使用Flink处理Kafka中的数据
目录
使用Flink处理Kafka中的数据
前提:
一, 使用Flink消费Kafka中ProduceRecord主题的数据
具体代码为(scala)
执行结果
二, 使用Flink消费Kafka中ChangeRecord主题的数据
具体代码(scala)
具体执行代码①
重要逻辑代码②
执行结果为:
使用Flink处理Kafka中的数据
前提:
创建主题 : ChangeRecord , ProduceRecord
使用kafka-topics.sh --zookeeper bigdata1:2181/kafka --list 查看主题
kafka-topics.sh --zookeeper bigdata1:2181/kafka --list

然后开启数据生成器
./jnamake_data_file_v1
一, 使用Flink消费Kafka中ProduceRecord主题的数据
启动Flume a1, a1为所赋予的名称
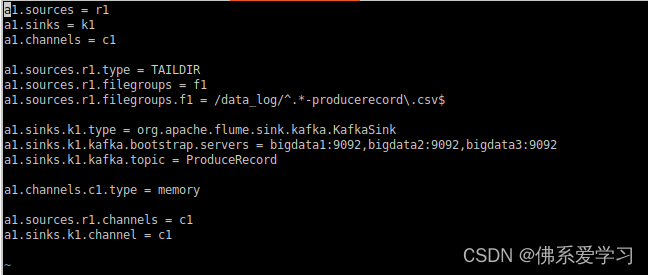
flume-ng agent --conf-file /opt/module/flume-1.9.0/job/flume-to-kafka-producerecord--name a1 -Dflume.root.logger=DEBUG,console
启动一个Kafka的消费者(consumer)来消费(读取)Kafka中的消息
kafka-console-consumer.sh --bootstrap-server bigdata1:9092 --from-beginning --topic ProduceRecord
编写Scala工程代码,使用Flink消费Kafka中的数据并进行相应的数据统计计算。
一, 使用Flink消费Kafka中ProduceRecord主题的数据,统计在已经检验的产品中,各设备每五分钟生产产品总数,将结果存入Redis中,key值为“totalproduce”,value值为“设备id,最近五分钟生产总数”。使用redis cli以HGETALL key方式获取totalproduce值,将结果截图粘贴至对应报告中,需两次截图,第一次截图和第二次截图间隔五分钟以上,第一次截图放前面,第二次放后面;
注:ProduceRecord主题,生产一个产品产生一条数据;
change_handle_state字段为1代表已经检验,0代表未检验;
时间语义使用Processing Time。
具体代码为(scala):
package gyflink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.{FlinkJedisClusterConfig, FlinkJedisPoolConfig}
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}import java.util.Properties
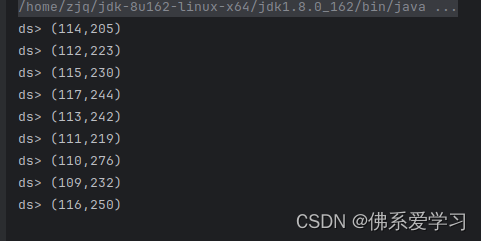
object test1{def main(args: Array[String]): Unit = {// 创建Flink流执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment// 设置并行度env.setParallelism(1)//指定时间语义env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)// kafka的属性配置val properties = new Properties()properties.setProperty("bootstrap.servers","bigdata1:9092,bigdata2:9092,bigdata3:9092")properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer")properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringSerializer")properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringSerializer")properties.setProperty("auto.offset.reset","earliest")// 读取kafka数据val FlinkKafkaConsumer = new FlinkKafkaConsumer[String]("ProduceRecord", new SimpleStringSchema(), properties)val text = env.addSource(FlinkKafkaConsumer)// TODO 使用flink算子对数据进行处理// topic的一条数据:2214,117,0002,2024-01-09 11:08:53,2024-01-09 11:08:53,2024-01-09 11:08:59,15897,1900-01-01 00:00:00,188815,0val inputMap = text.map(link => {val arr = link.split(",") // 使用‘,’作为分割符(arr(1).toInt, arr(9).toInt) // 下标取出第1个和第9个值}).filter(_._2 == 1) // 筛选条件:把第二个元素等于1.keyBy(_._1) // 将第一个元素作为key值.timeWindow(Time.minutes(5)) // 间隔5分钟进行计算.sum(1)inputMap.print("ds")// TODO 与 Redis 数据库进行连接// 创建Redis数据库的连接属性val config: FlinkJedisPoolConfig = new FlinkJedisPoolConfig.Builder() // 创建一个FlinkJedisPoolConfig对象.setHost("bigdata1") // 设置Redis数据库的主机地址.setPort(6379) // 设置Redis数据库的端口号.build()// 创建RedisSink对象,并将数据写入Redis中val redisSink = new RedisSink[(Int, Int)](config, new MyRedisMapper) // MyRedisMapper是一个自定义的映射器,将flink的数据转换为Redis的格式// 发送数据inputMap.addSink(redisSink) // 将flink的数据流和Redis数据库连接起来// 执行Flink程序env.execute("kafkaToRedis") // 向flink提交作业,开始执行}// 根据题目要求class MyRedisMapper extends RedisMapper[(Int, Int)] { // RedisMapper的方法是是将把flink的数据存储为Redis的存储格式//这里使用RedisCommand.HSET不用RedisCommand.SET,前者创建RedisHash表后者创建Redis普通的String对应表override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.HSET,"totalproduce")override def getKeyFromData(t: (Int, Int)): String = t._1 + ""override def getValueFromData(t: (Int, Int)): String = t._2 + ""}}执行结果:

