | LSKNet动态的空间感受野网络(轻量又提点)
前言 大家好,我是Snu77,这里是RT-DETR有效涨点专栏。 本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。 专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持Re…...

【进阶之路】如何提升 Java 编程内力?
如何提升 Java 编程内力? 可能很多初学者在学完 SpringBoot 之后,做了 1-2 个项目之后,不知道该去学习什么了,其实这时候需要去学习的东西还有很多,接下来我会列举一下主要需要从哪些方面来对 Java 编程深入学习&#…...
Git一台电脑 配置多个账号
Git一台电脑 配置多个账号 Git一台电脑 配置多个账号 常用的Git版本管理有 gitee github gitlab codeup ,每个都有独立账号,经常需要在一个电脑上向多个代码仓提交后者更新代码,本文以ssh 方式为例配置 1 对应账号 公私钥生成 建议&#…...
)
2024年华为OD机试真题-素数之积-Java-OD统一考试(C卷)
题目描述: RSA加密算法在网络安全世界中无处不在,它利用了极大整数因数分解的困难度,数据越大,安全系数越高,给定一个32位正整数,请对其进行因数分解,找出是哪两个素数的乘积。 输入描述: 一个正整数num 0 < num <= 2147483647 输出描述: 如果成功找到,以单个空…...
)
汤姆·齐格弗里德《纳什均衡与博弈论》笔记(2)
第三章 纳什均衡——博弈论的基础 冯诺伊曼没有解决的问题 博弈论在其建立初始也显现出了严重的局限性。冯诺伊曼解决了二人零和博弈,但对多人博弈问题仍无法解决。如果只是鲁宾逊克鲁索和星期五玩游戏,博弈论可以很好地被应用,但它无法精确…...
)
QT上位机开发(动态数据采集与监控)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】 上位机开发中,有一种类型的应用软件很特殊,它几乎没有什么交互操作,主要的工作就是检测和显示。如果说在此基础上有什么扩展的话,可能就是安全监控和报警。所以,这个上位机软件…...

vue2 -- 截图工具html2canvas
文章目录 🍉需求描述🍉基础功能实现🍉下载另存为本地图片功能🍉需求描述 可以将网页中的指定元素或整个页面截取为图片,以便保存或分享。 🍉基础功能实现 在 Vue 中使用 html2canvas 实现 1:安装 html2canvas 库。你可以使用 npm 安装,命令如下: npm install …...
-不战而屈人之兵,上兵伐谋,韩信之死)
笔记-孙子兵法-第三篇-谋攻(1)-不战而屈人之兵,上兵伐谋,韩信之死
笔记-From 《华杉讲透孙子兵法》和《兵以诈立,我读孙子》 第三篇-谋攻(1)不战而屈人之兵 《孙子兵法》第一篇讲计,第二篇讲野战,第三篇就讲攻城。 《孙子》尚谋,认为最好是“不战而屈人之兵”࿰…...
kafka参数配置参考和优化建议 —— 筑梦之路
对于Kafka的优化,可以从以下几个方面进行思考和优化: 硬件优化:使用高性能的硬件设备,包括高速磁盘、大内存和高性能网络设备,以提高Kafka集群的整体性能。 配置优化:调整Kafka的配置参数,包括…...
如何本地搭建Splunk Enterprise数据平台并实现任意浏览器公网访问
文章目录 前言1. 搭建Splunk Enterprise2. windows 安装 cpolar3. 创建Splunk Enterprise公网访问地址4. 远程访问Splunk Enterprise服务5. 固定远程地址 前言 本文主要介绍如何简单几步,结合cpolar内网穿透工具实现随时随地在任意浏览器,远程访问在本地…...
FlinkAPI开发之状态管理
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048 Flink中的状态 概述 有状态的算子 状态的分类 托管状态(Managed State)和原始状态&…...

initdb: command not found【PostgreSQL】
如果您遇到 “initdb: command not found” 错误,说明 initdb 命令未找到,该命令用于初始化新的 PostgreSQL 数据库群集。这通常是因为 PostgreSQL 相关的工具未正确安装或者安装路径不在系统的 PATH 变量中。 以下是解决这个问题的一些建议:…...
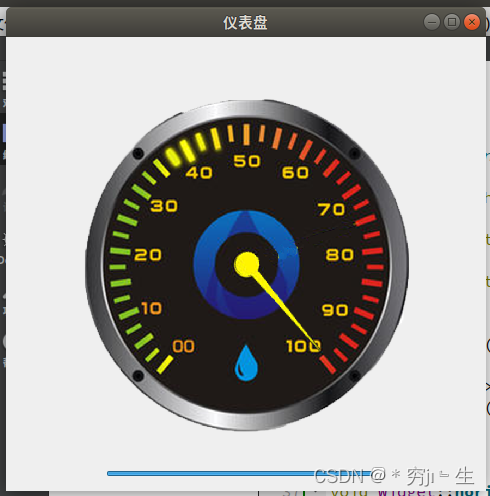
QT第六天
要求:使用QT绘图,完成仪表盘绘制,如下图。 素材 运行效果: 代码: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QPainter> #include <QPen>QT_BEGIN_NAMESPACE name…...

