Spark运行架构以及容错机制
Spark运行架构以及容错机制
- 1. Spark的角色区分
- 1.1 Driver
- 1.2 Excuter
- 2. Spark-Cluster模式的任务提交流程
- 2.1 Spark On Yarn的任务提交流程
- 2.1.1 yarn相关概念
- 2.1.2 任务提交流程
- 2.2 Spark On K8S的任务提交流程
- 2.2.1 k8s相关概念
- 2.2.2 任务提交流程
- 3. Spark-Cluster模式的容灾模式
- 3.1 Driver容灾
- 3.2 Executor容灾
- 3.3 RDD容错
- 4. 疑问和思考
- 4.1 是否可以部署多个Driver,形成HA模式,如果主Driver宕机,备Driver自动接替?
- 5. 参考文档
spark是一个开发框架,用于进行数据批处理,本文主要探讨Spark任务运行的的架构。由于在日常生产环境中,常用的是spark on yarn 和spark on k8s两种类型的模式,因此本文也主要探讨这两种类型的异同,以及不同角色的容错机制。
1. Spark的角色区分
1.1 Driver
Spark的驱动器节点,负责运行Spark程序中的main方法,执行实际的代码。Driver在Spark作业时主要负责:
- 将用户程序转化为作业(job)
- 负责跟RM(yarn)或者 Apiserver(k8s)申请资源,调度并拉起Excutor,协调和分配Executor之间的任务(task)
- 监控Executor的执行状态
- 通过UI展示运行情况。
1.2 Excuter
Executor是Spark程序中的一个JVM进程,负责执行Spark作业的具体任务(task),每个任务之间彼此相互独立。Spark应用启动时,Executor同时被启动,并且伴随着Spark程序的生命周期而存在。如果有Executor节点发生了故障,程序也不会停止运行,而是将出错的Executor节点上的任务调度到其他Executor节点运行。
Executor的核心功能:
- 运行Spark作业中具体的任务,并且将执行结果返回给Driver。
- 通过自身的块管理器(Block Manager)对用户要求缓存的RDD进行内存式存储。RDD式缓存在Executor进程内部的,这样任务在运行时可以充分利用缓存数据加速运算。
2. Spark-Cluster模式的任务提交流程
2.1 Spark On Yarn的任务提交流程
2.1.1 yarn相关概念
RM(ResourceManager):
即资源管理,在YARN中,RM负责集群中所有资源的统一管理和分配,它接收来自各个节点(NM)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是AM)
NM(NodeManager):
NM是运行在单个节点上的代理,它需要与应用程序的AM和集群管理者RM交互:
- 从AM上接收有关Container的命令并执行之(比如启动、停止Container);
- 向RM汇报各个Container运行状态和节点健康状况,并领取有关Container的命令(比如清理Container)执行之。
AM(ApplicationMaster):
用户提交的每个应用程序均包含一个AM,它可以运行在RM以外的机器上负责,主要负责
- 与RM调度器协商以获取资源(用Container表示),将得到的任务进一步分配给内部的任务(资源的二次分配)。
- 与NM通信以启动/停止任务。
- 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
注:RM只负责监控AM,并在AM运行失败时候启动它。RM不负责AM内部任务的容错,任务的容错由AM完成。
在Yarn任务的启动流程中,
- client优先跟RM获取NM资源并启动AM,在Cluster模式下,AM启动后client就可以退出了
- AM构建任务信息,并RM获取NM资源并启动Executor,并将task信息分配给Executor从而实现任务启动
- Executor需要跟AM进行心跳汇报,如果Executor异常,相关的拉起动作也是有AM来控制。
2.1.2 任务提交流程
Driver和AM是两个完全不同的东西,Driver是控制Spark计算和任务资源的,而AM是控制yarn app运行和任务资源的。在Spark On Yarn模式中,Driver运行在AM上,Driver会和AM通信,资源的申请由AppMaster来完成,而任务的调度和执行则由Driver完成,Driver会通过与AppMaster通信来让Executor的执行具体的任务。
任务提交流程图
