kafka summary
最近整体梳理之前用到的一些东西,回顾Kafka的时候好多东西都忘记了,把一些自己记的比较模糊并且感觉有用的东西整理一遍并且记忆一遍,仅用于记录以备后续回顾
Kafka的哪些场景中使用了零拷贝
-
生产者发送消息:在 Kafka 生产者发送消息时,使用零拷贝技术可以避免将数据从用户空间复制到内核空间,从而提高性能。具体来说,在发送消息之前,生产者将消息数据保存在内存缓冲区中,然后将指向缓冲区的指针传递给 Kafka 客户端库,客户端库再将指针传递给网络层,最终将数据发送到 Kafka 服务器。在这个过程中,数据在内存中只有一份副本,避免了数据的复制,从而提高了性能。
-
消费者接收消息:在 Kafka 消费者接收消息时,使用零拷贝技术可以避免将数据从内核空间复制到用户空间,从而提高性能。具体来说,在接收消息之前,消费者会注册一个内存映射文件(Memory-mapped file),然后 Kafka 客户端库会将消息数据写入到这个内存映射文件中。消费者只需要读取这个内存映射文件中的数据,就可以获取消息,避免了数据的复制,从而提高了性能。
-
消费者读取磁盘上的消息:Kafka 中的消息默认存储在磁盘上,消费者需要从磁盘上读取消息。使用零拷贝技术,可以将磁盘上的消息直接映射到内存中,而不需要将数据从磁盘复制到内存,从而提高了性能。
总之,Kafka 使用零拷贝技术来提高网络传输性能和磁盘读取性能,在发送消息和接收消息等场景中都得到了广泛应用。
为什么Kafka不支持读写分离?
在 Kafka 中,生产者写入消息、消费者读取消息的操作都是与 leader 副本进行交互的,从 而实现的是一种主写主读的生产消费模型。
Kafka 并不支持主写从读,因为主写从读有 2 个很明 显的缺点:
数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
延时问题。类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历网络→主节点内存→主节点磁盘→网络→从节点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
Kafka 如何保证高可用?
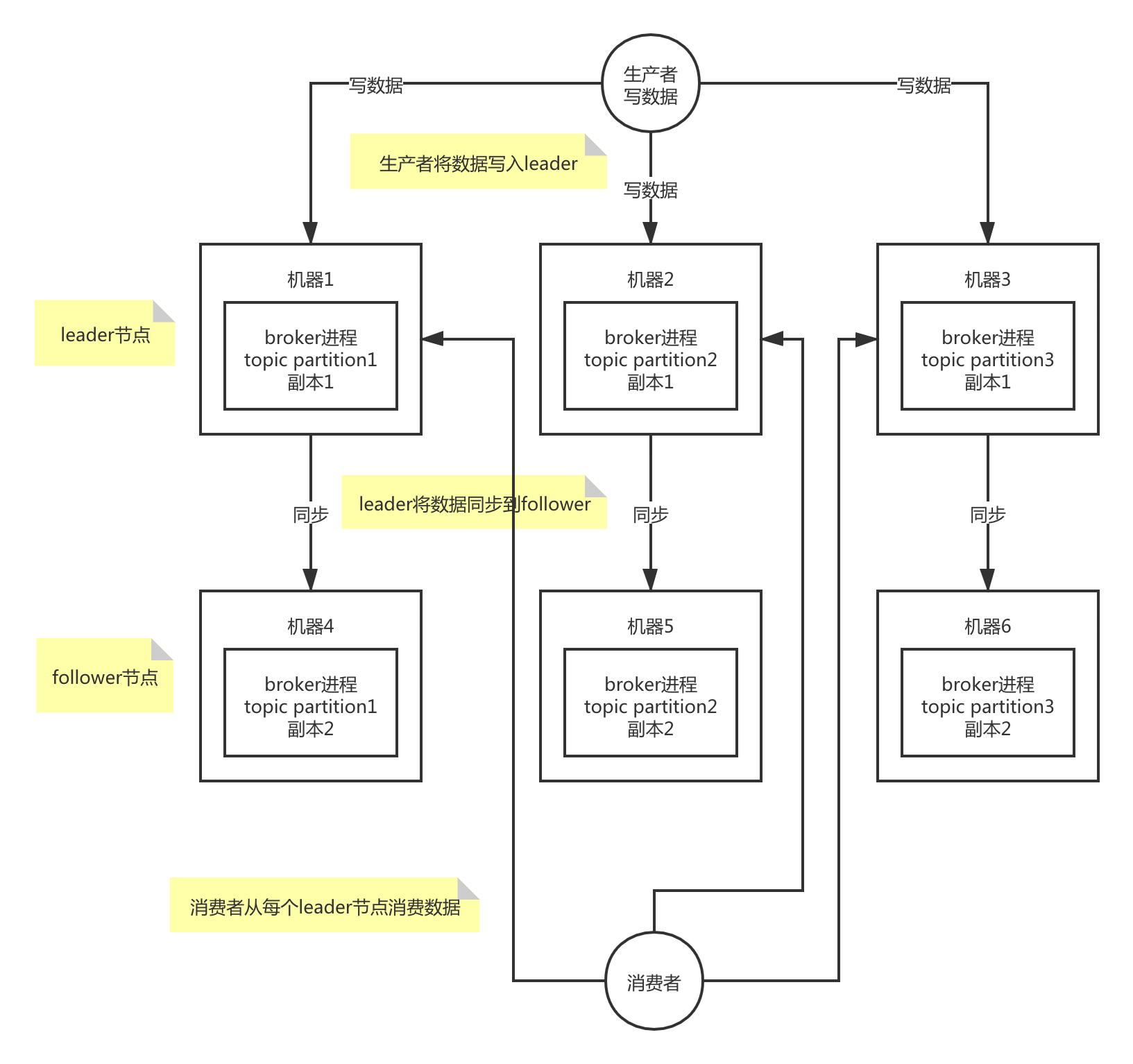
Kafka 的基本架构组成是:由多个 broker 组成一个集群,每个 broker 是一个节点;当创建一个 topic 时,这个 topic 会被划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 只存放一部分数据。
这就是天然的分布式消息队列,就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
在 Kafka 0.8 版本之前,是没有 HA 机制的,当任何一个 broker 所在节点宕机了,这个 broker 上的 partition 就无法提供读写服务,所以这个版本之前,Kafka 没有什么高可用性可言。
在 Kafka 0.8 以后,提供了 HA 机制,就是 replica 副本机制。每个 partition 上的数据都会同步到其它机器,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,消息的生产者和消费者都跟这个 leader 打交道,其他 replica 作为 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。Kafka 负责均匀的将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
