【Python】正则表达式简单教程
0x01 正则表达式概念及符号含义
掌握正则表达式,只需要记住不同符号所表示的含义,以及对目标对象模式(或规律)的正确概括。
1、基础内容
字符匹配
- 在正则表达式中,如果直接给出字符,就是精确匹配。
- \d 匹配一个数字
- \D 匹配一个非数字
- \w 匹配一个字母、数字或下划线_
- \W 匹配任何非单词字符,等价于“[^A-Za-z0-9_]"
- \s 匹配任何空白字符,包括空格、制表符、换页符等等,等价于[ \f\n\r\t\v]
- \S 匹配任何非空白字符
- \n 匹配一个换行符
- \r 匹配一个回车符
- \t 匹配一个制表符
数量匹配
- .匹配除“\n"之外的任何单个字符
- *匹配前面的子表达式零次或多次
- +匹配前面的子表达式一次或多次
- ?匹配前面的子表达式零次或一次
- {n},n是一个非负整数,匹配确定的n次
- {n,m},m和n均为非负整数,其中n<=m,最少匹配n次且最多匹配m次
- {n,},n是一个非负整数,至少匹配n次
- {,m} 匹配前面的正则表达式最多m次
范围匹配
- x|y 匹配x或y
- [xyz] 字符集合,匹配所包含的任意一个字符
- [^xyz] 负值字符集合,匹配未包含的任意字符
- [a-z] 字符范围,匹配指定范围内的任意字符
- [^a-z] 负值字符范围,匹配任何不在指定范围内的任意字符
来看一个稍微复杂的例子:\d{3,4}\s+\d{3,8}
我们来从左到右解读一下:
- \d{3,4}表示匹配3到4个数字,例如'010'、'0755';
- \s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等;
- \d{3,8}表示3-8个数字,例如'1234567'。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。
如果要匹配'010-12345'、'0755-26776666'这样的号码呢?
由于'-'是特殊字符,在正则表达式中,要用'\'转义,所以,上面的正则是\d{3,4}\-\d{3,8}。
但是,仍然无法匹配'010 - 12345',因为带有空格。所以我们需要更复杂的匹配方式。
2、进阶内容
要做更精确地匹配,可以用[]表示范围,比如:
- [0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线;
- [0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等;
- [a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;
- [a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
- A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。
- ^表示行的开头,^\d表示必须以数字开头。
- $表示行的结束,\d$表示必须以数字结束。
你可能注意到了,py也可以匹配'python',但是加上^py$就变成了只能匹配以'py'开头的字符串,
所以,如果某个字符串为'I love python',那么就无法匹配到,因为它不是以py开头。
3、正则表达式使用场景
- 判断某个字符串是否匹配特定的模式
- 切分字符串
- 提取特定模式的字符串
- 将指定模式的字符串进行替换
0x02 Python中正则表达式模块re
1、判断某个字符串是否匹配特定的模式
前面区号+电话号码的例子
# 导入re模块
import re# 匹配
result = re.match(r'\d{3,4}\-\d{3,8}$','020-12345')
print(result)# 不匹配
result2 = re.match(r'\d{3,4}\-\d{3,8}$','020 12345')
print(result2)# match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None。
# 常见的判断方法就是:# 带判断的字符串
test = '020-12345'
if re.match(r'\d{3,4}\-\d{3,8}$', test):print('match')
else:print('not match')小练习:判断给定的邮箱地址是否是NETEC邮箱
- 假设NETEC公司的邮箱格式为姓+.+名字+数字+@netec.com.cn。
- 其中数字不是必须的,只有相同名字的员工有多个时,才会存在数字
- 并且姓名拼音或英文都会使用小写字母,而不会使用大写字母
email = 'lee.jack3@netec.com.cn'pattern = r'^[a-z]{1,}\.[a-z]+\d*@netec.com.cn$'if re.match(pattern,email):print('是NETEC邮箱')
else:print('不是NETEC邮箱')2、切分字符串
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
result3 = 'a b c'.split(' ')
print(result3)
无法识别连续的空格,用正则表达式试试:
result4 = re.split(r'\s+', 'a b c') print(result4)
无论多少个空格都可以正常分割。加入","试试:
result5 = re.split(r'[\s\,]+', 'a,b,, c d') print(result5)
再加入";"试试:
result6 = re.split(r'[\s\,\;]+', 'a,b;; c d') print(result6)
3、提取特定模式的字符串
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。
用()表示的就是要提取的分组(Group)。比如:^(\d{3,4})-(\d{3,8})$
分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
m = re.match(r'^(\d{3,4})-(\d{3,8})$', '0755-12345')
print(m)
print(m.group(0)) # 匹配的整个字符串
print(m.group(1)) # 匹配的第一个小括号的内容,即第一个匹配的子串
print(m.group(2)) # 匹配的第二个小括号的内容,即第二个匹配的子串
一个复杂的例子,提起给定时间字符串中的小时、分钟、秒
t = '19:05:30'
m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
print(m.groups())
print(m.group(1))
print(m.group(2))
print(m.group(3))其实上面也有更简便的写法:
t = '19:05:30' m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:([0-5]?[0-9])\:([0-5]?[0-9])$', t) print(m.groups()) print(m.group(1)) print(m.group(2)) print(m.group(3))
4、将指定模式的字符串进行替换
result = re.sub('[ae]','X','abcdefghi')
print(result)result = re.subn('[ae]','X','abcdef')
print(result)
5、贪婪匹配 vs 非贪婪匹配
正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
result7 = re.match(r'^(\d+)(0*)$', '102300').groups() print(result7)
由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,
加个?就可以让\d+采用非贪婪匹配:
result8 = re.match(r'^(\d+?)(0*)$', '102300').groups() print(result8)
6、正则表达式的编译
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
- 编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
- 用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,
接下来重复使用时就不需要编译这个步骤了,直接匹配:
# 编译
re_telephone = re.compile(r'^(\d{3,4})-(\d{3,8})$')# 直接使用
print(re_telephone.match('010-12345').groups())# 直接使用
print(re_telephone.match('010-8086').groups())编译后生成Regular Expression对象,由于该对象自己包含了正则表达式,
所以调用对应的方法时不用给出正则字符串。
7、re模块中常用的几个函数
(1)compile()
compile() 编译正则表达式模式,返回一个对象的模式,这样某个模式编译一次就可以在程序中多次使用
import re tt = "Tina is a good girl, she is cool, clever, and so on..." rr = re.compile(r'\w*oo\w*') print(rr.findall(tt)) #查找所有包含'oo'的单词
(2)match()
match() 决定RE是否在字符串刚开始的位置匹配。//注:这个方法并不是完全匹配。
当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'
print(re.match('com','comwww.runcomoob').group())
(3)search()
re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
print(re.search('\dcom','www.4comrunoob.5com').group())
(4)findall()
findall() 遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
p = re.compile(r'\d+')
print(p.findall('o1n2m3k4'))
(5)finditer()
finditer() 搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。找到 RE 匹配的所有子串,并把它们作为一个迭代器返回。
iter = re.finditer(r'\d+','12 drumm44ers drumming, 11 ... 10 ...') for i in iter: print(i) print(i.group()) print(i.span())
(6)split()
split() 按照能够匹配的子串将string分割后返回列表。
可以使用re.split来分割字符串,如:re.split(r'\s+', text);将字符串按空格分割成一个单词列表。
print(re.split('\d+','one1two2three3four4five5'))
(7)sub()
sub() 使用re替换string中每一个匹配的子串后返回替换后的字符串。
import re text = "JGood is a handsome boy, he is cool, clever, and so on..." print(re.sub(r'\s+', '-', text))
(8)subn()
subn() 使用re替换string中每一个匹配的子串后返回替换后的字符串,并返回替换次数
print(re.subn('[1-2]','A','123456abcdef'))
print(re.sub("g.t","have",'I get A, I got B ,I gut C'))
print(re.subn("g.t","have",'I get A, I got B ,I gut C'))相关文章:

【Python】正则表达式简单教程
0x01 正则表达式概念及符号含义 掌握正则表达式,只需要记住不同符号所表示的含义,以及对目标对象模式(或规律)的正确概括。 1、基础内容 字符匹配 在正则表达式中,如果直接给出字符,就是精确匹配。\d 匹…...
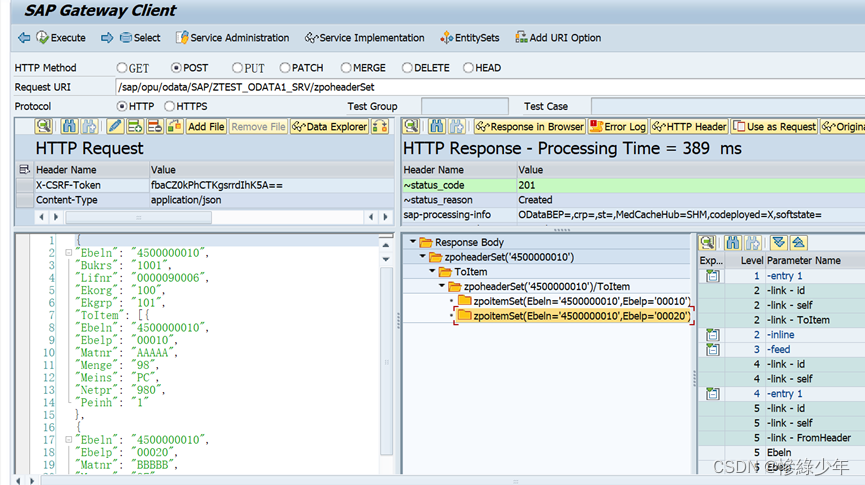
SAP ABAP Odata
GetEntity和GetEntitys GetEntitys 创建Odata Project 导入结构 选择需要的字段 设定Key 勾选字段的creatable、updatable、sortable、nullable、filterable属性值。 再依上述步骤创建ZPOITEM结构和实体集 3. 创建ZPOHEADER和ZPOITEM的Association 两个实体集的关联字段&…...

