机器学习整理
绪论
什么是机器学习?
机器学习研究能够从经验中自动提升自身性能的计算机算法。
机器学习经历了哪几个阶段?
推理期:赋予机器逻辑推理能力
知识期:使机器拥有知识
学习期:让机器自己学习
什么是有监督学习和无监督学习,并各举一个算法例子?
有监督学习:从有标记的样本中学习,如决策树。
无监督学习:从不含标记的样本中学习,如K均值算法。
性能度量
经验误差和泛化误差
经验误差:

泛化误差:
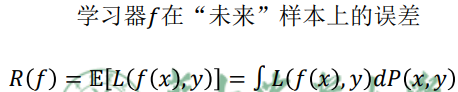
欠拟合和过拟合
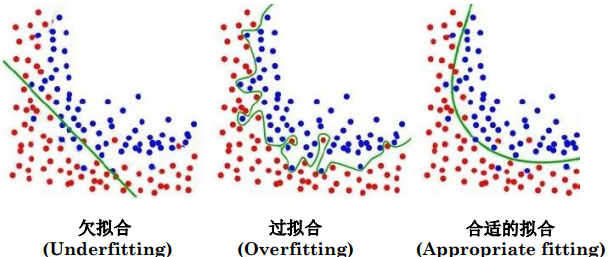
欠拟合:相较于数据而言,模型参数过少或者模型结构过于简单,以至于无法捕捉到数据中的规律的现象。
过拟合:模型过于紧密或精确地匹配特定数据集,以致于无法良好地拟合其他数据或预测未来的观察结果的现象。
合适的拟合:模型能够恰当地拟合和捕捉到数据中规律的现象。
留出法
留出法直接将数据集D划分为两个互斥的集合,分别为训练集S和测试集T。在S上训练出模型后,用T来评估其测试误差。
K折交叉验证法
- 首先将训练集均匀分成K份。
- 每次取其中一份作为验证集,剩下部分作为新的训练集,从而得到在该验证集的学习精度。
- 重复K次,得到平均精度。
- 对于每一组超参数,执行上述步骤,并基于验证性能选择最佳的超参数集。
- 在确定了最佳的超参数设置后,使用这些超参数和整个数据集来训练最终的模型
自助法
有放回采样。给定包含个样本的数据集D,我们对它进行采样产生数据集D’:每次随机从D中挑选一个样本,将其拷贝放入,这就是自助采样的结果。
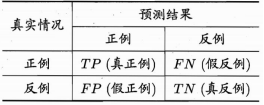
查准率、查全率与分类精度
混淆矩阵:
查准率:
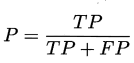
查全率:
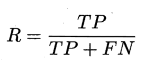
F1:
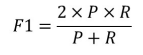
真正例率:
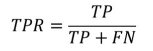
假正例率:
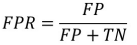
错误率:
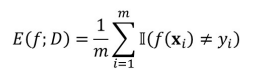
精度:
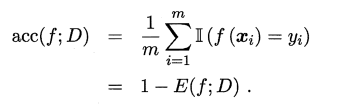
ROC AUC
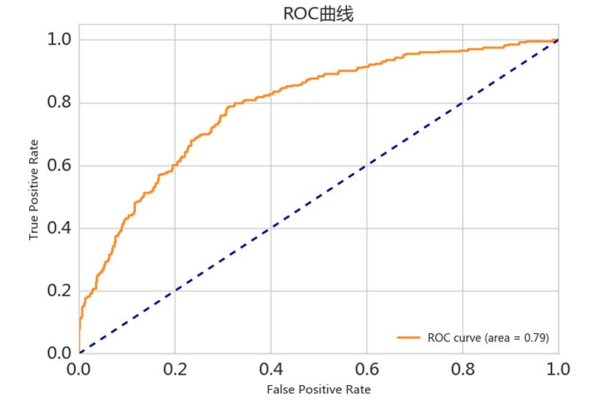
ROC曲线:根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出假正例率,真正例率。分别以它们为横、纵坐标作图。
AUC:ROC下的面积

线性模型
什么是线性回归?
线性回归是一种用于预测和建模的统计方法。线性回归的目的是找到一个线性关系,用来最好地预测一个因变量基于一个或多个自变量的值。
给定数据(X1,y1),(X2,y2),…,(Xm,ym),此处X可以是多维向量。线性回归的目标为学习合适的参数w和b使得
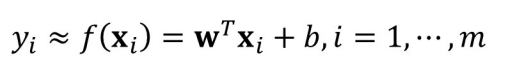
损失函数:用于度量yi和f(xi)的差异
均方误差:

最小二乘法:基于均方误差最小化来求解模型参数
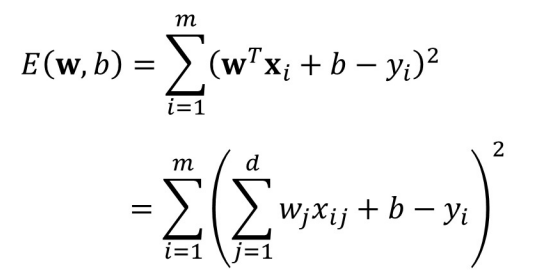
通过计算E(w,b)对w和b的偏导,并令其为零,得到最优解
概率、几率与对数几率关系?

概率:事件发生的可能性
几率:事件发生和不发生的比率
对数几率:几率取对数
对数几率回归模型?
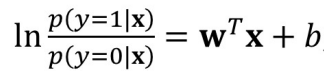
使用对数几率作为连接函数,将线性回归模型的输出映射到(0,1)区间内,表示为概率。对数几率回归提供了一个概率分数,表明观察属于正类的可能性,所以常用于二分类任务。
极大似然法
极大似然法是一种参数估计方法。在逻辑回归中,它用于估计模型参数(即权重 w 和偏差 b),使得观测数据出现的概率最大化。
- 似然函数:首先定义一个似然函数 L(w,b),表示在给定参数 w 和 b 的情况下,观测数据集发生的概率。
- 对数似然:由于乘积形式的似然函数可能会导致数值计算上的问题(如下溢),通常转而最大化对数似然函数 log(L(w,b))。
- 求解参数:找到一组参数 w 和 b,使得对数似然函数取得最大值。
梯度下降法
梯度下降法是一种优化算法,用于找到函数的局部最小值。在逻辑回归中,我们通常使用它来最小化代价函数。梯度下降法的核心思想是迭代地调整参数以最小化目标函数。
- 初始化参数:首先随机选择一个参数的初始值,或者从某个预定的起点开始。
- 计算梯度:计算目标函数关于每个参数的梯度。梯度是目标函数上升最快的方向,所以负梯度就是下降最快的方向。
- 更新参数:沿着负梯度方向更新参数。
- 重复迭代:重复步骤2和步骤3,直到满足停止条件,比如梯度的大小小于某个阈值,或者达到预定的迭代次数。
- 收敛至最小值:最终,梯度下降法会找到损失函数的局部最小值(在凸函数的情况下是全局最小值),这时的参数就是我们优化的结果。
学习率:梯度下降法中一个决定参数更新步长的超参数。
什么是线性判别分析? LDA
主要用于分类和降维。思想是寻找一个直线,使得同类样本的投影点尽可能接近,异类样本的投影点尽可能远离。使得在这个投影中,不同类别的数据点能够被最好地区分开来。
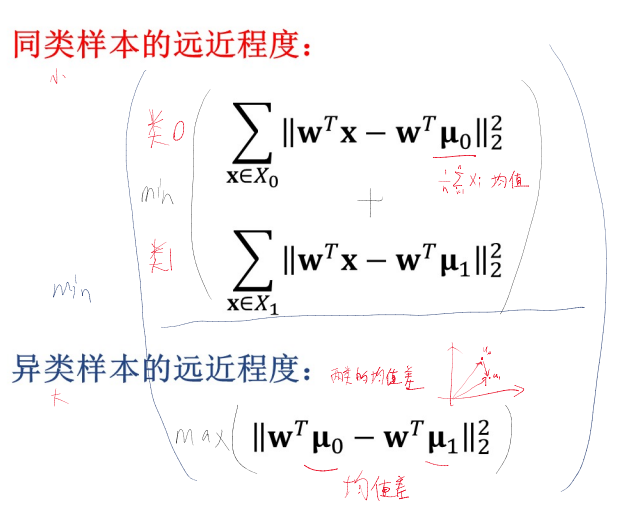


