kafka消费相关问题(GPT回答版本)
kafka消费相关问题(GPT回答版本)
在Java中,要避免重复消费Kafka消息,可以使用以下方法
1. 使用消费者组:
在设置Kafka消费者时,可以指定一个消费者组。一个消费者组中可以有多个消费者实例,每个实例只会消费到消息的其中一部分。当一条消息被某个消费者实例处理后,其他消费者实例就不会再消费到相同的消息。这种方式可以避免同一个消息被多个消费者重复处理。
2. 提交消费位移:
消费者在消费消息的同时,可以手动提交消费位移(offset)。消费位移表示消费者已经处理到的消息位置。通过手动提交位移,消费者可以在处理完一条消息后,立即提交位移,确保消息被成功消费。当消费者重启后,它可以根据上次提交的位移继续消费,从而避免重复消费。
3. 设置幂等性:
在订单系统中,幂等性是一个重要的概念。当同一个消息被重复消费时,保证系统行为的一致性非常重要。可以通过在订单系统中实现幂等性逻辑,来避免同一个订单被多次处理。例如,可以使用唯一订单号作为判定重复的依据,在处理订单前先检查订单号是否已经存在,如果存在则直接返回成功。
4. 使用分区键:
Kafka消息被分为多个分区,每个分区都有一个唯一的分区键。可以在生产者端设置合适的分区键,将相关的订单消息发送到同一个分区。这样,同一个订单的消息总是会被发送到同一个分区中,保证了消息的顺序性。消费者只需要消费特定的分区即可,避免重复消费。
通过以上方法,可以有效地避免重复消费Kafka消息,确保订单系统的消息处理准确性和可靠性。
对应的demo
1. 使用消费者组:
import org.apache.kafka.clients.consumer.*;
import java.util.*;public class KafkaConsumerDemo {private static final String TOPIC = "order_topic";private static final String GROUP_ID = "order_consumer_group";public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", GROUP_ID);props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList(TOPIC));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理接收到的消息System.out.println("Received message: " + record.value());}}}
}
2. 提交消费位移:
import org.apache.kafka.clients.consumer.*;
import java.util.*;public class KafkaConsumerDemo {private static final String TOPIC = "order_topic";public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "order_consumer_group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList(TOPIC));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理接收到的消息System.out.println("Received message: " + record.value());// 手动提交位移consumer.commitSync();}}}
}
3. 设置幂等性:
import org.apache.kafka.clients.consumer.*;
import java.util.*;public class KafkaConsumerDemo {private static final String TOPIC = "order_topic";public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "order_consumer_group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList(TOPIC));Set<String> processedOrders = new HashSet<>(); // 用于存储已经处理的订单号while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理接收到的消息String order = record.value();if (!processedOrders.contains(order)) {System.out.println("Processing order: " + order);// 在此处实现订单处理逻辑processedOrders.add(order); // 将已处理的订单号添加到集合中}}}}
}
4. 使用分区键:
import org.apache.kafka.clients.consumer.*;
import java.util.*;public class KafkaConsumerDemo {private static final String TOPIC = "order_topic";public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "order_consumer_group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.assign(Arrays.asList(new TopicPartition(TOPIC, 0))); // 消费指定分区while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理接收到的消息System.out.println("Received message from partition " + record.partition() + ": " + record.value());}}}
}
这些示例代码展示了如何在Java中使用Kafka来处理订单系统中的消息,并防止重复消费。
在订单系统中,为了避免重复消费 Kafka 消息并保持幂等性,通常需要在消费端做一些特殊的处理。以下是一个简单的 Java 示例,展示如何实现幂等性和避免重复消费:
假设订单系统中有一个主题(topic)叫做 “orders”,用于接收订单消息。在这个例子中,我们使用数据库来记录已经处理过的订单,并通过订单号来保持幂等性。
