从CNN ,LSTM 到Transformer的综述
前情提要:文本大量参照了以下的博客,本文创作的初衷是为了分享博主自己的学习和理解。对于刚开始接触NLP的同学来说,可以结合唐宇迪老师的B站视频【【NLP精华版教程】强推!不愧是的最完整的NLP教程和学习路线图从原理构成开始学,学完可实战!-哔哩哔哩】 https://b23.tv/WwVQnKr和【【唐博士带你学AI】NLP最著名的语言模型-BERT 10小时精讲,原理+源码+论文,计算机博士带你打通NLP-哔哩哔哩】 https://b23.tv/0ZtLcoj这两个视频使用Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT-CSDN博客
本文的大纲是:
目录
第一部分 单词向量化
1.1 word embedding
1.1.1 理解什么是one-hot representation
1.1.2 理解什么是distribution representation
1.1.2.1我们现在提出一个比one-hot更高级的文本向量化要求:
我们来比较一下词袋模型(bag of wordsmodel)和词嵌⼊模型(word embedding model)的区别:
1.1.2.2 如何用distribution representation把单词变成一个跟单词上下文有关,有语义的向量呢?
第二部分 从Seq2Seq序列引入Encoder-Decoder模型:RNN/LSTM与GRU
2.1 什么是Seq2Seq序列问题:输入一个序列 输出一个序列
2.2 介绍Encoder-Decoder模型:RNN/LSTM与GRU
2.3 开始介绍注意力机制(Attention)
第三部分 transformer
3.1自注意力部分:
3.1.1 先来认识一下三个向量
3.1.2 attention整体流程
第三、四步:分数除以8然后softmax
3.2 多头注意力机制“multi-headed” attention
3.2.1 定义
3.2.2过程介绍
第一部分 单词向量化
1.1 word embedding
单词向量化是本节任务的一个基础,因为我们不可能直接把人类的单词文本直接输入到模型中去吧,我们要转换成计算机能够看懂的语言形式。所以,单词向量化,顾名思义,就是把单词转化成向量的形式表示,在论文中我们经常看到一个单词(embedding),用词典翻译它就是“嵌入“,我们会感到一头雾水。我们其实可以理解为:embedding就是一个映射,将单词从原先所属空间映射(嵌入)到新的多维空间(变成向量)。
在自然语言处理任务中,有两种单词向量化的方法:
·onehot representation(独热形式)
·distribution representation(分配形式)
1.1.1 理解什么是one-hot representation
我们直接用下面的例子简单最粗暴的理解:从形式上看,每个向量之间的内积为0,也就是每个向量是互相正交的,除了当前单词位置的值为1之外,其余位置的值都为0,。
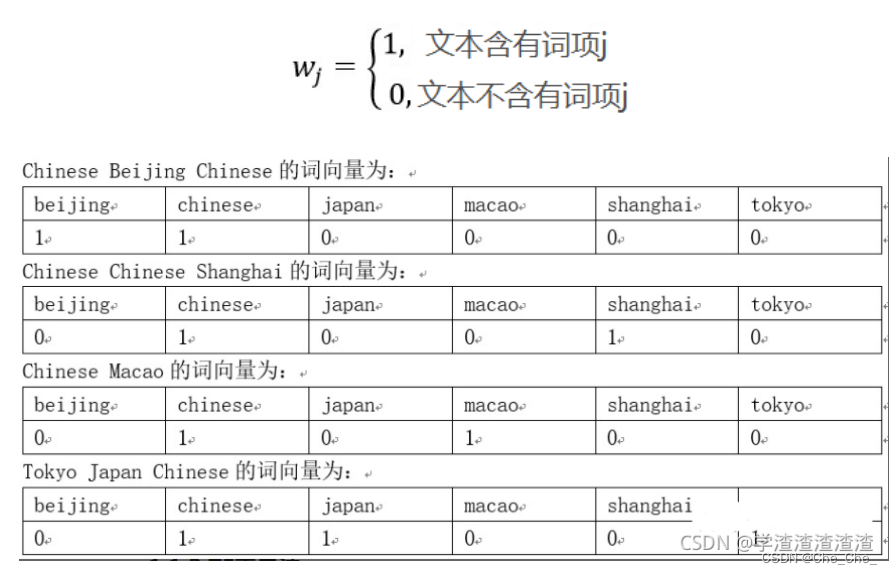
假设⽤ one-hot对句⼦进⾏表示,对句⼦分词之后,我们可以得到['我‘ , ’爱‘ , ’北京‘ , ’天安⻔‘],可以⽤one hot(独热编码)对单词进⾏编码。具体为:
“我”可以表示为[1,0,0,0]
"爱"可以表示为[0,1,0,0]
'北京'可以表示为[0,0,1,0]
'天安⻔'可以表示为[0,0,0,1]
缺点:这样单词编码之间互相正交的形式,使得的向量之间(单词)之间没有语义上的联系。
1.1.2 理解什么是distribution representation
这一节可以看唐宇迪的视频来理解:【【word2vec词向量模型】原理详解+代码实现,迪哥竟然把NLP最热门的词向量模型讲解的如此通俗易懂!-哔哩哔哩】 https://b23.tv/YJ6OMVX
不同于 one-hot粗暴的用1和0来编码,distribution representation克服了 one-hot的缺点:单词)之间没有语义上的联系。
分布式表示(distribution representation)将词转化为⼀个定⻓向量(可指定)、稠密并且互相存在语义关系(语义蕴藏在了向量的这些数字里面)的向量。
对比一下理解什么叫“蕴藏在了向量的这些数字”:
one-hot:[1,0,0,0]
distribution:[0.3,0.2,0.1,0.5] #是不是很长的像一个加权占比
1.1.2.1我们现在提出一个比one-hot更高级的文本向量化要求:
(本质上是因为distribution representation在向量化的过程中,要利用当前单词的上下文来训练模型,所以上下文语义自然蕴含在训练好的单词向量的每一维度的数值中 eg:[0.3,0.2,0.1,0.5]。
1.这个单词向量化模型要考虑单词出现的顺序:假设文本顺序为my name is chenfangyi ,出来的单词向量化中name 单词的编码(假设是[0.3,0.2,0.1,0.5])必须得体现出文本的顺序,比如只能先有name,再有is 和chenfangyi 吧,这样才符合我们人类的思维。
2.这个单词向量化模型词与词之间的等价关系要考虑到
eg:"nlp”单词要和“自然语言处理”映射到同一个向量空间,且语义相近的词在空间中离得要近。