求解最佳投影向量:
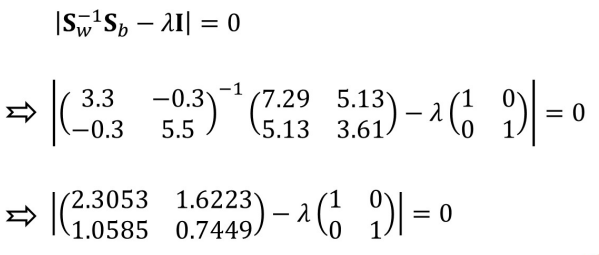

选最大特征值λ2

最后归一化
二阶求逆矩阵公式:
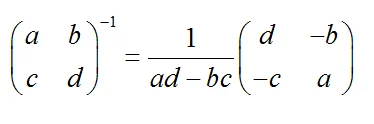
决策树
什么是决策树?决策树的优点?
决策树是一种基于树结构来进行决策的机器学习方法。这恰是人类在面临决策问题时一种很自然的处理机制。
优点:
- 不需要数据清洗,省去了数据标准化和虚拟变量创建的步骤。
- 训练速度快,成本与数据点数量呈对数关系。
- 能够同时处理连续和离散变量。
- 易于理解、解释和可视化,有助于逻辑分析。
- 可使用统计检验验证模型结果的可靠性。
- 即使与实际数据模型不符,也能表现良好。
信息量
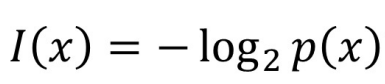
信息熵
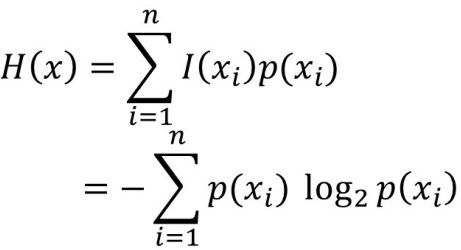
选择最优划分属性的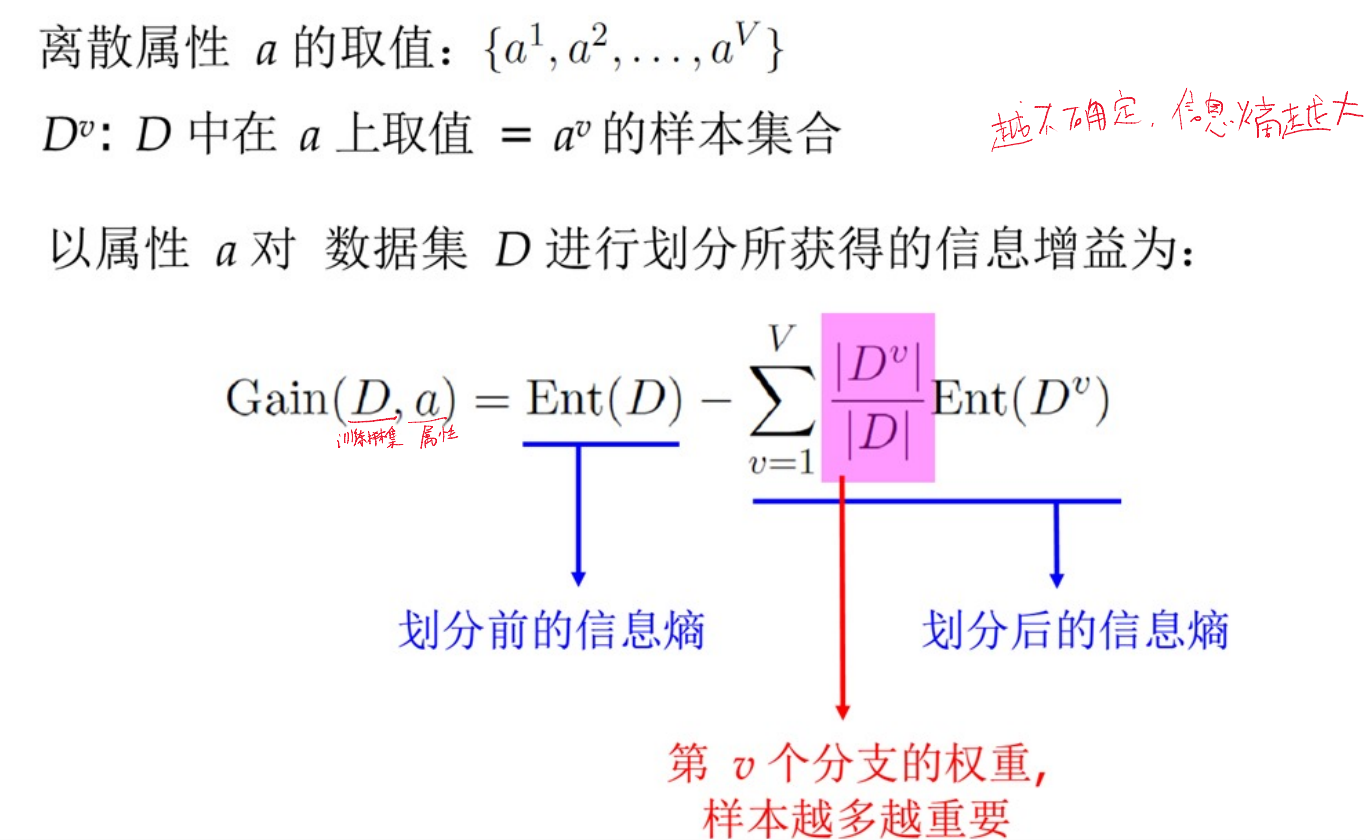 准则
准则
信息增益
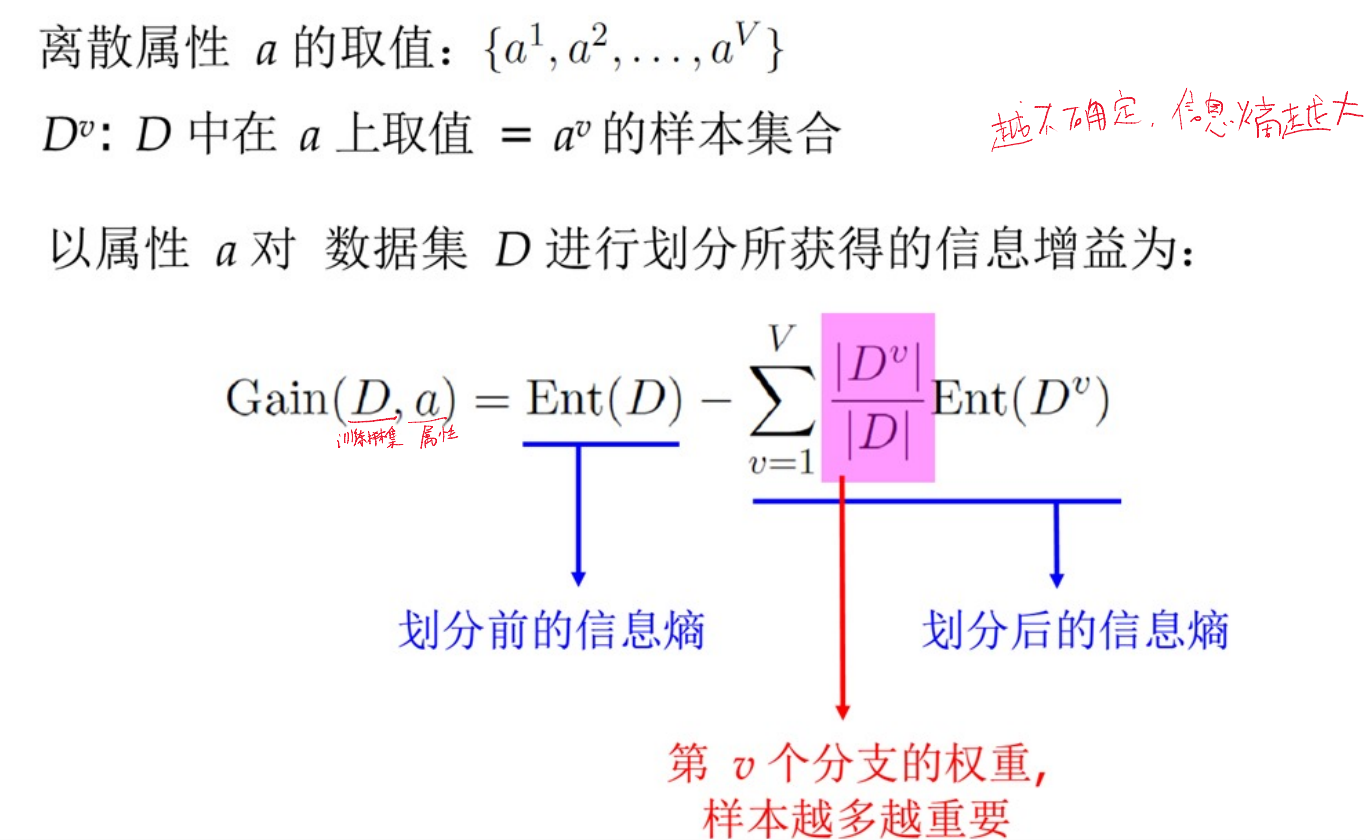
基尼指数
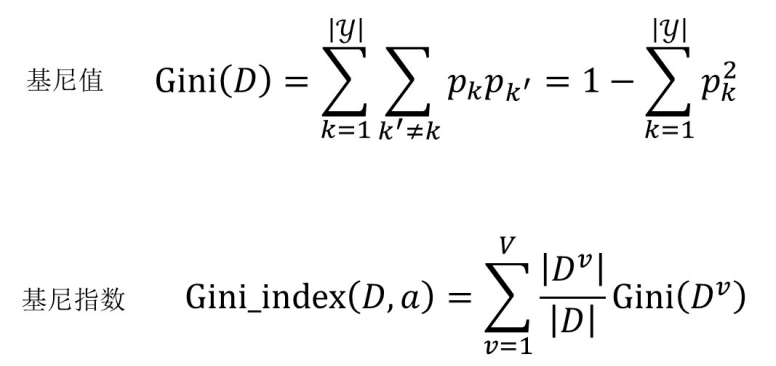
计算
每轮选择信息增益/基尼指数最大的扩展
神经网络
感知器 PLA
感知器是一种简单的神经网络,是用于二分类的线性模型。通过接收输入特征并将其与权重相乘,加上一个偏置项,然后通过一个阶跃激活函数来预测输出结果。感知器的核心是其学习规则,它根据预测错误来调整权重,适用于线性可分的数据集。尽管单个感知器的功能有限,但它们可以构建成多层架构,成为现代深度学习的基础。
一个感知器包括以下部分:
- 输入值:这些是输入数据或特征,通常表示为一个向量x。
- 权重:每个输入值都有一个对应的权重,表示为一个向量w。
- 偏置:一个常数,通常表示为b,可以看作是权重向量的一个额外维度。
- 激活函数:一个数学函数,用于计算输出。

