算法代码题——模板
文章目录
- 1. 双指针: 只有一个输入, 从两端开始遍历
- 2. 双指针: 有两个输入, 两个都需要遍历完
- 3. 滑动窗口
- 4. 构建前缀和
- 5. 高效的字符串构建
- 6. 链表: 快慢指针
- 7. 反转链表
- 8. 找到符合确切条件的子数组数
- 9. 单调递增栈
- 10. 二叉树: DFS (递归)]
- 11. 二叉树: DFS (迭代)
- 12. 二叉树: BFS
- 13. 图: DFS (递归)
- 14. 图: DFS (迭代)
- 15. 图: BFS
- 16. 找到堆的前 k 个元素
- 17. 二分查找
- 18. 二分查找: 重复元素,最左边的插入点
- 19. 二分查找: 重复元素,最右边的插入点
- 20. 二分查找: 贪心问题
- 寻找最小值:
- 寻找最大值:
- 21. 回溯
- 22. 动态规划: 自顶向下法
- 23. 构建前缀树(字典树)
1. 双指针: 只有一个输入, 从两端开始遍历
def fn(arr):left = ans = 0right = len(arr) - 1while left < right:# 一些根据 letf 和 right 相关的代码补充if CONDITION:left += 1else:right -= 1return ans
int fn(vector<int>& arr) {int left = 0;int right = int(arr.size()) - 1;int ans = 0;while (left < right) {// 一些根据 letf 和 right 相关的代码补充if (CONDITION) {left++;} else {right--;}}return ans;
}2. 双指针: 有两个输入, 两个都需要遍历完
def fn(arr1, arr2):i = j = ans = 0while i < len(arr1) and j < len(arr2):# 根据题意补充代码if CONDITION:i += 1else:j += 1while i < len(arr1):# 根据题意补充代码i += 1while j < len(arr2):# 根据题意补充代码j += 1return ans
int fn(vector<int>& arr1, vector<int>& arr2) {int i = 0, j = 0, ans = 0;while (i < arr1.size() && j < arr2.size()) {// 根据题意补充代码if (CONDITION) {i++;} else {j++;}}while (i < arr1.size()) {// 根据题意补充代码i++;}while (j < arr2.size()) {// 根据题意补充代码j++;}return ans;
}3. 滑动窗口
def fn(arr):left = ans = curr = 0for right in range(len(arr)):# 根据题意补充代码来将 arr[right] 添加到 currwhile WINDOW_CONDITION_BROKEN:# 从 curr 中删除 arr[left]left += 1# 更新 ansreturn ansint fn(vector<int>& arr) {int left = 0, ans = 0, curr = 0;for (int right = 0; right < arr.size(); right++) {// 根据题意补充代码来将 arr[right] 添加到 currwhile (WINDOW_CONDITION_BROKEN) {// 从 curr 中删除 arr[left]left++;}// 更新 ans}return ans;
}4. 构建前缀和
def fn(arr):prefix = [arr[0]]for i in range(1, len(arr)):prefix.append(prefix[-1] + arr[i])return prefix
vector<int> fn(vector<int>& arr) {vector<int> prefix(arr.size());prefix[0] = arr[0];for (int i = 1; i < arr.size(); i++) {prefix[i] = prefix[i - 1] + arr[i];}return prefix;
}5. 高效的字符串构建
# arr 是一个字符列表
def fn(arr):ans = []for c in arr:ans.append(c)return "".join(ans)
string fn(vector<char>& arr) {return string(arr.begin(), arr.end())
}
6. 链表: 快慢指针
def fn(head):slow = headfast = headans = 0while fast and fast.next:# 根据题意补充代码slow = slow.nextfast = fast.next.nextreturn ansint fn(ListNode* head) {ListNode* slow = head;ListNode* fast = head;int ans = 0;while (fast != nullptr && fast->next != nullptr) {// 根据题意补充代码slow = slow->next;fast = fast->next->next;}return ans;
}7. 反转链表
def fn(head):curr = headprev = Nonewhile curr:next_node = curr.nextcurr.next = prevprev = currcurr = next_node return prev
ListNode* fn(ListNode* head) {ListNode* curr = head;ListNode* prev = nullptr;while (curr != nullptr) {ListNode* nextNode = curr->next;curr->next = prev;prev = curr;curr = nextNode;}return prev;
}8. 找到符合确切条件的子数组数
from collections import defaultdictdef fn(arr, k):counts = defaultdict(int)counts[0] = 1ans = curr = 0for num in arr:# 根据题意补充代码来改变 currans += counts[curr - k]counts[curr] += 1return ans
int fn(vector<int>& arr, int k) {unordered_map<int, int> counts;counts[0] = 1;int ans = 0, curr = 0;for (int num: arr) {// 根据题意补充代码来改变 currans += counts[curr - k];counts[curr]++;}return ans;
}9. 单调递增栈
def fn(arr):stack = []ans = 0for num in arr:# 对于单调递减的情况,只需将 > 翻转到 <while stack and stack[-1] > num:# 根据题意补充代码stack.pop()stack.append(num)return ansint fn(vector<int>& arr) {stack<integer> stack;int ans = 0;for (int num: arr) {// 对于单调递减的情况,只需将 > 翻转到 <while (!stack.empty() && stack.top() > num) {// 根据题意补充代码stack.pop();}stack.push(num);}
}10. 二叉树: DFS (递归)]
def dfs(root):if not root:returnans = 0# 根据题意补充代码dfs(root.left)dfs(root.right)return ans
int dfs(TreeNode* root) {if (root == nullptr) {return 0;}int ans = 0;// 根据题意补充代码dfs(root.left);dfs(root.right);return ans;
}11. 二叉树: DFS (迭代)
def dfs(root):stack = [root]ans = 0while stack:node = stack.pop()# 根据题意补充代码if node.left:stack.append(node.left)if node.right:stack.append(node.right)return ansint dfs(TreeNode* root) {stack<TreeNode*> stack;stack.push(root);int ans = 0;while (!stack.empty()) {TreeNode* node = stack.top();stack.pop();// 根据题意补充代码if (node->left != nullptr) {stack.push(node->left);}if (node->right != nullptr) {stack.push(node->right);}}return ans;
}12. 二叉树: BFS
from collections import dequedef fn(root):queue = deque([root])ans = 0while queue:current_length = len(queue)# 做一些当前层的操作for _ in range(current_length):node = queue.popleft()# 根据题意补充代码if node.left:queue.append(node.left)if node.right:queue.append(node.right)return ans
int fn(TreeNode* root) {queue<TreeNode*> queue;queue.push(root);int ans = 0;while (!queue.empty()) {int currentLength = queue.size();// 做一些当前层的操作for (int i = 0; i < currentLength; i++) {TreeNode* node = queue.front();queue.pop();// 根据题意补充代码if (node->left != nullptr) {queue.push(node->left);}if (node->right != nullptr) {queue.push(node->right);}}}return ans;
}13. 图: DFS (递归)
以下图模板假设节点编号从 0 到 n - 1 ,并且图是以邻接表的形式给出的。
- 根据问题的不同,可能需要在使用模板之前将输入转换为等效的邻接表。
def fn(graph):def dfs(node):ans = 0# 根据题意补充代码for neighbor in graph[node]:if neighbor not in seen:seen.add(neighbor)ans += dfs(neighbor)return ansseen = {START_NODE}return dfs(START_NODE)unordered_set<int> seen;int fn(vector<vector<int>>& graph) {seen.insert(START_NODE);return dfs(START_NODE, graph);
}int fn dfs(int node, vector<vector<int>>& graph) {int ans = 0;// 根据题意补充代码for (int neighbor: graph[node]) {if (seen.find(neighbor) == seen.end()) {seen.insert(neighbor);ans += dfs(neighbor, graph);}}return ans;
}14. 图: DFS (迭代)
def fn(graph):stack = [START_NODE]seen = {START_NODE}ans = 0while stack:node = stack.pop()# 根据题意补充代码for neighbor in graph[node]:if neighbor not in seen:seen.add(neighbor)stack.append(neighbor)return ans
