2.机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解
2️⃣机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解
- 个人简介
- 一·算法概述
- 二·算法思想
- 2.1 KNN的优缺点
- 三·实例演示
- 3.1电影分类
- 3.2使用KNN算法预测 鸢(yuan)尾花 的种类
- 3.3 预测年收入是否大于50K美元
个人简介
🏘️🏘️个人主页:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证,CSDN内容合伙人,阿里云社区专家博主,新星计划导师,在职数据分析师。
🎉🎉免费学习专栏:1. 《Python基础入门》——0基础入门
2.《Python网络爬虫》——从入门到精通
3.《Web全栈开发》——涵盖了前端、后端和数据库等多个领域💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
一·算法概述
K-最近邻算法(K-Nearest Neighbor,简称KNN)是一种基于实例学习的算法,可以应用于分类和回归任务。作为一种非参数算法,KNN不对数据分布做任何假设,而是直接使用数据中的最近K个邻居的标签来预测新数据点的标签。
在KNN算法中,每个数据点都可以表示为一个n维向量,其中n是特征的数量。对于一个新的数据点,KNN算法会计算它与每个训练数据点之间的距离,并选择最近的K个训练数据点。对于分类问题,KNN算法会将这K个训练数据点中出现最多的类别作为预测结果。而对于回归问题,KNN算法会将这K个训练数据点的输出值的平均值作为预测结果。
在KNN算法中,K的取值是一个超参数,需要根据数据集的特点和算法的性能进行选择。通常情况下,较小的K值可以使模型更复杂,更容易受到噪声的影响,而较大的K值可以使模型更简单、更稳定,但可能会导致模型的欠拟合。因此,选择合适的K值对于KNN算法的性能至关重要。

二·算法思想
KNN(K-最近邻)算法是一种基于实例的分类方法,通过计算不同特征值之间的距离来进行分类。
1️⃣其核心思想是:
如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
2️⃣ KNN算法的主要步骤如下:
- 确定k值,即选取多少个最近邻居参与投票。
- 计算待分类样本与已知分类样本之间的距离,通常使用欧氏距离作为距离度量。
- 对距离进行排序,找出最近的k个邻居。
- 统计这k个邻居中各个类别的数量,将数量最多的类别作为待分类样本的类别。
3️⃣KNN算法涉及3个主要因素:
实例集、距离或相似的衡量、k的大小。实例集是指已知分类的样本集合;距离或相似的衡量是指计算样本之间距离的方法,如欧氏距离;k的大小是指选取多少个最近邻居参与投票,k值的选择会影响分类结果的准确性。
一个实例的最近邻是根据标准欧氏距离定义的。更精确地讲,把任意的实例x表示为下面的特征向量:

其中ar(x)表示实例x的第r个属性值。那么两个实例xi和xj间的距离定义为d(xi,xj),其中:
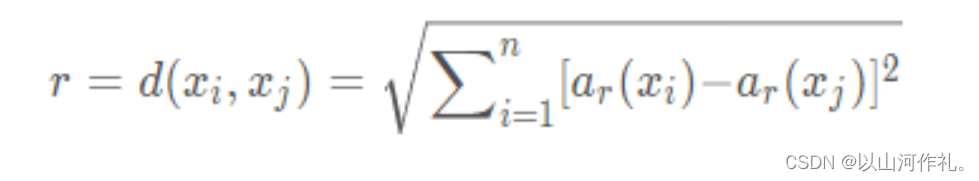

2.1 KNN的优缺点
1️⃣K-最近邻算法(KNN)的优点:
简单易懂:KNN算法的原理和实现都非常简单,容易理解和掌握。
非参数化:KNN是一种非参数化算法,不需要对数据分布做任何假设。
对异常值不敏感:KNN能够有效处理包含异常值的数据。
多用途:适用于分类和回归问题。
高维数据处理:可以处理高维特征空间的数据。
非线性问题处理:能够适应非线性的数据分布。
高度可解释性:结果直观,易于解释。
2️⃣KNN算法的缺点:
效率低:在大型数据集上计算距离时效率较低,尤其是在高维数据中。
对噪声敏感:训练数据中的噪声可能影响最近邻的选择,导致预测结果不准确。
K值选择:K值的选择对算法性能有很大影响,需要通过实验来确定最佳值。
距离度量:选择合适的距离度量方法对算法性能至关重要。
特征缩放敏感:需要对特征进行归一化或标准化,否则可能导致某些特征过于主导。
缺失值处理:处理缺失值较为困难,需要采取特定策略来应对。
解释性差:由于是基于实例的预测,相对于其他模型来说解释性较差。
三·实例演示
3.1电影分类
1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入KNN算法
# 谷歌的机器学习库
from sklearn.neighbors import KNeighborsClassifier3.导入warnings模块,并设置警告过滤器为忽略所有警告
import warnings
warnings.filterwarnings(action='ignore')
4.使用电影数据
movies = pd.read_excel('../data/movies.xlsx',sheet_name=1)
movies

