【汇编】三、寄存器(一只 Assember 的成长史)
嗨~你好呀!
我是一名初二学生,热爱计算机,码龄两年。最近开始学习汇编,希望通过 Blog 的形式记录下自己的学习过程,也和更多人分享。
上篇系列文章链接:【汇编】二、预备知识(一只 Assember 的成长史)
这篇文章主要讲解寄存器。
话不多说~我们开始吧!
⭐ 注:本系列文章基于 8086 CPU,16 位汇编,参考书《汇编语言》。
本系列旨在为 32 位汇编的学习以及汇编的实际使用打下基础。
目录
三 0. 本文中用到的汇编指令及其功能
三 1. 寄存器是什么
三 2. 寄存器的分类
1. 通用寄存器
2. 控制寄存器
3. 段寄存器
三 3. 通用寄存器及数据在通用寄存器中的存储
三 4. 物理地址、物理地址计算方法及段的概念
1. 物理地址
2. 物理地址计算方法
3. 段的概念
三 5. CS/IP 寄存器及 CPU 读取执行指令的工作过程
1. cs 和 ip 寄存器
2. CPU 读取、执行指令的工作过程
3. 修改 cs 和 ip 寄存器
三 0. 本文中用到的汇编指令及其功能
| 汇编指令 | 指令功能 | 高级语言语法描述 |
| mov X, Y | 将 Y 中的数据送至 X 中 | X = Y |
| add X, Y | 将 X,Y 相加,并将结果存储在 X 中 | X += Y 或 X = X+Y |
| jmp X:Y | 将 cs 的值设置为 X,将 ip 的值设置为 Y(后面会详细讲到) | cs = X; ip = Y |
| jmp 某一合法寄存器名 | 将 ip 的值设置为该合法寄存器中存储的值(后面会详细讲到) | ip = 该寄存器中存储的值 |
注:mov 和 add 的使用有一些限制,但涉及到更多知识,容易打乱思路和学习主线,所以会在遇到这些限制的时候再进行说明~
三 1. 寄存器是什么
上一篇说过,计算机有多种存储器,寄存器也是其中一种。
我们都知道,CPU 的运算速度远高于内存的读写速度,所以如果每次需要数据都要从内存中读取,会严重拖慢 CPU 的运行速度。正因如此,CPU 内嵌入了读写速度更快的 cache(高速缓存)和寄存器,用于存储最常用的数据(比如 for 循环中的 i)。cache 和寄存器也相当于 CPU 和内存之间的一座桥梁。
寄存器的体积最小、读写速度最快、价格最贵。
三 2. 寄存器的分类
不同的 CPU,寄存器的个数和结构都是不相同的,但总有那么几个寄存器出现在任何种类的 CPU 中。8086 CPU 共有 14 个寄存器(寄存器名不区分大小写):ax, bx, cx, dx, si, di, sp, dp, bp, ip, cs, ss, ds, es, psw。
不过这 14 个没必要一口气学完,此处仅列出分类,下文中会讲到几个,后续文章中会讲到其它的~如果现在就想详细了解,可以去:爱了爱了,这篇寄存器讲的有点意思
1. 通用寄存器
· 数据寄存器:ax, bx, cx, dx
· 地址指针寄存器:sp, bp
· 变址寄存器:si, di
2. 控制寄存器
· 指令指针寄存器:ip
· 标志寄存器:psw
3. 段寄存器
(结尾的 s 全称为 segment,即 “段”)
· 代码段:cs(c = code)
· 数据段:ds(d = data)
· 栈段:ss(s = stack)
· 附加段:es(e = extra)
三 3. 通用寄存器及数据在通用寄存器中的存储
8086 CPU 的所有寄存器都是 16 位的,可以存放两个字节(一个字)。如下图:
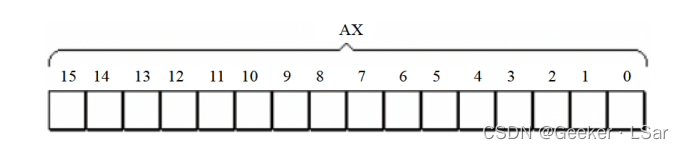
But,8086 的上一代 CPU 中的寄存器都是 8 位的,为了保证兼容,8086 CPU 中的 ax, bx, cx, dx 寄存器都可以分为两个 8 位寄存器来使用(但其他的不可以)。
ax 分为 ah 和 al(h = high,l = low,下同);
bx 分为 bh 和 bl;
cx 分为 ch 和 cl;
dx 分为 dh 和 dl;
通过其英文我们不难猜出,ah 中存储的是 ax 中的高 8 位数据,而 al 中存储的是 ax 中的低 8 位数据。下图是一个例子(“20H” 中的 H 表示该数据是十六进制)。
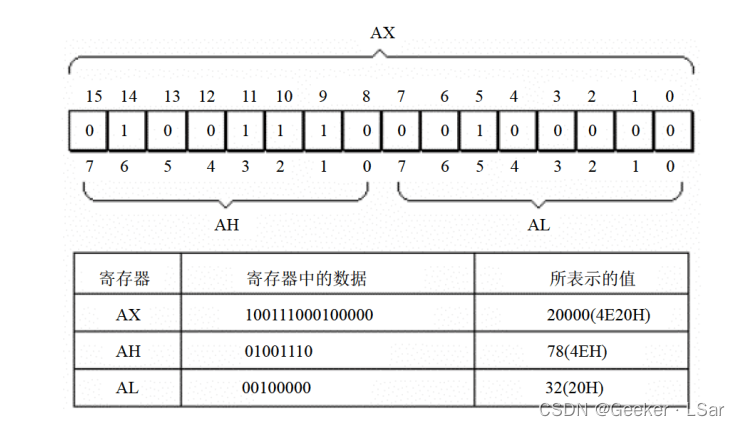
上图其实也表明了数据在 16 位寄存器中的存储。如果数据是一个字节,它将被存储在寄存器的某个 8 位中(高或低不确定)。如果数据是一个字,它的高位字节存储在寄存器的高 8 位中,低位字节存储在寄存器的低 8 位中。
