Hadoop增加新节点环境配置(自用)
完成Hadoop集群增添一个新的节点配置(文中命名为)Hadoop106,没有进行继续为该节点分配身份职能的步骤
1.在VMware中安装CentOS 7
-
新建虚拟机
1.⾸先我们创建⼀个新的虚拟机,也可以点⽂件-新建虚拟机。

2.选择⾃定义,可以根据要求来定义,如果没有什么特殊要求,可以选择“典型”。

3.硬件兼容性可以选择向下兼容。
4.这⾥我们选择稍后安装操作系统。
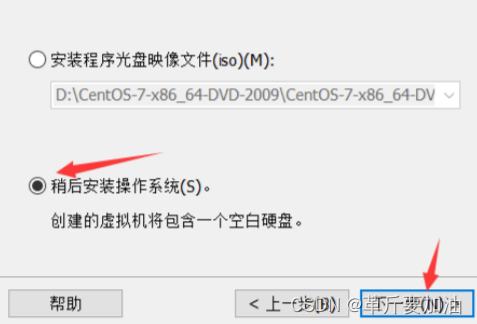
5.随后选择要安装的系统类型。
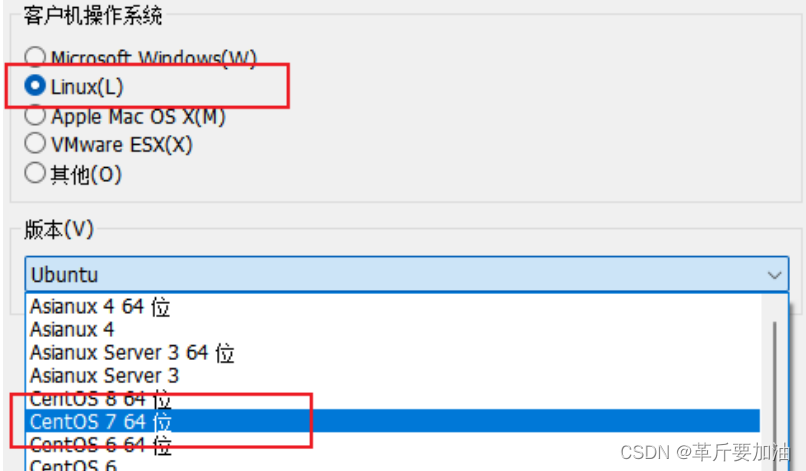
6.建议给虚拟机起个名字,hadoop106,更改存放路径(默认在C盘)。

7.设置虚拟机的内存,根据⾃⼰电脑性能调整,这⾥设置2048MB。

8.⽹络类型选 使⽤⽹络地址转换(NAT) 。

9. I/0类型默认(LSI Logic)
10. 磁盘类型,默认(SCSI)
11. 由于是新虚拟机,所以我们创建新的虚拟磁盘。磁盘的容量由于是动态增长,将虚拟磁盘拆分成多个⽂件,并为将来
安装做准备,根据⾃⼰电脑的性能,建议改成40G。
12. 指定磁盘⽂件,默认。
13. 最后将配置清单列出来,确认,点击完成。
-
安装centos7
- 打开我们上⼀个⽂档建⽴的虚拟机,并双击CD/DVD(IDE)配置光驱,加载CentOS 7系统镜像。

2.开启“hadoop106”虚拟机。

3. 系统会⾃动启动光驱,进⼊CentOS 7的安装界⾯,此界⾯有1分钟的停留时间,请快速将⿏标点击黑⾊部分。
4. 移动键盘上的上下键,选择图中的 Install CentOS 7 选项。

5. 进⼊系统安装界⾯。
6. 选择安装过程中⽤到的语⾔,必然选简体中⽂
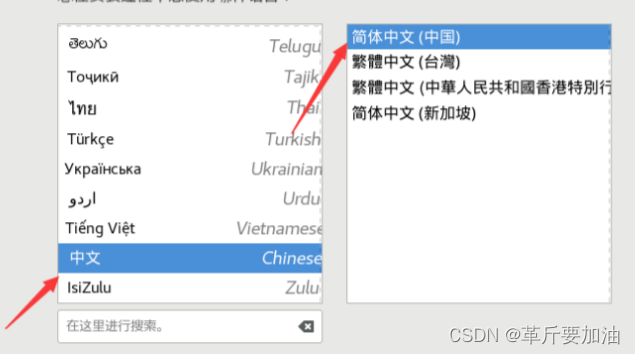
- 点击安装位置,选⾃动。或者⼿动(/boot 1g ext4、swap 4g xfs、/ 35g xfs)
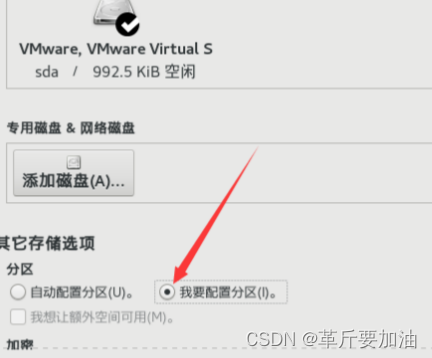