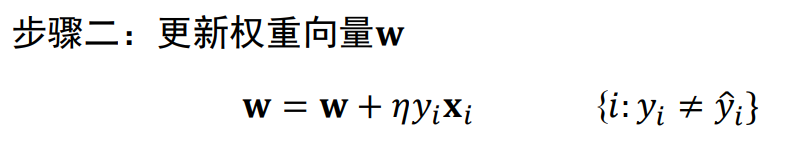
多类别感知器
- 一对多(One-vs-All):
- 对于每个类别,训练一个感知器来区分该类别和其他所有类别。
- 每个感知器的输出是一个分数,表示输入属于对应类别的程度。
- 在分类时,所有感知器都对给定的输入进行评分,选择得分最高的类别作为预测类别。
- 一对一(One-vs-One):
- 对于每对类别,训练一个感知器。
- 需要训练N(N−1)/2 个感知器,其中 N 是类别的数量。
- 每个感知器只负责区分两个类别。在分类时,每个感知器投票决定输入属于哪个类别,最终选票最多的类别为预测类别。
深度神经网络 DNN
有很多隐藏层的神经网络,每个隐藏层都是全连接层。
卷积神经网络 CNN
比DNN多了卷积层和池化层。CNN是一种专门用于处理具有类似网格结构的数据(如图像)的深度学习模型。
卷积层:
卷积核是一个小窗口。每个卷积核在输入图像上卷积,并计算卷积核和其覆盖的图像区域之间的点积。卷积层负责提取输入数据中的有用特征。多个卷积层可以捕获从低级到高级的特征。
池化层:
用于降低特征图的空间维度(宽度和高度),从而减少参数数量和计算量,防止过拟合,同时提高特征的不变性。CNN
激活函数作用
引入非线性到神经网络中。
三种梯度下降
通过迭代方式最小化损失函数,从而找到最佳的网络参数。梯度下降基本思想是在每次迭代中沿着损失函数梯度的反方向更新参数,因为这个方向是损失函数下降最快的方向。
批次梯度下降:使用整个训练数据集来计算损失函数的梯度。可以保证在凸函数上收敛到全局最小值。
随机梯度下降:随机选择一个训练样本来计算梯度。不一定收敛到全局最小值而且有波动。
小批量梯度下降:使用一个小批量的样本来计算梯度。收敛更快,更容易收敛到全局最小值。
支持向量机 SVM
什么是支持向量机?
SVM在高维空间中寻找最佳的超平面,以最大化不同类别之间的间隔。对于非线性可分的数据,SVM通过核技巧将数据映射到高维空间以实现有效的分类。
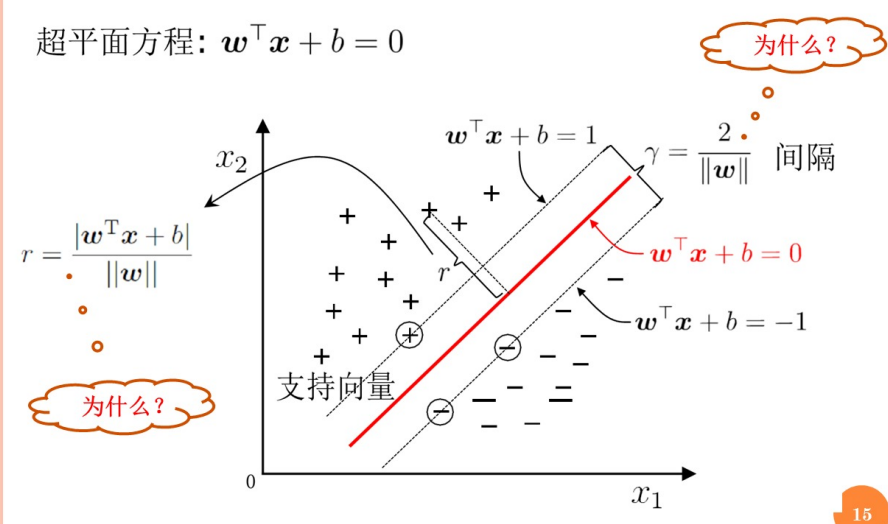
寻找参数,使得间隔最大

转化为目标函数:
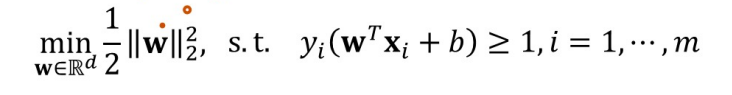
对偶问题
对偶问题提供了一种方式来优化原始的分类问题,使其更易于计算且能够应用核方法处理非线性可分的数据集。原始的SVM问题旨在找到最佳的分割超平面以最大化类别之间的间隔,但直接求解这个问题涉及复杂的约束优化。通过构造拉格朗日函数并将问题转化为其对偶形式,就得到了一个二次规划问题。求解对偶问题在数学上更简洁,能给出与原始问题相同的解。
对偶问题目标函数:
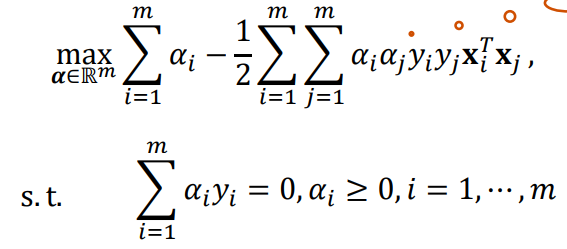
核函数
如果原始样本空间不存在能正确划分两类样本的超平面,可以使用核函数通过一个非线性映射将原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
软间隔
现实中很难确定合适的核函数,使训练样本在特征空间中线性可分。即便貌似线性可分,也很难断定是否是因过拟合造成的。所以引入软间隔,允许在一些样本上不满足约束。
支持向量回归 SVR
在回归问题中,需要预测一个连续的输出而非一个类别。在SVR中,我们不是寻找一个将两类数据分开的最大间隔超平面,而是寻找一个能够拟合尽可能多数据的函数,同时保持预测误差在一定阈值内。
集成学习
集成学习
集成学习通过构建并结合多个学习器来完成学习任务。先产生一组"个体学习器" ,再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法从训练数据产生。
Boosting
Boosting是一组可将弱学习器提升为强学习器的算法。不是同时训练所有模型,而是顺序地训练模型,每一个模型都尝试纠正前一个模型的错误。
- 先从初始训练集训练出一个基学习器
- 再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器的做错的训练样本在后续受到更多关注
- 然后基于调整后的样本分布来训练下一个基学习器
- 如此重复进行,直至基学习器数目达到事先指定的值T
- 最终将这T个基学习器进行加权结合。
AdaBoost
对同一数据集训练一系列的弱分类器,然后将它们组合起来,以提高整体性能。每一轮迭代中调整样本权重,使得被之前弱分类器错误分类的样本在后续的迭代中获得更多的关注。
Bagging
基于自助采样法,对原始训练数据集进行有放回的随机抽样,创建多个相同大小的子样本。使用每个子样本独立地训练出一个弱学习器。将所有弱学习器的预测结果进行聚合。分类问题采用投票机制,回归问题取平均值。
随机森林
随机森林是Bagging的一个扩展变体,在以决策树为基学习器构建 Bagging 集成的基础上,进一步在 决策树的训练过程中引入了随机属性选择。传统决策树在选择划分 属性时是在当前结点的属性集合中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最有属性用于划分。
- 自助采样:对原始训练数据集进行有放回的抽样,创建多个不同的训练子集。
- 构建决策树:对每个训练子集独立地构建一个决策树。在构建决策树的过程中,每次分割时都会从所有特征中随机选择一部分特征候选项。
- 多数投票或平均:在分类问题中,随机森林的预测结果是所有决策树的预测结果的多数投票;在回归问题中,则是平均值。
- 结果输出:输出预测结果。
使用集成学习优化SVM
Bagging
Bagging对原始数据集进行重采样(通常是有放回的抽样),形成多个不同的训练子集,然后在每个子集上独立地训练一个SVM模型。所有模型的预测结果通过投票(分类问题)或平均(回归问题)来汇总。Bagging对于减少模型的方差特别有效,这可以在数据集含有较多噪声时改善SVM的性能。
Boosting
Boosting是另一种集成方法,它不是同时训练所有模型,而是顺序地训练模型,每一个模型都尝试纠正前一个模型的错误。对于SVM来说,可以使用如AdaBoost算法,将弱SVM分类器组合成一个强分类器。在每一轮中,数据样本的权重会根据前一个SVM的错误率进行调整,使得随后的SVM更专注于那些之前被错误分类的样本。
聚类
什么是聚类?
聚类分析是将数据集分组,使得同一组内的数据相比与其他组的数据更相似。
聚类有哪些应用?
市场分割:根据客户的消费记录进行聚类,进而合理地推荐
基因分组:根据基因的表达模式进行聚类,用于分析基因功能。
医学图像分割:将肿瘤图像中的像素进行聚类,用于自动分割出肿瘤部分
自然图像分割:基于图像的模式识别的重要数据预处理步骤。
什么是K均值(K-Means)聚类算法?