二, 使用Flink消费Kafka中ChangeRecord主题的数据
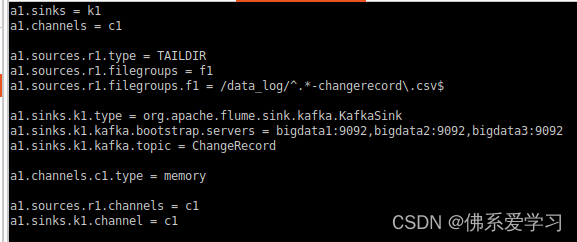
启动Flume a1, a1为所赋予的名称
flume-ng agent --conf-file /opt/module/flume-1.9.0/job/flume-to-kafka-changerecord --name a1 -Dflume.root.logger=DEBUG,console
启动一个Kafka的消费者(consumer)来消费(读取)Kafka中的消息
kafka-console-consumer.sh --bootstrap-server bigdata1:9092 --from-beginning --topic ChangeRecord
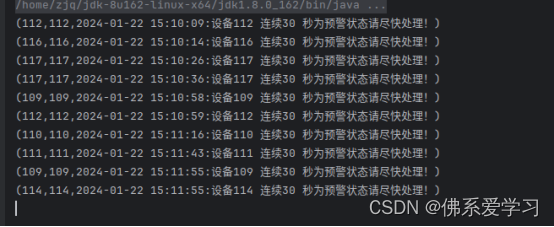
二, 使用Flink消费Kafka中ChangeRecord主题的数据,当某设备30秒状态连续为“预警”,输出预警信息。当前预警信息输出后,最近30秒不再重复预警(即如果连续1分钟状态都为“预警”只输出两次预警信息)。将结果存入Redis中,key值为“warning30sMachine”,value值为“设备id,预警信息”。使用redis cli以HGETALL key方式获取warning30sMachine值,将结果截图粘贴至对应报告中,需两次截图,第一次截图和第二次截图间隔一分钟以上,第一次截图放前面,第二次放后面;
注:时间使用change_start_time字段,忽略数据中的change_end_time不参与任何计算。忽略数据迟到问题。
Redis的value示例:115,2022-01-01 09:53:10:设备115 连续30秒为预警状态请尽快处理!
(2022-01-01 09:53:10 为change_start_time字段值,中文内容及格式必须为示例所示内容。)
具体代码(scala):
具体执行代码①:
package gyflinkimport org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}import java.text.SimpleDateFormat// 定义一个Change类,这个类里面定义四个参数,这四个参数对应着分割后的元素
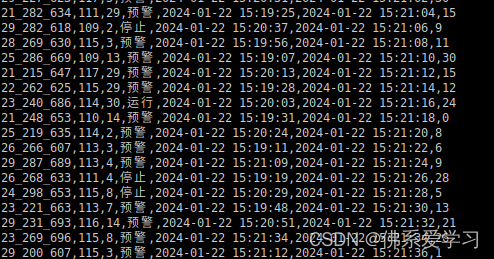
case class Change(ChangeId: Int, ChangeState:String, ChangeTime:String, timeStamp:Long)object flink_kafka_to_redis2 {def main(args: Array[String]): Unit = {/** 25_299_649,111,13,预警,2024-01-09 11:08:08,2024-01-09 11:08:52,15ChangeRecord的日志信息: 22_220_698,114,29,预警,2024-01-09 11:07:42,2024-01-09 11:09:00,15* */// TODO 创建flink的执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1) // 设置并行度为1,单节点运行// TODO 与kafka进行连接val kafkaSource = KafkaSource.builder().setBootstrapServers("bigdata1:9092") // 设置kafka服务器地址.setTopics("ChangeRecord") // flink需要订阅的主题.setValueOnlyDeserializer(new SimpleStringSchema()) // 设置只对value反序列化器,由于kafka使用网络进行传输,发送的是序列化数据,所以flink要做反序列化操作.setStartingOffsets(OffsetsInitializer.latest()) // 设置读取偏移量,从kafka最新的记录开始读取.build()// TODO 读取kafka数据,设置无水印val produceDataStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka_flink_redis")// kafka属性 水印设置 名称val kafka_value = produceDataStream.map(x => {val data = x.split(",") // 每一条记录以‘,’进行分割val timestamp = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(data(4)).getTime // 将string类型的时间转换为timestamp类型,形成时间戳Change(data(1).toInt, data(3), data(4),timestamp) // 输出:Change(110,预警,2024-01-18 14:09:36,1705558176000)})// 设置水位线val waterTimeStream = kafka_value.assignTimestampsAndWatermarks( // 创建一个新的watermark策略,并应用与kafka数据流// 