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;public class OrderConsumer {// 模拟数据库,用于记录已处理的订单号private static Set<String> processedOrders = ConcurrentHashMap.newKeySet();public static void main(String[] args) {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "your_kafka_bootstrap_servers");props.put(ConsumerConfig.GROUP_ID_CONFIG, "order-consumer-group");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // 关闭自动提交props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");Consumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList("orders"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));// 处理订单消息records.forEach(record -> {String orderId = record.key();String orderData = record.value();// 检查订单是否已经处理过if (!processedOrders.contains(orderId)) {// 在这里添加业务逻辑,处理订单消息// 记录已处理的订单号processedOrders.add(orderId);// 手动提交偏移量consumer.commitSync();} else {// 订单已处理过,可能是重复消息System.out.println("Order " + orderId + " has already been processed.");}});}} finally {consumer.close();}}
}
在这个示例中,processedOrders 是一个用于记录已处理订单号的集合。在处理每条消息之前,我们先检查订单是否已经在集合中,如果是,则认为这是一条重复消息,不再进行处理。否则,我们执行业务逻辑,并将订单号添加到已处理集合中。
请注意,这只是一个简单的示例,实际中可能需要更复杂的幂等性保证措施,具体要根据业务逻辑和系统架构来进行设计。
kafka重复发送消息
Kafka本身是一个分布式消息系统,而消息的重复发送通常是由于网络问题、生产者重试机制或者消费者处理失败引起的。以下是可能导致消息重复发送的一些情况以及相应的解决方法:
-
网络问题:
- 情况: 网络抖动、分区领导者切换等情况可能导致生产者在发送消息时出现网络错误。
- 解决方法: 在生产者端可以通过配置适当的重试机制,确保在网络问题得到解决后可以成功发送消息。此外,Kafka自身也有一些配置可以调整,例如
retries参数,控制生产者重试次数。
-
生产者确认机制问题:
- 情况: 如果生产者在发送消息后没有收到确认(acknowledgment),可能会触发重试机制,导致消息被重复发送。
- 解决方法: 配置生产者的
acks参数来调整确认机制。设置为"all"表示等待所有分区的确认,确保消息已经成功写入所有分区后才返回。
-
消费者处理失败:
- 情况: 消费者在处理消息时发生错误,可能触发消息重复消费。
- 解决方法: 在消费者端,可以通过记录已经处理过的消息的偏移量(offset)来避免重复消费。Kafka本身也提供了自动管理偏移量的功能,确保消息被消费后会更新偏移量。
-
Exactly-Once语义:
- 情况: Kafka提供的默认语义是至少一次(at-least-once)语义,这可能导致消息在发生重试时被重复发送。
- 解决方法: 如果确保消息不会被重复发送对你的应用非常关键,可以考虑使用Kafka事务或幂等性来实现Exactly-Once语义。这需要生产者和消费者的一些特殊配置和操作。
总体来说,确保Kafka集群的配置合理,生产者和消费者的配置符合业务需求,可以最大程度地避免消息重复发送和消费的问题。在设计时,也要考虑系统的幂等性,以最大程度地减少因重试而引起的问题。
下面我将为上述可能导致消息重复发送的情况分别提供一个简单的解决方案的示例:
1. 网络问题导致的消息重复发送:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;public class ProducerWithRetry {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "your_kafka_bootstrap_servers");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("acks", "all");props.put("retries", 3); // 设置重试次数Producer<String, String> producer = new KafkaProducer<>(props);try {// 发送消息ProducerRecord<String, String> record = new ProducerRecord<>("your_topic", "key", "value");producer.send(record);} catch (Exception e) {e.printStackTrace();// 处理发送失败的情况} finally {producer.close();}}
}
2. 生产者确认机制问题:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;public class ProducerWithAck {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "your_kafka_bootstrap_servers");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("acks", "all"); // 设置为"all"表示等待所有分区的确认Producer<String, String> producer = new KafkaProducer<>(props);try {// 发送消息ProducerRecord<String, String> record = new ProducerRecord<>("your_topic", "key", "value");producer.send(record);} catch (Exception e) {e.printStackTrace();// 处理发送失败的情况} finally {producer.close();}}
}
3. 消费者处理失败:
消费者的解决方案主要在于记录已经处理的消息的偏移量,并确保消费者的提交偏移量的操作在消息处理后执行。这部分通常需要在消费者的代码中实现。
4. Exactly-Once语义:
实现Exactly-Once语义通常需要涉及Kafka事务或幂等性的配置和操作,这可能会更为复杂。需要确保生产者和消费者的配置和代码逻辑符合Exactly-Once的要求。
相关文章:
)
kafka消费相关问题(GPT回答版本)
kafka消费相关问题(GPT回答版本) 在Java中,要避免重复消费Kafka消息,可以使用以下方法 1. 使用消费者组: 在设置Kafka消费者时,可以指定一个消费者组。一个消费者组中可以有多个消费者实例,每…...
【C++】string的基本使用二
我们接着上一篇的迭代器说起,迭代器不只有正向的,还有反向的,就是我们下边的这两个 它的迭代器类型也是不同的 rbegin就是末尾,rend就是开头,这样我们想遍历一个string对象的话就可以这样做 int main() {string s1(…...
MATLAB解决考研数学一题型(上)
闲来无事,情感问题和考研结束后的戒断反应比较严重,最近没有什么写博文的动力,抽空来整理一下考研初试前一直想做的工作——整理一下MATLAB解决数学一各题型的命令~ 本贴的目录遵循同济版的高数目录~ 目录 一.函数与极限 1.计算双侧极限 2…...