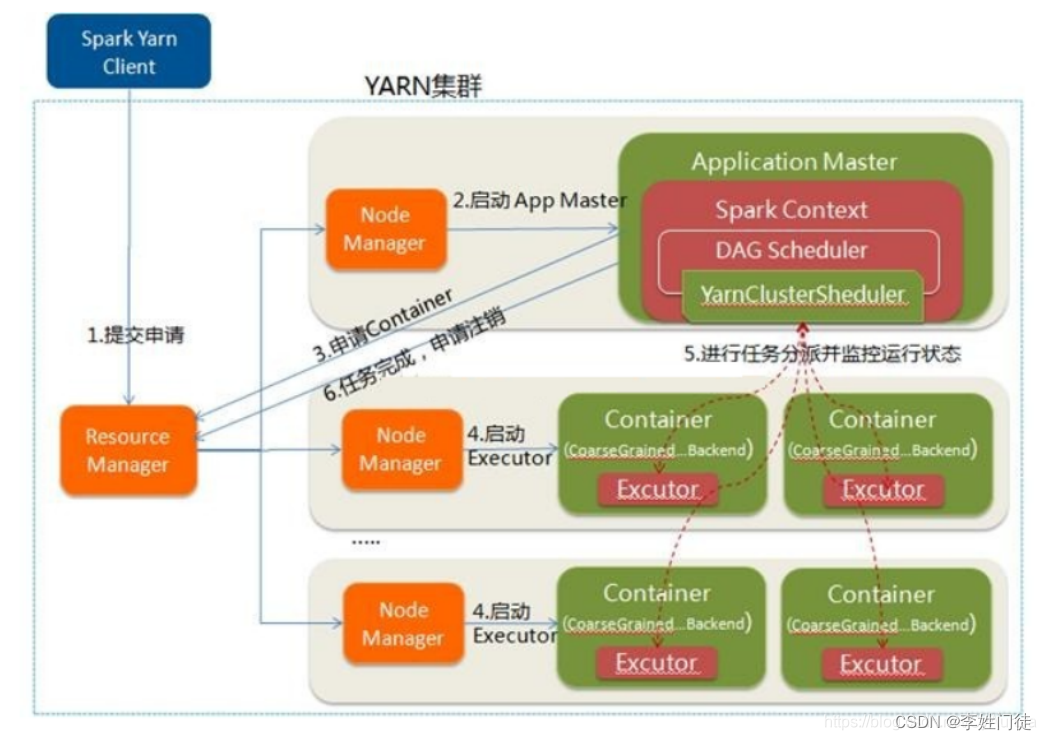
执行过程
- Client向YARN中提交应⽤程序,包括AM程序、启动AM的命令、需要在Executor中运⾏的程序等
- RM收到请求后,在集群中选择⼀个NM,为该应⽤程序分配第⼀个Container,要求它在这个Container中启动应⽤程序的AM,进行SparkContext(Driver)等的初始化
- AM向RM注册,这样⽤户可以直接通过RM查看应⽤程序的运⾏状态,然后它将采⽤轮询的⽅式通过RPC协议为各个任务申请资源,并监控它们的运⾏状态直到运⾏结束
- ⼀旦AM申请到资源(也就是Container)后,便与对应的NM通信,要求它在获得的Container中启动Executor,Executor启动后会向 AM中的SparkContext(Driver)注册并申请Task。
- AM中的SparkContext(Driver)分配Task给Executor执⾏,运⾏Task并向AM中的SparkContext(Driver)的汇报运⾏的状态和进度,以让 AM中的SparkContext(Driver)随时掌握各个任务的运⾏状态,从⽽可以在任务失败时重新启动任务应⽤程序运⾏完成后,AM中的SparkContext(Driver)向NM申请注销并关闭⾃⼰
6.应⽤程序运⾏完成后,AM向NM申请注销并关闭⾃⼰
YARN-Cluster的执行,需要安装spark 客户端,并执行如下命令提交任务
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--num-executors 1 \
/Users/ly/apps/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 10
2.2 Spark On K8S的任务提交流程
Spark 2.3开始,Spark官方就开始支持Kubernetes作为新的资源调度模式。
2.2.1 k8s相关概念
Master:
Kubernetes里的Master指的是集群控制节点,每一个Kubernetes集群里都必须要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes的所有控制命令都发给它,它来负责具体的执行过程,我们后面执行的所有命令基本都是在Master节点上运行的
Node:
Node节点是Kubernetes集群中的工作负载节点,每个Node都会被Master分配一些应用程序服务以及云工作流。
2.2.2 任务提交流程
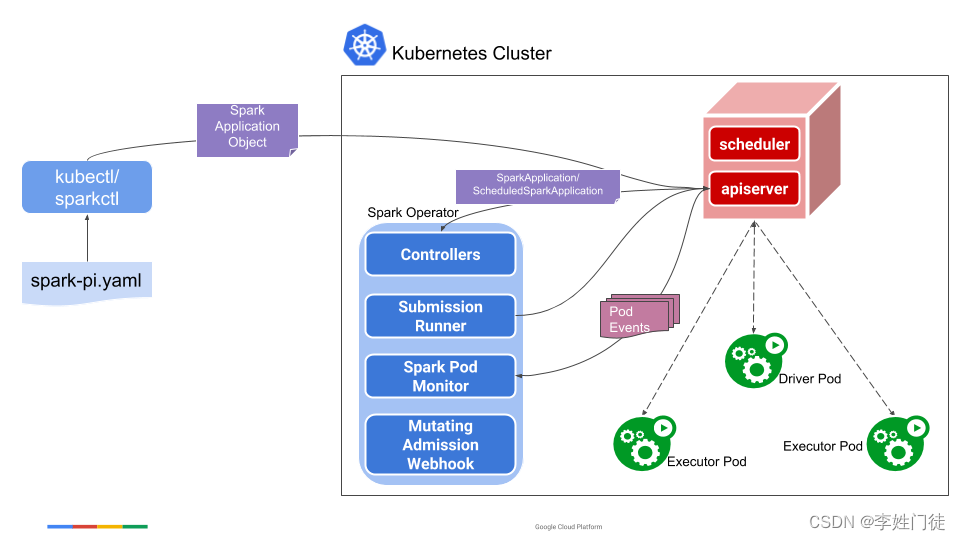
总体提交流程如下
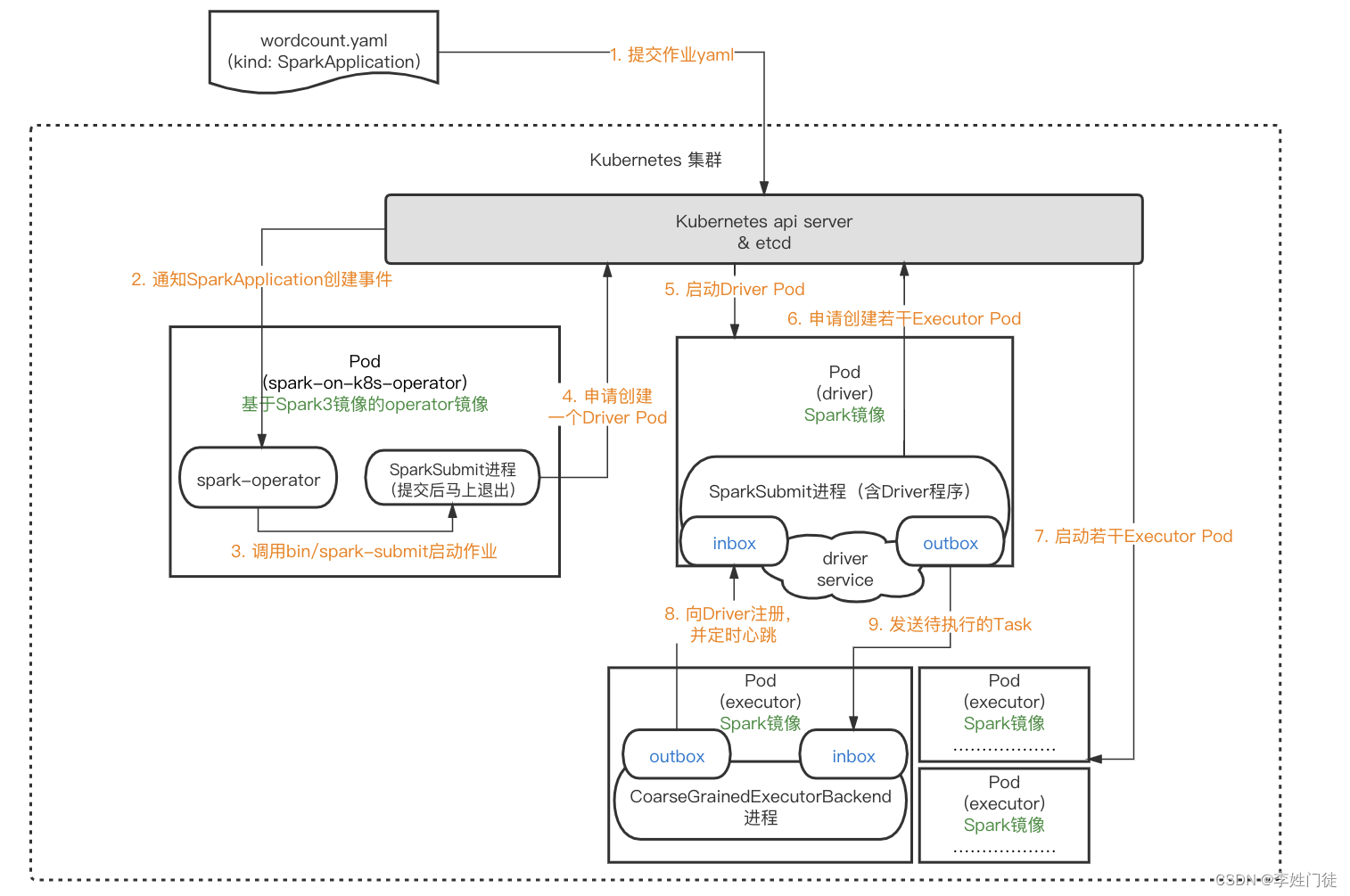
可以通过spark原生提交方式和 spark-on-k8s-operator提交 两种方式进行提交,两种方式实现上有些差异,但是总体流程是一致的。
1, spark原生提交方式
需要安装spark 客户端,并执行如下命令提交任务
bin/spark-submit \--master k8s://https://{k8s-apiserver-host}:6443 \--deploy-mode cluster \--name spark-wordcount-example \--class org.apache.spark.examples.JavaWordCount \local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar \oss://{wordcount-file-oss-bucket}/
2, spark-on-k8s-operator提交
spark-on-k8s-operator[2],可以让用户以CRD(CustomResourceDefinition) [4] 的方式提交和管理Spark作业。这种方式能够更好的利用k8s原生的能力,具备更好的扩展性。并且在此之上增加了定时任务、重试、监控等一系列功能。具体的功能特性可以在github查看官方文档(kubernetes官方推荐)
需要
1, 需要提前在k8s集群中安装,此时会启动一个名为sparkoperator的pod
2,定义提交spark任务的相关CRD资源
3,提交作业时,无需准备一个具备Spark环境的Client,直接通过kubectl或者kubernetes api就可以提交Spark作业。
列入一个crd,命名spark.yaml
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:name: spark-wordcount-examplenamespace: default
