滴滴基于 Ray 的 XGBoost 大规模分布式训练实践
背景介绍
作为机器学习模型的核心代表,XGBoost 在滴滴众多策略算法业务场景中发挥着至关重要的作用。因此,保障并持续提升 XGBoost 模型的离线训练及在线推理稳定性一直是机器学习平台的重点工作。同时,面对多样化的业务场景定制需求和数据规模从万到亿级的跨度,XGBoost 的训练效率和灵活性也成为我们需要重点关注的问题。
由于平台历史架构原因,平台 XGBoost 模型训练仍是开源 XGBoost On Spark 技术方案。但是在易用性和稳定性上一直存在问题:
缺乏任务容错和弹性训练。XGBoost On Spark 不支持 Task 粒度容错,导致在集群负载较高的情况下,任务失败概率非常高。
在亿级数据规模下,Spark 相关性能优化参数组合较多,对于算法同学门槛较高,问题排查也较为困难。
基于 JVM 语言生态实现,与主流的 AI 生态较难整合。XGBoost On Spark 仍然以 Scala 生态为主,大多数算法同学仍主要以 Python 语言为主,对于一些定制化需求(自定义 Loss、自定义评估指标)等场景上手难度较大。
XGBoost On Spark 版本升级困难。当前依赖的 XGBoost 仍为0.82,社区 XGBoost 最新已经到2.0,由于各种包版本依赖问题,很多社区新特性或者性能优化不能直接使用。
超参数搜索能力不足。对于有调参诉求的用户,只能够支持围绕 Spark 生态构建调参策略,与业内优秀的调参算法能力集成难度较大。
因此,鉴于以上 XGBoost On Spark 存在的问题,以及平台整体架构方向的综合考虑,我们先后调研了业内多种 MLOps 技术方案。最终,基于公司数据引擎在 Ray 方向的建设情况,我们尝试构建基于 Ray 云原生方案的 XGBoost 训练方式,结合 Ray 强大的 AI 生态,来最大化降低平台策略算法开发及业务侧算法同学维护和使用门槛。Ray 涵盖了常见特征处理、模型训练、模型评估、模型离线预测等功能,可以带来以下直接收益:
Ray 原生支持 XGBoost、LightGBM、Tensorflow、Pytorch 等算法实践中常用框架,同时支持一定的容错机制。
拥抱 Ray AI 生态技术栈,包含数据处理、模型训练、AutoML、超参数搜索。完全 Python 化,接入门槛低。
借用 Ray Tune 模块,能快速验证及接入业内更加丰富的超参搜索框架和优秀的算法策略。
借助 KubeRay,支持 Job 级别容器粒度的隔离机制以及训练容器定制化诉求。
最终,经过努力,各项收益中可衡量的关键指标都有不错的提升:
整体训练效率层面,相对原版 XGBoost On Spark 有2-6倍左右的提升。
在稳定性层面,经过压测因框架或者集群问题带来的失败率在(1.6%),远低于原 XGBoost On Spark 的因集群或者框架导致的失败率(4.6%)。
技术方案
整体架构
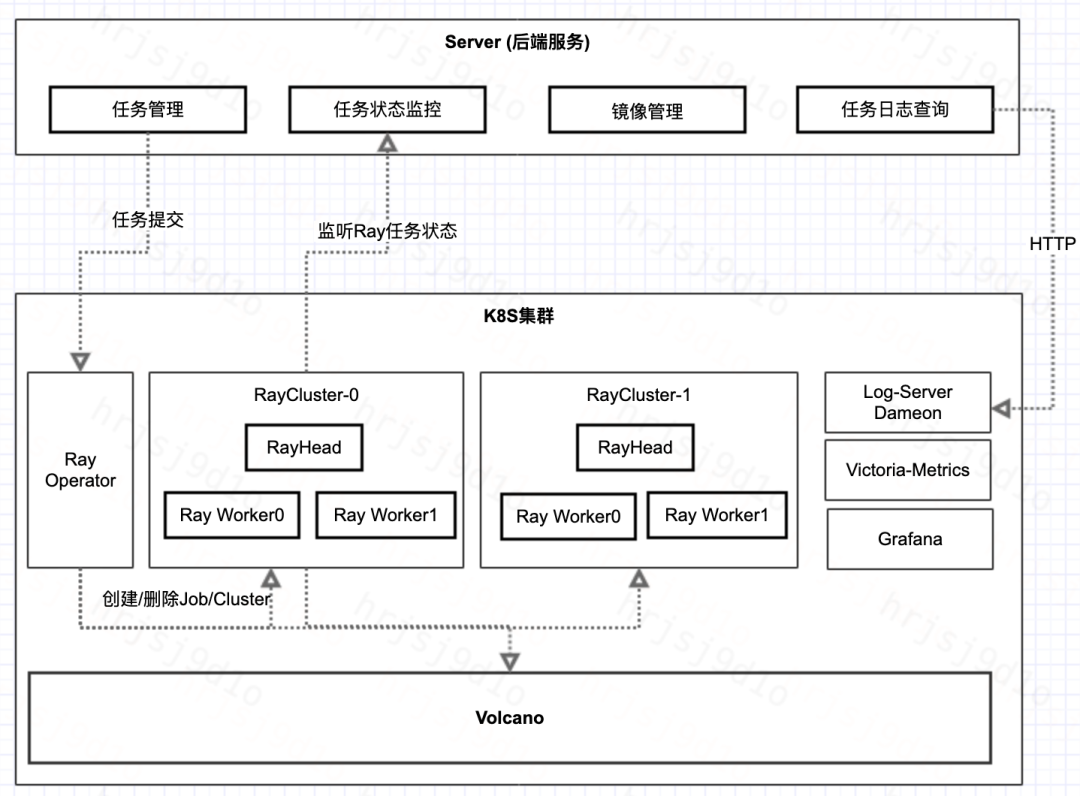
整体架构图
整体的技术架构如上图所示,整体的流程描述如下:
服务端解析训练任务参数构建 RayJob 实例,并通过 watch RayJob 的状态来监听任务的实时状态变化。
每个训练任务创建独立的 ray 集群,通过定制化容器,做到 Pod 粒度隔离。
采用 Volcano 做资源调度,实现 Gang 调度策略,并结合 Ray autoscaler 的能力,实现任务的动态资源申请。同时借助 gang 调度机制,在保证任务获得足够资源的同时,避免训练多个训练任务同时抢占集群资源,从而导致集群所有任务 hang 住的问题。
通过将 Ray job 的日志写入到挂载的宿主机盘上,通过引擎侧提供的 Log Server Daemon 来实时获取训练日志。
XGBoost on Ray 训练性能
作为 XGBoost On Spark 的替代方案,训练性能是我们首先需要考虑的事情。因此,我们对基于 Spark 和基于 Ray 不同滴滴业务场景中不同数量级的不同数据地进行了评测,结果如下图所示。
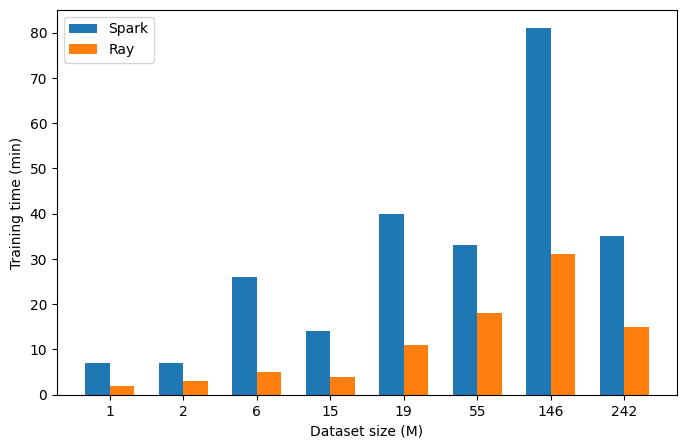
显示了基于Ray(红色)和基于Spark(蓝色)的XGBoost 训练效率对比
在测试中我们均使用相近的物理资源量(CPU/内存),得益于 XGBoost 版本的升级以及我们多次优化,从结果上看,Ray 在小规模数据集上的训练效率提升更为明显,在从百万至亿条样本(1M -242M)的不同业务数据中获得了约2-6 倍性能提升。
值得注意的是,图中虽然同一个实验下采用了相同的参数,但不同业务数据集具有不同特性(如特征数、稀疏度),并且在不同业务场景下采用不同最优参数(如树个数、树深度),因此训练时间并不严格随着数据集样本数的增加而线性增长。
XGBoost on Ray 容错能力
支持容错能力是我们选择 On Ray 的一个重要原因。随着训练数据的增加和训练任务的增多,XGBoost 分布式训练出错的可能性也在上升。然而,大多数分布式引擎,如 Spark,都是无状态的,需要在重启后通过保存历史检查点来恢复运行状态,这需要额外的管理模块,或者重新启动整个任务进行重新训练。无论是哪种方案,每次重启都会导致从分布式存储中重新加载和处理大量数据,以及重新初始化集群环境,从而产生巨大的开销。
XGBoost on Ray 建立在 Ray 的有状态 Actor 框架之上,并提供开箱即用的容错机制,同时最大限度地减少了上述与数据相关的开销。Ray 的有状态 API 允许 XGBoost on Ray 进行非常精细的 Actor 级故障处理和恢复。在发生单节点或者多节点故障,XGBoost on Ray 可以将加载的数据保留在 Object Store 中,并且只需要将数据集重新从 Ray Dataset 按照现有存活的 Actor 重新分片并加载为 XGBoost DMatrix, 避免了重新加载数据。
如下图所示,XGBoost Ray 提供两种故障处理机制:
非弹性训练:如果 Actor 失败,XGBoost Ray 将等待失败的 Actor 重新被调度,并从最新的检查点继续训练。期间活着的 Actor 会保持空闲状态,节省数据重新加载的开销。