# 有标签的:有监督学习# 训练数据
# x_train,y_train # 测试数据
# x_test,y_test# data : x特征数据
# target :y标签数据data = movies[['武打镜头','接吻镜头']]
data # 二维target = movies.分类情况
target # 一维

KNN模型
1.创建模型
# n_neighbors=5, k值 k = 5
# p = 2 距离算法,p=2表示欧氏距离 ,p = 1 表示曼哈顿距离
#
knn = KNeighborsClassifier(n_neighbors=5,p=2)
2.训练
knn.fit(data,target)
3.预测
# 自己提供测试数据,训练数据和测试数据列得相同,行可以不同x_test=np.array([[20,1],[0,20],[10,10],[33,2],[2,13]])
x_test = pd.DataFrame(x_test,columns= data.columns)
y_test = np.array(['动作片','爱情片','爱情片','动作片','爱情片'])
y_pred = knn.predict(x_test)
y_pred

4.得分 ,准确率

3.2使用KNN算法预测 鸢(yuan)尾花 的种类

1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入KNN算法
# 谷歌的机器学习库
from sklearn.neighbors import KNeighborsClassifier3.导入warnings模块,并设置警告过滤器为忽略所有警告
import warnings
warnings.filterwarnings(action='ignore')
4.得到鸢尾花数据
from sklearn.datasets import load_iris
# return_X_y=True 只返回data和target
# data,target = load_iris(return_X_y=True)
5.使用sklearn库中的load_iris()函数加载鸢尾花数据集,并将数据集分为数据(data)、目标(target)、目标名称(target_names)、特征名称(feature_names)四个部分。
iris = load_iris()
data = iris['data']
target = iris['target']
target_names = iris['target_names']
feature_names = iris['feature_names']
df = pd.DataFrame(data,columns=feature_names)
df