如果在 ax 中存放的数据超过了 16 位(如 mov ax, FFFFFF0H),会导致高位丢失。
如果单独使用 al 或 ah,存放的数据超过 8 位时会导致高位丢失(不要误认为,单独使用 al 时,如果超过 8 位,会将进位存储在 ah 中)。
注意不要混淆寄存器和内存单元,一个字可以使用一个寄存器存储,但会占用两个内存单元(一个内存单元 8 位)。
在进行数据传送或运算时,两个操作对象的位数应当是一致的,比如不能这样写:mov ax,bl(前者是 16 位寄存器,后者是 8 位寄存器)。
三 4. 物理地址、物理地址计算方法及段的概念
1. 物理地址
上篇文章中说过,各个存储器的物理存储空间被合在一起看成一个逻辑存储空间,也就是内存地址空间,这个空间由很多内存单元构成。
而 CPU 想要寻址,就必须保证内存单元的地址的唯一性。内存单元在内存地址空间中唯一的地址就是它的物理地址(相当于身份证号)。
这就涉及到了一个问题——CPU 怎么给出物理地址?
2. 物理地址计算方法
首先需要面对一个非常囧的情况:8086 CPU 有 20 根地址总线,但只有 16 根数据总线......
通过上篇文章的计算公式不难得出,它的寻址能力是 1MB(或者说最大可以有 1MB 内存)。但是它一次只能发送 64KB 的数据(相当于 16 位的地址),表现出的寻址能力只有 64KB...
怎么办?如果只能发送 16 位的地址,那么内存大小只会有 64KB,且还白白浪费了 4 根地址总线。
但大佬就是大佬,一个 16 位不够,可以用两个啊!(虽然我很好奇为什么当时不加上 4 根数据总线,那不就万事大吉了)
so,解决办法出炉了——用两个 16 位地址合成一个 20 位地址。一个称为段地址,一个称为偏移地址(后面会讲到)。
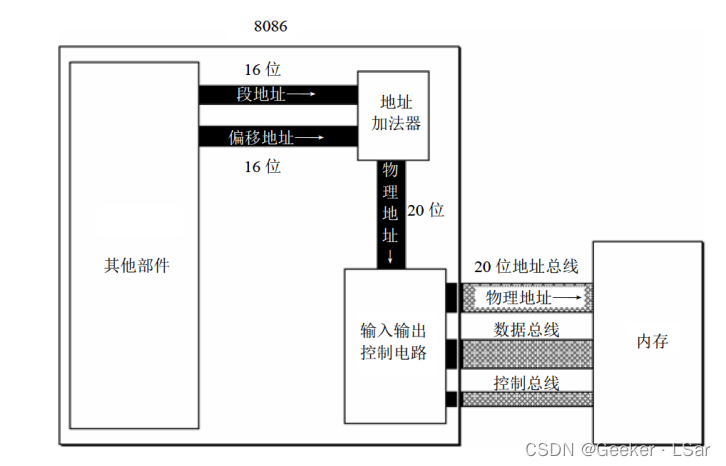
如上图,概括一下 8086 CPU 读写内存的过程:
CPU 把段地址和偏移地址告诉地址加法器,地址加法器按照公式用这两个 16 位地址生成一个 20 位物理地址,再通过地址总线送到存储器。
这个公式就是:物理地址 = 段地址 * 16 + 偏移地址( * 16 相当于左移 4 位)
补充一些数学知识:
· 一个 X 进制的数据左移 1 位,相当于乘以 X。
· 一个二进制数左移 4 位,相当于在原数的末尾加 4 个 0。
· 一个十六进制数左移 4 位,相当于在原数的末尾加 1 个 0。
补充的第二条也解释了为什么两个 16 位地址经过公式计算后可以生成一个 20 位地址。因为原来的段地址是 16 位,段地址 * 16 后末尾多了 4 个 0,变成了 20 位,再加上 16 位的偏移地址,还是 20 位。
下图是一个例子,其中段地址和偏移地址都用十六进制表示(其实它们在被送上地址总线的时候都是二进制,但是十六进制相对易读,也比较短)。
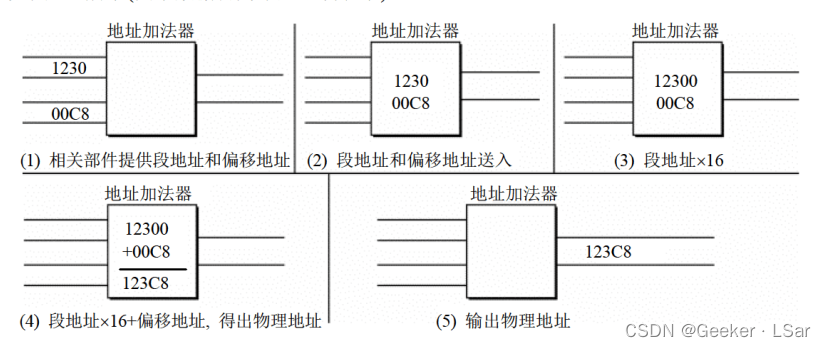
这个公式的本质含义是:CPU 在访问内存时,用一个基础地址和一个相对于基础地址的偏移地址相加,给出内存单元的物理地址。其中,“基础地址” 就是段地址 * 16。
根据这个公式,同一个物理地址可以用不同的段地址和偏移地址来表示,比如:
| 段地址 | 偏移地址 | 物理地址 |
| 0001 | 0000 | 0001 * 16 + 0000 = 00010+0000 = 00010 |
| 0000 | 0010 | 0000 * 16 + 0010 = 00000+0010 = 00010 |
其实 32 位 CPU 也延续了用段地址和偏移地址来表示一个内存单元的传统,只不过操作系统从实模式变成了保护模式,添加了 GDT、段描述符、段选择子等等一系列复杂的东西,后续文章会讲到哒~
3. 段的概念
你可能已经注意到了,“段地址” 这个名称似乎在暗示,内存地址空间是被分段的...?
nonono!内存地址空间是一个逻辑空间,并没有分段,段的划分来自于 CPU(上面那个表格也可以解释这一点,如果内存被分段的话,就会有两个内存单元对应同一个物理地址了)。
分段的方式可以让开发者更好地管理内存,比如我们可以把一部分内存划为代码段,专门用于存放代码;另一部分内存划分为数据段,专门用于存放数据;等等。在后续的文章中会陆续出现的~
比如,我们可以用不同的方式划分 10000H~100FFH 这段内存(不过一个段的起始地址一定是 16 的倍数,相当于段地址 * 16 + 0)。

