【软件测试】学习笔记-Nginx 在系统架构中的作用
本篇文章你探讨 Nginx 在应用架构中的作用,并从性能测试角度看如何利用 Nginx 数据统计用户访问量。
Nginx 重要的两个概念
代理
首先要来解释一下什么是代理,正向代理和反向代理是什么意思?各自作用是什么?不少同学经常听到这些名词,但往往分不清楚具体区别是什么。
什么是代理?
举个例子,比如你很想到某公司去做测试,对方公司的测试主管并不认识你,你也不知道这位测试主管的联系方式,但是你的朋友小王认识,他帮你推荐了简历,此时的小王就起到代理的作用,相当于一个渠道。
正向代理
正向代理的特点是你非常清楚地知道你要去哪儿,访问什么服务器,但服务器并不关心你的出发地是哪里,它只知道你从哪个代理服务器过来。
举个例子,北京去哈尔滨的高铁班次,对于目的地哈尔滨而言,它只知道这部分人是从北京过来的,但是并不清楚这些人之前是不是先从上海或者其他地方先到北京,再转车过来。
反向代理
刚刚说了正向代理,那反向代理又是什么呢?我先来说一下应用场景,比如我们的内部服务器集群,是不可能直接暴露出来让外网访问的,这样安全风险就非常大;再比如现在很多网站为了提高性能都采用了分布式部署,通过多台服务器来缓减服务端的压力,这些都可以通过 Nginx 来完成。
那我们的外网用户如何能够访问到内部的应用呢,Nginx 可以暴露端口给外网用户访问,当接收到请求之后分发给内部的服务器,此时的 Nginx 扮演的是反向代理的角色。这样一个过程,客户端是明确的,但对于访问到哪台具体的应用服务器是不明确的。就好像一个上海飞北京的班次,可能还有很多乘客到达北京之后会去沈阳、哈尔滨等,对于出发地上海而言,这个是不关心的。
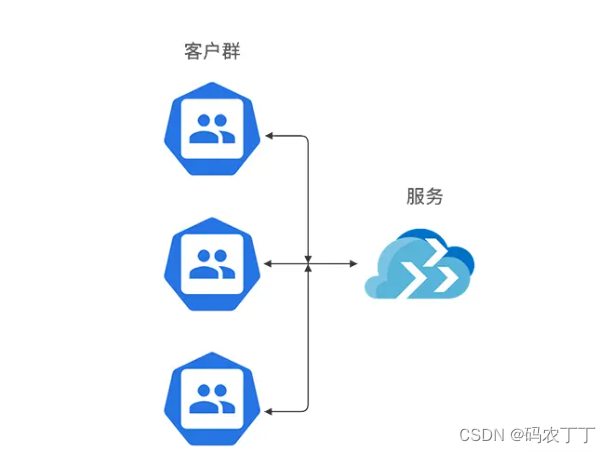
负载均衡
负载均衡是 Nginx 最重要也是最常见的功能,为什么需要负载均衡呢?你可以想一想,比如你线上只有一台应用服务器,如下图所示。
但是随着用户体量的上升,一台服务器并不能支撑现有用户的访问,那你就会考虑使用两台或者多台服务器,如下图所示:
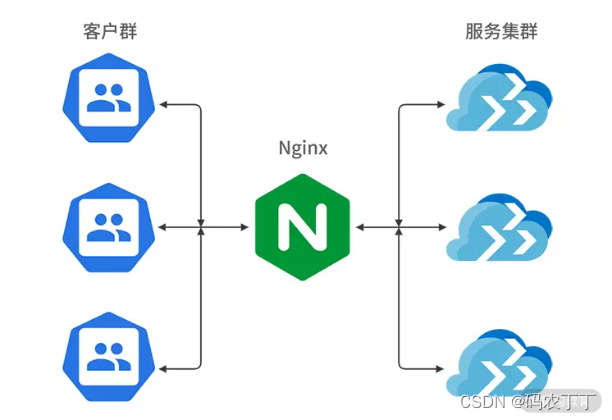
那用户如何能够相对均匀地访问到这些服务器呢,这就需要你去了解 Nginx 的负载均衡策略,简单来说,就是 Nginx 如何分发这些请求到后面的应用服务器集群,下面我介绍下 Nginx 的三种分配策略。
(1)轮询
也就是使用平均分配的方式,将每个请求依次分配到配置的后端服务器上。除非有服务宕机,才会停止分发。如下代码所示:
upstream localhost {//分发到各应用服务server 127.0.0.1:7070;server 127.0.0.1:7071;}server{//Nginx核心监听端口listen 8012;server_name localhost;location / {proxy_pass http://localhost;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;}}(2)权重
权重即配置轮询的比重,为什么需要这么配置呢?在真实的互联网场景下,很多服务器上都会配置多个应用,这样会导致每台服务器的资源占用不一致,所以在分布式部署配置下也需要注意这一点:
- 相对空闲的机器可以多配置访问比例;
- 比较繁忙的机器可以少配置一些。
如下代码所示,其中 ip1、ip2 以及 port 需要配置你实际的部署 ip 和 port。
upstream test {server ip1:8080 weight=9;server ip2:8081 weight=1;}(3)ip_hash
但上面两种配置方式在电商场景下有个很常见的问题,比如你登录了一个网站,登录信息已经保存到 a 机器,但当你做后续操作时的请求会到 b 机器,那么就获取不到你原来登录的信息,此时你就需要重新登录了。这样的情况是用户肯定不能接受的,ip_hash 模式就可以很好地解决这个问题,让每次访问能基于同一用户访问固定的服务器。
ip_hash 模式配置示例如下:
upstream test {ip_hash;server localhost:8080;server localhost:8081;}接着我们来看下如何基于 Nginx 记录的数据去分析用户访问请求分布,在讲下文之前,按照我的习惯,我想先说一说为什么我要通过 shell 命令去分析 Nginx 日志。