spec:type: JavasparkVersion: 2.4.5mainClass: org.apache.spark.examples.JavaWordCountimage: {Spark镜像地址}mainApplicationFile: "local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar"arguments:- "oss://{wordcount-file-oss-bucket}/"driver:cores: 1coreLimit: 1000mmemory: 4gexecutor:cores: 1coreLimit: 1000mmemory: 4gmemoryOverhead: 1ginstances: 2
执行如下命令即可启动相关的pod,并进行提交任务
kubectl apply -f spark.yaml
3. Spark-Cluster模式的容灾模式
3.1 Driver容灾
Driver异常退出时,一般要使用checkpoint重启Driver,重新构造上下文并重启接收器。
第一步,恢复检查点记录的元数据块。
第二步,未完成作业的重新形成。由于失败而没有处理完成的RDD,将使用恢复的元数据重新生成RDD,然后运行后续的Job重新计算后恢复。
3.2 Executor容灾
Executor异常是日常生产环境中最常遇到的现象,造成的原因很多,最常见的是由于机器故障,从而导致就上运行的Executor异常。
Executor异常退出时,Driver没有在规定时间内收到执行器的状态更新,于是Driver会将注册的Executor移除,并通过调度器自动重新拉起Executor。新启动的Executor会重新注册到Driver中,Driver会根据DAG给Executor重新分配相关的Task。Executor分配到到来自Driver的Task,需要重checkpoint重新加载数据并继续执行计算。Spark运算数据行程DAG,如果遇到不同的Executor之间有数据交互时(比如ExecutorA的数据聚合依赖于ExecutorB和ExecutorC,ExecutorB宕机,ExecutorA的数据聚合也不准确),不能简单的通过启动对应的Executor相关的数据进行恢复(可能会有数据紊乱),通常恢复的时间较久。
3.3 RDD容错
窄依赖
指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区 或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
宽依赖
指子RDD的分区依赖于父RDD的多个分区或所有分区,即存在一个父RDD的一个分区对应一个子RDD的多个分区。
checkpoint机制
是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
注意
1, 在容错机制中,如果一个节点死机了,而且运算窄依赖,则只要把丢失的父RDD分区重算即可,不依赖于其他节点。
2, 而宽依赖需要父RDD的所有分区都存在,重算就很昂贵了。如果恢复的代价过于昂贵,就会通过checkpoints重新进行计算。
3,利用checkpoint机制,记载最新的数据计算点,重新拉起任务进行计算
4. 疑问和思考
4.1 是否可以部署多个Driver,形成HA模式,如果主Driver宕机,备Driver自动接替?
可以,基于ZK进行选主。
5. 参考文档
- Spark 容错以及高可用性HA
- Spark 容错机制
- Spark on Kubernetes作业执行流程
- Spark on Yarn运行机制
相关文章:
Spark运行架构以及容错机制
Spark运行架构以及容错机制 1. Spark的角色区分1.1 Driver1.2 Excuter 2. Spark-Cluster模式的任务提交流程2.1 Spark On Yarn的任务提交流程2.1.1 yarn相关概念2.1.2 任务提交流程 2.2 Spark On K8S的任务提交流程2.2.1 k8s相关概念2.2.2 任务提交流程 3. Spark-Cluster模式的…...
短剧APP小程序源码 全开源短视频系统源码/h5/app/小视频系统
主要功能介绍: 小剧场短剧影视小程序源码 全开源 带支付收益等模式 付费短剧小程序源码 多平台小程序支持 项目功能介绍 支持无限滑动 高性能滑动 预加载 视频预览 支持剧情介绍,集合壁纸另外仿抖音滑动效果 支持会员模式,支持用户单独购买等等多功能 本系统&…...