如果你想在一个学校中找到 “初二 5 班 29 号同学”,你可以先找到初二5班,再在这个较小的范围中寻找 29 号同学,这可以减小你的工作量。
同理,分段可以让你不必记住这个内存单元的物理地址,而只需要先设置好段地址(后续文章会讲到),再通过偏移地址在这个段中定位需要的内存单元就可以了~
不过,偏移地址的长度是 16 位,所以一个段的长度最大为 64KB。
三 5. CS/IP 寄存器及 CPU 读取执行指令的工作过程
1. cs 和 ip 寄存器
cs 和 ip 是 CPU 中两个最关键的寄存器,它们指示了 CPU 当前要读取的指令的地址。其中 cs 为代码段寄存器(存储段地址),ip 为指令指针寄存器(存储偏移地址)。
若设 cs 中内容为 X,ip 中内容为 Y,对于 8086 CPU,它将从内存 X * 16 + Y 单元开始,读取一条指令并执行。换言之,它将 cs:ip 指向的内存单元中的内容当作指令执行。
2. CPU 读取、执行指令的工作过程
我们已经知道 CPU 会将 cs:ip 指向的内容当作指令执行,那么,一条指令究竟是怎么执行的呢?CPU 在这个过程中是如何工作的?
我们通过一个例子来看这个问题。
如下图,cs 的值为 2000H,ip 的值为 0000H,内存 20000H~20009H 单元存放着可执行的机器码,旁边给出了每几条对应的汇编指令。地址加法器负责计算物理地址;输入输出控制电路负责输入/输出数据;指令缓冲器负责缓冲(暂存)指令;指令执行器(或称为执行控制器)负责执行指令。