弹性训练:如果 Actor 失败,XGBoost Ray 将利用活着的 Actor 继续训练(更少Actor,更少数据集)。同时尝试重新启动已失败的 Actor,当 Actor 重新启动之后,自动触发异常并将 Actor 加入训练 Actor 中,加载最新的检查点,并重新分配数据集,进行后续的训练。这是我们最终采用的方案。
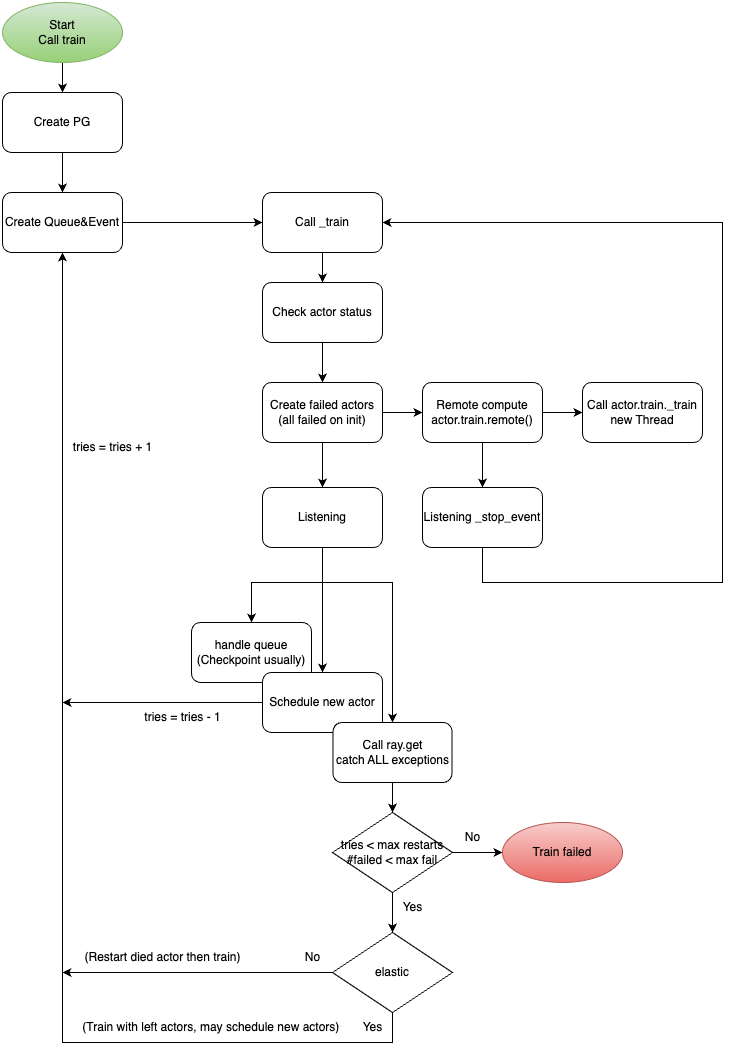
XGBoost Ray 的容错机制
在弹性训练任务中由于会基于更少的 Actor 和更少的数据集进行训练,直到新 Actor 重新加入,因此训练的性能可能因此收到影响。然而如下表所示,在实践中这个影响通常是可以忽略的,因为 Actor 的重启十分迅速。我们之所以采用这种方案,是因为可以避免资源浪费和频繁数据加载带来的开销。
数据集 | 19M * 105, regression | 106M * 139, classification | ||
实验方案 | metric (rsme) | train time (s) | metric (auc) | train time (s) |
0 (without fail) | 2.04003 | 591.28 | 0.772547 | 955.78 |
elastic + fail 1 | 2.04018 | 754.23 | 0.772393 | 964.28 |
elastic + fail 2 | 2.04031 | 772.41 | 0.772441 | 1047.91 |
elastic + fail 3 | 2.04019 | 765.13 | 0.772402 | 1040.76 |
non-elastic + fail 1 | 2.03988 | 581.44 | 0.772436 | 920.92 |
non-elastic + fail 2 | 2.03983 | 718.93 | 0.772478 | 814.45 |
non-elastic + fail 3 | 2.04007 | 728.45 | 0.77248 | 1004.27 |
两个不同真实的数据集上的容错结果对比
XGBoost on Ray 超参数搜索
在机器学习任务中,超参数搜索能帮助用户快速地在特定的搜索空间中查找当前任务的最优参数,相较于手动调参更加易用高效。近年来的一些超参数搜索方法(如PBT)需要根据每个试验都对特定迭代的开始、暂停、提前停止和重新启动的时间进行精细控制,同时在集中决策的 master-worker 架构中进行集体协调。这与常见的分布式执行引擎(如 Spark)的无状态、批量同步特性不符。
XGBoost on Ray 基于 Ray 的生态,可以直接使用 ray.tune 提供的超参数搜索能力。由于Ray Actor 是有状态的,可以利用 ray 原生的 API 检查、管理每个实验的状态、检查点和资源,因此 ray.tune 除了可以支持基于贝叶斯优化的超参数搜索方法,也支持遗传算法类算法。此外 ray tune 也与业界优秀的超参数搜索框架如 Optuna 、Flaml等很好的兼容。
Ray Tune 取代了对单独编排层的需求,并直接在同一个 Ray 集群中以容错和弹性的方式执行其并行实验分布式调优,由于并行的实验本质运行在同一个 ray 集群中,方便 ray tune 进行管理的同时,降低了通信成本的同时也降低了编排系统调度成本。
技术挑战及解决方案
尽管 XGBoost Ray 的开发者们已经做出了很多工作,但在将这个开源框架部署到系统中并适应滴滴的真实业务场景时,我们仍然面临着许多挑战。下面将为大家一一展开。
Spark 稀疏向量支持
由于历史原因,我们的算法平台所有的数据集都依赖于 Spark Vector(包括 SparseVector 和 DenseVector)来存储特征列。因此,XGBoost On Ray 需要支持 Spark Vector。
然而,我们发现现有的 Pyarrow Dataset -> Pandas -> Dmatrix 链路中, Pandas 无法支持单行数据的高维特征列表示,只能基于全量数据进行稀疏矩阵表示,这使得链路变为:Pyarrow -> Pandas -> scipy.Sparse.Matrix -> Dmatrix。同时,由于 Vector 结构的特殊性,Pyarrow -> Pandas -> scipy.Sparse.Matrix 每一步都需要进行一次额外的数据拷贝,这不仅增加了内存拷贝的开销,还增加了 Vector 结构的数据转换操作开销。
虽然可以通过 Pandarallel 库提升 Pandas 的并行处理效率,达到5-10倍左右,但在面对千万乃至亿级数据规模时,内存拷贝的开销问题仍然无法避免。为了解决这个问题,我们考虑去除中间的数据转换过程,实现 Pyarrow Dataset -> Dmatrix 的更短路径,以避免因额外的数据拷贝操作而产生开销。查阅 Pyarrow 和 XGBoost 的 API 后,我们发现 XGBoost 虽然支持直接读取 Pyarrow 数据,但只能读取基础数据字段(如int、double、float),尚不支持高维稀疏特征。
因此,我们需要做的是让 XGBoost 支持读取 Pyarrow 中的高维稀疏特征,而这个特征的表示正是来自于 Spark 定义的 Vector 数据结构类型。
查阅 XGBoost 相关读取 Pyarrow 数据源码实现可知,Pyarrow 数据是以 Arrow 数据格式存储,支持不同数据类型,如基础数据类型、数组、自定义结构体。Arrow 是一种高效的列式数据存储格式,它提供了一系列 API 和多语言的 SDK,使得上层应用在使用这些数据时无需在不同私有格式之间进行转换,从而节省了大量的序列化和反序列化计算资源。
对于自定义结构体类型 Vector,它实际上是由多种基础数据类型组成的,包括 int 类型的 size 和 type 字段,int 数组类型的 indices 字段,以及 double 数组类型的 values 字段。因此,我们根据 XGBoost 原有的读取 Arrow 基础数据类型的实现逻辑,定义了以下数据结构:
struct CompositeSubColumns {std::shared_ptr<Column> type;std::shared_ptr<Column> size;std::shared_ptr<Column> indices;std::shared_ptr<Column> values;
};同时,我们分别定义了 FixedListColumn、ListColumn、CompositeColumn 三种数据类型,用于解析数组类型和自定义 struct 类型(如 Vector)。相关实现如下:
template <typename T>
class ListColumn : public Column {static constexpr float kNaN = std::numeric_limits<float>::quiet_NaN();public:ListColumn(size_t idx, size_t length, size_t null_count,const uint8_t* bitmap, const T* data, float missing, const uint32_t* offset): Column{idx, length, null_count, bitmap}, data_{data}, missing_{missing}, offset_{offset} {}std::vector<COOTuple> GetElements(size_t row_idx) const override {CHECK(data_ && row_idx < length_) << "Column is empty or out-of-bound index of the column";if (IsValidElement(row_idx)) {auto slot_idx = offset_[row_idx];auto slot_length = offset_[row_idx + 1] - slot_idx;std::vector<COOTuple> fv;fv.reserve(slot_length);for (size_t i = 0; i < slot_length; ++i) {auto data = data_[slot_idx + i];COOTuple tuple{row_idx, i, static_cast<float>(data)}; fv.emplace_back(tuple); }return fv; }return {};}size_t NumElements(size_t row_idx) const override {if (IsValidElement(row_idx)) {auto slot_idx = offset_[row_idx];auto slot_length = offset_[row_idx + 1] - slot_idx;return slot_length;} else {return 0;}}private:const T* data_;float missing_; // user specified missing valueconst uint32_t* offset_;
}在完成了 XGBoost 的改造后,我们只需针对 XGBoost On Ray 模块(xgboost_ray)添加对 Arrow 数据格式的支持。这样一来,我们不仅避免了数据格式转换带来的内存开销,还解决了稀疏向量下的内存 OOM 问题。
CPU 多核利用率不超过 100%
在完成数据接入后,我们开始尝试验证 XGBoost 在 Ray 上的训练效率。经过多次测试,我们发现 XGBoost On Ray 的训练效率相比 XGBoost On Spark、XGBoost On K8S 存在较大差距,远低于我们的预期。进一步排查后发现,问题的根源在于 CPU 利用率不足,导致多核能力没有得到充分利用。
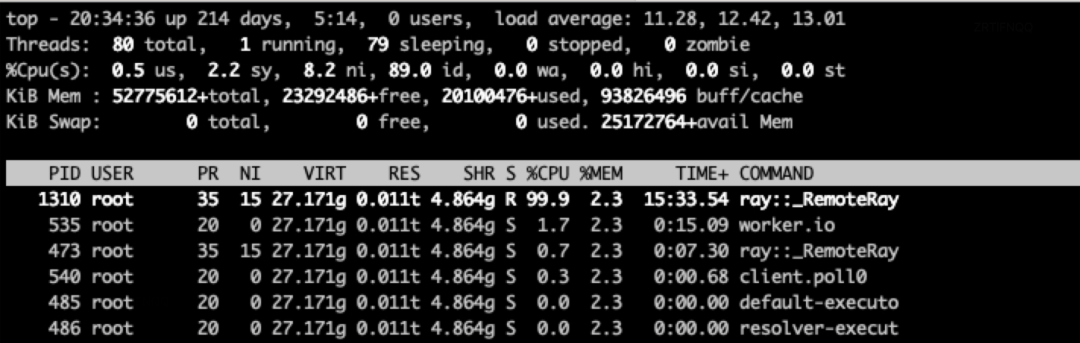
最终,通过代码分析,以及 gdb 调试,发现 XGBoost 在通过 Arrow 构建 DMatrix 时候,未能将多核配置参数设置,如下代码所示:
template <>
SimpleDMatrix::SimpleDMatrix(RecordBatchesIterAdapter* adapter, float missing, int nthread) {LOG(INFO) << "Create Simple DMatrix with RecordBatchesIterAdapter using nthread:" << nthread; this->ctx_.nthread = nthread; // 关键代码缺失,导致多核能力无法利用auto& offset_vec = sparse_page_->offset.HostVector();auto& data_vec = sparse_page_->data.HostVector();uint64_t total_batch_sze = 0;uint64_t total_elements = 0;adapter->BeforeFirst();// Iterate over batches of input datawhile (adapter->Next()) {auto& batches = adapter->Value();size_t num_elements = 0;size_t num_rows = 0;// Import Arrow RecordBatches
#pragma omp parallel for reduction(+ : num_elements, num_rows) num_threads(nthread)for (int i = 0; i < static_cast<int>(batches.size()); ++i) { // NOLINTnum_elements += batches[i]->Import(missing);num_rows += batches[i]->Size();}total_elements += num_elements;total_batch_size += num_rows;在完成以上问题修复后,我们测得在单机训练场景下,在 4 个 CPU 的情况下,模型 CPU 利用率稳定在 400% 左右:

小数据集 OOM 问题
在解决了 CPU 利用率低的问题后,我们再次面临了在资源充足的情况下,百万级数据量训练时的 OOM 问题,这与我们预期的结果不符。经过定位分析,我们发现开源的 xgboost_ray 模块在构建训练集 DMatrix 时,会重复加载两次数据,一次作为训练集,一次作为验证集。在这种情况下,对于大数据集的场景,OOM 问题尤为明显。以下是相关代码:
for deval, name in evals: # 训练集默认也会作为验证集,用于评估指标计算local_evals.append((_get_dmatrix(deval, self._data[deval]), name) # 重复load训练集)因此,考虑到数据集为不可变状态,对于训练集的验证集评估只需要构建一次即可。
for deval, name in evals: # 训练集默认也会作为验证集,用于评估指标计算 if deval != dtrain:local_evals.append((_get_dmatrix(deval, self._data[deval]), name))else:logger.warning(f"evaluate dataset contains training dataset, should not create dmatrix duplicated, just use it directly.")local_evals.append((local_dtrain, name))Ray 任务间资源抢占导致集群调度死锁问题
Autoscaler 是 Ray 的关键特性之一,它能够根据任务需求自动调整 Ray 集群的物理资源,从而实现资源的更高效利用。在批调度中,Gang 调度要求资源必须一次性满足,即 All or Nothing,以避免资源碎片化。XGBoost Ray 任务运行在 K8S 集群上,我们利用 Autoscaler 根据任务需求自动调整物理资源,以提高资源利用率。同时,我们通过 Volcano 实现 Gang 调度。然而,Ray 中的 Autoscaler 资源申请方式是逐个进行的,这不符合 Gang 调度的 All or Nothing 原则。
在我们的应用场景中,当同时执行多个大规模任务时,由于资源竞争导致集群 hang 住。为了解决这个问题,我们对 Autoscaler 进行了资源批申请的改造,通过调整 Ray AutoScaler 在 Pod Group 申请的最小副本校验逻辑,使得 Gang 调度能够正确识别任务的整体资源需求,从而有效地缓解了集群 hang 住的问题。
分类场景下概率校准效率问题
在分类任务中,我们经常使用保序回归(isotonic regression)来校准模型输出的概率得分,以提高其与实际频率或真实概率的一致性。在平台中,约15%的 XGBoost 任务需要进行模型输出校准。
在进行校准之前,需要计算每个预测值对应标签的平均值作为校准的目标值。然而,我们发现基于 Ray.Dataset 的 groupby.mean 实现耗时较长,且对集群内存造成较大压力。为了解决这个问题,我们采用排序+make_unique 的方法来实现这一过程,其中 make_unique 使用 Cython 实现。Cython 会将代码转换为C语言,然后再编译为 Python 可直接使用的动态库。
经过测试,对于100M的数据集,校准总耗时从19分钟降低到了2分钟,效果显著。
以下是 make_unique 函数的 Cython 实现:
import numpy as np
cimport numpy as np
def make_unique(np.ndarray[double, ndim=2] arr):cdef:list unique_x = []list unique_y = []double cur_x = 0double cur_y = 0double cur_w = 0Py_ssize_t ifor i in range(arr.shape[0]):if arr[i,0] == cur_x:cur_y += arr[i,1]cur_w += 1else:if cur_w != 0:unique_x.append(cur_x)unique_y.append(cur_y / cur_w)cur_x = arr[i,0]cur_y = arr[i,1] cur_w = 1if cur_w != 0:unique_x.append(cur_x)unique_y.append(cur_y / cur_w)return unique_x, unique_y总结及展望
尽管 Ray 开源生态丰富,但为了确保稳定性与效率,我们仍需进行充分的测试验证,以适应自身场景的需求。XGBoost 作为 On Ray 技术方向的平台首次尝试,遇到了诸多挑战,但在我们的共同努力下,已成功部署并获得了积极的用户反馈。未来,我们将持续迭代平台功能,提高任务稳定性和效率,同时围绕 Ray 生态开发更多组件,打造更为稳定、高效、易用的算法平台。
数据夜谈
聊聊看,你们在大规模分布式机器学习中有遇到哪些挑战?是如何解决的??如需与我们进一步交流探讨,也可直接私信后台。
作者将选取1则有意义的留言,送出滴滴产研公仔。2月1日晚9点开奖。