例题
K均值(K-Means)聚类算法优缺点?
依赖类别数K的选择
依赖初始类中心的选择
对异常点和孤立点敏感
K-Means++:优化了初始化时选择类中心的方法,避免类中心过于集中。
对于数据集中的每个点 x,计算它到最近中心的距离 D(x)。

什么是K中心点(K-Medoids)聚类算法?

更新类中心:
- 计算每个类别内所有样本点到其中一个样本点的曼哈顿距离和
- 选出绝对误差最小的样本点,即跟同类别其他样本点最相似的样本点,作为作为新的类中心
曼哈顿距离:每个维度的距离和。
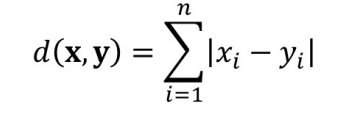
什么是层次聚类算法?

降维与度量学习
什么是降维?
降维是将数据从高维空间变换到低维空间,使得数据的低维表示能够保留原始数据的某些有意义的性质,理想情况下接近原始数据的本征维。
主成分分析 PCA
将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。

例题
PCA和LDA的异同
PCA和LDA都是降维技术,用于数据特征提取和降维。PCA是无监督学习,目标是找到数据中方差最大的方向,并将数据投影到这些方向上,旨在捕获最大的方差。LDA是监督学习,找到最佳的投影方向,使同类数据点尽可能接近,而不同类数据点尽可能远离,最大化类别可分性。PCA产生的是正交主成分,LDA产生的是最大化类别分离的线性组合。PCA更多用于数据的压缩和去噪,而LDA更多用于优化分类器的性能。
相关文章:
机器学习整理
绪论 什么是机器学习? 机器学习研究能够从经验中自动提升自身性能的计算机算法。 机器学习经历了哪几个阶段? 推理期:赋予机器逻辑推理能力 知识期:使机器拥有知识 学习期:让机器自己学习 什么是有监督学习和无监…...
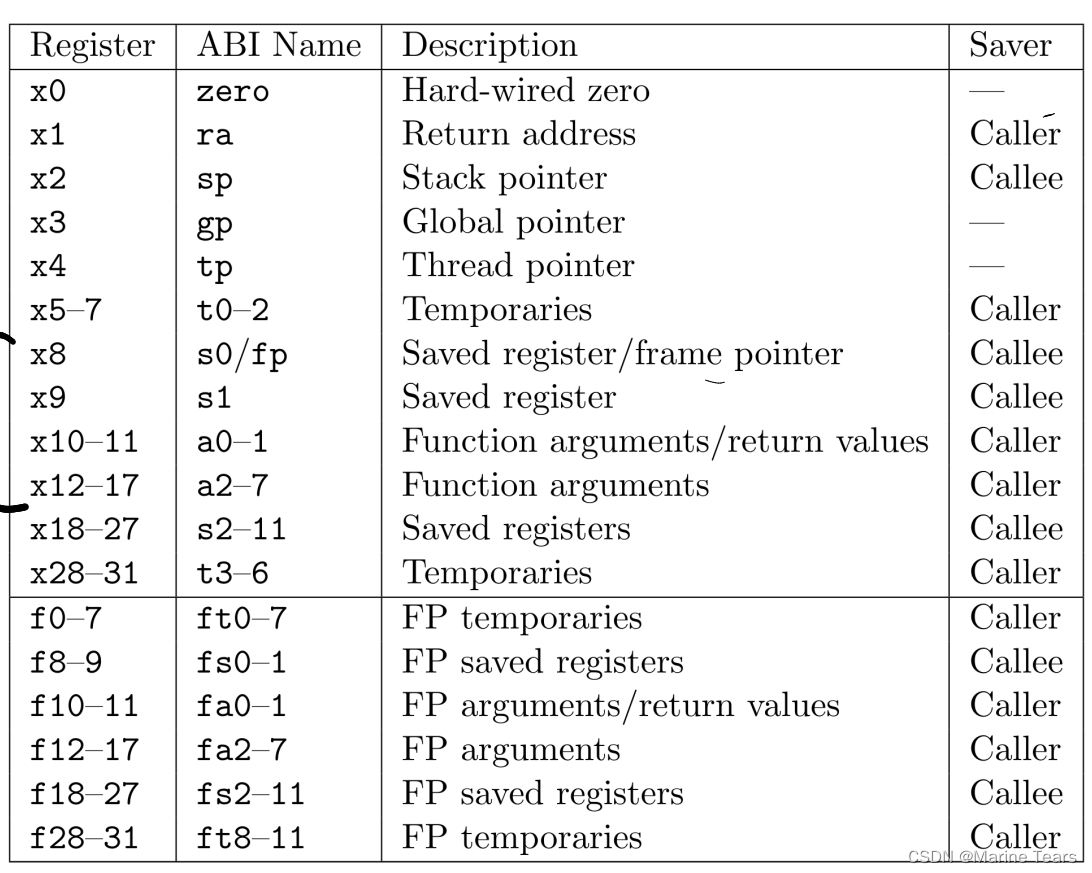
RISC-V常用汇编指令
RISC-V寄存器表: RISC-V和常用的x86汇编语言存在许多的不同之处,下面将列出其中部分指令作用: 指令语法描述addiaddi rd,rs1,imm将寄存器rs1的值与立即数imm相加并存入寄存器rdldld t0, 0(t1)将t1的值加上0,将这个值作为地址,取…...
第二篇:数据结构与算法-链表
概念 链表是线性表的链式存储方式,逻辑上相邻的数据在计算机内的存储位置不必须相邻, 可以给每个元素附加一个指针域,指向下一个元素的存储位 置。 每个结点包含两个域:数据域和指针域,指针域存储下一个结点的地址&…...

低代码配置-小程序配置
数据结构 {"data": {"layout": {"api":{"pageApi":{//api详情}},"config":{"title":"页面标题",},"listLayout": {"fields": [{"componentCode": "grid…...

第十八讲_HarmonyOS应用开发实战(实现电商首页)
HarmonyOS应用开发实战(实现电商首页) 1. 项目涉及知识点罗列2. 项目目录结构介绍3. 最终的效果图4. 部分源码展示 1. 项目涉及知识点罗列 掌握HUAWEI DevEco Studio开发工具掌握创建HarmonyOS应用工程掌握ArkUI自定义组件掌握Entry、Component、Builde…...

OJAC近屿智能张立赛博士揭秘GPT Store:技术创新、商业模式与未来趋势
Look!👀我们的大模型商业化落地产品📖更多AI资讯请👉🏾关注Free三天集训营助教在线为您火热答疑👩🏼🏫 亲爱的伙伴们: 1月31日晚上8:30,由哈尔滨工业大学的…...