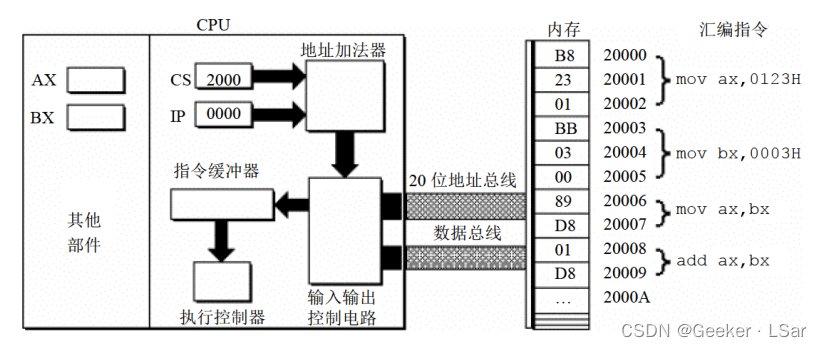
第一步:如下图,cs, ip 中的内容送入地址加法器,地址加法器通过 “物理地址 = 段地址 * 16 + 偏移地址” 计算出内存单元的物理地址。
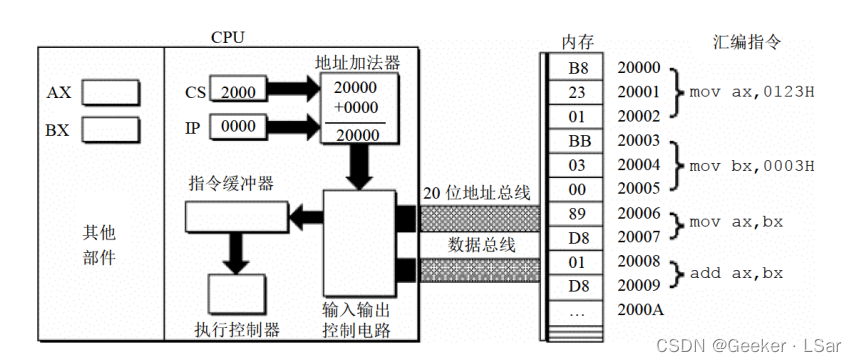
第二步:如下图,地址加法器将物理地址送入输入输出控制电路。
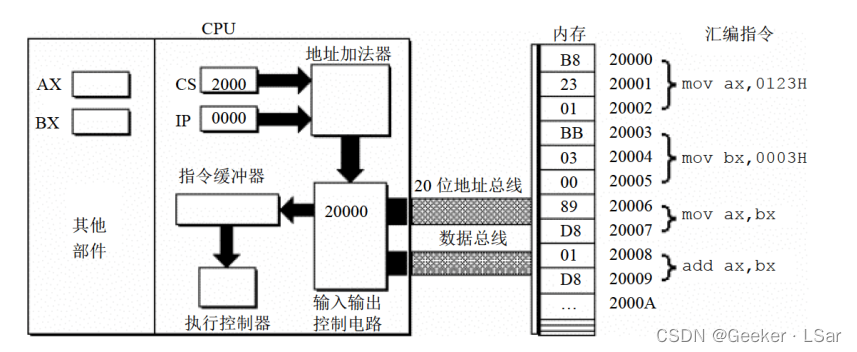
第三步:如下图,输入输出控制电路将物理地址 20000H 送上地址总线,经地址总线送入内存。
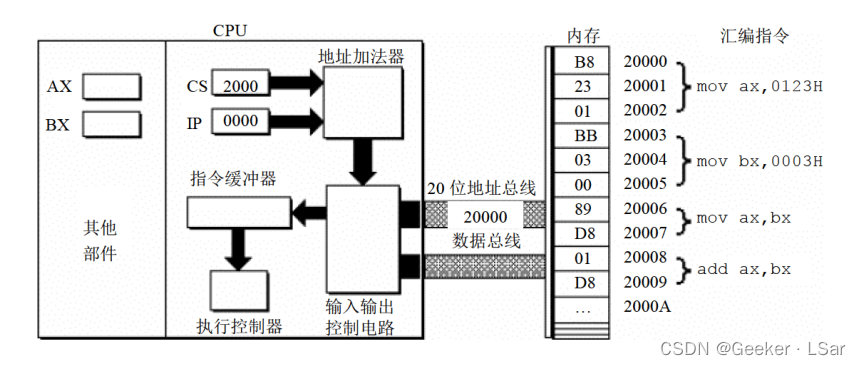
第四步:如下图,从内存 20000H 单元开始存放的机器指令(B8 23 01)通过数据总线被送入 CPU。
(你可能会好奇,诶 CPU 怎么知道它要三个内存单元的数据?它怎么知道 20000H 到 20003H 就是完整的一条汇编指令?)
(这是因为 CPU 有指令解释器,它知道 mov 后面跟着几个字节~)
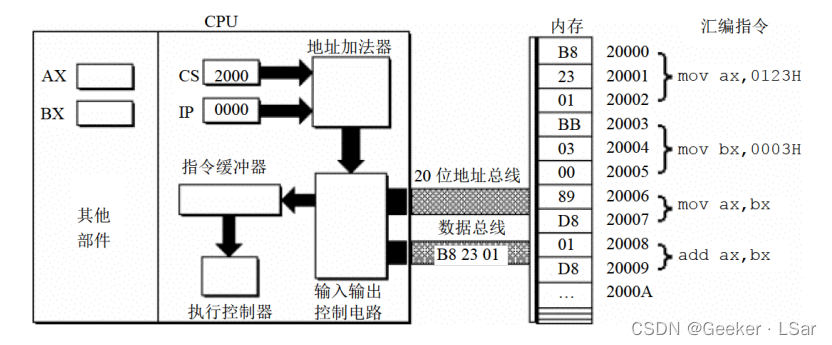
第五步:如下图,输入输出控制电路将机器指令(B8 23 01)送入指令缓冲器。
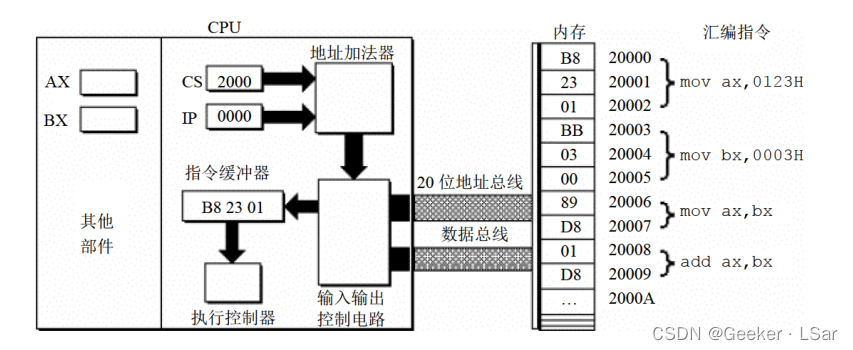
第六步:如下图,读取一条指令后,ip 寄存器中的值将自动增加,以便 CPU 可以读取下一条指令。因为当前读入的指令长度为 3 个字节,所以 ip 中的值自动加 3。此时 cs:ip 指向内存单元 2000:0003。