Android native ASAN 排查内存泄漏
一、概述 android 对native - c/c 的调试和排查是比较难受的一件事。我看周遭做window , linux 甚至ios的调试排查起c的代码都比较方便。习惯了app开发去熟悉native是各种痛苦,最主要是排查问题上。后续有时间打算整理下native 的错误排查使用ÿ…...
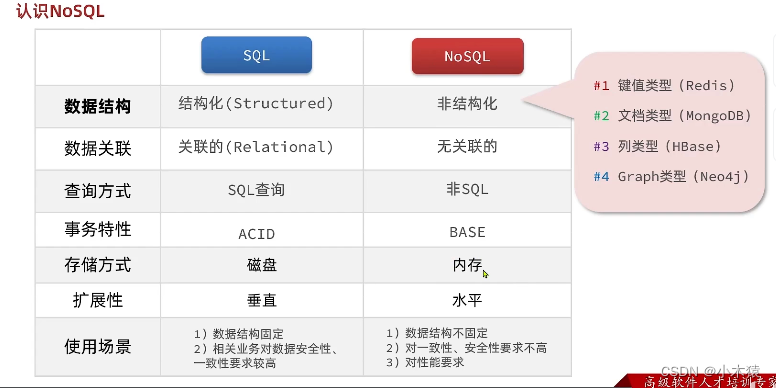
Django项目开发
一.认识NoSQL 1.SQL 关系型数据库 结构化: 定义主键,无符号型数据等关联的:结构化表和表之间的关系通过外键进行关联,节省存储空间SQL查询:语法固定 SELECT id,name,age FROM tb_user WHERE id1 ACID 2.NoSQL 非关系型数据库 Re…...

Debezium系列之:深入理解Debezium Server和Debezium Server实际应用案例详解
Debezium系列之:深入理解Debezium Server和Debezium Server实际应用案例详解 一、认识Debezium Server二、下载Debezium Server三、解压Debezium Server四、查看Debezium Server目录五、Debezium Server配置六、Debezium Server启动输出样式七、源配置八、格式配置九、Transfo…...
IDE2022源码编译tomcat
因为学习需要,我需要源码编译运行tomcat对其源码进行一个简单的追踪分析。由于先前并未接触过java相关的知识,安装阻力巨大。最后请教我的开发朋友才解决了最后的问题。将其整理出来,让大家能够快速完成相关的部署。本文仅解决tomcat-8.5.46版…...