相关文章:
滴滴基于 Ray 的 XGBoost 大规模分布式训练实践
背景介绍 作为机器学习模型的核心代表,XGBoost 在滴滴众多策略算法业务场景中发挥着至关重要的作用。因此,保障并持续提升 XGBoost 模型的离线训练及在线推理稳定性一直是机器学习平台的重点工作。同时,面对多样化的业务场景定制需求和数据规…...

k8s从入门到实践
k8s从入门到实践 介绍 Kubernetes(简称k8s)和Docker Swarm是两个流行的容器编排工具,它们都可以帮助用户管理和部署分布式应用,尤其是基于容器的应用。以下是两者的主要特点和对比: Kubernetes (k8s): 开…...
Qt5.12.0 与 VS2017 在 .pro文件转.vcxproj文件
一、参考资料 stackoverflow qt - How to generate .sln/.vcproj using qmake - Stack Overflowhttps://stackoverflow.com/questions/2339832/how-to-generate-sln-vcproj-using-qmake?answertabtrending#tab-topqt - 如何使用 qmake 生成 .sln/.vcproj - IT工具网 (coder.wo…...
金蝶云星空 ServiceGateway RCE漏洞复现
0x01 产品简介 金蝶云星空是一款云端企业资源管理(ERP)软件,为企业提供财务管理、供应链管理以及业务流程管理等一体化解决方案。金蝶云星空聚焦多组织,多利润中心的大中型企业,以 “开放、标准、社交”三大特性为数字经济时代的企业提供开放的 ERP 云平台。服务涵盖:财…...
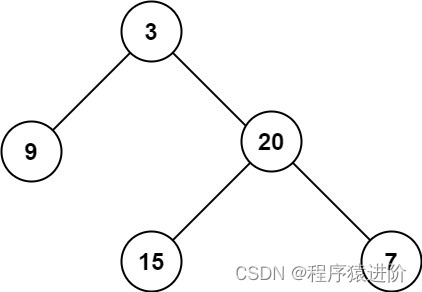
二叉树的最大深度[简单]
优质博文:IT-BLOG-CN 一、题目 给定一个二叉树root,返回其最大深度。 二叉树的最大深度是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3 示例 2:…...