深度学习中图像分类、目标检测、语义分割、实例分割哪个难度大,哪个检测精度容易实现,哪个速度低。请按照难度、精度容易实现程度、速度排名。
问题描述:深度学习中图像分类、目标检测、语义分割、实例分割哪个难度大,哪个检测精度容易实现,哪个速度低。请按照难度、精度容易实现程度、速度排名。 问题解答: 以下是一般情况下深度学习中图像分类、目标检测、语义分割、实…...

【AI视野·今日NLP 自然语言处理论文速览 第七十五期】Thu, 11 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 11 Jan 2024 Totally 36 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Leveraging Print Debugging to Improve Code Generation in Large Language Models Authors Xueyu Hu, Kun K…...
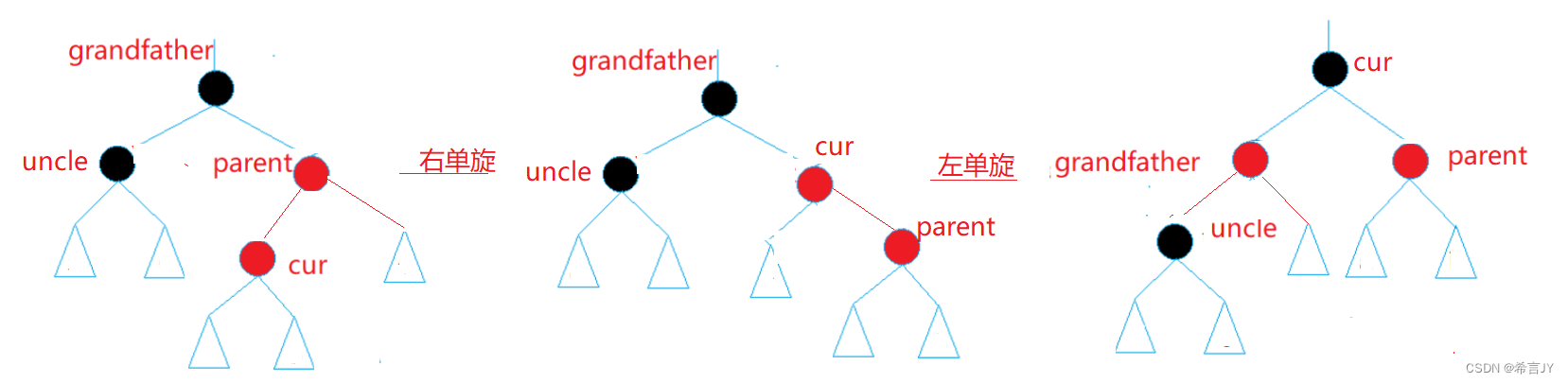
数据结构:搜索二叉树 | 红黑树 | 验证是否为红黑树
文章目录 1.红黑树的概述2.红黑树的性质3.红黑树的代码实现3.1.红黑树的节点定义3.2.红黑树的插入操作3.3.红黑树是否平衡 黑红树是一颗特殊的搜索二叉树,本文在前文的基础上,图解红黑树插入:前文 链接,完整对部分关键代码展示&a…...
数据结构顺序表
思维导图 练习 头文件 1 #ifndef __HEAD_H__2 #define __HEAD_H__3 4 5 #include <stdio.h>6 #include <string.h>7 #include <stdlib.h>8 9 10 #define MAXSIZE 711 typedef int datatype;12 enum13 {14 FLASE-1,15 SUCCESS16 };17 //定义顺序表&a…...
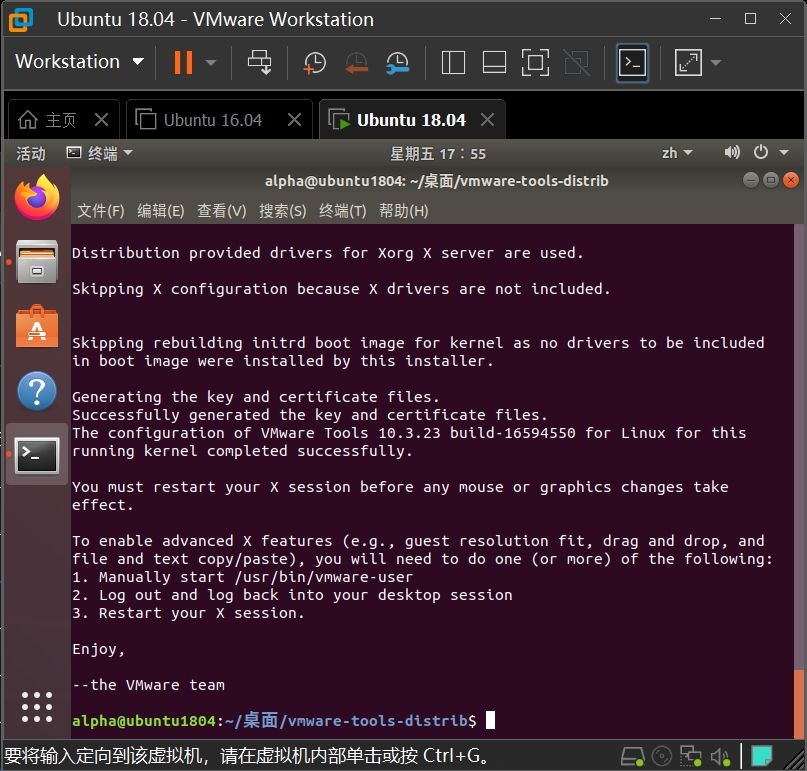
手把手教你优雅的安装虚拟机 Ubuntu —— 图文并茂
目录 Ubuntu 获取Vmware 安装新建虚拟机Ubuntu 安装虚拟机工具安装更多内容 本文教你如何优雅的在虚拟机中安装 Ubuntu,图文并茂、包教包会! Ubuntu 获取 Ubuntu 官网镜像下载速度较慢,建议从国内镜像网站下载,如网易、中科大、…...