拥有了 replica 副本机制,如果某个 broker 宕机了,这个 broker 上的 partition 在其他机器上还存在副本。如果这个宕机的 broker 上面有某个 partition 的 leader,那么此时会从其 follower 中重新选举一个新的 leader 出来,这个新的 leader 会继续提供读写服务,这就有达到了所谓的高可用性。
写数据的时候,生产者只将数据写入 leader 节点,leader 会将数据写入本地磁盘,接着其他 follower 会主动从 leader 来拉取数据,follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。
消费数据的时候,消费者只会从 leader 节点去读取消息,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
什么是消费者组
消费者组是Kafka独有的概念,即消费者组是Kafka提供的可扩展且具有容错性的消费者机制。
但实际上,消费者组(Consumer Group)其实包含两个概念,作为队列,消费者组允许你分割数据处理到一组进程集合上(即一个消费者组中可以包含多个消费者进程,他们共同消费该topic的数据),这有助于你的消费能力的动态调整;作为发布-订阅模型(publish-subscribe),Kafka允许你将同一份消息广播到多个消费者组里,以此来丰富多种数据使用场景。
需要注意的是:在消费者组中,多个实例共同订阅若干个主题,实现共同消费。同一个组下的每个实例都配置有相同的组ID,被分配不同的订阅分区。当某个实例挂掉的时候,其他实例会自动地承担起它负责消费的分区。 因此,消费者组在一定程度上也保证了消费者程序的高可用性。
kafka 为什么那么快?
- Cache Filesystem Cache PageCache缓存
顺序写:由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。Zero-copy:零拷技术减少拷贝次数Batching of Messages:批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。Pull 拉模式:使用拉模式进行消息的获取消费,与消费端处理能力相符。
Kafka如何保证消息不丢失?
首先需要弄明白消息为什么会丢失,对于一个消息队列,会有 生产者、MQ、消费者 这三个角色,在这三个角色数据处理和传输过程中,都有可能会出现消息丢失。
消息丢失的原因以及解决办法:
消费者异常导致的消息丢失
消费者可能导致数据丢失的情况是:消费者获取到了这条消息后,还未处理,Kafka 就自动提交了 offset,这时 Kafka 就认为消费者已经处理完这条消息,其实消费者才刚准备处理这条消息,这时如果消费者宕机,那这条消息就丢失了。
消费者引起消息丢失的主要原因就是消息还未处理完 Kafka 会自动提交了 offset,那么只要关闭自动提交 offset,消费者在处理完之后手动提交 offset,就可以保证消息不会丢失。但是此时需要注意重复消费问题,比如消费者刚处理完,还没提交 offset,这时自己宕机了,此时这条消息肯定会被重复消费一次,这就需要消费者根据实际情况保证幂等性。
生产者数据传输导致的消息丢失