[Redis]不同系统间安装redis服务器
日常服务器端开发,消息队列等需求,免不了用到redis,搭建一个redis服务器,方便开发和测试,我们从以下三类系统来说明下: 安装 Redis 服务器的过程因操作系统而异。以下是在常见的 Linux 发行版(…...
Unity之动画和角色控制
目录 📕 一、动画 1.创建最简单的动画 2.动画控制器 📕二、把动画和角色控制相结合 📕三、实现实例 3.1 鼠标控制角色视角旋转 3.2 拖尾效果 📕四、混合动画 最近学到动画了,顺便把之前创建的地形࿰…...

C语言库函数实现字符串转大小写
目录 引言 代码 引言 处理字符串时,除了将字符串中的所有大写字母转换为小写字母外,我们还可以利用其他相关函数进行更丰富的文本操作。本文将以一段使用isupper()、tolower()函数实现字符串全转小写的C语言程序为例,详细介绍这两个函数以及…...
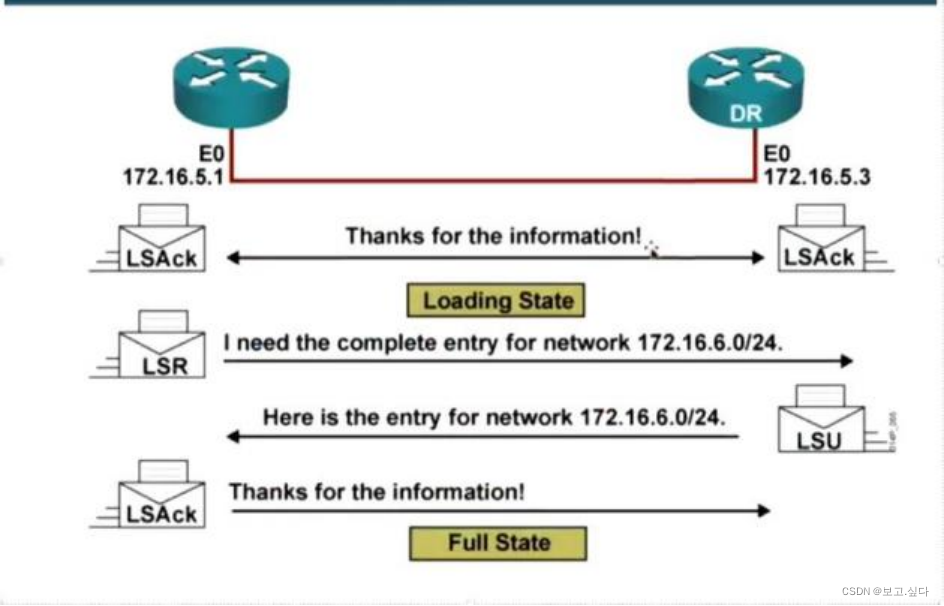
hcip----ospf
一:动态路由协议 IGP 协议---RIP OSPF ISIS EIGRP EGP--EGP ---BGP 三个角度的评判一款动态路由协议的优劣 RIP --request response 1.选路--选路依据不好,可能出现环路 2.收敛速度--计时器 3.占用资源-- RIPV1 RIPV2 RIPNG--ipv6 OSPFV1 OSPFV…...