6.拆分数据集
把data和target取一部分作为测试数据,剩下的作为训练数据
从sklearn库的model_selection模块中导入train_test_split函数,该函数用于将数据集划分为训练集和测试集。
from sklearn.model_selection import train_test_split
# test_size
# 整数:测试数据的数量
# 小数:测试数据的占比,一般比较小,0.2,0.3x_train, x_test, y_train, y_test = train_test_split(data,target,test_size=0.2)
x_train.shape, x_test.shape
# y_test 表示测试数据的真实结果
# y_pred:表示测试数据的预测结果
7.使用KNN算法
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
knn.score(x_test,y_test)
#0.33
#0.7以上:得分正常
#0.8以上:比较好
#0.9以上:非常好
3.3 预测年收入是否大于50K美元
1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入KNN算法
# 谷歌的机器学习库
from sklearn.neighbors import KNeighborsClassifier3.导入warnings模块,并设置警告过滤器为忽略所有警告
import warnings
warnings.filterwarnings(action='ignore')读取adults.csv文件,最后一列是年收入,并使用KNN算法训练模型,然后使用模型预测一个人的年收入是否大于50```python
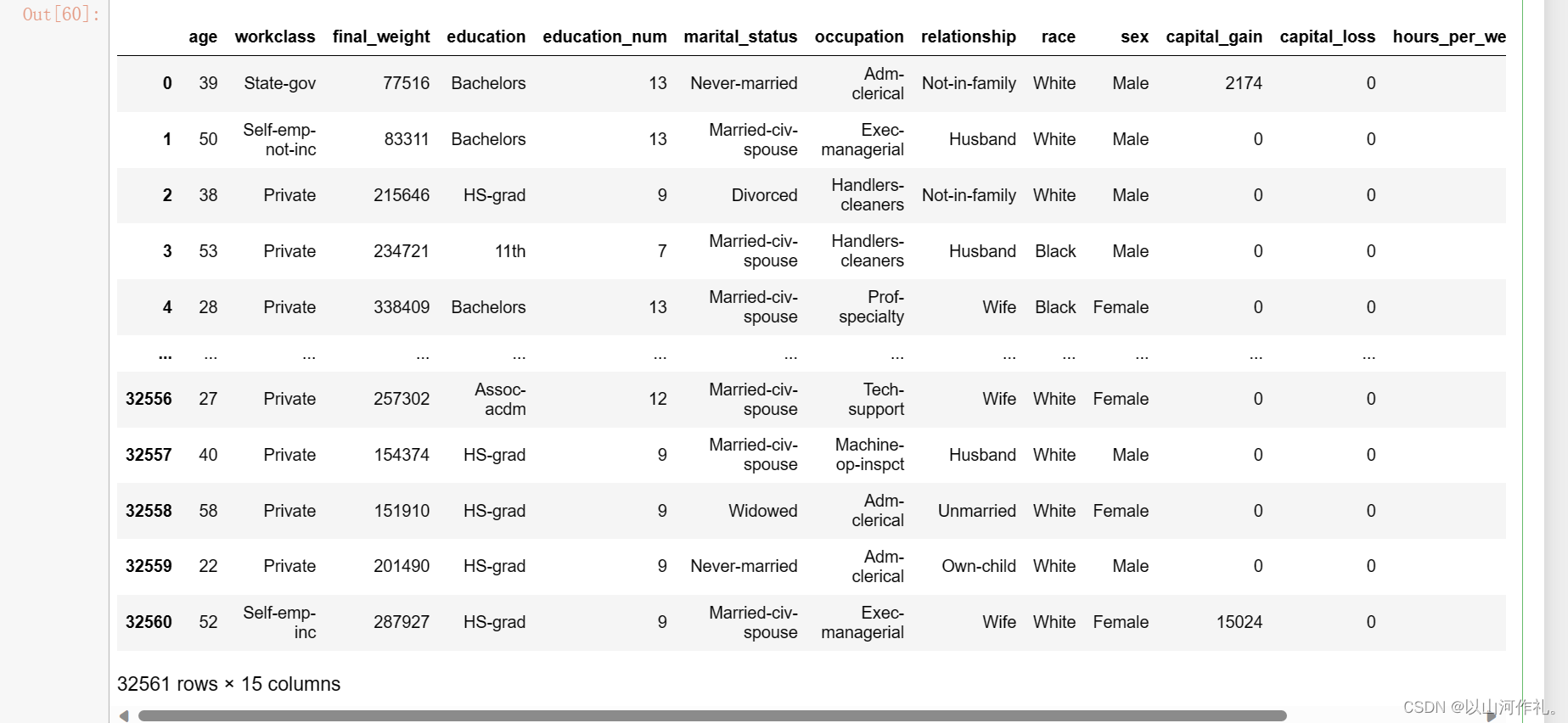
adults = pd.read_csv('../data/adults.csv')
adults
4.获取年龄age、教育程度education、职位workclass、每周工作时间hours_per_week 作为机器学习数据 获取薪水作为对应结果
data = adults[['age','education','workclass','hours_per_week']].copy()
target = adults['salary']
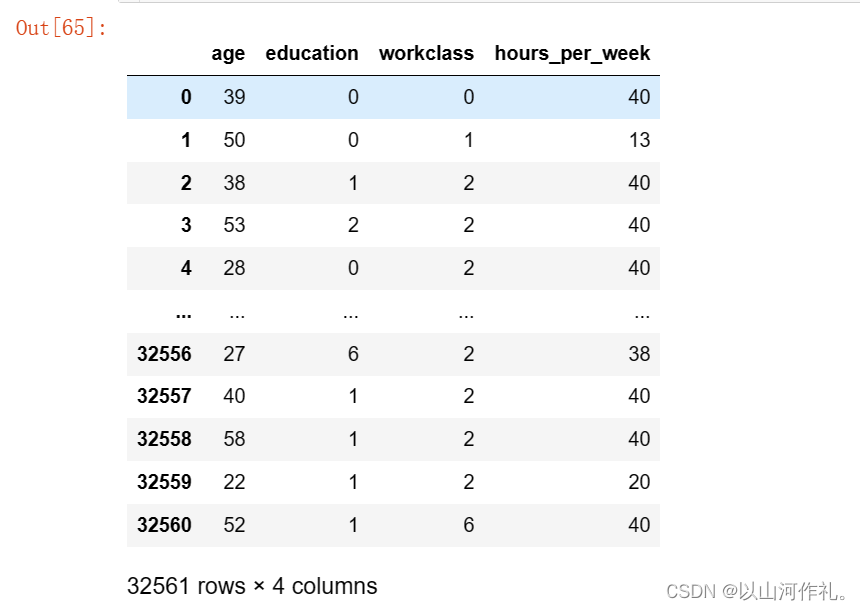
5.数据转换,将String/Object类型数据转换为int,用0,1,2,3…表示
使用factorize()函数
data['education'] = data['education'].factorize()[0]
data['workclass'] = data['workclass'].factorize()[0]
data
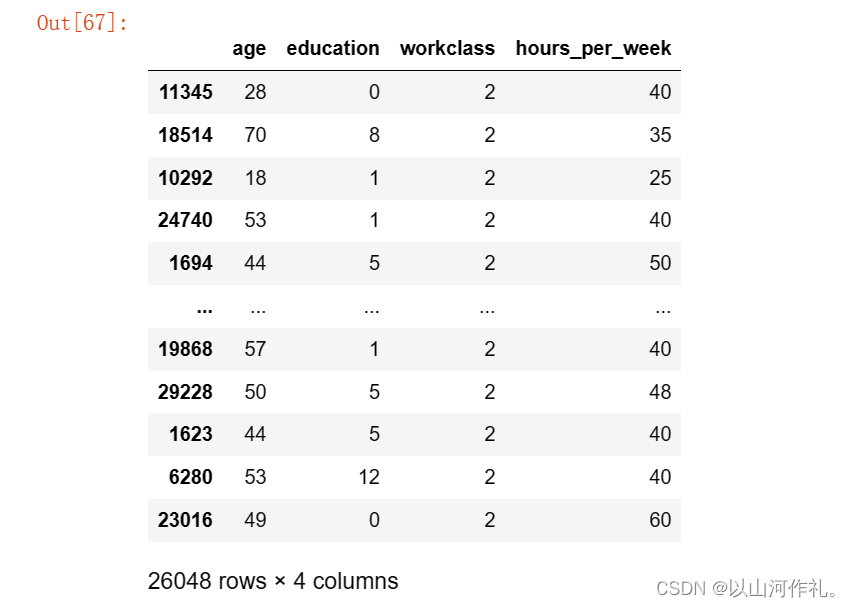
6.拆分数据集:训练数据和预测数据
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.2)
x_train
7.使用KNN算法
knn = KNeighborsClassifier()
knn.fit(x_train,y_train)
knn.score(x_test,y_test)