linux 安装 grafana
Ubuntu 和 Debian(64 位)SHA256: e551434e9e3e585633f7b56a33d8f49cda138d92ad69c2c29dcec2c3ede84607 sudo apt-get install -y adduser libfontconfig1 muslwget https://dl.grafana.com/enterprise/release/grafana-enterprise_10.2.3_amd64.debsudo dpkg -i gra…...
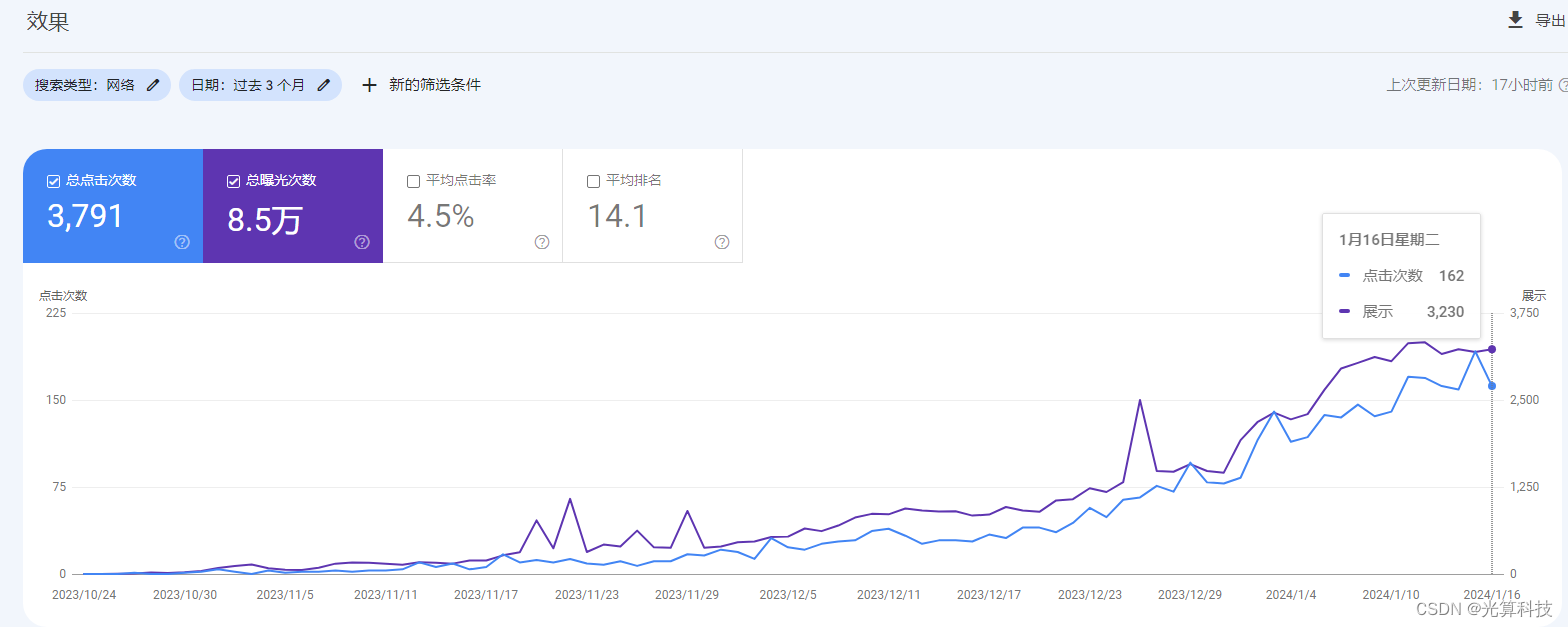
“GPC爬虫池有用吗?
作为光算科技的独有技术,在深入研究谷歌爬虫推出的一种吸引谷歌爬虫的手段 要知道GPC爬虫池是否有用,就要知道谷歌爬虫这一概念,谷歌作为一个搜索引擎,里面有成百上千亿个网站,对于里面的网站内容,自然不可…...