int fn(vector<vector<int>>& graph) {stack<int> stack;unordered_set<int> seen;stack.push(START_NODE);seen.insert(START_NODE);int ans = 0;while (!stack.empty()) {int node = stack.top();stack.pop();// 根据题意补充代码for (int neighbor: graph[node]) {if (seen.find(neighbor) == seen.end()) {seen.insert(neighbor);stack.push(neighbor);}}}
}
15. 图: BFS
from collections import dequedef fn(graph):queue = deque([START_NODE])seen = {START_NODE}ans = 0while queue:node = queue.popleft()# 根据题意补充代码for neighbor in graph[node]:if neighbor not in seen:seen.add(neighbor)queue.append(neighbor)return ansint fn(vector<vector<int>>& graph) {queue<int> queue;unordered_set<int> seen;queue.add(START_NODE);seen.insert(START_NODE);int ans = 0;while (!queue.empty()) {int node = queue.front();queue.pop();// 根据题意补充代码for (int neighbor: graph[node]) {if (seen.find(neighbor) == seen.end()) {seen.insert(neighbor);queue.push(neighbor);}}}
}16. 找到堆的前 k 个元素
import heapqdef fn(arr, k):heap = []for num in arr:# 做根据题意补充代码,根据问题的条件来推入堆中heapq.heappush(heap, (CRITERIA, num))if len(heap) > k:heapq.heappop(heap)return [num for num in heap]vector<int> fn(vector<int>& arr, int k) {priority_queue<int, CRITERIA> heap;for (int num: arr) {heap.push(num);if (heap.size() > k) {heap.pop();}}vector<int> ans;while (heap.size() > 0) {ans.push_back(heap.top());heap.pop();}return ans;
}17. 二分查找
def fn(arr, target):left = 0right = len(arr) - 1while left <= right:mid = (left + right) // 2if arr[mid] == target:# 根据题意补充代码returnif arr[mid] > target:right = mid - 1else:left = mid + 1# left 是插入点return leftint binarySearch(vector<int>& arr, int target) {int left = 0;int right = int(arr.size()) - 1;while (left <= right) {int mid = left + (right - left) / 2;if (arr[mid] == target) {// 根据题意补充代码return mid;}if (arr[mid] > target) {right = mid - 1;} else {left = mid + 1;}}// left 是插入点return left;}18. 二分查找: 重复元素,最左边的插入点
def fn(arr, target):left = 0right = len(arr)while left < right:mid = (left + right) // 2if arr[mid] >= target:right = midelse:left = mid + 1return leftint binarySearch(vector<int>& arr, int target) {int left = 0;int right = arr.size();while (left < right) {int mid = left + (right - left) / 2;if (arr[mid] >= target) {right = mid;} else {left = mid + 1;}}return left;
}19. 二分查找: 重复元素,最右边的插入点
def fn(arr, target):left = 0right = len(arr)while left < right:mid = (left + right) // 2if arr[mid] > target:right = midelse:left = mid + 1return leftint binarySearch(vector<int>& arr, int target) {int left = 0;int right = arr.size();while (left < right) {int mid = left + (right - left) / 2;if (arr[mid] > target) {right = mid;} else {left = mid + 1;}}return left;
}20. 二分查找: 贪心问题
寻找最小值:
def fn(arr):def check(x):# 这个函数的具体实现取决于问题return BOOLEANleft = MINIMUM_POSSIBLE_ANSWERright = MAXIMUM_POSSIBLE_ANSWERwhile left <= right:mid = (left + right) // 2if check(mid):right = mid - 1else:left = mid + 1return left
int fn(vector<int>& arr) {int left = MINIMUM_POSSIBLE_ANSWER;int right = MAXIMUM_POSSIBLE_ANSWER;while (left <= right) {int mid = left + (right - left) / 2;if (check(mid)) {right = mid - 1;} else {left = mid + 1;}}return left;
}bool check(int x) {// 这个函数的具体实现取决于问题return BOOLEAN;
}寻找最大值:
def fn(arr):def check(x):# 这个函数的具体实现取决于问题return BOOLEANleft = MINIMUM_POSSIBLE_ANSWERright = MAXIMUM_POSSIBLE_ANSWERwhile left <= right:mid = (left + right) // 2if check(mid):left = mid + 1else:right = mid - 1return rightint fn(vector<int>& arr) {int left = MINIMUM_POSSIBLE_ANSWER;int right = MAXIMUM_POSSIBLE_ANSWER;while (left <= right) {int mid = left + (right - left) / 2;if (check(mid)) {left = mid + 1;} else {right = mid - 1;}}return right;
}bool check(int x) {// 这个函数的具体实现取决于问题return BOOLEAN;
}21. 回溯
def backtrack(curr, OTHER_ARGUMENTS...):if (BASE_CASE):# 修改答案returnans = 0for (ITERATE_OVER_INPUT):# 修改当前状态ans += backtrack(curr, OTHER_ARGUMENTS...)# 撤消对当前状态的修改return ansint backtrack(STATE curr, OTHER_ARGUMENTS...) {if (BASE_CASE) {// 修改答案return 0;}int ans = 0;for (ITERATE_OVER_INPUT) {// 修改当前状态ans += backtrack(curr, OTHER_ARGUMENTS...)// 撤消对当前状态的修改}return ans;
}22. 动态规划: 自顶向下法
def fn(arr):def dp(STATE):if BASE_CASE:return 0if STATE in memo:return memo[STATE]ans = RECURRENCE_RELATION(STATE)memo[STATE] = ansreturn ansmemo = {}return dp(STATE_FOR_WHOLE_INPUT)unordered_map<STATE, int> memo;int fn(vector<int>& arr) {return dp(STATE_FOR_WHOLE_INPUT, arr);
}int dp(STATE, vector<int>& arr) {if (BASE_CASE) {return 0;}if (memo.find(STATE) != memo.end()) {return memo[STATE];}int ans = RECURRENCE_RELATION(STATE);memo[STATE] = ans;return ans;
}23. 构建前缀树(字典树)
- 注意:只有需要在每个节点上存储数据时才需要使用类。
- 否则,您可以只使用哈希映射实现一个前缀树。
# 注意:只有需要在每个节点上存储数据时才需要使用类。
# 否则,您可以只使用哈希映射实现一个前缀树。
class TrieNode:def __init__(self):# you can store data at nodes if you wishself.data = Noneself.children = {}def fn(words):root = TrieNode()for word in words:curr = rootfor c in word:if c not in curr.children:curr.children[c] = TrieNode()curr = curr.children[c]# 这个位置上的 curr 已经有一个完整的单词# 如果你愿意,你可以在这里执行更多的操作来给 curr 添加属性return root
// 注意:只有需要在每个节点上存储数据时才需要使用类。
// 否则,您可以只使用哈希映射实现一个前缀树。
struct TrieNode {int data;unordered_map<char, TrieNode*> children;TrieNode() : data(0), children(unordered_map<char, TrieNode*>()) {}
};TrieNode* buildTrie(vector<string> words) {TrieNode* root = new TrieNode();for (string word: words) {TrieNode* curr = root;for (char c: word) {if (curr->children.find(c) == curr->children.end()) {curr->children[c] = new TrieNode();}curr = curr->children[c];// 这个位置上的 curr 已经有一个完整的单词// 如果你愿意,你可以在这里执行更多的操作来给 curr 添加属性}}return root;
}相关文章:

算法代码题——模板
文章目录1. 双指针: 只有一个输入, 从两端开始遍历2. 双指针: 有两个输入, 两个都需要遍历完3. 滑动窗口4. 构建前缀和5. 高效的字符串构建6. 链表: 快慢指针7. 反转链表8. 找到符合确切条件的子数组数9. 单调递增栈10. 二叉树: DFS (递归)]11. 二叉树: DFS (迭代)12. 二叉树: …...
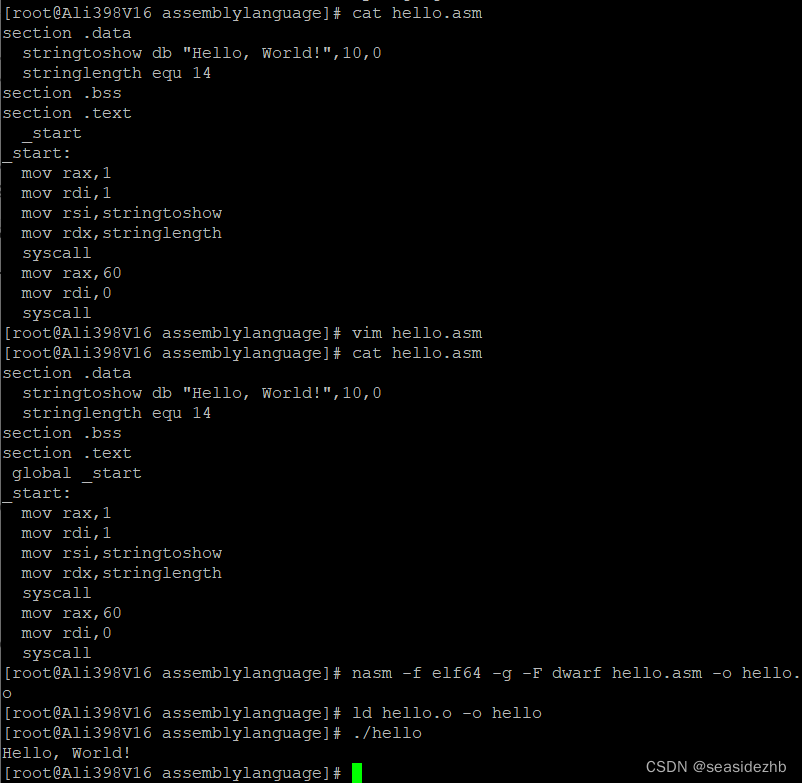
CentOS 7.9汇编语言版Hello World
先下载、编译nasm汇编器。NASM汇编器官网如下图所示: 可以点图中的List进入历史版本下载网址: 我这里下载的是nasm-2.15.05.tar.bz2 在CentOS 7中,使用 wget http://www.nasm.us/pub/nasm/releasebuilds/2.15.05/nasm-2.15.05.tar.bz2下载…...

