关于缓存 db redis local 取舍之道
文章目录
- 前言
- 一、影响因素
- 二、db or redis or local
- 1.db
- 2.redis
- 3. local
- 三、redisson 和 CaffeineCache 封装
- 3.1 redisson
- 3.1.1 maven
- 3.1.2 封装
- 3.1.3 使用
- 3.2 CaffeineCache
- 3.1.1 maven
- 3.1.2 封装
- 3.1.3 使用
- 总结
前言
让我们来聊一下数据缓存,它是如何为我们带来快速的数据响应的。你知道吗,为了提高数据的读取速度,我们通常会引入数据缓存。但是,你知道吗,不是所有的数据都适合缓存,有些数据更适合直接从数据库查询。现在,我们就来一起讨论一下,什么样的数据适合直接从数据库查询,什么样的数据适合从缓存中读取。这将有助于我们更好地利用缓存,提高系统的性能。让我们开始吧!
一、影响因素
当涉及到数据查询和缓存时,有几个因素可以考虑来确定什么样的数据适合直接从数据库查询,什么样的数据适合从缓存中读取。
-
访问频率:如果某个数据被频繁访问,且对实时性要求不高,那么将其缓存在内存中会显著提高响应速度。这样的数据可以是经常被查询的热点数据,比如网站的热门文章、商品信息等。
-
数据更新频率:如果某个数据经常发生更新,那么将其缓存可能导致缓存和数据库中的数据不一致。对于这种情况,最好直接从数据库中查询最新数据。比如用户个人信息、订单状态等经常变动的数据。
-
数据大小:较大的数据对象,如图片、视频等,由于其体积较大,将其缓存到内存中可能会占用大量资源。这种情况下,可以将这些数据存储在分布式文件系统或云存储中,并通过缓存存储其访问路径或标识符。
-
数据一致性:一些数据在不同地方的多个副本可能会导致一致性问题。对于需要保持强一致性的数据,建议直接从数据库查询。而对于可以容忍一定程度的数据不一致的场景,可以考虑将数据缓存。
-
查询复杂度:某些复杂的查询操作可能会消耗大量的计算资源和时间,如果这些查询结果需要频繁访问,可以将其缓存,避免重复计算,提高响应速度。
需要注意的是,数据缓存并非适用于所有情况。缓存的使用需要谨慎,需要权衡数据的实时性、一致性和存储成本等方面的需求。此外,对于缓存数据的更新和失效策略也需要考虑,以确保缓存数据的准确性和及时性。
综上所述,数据适合直接从数据库查询还是缓存读取,取决于数据的访问频率、更新频率、大小、一致性要求和查询复杂度等因素。在实际应用中,需要根据具体情况进行综合考虑和合理选择。
二、db or redis or local
1.db
- 查询复杂度低
- 字段少
- sql执行效率高
- 实时性高
通常数据库适合查询字典类型数据,如类似 key value 键值对,数据更新频繁,实时性高的数据。
对于sql效率高的查询,redis查询不一定比db查询快。
2.redis
- 查询复杂度高
- 字段相对不多
- 实时性低
Redis适合查询复杂度较高、实时性要求较低的数据。当SQL查询效率较低,或者需要进行字段code和value的转换存储时,Redis可以提供更高效的查询方式。不过,需要注意的是,Redis的主要瓶颈在于数据的序列化和反序列化过程。如果数据量较大,包含大量字段或者数据量巨大,那么Redis的查询速度可能不一定比数据库快,当然此时数据库本身执行效率也低。在这种情况下,我们需要综合考虑数据的复杂度、实时性要求以及数据量的大小,选择最适合的查询方式。有时候,可能需要在数据库和Redis之间进行权衡和折中,以找到最佳的性能和效率平衡点。因此,为了提高查询速度,我们需要根据具体的业务需求和数据特性,选择合适的存储和查询方案。
3. local
- 查询复杂度高
- 字段多
- 实时性低
本地缓存通常是最快的。它可以在内存中直接读取数据,速度非常快。然而,由于受限于内存大小,本地缓存的数据量是有限的。对于那些数据库和Redis难以处理的大型数据,我们可以考虑使用本地缓存。通过将一部分频繁访问的数据存储在本地缓存中,可以大大提高系统的响应速度。这样,我们可以在不牺牲太多内存资源的情况下,快速获取到需要的数据。当然,需要注意的是,由于本地缓存的数据是存储在内存中的,所以在服务器重启或缓存过期时,需要重新从数据库或Redis中加载数据到本地缓存中。因此,在使用本地缓存时,需要权衡数据的大小、更新频率以及内存资源的限制,以获得最佳的性能和可用性。
三、redisson 和 CaffeineCache 封装
提供缓存查询封装,查询不到时直接查数据库后存入缓存。
3.1 redisson
3.1.1 maven
<dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId></dependency>
3.1.2 封装
import cn.hutool.core.util.ObjectUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import com.cuzue.common.core.exception.BusinessException;
import com.cuzue.dao.cache.redis.RedisClient;
import org.redisson.api.RBucket;
import org.redisson.api.RKeys;