Vue以弹窗形式实现导入功能
目录 前言正文 前言 由于个人工作原因,偏全栈,对于前端的总结还有些初出茅庐,后续会进行规整化的总结 对应的前端框架由:【vue】avue-crud表单属性配置(表格以及列) 最终实现的表单样式如下:…...

分布式锁原理及实现
目录 一、锁的使用场景 二、如何实现控制? 三、单台服务器使用锁的场景 四、分布式锁 五、Redis 实现分布式锁及存在问题 六、Redisson 实现分布式锁 七、定时任务+锁 一、锁的使用场景 1. 控制定时任务执行 定时任务多次执行浪费资源ÿ…...
)
蓝桥杯官网填空题(海盗与金币)
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 12名海盗在一个小岛上发现了大量的金币,后统计一共有将近5万枚。 登上小岛是在夜里,天气又不好。由于各种原因,有的海盗偷拿了很…...

JavaScript 中JSON 字符串和对象之间的转换。
JSON.stringify() 方法(对象转换为 JSON 字符串) 用于将 JavaScript 对象转换为 JSON 字符串。 它接受一个 JavaScript 对象作为参数,并返回对应的 JSON 字符串表示。例如: const obj { name: John, age: 25 }; const jsonStr…...
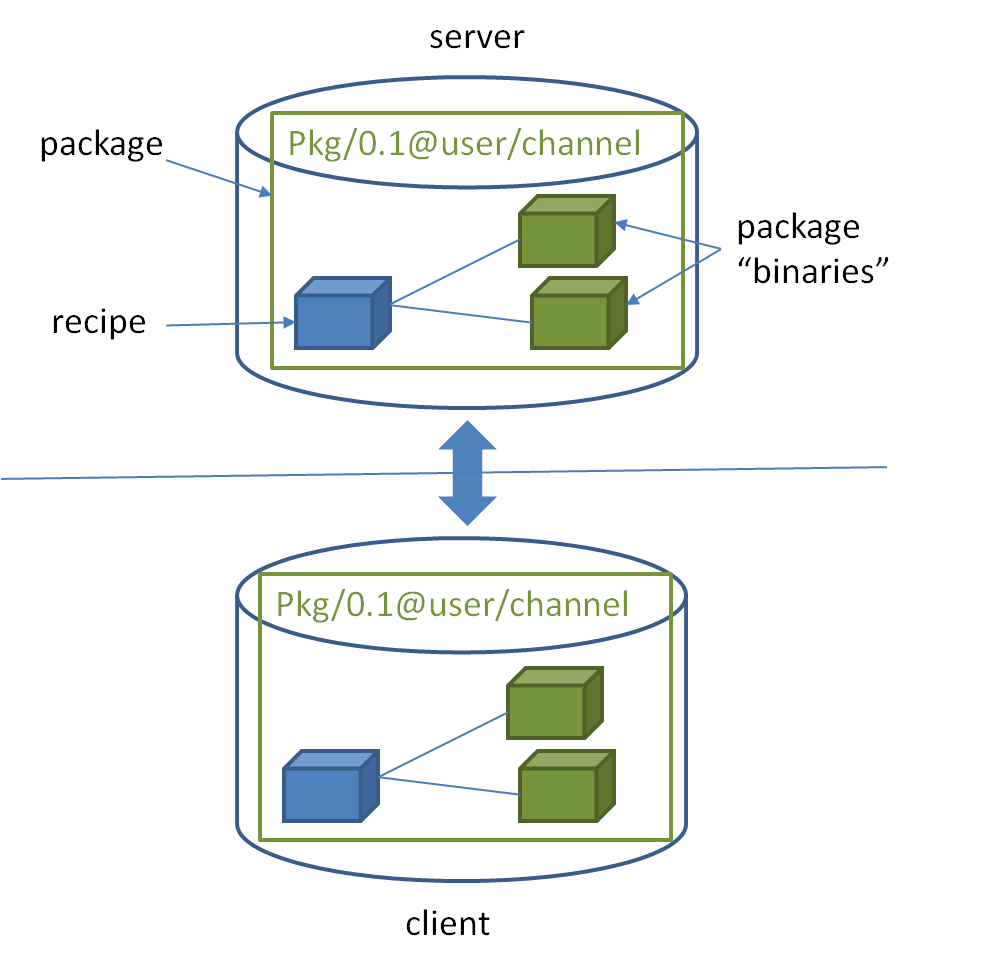
All the stories begin at installation
Before installation, there are some key points about Conan: “Conan is a dependency and package manager for C and C languages.”“With full binary management, Conan can create and reuse any number of different binaries (for different configurations like a…...
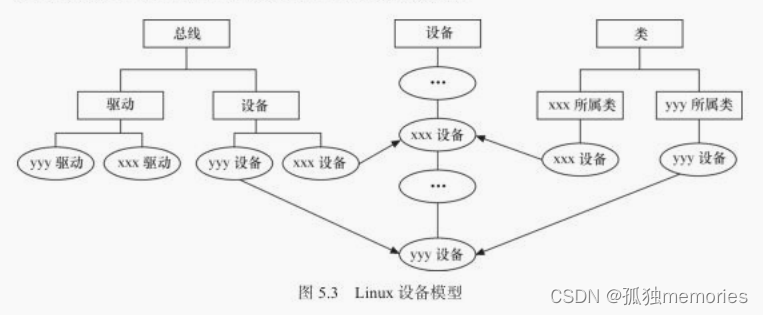
Linux文件系统与设备文件
Linux文件系统与设备文件 文章目录 Linux文件系统与设备文件Linux文件操作文件操作系统调用C库文件操作 Linux文件系统Linux文件系统目录结构Linux文件系统与设备驱动file结构体inode结构体file结构体和inode结构体的区别 devfsudev用户空间设备管理sysfs文件系统与Linux设备模…...