首先对于测试同学而言,比较熟练地掌握了 Python 或者 Java 的用法,但对于 Linux 中的 shell 命令不是很熟悉,也有同学说 shell 能做的我觉得 Python 也可以实现。我想对于性能测试而言,处理效率是一个我们都比较关心的问题。在 Linux 服务器上,你可以处理数据的级别达到百万条以上,对于 Linux 上的文本操作而言,相对于 Python 或者 Java,shell 在处理效率方面有着得天独厚的优势,所以掌握基础的 shell 命令还是必要的。
再说我为什么会选择 Nginx 日志去分析,这也得从互联网行业的现状说起:
- 对于大型互联网公司,关于获取分析日志我想早已有平台化支持,一键就可以导出你需要的用户数据访问报表;
- 而对于中小公司的测试来说,去哪里获取可能都不是很清楚。
所以我选择了使用 Nginx 这种比较原生的方式去讲解,这样对于使用过平台化操作的同学也可以了解一些底层的逻辑操作,也让没有接触过这方面数据统计的同学掌握其中一种实现方法。
Linux 的 shell 命令
Linux 的 shell 命令常见的文本操作命令有 awk、sed、sort、wc 等,通过这些命令的熟练掌握和搭配使用,相信你可以对 Linux 服务器上的文本处理如鱼得水。
awk
awk 可以将文本中的内容按行去读取,然后将读取出来的行按照规定的分隔符去提取你所需要的内容。
awk 常用参数是 -F 指定分隔符。
比如以下代码就是以 : 为分隔符,寻找以 root 开头的行数据,打印第 7 列。
# awk -F : '/^root/{print $7}' /etc/passwd/bin/bash以下代码表示以 begin 开头、end 结尾,打印第 1 列数据。
代码块示例
# awk -F : 'BEGIN{print "begin"}{print $1} END{print "end"}' /etc/passwdbeginroot..endSed
Sed 是一个流编辑器,一次只能处理一行内容,需要注意的是 sed 并不改变文本本身的内容,它只是把结果存放在临时缓冲区中。
sed 常用的参数有:
- a 表示新增;
- i 表示插入;
- c 表示取代;
- d 表示删除。
举个例子,我们设置一个文本文件,每行只有一个数字,如下所示:
[root@JD data]# cat sed.txt
在第一行下新增 4:
[root@JD data]# sed '1a 4' sed.txt
看下原来的文本,你会发现没有任何改动,如下代码所示:
[root@JD data]# cat sed.txt
Sort
Sort 的默认方式就是把第一列根据 ASCII 值排序输出。常用参数有:
- -n,依照数值的大小排序;
- -r,以相反的顺序来排序;
- -k,选择以某个区间进行排序。
举个简单的示例,将上述的 sed.txt 倒序输出,如下代码所示:
[root@JD data]# sort -r sed.txt
uniq
uniq 用于检查或者统计文本出现的重复行,常用参数是 -c,它用于连续重复行次数的统计。
我们构造一个 uniq.txt,如下所示:
[root@JD data]# cat uniq.txt hellohellocctestercctestercctestercom然后对 uniq.txt 进行重复数据统计,并根据重复次数由大到小排序,如下所示:
[root@JD data]# uniq -c uniq.txt |sort -r3 cctester2 hello1 com学完了这些基础命令,我带你来看 Nginx 日志分析,如果你不清楚你的 Nginx 日志地址,查看nginx.conf 文件的配置即可,指定日志路径如下所示:
access_log /data/logs/access.log main;
其中部分的日志显示,如下所示:
120.204.101.238 - - [29/Nov/2020:14:19:39 +0800] "GET /hello/map HTTP/1.1" 200 202 47.92.11.105 - - [29/Nov/2020:14:19:39 +0800] "GET /hello/map HTTP/1.1" 200 202 185.39.101.238 - - [29/Nov/2020:14:19:39 +0800] "GET /hello/list HTTP/1.1" 200 150 "-101.132.114.23 - - [29/Nov/2020:14:19:39 +0800] "GET /hello/list HTTP/1.1" 200 150 "-120.204.101.238 - - [29/Nov/2020:14:19:39 +0800] "POST /v1/login HTTP/1.1" 200 36 "-观察上述的日志,是以空格为分隔符号,第一行第一列是 120.204.101.238,第一行第二列是 -,以此类推,打印第 7 列,如下所示:
awk '{print $7}' access.log /hello/list/v1/login/hello/list/hello/map你也可以自行验证下输出是否符合预期。
接着我基于这份日志统计访问接口的比例分布,使用如下命令:
cat access.log |awk '{print $7}'|sort|uniq -c|sort -n -k -r
这个命令,是提取 acccess.log 的第 7 列,也就是接口路径:
- 先 sort 排序,这样可以将相同的接口访问路径合并一起;
- 再使用 uniq -c 统计连续访问的次数;
- 最后根据访问次数排序,便可以得到如下结果。
[root@JD logs]# cat access.log |awk '{print $7}'|sort|uniq -c|sort -n -k 1 -r87280 /hello/list18892 /hello/map12846 /v1/login通过输出结果可以看出第一列就是给定日志内的接口访问次数统计,比如 87280 就是 /hello/list 的访问次数。
总结
本篇文章相对全面地分享 Nginx 在系统架构中的作用,通过对访问日志的分析,也能够获取用户的基本访问情况。在实际工作过程中,面对没有原始访问数据的情况下,你就多了一条思路、一种解决方案。
相关文章:
【软件测试】学习笔记-Nginx 在系统架构中的作用
本篇文章你探讨 Nginx 在应用架构中的作用,并从性能测试角度看如何利用 Nginx 数据统计用户访问量。 Nginx 重要的两个概念 代理 首先要来解释一下什么是代理,正向代理和反向代理是什么意思?各自作用是什么?不少同学经常听到这…...

鸿蒙开发【应用开发基础知识】
应用开发介绍 1. 项目说明 通过OpenHarmony提供的Stage模型和ArkUI的eTS声明式开发规范,结合简单的Demo,分享学习OpenHarmony/docs/application-dev[应用开发文档] 2. 主要功能 目录标题展示,目录列表展示点击目录列表,查看列…...

腾讯云幻兽帕鲁4核16G14M服务器性能测评和价格
腾讯云幻兽帕鲁服务器4核16G14M配置,14M公网带宽,限制2500GB月流量,系统盘为220GB SSD盘,优惠价格66元1个月,277元3个月,支持4到8个玩家畅玩,地域可选择上海/北京/成都/南京/广州,腾…...

Linux第一个小程序——进度条
目录 回车和换行 缓冲区 设计倒计时 进度条(多文件操作) Version1:进度条 Version2:应用场景进度条 Version3:升级彩色进度条 回车和换行 回车\r:r 回车,回到当前行的行首,而…...
(N-141)基于springboot,vue网上拍卖平台
开发工具:IDEA 服务器:Tomcat9.0, jdk1.8 项目构建:maven 数据库:mysql5.7 系统分前后台,项目采用前后端分离 前端技术:vueelementUI 服务端技术:springbootmybatis-plusredi…...
深入了解Figure的结构与层次
深入了解Figure的结构与层次 一 Matplotlib中的Figure1.1 Figure的概念和作用:1.2.创建Figure对象:1.3 Figure的属性和方法: 二 子图(Axes)的角色与创建2.1 子图(Axes)的概念:2.2 创建子图的方法:2.3 Axes的…...

c语言基础6
1.逗号表达式 逗号表达式,就是用逗号隔开的多个表达式。 逗号表达式,从左向右依次执行。整个表达式的结果是最后⼀个表达式的结果。 我们来看下面的一个代码: int main() {int a 1;int b 2;int ret (a > b, a b 2, b, b a 1);p…...

kotlin sum 与 sumOf
kotlin 中 sum 的作用: 计算一个列表里面数字的总和: val numbers listOf(1, 2, 3, 4, 5) val sum numbers.sum() println("The sum is: $sum") // 打印结果: The sum is: 15 kotlin中sumOf的作用: 也是计算一个列表里面数字…...