这里插入一个跟本文主线不相关的概念:
我们来比较一下词袋模型(bag of wordsmodel)和词嵌⼊模型(word embedding model)的区别:
词袋模型是对整个文档的向量化,反映的是整个文档的单词,而本文提到的词嵌⼊模型是针对单个单词向量化,只不过在某些方法中单词的向量化与它的上下文也有关联。
1 词袋模型和编码⽅法
1.1 ⽂本向量化
⽂本向量化就是指⽤数值向量来表示⽂本的语义,即,把⼈类可读的⽂本转化成机器可读形式。
如何转化成机器可读的形式?这⾥⽤到了信息检索领域的词袋模型,词袋模型在部分保留⽂本语义的前提下对⽂本进⾏向量化表示。在后面的信息抽取博客打下基础
1.2 词袋及编码⽅法
我们先来看2个例句:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
将所有词语装进⼀个袋⼦⾥,不考虑其词法和语序的问题,即每个词语都
是独⽴的。例如上⾯2个例句,就可以构成⼀个词袋,袋⼦⾥包括Jane、
wants、to、go、Shenzhen、Bob、Shanghai。假设建⽴⼀个数组(或词
典)⽤于映射匹配:
[Jane, wants, to, go, Shenzhen, Bob, Shanghai]
那么上⾯两个例句就可以⽤以下两个向量表示,对应的下标与映射数组的
下标相匹配,其值为该词语出现的次数:
# 词典的key值:[Jane, wants, to, go, Shenzhen, Bob, Shanghai]
1 [1,1,2,1,1,0,0]
2 [0,1,2,1,0,1,1]
词频向量就是词袋模型,可以很明显的看到语序关系已经完全丢
失。
1.3 类型介绍
1.3.1 它也可以one-hot编码
对于每⼀个单词,我们观察该词语是否出现,出现就为1,没有出现就
是0,得到⽂本向量,规则如下:
1.3.2 TF 编码1.2例句介绍用的就是这个,TF表示法的数值计算规则为:词语序列中出现的词语其数值为词语在所在⽂本中的频次,词语序列中未出现的词语其数值为0。
1.3.3 TF- IDF表示法
TF-IDF表示法的数值计算规则为:词语序列中出现的词语其数值为词语在
所在⽂本中的频次乘以词语的逆⽂档频率,词语序列中未出现的词语其数
值为0。⽤数学式⼦表达为:

1.1.2.2 如何用distribution representation把单词变成一个跟单词上下文有关,有语义的向量呢?
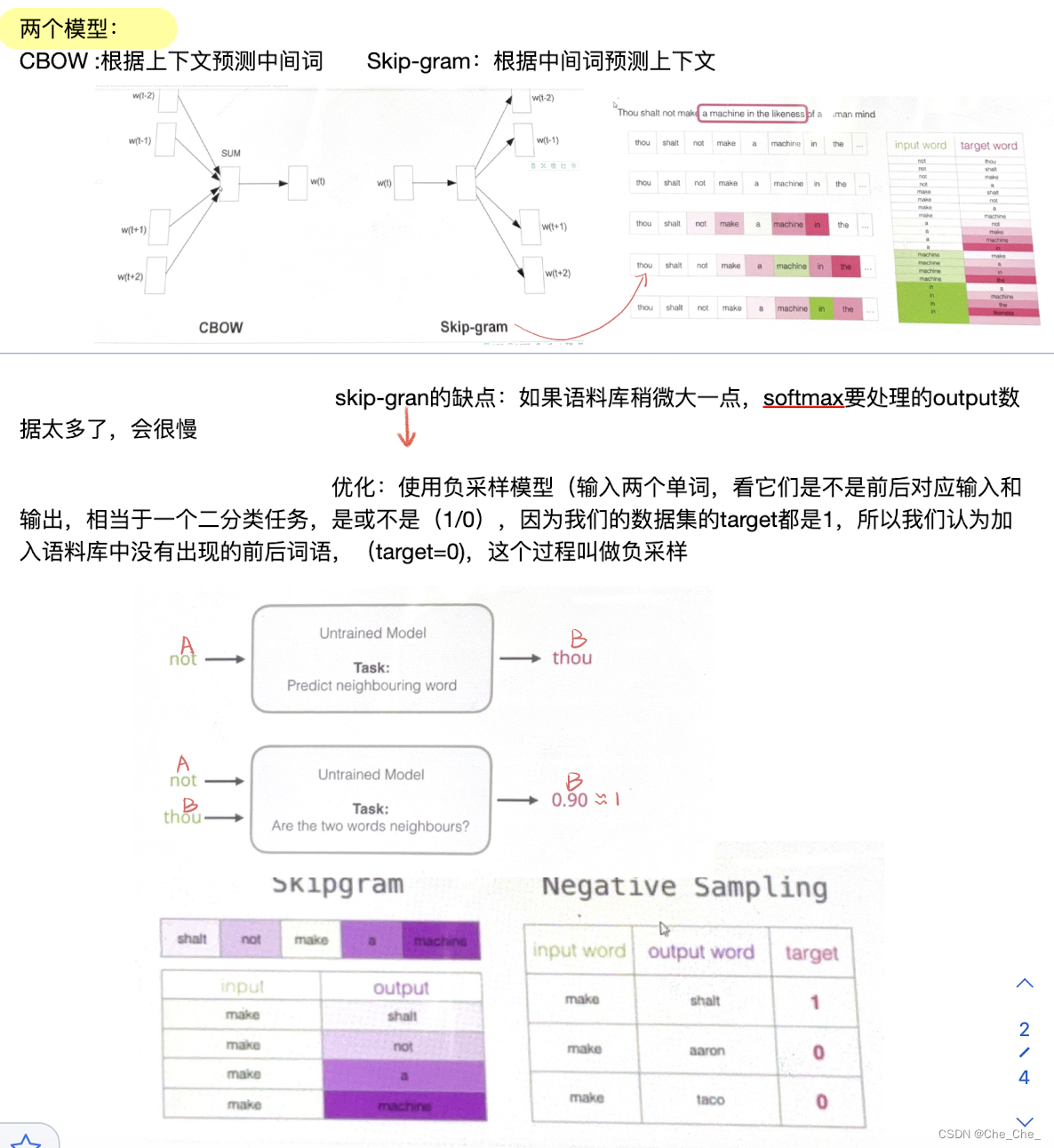
假设我们的句子是A_B_C,对于单词C来说,A B就是它的上下文。我们的模型本质是一个单词预测模型已知AB,预测单词C(分类模型:最终输出的结果是整个单词语料库每个单词预测的概率),那就有疑问了,不是说是一个目的是把单词转化成蕴藏上下文语义的向量化模型吗?怎么叫单词的预测模型了?
因为我们在输入的时候,不可能直接把单词直接输入网路,我们把单词A,B表示成了一个初始化的向量(诶,那我们的任务不就结束了吗,已经单词向量化了呀?)并不是,这个初始化是我们自己定的,我们要利用这个单词预测模型来达到:不断更新单词A和B初始化向量里面的数值。
简而言之,这个单词预测模型只是一个帮手,我们其实不是要最终的输出结果,我们要知道模型每次训练除了更新权重参数,还会更新每次的输入值,我们要的就是,最终,模型训练好之后,输入的词向量里面的向量每一个维度的数值):“A”和“B”会由初始值不断更新(前向训练,反向传播)直到得到的最终的向量 。注:向量 【0.3,0.2,0.1,0.5】里面这4个数据(不一定维度一定是4,只是假设)