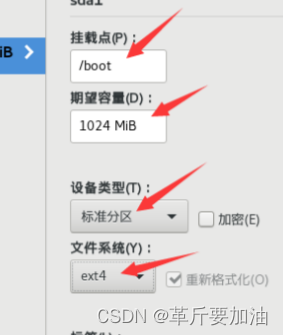
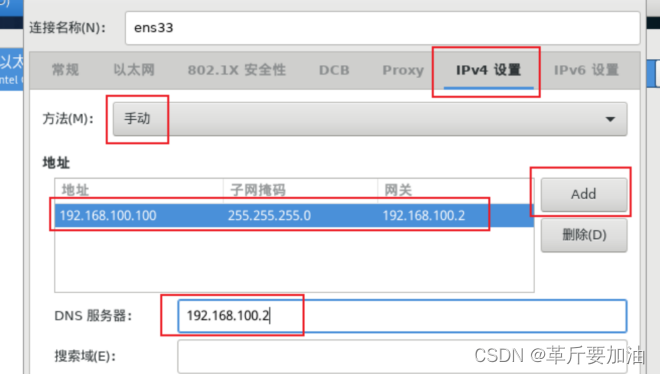
8. ⽹络和主机名,我们做如下的更改:
打开以太⽹,这样在启动时就使⽹卡处于激活状态。

主机名改成hadoop106,点应用
IP:192.168.100.106,子网掩码:255.255.255.0,网关:192.168.100.2,DNS:192.168.100.2。
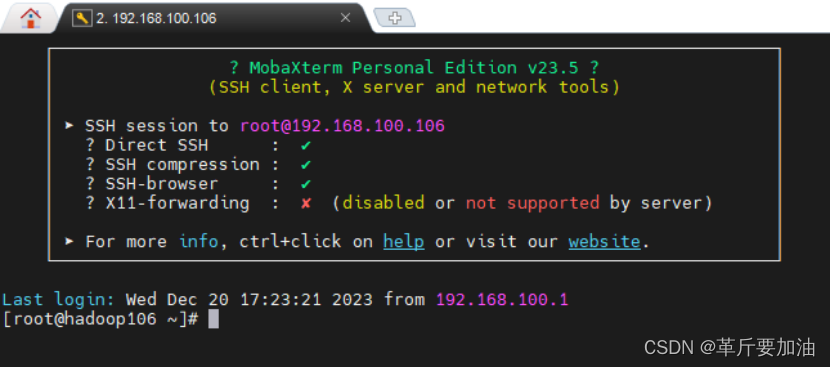
9.然后就点开始安装,在这个期间创建root密码123123,由于我们的密码不符合系统安全要求,所以需要点击两次完成。等进度条⾛完,就可以点重启了。此时CentOS7安装完成并启动,等待我们输⼊账户,密码。

此时可打开 mobaxterm 新建session 输⼊192.168.100.106 连接
- 安装 rsync yum -y install rsync
- 安装 nano yum -y install nano
- 安装 ntpd yum -y install ntp

-
配置centos7
1. 关闭防⽕墙,集群⼀般搭建在局域⽹内,公司在外部建⽴专业的防⽕墙,为了⽅便集群之间通信,请关闭集群中各节点的防⽕墙。
·在root⽤户下直接关闭防⽕墙 systemctl stop firewalld.service
· 禁⽌firewall开机启动 systemctl disable firewalld.service
· 关闭SELinux命令(永久关闭) nano /etc/selinux/config 注释掉下面两行:
#SELINUX=enforcingSELINUX=disabled#SELINUXTYPE=targeted重启
- 查看防⽕墙状态 systemctl status firewalld

2. 在/opt ⽬录下创建 module(程序⽂件夹)、software(安装包) ⽂件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software