import org.redisson.api.RedissonClient;import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.function.Supplier;public class RedisCacheProvider {private static RedissonClient redissonClient;public RedisCacheProvider(RedissonClient redissonClient) {this.redissonClient = redissonClient;}/*** 从redissonClient缓存中取数据,如果没有,查数据后存入** @param key redis key* @param dataFetcher 获取数据* @param ttl 缓存时间* @param timeUnit 缓存时间单位* @param <T>* @return 数据*/public <T> List<T> getCachedList(String key, Supplier<List<T>> dataFetcher, long ttl, TimeUnit timeUnit) {if (ObjectUtil.isNotNull(redissonClient)) {// 尝试从缓存中获取数据List<T> cachedData = redissonClient.getList(key);if (cachedData.size() > 0) {// 缓存中有数据,直接返回return cachedData;} else {// 缓存中没有数据,调用数据提供者接口从数据库中获取List<T> data = dataFetcher.get();cachedData.clear();cachedData.addAll(data);// 将数据存入缓存,并设置存活时间// 获取 bucket 对象,为了设置过期时间RBucket<List<T>> bucket = redissonClient.getBucket(key);// 为整个列表设置过期时间bucket.expire(ttl, timeUnit);// 返回新获取的数据return data;}} else {throw new BusinessException("redissonClient has not initialized");}}/*** 删除缓存** @param key redis key*/public void deleteCachedList(String systemName, String key) {if (ObjectUtil.isNotNull(redissonClient)) {RKeys keys = redissonClient.getKeys();keys.deleteByPattern(key);} else {throw new BusinessException("redis client has not initialized");}}
}
3.1.3 使用
启动类添加:@Import({RedissonConfig.class})
直接引用:
@Resource
private RedissonClient redissonClient;//缓存数据获取
public List<MatMaterialsResp> listCache(ListQO qo) {RedisCacheProvider cache = new RedisCacheProvider(redissonClient);List<MatMaterialsResp> resps = cache.getCachedList("testList", () -> {// 缓存数据查询}, 20, TimeUnit.SECONDS);return resps;
}
3.2 CaffeineCache
也可以使用hashMap
3.1.1 maven
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.0.5</version></dependency>
3.1.2 封装
CaffeineCache<K, V>
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.Weigher;import java.util.concurrent.TimeUnit;
import java.util.function.Function;public class CaffeineCache<K, V> {private final Cache<K, V> cache;/*** 不过期缓存** @param maxSize 缓存条目数量 注意对象大小不要超过jvm内存*/public CaffeineCache(long maxSize) {this.cache = Caffeine.newBuilder().maximumSize(maxSize).build();}/*** 初始化Caffeine** @param maxSize* @param expireAfterWriteDuration* @param unit*/public CaffeineCache(long maxSize, long expireAfterWriteDuration, TimeUnit unit) {this.cache = Caffeine.newBuilder().maximumSize(maxSize).expireAfterWrite(expireAfterWriteDuration, unit).build();}/*** 初始化Caffeine 带权重** @param