CoreData数据库探索
CoreData是什么 Core Data 是苹果公司提供的一个对象-关系映射框架(Object-Relational Mapping,ORM),用于管理应用程序的数据模型。Core Data 提供了一个抽象层,使开发人员能够使用面向对象的方式访问和操作数据&…...
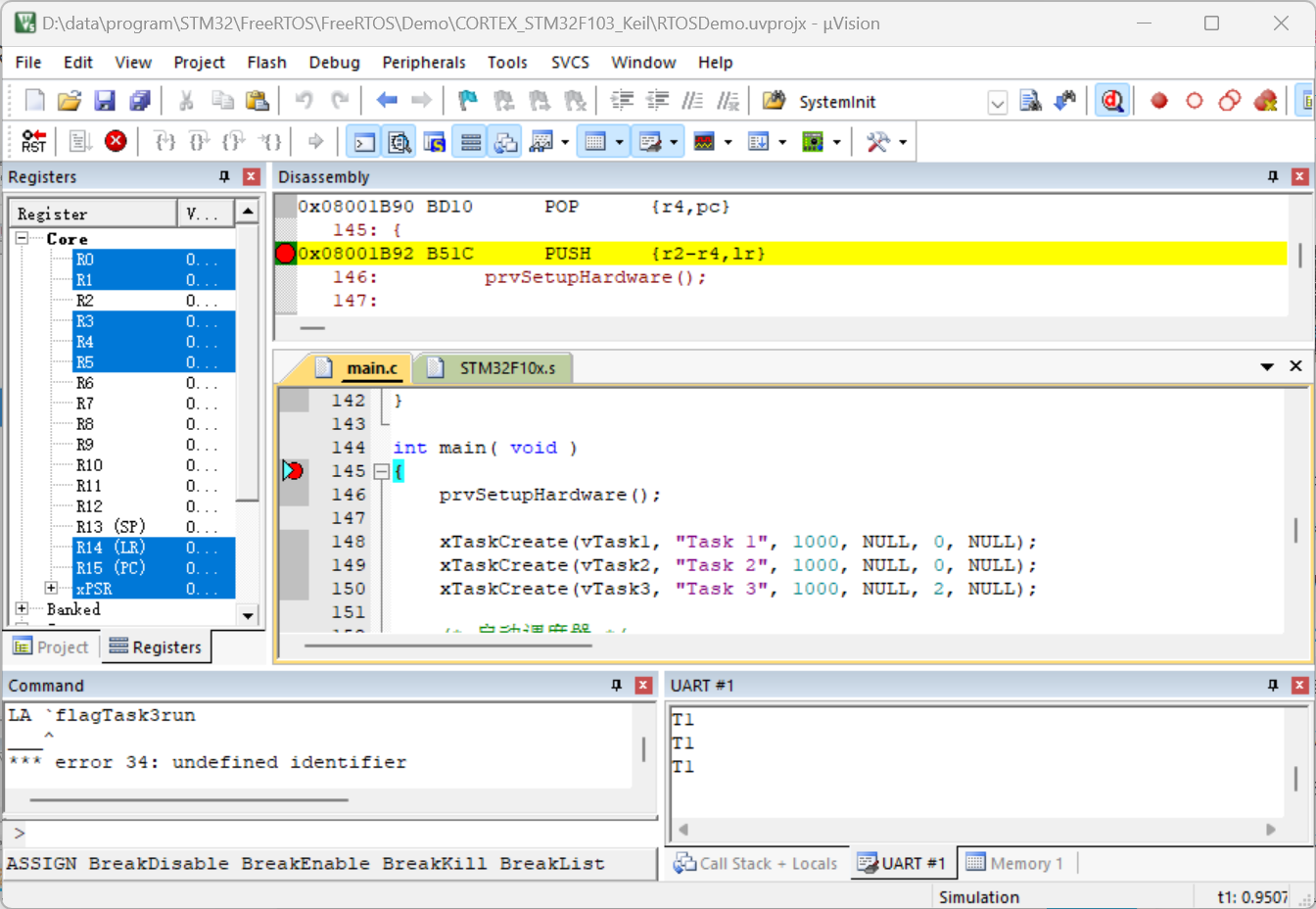
FreeRTOS入门
目录 一、简介 二、堆的概念 三、栈的概念 四、从官方源码中精简出第一个FreeRTOS程序 五、修改官方源码增加串口打印 一、简介 FreeRTOS是一个迷你的实时操作系统内核。作为一个轻量级的操作系统,功能包括:任务管理、时间管理、信号量、消息队列、…...
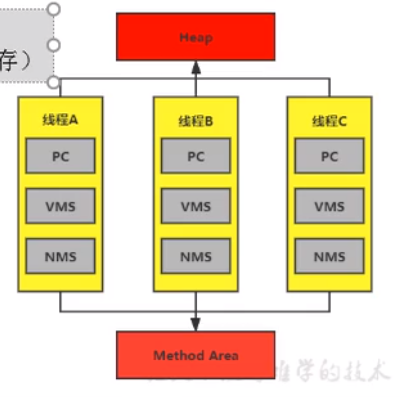
JVM运行时数据区划分
Java内存空间 内存是非常重要的系统资源,是硬盘和cpu的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM内存布局规定了JAVA在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行。不同的jvm对于内存的划分方式和管理机…...
重装系统一半电脑蓝屏如何解决
小编相信大家在使用电脑或者给电脑重装系统的时候都遇到过电脑蓝屏等等故障问题。最近有用户就遇到了这样一个问题,问小编重装系统一半电脑蓝屏怎么办,那么今天小编就告诉大家重装系统一半电脑蓝屏的解决方法。 工具/原料: 系统版本&#x…...
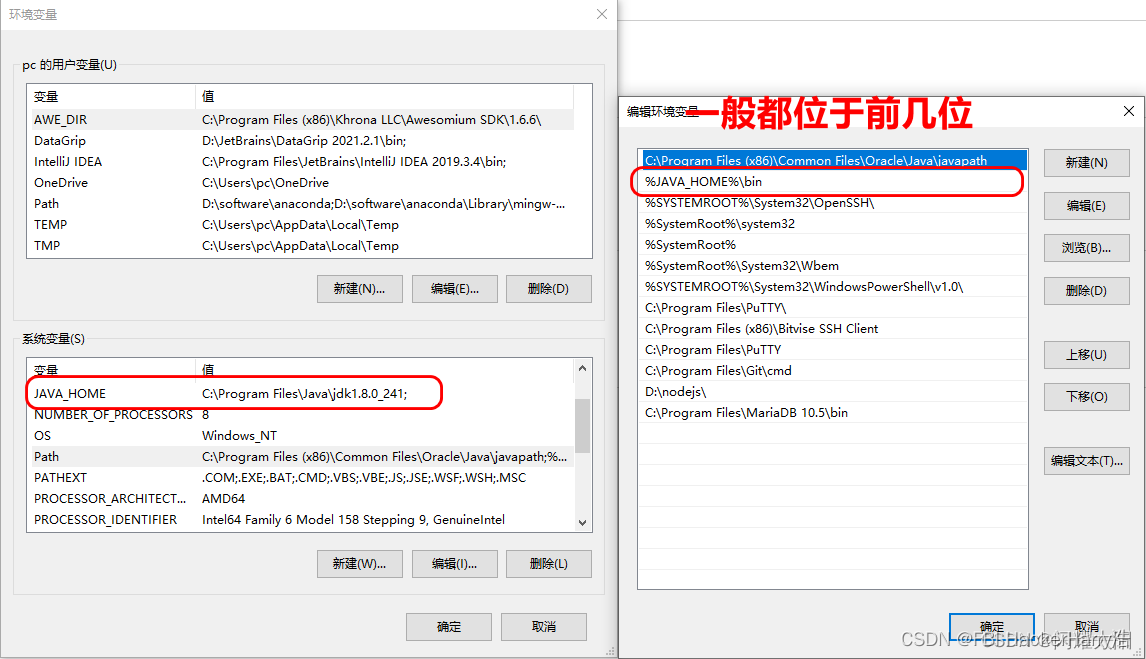
SpringBoot(tedu)——day01——环境搭建
SpringBoot(tedu)——day01——环境搭建 目录SpringBoot(tedu)——day01——环境搭建零、今日目标一、IDEA2021项目环境搭建1.1 通过 ctrl鼠标滚轮 实现字体大小缩放1.2 自动提示设置 去除大小写匹配1.3 设置参数方法自动提示1.4 设定字符集 要求都使用UTF-8编码1.5 设置自动编…...