2.在Hadoop106节点安装JDK、Hadoop
·安装JDK
1. 将jdk-8u341-linux-x64.tar.gz 利⽤xftp上传到/opt/software
2. 解压jdk到/opt/module⽂件夹
[root@hadoop100 ~]# tar -zxvf /opt/software/jdk-8u341-linux-x64.tar.gz -C /opt/module/
3. nano /etc/profile.d/my_path.sh ⽂件,输⼊
#JAVA_HOMEexport JAVA_HOME=/opt/module/jdk1.8.0_341export PATH=$PATH:$JAVA_HOME/bin4. source ⼀下 /etc/profile ⽂件,让新的环境变量 PATH ⽣效
[root@hadoop100 ~]# source /etc/profile
5. 检验⼀下成功不
[root@hadoop100 ~]# java -version
·安装Hadoop
1. 将hadoop-3.3.3.tar.gz利⽤xftp上传到/opt/software
2. 解压hadoop到/opt/module⽂件夹
[root@hadoop100 ~]# tar -zxvf /opt/software/hadoop-3.3.3.tar.gz -C /opt/module/
3. 在 /etc/profile.d/my_path.sh ⽂件,加⼊下⾯内容
#HADOOP_HOMEexport HADOOP_HOME=/opt/module/hadoop-3.3.3export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin
4. source ⼀下 /etc/profile ⽂件,让新的环境变量 PATH ⽣效
[root@hadoop100 ~]# source /etc/profile

5. 测试
[root@hadoop100 ~]# hadoop version
·新增ens37网卡
1. 关闭 hadoop106
2. 右击虚拟机选项卡 -> 配置 -> 添加 -> ⽹络适配器 -> 改成桥接
3. 启动 hadoop106
4. nmcli connection add type ethernet con-name ens37 ifname ens37 autoconnect yes
5. nano /etc/sysconfig/network-scripts/ifcfg-ens37
6. 更改 ifcfg-ens37 ⽂件
TYPE=EthernetPROXY_METHOD=noneBROWSER_ONLY=noBOOTPROTO=staticDEFROUTE=yesIPV4_FAILURE_FATAL=noIPV6INIT=yesIPV6_AUTOCONF=yesIPV6_DEFROUTE=yesIPV6_FAILURE_FATAL=noIPV6_ADDR_GEN_MODE=stable-privacyNAME=ens37UUID=59021522-3de9-492b-9308-b6ab7596acebDEVICE=ens37ONBOOT=yesIPADDR=10.227.x.1y6NETMASK=255.255.254.0注:
x:班级号,7班是2或8班是3
y:组号,1-10
service network start

·Hadoop101配置
1. 打开 hadoop101完全分布式新增hadoop106节点.md 2023-12-18
2. nano /etc/hosts 加⼊
10.227.x.1y6 hadoop106
注:x:班级号,7班是2或8班是3;y:组号,1-10
3. nano $HADOOP_HOME/etc/hadoop/workers 加⼊ hadoop106
4. ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop106
5. rsync -av
$HADOOP_HOME/etc/hadoop root@hadoop106:/opt/module/hadoop-3.3.3/etc/
6. rsync -av /etc/hosts root@hadoop106:/etc
7. 远程到 hadoop106 ssh hadoop106
8. nano /opt/module/hadoop-3.3.3/etc/hadoop/hadoop-env.sh 修改 JAVA_HOME export
JAVA_HOME=/opt/module/jdk1.8.0_341
3.启动集群
1. jpsall.sh 中加⼊ hadoop106 nano ~/bin/jpsall.sh
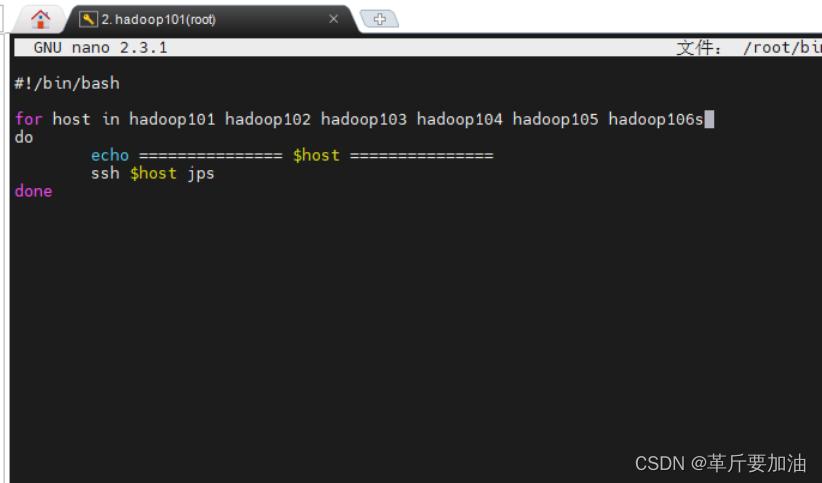
2.shutdown_all.sh 中加⼊ hadoop106 nano ~/bin/shutdown_all.sh
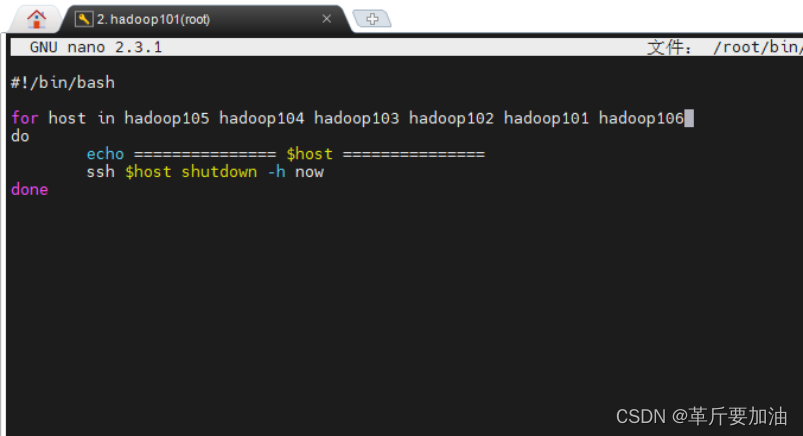
3. 启动集群 myhadoop.sh start
4. 观察各节点进程的启动情况