Java接收curl发出的中文请求无法解析
最近做项目遇到了这种情况,Java接收curl发出的中文请求无法解析,英文请求一切正常,中文请求则对方服务器无法解析,可以猜测是中文导致的编码问题,但是奇怪的是,本地输出json也没有乱码,编解码正…...

Java设计模式-外观模式(11)
大家好,我是馆长!今天开始我们讲的是结构型模式中的外观模式。老规矩,讲解之前再次熟悉下结构型模式包含:代理模式、适配器模式、桥接模式、装饰器模式、外观模式、享元模式、组合模式,共7种设计模式。。 外观模式(Decorator Pattern) 定义 外观(Facade)模式一种通…...
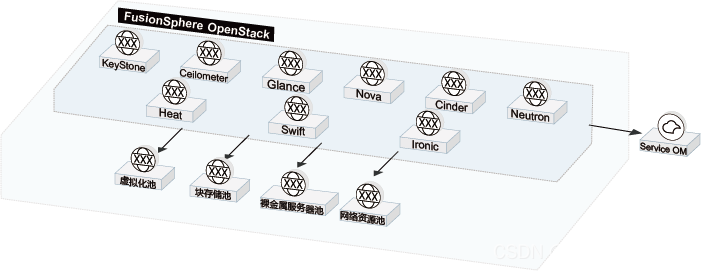
HCS-华为云Stack-FusionSphere
HCS-华为云Stack-FusionSphere FusionSphere是华为面向多行业客户推出的云操作系统解决方案。 FusionSphere基于开放的OpenStack架构,并针对企业云计算数据中心场景进行设计和优化,提供了强大的虚拟化功能和资源池管理能力、丰富的云基础服务组件和工具…...