214 情人节来袭,电视剧 《点燃我温暖你》李峋同款 Python爱心表白代码,赶紧拿去用吧
大家好,我是徐公,六年大厂程序员经验,今天为大家带来的是动态心形代码,电视剧 《点燃我温暖你》同款的,大家赶紧看看,拿去向你心仪的对象表白吧,下面说一下灵感来源。 灵感来源 今天ÿ…...

数据库范式
基本概念 函数依赖 x→yx\rightarrow yx→y,当确定xxx的时候,yyy也可以确定 例: 学号→\rightarrow→姓名,当知道了学号,就知道了学生姓名 学号,课程号→\rightarrow→成绩,当知道了学号和课程号ÿ…...
CUDA中的底层驱动API
文章目录CUDA底层驱动API1. Context2. Module3. Kernel Execution4. Interoperability between Runtime and Driver APIs5. Driver Entry Point Access5.1. Introduction5.2. Driver Function Typedefs5.3. Driver Function Retrieval5.3.1. Using the driver API5.3.2. Using …...

【博客616】prometheus staleness对PromQL查询的影响
prometheus staleness对PromQL查询的影响 1、prometheus staleness 官方文档的解释: 概括: 运行查询时,将独立于实际的当前时间序列数据选择采样数据的时间戳。这主要是为了支持聚合(sum、avg 等)等情况,…...

多传感器融合定位十三-基于图优化的建图方法其二
多传感器融合定位十二-基于图优化的建图方法其二3.4 预积分方差计算3.4.1 核心思路3.4.2 连续时间下的微分方程3.4.3 离散时间下的传递方程3.5 预积分更新4. 典型方案介绍4.1 LIO-SAM介绍5. 融合编码器的优化方案5.1 整体思路介绍5.2 预积分模型设计Reference: 深蓝学院-多传感…...
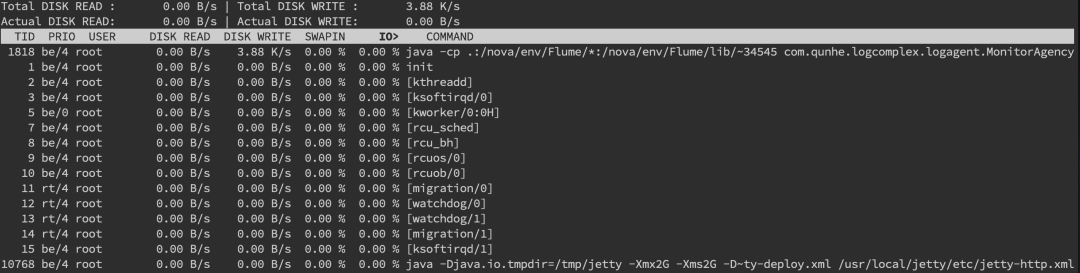
linux 服务器线上问题故障排查
一 线上故障排查概述 1.1 概述 线上故障排查一般从cpu,磁盘,内存,网络这4个方面入手; 二 磁盘的排查 2.1 磁盘排查 1.使用 df -hl 命令来查看磁盘使用情况 2.从读写性能排查:iostat -d -k -x命令来进行分析 最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及…...