对于生产者数据传输导致的数据丢失主常见情况是生产者发送消息给 Kafka,由于网络等原因导致消息丢失,对于这种情况也是通过在 producer 端设置 acks=all 来处理,这个参数是要求 leader 接收到消息后,需要等到所有的 follower 都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试。
Kafka 导致的消息丢失
Kafka 导致的数据丢失一个常见的场景就是 Kafka 某个 broker 宕机,,而这个节点正好是某个 partition 的 leader 节点,这时需要重新重新选举该 partition 的 leader。如果该 partition 的 leader 在宕机时刚好还有些数据没有同步到 follower,此时 leader 挂了,在选举某个 follower 成 leader 之后,就会丢失一部分数据。
对于这个问题,Kafka 可以设置如下 4 个参数,来尽量避免消息丢失:
- 给
topic设置replication.factor参数:这个值必须大于1,要求每个partition必须有至少2个副本; - 在
Kafka服务端设置min.insync.replicas参数:这个值必须大于1,这个参数的含义是一个leader至少感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower节点。 - 在
producer端设置acks=all,这个是要求每条数据,必须是写入所有replica之后,才能认为是写成功了; - 在
producer端设置retries=MAX(很大很大很大的一个值,无限次重试的意思):这个参数的含义是一旦写入失败,就无限重试,卡在这里了。
Kafka 如何保证消息的顺序性
在某些业务场景下,我们需要保证对于有逻辑关联的多条MQ消息被按顺序处理,比如对于某一条数据,正常处理顺序是新增-更新-删除,最终结果是数据被删除;如果消息没有按序消费,处理顺序可能是删除-新增-更新,最终数据没有被删掉,可能会产生一些逻辑错误。对于如何保证消息的顺序性,主要需要考虑如下两点:
- 如何保证消息在
Kafka中顺序性; - 如何保证消费者处理消费的顺序性。
如何保证消息在 Kafka 中顺序性
对于 Kafka,如果我们创建了一个 topic,默认有三个 partition。生产者在写数据的时候,可以指定一个 key,比如在订单 topic 中我们可以指定订单 id 作为 key,那么相同订单 id 的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。消费者从 partition 中取出来数据的时候,也一定是有顺序的。通过制定 key 的方式首先可以保证在 kafka 内部消息是有序的。
如何保证消费者处理消费的顺序性
对于某个 topic 的一个 partition,只能被同组内部的一个 consumer 消费,如果这个 consumer 内部还是单线程处理,那么其实只要保证消息在 MQ 内部是有顺序的就可以保证消费也是有顺序的。但是单线程吞吐量太低,在处理大量 MQ 消息时,我们一般会开启多线程消费机制,那么如何保证消息在多个线程之间是被顺序处理的呢?对于多线程消费我们可以预先设置 N 个内存 Queue,具有相同 key 的数据都放到同一个内存 Queue 中;然后开启 N 个线程,每个线程分别消费一个内存 Queue 的数据即可,这样就能保证顺序性。当然,消息放到内存 Queue 中,有可能还未被处理,consumer 发生宕机,内存 Queue 中的数据会全部丢失,这就转变为上面提到的如何保证消息的可靠传输的问题了。