流过来的数据时间是递增的,将迟到的数据直接丢弃WatermarkStrategy.forMonotonousTimestamps() // 用于处理单调递增的时间戳(升序的时间戳).withTimestampAssigner(new SerializableTimestampAssigner[Change] { // 定义了一个时间戳分配器,从每个事件中提取时间戳override def extractTimestamp(change: Change, recordTimestamp: Long): Long = { // 定义了两个参数,第一个参数表示Change类型,第二个是个Long类型,这个函数返回值为Long的change.timeStamp // 从 change(Change) 提取timeStamp的参数}}))// 开始处理数据流val resultSteam = waterTimeStream.keyBy(_.ChangeId) // 按照ChangeId进行分组.process(new flink_kafka_to_redis2_Process) // 调用处理类// 与Redis建立连接val JedisPoolConfig = new FlinkJedisPoolConfig.Builder().setHost("bigdata1").setPort(6379)// .setDatabase(0).build()val Warning30Machine = new RedisMapper[(Int, String)] {override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.HSET, "warning30sMachine")override def getKeyFromData(t: (Int, String)): String = t._1.toStringoverride def getValueFromData(t: (Int, String)): String = t._2}// 建立Redis通道val redisSink = new RedisSink[(Int, String)](JedisPoolConfig, Warning30Machine)// 将结果流加入到通道resultSteam.addSink(redisSink)resultSteam.print()env.execute()}}重要逻辑代码②:
package gyflink
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.util.Collectorclass flink_kafka_to_redis2_Process extends KeyedProcessFunction[Int,Change, (Int, String)] {// 键类型 输入类型 输出类型// 用于保存上一条的记录的状态private lazy val lastState:ValueState[Change] = getRuntimeContext.getState( // 延迟初始化的私有变量new ValueStateDescriptor[Change]("lastState",classOf[Change]))override def processElement(Change: Change, ctx: KeyedProcessFunction[Int, Change, (Int, String)]#Context, out: Collector[(Int, String)]): Unit = {// 获取定时服务val timerService = ctx.timerService()// 如果是预警信息if (Change.ChangeState.equals("预警")){if (lastState.value() == null){lastState.update(Change)timerService.registerEventTimeTimer(Change.timeStamp + 30000)}} else {// 出现不是预警信息,删除存在的定时器,如果不存在定时器会忽略if (lastState.value() != null){timerService.deleteEventTimeTimer(lastState.value().timeStamp + 30000)lastState.update(null)}}}// 定时器逻辑override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Int, Change, (Int, String)]#OnTimerContext, out: Collector[(Int, String)]): Unit = {val record = lastState.value()// out.collect((record.ChangeId,s"${record.ChangeTime}:设备${record.ChangeId}连续30秒为预警状态请尽快处理!"))out.collect(record.ChangeId,s"${record.ChangeId},${record.ChangeTime}:设备${record.ChangeId} 连续30 秒为预警状态请尽快处理!")lastState.update(null)}}执行结果为:

相关文章:
使用Flink处理Kafka中的数据
目录 使用Flink处理Kafka中的数据 前提: 一, 使用Flink消费Kafka中ProduceRecord主题的数据 具体代码为(scala) 执行结果 二, 使用Flink消费Kafka中ChangeRecord主题的数据 具体代码(scala) 具体执行代码① 重要逻…...
跟着pink老师前端入门教程-day07
去掉li前面的项目符号(小圆点) 语法:list-style: none; 十五、圆角边框 在CSS3中,新增了圆角边框样式,这样盒子就可以变成圆角 border-radius属性用于设置元素的外边框圆角 语法:border-radius:length…...

Pixelmator Pro Mac版 v3.5 图像处理软件 兼容 M1/M2
在当今数字化时代,图像编辑软件成为了许多人必备的工具之一。无论您是摄影师、设计师还是普通用户,您都需要一款功能强大、易于使用的图像编辑软件来处理和优化您的照片和图像。而Pixelmator Pro for Mac正是满足这一需求的理想选择。 Pixelmator Pro f…...
《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(15)-Fiddler弱网测试,知否知否,应是必知必会
1.简介 现在这个时代已经属于流量时代,用户对于App或者小程序之类的操作界面的数据和交互的要求也越来越高。对于测试人员弱网测试也是需要考验自己专业技术能力的一种技能。一个合格的测试人员,需要额外关注的场景就远不止断网、网络故障等情况了。还要…...
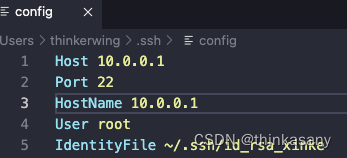
【vscode】远程资源管理器自动登录服务器保姆级教程
远程资源管理器自动登录服务器 介绍如何配置本地生成rsa服务端添加rsa.pub配置config文件 介绍 vscode SSH 保存密码自动登录服务器 对比通过账号密码登录,自动连接能节约更多时间效率,且通过vim修改不容易发现一些换行或者引号导致的错误,v…...

写点东西《Javascript switch 语句的替代方法》
写点东西《Javascript switch 语句的替代方法》 那么 switch 语句有什么问题? Object Literal 查找的替代方法 将我们学到的东西变成一个实用函数 您需要的一切都在一个地方# [](#javascript-version) Javascript 版本Tyepscript version🌟更多精彩 本文…...
)
python学习笔记10(循环结构2)
(一)循环结构2 1、扩展模式 语法: for 循环变量 in 遍历对象: 语句块1 else: 语句块2 说明:else在循环结束后执行,通常和break和continue结合使用 2、无限循环while while 表达式: 语句块…...

Codefroces 191A - Dynasty Puzzles
思路 d p dp dp d p i , j dp_{i,j} dpi,j 表示以 i i i 开始以 j j j 结尾的最长长度。方程: d p j , r m a x ( d p j , l , d p j , l l e n g t h l , r ) dp_{j,r}max(dp_{j,l}\;,\;dp_{j,l}length_{l,r}) dpj,rmax(dpj,l,dpj,llengthl,r) 有点区…...