vue中如何写过滤器
全局注册 (可以在main.js中进行全局注册 vue.fifler(test’,function(v){return v0? ‘终止’:v1?进行中:异常 })在组件页面使用 <view>{{state|test}}</view> <script> export default {data(){return {state: 1// state 1 进行中…...
)
c语言-文件的读写操作(下)
文章目录 前言一、文件的随机读写1.1 fseek()1.2 ftell()1.3 rewind() 总结 前言 本篇文章介绍c语言中文件的随机读写 一、文件的随机读写 1.1 fseek() fseek()函数的作用是根据文件指针的位置和偏移量定位文件指针 int fseek ( FILE * stream, long int offset, int origi…...

android学习笔记----SQLite数据库
用SQLite语句执行: 首先看到界面: 代码如下: MainActivity.java import android.support.v7.app.AppCompatActivity; import android.os.Bundle; import android.text.TextUtils; import android.view.View; import android.widget.EditTe…...

开发知识点-Flutter移动应用开发
支持 安卓 IOS Android 鸿蒙 第一章dart基础章节介绍 移动电商——Flutter-广告Banner组件制作 移动电商——Flutter实战课程介绍 Flutter实例——路由跳转的动画效果...

视频尺寸魔方:分层遮掩3D扩散模型在视频尺寸延展的应用
▐ 摘要 视频延展(Video Outpainting)是对视频的边界进行扩展的任务。与图像延展不同,视频延展需要考虑到填充区域的时序一致性,这使得问题更具挑战性。在本文中,我们介绍了一个新颖的基于扩散模型的视频尺寸延展方法——分层遮掩3D扩散模型(…...

openssl3.2/test/certs - 061 - other@good.org not permitted by CA1
文章目录 openssl3.2/test/certs - 061 - othergood.org not permitted by CA1概述笔记END openssl3.2/test/certs - 061 - othergood.org not permitted by CA1 概述 openssl3.2 - 官方demo学习 - test - certs 笔记 /*! * \file D:\my_dev\my_local_git_prj\study\openSS…...

如何实现无公网ip远程访问本地websocket服务端【内网穿透】
文章目录 1. Java 服务端demo环境2. 在pom文件引入第三包封装的netty框架maven坐标3. 创建服务端,以接口模式调用,方便外部调用4. 启动服务,出现以下信息表示启动成功,暴露端口默认99995. 创建隧道映射内网端口6. 查看状态->在线隧道,复制所创建隧道的公网地址加端口号7. 以…...

pip清华源怎么换回来
怎么临时使用清华源 pip install scrapy -i https://pypi.Python.org/simple/怎么永久换源 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple修改清华源后怎么换回来 删掉/home/XXX/.config/pip/pip.conf...