4.个人配置中遇到的问题
-
电脑没有vmnet8虚拟网卡
编辑--->虚拟网络编辑器--->VMnet8--->还原默认设置--->NAT设置--->更改网关IP--->应用确定
设置 ---> 网络和Internet ---> 更改适配器选项 ---> 查看VMnet8,出现并显示已启用
-
Hadoop104、105DataNodeID缺失
通过查找日志,在记录中找到了对应的节点的DataNode,然后我们进入到了103节点的$HADOOP_HOME/data/dfs/data/current/VERSION目录下,复制了103节点的VERSION文件,然后分别进入到了104和105节点的$HADOOP_HOME/data/dfs/data/current下,创建了VERSION文件,将从103中复制的内容粘贴到了新创建的文件中,并根据在日志中查找到的将其对应的DataNodeID,其内容如下(示例):
storageID=DS-5c72e6f4-c180-44b4-9f26-6abc84327f43clusterID=CID-fd0aa33f-424c-4212-a725-dd33a3ff126ccTime=0datanodeUuid=75809195-27bf-4c87-bb4d-8fb81642e7aestorageType=DATA_NODElayoutVersion=-57其中,storageID会由系统自动生成,更改以后重新启动集群,集群数据接收正常
相关文章:
Hadoop增加新节点环境配置(自用)
完成Hadoop集群增添一个新的节点配置(文中命名为)Hadoop106,没有进行继续为该节点分配身份职能的步骤 1.在VMware中安装CentOS 7 新建虚拟机 1.⾸先我们创建⼀个新的虚拟机,也可以点⽂件-新建虚拟机。 2.选择⾃定义,…...
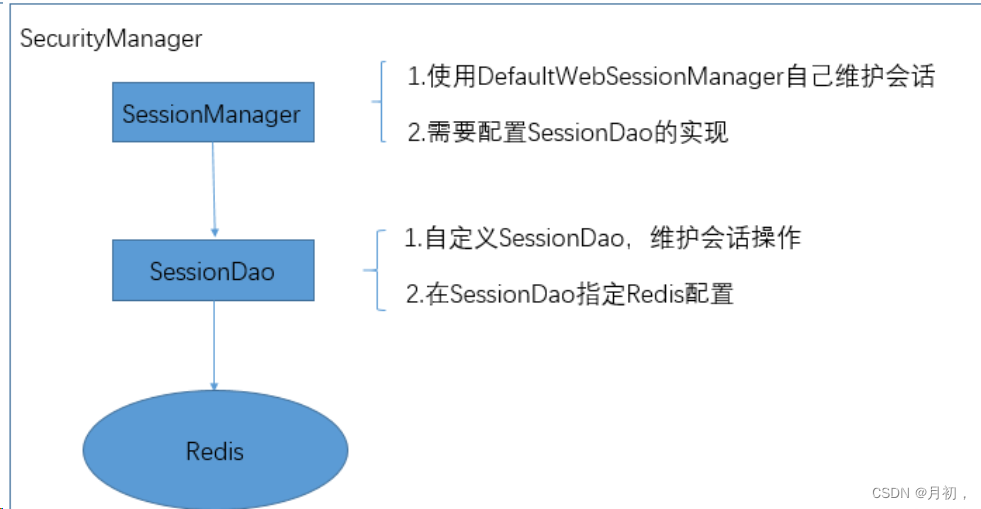
Apache Shiro 安全框架
前言 Apache Shiro 是一个强大且容易使用的Java安全矿建,执行身份验证,授权,密码和会话管理。使用Shiro的易于理解的API您可以快速轻松的获得任何应用程序直到大的项目。 一丶什么是Shiro 1.Shiro是什么 Apache Shiro是一个强大且易于使用…...