源 “MySQL 5.7 Community Server“ 的 GPG 密钥已安装,但是不适用于此软件包。请检查源的公钥 URL 是否配置正确。
源 “MySQL 5.7 Community Server” 的 GPG 密钥已安装,但是不适用于此软件包。请检查源的公钥 URL 是否配置正确。 失败的软件包是:mysql-community-server-5.7.44-1.el7.x86_64 GPG 密钥配置为:file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql…...

springboot核心有几层架构
Spring Boot核心有四层架构: 应用层:包含应用程序的入口点和控制器层。这层负责接收请求、处理业务逻辑,并返回响应结果。 服务层:包含业务逻辑的实现。这层负责处理各种业务逻辑,例如数据处理、事务管理等。 数据访…...
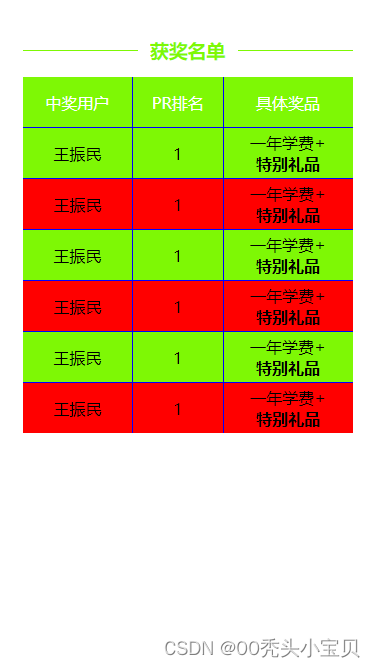
css3表格练习
1.效果图 2.html <div class"line"></div><h3>获奖名单</h3><!-- 表格 cellspacing内边距 cellpadding外边距--><table cellspacing"0" cellpadding"0" ><!-- thead表头 --><thead><tr>…...
项目实战——Qt实现FFmpeg音视频转码器
文章目录 前言一、移植 FFmpeg 相关文件二、绘制 ui 界面三、实现简单的转码四、功能优化1、控件布局及美化2、缩放界面3、实现拖拽4、解析文件5、开启独立线程6、开启定时器7、最终运行效果 五、附录六、资源自取 前言 本文记录使用 Qt 实现 FFmepg 音视频转码器项目的开发过…...