模型的输入是:A(假设是shalt并且已经随机向量初始化)和Bthou(假设是shalt并且已经随机向量初始化)蕴藏上下文语义的向量:
eg :
模型的输出就是:在整个语料库中每个词预测正确的概率值

总结起来就是,在这个预测模型中,随着预测单词的结果匹配语料库的概率值越来越接近真实值C,每次训练模型的输入值都会发生变化,最终我们想要的结果是蕴藏上下文语义的输入向量就得到了。
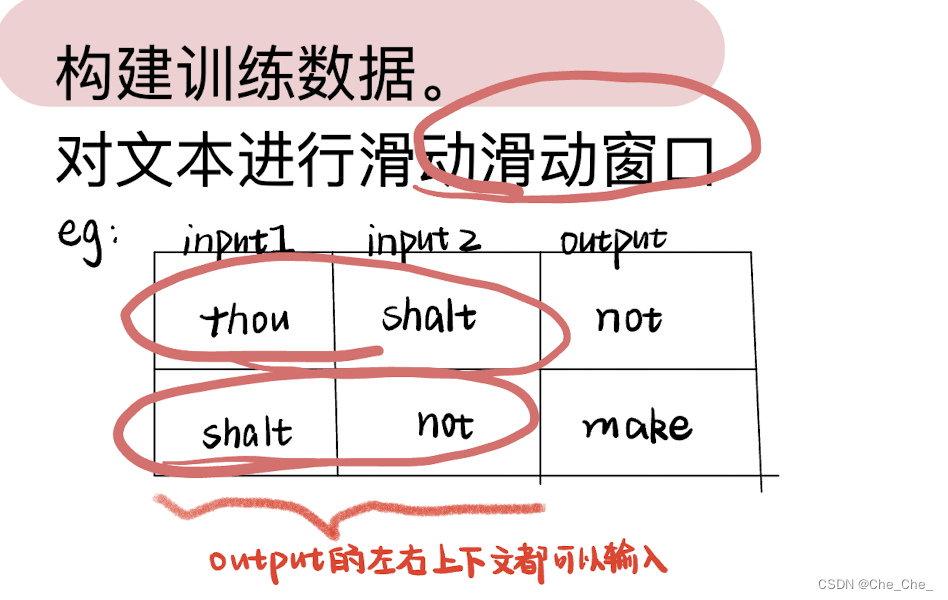
构建训练数据:

第二部分 从Seq2Seq序列引入Encoder-Decoder模型:RNN/LSTM与GRU
2.1 什么是Seq2Seq序列问题:输入一个序列 输出一个序列
比如翻译模型: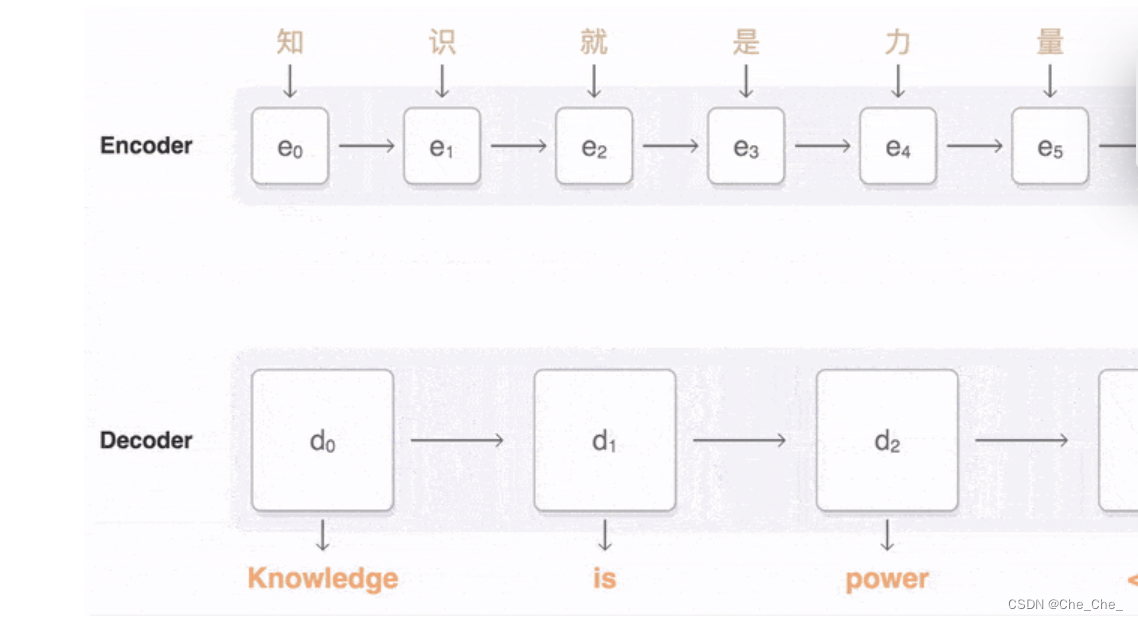
2.2 介绍Encoder-Decoder模型:RNN/LSTM与GRU
这里推荐直接去看这个大佬的博客:如何从RNN起步,一步一步通俗理解LSTM_rnn lstm-CSDN博客
大佬写的超级好,这里就不再赘述了。
2.3 开始介绍注意力机制(Attention)
·对于Seq2Seq without Attention来说:Encoder(编码器)和 Decoder(解码器)之间只有一个「向量C」来传递信息,且C的长度固定。当输入句子比较长时,所有语义完全转换为一个中间语义向量C来表示,单词原始的信息已经消失,可想而知会丢失很多细节信息