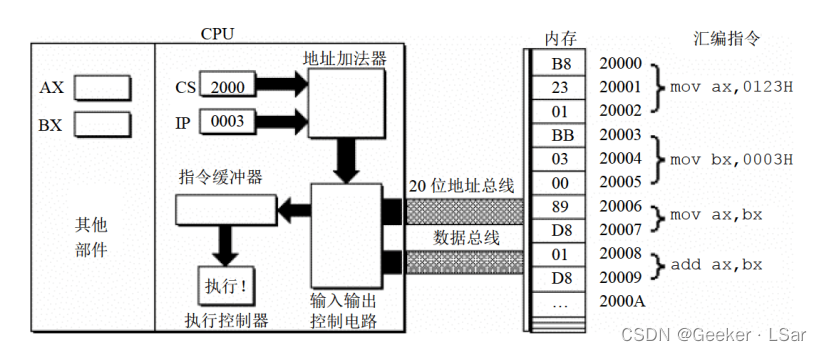
第七步:如下图,指令执行器执行指令 B8 23 01。
此时,ax 寄存器中的内容为 123H。
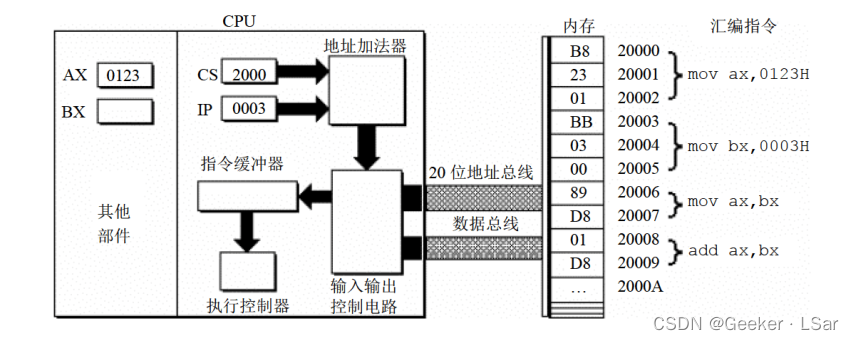
总结一下 CPU 读取和执行指令的过程吧~:
1. 从 cs:ip 指向的内存单元读取指令,读取的指令进入指令缓冲器;
2. ip = ip + 所读取的指令的长度,从而转向下一条指令;
3. 执行指令,转到步骤 1,重复这个过程。
3. 修改 cs 和 ip 寄存器
本文最开始提到,mov 和 add 指令的使用是有限制的,其中的一些限制在这里表现了出来。
如何改变一个寄存器的值?我猜你第一个想到的是使用 mov 指令,把一个值送入寄存器。
buuuuuut...cs 和 ip 偏偏就很有个性,它俩不接受通过 mov 修改它们的值...(其实 “有个性” 的寄存器不止它俩,后续文章中会提到~)
能够改变 cs 和 ip 的值的指令被称为转移指令,其中最简单的一个是 jmp 指令。
若想同时修改 cs 和 ip 的值,可用形如 “jmp 段地址:偏移地址” 来实现。jmp 用指令中给出的段地址修改 cs,用指令中给出的偏移地址修改 ip。如:jmp 218h:520h,执行后 cs = 218H,ip = 520H,CPU 将从 026A0H(218H * 16 + 520H)处读取指令。
若仅想修改 ip 的值,可用形如 “jmp 某一台合法寄存器” 来实现。jmp 用指令中给出的合法寄存器中的值修改 ip。如:mov ax, 1320h; jmp ax(注意!汇编代码后面没有分号,此处使用分号仅仅为了便于区分两条指令~),执行后 ip = 1320H。
如果你希望定义一个代码段,可以使用 cs:ip 指向代码段中第一条指令所在的内存地址空间(的起始位置)。
还有一些别的转移指令,后续文章中会讲到~
以上就是本文的全部内容啦~感谢你看到这里~
作者只是一名初学者,有任何错误或解释不当之处欢迎指出呀~一起加油!
那,我们下一篇再见咯~
2023-03-04
By Geeker · LStar
❤️
相关文章:
【汇编】三、寄存器(一只 Assember 的成长史)
嗨~你好呀! 我是一名初二学生,热爱计算机,码龄两年。最近开始学习汇编,希望通过 Blog 的形式记录下自己的学习过程,也和更多人分享。 上篇系列文章链接:【汇编】二、预备知识(一只 Assember 的…...