maxSize* @param weigher 权重* @param expireAfterWriteDuration* @param unit*/public CaffeineCache(long maxSize, Weigher weigher, long expireAfterWriteDuration, TimeUnit unit) {this.cache = Caffeine.newBuilder().maximumSize(maxSize).weigher(weigher).expireAfterWrite(expireAfterWriteDuration, unit).build();}public V get(K key) {return cache.getIfPresent(key);}public void put(K key, V value) {cache.put(key, value);}public void remove(K key) {cache.invalidate(key);}public void clear() {cache.invalidateAll();}// 如果你需要一个加载功能(当缓存miss时自动加载值),你可以使用这个方法public V get(K key, Function<? super K, ? extends V> mappingFunction) {return cache.get(key, mappingFunction);}// 添加获取缓存统计信息的方法public String stats() {return cache.stats().toString();}
}LocalCacheProvider
import cn.hutool.core.util.ObjectUtil;
import com.cuzue.dao.cache.localcache.CaffeineCache;import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
import java.util.function.Supplier;/*** 本地缓存*/
public class LocalCacheProvider {private static CaffeineCache cache;/*** 无过期时间* @param maxSize 缓存最大条数*/public LocalCacheProvider(long maxSize) {cache = new CaffeineCache(maxSize);}/*** 带过期时间* @param maxSize 缓存最大条数* @param ttl 过期时间* @param timeUnit 时间单位*/public LocalCacheProvider(long maxSize, long ttl, TimeUnit timeUnit) {cache = new CaffeineCache(maxSize, ttl, timeUnit);}public static <T> List<T> getCachedList(String key, Supplier<List<T>> dataFetcher) {if (ObjectUtil.isNotNull(cache.get(key))) {return (List<T>) cache.get(key);} else {List<T> data = dataFetcher.get();cache.put(key, data);return data;}}public static <T> List<T> getCachedList(String key, Function<String, List<T>> dataFetcher) {return (List<T>) cache.get(key, dataFetcher);}/*** 删除缓存** @param key redis key*/public void deleteCachedList(String key) {cache.remove(key);}
}
3.1.3 使用
//初始化caffeine对象
LocalCacheProvider cache = new LocalCacheProvider(5000, 20, TimeUnit.SECONDS);//缓存数据获取
public List<MatMaterialsResp> listLocalCache(ListQO qo) {List<MatMaterialsResp> resps = cache.getCachedList("testList", (s) -> {// 缓存数据查询});return resps;
}
注意:Caffeine 实现的缓存占用 JVM 内存,小心 OutOfMemoryError
解决场景:
1.本地缓存适用不限制缓存大小,导致OOM,适合缓存小对象
2.本地缓存长时间存在,未及时清除无效缓存,导致内存占用资源浪费
3.防止人员api滥用, 未统一管理随意使用,导致维护性差等等
总结
从前的无脑经验,db查询慢,redis缓存起来,redis真不一定快!
一个简单性能测试:(测试响应时间均为二次查询的大概时间)
- 前置条件: 一条数据转换需要200ms,共5条数据,5个字段项,数据量大小463 B
db > 1s
redis > 468ms
local > 131ms
- 去除转换时间,直接响应
db > 208ms
redis > 428ms
local > 96ms