C++类模板实现顺序表SeqList
main函数 #include<iostream> #include<stdlib.h> #include"SeqList.cpp"using namespace std;typedef int ElementType; int main(void) {SeqList< ElementType, 10> SeqList(1);cout << SeqList.ListLength() << endl;bool result;…...
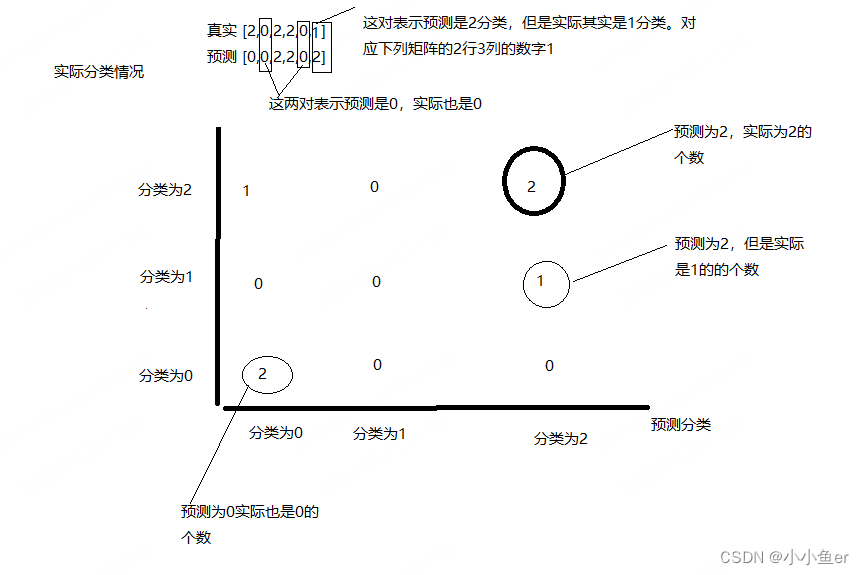
sklearn 学习-混淆矩阵 Confusion matrix
混淆矩阵Confusion matrix:也称为误差矩阵,通过计算得出矩阵的结果用来表示分类器的精度。其每一列代表预测值,每一行代表的是实际的类别。 from sklearn.metrics import confusion_matrixy_true [2, 0, 2, 2, 0, 1] y_pred [0, 0, 2, 2, 0…...
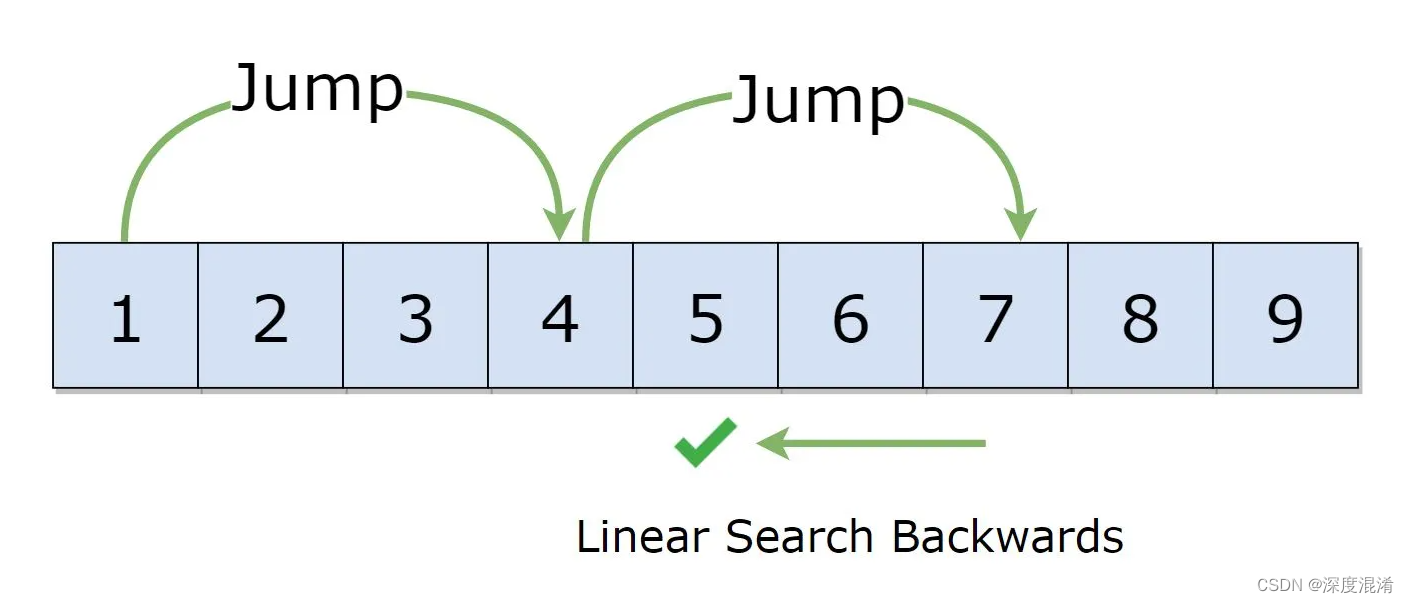
C#,数据检索算法之跳跃搜索(Jump Search)的源代码
数据检索算法是指从数据集合(数组、表、哈希表等)中检索指定的数据项。 数据检索算法是所有算法的基础算法之一。 本文提供跳跃搜索的源代码。 1 文本格式 using System; namespace Legalsoft.Truffer.Algorithm { public static class ArraySe…...