而为了解决「信息过长,信息丢失」的问题,Attention 机制就应运而生了。
·对于Seq2Seq with Attention来说:Eecoder 不再将整个输入序列编码为固定长度的「中间向量C」,而是编码成一个向量的序列(包含多个向量)。

Attention 机制:


对于中间语义编码和attention值之间的关系:看这个博主的https://blog.csdn.net/qq_45556665/article/details/127459191这一部分博客
「
「
」
我现在的理解是:经过Encoder,被编码成语义编码C,语义编码是一块高度抽象的内容。Ci 就是第i个单词的attention值,它是一个中间语义编码,解码(Y1 = f1 ( C1 ) ; Y2 = f1 ( C2 ,Y1 ) ; Y3 = f1 (C3 ,Y1,Y2 ))完成后输出序列 {Y1=“汤姆”,Y2=“追逐”,Y3=“杰瑞”}。
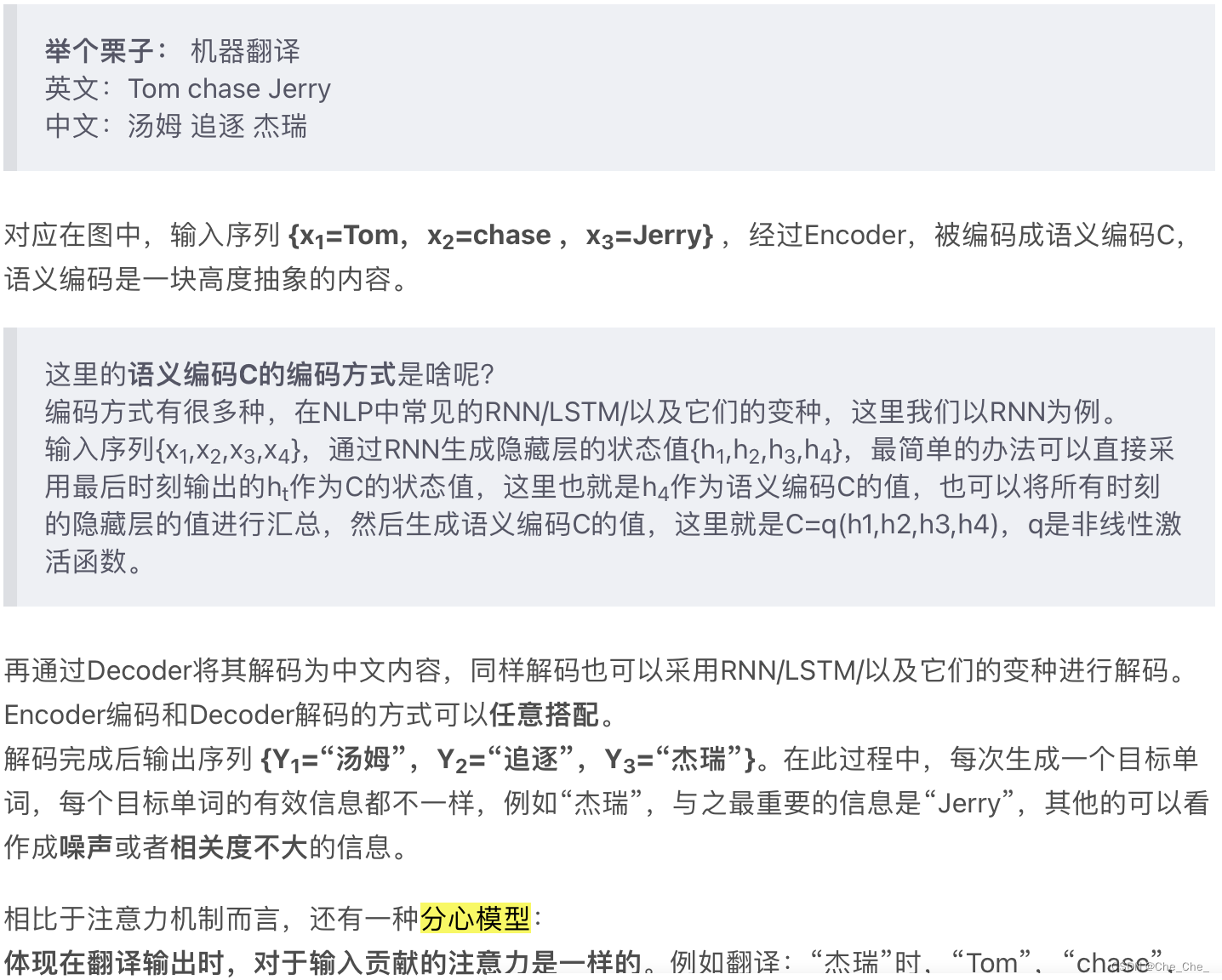