AI数字人-数字人视频创作数字人直播效果媲美真人
在科技的不断革新下,数字人技术正日益融入到人们的生活中。近年来,随着AI技术的进一步发展,数字人视频创作领域出现了一种新的创新方式——AI数字人。数字人视频通过AI算法生成虚拟主播,其外貌、动作、语音等方面可与真实人类媲美…...
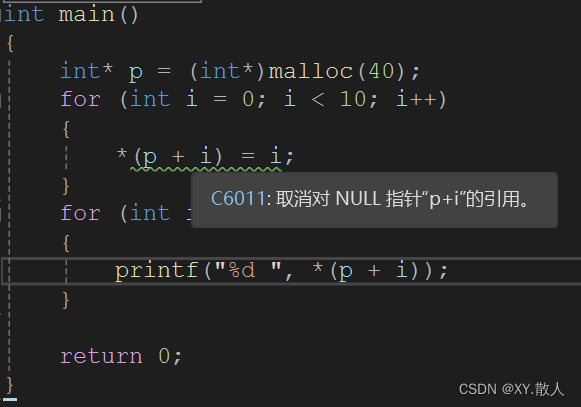
初识C语言·动态内存开辟
1 为什么要有动态内存开辟 int a 10; int arr[10] { 0 }; 上述定义了一个整型,开辟了4个字节,定义了一个整型数组,开辟了40个字节,但是是固定开辟的,面对灵活多变的实际问题的时候可能就有点鸡肋,这种开…...
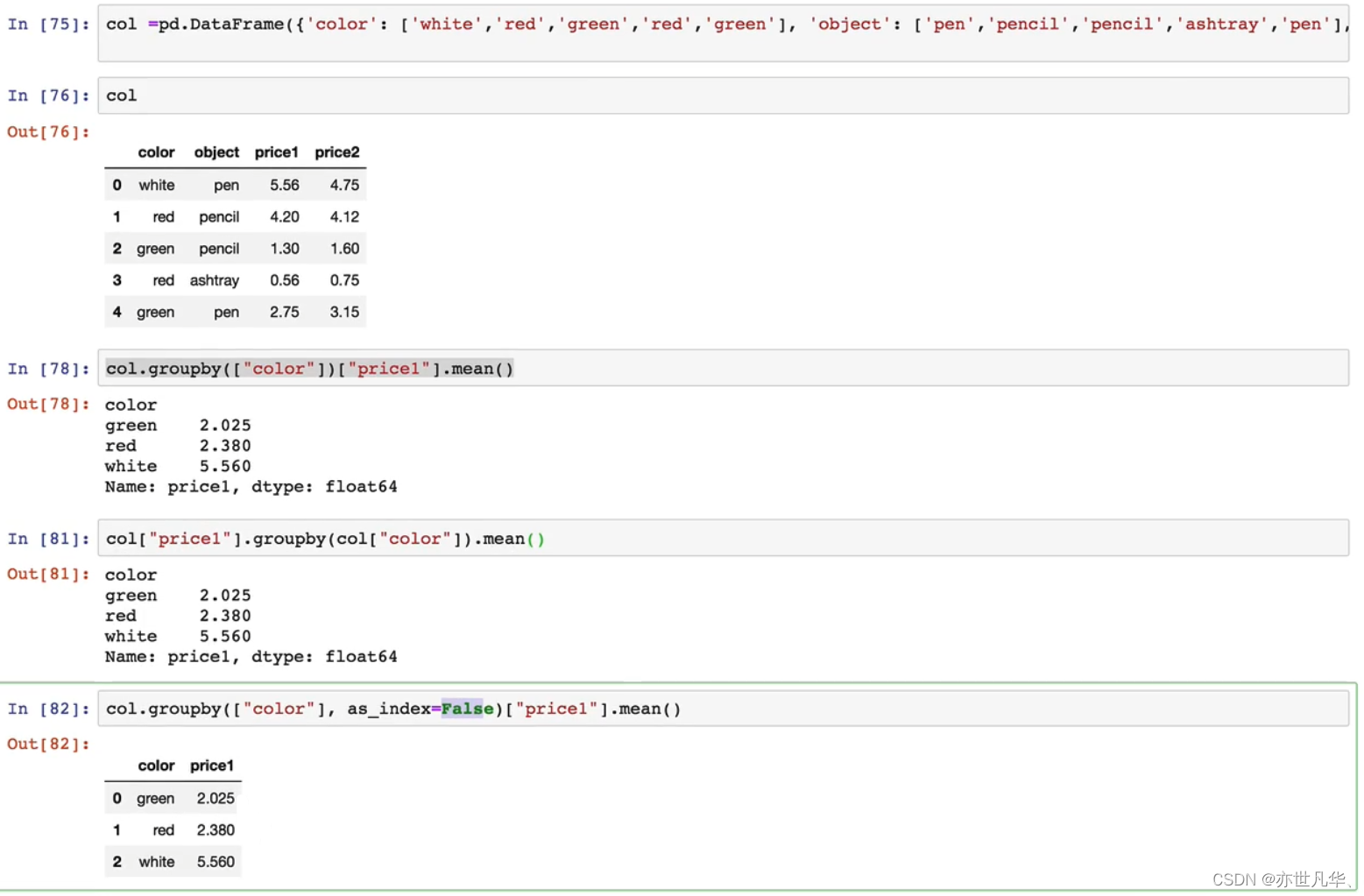
机器学习 | 利用Pandas进入高级数据分析领域
目录 初识Pandas Pandas数据结构 基本数据操作 DataFrame运算 文件读取与存储 高级数据处理 初识Pandas Pandas是2008年WesMcKinney开发出的库,专门用于数据挖掘的开源python库,以Numpy为基础,借力Numpy模块在计算方面性能高的优势&am…...