——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH)
ElasticSearch 开发总结(九)——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH
ElasticSearch 开发总结(九)——SearchType:DFS_QUERY_THEN_FETCH和QUERY_THEN_FETCH-CSDN博客 1.SearchType ES的搜索类型 有一个类SearchType(如下图示),关于该类的描述: Search type repre…...
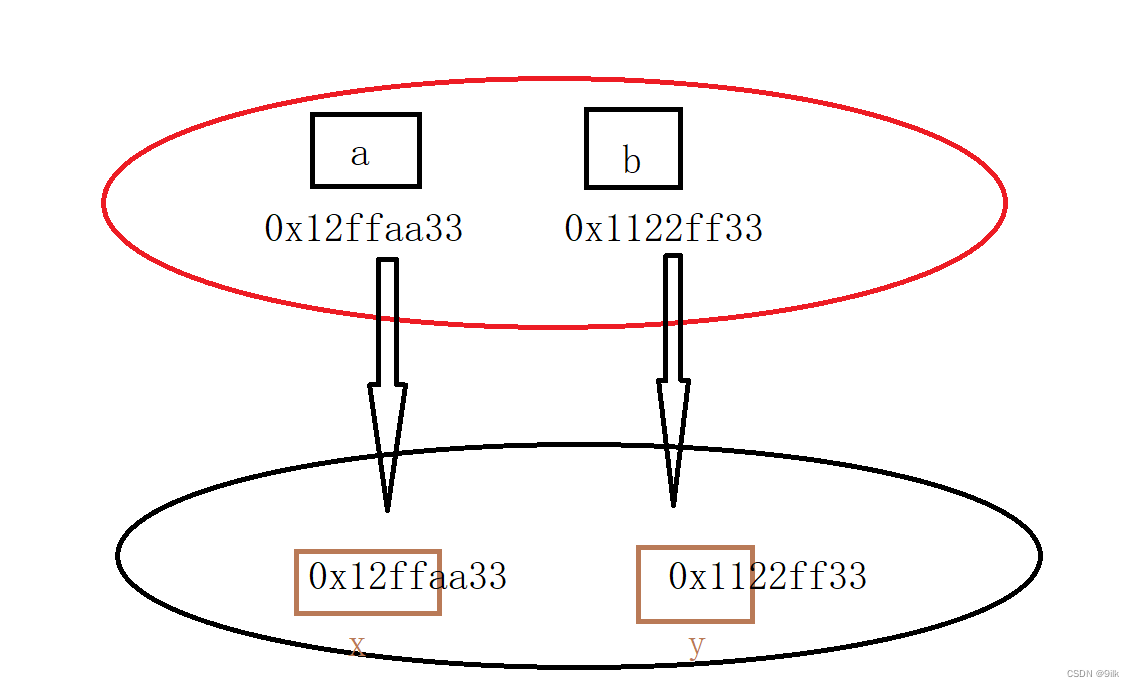
那些年与指针的爱恨情仇(一)---- 指针本质及其相关性质用法
关注小庄 顿顿解馋 (≧∇≦) 引言: 小伙伴们在学习c语言过程中是否因为指针而困扰,指针简直就像是小说女主,它逃咱追,我们插翅难飞…本篇文章让博主为你打理打理指针这个傲娇鬼吧~ 本节我们将认识到指针本质,何为指针和…...
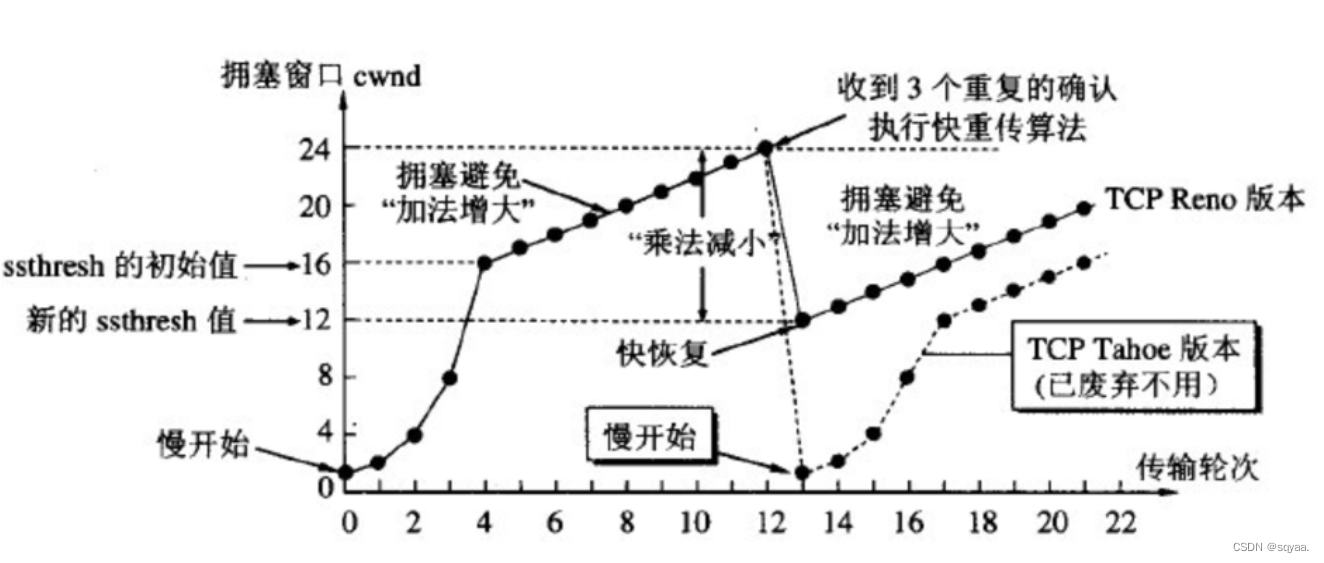
计算机网络——TCP协议
💡TCP的可靠不在于它是否可以把数据100%传输过去,而是 1.发送方发去数据后,可以知道接收方是否收到数据;2.如果接收方没收到,可以有补救手段; 图1.TCP组成图 TCP的可靠性是付出代价的,即传输效率…...

