Elasticsearch:和 LIamaIndex 的集成
LlamaIndex 是一个数据框架,供 LLM 应用程序摄取、构建和访问私有或特定领域的数据。
LlamaIndex 是开源的,可用于构建各种应用程序。 在 GitHub 上查看该项目。

安装
在 Docker 上设置 Elasticsearch
使用以下 docker 命令启动单节点 Elasticsearch 实例。我们可以参考之前的文章 “Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发”。我选择不使用安全配置。直接使用 docker compose 来启动 Elasticsearch 及 Kibana:
.env
$ pwd
/Users/liuxg/data/docker8
$ ls -al
total 16
drwxr-xr-x 4 liuxg staff 128 Jan 16 13:00 .
drwxr-xr-x 193 liuxg staff 6176 Jan 12 08:31 ..
-rw-r--r-- 1 liuxg staff 21 Jan 16 13:00 .env
-rw-r--r-- 1 liuxg staff 733 Mar 14 2023 docker-compose.yml
$ cat .env
STACK_VERSION=8.11.3docker-compose.yml
version: "3.9"
services:elasticsearch:image: elasticsearch:${STACK_VERSION}container_name: elasticsearchenvironment:- discovery.type=single-node- ES_JAVA_OPTS=-Xms1g -Xmx1g- xpack.security.enabled=falsevolumes:- type: volumesource: es_datatarget: /usr/share/elasticsearch/dataports:- target: 9200published: 9200networks:- elastickibana:image: kibana:${STACK_VERSION}container_name: kibanaports:- target: 5601published: 5601depends_on:- elasticsearchnetworks:- elastic volumes:es_data:driver: localnetworks:elastic:name: elasticdriver: bridge我们使用如下的命令来启动:
docker-compose up
这样我们就完成了 Elasticsearch 及 Kibana 的安装了。我们的 Elasticsearch 及 Kibana 都没有安全的设置。这个在生产环境中不被推荐使用。
应用设计 - 组装管道
我们将使用 Jupyter notebook 来进行设计。我们在命令行中打入:
jupyter notebook安装依赖
我们使用如下的命令来安装 Python 的依赖包:
pip3 install llama-index openai elasticsearch load_dotenv我们接下来在当前的工作目录中创建一个叫做 .env 的文件:
.env
OPENAI_API_KEY="YourOpenAIKey"请在 .env 中创建如上所示的变量。你需要把自己的 openai key 写入到上面的文件里。
加载模块及读取环境变量
import logging
import sys
import os
from dotenv import load_dotenvload_dotenv()logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')import openai连接到 Elasticsearch
ElasticsearchStore 类用于连接到 Elasticsearch 实例。 它需要以下参数:
- index_name:Elasticsearch 索引的名称。 必需的。
- es_client:可选。 预先存在的 Elasticsearch 客户端。
- es_url:可选。Elasticsearch 网址。
- es_cloud_id:可选。 Elasticsearch 云 ID。
- es_api_key:可选。 Elasticsearch API 密钥。
- es_user:可选。 Elasticsearch 用户名。
- es_password:可选。 弹性搜索密码。
- text_field:可选。 存储文本的 Elasticsearch 字段的名称。
- vector_field:可选。 存储 Elasticsearch 字段的名称嵌入。
- batch_size:可选。 批量索引的批量大小。 默认为 200。
- distance_strategy:可选。 用于相似性搜索的距离策略。默认为 “COSINE”。
针对,我们的情况,我们可以使用如下的示例方法来进行本地连接:
from llama_index.vector_stores import ElasticsearchStorees = ElasticsearchStore(index_name="my_index",es_url="http://localhost:9200",
)我们将在下面的代码中使用上述的方法来连接 Elasticsearch。
加载文档,使用 Elasticsearch 构建 VectorStoreIndex
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores import ElasticsearchStore!mkdir -p 'data/paul_graham/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'
运行完上面的命令后,我们可以在当前的目录下查看:
$ pwd
/Users/liuxg/python/elser
$ ls data/paul_graham/
paul_graham_essay.txt我们可以看到一个叫做 pau_graham_essay.txt 的文件。它的内容如下:
What I Worked OnFebruary 2021Before college the two main things I worked on, outside of school, were writing and programming. I didn't write essays. I wrote what beginning writers were supposed to write then, and probably still are: short stories. My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep.The first programs I tried writing were on the IBM 1401 that our school district used for what was then called "data processing." This was in 9th grade, so I was 13 or 14. The school district's 1401 happened to be in the basement of our junior high school, and my friend Rich Draves and I got permission to use it. It was like a mini Bond villain's lair down there, with all these alien-looking machines — CPU, disk drives, printer, card reader — sitting up on a raised floor under bright fluorescent lights....The language we used was an early version of Fortran. You had to type programs on punch cards, then stack them in the card reader and press a button to load the program into memory and run it. The result would ordinarily be to print something on the spectacularly loud printer.I was puzzled by the 1401. I couldn't figure out what to do with it. And in retrospect there's not much I could have done with it. The only form of input to programs was data stored on punched cards, and I didn't have any data stored on punched cards. The only other option was to do things that didn't rely on any input, like calculate approximations of pi, but I didn't know enough math to do anything interesting of that type. So I'm not surprised I can't remember any programs I wrote, because they can't have done much. My clearest memory is of the moment I learned it was possible for programs not to terminate, when one of mine didn't. On a machine without time-sharing, this was a social as well as a technical error, as the data center manager's expression made clear.
...Toward the end of the summer I got a big surprise: a letter from the Accademia, which had been delayed because they'd sent it to Cambridge England instead of Cambridge Massachusetts, inviting me to take the entrance exam in Florence that fall. This was now only weeks away. My nice landlady let me leave my stuff in her attic. I had some money saved from consulting work I'd done in grad school; there was probably enough to last a year if I lived cheaply. Now all I had to do was learn Italian.
...documents = SimpleDirectoryReader("./data/paul_graham/").load_data()from llama_index.storage.storage_context import StorageContextvector_store = ElasticsearchStore(es_url="http://localhost:9200",# Or with Elastic Cloud# es_cloud_id="my_cloud_id",# es_user="elastic",# es_password="my_password",index_name="paul_graham",
)storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context
)
基本查询
我们将向查询引擎询问有关我们刚刚索引的数据的问题。