相关文章:
关于缓存 db redis local 取舍之道
文章目录 前言一、影响因素二、db or redis or local1.db2.redis3. local 三、redisson 和 CaffeineCache 封装3.1 redisson3.1.1 maven3.1.2 封装3.1.3 使用 3.2 CaffeineCache3.1.1 maven3.1.2 封装3.1.3 使用 总结 前言 让我们来聊一下数据缓存,它是如何为我们带…...

imgaug库图像增强指南(33):塑造【云层】效果的视觉魔法
引言 在深度学习和计算机视觉的世界里,数据是模型训练的基石,其质量与数量直接影响着模型的性能。然而,获取大量高质量的标注数据往往需要耗费大量的时间和资源。正因如此,数据增强技术应运而生,成为了解决这一问题的…...

树莓派ubuntu:CSI接口摄像头安装驱动程序及测试
树莓派中使用OV系列摄像头,网上能搜到的文章资源太老了,文章中提到的摄像头配置选项在raspi-config中并不存在。本文重新测试整理树莓派摄像头的驱动安装、配置、测试流程说明。 libcamera 新版本中使用libcamera作为摄像头驱动程序。 libcamera是一个…...

Webpack5入门到原理6:处理图片资源
处理图片资源 过去在 Webpack4 时,我们处理图片资源通过 file-loader 和 url-loader 进行处理 现在 Webpack5 已经将两个 Loader 功能内置到 Webpack 里了,我们只需要简单配置即可处理图片资源 1. 配置 const path require("path");modul…...
有哪些?)
大语言模型(LLM)有哪些?
国际大语言模型 目前国际上有以下几个知名的大语言模型: GPT-4 GPT-4由OpenAI团队开发,是闭源的。GPT(Generative Pre-trained Transformer)系列是目前最著名的大语言模型之一。最早的版本是GPT-1,之后发展到了GPT-2和GPT-3&…...

2 - 部署Redis集群架构
部署Redis集群架构 部署Redis集群部署管理主机第一步 准备ruby脚本的运行环境第二步 创建脚本第三步 查看脚本帮助信息 配置6台Redis服务器第一步 修改配置文件启用集群功能第二步 重启redis服务第三步 查看Redis-server进程状态(看到服务使用2个端口号为成功&#…...
NOIP2003提高组T1:神经网络
题目链接 [NOIP2003 提高组] 神经网络 题目背景 人工神经网络(Artificial Neural Network)是一种新兴的具有自我学习能力的计算系统,在模式识别、函数逼近及贷款风险评估等诸多领域有广泛的应用。对神经网络的研究一直是当今的热门方向&am…...

Doris数据库误删除恢复
如果不小心误删除了表,doris提供了恢复机制,但时间间隔不能超过一天,记得要迅速 首先查看当前能恢复的记录有那些 可以通过 SHOW CATALOG RECYCLE BIN 来查询当前可恢复的元信息,也可以在语句后面加 WHERE NAME XXX 来缩小查询…...

C# byte转int:大小端读取
参考:byte[]数组和int之间的转换 文章目录 Byte转为INT小端存储方式转int大端存储方式转int 大端模式和小端模式是计算机存储多字节数据时的两种方式。内存地址从小往大增长。 大端模式:最高有效(最高位)的字节存放在最小地址上&…...