相关文章:
2.机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解
2️⃣机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解 个人简介一算法概述二算法思想2.1 KNN的优缺点 三实例演示3.1电影分类3.2使用KNN算法预测 鸢(yuan)尾花 的种类3.3 预测年收入是否大于50K美元 个人简介 🏘️&…...
WordPress顶部管理工具栏怎么添加一二级自定义菜单?
默认情况下,WordPress前端和后台页面顶部都有一个“管理工具栏”,左侧一般就是站点名称、评论、新建,右侧就是您好,用户名称和头像。那么我们是否可以在这个管理工具栏中添加一些一二级自定义菜单呢? 其实,…...
Linux安装ossutil工具且在Jenkins中执行shell脚本下载文件
测试中遇到想通过Jenkins下载OSS桶上的文件,要先在linux上安装ossutil工具,记录安装过程如下: 一、下载安装ossutil,使用命令 1.下载:wget https://gosspublic.alicdn.com/ossutil/1.7.13/ossutil64 2.一定要赋权限…...
Docker命令---搜索镜像
介绍 使用docker命令搜索镜像。 命令 docker search 镜像命令:版本号示例 以搜索ElasticSearch镜像为例 docker search ElasticSearch...
docker使用http_proxy配置代理
钢铁知识库,一个学习python爬虫、数据分析的知识库。人生苦短,快用python。 在内网服务器中,docker经常需要下载拉取镜像,但由于没有网络要么只能手动导入镜像包,又或者通过http_proxy代理到其它服务器下载。 解决方法…...
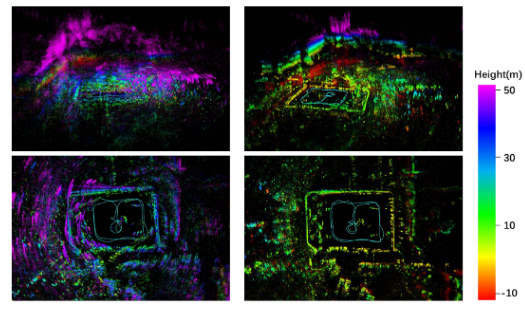
综述:自动驾驶中的 4D 毫米波雷达
论文链接:《4D Millimeter-Wave Radar in Autonomous Driving: A Survey》 摘要 4D 毫米波 (mmWave) 雷达能够测量目标的距离、方位角、仰角和速度,引起了自动驾驶领域的极大兴趣。这归因于其在极端环境下的稳健性以及出色的速度和高度测量能力。 然而…...
)
蓝桥杯:1.特殊日期(Java)
题目描述 对于一个日期,我们可以计算出年份的各个数位上的数字之和,也可以分别计算月和日的各位数字之和。 请问从1900年1月1日至9999年12月31日,总共有多少天,年份的数位数字之和等于月的数位数字之和加日的数位数字之和。 例如&…...
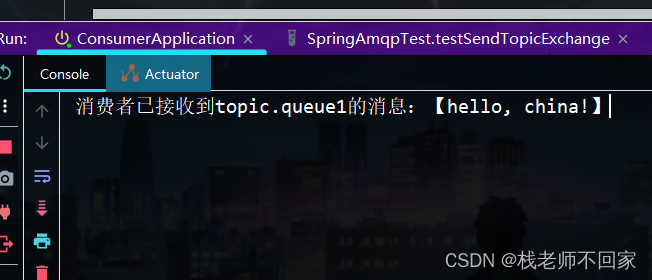
服务异步通讯之 SpringAMQP【微服务】
文章目录 一、初识 MQ1. 同步通讯2. 异步通讯3. MQ 常见框架 二、RabbitMQ 入门1. 概述和安装2. 常见消息模型3. 基础模型练习 三、SpringAMQP1. 简单队列模型2. 工作队列模型3. 发布订阅模型3.1 Fanout Exchange3.2 Direct Exchange3.3 Topic Exchange 一、初识 MQ 1. 同步通…...