在下面的transformer中,会用到另一种机制 self-attention.
1.注意力机制Attention发生在Target的元素Query和Source中的所有元素之间。
2.而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已。
3.可以粗暴的理解为:self-attention是attention的一种特殊情况
第三部分 transformer
这一部分建议看这个视频:【【唐博士带你学AI】NLP最著名的语言模型-BERT 10小时精讲,原理+源码+论文,计算机博士带你打通NLP-哔哩哔哩】 https://b23.tv/NwnylCo
还是考虑上文中已经出现过的机器翻译的模型(Transformer一开始的提出即是为了更好的解决机器翻译问题)。

3.1自注意力部分:
3.1.1 先来认识一下三个向量
每个单词各自创建一个查询向量、一个键向量和一个值向量

3.1.2 attention整体流程

第一步:生成查询向量、键向量和值向量
第二步:计算得分:要去查询的单词(Query)去点积例子中所有词的键向量key
·q1和k1的点积(根据点积结果可以判断q1和k1这个向量的相似性)
·q1和k2的点积(根据点积结果可以判断q1和k2这个向量的相似性)
第三、四步:分数除以8然后softmax
第五、六步:值向量乘以softmax分数后对加权值向量求和
整体思路会发现,self-attention和attention 几乎一样,区别在于Target?=Source
3.2 多头注意力机制“multi-headed” attention
3.2.1 定义
简单的说就是,多来几对“
”的矩阵集合
3.2.2过程介绍
如果我们做与上述相同的自注意力计算,只需8次不同的权重矩阵运算,我们就会得到8个不同的Z矩阵


前馈层没法一下子接收多个矩阵,它需要一个单一的矩阵(矩阵中每个的行向量对应一个单词,比如矩阵的第一行对应单词Thinking、矩阵的第二行对应单词Machines)
所以我们需要一种方法把这多个矩阵合并成一个矩阵。直接把这些矩阵拼接在一起,然后乘以一个附加的权重矩阵

3.2.3 为什么要用“多头 ”,“1个头”不行吗?
我们在学习计算机视觉的时候,对于线性分类的的权值模版,在不考虑代价的情况的自然是多多益善。这样机器能学到更多的图像特征,图像分类任务会更加精准。
在本文这个任务重,通过不同的head得到不同的特征表达。总有一个头会关注到咱们想关注的点,避免在编码时遗漏了我们想要关注的点。
3.3 Transformer 的编码器和解码器
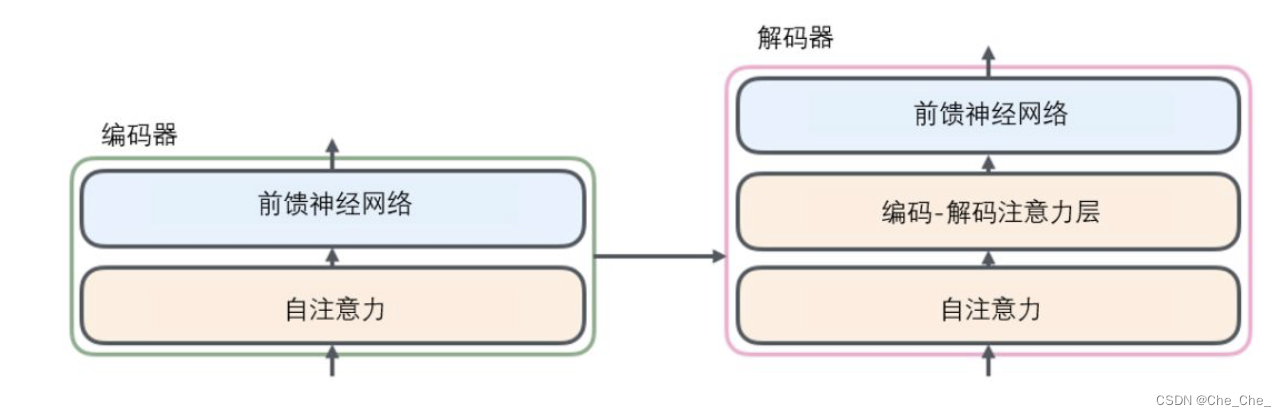
3.3.1 编码器 将源语转化为一个中间语义向量C
1.先经过一个自注意力层(self-attention ):self-attention机制会帮助编码器在对每个单词编码时关注输入句子中的的其他单词。
2.前馈(feed-forward)神经网络
注:可能会有好几层这样的结构
3.3.2 解码器
1 .一个带masked的Multi-Head Attention,本质是Self-Attention :
该自注意力层只允许关注已输出位置的信息,实现方法是在自注意力层的softmax之前进行mask,将未输出位置的权重设置为一个非常大的负数(进一步softmax之后基本变为0,相当于直接屏蔽了未输出位置的信息) 简而言之就是,在翻译第i个单词的时候,不能看到第i个后面翻译的单词
2.一个不带masked的Multi-Head Attention,本质是Encoder-Decoder Attention
这个注意力层的K 和V都来自Encoder最后一层的输出,Q来自于上一个Decoder单元的输出
比如当我们要把“Hello Word”翻译为“你好,世界”时:
在解码并输出 “你好”时,会关注编码器的“Hello ”和“Word”
相关文章:
从CNN ,LSTM 到Transformer的综述
前情提要:文本大量参照了以下的博客,本文创作的初衷是为了分享博主自己的学习和理解。对于刚开始接触NLP的同学来说,可以结合唐宇迪老师的B站视频【【NLP精华版教程】强推!不愧是的最完整的NLP教程和学习路线图从原理构成开始学&a…...

Git学习笔记:1 基础命令详解
文章目录 Git基础命令详解: Git基础命令详解: git commit 用法:git commit -m "commit message"功能:将暂存区(stage)中的所有更改提交到本地仓库的当前分支,同时提供一个简短的提交信…...