防火墙的NAT
目录 1. NAT 概念解析 2. 配置NAT策略: 1. NAT 概念解析 静态NAT --- 一对一 动态NAT --- 多对多 NAPT --- 一对多的NAPT --- easy ip --- 多对多的NAPT 服务器映射 源NAT --- 基于源IP地址进行转换。我们之前接过的静态NAT,动态NAT,NAPT都属…...
Java基础进阶03-注解和单元测试
目录 一、注解 1.概述 2.作用 3.自定义注解 (1)格式 (2)使用 (3)练习 4.元注解 (1)概述 (2)常见元注解 (3)Target &#x…...
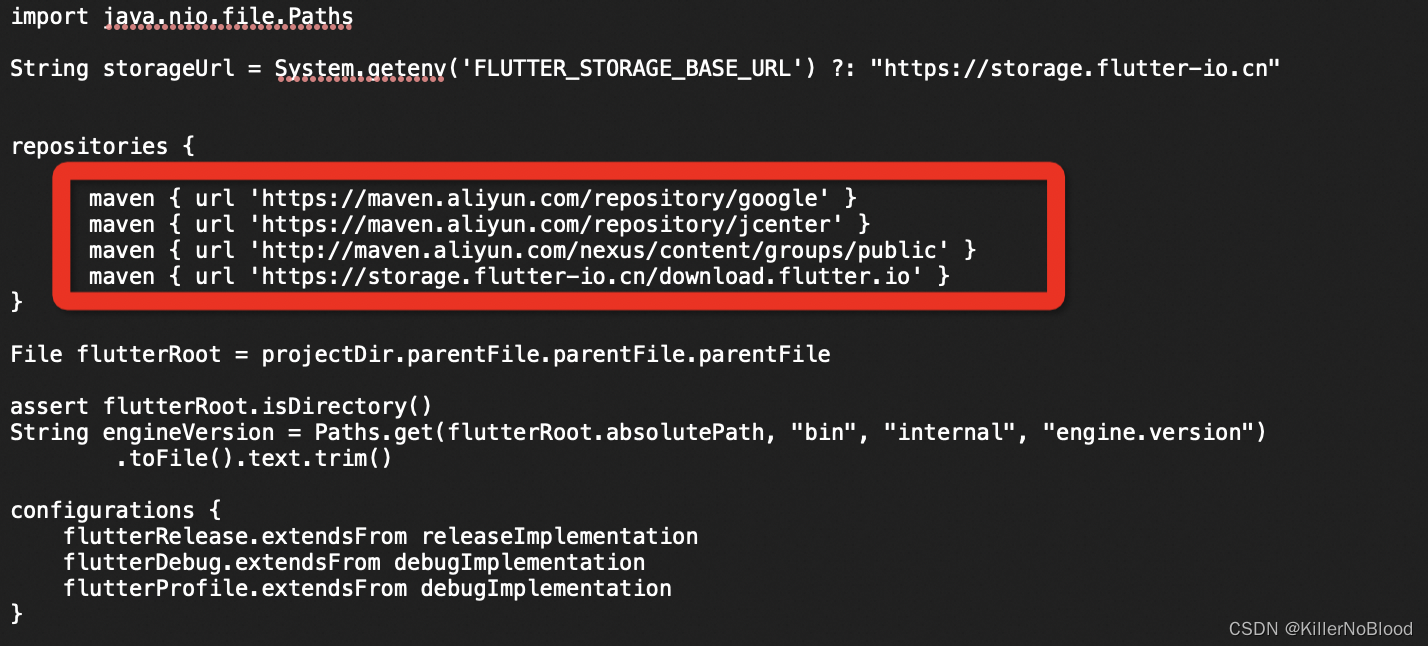
Mac+Android Studio配置 Flutter环境
Fluttrer中文下载官网 Flutter下载官网 1、环境变量 .zshrc #Flutter export PUB_HOSTED_URL"https://pub.flutter-io.cn" export FLUTTER_STORAGE_BASE_URL"https://storage.flutter-io.cn" export FLUTTER_HOME/Users/leon/Flutter/flutter_3_10_4/f…...
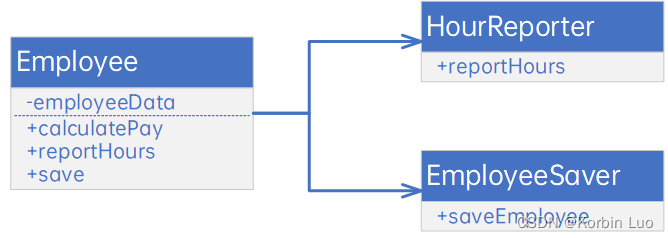
架构整洁之道-设计原则
4 设计原则 通常来说,要想构建一个好的软件系统,应该从写整洁的代码开始做起。这就是SOLID设计原则所要解决的问题。 SOLID原则的主要作用就是告诉我们如何将数据和函数组织成为类,以及如何将这些类链接起来成为程序。请注意,这里…...