14. Kafka中的ISR、AR代表什么?ISR的伸缩指什么?
ISR:In-Sync Replicas 副本同步队列AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度,当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。
AR=ISR+OSR。
分区Leader选举策略有几种?
分区的Leader副本选举对用户是完全透明的,它是由Controller独立完成的。你需要回答的是,在哪些场景下,需要执行分区Leader选举。每一种场景对应于一种选举策略。
- OfflinePartition Leader选举:每当有分区上线时,就需要执行Leader选举。所谓的分区上线,可能是创建了新分区,也可能是之前的下线分区重新上线。这是最常见的分区Leader选举场景。
- ReassignPartition Leader选举:当你手动运行kafka-reassign-partitions命令,或者是调用Admin的alterPartitionReassignments方法执行分区副本重分配时,可能触发此类选举。假设原来的AR是[1,2,3],Leader是1,当执行副本重分配后,副本集合AR被设置成[4,5,6],显然,Leader必须要变更,此时会发生Reassign Partition Leader选举。
- PreferredReplicaPartition Leader选举:当你手动运行kafka-preferred-replica-election命令,或自动触发了Preferred Leader选举时,该类策略被激活。所谓的Preferred Leader,指的是AR中的第一个副本。比如AR是[3,2,1],那么,Preferred Leader就是3。
- ControlledShutdownPartition Leader选举:当Broker正常关闭时,该Broker上的所有Leader副本都会下线,因此,需要为受影响的分区执行相应的Leader选举。
这4类选举策略的大致思想是类似的,即从AR中挑选首个在ISR中的副本,作为新Leader。
相关文章:
kafka summary
最近整体梳理之前用到的一些东西,回顾Kafka的时候好多东西都忘记了,把一些自己记的比较模糊并且感觉有用的东西整理一遍并且记忆一遍,仅用于记录以备后续回顾 Kafka的哪些场景中使用了零拷贝 生产者发送消息:在 Kafka 生产者发送…...
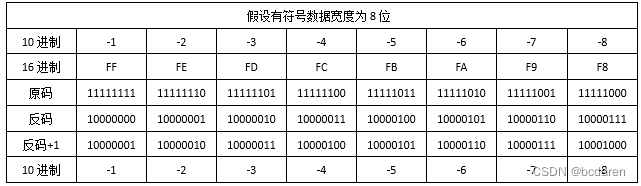
【新书推荐】2.6节 原码、反码和补码
回顾上一节中,我们讲解了整数的编码规则。 无符号整数编码规则:无符号整数全部都是正数,是什么就存什么。 有符号整数编码规则:有符号整数最高有效位为0是正数,最高有效位为1是负数。 本节内容:原码、反…...
docker 网络及如何资源(CPU/内存/磁盘)控制
安装Docker时,它会自动创建三个网络,bridge(创建容器默认连接到此网络)、 none 、host docker网络模式 Host 容器与宿主机共享网络namespace,即容器和宿主机使用同一个IP、端口范围(容器与宿主机或其他使…...
安装 nvm
前言: nvm 即 node 版本管理工具 (node version manager),好处是方便切换 node.js 版本。 通过将多个 node 版本安装在指定路径,然后通过 nvm 命令切换时,就会切换我们环境变量中 node 命令指定的实际执行的软件路径。 使用场景…...