【服务器】安装宝塔面板
目录 🌺【前言】 🌼【前提】连接服务器 🌷方式一 使用工具登录服务器如Xshell 🌷方式二 阿里云直接连接 🌼 1. 安装宝塔 🌷获取安装脚本 方式一 使用下面提供的脚本安装 方式二 使用官网提供的脚本…...
)
开源模型应用落地-业务优化篇(一)
一、前言 通过参与“开源模型应用落地-业务整合系列篇”的学习,我们已经成功建立了基本的业务流程。然而,这只是迈出了万里长征的第一步。现在我们要对整个项目进行优化,以提高效率。我们计划利用线程池来加快处理速度,使用redis来实现排队需求,以及通过多级环境来减轻负载…...
【遥感专题系列】影像信息提取之——基于专家知识的决策树分类
可以将多源数据用于影像分类当中,这就是专家知识的决策树分类器,本专题以ENVI中Decision Tree为例来叙述这一分类器。 本专题包括以下内容: 专家知识分类器概述知识(规则)定义ENVI中Decision Tree的使用 概述 基于知…...
lqb日志08
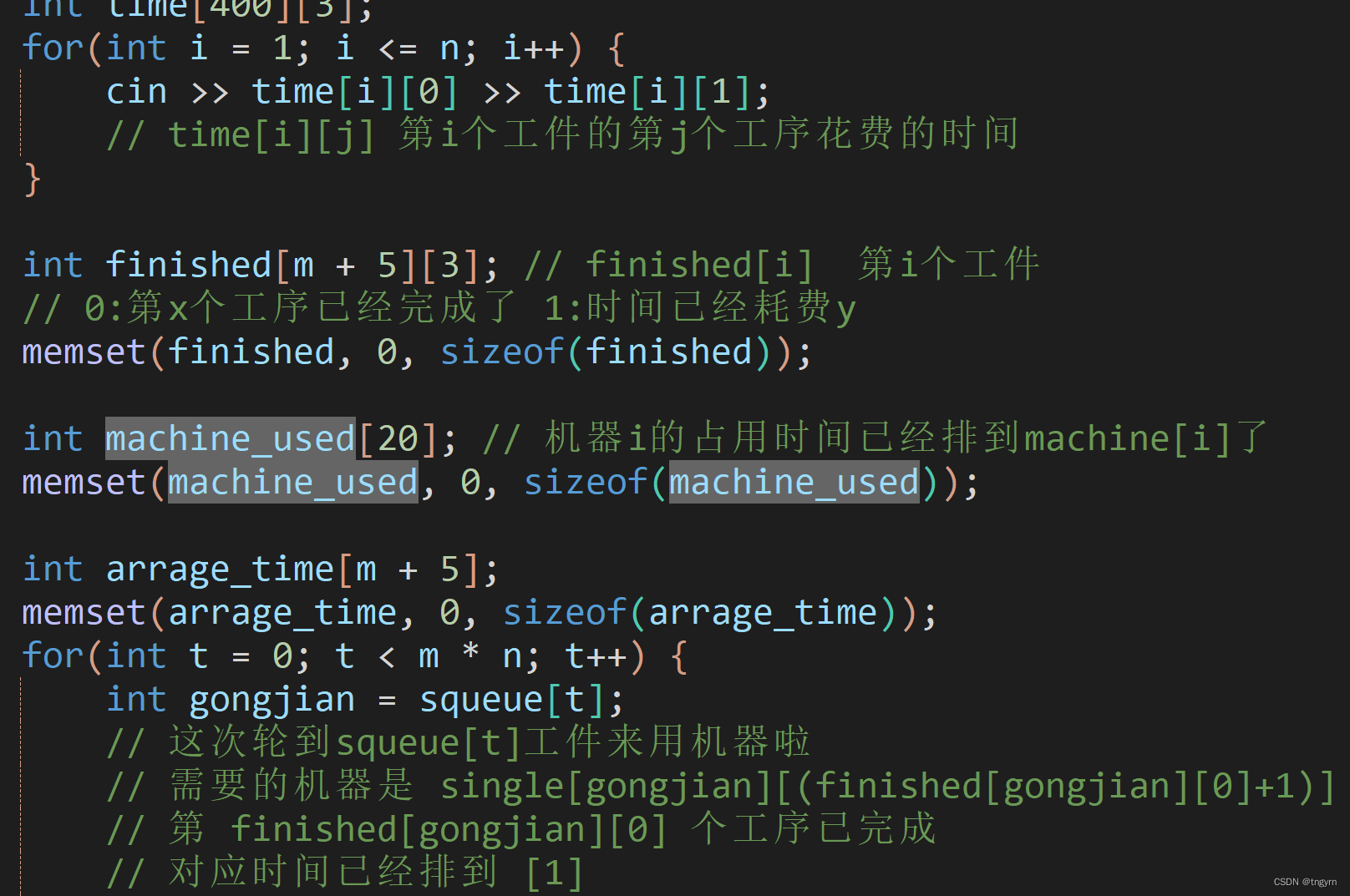
一只小蒟蒻备考蓝桥杯的日志 文章目录 笔记坐标相遇判断工作调度问题(抽象时间轴绘制) 刷题心得小结 笔记 坐标相遇判断 我是小懒虫,碰了一下运气,开了个“恰当”的数(7000)如果,7000次还不能…...