数据结构(队列)
一.什么是队列 1.队列定义 队列是一种特殊的线性表,特殊之处在于他只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。和栈一样,队列也是一种操作受限制的线性表。进行插入操作的一端称为队尾,进行删除操作的…...
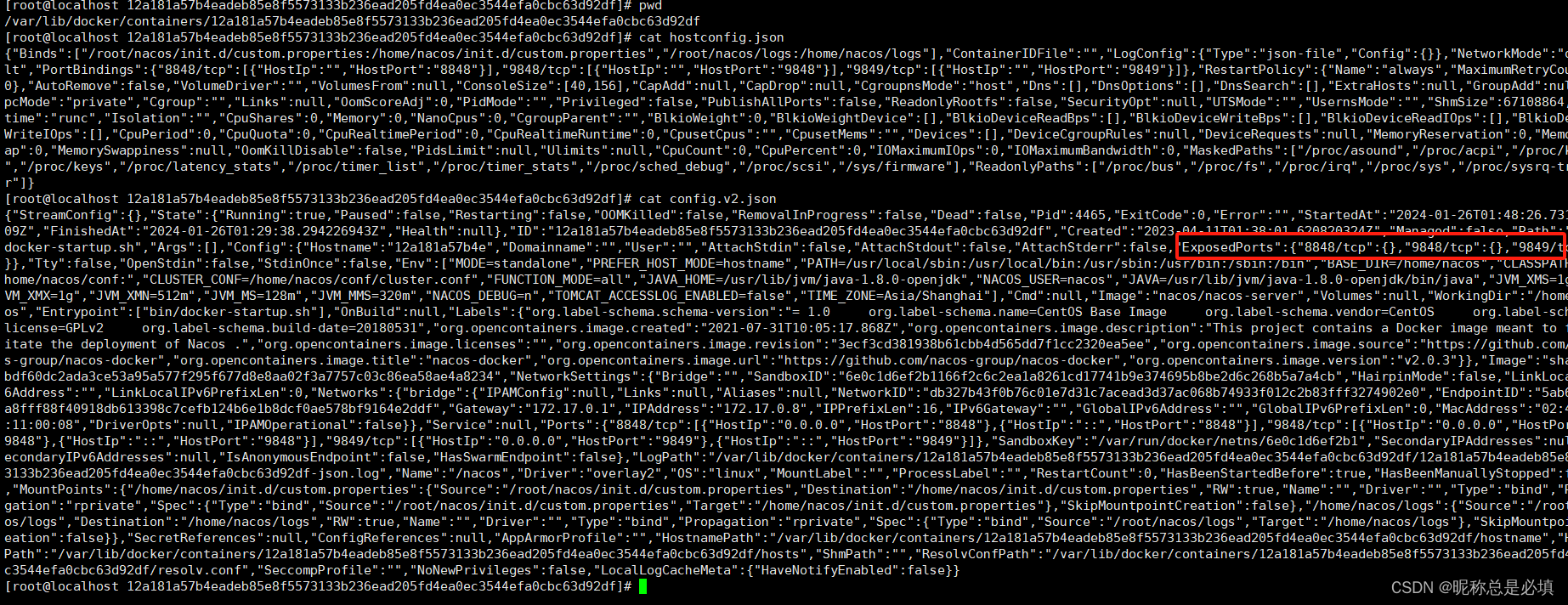
docker容器启动后修改或添加端口 nacos容器 版本2.x需要额外开放9848、9849
1.输入docker ps -a查看需要修改的容器ID: 记录下、 docker ps -a 2.停止docker systemctl stop docker 3.进入docker 容器文件夹,找到对应容器的位置: docker的默认文件夹应该是/var/lib/docker 如果不是root用户查看的话,可能会出现权限…...
C语言实现归并排序算法(附带源代码)
归并排序 把数据分为两段,从两段中逐个选最小的元素移入新数据段的末尾。 可从上到下或从下到上进行。 动态效果过程演示: 归并排序(Merge Sort)是一种分治算法,它将一个数组分为两个子数组,分别对这两个…...
考研C语言刷题基础篇之分支循环结构基础(二)
目录 第一题分数求和 第二题:求10 个整数中最大值 第三题:在屏幕上输出9*9乘法口诀表 第四题:写一个代码:打印100~200之间的素数 第五题:求斐波那契数的第N个数 斐波那契数的概念:前两个数相加等于第三…...