Redis解决方案:NOAUTH Authentication required(连接jedis绑定密码或修改redis密码)
Redis解决方案:NOAUTH Authentication required(连接jedis绑定密码或修改redis密码) Java使用jedis连接redis时出现错误NOAUTH Authentication required 一、问题报错和原因 本地设置了redis的密码,但在远程连接时并没有输入密…...

多维时序 | Matlab实现WOA-TCN-Multihead-Attention鲸鱼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测
多维时序 | Matlab实现WOA-TCN-Multihead-Attention鲸鱼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测 目录 多维时序 | Matlab实现WOA-TCN-Multihead-Attention鲸鱼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测效果一览基本介绍程序设计参考资料 效…...

如何实现无公网IP实现远程访问MongoDB文件数据库
📑前言 本文主要是如何实现无公网IP实现远程访问MongoDB文件数据库的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页放风讲故事 &#x…...
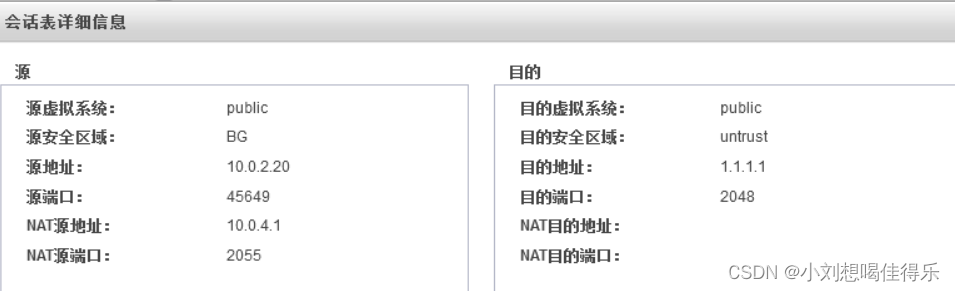
华为防火墙USG6000V1的NAT实验
实验拓扑: 之前实验做过,可以翻找之前的博客,各设备ip和接口已配好,均可可ping通防火墙。 实验要求: 一.生产区在工作时间内可以访问dmz区域,仅可以访问http服务器。 二.办公区全天可以访问dmz区域&…...