HIVE中关联键类型不同导致数据重复,以及数据倾斜
比如左表关联键是string类型,右表关联键是bigint类型,关联后会出现多条的情况 解决方案: 关联键先统一转成string类型再进行关联 原因: 根据HIVE版本不同,数据位数上限不同, 低版本的超过16位会出现这种…...

CRM系统是如何解决企业的痛点的?
在当今竞争激烈的商业世界中,客户关系管理(CRM)数字化转型已经成为大企业成功的重要秘诀。大型跨国公司如亚马逊、苹果和微软等已经在CRM数字化方面走在了前列,实现了高度个性化的客户体验,加强了客户忠诚度。 然而&a…...

系统架构14 - 软件工程(2)
需求工程 需求工程软件需求两大过程三个层次业务需求(business requirement)用户需求(user requirement)功能需求 (functional requirement)非功能需求 概述活动阶段需求获取基本步骤获取方法 需求分析三大模型数据流图数据字典DD需求定义方法 需求验证需求管理需求基线变更控制…...

vue封装接口
目录 封装接口前缀 配置逻辑 接口存放文件 配置代理 获取数据方法 封装接口前缀 config.js const serverConfig {baseURL: "https://xxx.xxxxxxxx.com/api", // 请求基础地址,可根据环境自定义useTokenAuthorization: false, // 是否开启 token 认证};export …...
Dell戴尔XPS 8930笔记本电脑原装Win10系统 恢复出厂预装OEM系统
链接:https://pan.baidu.com/s/1eaTQeX-LnPJwWt3fBJD8lg?pwdajy2 提取码:ajy2 原厂系统自带所有驱动、出厂主题壁纸、系统属性联机支持标志、系统属性专属LOGO标志、Office办公软件、MyDell等预装程序 文件格式:esd/wim/swm 安装方式&am…...
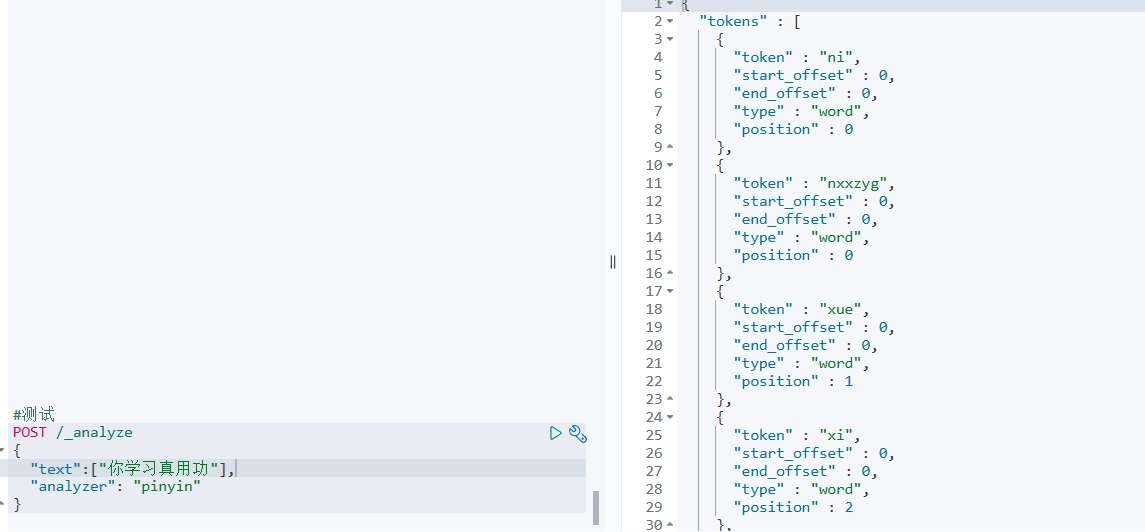
elasticsearch的拼音分词器安装
安装拼音分词器 第一步:下载 要实现根据字母做补全,就必须对文档按照拼音分词。在 GitHub 上恰好有 elasticsearch 的拼音分词插件。地址: 仓管的主页: https://github.com/infinilabs/analysis-pinyin 仓管的版本页 https:…...