# set Logging to DEBUG for more detailed outputs
query_engine = index.as_query_engine()
response = query_engine.query("what were his investments in Y Combinator?")
print(response)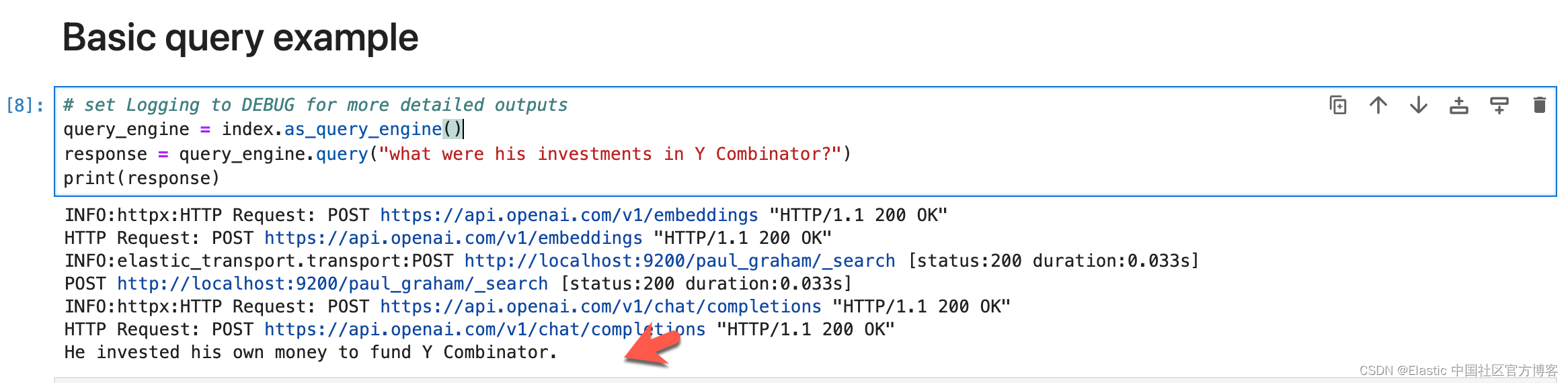
元数据过滤器
在这里,我们将使用元数据索引一些文档,以便我们可以将过滤器应用于查询引擎。
from llama_index.schema import TextNodenodes = [TextNode(text="The Shawshank Redemption",metadata={"author": "Stephen King","theme": "Friendship",},),TextNode(text="The Godfather",metadata={"director": "Francis Ford Coppola","theme": "Mafia",},),TextNode(text="Beautiful weather",metadata={"director": "Mark shuttle","theme": "Mafia",},), TextNode(text="Inception",metadata={"director": "Christopher Nolan",},),
]# initialize the vector store
vector_store_metadata_example = ElasticsearchStore(index_name="movies_metadata_example",es_url="http://localhost:9200",
)
storage_context = StorageContext.from_defaults(vector_store=vector_store_metadata_example
)
index1 = VectorStoreIndex(nodes, storage_context=storage_context)# Metadata filter
from llama_index.vector_stores.types import ExactMatchFilter, MetadataFiltersfilters = MetadataFilters(filters=[ExactMatchFilter(key="theme", value="Mafia")]
)retriever = index1.as_retriever(filters=filters)retriever.retrieve("weather is so beautiful") 在上面,我们搜索的是 “weather is so beautiful”,从而在两个 theme 为 Mafia 的 Texnode 里,Mark shuttle 位列第一。这个是因为 “weather is so beautiful” 更和 “Beautiful weather” 更为贴近。 如果我们使用如下的查询:
在上面,我们搜索的是 “weather is so beautiful”,从而在两个 theme 为 Mafia 的 Texnode 里,Mark shuttle 位列第一。这个是因为 “weather is so beautiful” 更和 “Beautiful weather” 更为贴近。 如果我们使用如下的查询:
retriever.retrieve("The godfather is a nice person")
很显然,这次我们的搜索结果的排序颠倒过来了。
自定义过滤器和覆盖查询
llama-index 目前仅支持 ExactMatchFilters。 Elasticsearch 支持多种过滤器,包括范围过滤器、地理过滤器等。 要使用这些过滤器,你可以将它们作为字典列表传递给 es_filter 参数。
def custom_query(query, query_str):print("custom query", query)return queryquery_engine = index.as_query_engine(vector_store_kwargs={"es_filter": [{"match": {"content": "growing up"}}],"custom_query": custom_query,}
)response = query_engine.query("what were his investments in Y Combinator?")
print(response)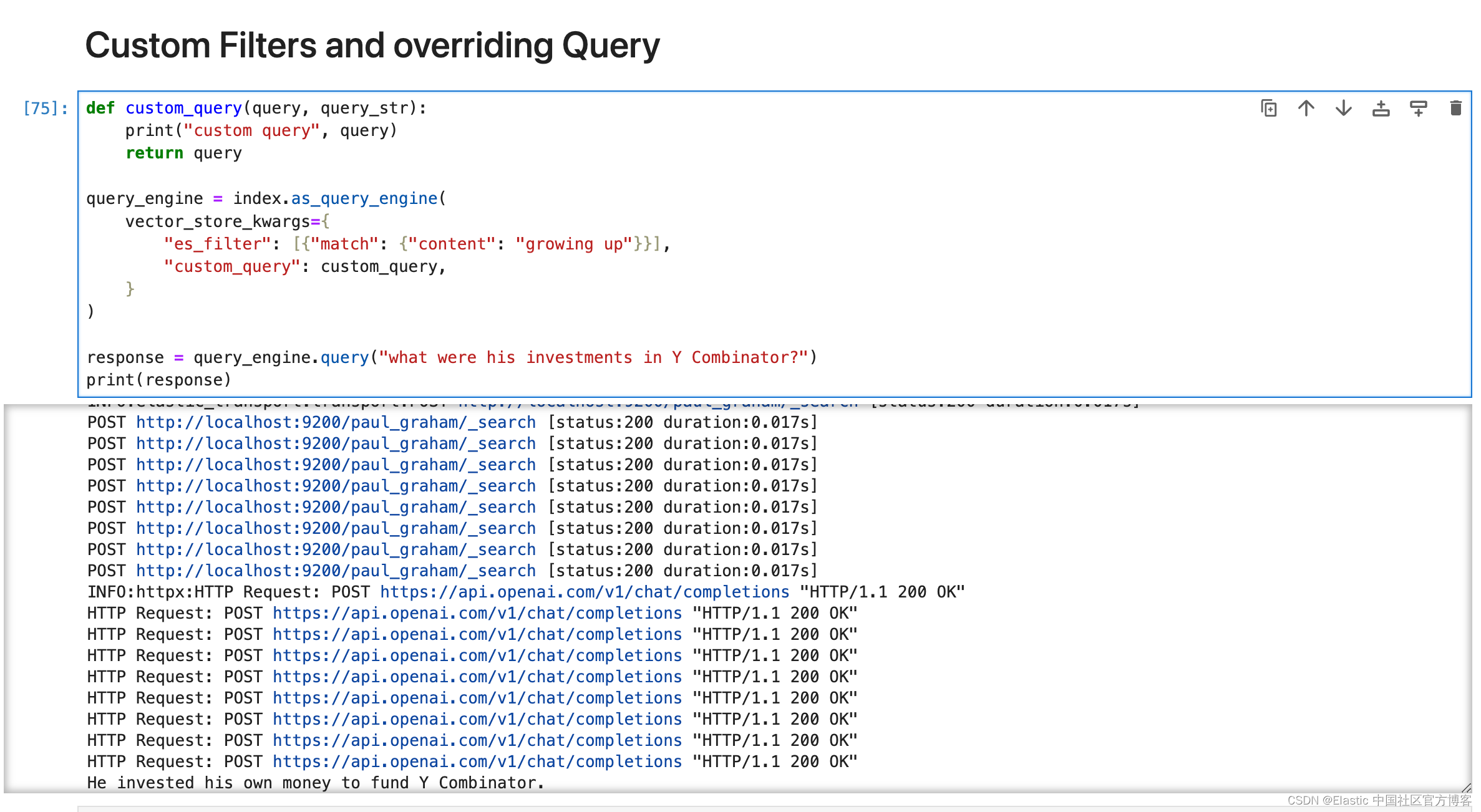
为了方便大家学习,我把所有的源码放到 github:https://github.com/liu-xiao-guo/semantic_search_es。其中相关的文件是:
- https://github.com/liu-xiao-guo/semantic_search_es/blob/main/Elasticsearch%20integration%20-%20LIamaIndex%20.ipynb
更多阅读:使用 Elasticsearch 和 LlamaIndex 进行高级文本检索:句子窗口检索
相关文章:
Elasticsearch:和 LIamaIndex 的集成
LlamaIndex 是一个数据框架,供 LLM 应用程序摄取、构建和访问私有或特定领域的数据。 LlamaIndex 是开源的,可用于构建各种应用程序。 在 GitHub 上查看该项目。 安装 在 Docker 上设置 Elasticsearch 使用以下 docker 命令启动单节点 Elasticsearch 实…...
QT操作office实例)
QT基础篇(14)QT操作office实例
1.QT操作office的基本方式 通过QT操作Office软件,可以使用Qt的QAxObject类来进行操作。下面是一个例子,展示了通过Qt操作Excel的基本方式: #include <QApplication> #include <QAxObject>int main(int argc, char *argv[]) {QA…...