springboot整合redis
1.redis的数据类型,一共有5种.后面结合Jedis和redistemplate,以及单元测试junit一起验证 1)字符串 2)hash 3)列表 4)set(无序集合) 5)zset(有序集合) 2.Jedis的使用 a)引入依赖 <!--加入springboot的starter的起步依赖--><dependency><groupId>…...
【Java】Spring Boot下的MVC
文章目录Spring MVC程序开发1. 什么是Spring MVC?1.1 MVC定义1.2 MVC 和 Spring MVC 的关系2. 为什么学习Spring MVC?3. 怎么学习Spring MVC?3.1 Spring MVC的创建和连接3.1.1 创建Spring MVC项目3.1.2 RequestMapping 注解介绍3.1.3 Request…...
【项目精选】 塞北村镇旅游网站设计(视频+论文+源码)
点击下载源码 摘要 城市旅游产业的日新月异影响着村镇旅游产业的发展变化。网络、电子科技的迅猛前进同样牵动着旅游产业的快速成长。随着人们消费理念的不断发展变化,越来越多的人开始注意精神文明的追求,而不仅仅只是在意物质消费的提高。塞北村镇旅游…...

十、Spring IoC注解式开发
1 声明Bean的注解 负责声明Bean的注解,常见的包括四个: ComponentControllerServiceRepository Controller、Service、Repository这三个注解都是Component注解的别名。 也就是说:这四个注解的功能都一样。用哪个都可以。 只是为了增强程序…...
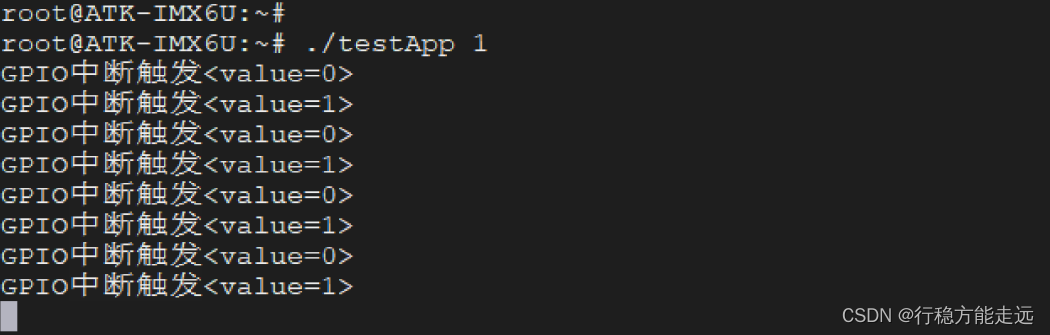
Linux系统GPIO应用编程
目录应用层如何操控GPIOGPIO 应用编程之输出GPIO 应用编程之输入GPIO 应用编程之中断在开发板上测试GPIO 输出测试GPIO 输入测试GPIO 中断测试本章介绍应用层如何控制GPIO,譬如控制GPIO 输出高电平、或输出低电平。应用层如何操控GPIO 与LED 设备一样,G…...
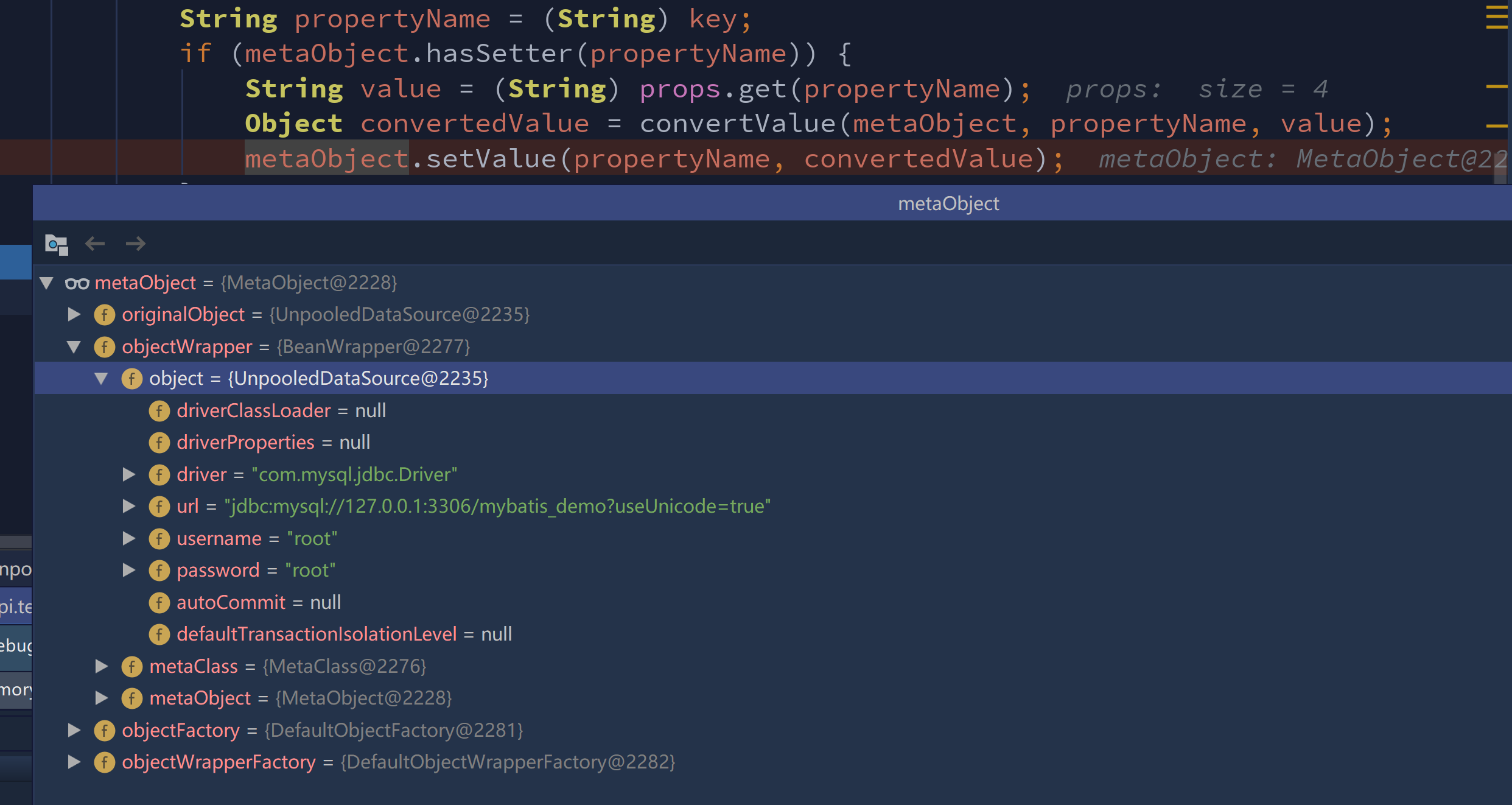
手敲Mybatis-反射工具天花板
历时漫长的岁月,终于鼓起勇气继续研究Mybatis的反射工具类们,简直就是把反射玩出花,但是理解起来还是很有难度的,涉及的内容代码也颇多,所以花费时间也比较浩大,不过当了解套路每个类的功能也好,…...
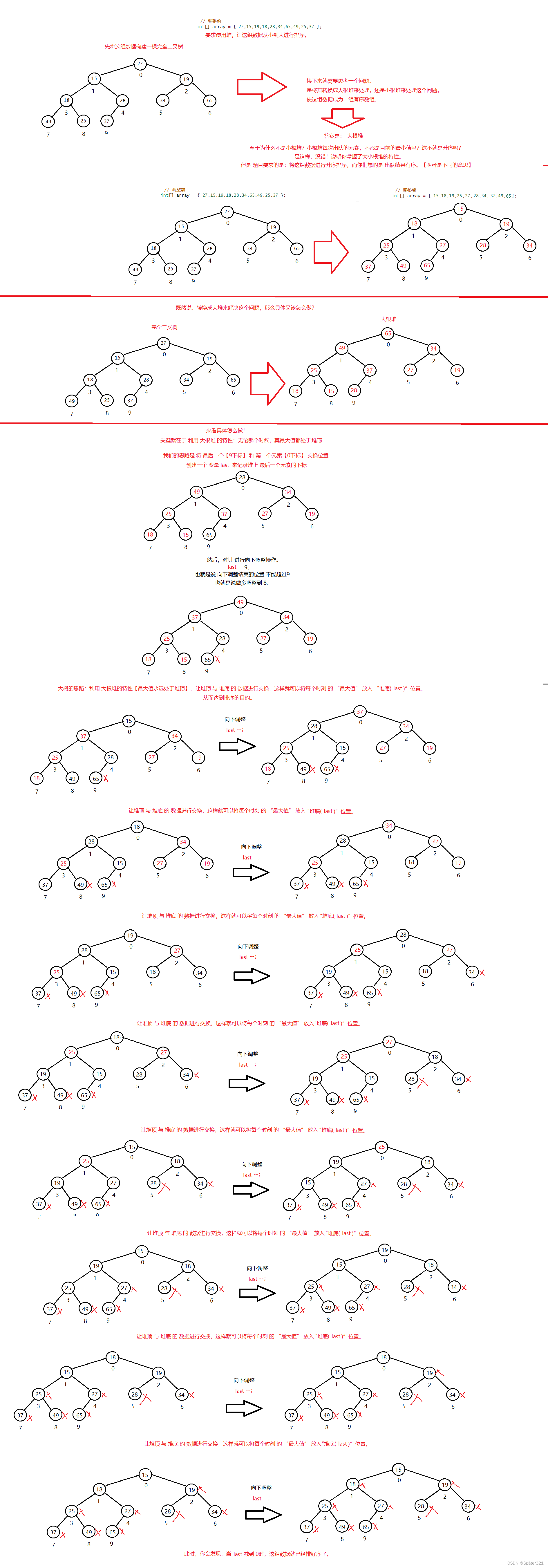
Java -数据结构,【优先级队列 / 堆】
一、二叉树的顺序存储 在前面我们已经讲了二叉树的链式存储,就是一棵树的左孩子和右孩子 而现在讲的是:顺序存储一棵二叉树。 1.1、存储方式 使用数组保存二叉树结构,方式即将二叉树用层序遍历方式放入数组中。 一般只适合表示完全二叉树&a…...