2024阿里云优惠,云服务器61元一年起
2024年最新阿里云主机价格,最低配置2核2G3M起步,只要61元一年,还可以在阿里云CLUB中心领券 aliyun.club 专用满减优惠券。 1、云服务器ECS经济型e实例2核2G、3M固定带宽99元一年 2、轻量应用服务器2核2G3M带宽轻量服务器一年61元 3、阿里云轻…...
基于SpringBoot+Vue实现的社区养老管理平台(源码+数据库脚本+设计文档+部署视频)
系统介绍 基于SpringBootVue实现的社区养老服务管理平台采用springboot以及vue框架技术,实现了社区养老管理系统,实现了对养老院的员工、管理员对入住的老人及其健康档案实现信息化管理。 技术选型 开发工具:idea2020.3Webstorm2020.3(其他…...
【漏洞复现】CloudPanel makefile接口远程命令执行漏洞(CVE-2023-35885)
文章目录 前言声明一、CloudPanel 简介二、漏洞描述三、影响版本四、漏洞复现五、修复建议 前言 CloudPanel 是一个基于 Web 的控制面板或管理界面,旨在简化云托管环境的管理。它提供了一个集中式平台,用于管理云基础架构的各个方面,包括 &a…...

【Spring Boot 3】【Redis】集成Redisson
【Spring Boot 3】【Redis】集成Redisson 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...
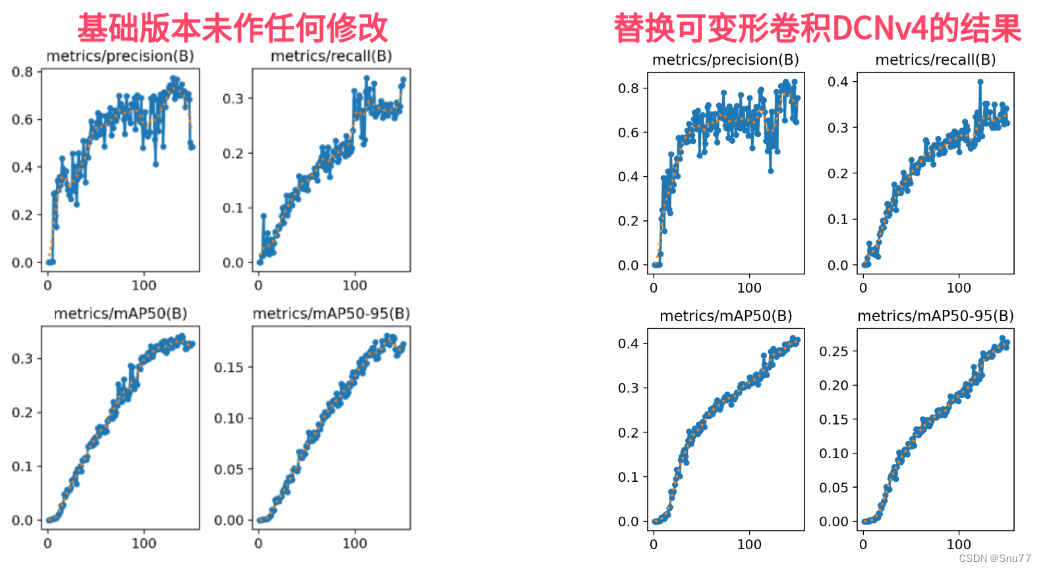
YOLOv8改进 | Conv篇 | 2024.1月最新成果可变形卷积DCNv4(适用检测、Seg、分类、Pose、OBB)
一、本文介绍 本文给大家带来的改进机制是2024-1月的最新成果DCNv4,其是DCNv3的升级版本,效果可以说是在目前的卷积中名列前茅了,同时该卷积具有轻量化的效果!一个DCNv4参数量下降越15Wparameters左右,。它主要通过两个方面对前一版本DCNv3进行改进:首先,它移除了空间聚…...