Scala基础知识
scala 1、scala简介 scala是运行在JVM上的多范式编程语言,同时支持面向对象和面向函数式编程。 2、scala解释器 要启动scala解释器,只需要以下几步: 按住windows键 r输入scala即可 在scala命令提示窗口中执行:quit,即可退…...

数学建模-------误差来源以及误差分析
绝对误差:精确值-近似值; 举个例子:从A到B,应该有73千米,但是我们近似成了70千米;从C到D,应该是1373千米,我们近似成了1370千米,如果使用绝对误差,结果都是3…...

Arduino和MPLAB X 开发STM32F103和PIC16F15376
要点: 使用Arduino开发STM32F103(Blue Pill),MPLAB X 开发PIC16F15376(Curiosity Nano)C/C嵌入式开发ESP32(Arduino、ESP-IDF)和STM32实时操作系统FreeRTOS STM32使用FreeRTOS示例 在使用 FreeRTOS 时&a…...

手机操作系统Android
▶1.Android系统概述 Andaid(读[安卓)由Coosle公司和开放手机联盟共同开发,它是基于Lmx内核的开源操作系统。Andtoid主要用于移动设备,如智能手机和平板计算机。2008年发布了第一部Andtoid智能手机,以后Android逐渐扩展到平板计算机、电视、…...

2024年,你是否还在迷茫?
2024年,你是否还在迷茫? 别担心!鸿蒙来了,这个未来技术的制高点,为你提供了答案! 诸多大厂疯抢、24年预计鸿蒙相关的岗位需求将达到百万级、就业均薪达到19K,全国高校开课…… 种种现象都在表…...
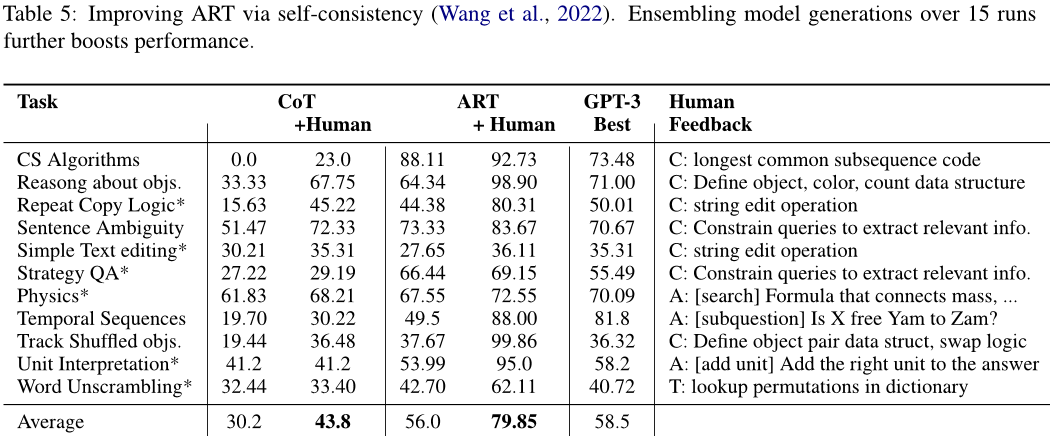
ART: Automatic multi-step reasoning and tool-use for large language models 导读
ART: Automatic multi-step reasoning and tool-use for large language models 本文介绍了一种名为“自动推理和工具使用(ART)”的新框架,用于解决大型语言模型(LLM)在处理复杂任务时需要手动编写程序的问题。该框架可…...