Python+Qt指纹录入识别考勤系统
PythonQt指纹录入识别考勤系统如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<PythonQt指纹录入识别考勤系统>>编写代码,代码整洁,规则,易读。 学…...
K_A14_004 基于STM32等单片机驱动旋转角度传感器模块 串口与OLED0.96双显示
K_A14_004 基于STM32等单片机驱动旋转角度传感器模块 串口与OLED0.96双显示一、资源说明二、基本参数参数引脚说明三、驱动说明IIC地址/采集通道选择/时序对应程序:四、部分代码说明1、接线引脚定义1.1、STC89C52RC旋转角度传感器模块1.2、STM32F103C8T6旋转角度传感器模块五、…...

2023年全国最新机动车签字授权人精选真题及答案12
百分百题库提供机动车签字授权人考试试题、机动车签字授权人考试预测题、机动车签字授权人考试真题、机动车签字授权人证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.注册登记前所有机动车都应进行安全技术检验。 答案…...
Linux小黑板(10):信号
我们写在linux系统环境下写一个程序,唔,"它的功能是每隔1s向屏幕打印hello world。"这时,我们在键盘上按出"Ctrl C"后,进程会发生什么??我们清晰地看到,进程已经在我们按出"Ctrl…...
GO 语言基础语法一 (快速入门 Go 语言)
Go语言基础语法一. golang 标识符,关键字,命名规则二. golang 变量三. golang 常量四. golang 数据类型五. golang 布尔类型六. golang 数字类型七. golang 字符串1. go语言字符串字面量2. go语言字符串连接(1). 使用加号(2). 使用 fmt.Sprintf() 函数(3…...