LED闪烁
这段代码是用于STM32F10x系列微控制器的程序,主要目的是初始化GPIOA的Pin 0并使其按照特定的模式进行闪烁。下面是对这段代码的逐行解释: #include "stm32f10x.h":这一行包含了STM32F10x系列微控制器的设备头文件。这个头文件包含…...
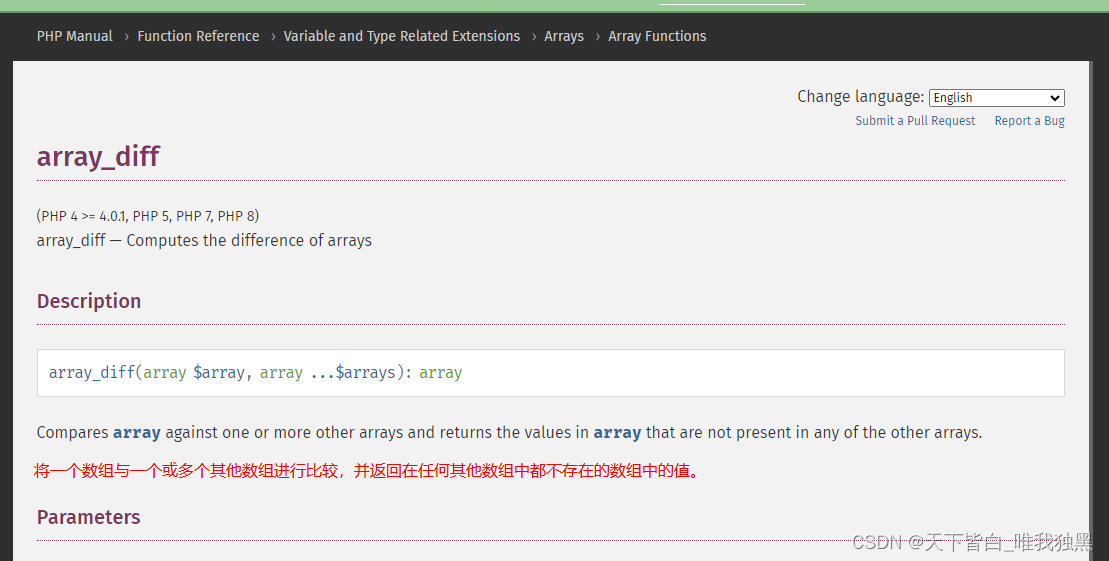
php array_diff 比较两个数组bug避坑 深入了解
今天实用array_diff出现的异常问题,预想的结果应该是返回 "integral_initiate">"0",实际没有 先看测试代码: $a ["user_name">"测","see_num">0,"integral_initiate&quo…...