QT的绘图系统QPainterDevice与文件系统QIODevice
QT的绘图系统(QPainterDevice)与文件系统(QIODevice) 文章目录 1、Qt 的绘图系统1、QPainter的使用2、QPen(画笔)及QBursh(画刷)3、手动更新窗口4、绘图设备1、四种绘图设备的 区别2、 QBitmap3…...
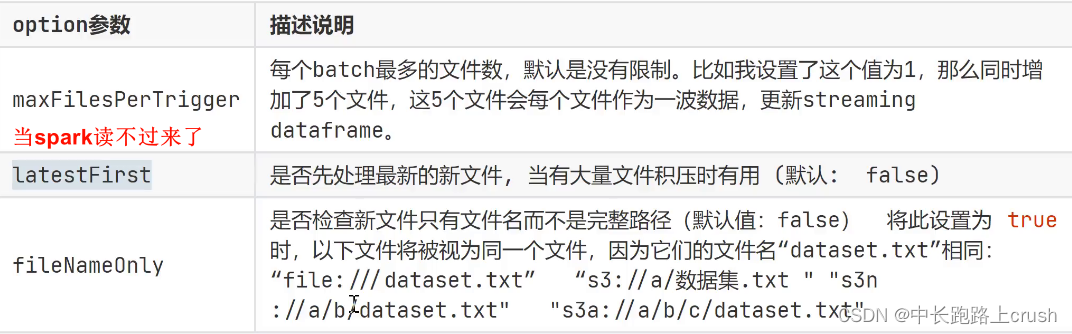
Spark流式读取文件数据
流式读取文件数据 from pyspark.sql import SparkSession ss SparkSession.builder.getOrCreate() # todo 注意1:流式读取目录下的文件 --》一定一定要是目录,不是具体的文件,# 目录下产生新文件会进行读取# todo 注意点2࿱…...

Leetcode 3011. Find if Array Can Be Sorted
Leetcode 3011. Find if Array Can Be Sorted 1. 解题思路2. 代码实现 题目链接:3011. Find if Array Can Be Sorted 1. 解题思路 这一题挺简单的,就是一个分组进行排序考察,我们将相邻且bit set相同的元素划归到同一组,然后进…...

Databend 开源周报第 129 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 支持标准流 标…...

python 正则表达式学习(1)
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 1. 特殊符号 1.1 符号含义 模式描述^匹配字符串的开头$匹配字符串的末尾.匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包…...

安全防御-基础认知
目录 安全风险能见度不足: 常见的网络安全术语 : 常见安全风险 网络的基本攻击模式: 病毒分类: 病毒的特征: 常见病毒: 信息安全的五要素: 信息安全的五要素案例 网络空间:…...