重拾计网-第四弹 计算机网络性能指标
ps:本文章的图片内容来源都是来自于湖科大教书匠的视频,声明:仅供自己复习,里面加上了自己的理解 这里附上视频链接地址:1.5 计算机网络的性能指标(1)_哔哩哔哩_bilibili 目录 &#x…...
【Vue】Vue 路由的配置及使用
目录捏 前言一、路由是什么?1.前端路由2.后端路由 二、路由配置1.安装路由2.配置路由 三、路由使用1.route 与 router2. 声明式导航3. 指定组件的呈现位置 四、嵌套路由(多级路由)五、路由重定向1.什么是路由重定向?2.设置 redire…...

网络安全事件分级指南
一、特别重大网络安全事件 符合下列情形之一的,为特别重大网络安全事件: 1.重要网络和信息系统遭受特别严重的系统损失,造成系统大面积瘫痪,丧失业务处理能力。 2.国家秘密信息、重要敏感信息、重要数据丢失或被窃取、篡改、假…...

uniapp组件库SwipeAction 滑动操作 使用方法
目录 #平台差异说明 #基本使用 #修改按钮样式 #点击事件 #API #Props #Event 该组件一般用于左滑唤出操作菜单的场景,用的最多的是左滑删除操作。 注意 如果把该组件通过v-for用于左滑删除的列表,请保证循环的:key是一个唯一值,可以…...
YARN节点故障的容错方案
YARN节点故障的容错方案 1. RM高可用1.1 选主和HA切换逻辑 2. NM高可用2.1 感知NM节点异常2.2 异常NM上的任务处理 4. 疑问和思考4,1 RM感知NM异常需要10min,对于app来说是否太长了? 5. 参考文档 本文主要探讨yarn集群的高可用容错方案和容错能力的探讨。…...