Sandman:一款基于NTP协议的红队后门研究工具
关于Sandman Sandman是一款基于NTP的强大后门工具,该工具可以帮助广大研究人员在一个安全增强型网络系统中执行红队任务。 Sandman可以充当Stager使用,该工具利用了NTP(一个用于计算机时间/日期同步协议)从预定义的服务器获取并…...
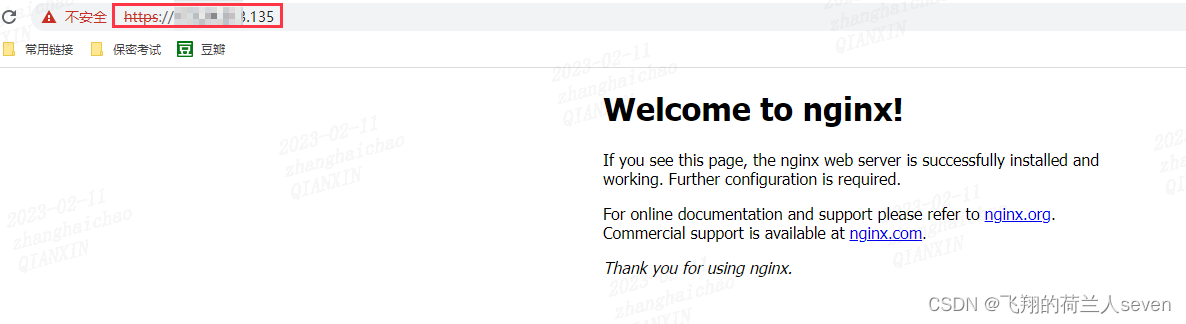
【SSL/TLS】准备工作:HTTPS服务器部署:Nginx部署
HTTPS服务器部署:Nginx部署1. 准备工作2. Nginx服务器YUM部署2.1 直接安装2.2 验证3. Nginx服务器源码部署3.1 下载源码包3.2 部署过程4. Nginx基本操作4.1 nginx常用命令行4.2 nginx重要目录1. 准备工作 1. Linux版本 [rootlocalhost ~]# cat /proc/version Li…...
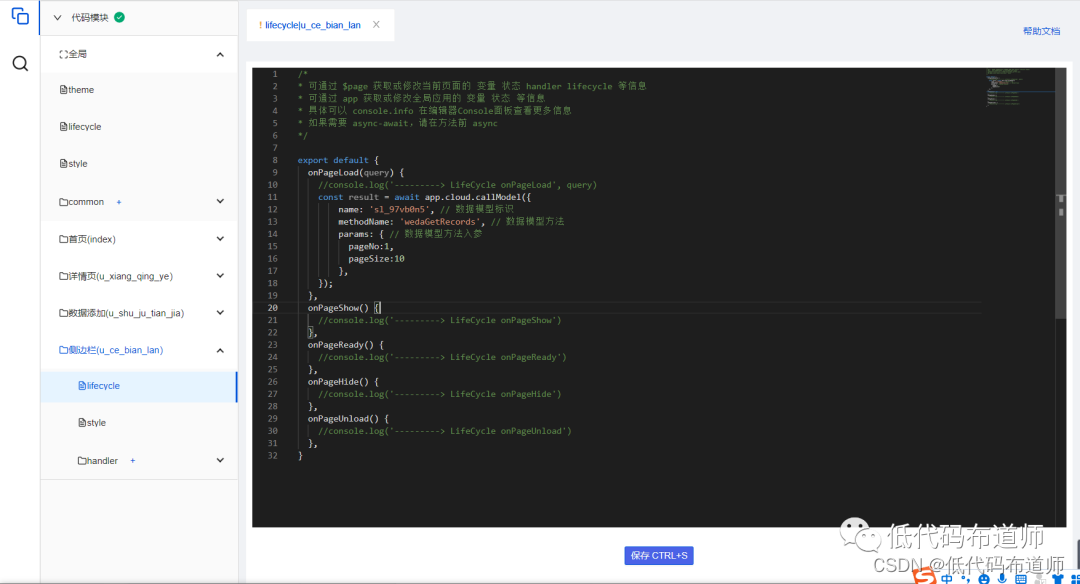
微搭低代码从入门到精通11-数据模型
学习微搭低代码,先学习基本操作,然后学习组件的基本使用。解决了前端的问题,我们就需要深入学习后端的功能。后端一般包括两部分,第一部分是常规的数据库的操作,包括增删改查。第二部分是业务逻辑的编写,在…...