三、计算机理论-计算机网络-物理层,数据通信的理论基础,物理传输媒体、编码与传输技术及传输系统
物理层概述 物理层为数据链路层提供了一条在物理的传输媒体上传送和接受比特流的能力。物理层提供信道的物理连接,主要任务可以描述为确定与传输媒体的接口有关的一些特性:机械特性、电气特性、功能特性、过程特性 数据通信的理论基础 数据通信的意义 主…...
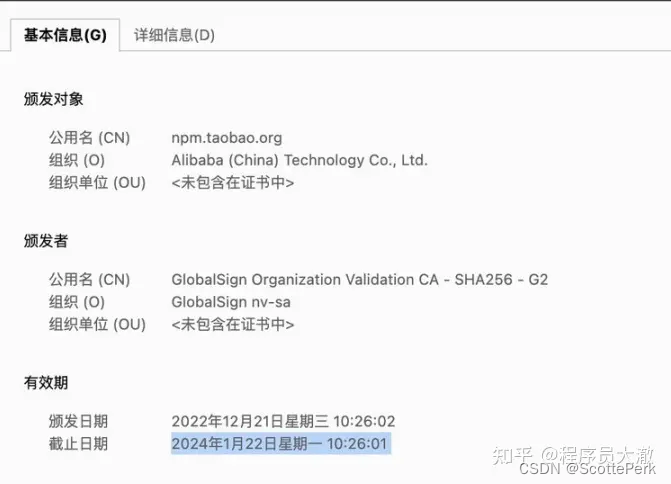
ERROR Failed to get response from https://registry.npm.taobao.org/ 错误的解决
这个问题最近才出现的。可能跟淘宝镜像的证书到期有关。 解决方式一:更新淘宝镜像(本人测试无效,但建议尝试) 虽然无效,但感觉是有很大关系的。还是设置一下比较好。 淘宝镜像的地址(registry.npm.taobao…...

overflow产生的滚动条样式设置
修改overflow产生的滚动条样式,主要可以通过如下三个伪元素设置: 1)-webkit-scrollbar:设置水平滚动条的高度,垂直滚动的宽度 2)-webkit-scrollbar-thumb:设置滚动条里面的滑块样式 3)-webkit-scrollbar-track&…...