C++后端笔记
C后端笔记 资源整理一、高级语言程序设计1.1 进制1.2 程序结构基本知识1.3 数据类型ASCII码命名规则变量间的赋值浮点型变量的作用字符变量常变量 const运算符 二、高级语言程序设计(荣) 资源整理 C后端开发学习路线及推荐学习时间 C基础知识大全 C那…...

JavaEE中什么是Web容器?
Web容器(也称为Servlet引擎)是一个用于执行Java Servlet和JSP的服务器端环境。它负责管理和执行在其上运行的Web应用程序。 Tomcat是Web容器 Apache Tomcat 是一个流行的开源的Web容器,它实现了Java Servlet和JavaServer Pages(…...
(1))
MySQL 8.0 架构 之错误日志文件(Error Log)(1)
文章目录 MySQL 8.0 架构 之错误日志文件(Error Log)(1)MySQL错误日志文件(Error Log)MySQL错误日志在哪里Window环境Linux环境 错误日志相关参数log_error_services 参考 【声明】文章仅供学习交流&#x…...

51单片机实验课一
实验任务一:实现控制8个发光管的亮(灭) #include <REGX52.H> void Delay1ms(unsigned int xms) //11.0592MHz {unsigned char i, j;while(xms){xms--;i 12;j 169;do{while (--j);} while (--i);} } void main() {while(1){P20;//八…...

【.NET Core】多线程之线程池(ThreadPool)详解(一)
【.NET Core】多线程之线程池(ThreadPool)详解(一) 文章目录 【.NET Core】多线程之线程池(ThreadPool)详解(一)一、概述二、线程池的应用范围三、线程池特性3.1 线程池线程中的异常…...

圆的参数方程是如何推导的?
圆的参数方程是如何推导的? 1. 圆的三种参数表示2. 三角函数万能公式3. 回到圆的参数方程1. 圆的三种参数表示 已知圆的第一种参数方程为: x 2 + y 2 = r x^2+y^2=r x2+y2=r 圆的图像如下: 通过上图,不难理解,圆的参数方程还可以用三角函数表示,也就是第二种参数表…...

sqlmap使用教程(2)-连接目标
目录 连接目标 1.1 设置认证信息 1.2 配置代理 1.3 Tor匿名网络 1.4 检测WAF/IPS 1.5 调整连接选项 1.6 处理连接错误 连接目标 场景1:通过代理网络上网,需要进行相应配置才可以成功访问目标主机 场景2:目标网站需要进行身份认证后才…...

