关于slice扩容性能损耗的探究
背景
如果让我评选最伟大的数据结构,在我心中答案只有两个,数组和哈希表,这两个是我的程序的重要组成部分,同时也是我饭碗的重要组成部分。slice和map简洁明了的API很容易让我们有一种他们提供了无限大的空间,可以容纳无限多的数据。然而,我们内心都有一面明镜,知道他们这些岁月静好的背后是通过扩容操作替我们负重前行。在nutsdb有slice和map来构建关键的数据结构或者处理数据,为了探究slice和map的使用对性能有没有影响,有多大影响,由此评估需不需要对这两个数据结构的使用方式进行优化。于是对slice和map扩容对性能的影响这个问题做了一些探究。总结出了一些文章。这是这个系列的第一篇文章。对slice扩容对性能的影响的研究。分享给大家。
1. Slice扩容对性能的影响
Slice是Go提供给我们的数据结构,基本上也是我们开发中最常用的数据结构了,在开发中使用过程一般是下面这样:
func TestSliceBaseUsage(t *testing.T) {var slice []intslice = append(slice, 1, 2, 3)
}func TestSizedSliceBaseUsage(t *testing.T) {slice := make([]int, 10)slice = append(slice, 1, 2, 3)
}
第一种用法就是不指定切片的容量,用到哪里是哪里,第二种就是指定了容量,先申请一片空间,等用到了一定程度再继续扩容。那么他们两个之间到底有怎样的差异呢?我们来看看下面这段Benchmark测试。
func BenchmarkSlickGrow(b *testing.B) {// 要测试的切片长度var lengths = []int{1000, 10 * 1000, 100 * 1000, 1000 * 1000}for _, length := range lengths {// 直接申请空间的切片 性能测试nameOfNotGrowBM := fmt.Sprintf("test_slice_not_grow_%d", length)b.Run(nameOfNotGrowBM, func(b *testing.B) {b.ReportAllocs()b.StartTimer()for i := 0; i < b.N; i++ {value := 1slice := make([]int, length)for i := 0; i < length; i++ {slice = append(slice, value)}}})// 从一开始就不申请空间,一路append的切片 性能测试nameOfGrowBM := fmt.Sprintf("test_slice_grow_%d", length)b.Run(nameOfGrowBM, func(b *testing.B) {b.ReportAllocs()b.StartTimer()for i := 0; i < b.N; i++ {value := 1var slice []intfor i := 0; i < length; i++ {slice = append(slice, value)}}})}
}这个benchmark测试了从长度数量级为一千到一百万的切片,直接申请空间然后逐渐添加元素和不申请空间通过append添加元素这两种操作之间的性能对比。我们跑一下这个代码来看看结果:
goos: darwin
goarch: arm64
pkg: go-learn/go
BenchmarkSlickGrow
BenchmarkSlickGrow/test_slice_not_grow_1000
BenchmarkSlickGrow/test_slice_not_grow_1000-10 242797 4759 ns/op 38912 B/op 3 allocs/op
BenchmarkSlickGrow/test_slice_grow_1000
BenchmarkSlickGrow/test_slice_grow_1000-10 304522 3619 ns/op 25208 B/op 12 allocs/op
BenchmarkSlickGrow/test_slice_not_grow_10000
BenchmarkSlickGrow/test_slice_not_grow_10000-10 16395 71704 ns/op 507905 B/op 4 allocs/op
BenchmarkSlickGrow/test_slice_grow_10000
BenchmarkSlickGrow/test_slice_grow_10000-10 22346 52807 ns/op 357626 B/op 19 allocs/op
BenchmarkSlickGrow/test_slice_not_grow_100000
BenchmarkSlickGrow/test_slice_not_grow_100000-10 1620 729987 ns/op 6635538 B/op 5 allocs/op
BenchmarkSlickGrow/test_slice_grow_100000
BenchmarkSlickGrow/test_slice_grow_100000-10 2632 468636 ns/op 4101390 B/op 28 allocs/op
BenchmarkSlickGrow/test_slice_not_grow_1000000
BenchmarkSlickGrow/test_slice_not_grow_1000000-10 308 3843628 ns/op 65708071 B/op 5 allocs/op
BenchmarkSlickGrow/test_slice_grow_1000000
BenchmarkSlickGrow/test_slice_grow_1000000-10 360 3247562 ns/op 41678130 B/op 38 allocs/op
PASS
从测试结果来看,不扩容的测试组性能上,内存上,比起扩容的测试组,领先优势起码拉开了一个身位。
- 1000这个档位,速度上不扩容比扩容快约30%, 内存上不扩容比扩容省50%
- 10,000这个档位,速度上不扩容比扩容快约36%, 内存上不扩容比扩容省42%
- 100,000这个档位,速度上不扩容比扩容快约18%, 内存上不扩容比扩容省20%
为什么会造成这个样子的结果呢?让我们来看看slice的扩容原理。
func growslice(et *_type, old slice, cap int) slice {newcap := old.capdoublecap := newcap + newcapif cap > doublecap {newcap = cap} else {const threshold = 256if old.cap < threshold {newcap = doublecap} else {// Check 0 < newcap to detect overflow// and prevent an infinite loop.for 0 < newcap && newcap < cap {// Transition from growing 2x for small slices// to growing 1.25x for large slices. This formula// gives a smooth-ish transition between the two.newcap += (newcap + 3*threshold) / 4}// Set newcap to the requested cap when// the newcap calculation overflowed.if newcap <= 0 {newcap = cap}}}}
这个是go1.8的growslice函数,这里面实现的slice扩容原理是这样的,在容量小于256的时候,执行成本扩容,在容量大于256的时候,将执行1.25倍的扩容。另外扩容的时候会申请一片长度为扩容后的容量的内存把数据都搬迁过去,迁移之后原来的内存就无用了,会一直在内存中飘荡等待GC的回收。
总结
所以在我们在使用slice处理数据的时候要留意一下他的扩容问题。乍看下来还是有一定影响的。在数据量大的情况下,如果要优化内存和执行速度,是可以考虑对slice进行一定的优化的,比如:
- 如果已经知道了要处理的数据量,可以直接申请足够大的空间来处理。
- 如果不知道数据量,可以把处理流程改成将数据一个个进行处理。
相关文章:

关于slice扩容性能损耗的探究
背景 如果让我评选最伟大的数据结构,在我心中答案只有两个,数组和哈希表,这两个是我的程序的重要组成部分,同时也是我饭碗的重要组成部分。slice和map简洁明了的API很容易让我们有一种他们提供了无限大的空间,可以…...

Java实现单向链表
✅作者简介:热爱Java后端开发的一名学习者,大家可以跟我一起讨论各种问题喔。 🍎个人主页:Hhzzy99 🍊个人信条:坚持就是胜利! 💞当前专栏:Java数据结构与算法 ǹ…...

3月4日,30秒知全网,精选7个热点
///印度最大供电商罕见于现货市场购煤,能源供应短缺成忧 据知情人士透露,这家印度国有发电公司计划在下周左右发布300万吨的招标 ///QQ音乐推出AIGC黑胶播放器 这是国内音乐行业首个运用AI技术,通过文字、图片指令快速生成不同风格的播放器…...

EXCEL-职业版本(2)
Excel-职业版本(2) 定位 1.如何快速定位到不连续的空值,填充为0 1.在任意空单元格里复制0 2.选中数据区域CtrlA 3.CtrlG 4.选择【定位条件】 5.选择【空值】 6.ctrlV 粘贴 即可 2.怎么一次性计算每个小组的数量 单价和金额的和? 1.选中…...

java中延时队列的实现
大家好,我是一名CRUD工程师,最近我朋友突然来问我如何实现延时队列,我脱口而出就是MQ。不过突然想到公司的项目好像用的是java的一个原生类。于是我就想着趁周末的时间好好的去探究一下各方法实现延时队列的优缺点。 延迟消息 延迟消息就是字…...

基于java的circle buffer的实现
总目录链接==>> AutoSAR入门和实战系列总目录 文章目录 缓冲区示例什么是循环缓冲区?方法 1:使用数组插入元素删除元素方法 2:使用链表插入元素:删除元素:当数据经常从一个地方移动到另一个地方或从一个进程移动到另一个进程或被频繁访问时,它不能存储在永久性内存…...

通用方法——为什么重写equals还要重写hashcode
本文介绍java.lang.Object类中的两个方法:equals和hashCode。这两个方法大家应该都知道,但是这两个方法的作用是什么、为什么重写equals还要重写hashCode、它们之间有什么关系和约定等,今天就来带大家了解一下。 1、hashCode hashCode即散列…...
JavaSE学习进阶day2_01 包和权限修饰符
第一章 包 1.1 包 包在操作系统中其实就是一个文件夹。包是用来分门别类的管理技术,不同的技术类放在不同的包下,方便管理和维护。 在IDEA项目中,建包的操作如下: 这个咱们在基础班就谈到过。 包名的命名规范: 路径…...