Github 2024-01-26 开源项目日报Top10
根据Github Trendings的统计,今日(2024-01-26统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Python项目4Jupyter Notebook项目2HTML项目1Shell项目1Dockerfile项目1非开发语言项目1Go项目1Rust项目1 高级…...
免费的 UI 设计资源网站 Top 8
今日与大家分享8个优秀的免费 UI 设计资源网站。这些网站的资源包括免费设计材料站、设计工具、字体和其他网站,尤其是一些材料站。它们是免费下载的,材料的风格目前很流行,适合不同的项目。非常适合平面设计WEB/UI设计师收藏,接下…...

人机协同对人工智能治理的影响
人机协同对人工智能治理的影响是多方面的。 首先,人机协同可以提供更有效的人工智能监管和治理机制。人工智能系统通常需要大量的数据来训练和运行,而人类在监管和治理方面有独特的能力。通过人机协同,人们可以利用他们的主观意见和专业知识来…...

Form.List的使用,设置某个字段的值
1.Form.Item的name <Form.Itemname{[base_range, company_base_range_start]}dependencies{[[base_range, company_base_range_end]]}rules{[{ required: true, message: 请输入下限 },{validator: (_, value) >validateMoneyRule(value,base_range?.company_base_range…...

caffeine+redis实现多级缓存解决缓存雪崩
废话不多说直接上代码:1.依赖<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.9.3</version></dependency>这里版本java8所以用的2.9.32.配置类&#…...

Illustrator脚本革命:7个必备工具彻底改变你的设计工作流
Illustrator脚本革命:7个必备工具彻底改变你的设计工作流 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否还在Adobe Illustrator中重复着枯燥的手工操作ÿ…...

Dism++终极指南:5步彻底解决Windows系统卡顿和臃肿问题
Dism终极指南:5步彻底解决Windows系统卡顿和臃肿问题 【免费下载链接】Dism-Multi-language Dism Multi-language Support & BUG Report 项目地址: https://gitcode.com/gh_mirrors/di/Dism-Multi-language 你是否曾为Windows系统越来越慢而烦恼…...

从 SU22 到 SU24,权限检查指示符和默认值的装载与落地治理
在 SAP 权限项目里,最容易被低估的一类数据,不是用户主记录,也不是 PFCG 角色本身,而是藏在 SU22 和 SU24 背后的权限检查指示符与授权默认值。很多团队在 DEV 系统里把角色调到绿灯,以为传到 QAS 和 PRD 以后就万事大吉,结果一到回归测试,业务顾问打开 VA01、ME21N、FD…...

争分夺秒与步步为营:Infoseek舆情系统如何重构危机响应的时间哲学
“黄金4小时”甚至“黄金1小时”,是公关行业奉行的铁律。然而,为了追求速度而仓促发出的声明,常常因为事实核查不清、逻辑存在漏洞或情感表达不当,引发更猛烈的“二次翻车”。这种“翻车”对企业公信力的伤害,往往比原…...

人工智能【第22篇】Seq2Seq模型与注意力机制:机器翻译的基石
作者的话:在前面的文章中,我们学习了RNN、LSTM以及NLP的基础知识。现在让我们进入NLP的核心应用——机器翻译。Seq2Seq(Sequence to Sequence)模型是机器翻译的基石,而注意力机制(Attention)的出…...

为什么 Promise 比 setTimeout 先执行?——JavaScript 事件循环与异步顺序完全指南
为什么 Promise 比 setTimeout 先执行?——JavaScript 事件循环与异步顺序完全指南 这是 JavaScript 异步中最经典也最容易困惑的问题之一。核心答案是: Promise 的回调属于 Microtask(微任务),setTimeout 属于 Macro…...
)
ChatGPT Instagram内容策略失效真相(92%运营者忽略的算法适配层)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Instagram内容策略失效的底层归因 Instagram 的算法演进与用户行为迁移,正系统性瓦解基于通用大模型(如 ChatGPT)生成的“模板化内容策略”。其失效并非源于…...

EchoType开源键盘固件:基于状态感知的智能输入引擎深度解析
1. 项目概述:从“EchoType”看开源键盘固件的深度定制最近在键盘客制化圈子里,一个名为“EchoType”的项目开始被一些资深玩家频繁提及。它的GitHub仓库地址是ljyou001/echotype,从名字上你就能猜到,这大概率是一个与键盘固件、打…...

5分钟快速上手:qmcdump免费解密QQ音乐文件的终极指南
5分钟快速上手:qmcdump免费解密QQ音乐文件的终极指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...