安全通信网络
1.网络架构 1)应保证网络设备的业务处理能力满足业务高峰期需要。 设备CPU和内存使用率的峰值不大于设备处理能力的70%。 在有监控环境的条件下,应通过监控平台查看主要设备在业务高峰期的资源(CPU、内存等)使用 情况ÿ…...
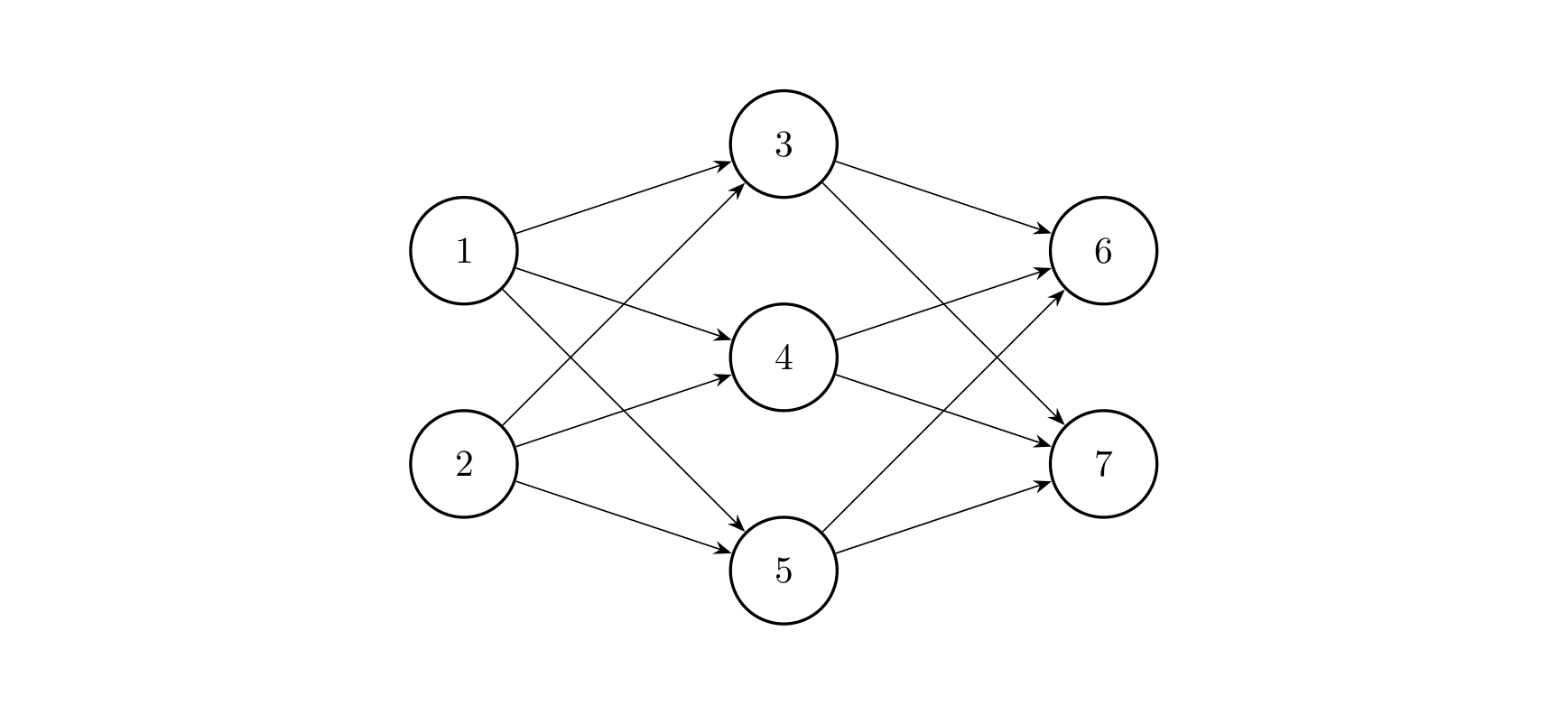
深度学习笔记(九)——tf模型导出保存、模型加载、常用模型导出tflite、权重量化、模型部署
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 本篇博客主要是工具性介绍,可能由于软件版本问题导致的部分内容无法使用。 首先介绍tflite: TensorFlow Lite 是一组工具,可帮助开…...

七Docker可视化管理工具
Docker可视化管理工具 本节介绍几款Docker可视化管理工具。 DockerUI(ui for Docker) 官方GitHub:https://github.com/kevana/ui-for-docker 项目已废弃,现在转投Portainer项目,不建议使用。 Portainer 简介:Portainer是一个…...