c++ http第一个服务
c http第一个服务 一、下载相关依赖:这是一个git开源项目 代码仓地址 二、演示代码,编译参数:g test.cpp -I/**** -lpthread #include <httplib.h> using namespace httplib;void wuhan(const Request &req, Response &res) …...
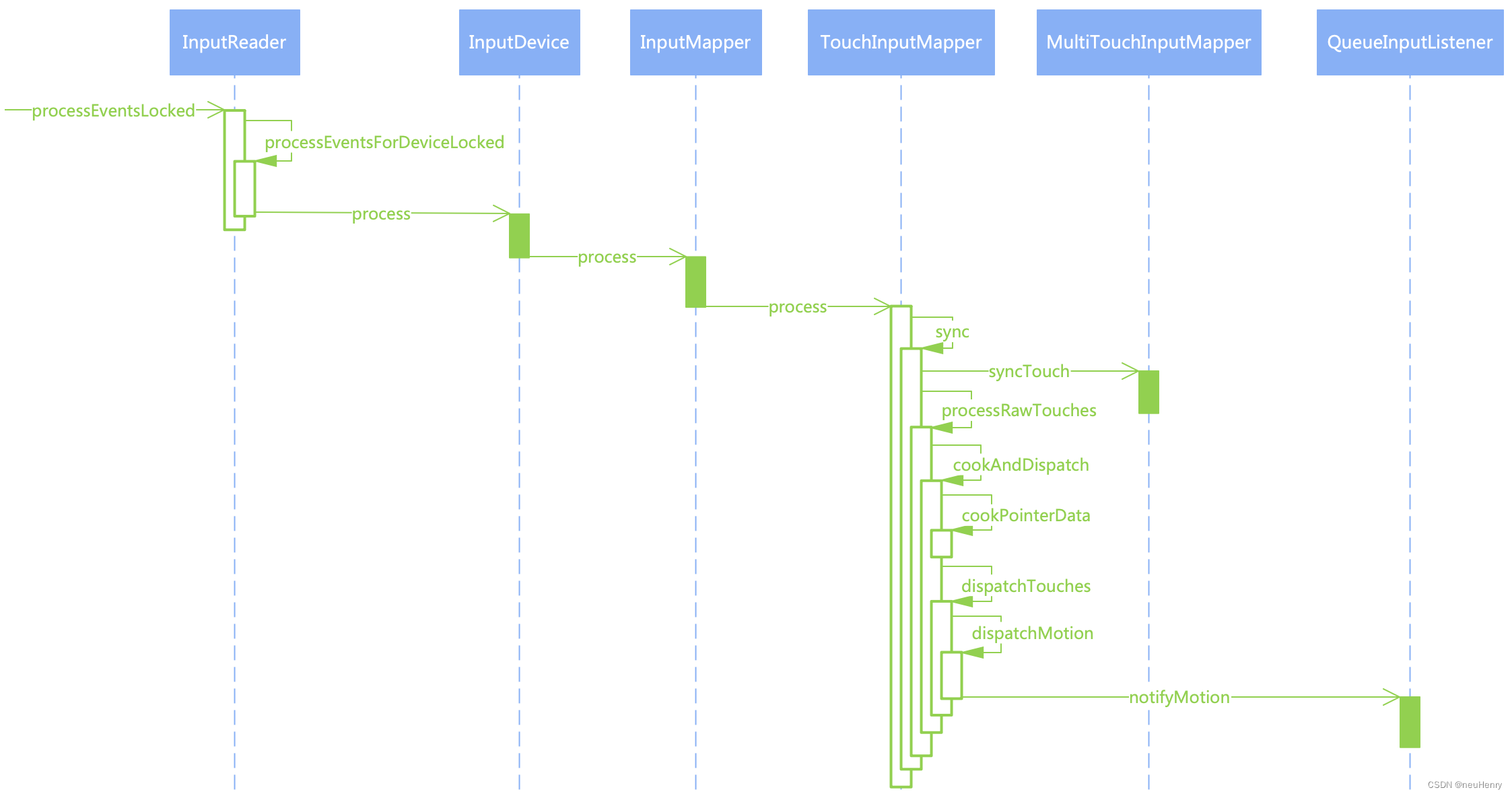
深入Android S (12.0) 探索Framework之输入子系统InputReader的流程
Framework层之输入系统 第一篇 深入Android S (12.0) 探索Framework之输入系统IMS的构成与启动 第二篇 深入Android S (12.0) 探索Framework之输入子系统InputReader的流程 文章目录 Framework层之输入系统前言一、基础知识1、输入子系统2、INotify 与 Epoll2.1、INotify 机制…...
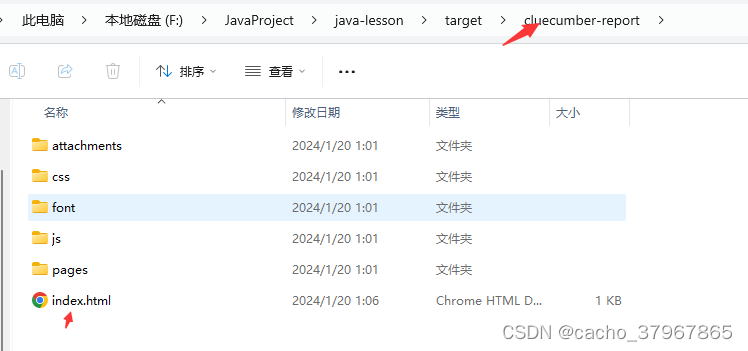
【cucumber】cluecumber-report-plugin生成测试报告
cluecumber为生成测试报告的第三方插件,可以生成html测报,该测报生成需以本地json测报的生成为基础。 所以需要在测试开始主文件标签CucumberOptions中,写入生成json报告。 2. pom xml文件中加入插件 <!-- 根据 cucumber json文件 美化测…...