spark-flink设计思想之吸星大法-1
Spark和Flink都是大数据处理框架,它们的设计思想有一些不同之处。以下是对它们设计思想的简要对比: 数据模型和计算模型: Spark:Spark使用弹性分布式数据集(RDD)作为其核心数据结构。RDD是只读的、不可变的…...

力扣1312. 让字符串成为回文串的最少插入次数
动态规划 思路: 通过插入字符构造回文串,要想插入次数最少,可以将字符串 s 的逆序 s 进行比较找出最长公共子序列;可以先分析,字符串 s 通过插入得到回文串 ps,其中间的字符应该不会变化: 若 s…...
qemu的安装
1、简介 QEMU(Quick EMUlator)是一个开源的处理器模拟器,它可以在一种硬件平台上模拟另一种硬件平台,从而运行各种不同的操作系统。QEMU通过动态二进制翻译来实现高性能的模拟,这使得它可以在接近原生性能的速度下运行…...

myql入门
目录 安装修改密码学习资料个人git仓库文章视频官网 安装 #移除以前的mysql相关 sudo apt remove --purge mysql-\* #安装mysql sudo apt install mysql-server mysql-client #查看是否启动 systemctl status mysql #手动启动 systemctl start mysql #查看mysql版本 mysql --v…...

前端开发有没有必要转鸿蒙开发?
前端开发有没有必要转鸿蒙开发?如果后面的工作中有参与鸿蒙开发的机会,那肯定是转呀!毕竟多接触一些技能也不会有什么坏处。 我想说的是:鸿蒙替代不了前端,如果你目前正在从事前端开发,那么你完全可以将鸿蒙…...
》笔记1)
《动手学深度学习(PyTorch版)》笔记1
Chapter1 Introduction 1.1 机器学习的关键组件 data 每个数据集由一个个样本(example, sample)组成,大多时候,它们遵循独立同分布(independently and identically distributed, i.i.d.)。 样本有时也叫做数据点(dat…...
)
前端工程化之:webpack1-5(配置文件)
一、配置文件 webpack 提供的 cli 支持很多的参数,例如 --mode ,但更多的时候,我们会使用更加灵活的配置文件来控制 webpack 的行为。 默认情况下, webpack 会读取 webpack.config.js 文件作为配置文件,但也可以通过 C…...

代码随想录栈和队列专题二刷复盘day17
栈和队列理论基础 队列是先进先出,栈是先进后出 栈和队列是STL里面的两个数据结构 三个最为普遍的STL版本 1.HP STL其他版本的C STL,一般是以HP STL为蓝本实现出来的,HP STL是C STL的第一个实现版本,且开放源代码 2.P.J.Plauger…...
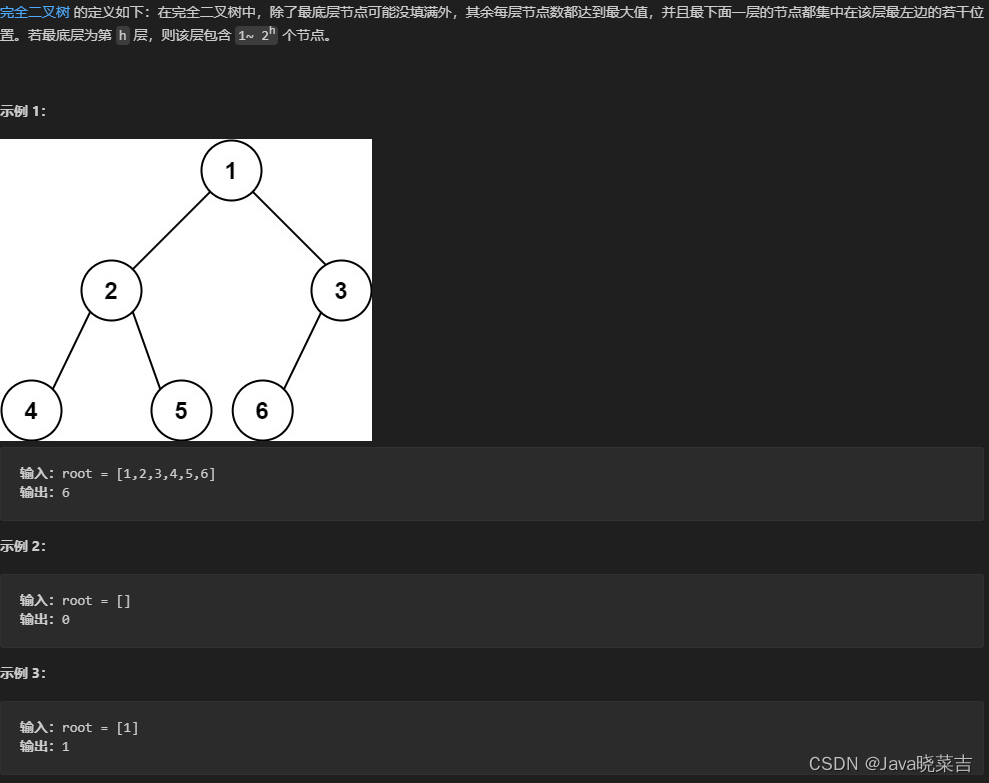
代码随想录算法刷题训练营day16
代码随想录算法刷题训练营day16:LeetCode(104)二叉树的最大深度 、LeetCode(559)n叉树的最大深度、LeetCode(111)二叉树的最小深度、LeetCode(222)完全二叉树的节点个数 LeetCode(104)二叉树的最大深度 题目 代码 /*** Definition for a binary tree node.* publ…...