【算法基础】前缀和与差分
😽PREFACE🎁欢迎各位→点赞👍 收藏⭐ 评论📝📢系列专栏:算法💪种一棵树最好是十年前其次是现在1.什么是前缀和前缀和指一个数组的某下标之前的所有数组元素的和(包含其自身&#x…...
LTD212次升级 | 官网社区支持PC端展示 • 官网新增证件查询应用,支持条形码扫码查询
1、新增证件查询应用,支持条形码扫码查询; 2、新增用户社区PC端功能; 01证件查询应用 1、新增证件查询应用功能 支持证件信息录入、打印功能,支持条形码扫码识别。 后台管理操作路径:官微中心 - 应用 - 证件查询 …...
【安全】nginx反向代理+负载均衡上传webshell
目录 一、负载均衡反向代理下上传webshell Ⅰ、环境搭建 ①下载蚁剑,于github获取官方版: ②下载docker&docker-compose ③结合前面启动环境 ④验证 负载均衡下webshell上传 一、负载均衡反向代理下上传webshell 什么是反向代理? 通常的代…...
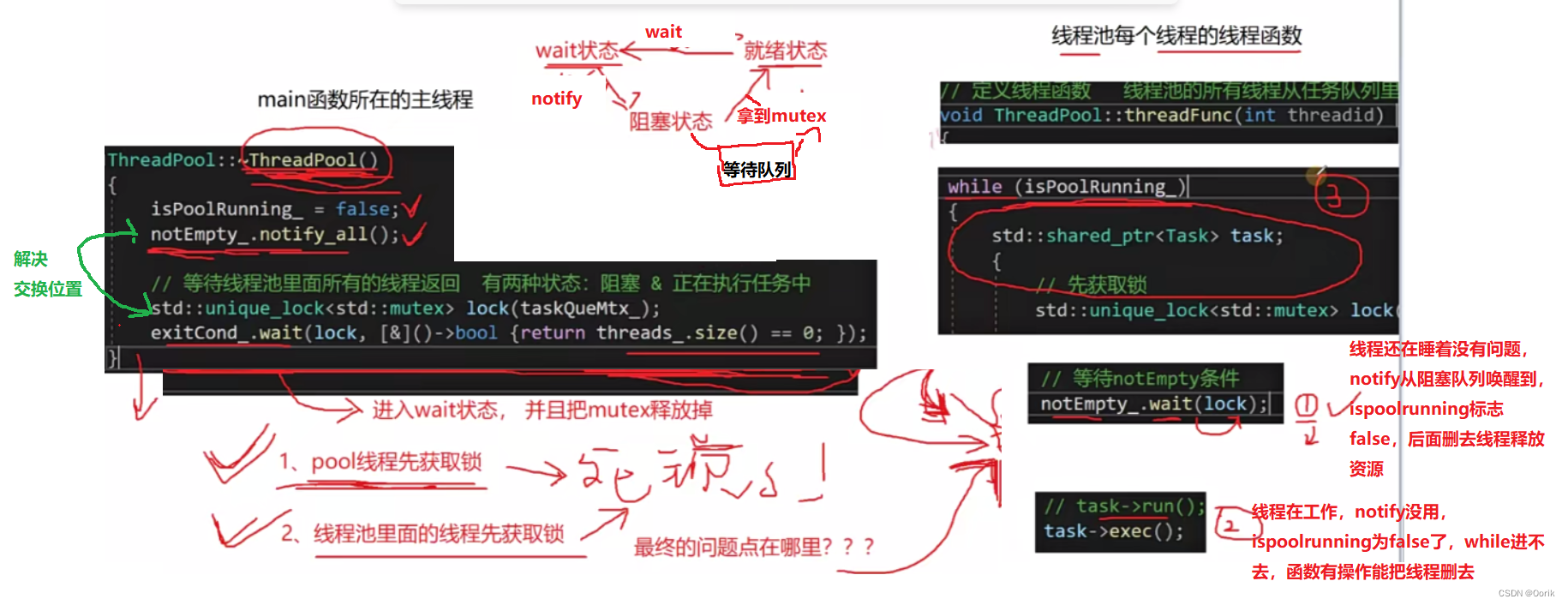
线程池框架
这是之前有做的一个可以接受用户传入任意类型的任务函数和任意参数,并且能拿到任务对应返回值的一个线程池框架,可以链接成动态库,用在相关项目里面。一共实现了两版,都是支持fixed和cached模式的,半同步半异步的&…...