TFT通信协议解析与应用
TFTP(Trivial File Transfer Protocol)是一种简单的文件传输协议,常用于在本地网络上的设备之间传输小型文件。 通信大致过程 TFTP通信过程如下: TFTP通信双方建立连接:TFTP客户端与TFTP服务器建立连接。TFTP服务器监…...

python 操作word库docx 增强接口
前言用python 的docx 库操作word完成一些自动化的文档生成工作,但有时候会遇到docx库提供的操作无法直接满足业务上的需求,需要对其进行一些扩展。接口完善实现在指定的文字后面插入指定的文字任务:以下示例需要在文档中的所有 "人生苦短…...

ARM uboot 源码分析9 - uboot的硬件驱动部分
一、uboot 与 linux 驱动 1、uboot 本身是裸机程序 (1) 裸机本来是没有驱动的概念的(狭义的驱动的概念就是,操作系统中用来具体操控硬件的那部分代码叫驱动) (2) 裸机程序中是直接操控硬件的,操作系统中必须通过驱动来操控硬件…...

Mybatis动态sql语句foreach中拼接正则表达式字符串注意事项
今天要说到的查询情况,平时项目里边其实用到的并不是很多,使用正则表达式无非是为了匹配结果比较灵活,最常见的,我们的查询条件一般一个参数仅仅只是一种情况的筛选,对于如何选择查询方式,主要还是要看前端…...
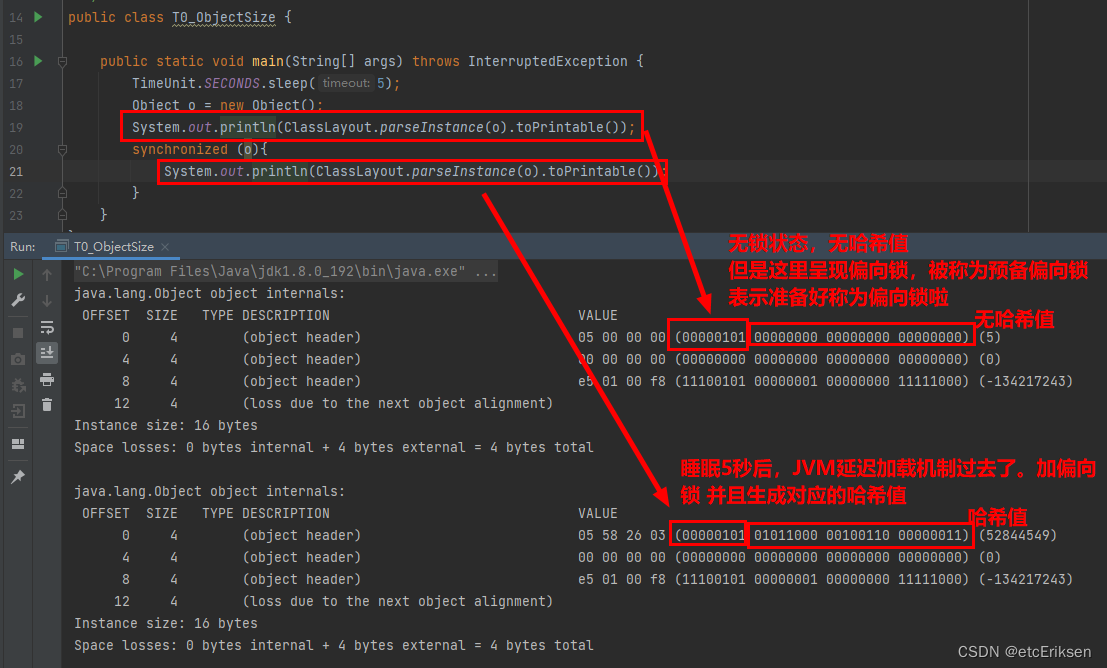
JVM内置锁synchronized关键字详解
目录 JVM内置锁synchronized关键字详解 设计同步器的意义 如何解决线程并发安全问题? synchronized原理详解 synchronized底层原理 synchronized在jdk1.6前后的变化【重点】 jdk小于1.6时 jdk>1.6时 轻量级锁何时升级为重量级锁??…...