【C语言/数据结构】排序(直接插入排序|希尔排序)
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343🔥 系列专栏:《数据结构》https://blog.csdn.net/qinjh_/category_12536791.html?spm1001.2014.3001.5482 目录 插入排序 直接插入排序&…...
Jupyter Notebook安装使用教程
Jupyter Notebook 是一个基于网页的交互式计算环境,允许你创建和共享包含代码、文本说明、图表和可视化结果的文档。它支持多种编程语言,包括 Python、R、Julia 等。其应用场景非常广泛,特别适用于数据科学、机器学习和教育领域。它可以用于数…...

Unity 中的接口和继承
在Unity的游戏开发中,理解面向对象编程的概念,如类、接口、继承和多态性,是非常重要的。本文旨在帮助理解和掌握Unity中接口和继承的概念,以及如何在实际项目中应用这些知识。 类和继承 在C#和Unity中,类是构建应用程序…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...
)
别再死记硬背公式了!用Python+NumPy手把手带你仿真RLC串联谐振(附代码)
用PythonNumPy动态仿真RLC串联谐振:告别枯燥公式,直观理解电路本质 当你第一次翻开电路分析教材,看到那些密密麻麻的公式推导和抽象的频率响应曲线时,是否感到一阵眩晕?RLC串联谐振作为电路分析的核心概念,…...

Rekall:基于时空查询的视频内容智能检索开源框架
1. 项目概述:Rekall,一个面向视频时空查询的开源利器 如果你曾经尝试过从一段长视频里,精准地找出“那个穿红色衣服的人从画面左侧走到右侧的片段”,或者想快速定位“所有出现这只特定宠物狗的镜头”,你就会知道这有多…...

Switch便携投影底座DIY:3D打印与硬件改造实战指南
1. 项目概述:当Switch遇上投影,一场桌面上的大屏革命作为一个折腾过不少游戏机外设的玩家,我一直在想,有没有办法让Switch的“便携”属性再进化一步?官方底座接电视固然爽,但总被一根线缆束缚在客厅。直到我…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...

药物发现自动化:FEP计算工作流引擎faah的设计原理与实战
1. 项目概述:一个面向药物发现的自动化工作流引擎 最近在药物研发的自动化工具领域,一个名为 kiron0/faah 的项目引起了我的注意。这并非一个简单的脚本集合,而是一个设计精巧、旨在为药物发现中的自由能微扰计算提供端到端自动化解决方案的…...

基于BLE HID与旋转编码器打造双模式无线遥控器
1. 项目概述你有没有过这样的时刻:窝在沙发里看剧,想调个音量或者暂停一下,却不得不伸手去够茶几上的键盘或鼠标,打断那份沉浸的惬意?或者,在电脑上回味一些经典老游戏时,觉得用键盘移动、鼠标射…...

如何在Windows上无缝安装安卓应用:APK安装器终极指南
如何在Windows上无缝安装安卓应用:APK安装器终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾在电脑上羡慕安卓应用的便利,却苦…...

I2C地址冲突全解析:从原理到实战的嵌入式系统设计指南
1. I2C地址:嵌入式系统设计的“门牌号”与“交通规则”如果你玩过单片机或者树莓派,肯定对I2C不陌生。两根线,SDA和SCL,就能挂上一堆传感器、显示屏、扩展芯片,听起来简直是嵌入式开发的“万金油”。但真正上手后&…...