c++中STL的vector简单实现
文章目录 vector构造函数 vector()拷贝构造 vector()析构函数 ~vector()iterator 的定义begin()与const版本end()与const版本增删改查尾插push_back()尾删pop_back()指定位置插入insert()指定位置删除 erase() operator[]与const版本容量增容reserve()设置容量 resize() 成员函…...

C# 更改Bitmap图像色彩模式
方法一:直接修改RGB的值 首先将BitmapData扫描线上的所有像素复制到字节数组中,然后遍历数组并对每个像素的RGB值进行修改,最后将修改后的像素值复制回BitmapData。这个过程不会影响原始的Bitmap对象,但会改变锁定的位图区域的数…...
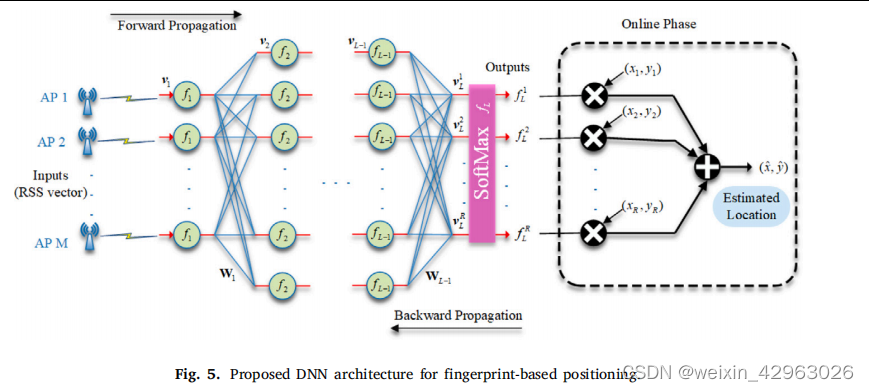
5.2 基于深度学习和先验状态的实时指纹室内定位
文献来源 Nabati M, Ghorashi S A. A real-time fingerprint-based indoor positioning using deep learning and preceding states[J]. Expert Systems with Applications, 2023, 213: 118889.(5.2_基于指纹的实时室内定位,使用深度学习和前一状态&…...

AIGC时代高效阅读论文实操
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…...
对网站进行打点(不要有主动扫描行为)
什么是打点? 简单来说就是获取一个演习方服务器的控制权限。 目的: 1. 上传一个一句话木马 2. 挖到命令执行 3. 挖到反序列化漏洞 4. 钓鱼 假设对“千峰”网站进行打点: 1. 利用平台 1. 利用各类平台: 天眼查-商业查询平…...
)
502. IPO(贪心算法+优先队列/堆)
整体思想:在满足可用资金的情况下,选择其中利润最大的业务,直到选到k个业务为止,注意k可能比n大。 每次选择完一个业务,可用资金都会变动,这是可选择的业务也会变化,因此每次将可选择的业务放在…...

设计模式篇---中介者模式
文章目录 概念结构实例总结 概念 中介者模式:用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显示地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。 就好比世界各个国家之间可能会产生冲突,但是当产…...