Android性能调优 - 省电优化
省电:通过工具Battery Historian查看到:耗电大头: 屏幕、网络、cpuled/oled屏幕显示:降低亮度,开深色模式;锁屏间隔缩短到 ;亮屏需要一直持有唤醒锁,还有gps定位也需要用到唤醒锁;网络: 常用的网络优化措施…...

ElasticSearch - SpringBoot整合ES之全文搜索匹配查询 match
文章目录1. 数据准备2. match 匹配查询1. 全文检索2. 简化查询DSL语句3. match 匹配查询原理官方文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/index.html权威指南:https://www.elastic.co/guide/cn/elasticsearch/guide/current/…...

句子的改写和扩写
目录 1.句子改写 2.句子扩写 (不低于15个句子算是长句子,不能太多长句子) 1.句子改写 我绝不会嫁给你的。 如果你是世界上最后一个男人,我就去寺庙。 If you married me,I would jump into the well. 如果你嫁给我,我…...
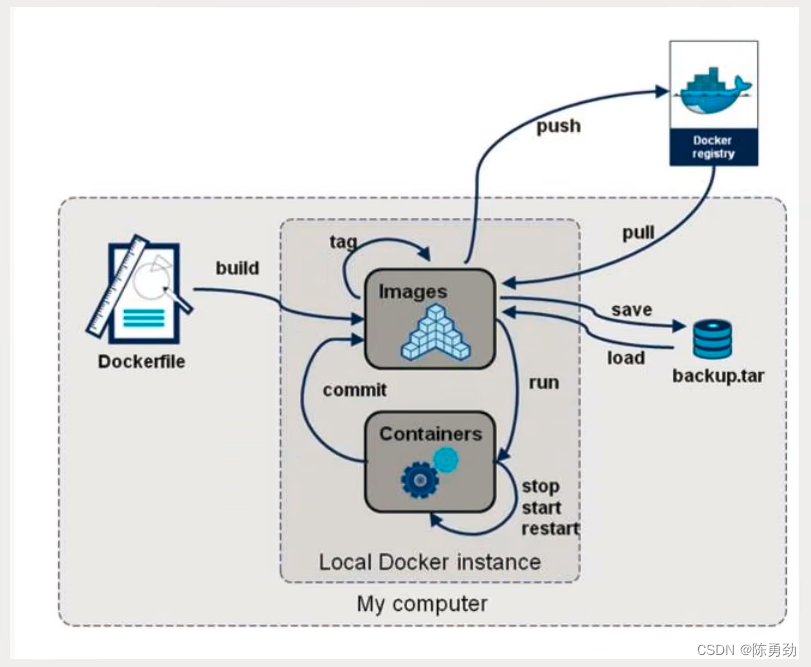
DockerFile创建及案例
DockerFile dockerfile是用来构建docker镜像的文件,命令脚本参数脚本! 构建步骤 编写一个dockerfile文件docker build 构建成为一个对象docker run 运行镜像docker push 发布镜像(DockerHub、阿里云镜像仓库) 去官网Docker-Hub…...

第十四届蓝桥杯三月真题刷题训练——第 1 天
目录 题目1:数列求值 代码: 题目2:质数 代码: 题目3:饮料换购 代码: 题目1:数列求值 题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出…...

基于容器云提交spark job任务
容器云提交spark job任务 容器云提交KindJob类型的spark任务,首先需要申请具有Job任务提交权限的rbac,然后编写对应的yaml文件,通过spark内置的spark-submit命令,提交用户程序(jar包)到集群执行。 1、创建任务job提交权限rbac …...

Linux系统调用之目录操作函数
前言 如果,想要深入的学习Linux系统调用中mkdir,rmdir,rename,chdir,getcwd等这些有关于目录操作函数,还是需要去自己阅读Linux系统中的帮助文档。 具体输入命令: man 2 mkdir/rmdir/rename/ch…...

设计模式-策略模式
前言 作为一名合格的前端开发工程师,全面的掌握面向对象的设计思想非常重要,而“设计模式”是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的,代表了面向对象设计思想的最佳实践。正如《HeadFirst设计模式》中说的一句话&…...

面试+算法:罗马数字及Excel列名与数字互相转换
概述 算法是一个程序员的核心竞争力,也是面试最重要的考查环节。 试题 判断一个罗马数字是否有效 罗马数字包含七种字符:I,V,X,L,C,D和M,如下 字符数值I1V5X10L50C100D500M1000…...
)
Connext DDS路由服务Routing Service(1)
1 简介 RTI路由服务是一种开箱即用的解决方案,允许开发人员快速扩展和集成不同或地理位置分散的实时系统。它跨域、LAN和WAN扩展RTI ConnextDDS应用程序,包括防火墙和NAT穿越。 它还支持DDS到DDS的桥接,允许您对数据进行转换。这允许未修改的DDS应用程序进行通信,即使它们是…...
如何使用SaleSmartly进行Facebook Messenger 营销、销售和支持
如何使用SaleSmartly(ss客服)进行Facebook Messenger 营销、销售和支持上篇文章我们讲了什么是Facebook Messenger CRM以及获得Facebook Messenger CRM的注意事项,现在你有更多时间与客户聊天,让我们看看你如何使用SaleSmartly&am…...