各省税收收入、个人和企业所得税数据,Shp、excel格式,2000-2021年
基本信息. 数据名称: 各省税收收入、个人和企业所得税数据 数据格式: Shp、excel 数据时间: 2000-2021年 数据几何类型: 面 数据坐标系: WGS84 数据来源:网络公开数据 数据字段: 序号字段名称字段说明1sssr_2021税收收入(亿元&am…...

Vue记录
vue2、vue3记录,参考地址:尚硅谷Vue项目实战硅谷甄选,vue3项目TypeScript前端项目一套通关_哔哩哔哩_bilibili vue2记录 经典vue2结构 index.vue: <template><div>...</div> </template><script>…...

【JavaEE进阶】 Spring Boot⽇志
文章目录 🎋关于日志🚩为什么要学习⽇志🚩⽇志的⽤途🚩日志的简单使用 🎄打印⽇志🚩程序中得到⽇志对象🚩使⽤⽇志对象打印⽇志 🎍⽇志格式的说明🚩⽇志级别的作用&#…...
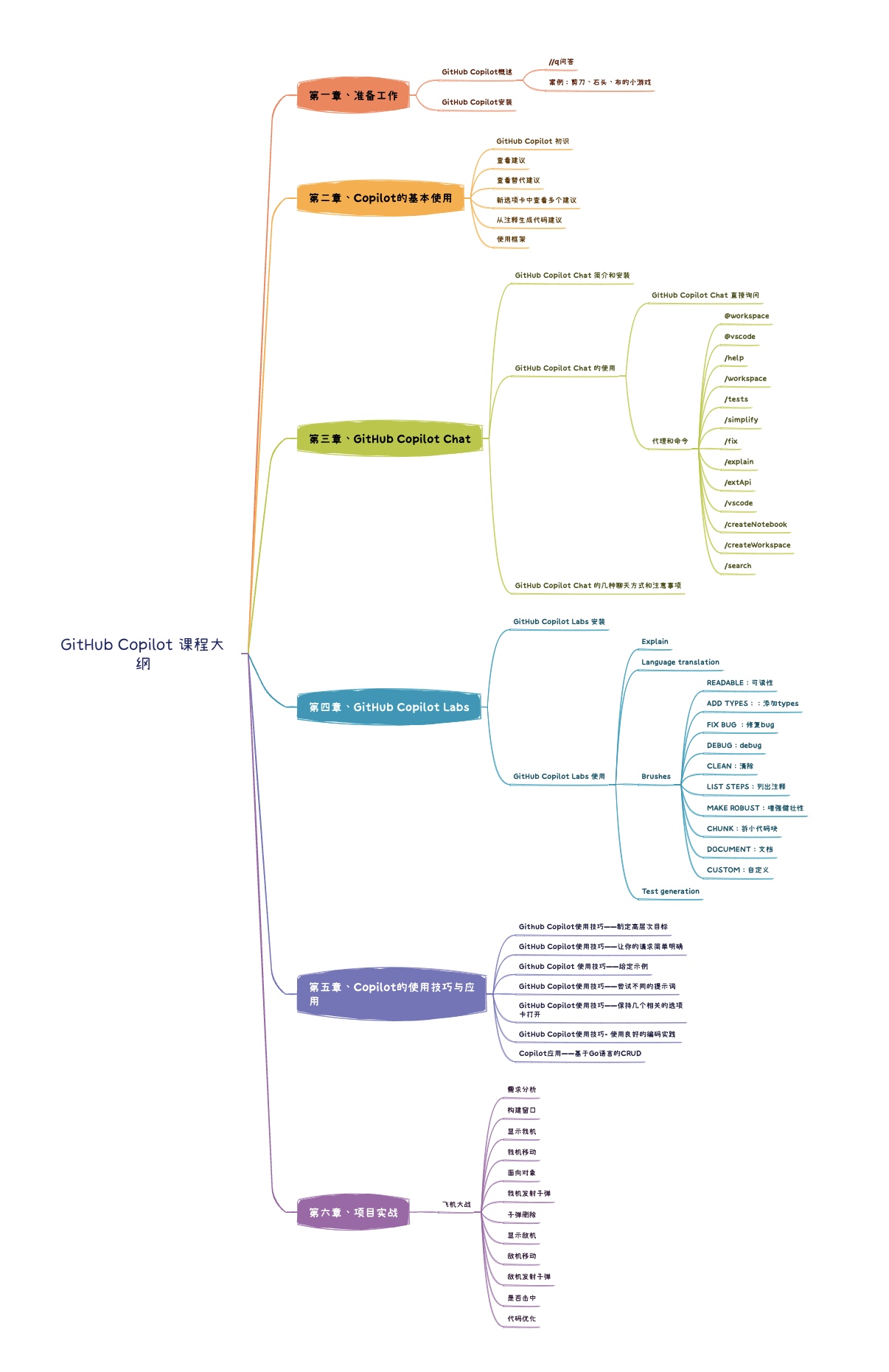
《GitHub Copilot 操作指南》课程介绍
第1节:GitHub Copilot 概述 一、什么是 GitHub Copilot 什么是 GitHub Copilot GitHub Copilot是GitHub与OpenAI合作开发的编程助手工具,利用机器学习模型生成代码建议。它集成在开发者的集成开发环境(IDE)中,可以根…...
)
结构体(C语言)
结构体 1.结构体基础知识: //结构是一些值的集合,这些值称为成员变量. // 结构的每个成员可以是不同类型的变量. 2.结构的定义 struct peo { char name[10];//姓名 char tele[12];//电话 char gender[5];//性别 int high;//身高 }; struct stu { struct…...