Ubuntu环境vscode配置Log4cplus库
1、下载源码 http://sourceforge.net/projects/log4cplus/ 2、安装 例如我下载的是2.0.8版本压缩包,需要解压缩 log4cplus-2.0.8.7z安装解压工具: apt install p7zip-full解压: 7z x log4cplus-2.0.8.7z -r -o/home/配置及编译安装&#x…...

vue中,使用file-saver导出文件,下载Excel文件、下载图片、下载文本
vue中,使用file-saver导出文件,下载Excel文件、下载图片、下载文本 1、基本介绍 npm地址:file-saver - npm 2、安装 # Basic Node.JS installation npm install file-saver --save bower install file-saver# Additional typescript defin…...
)
【VUE】v-if 和 v-show 大详解(多角度分析+面试简答版)
多角度分析+面试简答版 一、`v-if` 和 `v-show` 的区别之多角度分析控制手段:编译过程:编译条件:性能消耗:总结使用场景二、 `v-if`、`v-show`、`display:none` 和`visibility: hidden` 的区别三、简洁版回答:`v-show` 与 `v-if` 比较一、v-if 和 v-show 的区别之多角度分…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

Emacs AI编程助手:ai-code-interface.el深度集成指南
1. 项目概述:一个为Emacs注入AI灵魂的代码接口如果你是一位Emacs的深度用户,同时又对AI辅助编程抱有极大的热情,那么你很可能已经厌倦了在浏览器、终端和编辑器之间反复横跳的割裂体验。tninja/ai-code-interface.el这个项目,正是…...

移动端AI助手开发实战:混合架构、模型部署与性能优化
1. 项目概述:一个移动端AI助手的诞生 最近在移动端AI应用开发圈子里,一个名为 copaw-mobile 的项目开始引起不少同行的注意。这个由 xmingai 团队开源的项目,定位非常清晰——它要做的,就是将一个功能强大的AI助手,…...

gnamiblast-skill:基于技能化与管道化的智能文本处理工具解析
1. 项目概述与核心价值最近在GitHub上闲逛,又发现了一个挺有意思的项目,叫gabrivardqc123/gnamiblast-skill。光看这个名字,可能有点摸不着头脑,gnamiblast听起来像是个自造词,skill又指向了某种技能或功能。作为一名常…...

faah:轻量级自动化任务编排器,简化运维与数据处理工作流
1. 项目概述:一个被低估的自动化利器最近在整理自己的自动化工具链时,又翻出了kiron0/faah这个项目。说实话,第一次看到这个仓库名,我也有点懵——“faah”?这名字听起来不像是一个典型的工具。但点进去之后࿰…...

工控一体机电脑核心性能特征解析:从选型到部署的实战指南
1. 项目概述:为什么我们需要重新审视工控一体机电脑?在工业自动化、智能制造、智慧零售乃至边缘计算这些听起来高大上的领域里,有一类设备常常是幕后的“无名英雄”,它不像机器人手臂那样引人注目,也不像云端服务器那样…...

大语言模型长上下文建模:从注意力优化到Mamba架构的工程实践
1. 项目概述:为什么长上下文建模是LLM的“圣杯”?如果你在过去一年里深度使用过任何主流的大语言模型,无论是ChatGPT、Claude还是开源的Llama、Qwen,一个共同的痛点一定让你印象深刻:“它好像不记得我们之前聊了什么”…...

AI编程助手用量追踪器:设计原理与本地化部署实践
1. 项目概述:一个专为编码代理设计的用量追踪器最近在折腾AI编程助手,发现一个挺实际的问题:当你把像Cursor、Claude Code、GitHub Copilot这类“编码代理”引入团队或者个人深度工作流后,怎么知道它们到底“吃”了多少资源&#…...

AI智能体可观测性实战:用AgentOps实现全链路追踪与性能优化
1. 项目概述:当AI智能体遇上“黑匣子”,我们如何看清它的每一步?如果你最近在折腾AI智能体(Agent),无论是用LangChain、AutoGPT还是自己手搓的框架,大概率会遇到一个共同的痛点:调试…...

苍穹外卖day11
概述项目步入尾声,进行商家数据统计开发分为营业额统计,用户统计,订单统计,销量排名 导航栏的内容为查询选定时间内的的数据统计 右上角的数据导出为下一天的内容 数据导出后形成的图表由Apache的Echarts生成,是开发中…...