Kotlin协程的JVM实现源码分析(下)
协程 根据 是否保存切换 调用栈 ,分为: 有栈协程(stackful coroutine)无栈协程(stackless coroutine) 在代码上的区别是:是否可在普通函数里调用,并暂停其执行。 Kotlin协程&…...

js实现九九乘法表
效果图 代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><script type"text/javascript">// 输出乘法口诀表// document.write () 空格 " " 换行…...
HarmonyOS鸿蒙应用开发(三、轻量级配置存储dataPreferences)
在应用开发中存储一些配置是很常见的需求。在android中有SharedPreferences,一个轻量级的存储类,用来保存应用的一些常用配置。在HarmonyOS鸿蒙应用开发中,实现类似功能的也叫首选项,dataPreferences。 相关概念 ohos.data.prefe…...
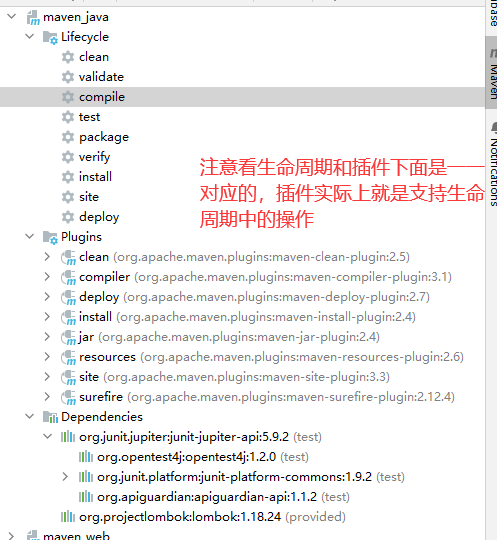
基于 IDEA 进行 Maven 工程构建
1. 构建概念和构建过程 项目构建是指将源代码、依赖库和资源文件等转换成可执行或可部署的应用程序的过程,在这个过程中包括编译源代码、链接依赖库、打包和部署等多个步骤。 项目构建是软件开发过程中至关重要的一部分,它能够大大提高软件开发效率&am…...

牛客周赛 Round 17 解题报告 | 珂学家 | 枚举贪心 + 二分最短路
前言 整体评价 其实T3最有意思, T4很典,是一道二分最短路径经典套路。 T3 如果尝试 增量差值最小 的最大梯度去贪心的话,会失败,需要切换思路。 珂朵莉 牛客周赛专栏 珂朵莉 牛客小白月赛专栏 A. 游游的正方形披萨 如果横竖差…...

量子计算安全:NISQ时代的串扰攻击与防御策略
1. 量子计算安全背景与挑战在NISQ(Noisy Intermediate-Scale Quantum)时代,量子计算机面临着两个核心矛盾:一方面,硬件资源极度稀缺,单个量子程序往往无法充分利用全部量子比特;另一方面&#x…...

如何新建自己的应用
建议步骤如下。 1 创建 WPF 项目 项目文件至少包含: <TargetFramework>net7.0-windows</TargetFramework> <UseWPF>true</UseWPF>2 引用基础库 至少引用: HeBianGu.Base.WpfBaseHeBianGu.General.WpfControlLib 根据需要再…...

告别RGB控制混乱:用ChromaControl打造统一灯光生态
告别RGB控制混乱:用ChromaControl打造统一灯光生态 【免费下载链接】ChromaControl 3rd party device lighting support for Razer Synapse. 项目地址: https://gitcode.com/gh_mirrors/ch/ChromaControl 你是否曾经面对桌上五颜六色的RGB设备感到困惑&#…...
:助你轻松掌握办公自动化利器)
Excel VBA编程实例(150例):助你轻松掌握办公自动化利器
Excel VBA编程实例(150例):助你轻松掌握办公自动化利器 【下载地址】ExcelVBA编程实例150例资源下载 本仓库提供了一个名为“Excel VBA编程实例(150例)”的资源文件下载。该资源文件包含了150个Excel VBA编程实例,旨在帮助用户通过实际案例学习和掌握Exc…...

从决策树到XGBoost:核心原理、目标函数与工程优化全解析
1. 从“头发长短”到“预测房价”:决策树的灵魂与回归树的诞生很多朋友第一次接触XGBoost,或者更广义的树模型时,都会被一堆公式和术语劝退。什么信息增益、基尼系数、正则项、二阶泰勒展开……看几篇博客,感觉每篇都在自说自话&a…...

从Vue源码的preinstall钩子看团队包管理器规范:npx only-allow pnpm的工程实践
1. 为什么需要统一包管理器 最近在查看Vue源码时,发现package.json里有个有趣的配置:"preinstall": "npx only-allow pnpm"。这行看似简单的命令,背后隐藏着团队协作中一个非常重要的问题——包管理器的统一性。 想象一下…...

Bilibili视频下载器:跨平台高效离线下载方案
Bilibili视频下载器:跨平台高效离线下载方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibil…...

AI 科技日报-2026年5月19日
AI 科技日报 | 2026年5月19日 今日AI领域八大要闻速递 1. 京东宣布AI研发投入增长超200%,"618"全面智能化 京东集团技术委员会主席曹鹏在"618"启动发布会上透露,今年京东体系AI相关研发投入增长将超200%,AI将首次全场…...

2025届最火的十大降重复率平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 知网所具备的降AI技术,目的在于使论文里人工智能生成部分的内容重复率得以降低&…...

OpenRGB终极指南:如何用开源软件统一管理所有RGB设备,告别多软件混乱
OpenRGB终极指南:如何用开源软件统一管理所有RGB设备,告别多软件混乱 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcPr…...