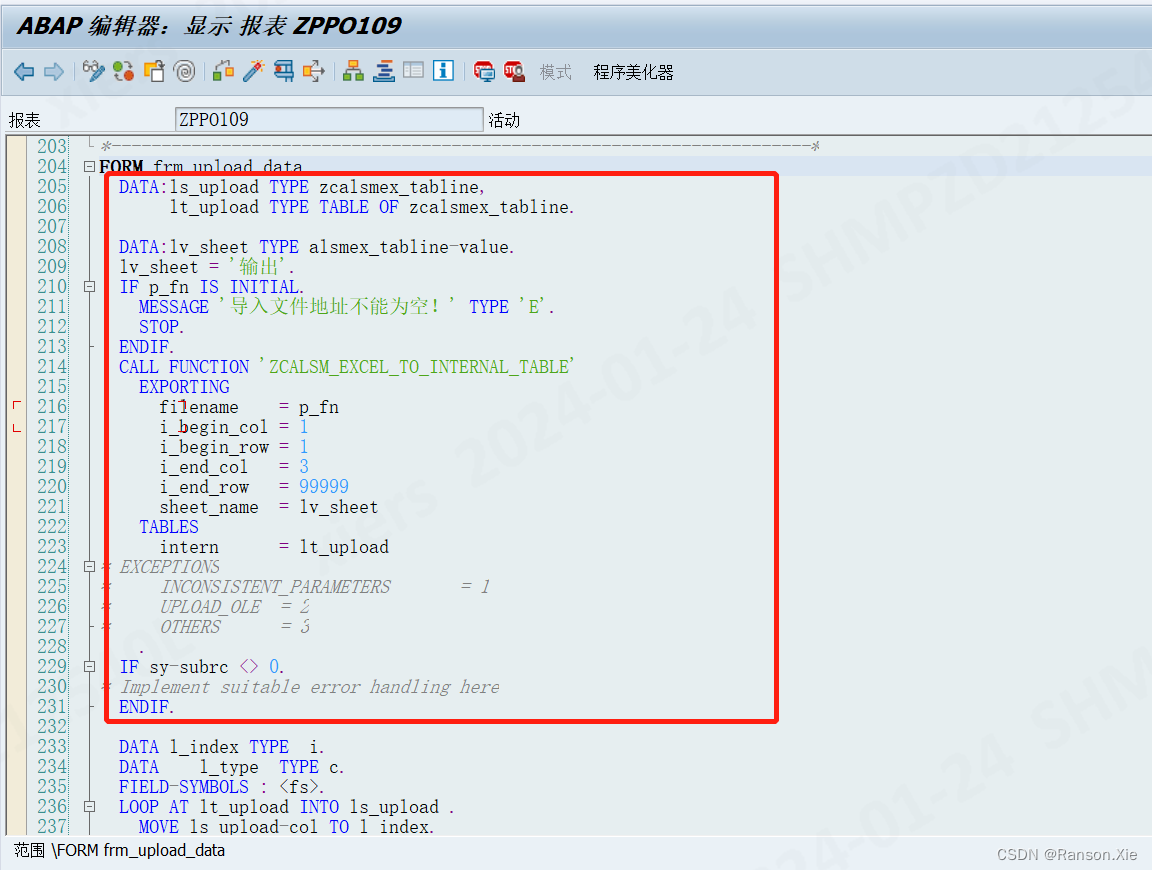
SAP EXCEL上传如何实现指定读取某一个sheet页(ALSM_EXCEL_TO_INTERNAL_TABLE)
如何读取指定的EXCEL sheet 页签,比如要读取下图中第二个输出sheet页签 具体实现方法如下: 拷贝标准的函数ALSM_EXCEL_TO_INTERNAL_TABLE封装成一个自定义函数ZCALSM_EXCEL_TO_INTERNAL_TABLE 在自定义函数导入参数页签新增一个参数SHEET_NAME 在源代码…...
奇怪问题说 - 测试篇
文章目录 1.什么是软件测试2.软件测试和开发的区别3.软件测试的发展:4.软件测试岗位5.软件测试在不同类型公司的定位6.一个优秀的软件测试人员具备的素质6.1综合能力6.2掌握自动化测试技术6.3优秀的测试用例设计能力6.4探索性思维6.5有责任感和一定的压力 7.软件测试…...
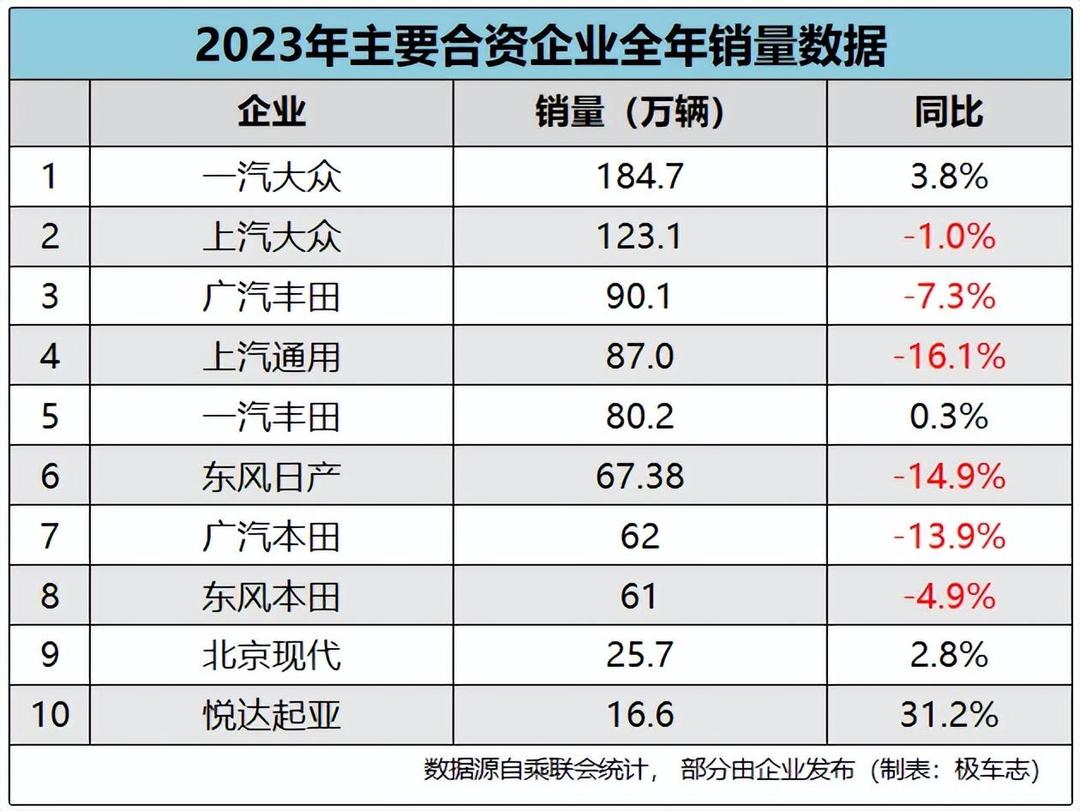
中国新能源汽车持续跑出发展“加速度”,比亚迪迎来向上突破
2023年已经过去,对于汽车圈而言,2023年是中国车市的分水岭,在这一年,中国汽车工业70年以来首次进入全球序列,自主品牌强势霸榜,销量首次超过合资车。要知道,这是自大众于1984年进入中国市场成立…...