双端Diff算法
双端Diff算法 双端Diff算法指的是,在新旧两组子节点的四个端点之间分别进行比较,并试图找到可复用的节点。相比简单Diff算法,双端Diff算法的优势在于,对于同样的更新场景,执行的DOM移动操作次数更少。 简单 Diff 算法…...

react+antd,Table表头文字颜色设置
1、创建一个自定义的TableHeaderCell组件,并设置其样式为红色 const CustomTableHeaderCell ({ children }) > (<th style{{ color: "red" }}>{children}</th> ); 2、将CustomTableHeaderCell组件传递到Table组件的columns属性中的titl…...

2024年1月18日Arxiv最热NLP大模型论文:Large Language Models Are Neurosymbolic Reasoners
大语言模型化身符号逻辑大师,AAAI 2024见证文本游戏新纪元 引言:文本游戏中的符号推理挑战 在人工智能的众多应用场景中,符号推理能力的重要性不言而喻。符号推理涉及对符号和逻辑规则的理解与应用,这对于处理现实世界中的符号性…...

JetBrains IDE试用期重置全攻略:让30天试用无限循环的终极技巧
JetBrains IDE试用期重置全攻略:让30天试用无限循环的终极技巧 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains IDE试用期到期而焦虑吗?每次看到"试用期已结束"的…...

如何高效配置跨平台网盘直链解析工具:技术实现与实战指南
如何高效配置跨平台网盘直链解析工具:技术实现与实战指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

Bubble Navigation实战:构建现代化电商App导航系统的终极指南
Bubble Navigation实战:构建现代化电商App导航系统的终极指南 【免费下载链接】bubble-navigation 🎉 [Android Library] A light-weight library to easily make beautiful Navigation Bar with ton of 🎨 customization option. 项目地址…...

3个关键步骤解锁Switch隐藏功能:TegraRcmGUI图形化注入工具完整指南
3个关键步骤解锁Switch隐藏功能:TegraRcmGUI图形化注入工具完整指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI 想为你的Nintendo Switch解锁…...

从失败案例看全球化内容服务的合规架构与自动化风控实践
1. 项目概述与背景解析最近在和一些做全球化内容分发或者跨国协作项目的朋友交流时,大家普遍会提到一个词:“内容合规性审查”。这听起来像是一个法务或者运营的术语,但对我们这些搞技术、做开发的人来说,它背后其实是一整套复杂的…...

NUS 提出 SkillGraph:让多模态多智能体边协作边进化
📌 一句话总结: 本文提出 SkillGraph,将动态通信拓扑与自进化 Skill Bank 闭环耦合,让 VMAS 根据图像、问题和当前技能自动组织协作。在四个多模态基准、五种 MAS 结构和四类 VLM 上均稳定提升,最高平均提升约 3.0%。…...

基于wechat_bot_sdk的微信机器人开发:从协议模拟到工程化实践
1. 项目概述与核心价值最近在折腾一个需要对接微信消息通知的项目,发现市面上很多现成的机器人框架要么太重,要么封装得过于“黑盒”,想改点东西得扒好几层源码。后来在GitHub上翻到了waro163/wechat_bot_sdk这个项目,看名字就知道…...

基于LangChain构建AI智能体:从核心架构到生产部署实战
1. 项目概述与核心价值最近在GitHub上看到一个名为“GenAI_Agents”的项目,作者是NirDiamant。这个项目名本身就很有意思,它直指当前AI领域最火热、也最具想象力的方向之一:智能体(Agents)。简单来说,这个项…...

启扬RK3568核心板如何赋能智能炒菜机:从嵌入式主控到AI烹饪
1. 项目概述:当嵌入式核心板遇上智能炒菜机在餐饮后厨这个看似传统,实则对效率、成本和一致性要求极高的领域,痛点一直非常明确。人工炒菜,老师傅的手艺固然可贵,但出餐速度受限于体力,菜品口味因厨师状态、…...
物理层设计解析)
5G NR(新空口)物理层设计解析
5G NR(新空口)物理层设计解析 在无线通信技术的演进过程中,5G NR(新空口)作为第五代移动通信技术的核心组成部分,其物理层设计承载着提升数据传输速率、降低时延、增强连接密度等多重目标。本文将围绕5G NR…...