教资教育知识与能力中学教学
目录 3.1 教学概述 3.2 教学过程 3.3 教学原则*【简答/辨析重点】 3.4 教学方法 3.5 教学组织形式 3.6 教学工作基本环节 3.7 教学评价 3.1 教学概述 1、教学的意义【14/18辨析】 教学是传授系统知识、促进学生发展的最有效形式; 教学是学校进行全面发展教…...

Nunchaku FLUX.1-dev效果展示:4步生成惊艳图片案例分享
Nunchaku FLUX.1-dev效果展示:4步生成惊艳图片案例分享 你是否曾经被AI生成图片的漫长等待时间所困扰?传统文生图模型往往需要20步以上的推理才能获得理想效果,而今天我要展示的Nunchaku FLUX.1-dev模型,仅需4步就能生成令人惊艳…...

5分钟掌握gInk:让屏幕标注如同纸上书写的终极指南
5分钟掌握gInk:让屏幕标注如同纸上书写的终极指南 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk 你是否曾在远程会议中,试图在共享屏幕上圈出重…...

告别重复训练!用InverseSR和潜在扩散模型搞定不同医院的三维脑MRI超分难题
医学影像超分辨率革命:InverseSR与潜在扩散模型的跨中心应用实践 在医学影像分析领域,高分辨率脑部MRI数据对疾病诊断和治疗规划至关重要。然而现实情况是,不同医疗机构的扫描设备、协议和参数存在显著差异,导致获取的影像质量参…...

构建稳定爬虫服务:基于快马ai生成openclaw的windows生产级部署实战
构建稳定爬虫服务:基于快马AI生成OpenClaw的Windows生产级部署实战 最近在做一个数据采集项目,需要将OpenClaw爬虫部署到Windows服务器上长期运行。经过一番折腾,终于通过InsCode(快马)平台生成了一个完整的生产级部署方案,这里分…...
)
华为OD机考双机位C卷 - 数字游戏 (Java)
# 数字游戏 2026华为OD机试双机位C卷 - 华为OD上机考试双机位C卷 华为OD机试双机位C卷真题目录(Java)点击查看: 【全网首发】2026华为OD机位C卷 机考真题题库含考点说明以及在线OJ(Java题解) 题目描述 小明玩一个游戏。 系统发1+n张牌,每张牌上有一个整数。 第一张给…...

5分钟打造个人游戏库:FitGirl Repack Launcher高效管理方案
5分钟打造个人游戏库:FitGirl Repack Launcher高效管理方案 【免费下载链接】Fitgirl-Repack-Launcher An Electron launcher designed specifically for FitGirl Repacks, utilizing pure vanilla JavaScript, HTML, and CSS for optimal performance and customiz…...

Win11Debloat深度优化指南:系统效能倍增的底层逻辑与实施路径
Win11Debloat深度优化指南:系统效能倍增的底层逻辑与实施路径 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter…...

Kandinsky-5.0-I2V-Lite-5s企业级部署案例:客服知识库配图→动态教学短视频生成
Kandinsky-5.0-I2V-Lite-5s企业级部署案例:客服知识库配图→动态教学短视频生成 1. 项目背景与需求分析 在客服培训领域,传统的知识库配图往往是静态图片,难以直观展示操作流程和动态场景。某大型电商平台客服团队面临以下痛点:…...

intv_ai_mk11用于IT运维文档:错误日志分析、解决方案生成与报告撰写
intv_ai_mk11用于IT运维文档:错误日志分析、解决方案生成与报告撰写 1. 为什么IT运维需要AI助手 每天处理海量错误日志、编写故障报告、寻找解决方案是IT运维人员的日常工作痛点。传统方式下,工程师需要: 手动筛选关键错误信息在知识库中反…...
)
从移动平均到IIR滤波:用Matlab filter函数实现数据降噪的完整指南(附对比实验)
从移动平均到IIR滤波:用Matlab filter函数实现数据降噪的完整指南(附对比实验) 在数据分析与信号处理领域,噪声污染是影响结果准确性的常见挑战。无论是来自传感器的物理干扰,还是数据传输过程中的随机波动,…...