vue和react的差异梳理
特性VueReact响应式系统使用Object.defineProperty()或Proxy使用不可变数据流和状态提升模板系统HTML模板语法JSX(JavaScript扩展语法)组件作用域样式支持scoped样式需要CSS-in-JS库(如styled-components)状态管理Vuex(…...
(笔记总结)C/C++语言的常用库函数(持续记录,积累量变)
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...
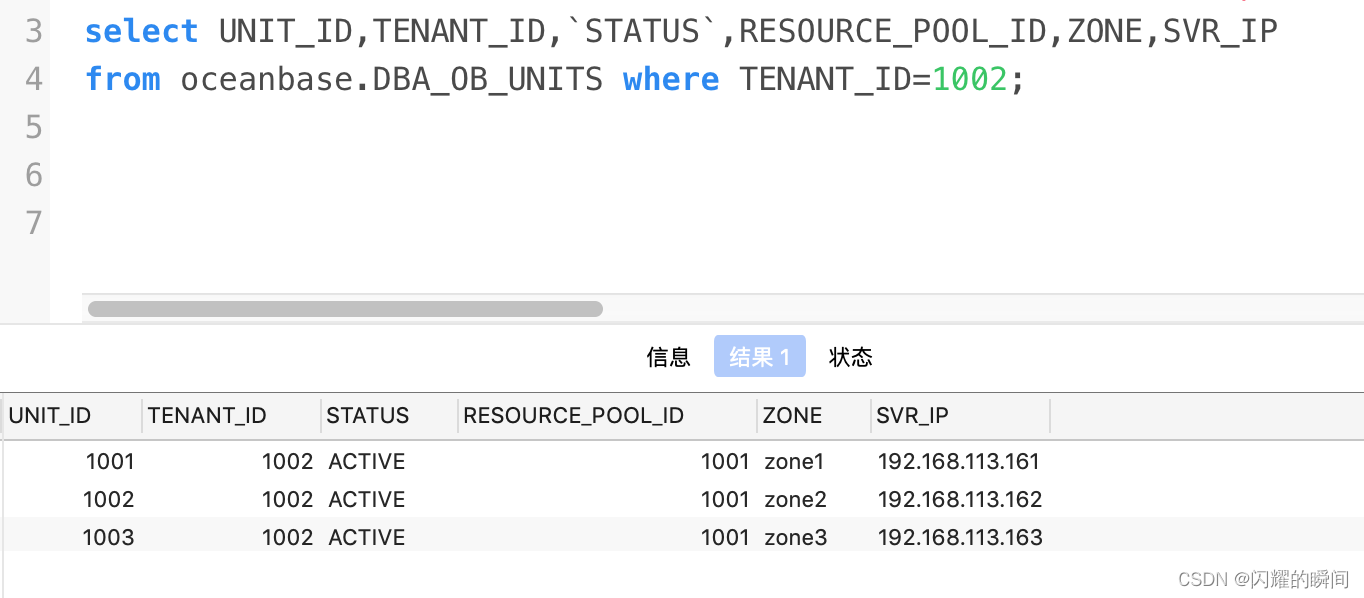
OceanBase集群扩缩容
OceanBase 数据库采用 Shared-Nothing 架构,各个节点之间完全对等,每个节点都有自己的 SQL 引擎、存储引擎、事务引擎,天然支持多租户,租户间资源、数据隔离,集群运行的最小资源单元是Unit,每个租户在每…...

html 3D 倒计时爆炸特效
下面是代码: <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>HTML5 Canvas 3D 倒计时爆炸特效DEMO演示</title><link rel"stylesheet" href"css/style.css" media"screen&q…...

记一次垃圾笔记应用VNote安装失败过程
特色功能简介 1.全文搜索: VNote支持根据关键词搜索整个笔记本或者特定文件夹内的文档内容,非常适合快速找到信息。 2.标签管理: 你可以给笔记添加标签,从而更好地组织和检索你的笔记内容。 3.自定义主题和样式: 进入设置,VNote允许你选…...