SpringBoot开发秘籍【个人八股】
介绍一下 SpringBoot? Spring Boot极大地简化了 Spring 应用的开发和部署过程。 以前我们用 Spring 开发项目的时候,需要配置一大堆 XML 文件,包括 Bean 的定义、数据源配置、事务配置等等,非常繁琐。而且还要手动管理各种 jar 包…...

扛住十万并发的“冷面保安”:一文扒透限流的四大经典算法与代码实战
在高并发架构中,如果说缓存和 MQ 是替服务器扛伤害的“防弹衣”,那么限流(Rate Limiting)就是守在系统大门外的“冷面保安”。他的核心逻辑极其冷酷:不管外面排队的人有多急,只要超过了系统的最大接待能力&…...

拯救吃灰的MT7921网卡:保姆级教程,在Ubuntu 22.04上为联想拯救者系列驱动Wi-Fi
拯救吃灰的MT7921网卡:联想拯救者Ubuntu 22.04无线驱动全攻略 当联想拯救者Y9000P/R7000P等2021款笔记本遇上Ubuntu 22.04,那块被诟病已久的MT7921无线网卡往往成为最大的绊脚石。不同于Windows下的即插即用,Linux环境需要精准的内核版本与固…...

别再只盯着RMSE了!MATLAB里这7个模型评价指标,你用对了吗?
别再只盯着RMSE了!MATLAB里这7个模型评价指标,你用对了吗? 在数据建模的世界里,我们常常陷入一个误区:用单一指标评判模型的优劣。就像用一把尺子测量所有物体,RMSE(均方根误差)固然…...

如何通过QuickLookVideo实现Mac视频预览效率革命:终极工具深度解析
如何通过QuickLookVideo实现Mac视频预览效率革命:终极工具深度解析 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: ht…...

taotoken api密钥管理与审计日志保障ubuntu服务器访问安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API密钥管理与审计日志保障Ubuntu服务器访问安全 1. 场景概述 在基于Ubuntu的服务器环境中集成大模型服务,安…...

Windows远程桌面终极解锁指南:RDP Wrapper完整使用方案
Windows远程桌面终极解锁指南:RDP Wrapper完整使用方案 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 还在为Windows家庭版无法使用远程桌面而烦恼吗?是否曾经羡慕专业版用户能够享受多用户…...

3个必知技巧:快速掌握Meshroom三维重建核心
3个必知技巧:快速掌握Meshroom三维重建核心 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom Meshroom是一款基于节点化视觉编程的开源三维重建软件,它能将你的照片和视频…...

从打磨抛光到医疗康复:拆解阻抗控制在机器人实际场景中的选型指南
从打磨抛光到医疗康复:拆解阻抗控制在机器人实际场景中的选型指南 在工业4.0和智能制造的浪潮中,机器人技术正从传统的重复定位作业向更复杂的交互任务演进。无论是汽车制造中的精密装配,还是医疗器械的力控打磨,亦或是康复训练中…...

解锁游戏时间魔法:OpenSpeedy如何重塑你的单机游戏体验
解锁游戏时间魔法:OpenSpeedy如何重塑你的单机游戏体验 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾在游戏中经历过这样的时刻:冗长的剧情…...