Java高效率复习-SpringMVC[SpringMVC-2]
SpringMVC获取请求参数 SpringMVC获取请求参数的两种方式↓ 通过ServletAPI获取请求参数 将HttpServletRequest作为控制器方法的形参,此时HttpServletRequest类型的参数表示封装了当前请求的请求报文的对象 通过request的API——getParameter(String s)方法来获取…...

PyTorch 3.0静态图训练突然降速37%?紧急排查清单:CUDA Graph复用失效、TensorPipe通道泄漏、以及被隐藏的TORCH_COMPILE_DEBUG=1黄金日志开关
第一章:PyTorch 3.0静态图分布式训练性能骤降的典型现象与影响评估近期多个生产级训练集群反馈,在升级至尚未正式发布的 PyTorch 3.0 预览版(基于 TorchDynamo AOTAutograd 的全静态图编译路径)后,使用 torch.distrib…...

SecGPT-14B模型微调:提升OpenClaw安全任务执行准确率
SecGPT-14B模型微调:提升OpenClaw安全任务执行准确率 1. 为什么需要微调SecGPT-14B 去年我在使用OpenClaw自动化执行安全扫描任务时,经常遇到一个头疼的问题:当Agent尝试分析漏洞报告时,基础模型总是把"SSRF漏洞"和&q…...

HGD运动想象脑电数据集预处理实战:从数据加载到特征标准化
1. HGD数据集简介与下载指南 HGD(High Gamma Dataset)是目前运动想象脑电研究领域最常用的公开数据集之一,由德国柏林工业大学团队采集并开源。这个数据集包含了14名受试者在执行左手、右手、脚部和休息四种运动想象任务时的高密度脑电信号&a…...

大模型“语言翻译官“Token深度解析:从人类语言到机器密码的惊险旅程!
本文深入浅出地介绍了大模型如何通过Token(词元)这一关键组件将人类自然语言翻译成机器能理解的数字密码。文章从Token的来源、生成全过程(分词、数字化映射、向量化、矩阵运算、采样解码)以及四种主流分词方案(BPE、W…...

剪接位点与调控元件预测:基于机器学习的基因注释增强
点击 “AladdinEdu,你的AI学习实践工作坊”,注册即送-H卡级别算力,沉浸式云原生集成开发环境,80G大显存多卡并行,按量弹性计费,教育用户更享超低价。 摘要:精确识别剪接位点和剪接调控元件是理解…...

计算机毕业设计springboot展会门票系统 基于SpringBoot的会展票务数字化服务平台 SpringBoot框架下的博览会入场券预约与核销系统
计算机毕业设计springboot展会门票系统 (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着会展经济的蓬勃发展和数字化转型的深入推进,各类展会活动规模不断扩大&am…...

NoFences:免费开源桌面分区管理工具,告别杂乱桌面,提升工作效率50%
NoFences:免费开源桌面分区管理工具,告别杂乱桌面,提升工作效率50% 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 想要告别杂乱无章的Win…...

BR DI426数字输入模块
B&R DI426 数字输入模块是一款工业自动化系统用的 I/O 模块,主要用于采集现场开关量信号并传输至控制系统。一、基本概述型号:DI426类型:数字输入模块用途:采集工业现场的开关量信号,为控制系统提供输入数据二、主…...

Clipboard主题定制终极指南:打造个性化剪贴板界面的简单方法
Clipboard主题定制终极指南:打造个性化剪贴板界面的简单方法 【免费下载链接】Clipboard 😎🏖️🐬 Your new, 𝙧𝙞𝙙𝙤𝙣𝙠𝙪𝙡&#…...
)
从package.xml到CMakeLists.txt:手把手教你配置一个ROS1机器人控制包(附完整项目模板)
从package.xml到CMakeLists.txt:构建工业级ROS1机器人控制包的完整指南 在机器人操作系统(ROS)开发中,功能包的配置质量直接影响项目的可维护性和扩展性。本文将带您深入理解ROS1功能包的核心配置文件,通过一个完整的工业机器人控制包案例&am…...