软考高级有意义吗?
有同学在平台向我提问,软考高级好像不好通过,花那么多时间去准备(非科班),有意义么? 我知道有些同学还在犹豫,不确定是否要报名软考系统架构设计师或者系统分析师。我认为,这种犹豫…...
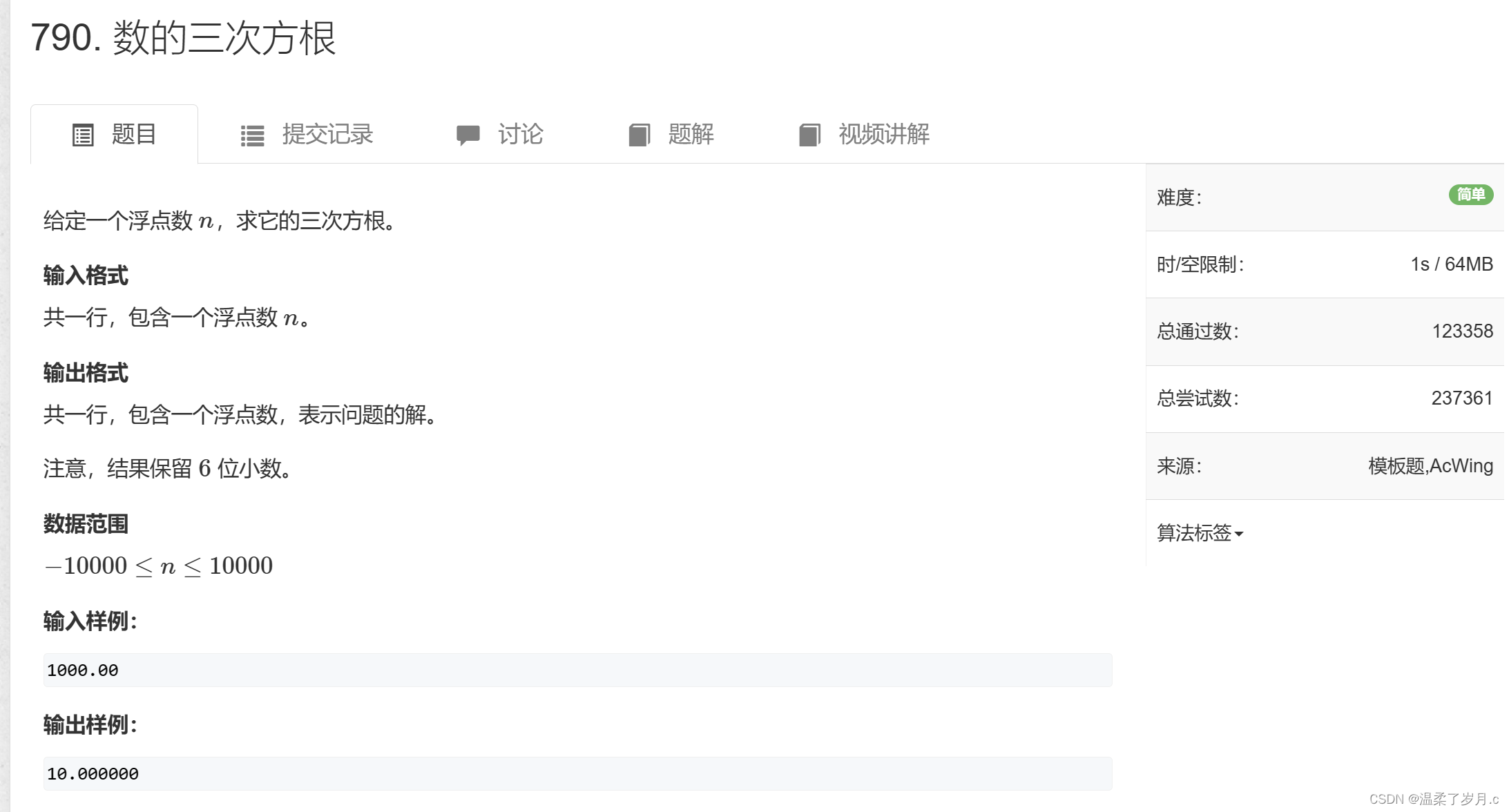
二分算法模版
二分算法模版 实数二分算法模版实数二分模版题 整数二分算法模版向上取整二分模版向下取整二分模版二分模版的注意点二分模版中check函数的实现能够使用二分的条件 二分主要分两类, 一类是对实数进行二分,一类是对整数进行二分 对整数二分又分成2种&…...
【CSS】字体效果展示
测试时使用了Google浏览器。 1.Courier New 2.monospace 3.Franklin Gothic Medium 4.Arial Narrow 5.Arial 6.sans-serif 7.Gill Sans MT 8.Calibri 9.Trebuchet MS 10.Lucida Sans 11.Lucida Grande 12.Lucida Sans Unicode 13.Geneva 14.Verdana 15.Segoe UI 16.Tahoma 17.…...
asp.net宠物流浪救助系统
asp.net宠物流浪救助系统 当领养人是无或者未领养的时候,就会显示领养申请按钮,登陆的用户可以申请领域该宠物,未登录会提示登陆然后转到登陆页面 宠物领养页面支持关键字查询符合条件的宠物 当有领养人时就隐藏领养申请按钮 社区交流意见…...

git常见命令
1、常用命令记录 1)切换分支 git checkout 分支名2)查看分支 查看远程分支 git branch -r 查看所有分支包括本地分支和远程分支 git branch -a3)合并分支 git merge 来源分支4)删除分支 删除本地分支:git branch …...

基于Fire2012算法与FastLED库的Arduino LED篝火制作全攻略
1. 项目概述:用代码点燃一场永不熄灭的数字篝火夏夜、星空、朋友围坐,篝火带来的温暖与氛围是露营的灵魂。但现实是,很多营地禁止明火,或者在城市阳台、室内空间,生一堆真正的火既不安全也不现实。作为一名玩了十多年A…...

3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍
3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况࿱…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

构建动态技能图谱:从数据模型到自动化可视化的完整实践
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。乍一看,这只是一个个人仓库,但点进去你会发现,它远不止是一个简单的代码集合。它更像是一张动态的、可视化的个人技能地图&am…...

AI驱动命令行工具:用自然语言自动化开发任务
1. 项目概述:一个为开发者“下厨”的AI助手如果你是一名开发者,每天在终端里敲打命令,构建、部署、调试,那么你肯定对重复性的命令行操作感到厌倦。比如,每次启动一个新项目,都要手动创建目录结构、初始化G…...

基于MCP协议构建AI编程助手:unloop-mcp文件系统服务器实战指南
1. 项目概述:一个面向开发者的“解循环”MCP服务器最近在GitHub上看到一个挺有意思的项目,叫Escapepaleolithic247/unloop-mcp。光看这个名字,可能有点摸不着头脑,但如果你是一个经常和AI助手(比如Claude、Cursor等&am…...

DeepMind Lab:强化学习研究的3D视觉仿真平台搭建与实战指南
1. 项目概述:一个被低估的强化学习研究“健身房”如果你在深度强化学习(Deep Reinforcement Learning, DRL)这个圈子里待过一段时间,或者正试图入门,那么你大概率听说过OpenAI的Gym、Unity的ML-Agents,甚至…...

独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力 对于独立开发者或小型工作室而言,在产品开发的早期阶段…...

AI与人类共创:从替代焦虑到协作闭环
GPT-Image 2 与人类创造力的共生:从“替代焦虑”到“协作闭环”(2026 研究视角与可落地实践)当 GPT-Image 2 这样的多模态生成/理解模型进入创作流程后,“竞争还是协作”立刻变成一个绕不开的讨论。直觉上,大家会把它理…...
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案 摘要 Point Transformer V3(PTv3)是CVPR 2024发布的高效点云处理模型,在语义分割任务中表现出色。然而,在16类牙齿语义分割任务的测试阶段,模型输出全部为0的问题却常常困扰开发者。本文将从数据…...