记一次 stackoverflowerror 线上排查过程
一.线上 stackOverFlowError xxx日,突然收到线上日志关键字频繁告警 classCastException.从字面上的报警来看,仅仅是类型转换异常,查看细则发现其实是 stackOverFlowError.很多同学面试的时候总会被问到有没有遇到过线上stackOverFlowError?有么有遇到栈溢出?具体栈溢出怎么来…...

论文写作之十个问题
前言 最近进入瓶颈? 改论文,改到有些抑郁了 总是不对,总是被打回 好的写作,让人一看就清楚明白非常重要 郁闷时候看看大佬们怎么说的 沈向洋、华刚:读科研论文的三个层次、四个阶段与十个问题 十问 What is the pro…...
leetcode2171 拿出最少数目的魔法豆
题目 给定一个 正整数 数组 beans ,其中每个整数表示一个袋子里装的魔法豆的数目。 请你从每个袋子中 拿出 一些豆子(也可以 不拿出),使得剩下的 非空 袋子中(即 至少还有一颗 魔法豆的袋子)魔法豆的数目…...

使用 TaoToken CLI 工具为团队统一配置开发环境中的模型端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 TaoToken CLI 工具为团队统一配置开发环境中的模型端点 基础教程类,面向团队技术负责人,介绍如何通过…...

快手推荐算法实战解析:从三层漏斗架构到多目标优化
1. 项目概述:从“刷”到“懂”,快手推荐算法的冰山一角 刷快手,可能是很多人每天的习惯性动作。手指一划,一个接一个的短视频,好像总能精准地戳中你的笑点、泪点或是知识盲区。你有没有想过,为什么你看到的…...

终极ASI加载器:Windows游戏修改的完整解决方案
终极ASI加载器:Windows游戏修改的完整解决方案 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/Ultimate-ASI-Loader …...

如何快速解决多设备滚动冲突:Scroll Reverser终极配置指南
如何快速解决多设备滚动冲突:Scroll Reverser终极配置指南 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在Mac上同时使用触控板和鼠标时,被混…...

物联网设备网络无缝切换与多网融合:exnetif模块实战指南
1. 项目概述:为什么我们需要exnetif? 在物联网项目的实际开发中,我遇到过太多因为网络环境不稳定而导致的“玄学”问题。比如,一个部署在工厂车间的智能网关,原本通过稳定的有线以太网连接云端,一旦生产线调…...
)
保姆级教程:用ADAMS 2023复现人体行走与跌倒仿真(附完整模型参数与源文件)
ADAMS 2023生物力学仿真实战:从人体步态建模到跌倒临界点分析 在工程仿真领域,人体运动动力学一直是极具挑战性的研究方向。ADAMS作为多体动力学仿真软件的标杆,其2023版本在生物力学仿真方面新增了多项实用功能。本文将带您从零开始…...

别再写一堆CASE WHEN了!PostgreSQL里COALESCE和NULLIF这两个函数,帮你把SQL写得又短又稳
告别冗长SQL:用PostgreSQL的COALESCE和NULLIF重构条件逻辑 在数据处理的世界里,SQL就像是我们与数据库对话的语言。但你是否经常遇到这样的情况:为了处理各种空值和边界条件,你的SQL查询变成了一个由无数CASE WHEN语句组成的庞然大…...

构建多模型智能客服时如何借助 Taotoken 实现灵活路由与降级
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型智能客服时如何借助 Taotoken 实现灵活路由与降级 在构建企业级智能客服系统时,服务的稳定性和响应能力至关…...

基于ESP32与电子墨水屏的低功耗物联网信息终端开发实战
1. 项目概述:打造你的专属韦伯望远镜状态看板 如果你和我一样,对浩瀚宇宙充满好奇,同时又是个喜欢动手鼓捣硬件的极客,那么这个项目绝对能让你兴奋起来。想象一下,在你的书桌或工作台上,有一个巴掌大的设备…...

如何在Windows上安装APK文件:APK Installer终极指南
如何在Windows上安装APK文件:APK Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK Installer是一款专为Windows系统设计的Android应用…...