【2021.12.25】xv6系统入门学习
【2021.12.28】为xv6系统添加一个开机密码 文章目录【2021.12.28】为xv6系统添加一个开机密码0、说明1、Ubuntu20上安装xv62、测试指令3、修改系统代码4、添加自己的程序命令0、说明 xv6 是 MIT 设计的一个教学型操纵系统。 记录Ubuntu上安装x86版本的xv6系统,为其…...
——crtc分析)
Linux内核4.14版本——drm框架分析(4)——crtc分析
目录 1. struct drm_crtc结构体 2. crtc相关的API 2.1 drm_crtc_init_with_planes 2.5 drm_mode_setcrtc 3. func的一些介绍 3.1 struct drm_crtc_helper_funcs 3.2 struct drm_crtc_funcs 4. 应用层的调用 4.1 drmModeSetCrtc (drmlib库里)---…...

用原生js手写分页功能
分页功能如下: 数据分页显示,每页显示若干条数据,默认当前页码为第一页。例如:每页5条数据,则第一页显示 1-5 条,第二页显示 6-10 条,依此类推。当页码为第一页时,上一页为禁用状态…...

CornerNet介绍
CornerNet: Detecting Objects as Paired Keypoints ECCV 2018 Paper:https://arxiv.org/pdf/1808.01244v2.pdf Code:GitHub - princeton-vl/CornerNet 摘要: 提出了一种single-stage的目标检测算法CornerNet,它把每个目标检…...

【SpringBoot】日志使用
默认配置 Spring Boot默认帮我们配置好了日志 //记录器Logger logger LoggerFactory.getLogger(getClass());Testpublic void contextLoads() {//System.out.println();//日志的级别;//由低到高 trace<debug<info<warn<error//可以调整输出的日志级…...

关于slice扩容性能损耗的探究
背景 如果让我评选最伟大的数据结构,在我心中答案只有两个,数组和哈希表,这两个是我的程序的重要组成部分,同时也是我饭碗的重要组成部分。slice和map简洁明了的API很容易让我们有一种他们提供了无限大的空间,可以…...

Java实现单向链表
✅作者简介:热爱Java后端开发的一名学习者,大家可以跟我一起讨论各种问题喔。 🍎个人主页:Hhzzy99 🍊个人信条:坚持就是胜利! 💞当前专栏:Java数据结构与算法 ǹ…...

3月4日,30秒知全网,精选7个热点
///印度最大供电商罕见于现货市场购煤,能源供应短缺成忧 据知情人士透露,这家印度国有发电公司计划在下周左右发布300万吨的招标 ///QQ音乐推出AIGC黑胶播放器 这是国内音乐行业首个运用AI技术,通过文字、图片指令快速生成不同风格的播放器…...

EXCEL-职业版本(2)
Excel-职业版本(2) 定位 1.如何快速定位到不连续的空值,填充为0 1.在任意空单元格里复制0 2.选中数据区域CtrlA 3.CtrlG 4.选择【定位条件】 5.选择【空值】 6.ctrlV 粘贴 即可 2.怎么一次性计算每个小组的数量 单价和金额的和? 1.选中…...

java中延时队列的实现
大家好,我是一名CRUD工程师,最近我朋友突然来问我如何实现延时队列,我脱口而出就是MQ。不过突然想到公司的项目好像用的是java的一个原生类。于是我就想着趁周末的时间好好的去探究一下各方法实现延时队列的优缺点。 延迟消息 延迟消息就是字…...