理解反向代理
反向代理是一个不可或缺的组件。 它在客户端和服务器之间充当中介,提高了安全性、负载平衡和应用性能。 一、反向代理简介 反向代理是一种服务器,它位于客户端和后端服务器之间。与常见的(正向)代理不同,反向代理代表…...

古星图导航测试:波利尼西亚航海术的AI复现
跨越千年的航海智慧与现代测试的碰撞在科技高度发达的今天,GPS、北斗等卫星导航系统已成为我们出行、航海、航空等领域不可或缺的工具。然而,在数千年前,太平洋上的波利尼西亚人却凭借着对星空的深刻理解和独特的航海技术,在广袤无…...

ARM Cortex-M调试陷阱:Flash断点残留如何导致Hard Fault
1. 项目概述:一次由断点引发的“血案”与深度剖析最近在支持一个基于NXP KW36(Cortex-M0内核)的BLE项目时,我遇到了一个极其隐蔽且令人抓狂的问题。同一批次的板子,烧录完全相同的固件,绝大多数运行正常&am…...

GitHub下载太慢?3分钟学会Fast-GitHub加速插件的终极解决方案
GitHub下载太慢?3分钟学会Fast-GitHub加速插件的终极解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 作为一名…...

Ubuntu系统部署Cursor AI编辑器:从安装配置到实战优化全指南
1. 项目概述:在Ubuntu上快速部署Cursor AI编辑器最近在开发者圈子里,Cursor这款AI驱动的代码编辑器热度持续攀升。作为一个深度依赖Ubuntu进行日常开发的程序员,我自然也第一时间尝试了在Ubuntu 22.04 LTS上安装和配置Cursor。整个过程比预想…...

基于M6801SPCS的闭环步进电机控制:从PID三环到工业应用实战
1. 项目概述:当步进电机遇上闭环,工业自动化的一次精密升级在工业自动化领域,步进电机因其结构简单、控制方便、成本低廉,一直是许多点位控制、低速高精度场景的宠儿。但传统开环步进有个“阿喀琉斯之踵”——丢步。一旦负载突变或…...

ElevenLabs动画配音语音交付危机预警,紧急修复唇动不同步、语速断层、多语言混读错位的6大实时响应方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs动画配音语音交付危机的本质溯源 当动画制作团队依赖 ElevenLabs API 实时生成角色语音时,突然出现的 429 Too Many Requests 响应、TTS 音频静音片段、以及语音情感断层现象&…...

Composer依赖管理可视化:saketsarin/composer-web工具详解与实践指南
1. 项目概述:一个为Composer量身定制的Web管理界面如果你是一名PHP开发者,那么对Composer一定不会陌生。它是PHP生态的基石,一个强大的依赖管理工具,让我们能够通过一条简单的命令,将成千上万的第三方库引入到自己的项…...

解放双手还是重复劳动?AzurLaneAutoScript 让你的碧蓝航线游戏体验全面升级
解放双手还是重复劳动?AzurLaneAutoScript 让你的碧蓝航线游戏体验全面升级 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoS…...

【MQTT】paho.mqtt.c 库的“异步/同步模式选择、编译配置与实战” 深度解析,附嵌入式客户端开发指南
1. MQTT与paho.mqtt.c库的核心价值 在物联网设备通信领域,MQTT协议凭借其轻量级、低功耗和发布/订阅模式的优势,已经成为设备间通信的事实标准。而Eclipse Paho项目提供的paho.mqtt.c库,则是C语言开发者实现MQTT客户端功能的首选工具包。这个…...

TalkingHeads开源项目:基于扩散模型的AI人脸说话视频生成技术详解
1. 项目概述:当AI学会“眉目传情” 最近在折腾一个挺有意思的开源项目,叫TalkingHeads。简单来说,它能让一张静态的人脸照片“活”过来,不仅能根据你输入的音频或文本生成口型同步的说话视频,还能让视频里的人做出各种…...