华为欧拉操作系统结合内网穿透实现固定公网地址SSH远程连接
文章目录 1. 本地SSH连接测试2. openEuler安装Cpolar3. 配置 SSH公网地址4. 公网远程SSH连接5. 固定连接SSH公网地址6. SSH固定地址连接测试 欧拉操作系统(openEuler, 简称“欧拉”)是面向数字基础设施的操作系统,支持服务器、云计算、边缘openEuler是面向数字基础设施的操作系…...
加速 Selenium 测试执行最佳实践
Selenium测试自动化的主要目的是加快测试过程。在大多数情况下,使用 Selenium 的自动化测试比手动测试执行得特别好。在实际自动化测试实践中,我们有很多方式可以加速Selenium用例的执行。 我们可以选择使用不同类型的等待、不同类型的 Web 定位器、不同…...

c语言野指针
系列文章目录 c语言野指针 c语言野指针 系列文章目录c语言野指针 c语言野指针 野指针可以用于破坏修改别人的内存空间,比如游戏外挂 野指针 野指针:野指针是指向一个未知的内存空间,在读写的时候出现错误。 0-255都是系统保留的 不可以读&am…...
如何用TranslucentTB实现Windows任务栏透明化:3分钟完成桌面美化终极指南
如何用TranslucentTB实现Windows任务栏透明化:3分钟完成桌面美化终极指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是…...

终于有人说清楚经营分析会怎么开了!一篇看懂经营分析会全流程
各位老板有没有想过,为什么你的经营分析会越开越多?有的企业月月开、周周开,甚至恨不得天天开。会一多,人就麻木了,翻来覆去讲同样的数据、追同样的问题,真正该花时间去解决的业务卡点,反而没人…...

协议转换网关与数据采集网关的区别与差异
摘要在工业自动化、物联网、智能建筑等领域中,“协议转换”和“数据采集网关”是两个常被提及但容易混淆的概念。它们虽有关联,却扮演着不同的角色。理解其核心差异对于构建高效、可靠的数据通信系统至关重要。1.核心定义:本质差异1.1协议转换…...

拆解昇腾 CANN 五层架构:一个 MatMul 请求的完整旅程
适合人群:想从全局视角理解 CANN 架构的开发者 核心仓库:https://atomgit.com/cann 阅读时长:6 分钟 目录 一、为什么需要五层架构?二、第1层:昇腾计算语言层 AscendCL三、第2层:昇腾计算服务层四、第3层&…...

从‘延迟’到‘精准’:聊聊风力发电机液压偏航控制中的那些坑与优化思路
从‘延迟’到‘精准’:风力发电机液压偏航控制的实战优化指南 引言:当风向变化比控制指令更快 在内蒙古某风电场,一台2.5MW机组在春季大风季节出现了令人费解的现象:尽管偏航系统持续运转,发电量却比相邻机组低12%。现…...

nuScenes数据集“平替”指南:Mini版够用吗?完整版、Test版到底怎么选?
nuScenes数据集选型实战指南:从Mini版到完整版的决策逻辑 第一次接触nuScenes数据集时,面对动辄几百GB的庞然大物和仅有3.9GB的mini版本,相信不少研究者都会陷入选择困难。这就像站在自助餐厅里,既想品尝所有美味,又担…...

openssl基于ede3的加密和解密
基于ede3的加密和解密当前提供模式有cfb和cbc数据长度非向量整数倍特别注意当数据长度是非向量证书倍的时候该如何处理数据openssl 版本 OpenSSL 1.1.1 11 Sep 2018验证结果: 明文 100: 00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10 11 12 13 14…...

美股api的WebSocket偶尔断连,心跳间隔设多少秒最合适?
做美股相关的数据服务时,我碰到一个小烦恼:WebSocket连接偶尔断开。尤其是实时tick数据,程序明明还在跑,提示“断开”,有时候还挺突然的。我自己测试了不少方法,发现心跳设置是最容易影响稳定性的一个点。 …...

Python DXF处理库ezdxf的技术架构与工程实践深度解析
Python DXF处理库ezdxf的技术架构与工程实践深度解析 【免费下载链接】ezdxf Python interface to DXF 项目地址: https://gitcode.com/gh_mirrors/ez/ezdxf ezdxf是一个面向专业CAD数据交换的Python库,它提供了对DXF(Drawing Exchange Format&am…...
配置与抗干扰应用实战)
STM32MP1 Cortex-M4窗口看门狗(WWDG)配置与抗干扰应用实战
1. 项目概述:为什么需要窗口看门狗?在嵌入式开发,尤其是基于STM32MP1这类异构多核处理器的项目中,系统可靠性是工程师必须直面的核心挑战。想象一下,你的设备在野外无人值守,或者在一个工业控制现场连续运行…...