[Go]认识Beego框架
对比Gin的简洁,自己之前基于Gin撸了一个架子,确实比beego目录看着舒服多了,不过最近接触到beego的项目,beego的bee工具使用还是很方便,来简单梳理下细节; Beego是一个开源的Go语言Web应用框架,…...
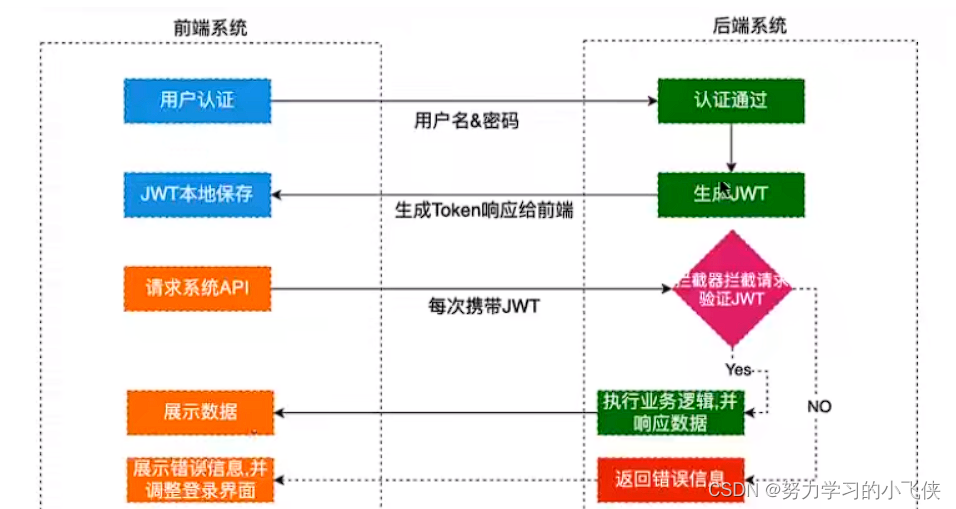
JWT登录
JWT JSON Web Token(JSON Web令牌) 是一个开放标准(rfc7519),它定义了一种紧凑的、自包含的方式,用于在各方之间以JSON对象安全地传输信息。此信息可以验证和信任,因为它是数字签名的。jwt可以使用秘密〈使用HNAC算法…...

MySQL和Redis的事务有什么异同?
MySQL和Redis是两种不同类型的数据库管理系统,它们在事务处理方面有一些重要的异同点。 MySQL事务: ACID属性: MySQL是一个关系型数据库管理系统(RDBMS),支持ACID属性,即原子性(Ato…...

电源完整性设计:电容模型、去耦策略与测量验证实战解析
1. 电容与去耦:从概念到实战的深度解析上周我们聊了聊去耦电容在电源完整性设计中的一些基本概念和时机选择,算是开了个头。这周咱们继续深入,把这块硬骨头啃得更透一些。很多工程师,尤其是刚入行的朋友,常常觉得电容选…...

基于MCP的任务编排框架:让AI代理动态规划与执行复杂工作流
1. 项目概述:一个面向AI代理的任务编排与执行框架最近在折腾AI应用开发,特别是想让大语言模型(LLM)能更“自主”地完成一些复杂任务时,发现了一个绕不开的痛点:任务编排。你给模型一个目标,比如…...

DOM NodeList 深入解析
DOM NodeList 深入解析 概述 DOM NodeList 是 Web 开发中常用的一种数据结构,它代表了文档中一系列元素的集合。在本文中,我们将对 DOM NodeList 进行深入解析,包括其定义、特点、使用方法以及在实际开发中的应用。 定义 DOM NodeList 是一个类似数组的对象,它包含了文…...

下行周期生存之道 = 低风险试错 × 即时反馈 × 长期复购
总结公式: 下行周期赚钱 低风险试错 即时反馈 长期复购 日本用30年验证了这套逻辑。 普通人现在能不能赚到钱,不在于胆子够不够大,而在于你能不能在大家焦虑的时候,给他一点确定感。 先收藏,慢慢找自己的切入口。...

LeetCode 岛屿数量题解
LeetCode 岛屿数量题解 题目描述 给定一个二维网格地图 1(陆地)和 0(水),计算岛屿的数量。 示例: 输入:grid [ ["1","1","1","1","0"], …...

别再只盯着应力云图了!用ANSYS Workbench的‘圣维南原理’和模型简化,把你的计算效率提升200%
别再只盯着应力云图了!用ANSYS Workbench的‘圣维南原理’和模型简化,把你的计算效率提升200% 有限元分析工程师常常陷入一个误区:认为模型越精细,结果越准确。但现实情况是,一个未经合理简化的复杂模型不仅会消耗大量…...
原理、影响与防护策略全解析)
FPGA单粒子翻转(SEU)原理、影响与防护策略全解析
1. 是什么在“骚扰”我的FPGA?——深入解析单粒子翻转作为一名在电子设计领域摸爬滚打了十几年的工程师,我经手过不少高可靠性的项目,从地面通信基站到近地轨道的载荷设备都有涉及。在这些项目中,有一个幽灵般的问题总是如影随形&…...
— 硬件I2C驱动AT24C02 EEPROM从零到一)
小熊派gd32f303实战指南(9)— 硬件I2C驱动AT24C02 EEPROM从零到一
1. 硬件I2C与AT24C02基础认知 第一次接触硬件I2C时,我也被那些专业术语搞得一头雾水。简单来说,I2C就像两个人用摩斯密码交流——只需要两根线(SDA数据线和SCL时钟线),就能让主设备(GD32F303)和…...

纯Java实现Gemma大模型推理:在JVM中部署轻量级AI的工程实践
1. 项目概述:当Gemma遇上Java,一个轻量级AI推理的新选择最近在开源社区里,一个名为mukel/gemma4.java的项目引起了我的注意。作为一名长期在Java生态和机器学习边缘部署领域摸爬滚打的开发者,看到这个标题的第一反应是:…...

渗透PHP伪协议
一、debug调试 1、定义 Debug,又叫断点调试,就是对写好的程序进行逐步运行、分解、调试的过程,通过这个过程,我们可以跟踪程序的详细运行过程, 是程序员的开发神器,也是开发必会的一个重要技能。 2、意义…...