基于java的circle buffer的实现
总目录链接==>> AutoSAR入门和实战系列总目录 文章目录 缓冲区示例什么是循环缓冲区?方法 1:使用数组插入元素删除元素方法 2:使用链表插入元素:删除元素:当数据经常从一个地方移动到另一个地方或从一个进程移动到另一个进程或被频繁访问时,它不能存储在永久性内存…...

通用方法——为什么重写equals还要重写hashcode
本文介绍java.lang.Object类中的两个方法:equals和hashCode。这两个方法大家应该都知道,但是这两个方法的作用是什么、为什么重写equals还要重写hashCode、它们之间有什么关系和约定等,今天就来带大家了解一下。 1、hashCode hashCode即散列…...
JavaSE学习进阶day2_01 包和权限修饰符
第一章 包 1.1 包 包在操作系统中其实就是一个文件夹。包是用来分门别类的管理技术,不同的技术类放在不同的包下,方便管理和维护。 在IDEA项目中,建包的操作如下: 这个咱们在基础班就谈到过。 包名的命名规范: 路径…...

Android性能调优 - 省电优化
省电:通过工具Battery Historian查看到:耗电大头: 屏幕、网络、cpuled/oled屏幕显示:降低亮度,开深色模式;锁屏间隔缩短到 ;亮屏需要一直持有唤醒锁,还有gps定位也需要用到唤醒锁;网络: 常用的网络优化措施…...

为什么选择Clasp?10个理由让你彻底爱上本地开发Apps Script [特殊字符]
为什么选择Clasp?10个理由让你彻底爱上本地开发Apps Script 🚀 【免费下载链接】clasp 🔗 Command Line Apps Script Projects 项目地址: https://gitcode.com/gh_mirrors/clasp/clasp Clasp(Command Line Apps Script Pro…...

终极AI图像分层指南:3分钟将复杂插画变成可编辑PSD图层
终极AI图像分层指南:3分钟将复杂插画变成可编辑PSD图层 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾面对一幅精美的数字插画&…...

新手零基础入门:借助快马AI生成带注释的微信小程序示例代码
作为一个刚接触微信小程序开发的新手,我最近在InsCode(快马)平台上尝试了一个特别适合零基础学习的实践项目。这个平台最让我惊喜的是,只需要用自然语言描述需求,就能快速生成带详细注释的完整代码,这对理解小程序开发流程帮助很大…...

DeepAnalyze数据结构优化:提升大规模数据处理性能
DeepAnalyze数据结构优化:提升大规模数据处理性能 1. 引言 当你面对几十GB甚至TB级别的数据集时,是不是经常遇到处理速度慢、内存占用高的问题?DeepAnalyze作为一款强大的AI数据分析工具,在处理大规模数据时,数据结构…...

CloudFlare R2的S3兼容性有多香?一个PicGo插件搞定七牛云、阿里云OSS无缝迁移
CloudFlare R2的S3兼容性实战:用PicGo实现多平台图床无缝迁移 当七牛云突然调整存储计费策略时,我服务器上3000多张技术文档配图每月产生了近200元的额外成本。而迁移到阿里云OSS后,又遇到了国内备案的繁琐流程。直到发现CloudFlare R2的S3兼…...

低显存福音:实测Neeshck轻量化工具,16G显卡流畅跑Z-Image模型
低显存福音:实测Neeshck轻量化工具,16G显卡流畅跑Z-Image模型 1. 轻量化方案的诞生背景 1.1 大模型与小显存的矛盾 Z-Image作为国产文生图模型的代表,其强大的生成能力有目共睹。但原生部署对显存的高要求(通常需要20GB以上&am…...

家长选择赶考状元AI学伴的五大理由:解锁学习新体验与核心好处
在AI技术蓬勃发展的今天,教育领域正经历一场深刻的变革。赶考状元AI学伴作为创新教育模式的代表,为孩子们带来了前所未有的学习新体验。越来越多的家长开始关注并选择这一系统,其背后的理由和好处值得深入探讨。本文将从行业角度,…...

开源工具本地化实践:FigmaCN插件让设计协作更高效
开源工具本地化实践:FigmaCN插件让设计协作更高效 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 在全球化协作与本地化需求日益增长的今天,开源工具本地化已成为…...

MIL图像库实战:从采集卡配置到Qt应用开发
1. 工业视觉项目开发全流程解析 第一次接触MIL图像库时,我被它强大的硬件抽象能力震撼到了。这个由Matrox开发的图像处理库,就像一位经验丰富的翻译官,把不同品牌采集卡的硬件差异统统屏蔽掉。想象一下,你手里有Basler、AVT、Dals…...

DirectX兼容性修复工具:让老游戏在现代Windows系统重获新生
DirectX兼容性修复工具:让老游戏在现代Windows系统重获新生 【免费下载链接】dxwrapper Fixes compatibility issues with older games running on Windows 10 by wrapping DirectX dlls. Also allows loading custom libraries with the file extension .asi into …...