【TCP的拥塞控制】基于窗口的拥塞控制
TCP的拥塞窗口CWND大小和传输轮次n的关系如下所示。(本题10分) cwnd12481632333435363738394041422122232425261248N1234567891011121314151617181920212223242526 问题: (1)慢开始阶段的时间间隔?&#…...

开源协作平台Octopal:整合Git、文档与任务的项目管理利器
1. 项目概述:一个为开发者量身定制的开源协作平台如果你是一名开发者,或者是一个小型技术团队的负责人,那么你一定对这样的场景不陌生:手头有几个并行的项目,团队成员分散,沟通主要靠即时通讯工具ÿ…...
)
告别手写代码!用Simulink+STM32CubeMX给F103点个灯(保姆级图文教程)
零代码玩转STM32:Simulink与CubeMX联动的LED控制实战指南 在嵌入式开发领域,传统的手写代码方式正逐渐被模型化设计工具所革新。想象一下,只需拖拽几个功能模块,设置几个参数,就能让STM32微控制器按照你的想法工作——…...

Audacity音频编辑完全手册:从零开始制作专业音频作品
Audacity音频编辑完全手册:从零开始制作专业音频作品 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 想制作播客却不知道如何剪辑?需要为视频添加背景音乐但找不到合适的工具?或…...

Erupt 七年最有诚意升级:官网、文档、脚手架更新,迈向工业级开源生态!
一、写在前面:为什么这次更新值得你重新认识 Erupt?过去几年,Erupt 一直被打上“功能强但太朴素”的标签。注解驱动、AI 模块、多 UI 模板、Cloud 集群、AI Agent,内核卷到飞起,但官网、文档、脚手架这“门面三件套”始…...

AI编码助手配置框架:六层缰绳架构实现团队规范与上下文持久化
1. 项目概述:为什么你的AI编码助手总像个“健忘的实习生”? 如果你和我一样,已经深度使用Claude Code、Cursor这类AI编码助手超过半年,那你一定经历过这种“血压升高”的时刻:明明昨天刚跟它详细解释过项目的架构规范…...

机器视觉在人工智能领域的应用
机器视觉在人工智能领域的应用 目录机器视觉在人工智能领域的应用一、图像处理与机器视觉的概念阐述1. 图像处理(Image Processing)2. 机器视觉(Machine Vision / Computer Vision)二、图像处理与机器视觉的区别与共同点区别共同点…...

学术人必抢的实时检索红利,Perplexity这4个隐藏功能90%研究者至今未启用,错过再等半年!
更多请点击: https://intelliparadigm.com 第一章:Perplexity实时学术搜索怎么用 Perplexity 是一款面向研究者与开发者设计的实时学术搜索引擎,其核心优势在于直接对接 arXiv、PubMed、ACL Anthology、Semantic Scholar 等权威学术数据库&a…...

如何自定义 LangGraph 的 State Schema 以支持复杂业务数据流
标题选项 《LangGraph实战进阶:自定义State Schema搞定复杂业务数据流全指南》 《从零搞定LangGraph复杂工作流:State Schema自定义从原理到落地》 《告别简单Demo:自定义LangGraph State Schema支撑企业级复杂数据流》 《LangGraph核心原理解锁:State Schema自定义设计思路…...
 函数)
C语言(8) 函数
第五章 函数一段功能代码,被称为函数1. 为了避免代码的重复。 复用性。 开发不用从头开始(库函数)。 2. 模块化的思想 。 大问题,分解成小问题,逐个解决。 设计函数 ,高内聚,低耦合。 功能越单一越好 ,对外…...

中小团队如何利用Taotoken统一管理多个项目的AI调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小团队如何利用Taotoken统一管理多个项目的AI调用成本 对于同时推进多个AI应用开发项目的中小型技术团队而言,管理分…...