chatGPT辅助写硕士毕业论文
一、写作顺序 1.标题、研究问题、研究方法 2.文献综述(占比1/5-1/6) 3.论证章节 4.结论、不足、启示 5.处理图表、参考文献的格式 6.绪论或引言 7.摘要、关键词 8.查重、装订 http://【硕士毕业论文写不下去,多亏听了张博士的论文写…...
搭建nginx图片服务器
(1)将图片存储于/home/data/images目录; (2)配置nginx.conf user nginx; worker_processes 4;error_log /var/log/nginx/error.log notice; pid /var/run/nginx.pid;events {worker_connections 10000; }ht…...

大数据学习之Flink算子、了解DataStream API(基础篇一)
DataStream API (基础篇) 注: 本文只涉及DataStream 原因:随着大数据和流式计算需求的增长,处理实时数据流变得越来越重要。因此,DataStream由于其处理实时数据流的特性和能力,逐渐替代了DataSe…...

js中字符串string,遍历json/Object【匹配url、邮箱、电话,版本号,千位分割,判断回文】
目录 正则 合法的URL 邮箱、电话 字符串方法 千位分割:num.slice(render, len).match(/\d{3}/g).join(,) 版本号比较 判断回文 json/Object 遍历 自身属性 for...inhasOwnProperty(key) Object.获取数组(obj):Object.keys,Object…...
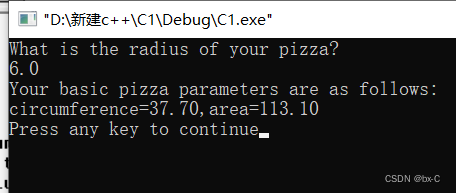
字符串和C预处理器
本文参考C Primer Plus第四章学习 文章目录 常量和预处理器const限定符 1. 常量和预处理器 有时,在程序中要使用常量。例如,可以这样计算圆的周长: circumference 3.14159 * diameter; 这里,常量3.14159 代表著名的常量 pi(π)。…...

Ultraleap 3Di新建项目之给所有的Joint挂载物体
工程文件 Ultraleap 3Di给所有的Joint挂载物体 前期准备 参考上一期文章,进行正确配置 Ultraleap 3Di配置以及在 Unity 中使用 Ultraleap 3Di手部跟踪 新建项目 初始项目如下: 新建Create Empty 将新建的Create Empty,重命名为LeapPro…...

关于session每次请求都会改变的问题
这几天在部署一个前后端分离的项目,使用docker进行部署,在本地测试没有一点问题没有,前脚刚把后端部署到服务器,后脚测试就出现了问题!查看控制台报错提示跨域错误?但是对于静态资源请求,包括登…...

【leetcode题解C++】150.逆波兰表达式求值 and 239.滑动窗口最大值 and 347.前k个高频元素
150.逆波兰表达式求值 给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。 请你计算该表达式。返回一个表示表达式值的整数。 注意: 有效的算符为 、-、* 和 / 。每个操作数(运算对象)都可以是一个整数…...
【计网·湖科大·思科】实验三 总线型以太网的特性、集线器和交换机的区别、交换机的自学习算法
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的很重要&…...

API设计模式:REST、GraphQL、gRPC与tRPC全面解析
一、引言 在现代Web和微服务架构中,API(应用程序编程接口)的设计和实现方式至关重要。本文将探讨四种流行的API设计模式:REST(Representational State Transfer)、GraphQL、gRPC以及新兴的tRPC。每种模式都…...

C/C++ protobuf与json互转
测试环境 ubuntu16.04 64bitprotocbuf:3.9.1 (支持json转换需>3.0.0) 协议 syntax "proto2";message Person{optional string name 1;optional uint32 age 2;optional string address 3; }测试代码 //protobuf > 3.0.0#…...

开发者专属提示词库:提升AI协作效率的实战指南
1. 项目概述:一个为开发者量身定制的提示词宝库如果你是一名开发者,无论是前端、后端、运维还是算法工程师,我相信你都或多或少地接触过像 ChatGPT 这类大型语言模型。它们能写代码、解 Bug、解释概念,甚至帮你设计架构。但很多时…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

VHDL转Verilog终极指南:如何用VHD2VL v3.0快速完成硬件描述语言转换
VHDL转Verilog终极指南:如何用VHD2VL v3.0快速完成硬件描述语言转换 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA开发领域,VHDL和Verilog是两大主流硬件描述语言,但团队协作或项目迁移时经常…...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

3分钟完成30分钟任务:词达人自动化助手终极指南
3分钟完成30分钟任务:词达人自动化助手终极指南 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否厌倦了每周在词达人平台上花费数小时完成枯燥的…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

Forge模组开发效率提升:Gradle插件自动化构建与热部署实践
1. 项目概述:一个为Forge模组开发者准备的“瑞士军刀”如果你是一名Minecraft Forge模组的开发者,或者你正打算踏入这个充满创造力的领域,那么你大概率经历过这样的场景:为了测试一个简单的功能改动,你需要反复地执行g…...

模拟电路布局优化:多智能体强化学习实践
1. 模拟电路布局优化的挑战与机遇在集成电路设计领域,模拟电路布局一直是个令人头疼的问题。作为一名从业十余年的模拟电路设计师,我深刻体会到传统布局方法在面对现代工艺挑战时的局限性。每次手工调整晶体管位置时,那种"差之毫厘&…...

基于RP2040与CircuitPython的键盘内嵌DOOM游戏启动器DIY指南
1. 项目概述与核心思路几年前,我还在用笨重的全尺寸键盘时,就总琢磨着怎么给这每天摸上八小时的家伙加点“私货”。直到后来玩起了RP2040和CircuitPython,一个念头就冒出来了:能不能把游戏直接“焊”进键盘里?不是那种…...

数据分析师能力展示:从项目构建到报告呈现的完整指南
1. 项目概述:一个数据分析师的能力展示平台最近在GitHub上看到一个挺有意思的项目,叫“dataanalyst-showcase”。光看名字,你可能会觉得这又是一个数据科学项目合集,但点进去仔细研究后,我发现它的定位非常精准——它不…...