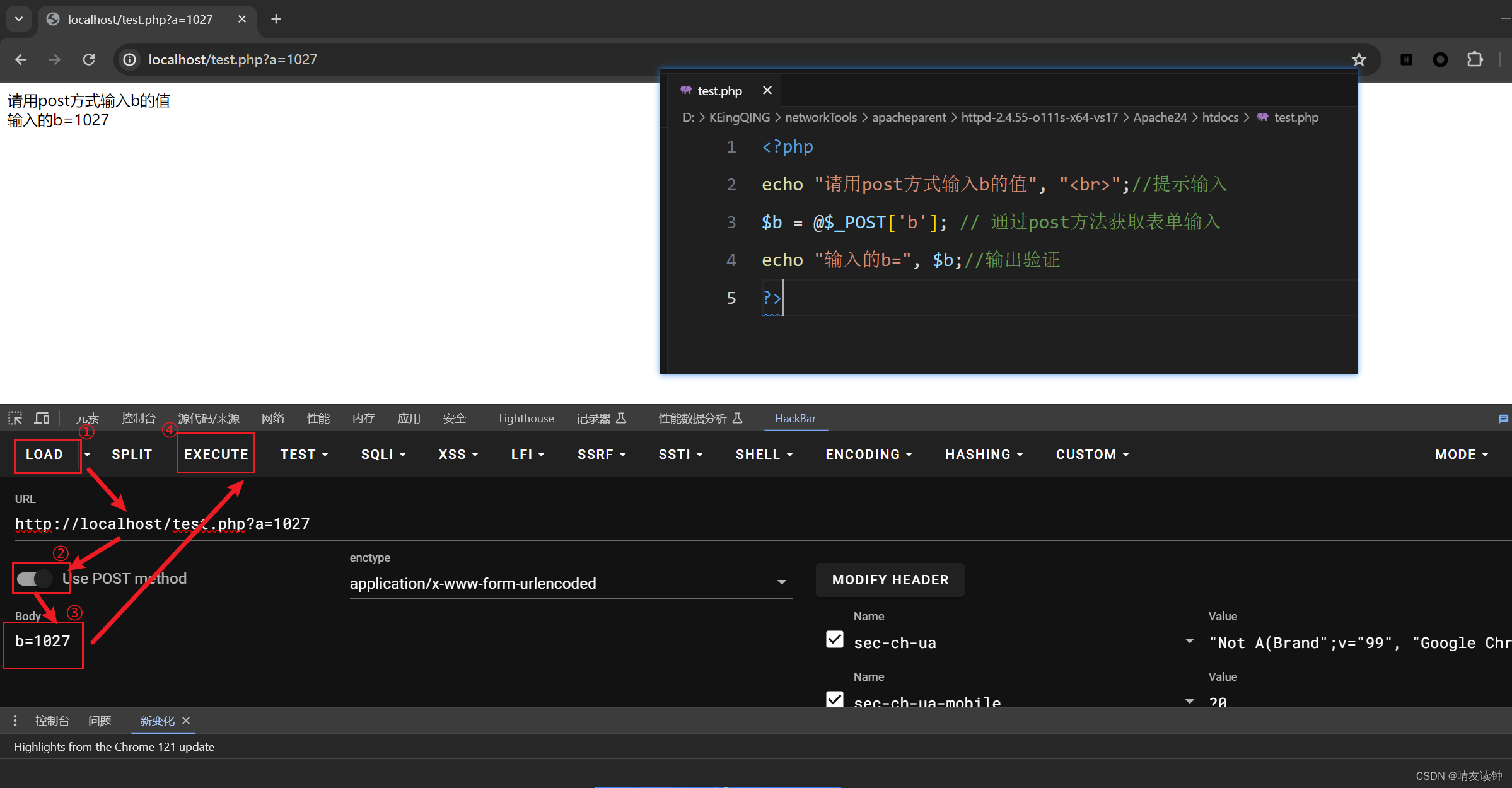
php怎么输入一个变量,http常用的两种请求方式getpost(ctf基础)
php是网页脚本语言,网页一般支持两种提交变量的方式,即get和post get方式传参 直接在网页URL的后面写上【?a1027】,如果有多个参数则用&符号连接, 如【?a10&b27】 post方式传参 需要借助插件,ctfer必备插…...
Spring Boot 项目配置文件
文章目录 配置文件的作用properties基本语法读取文件信息缺点 yml基本语法优点配置不同数据类型字符串类型的写法 配置对象配置集合 读取配置文件的几种方法EnvironmentPropertySource使用原生方式读取 设置不同环境的配置文件 配置文件的作用 整个项目中重要的数据都是在配置…...
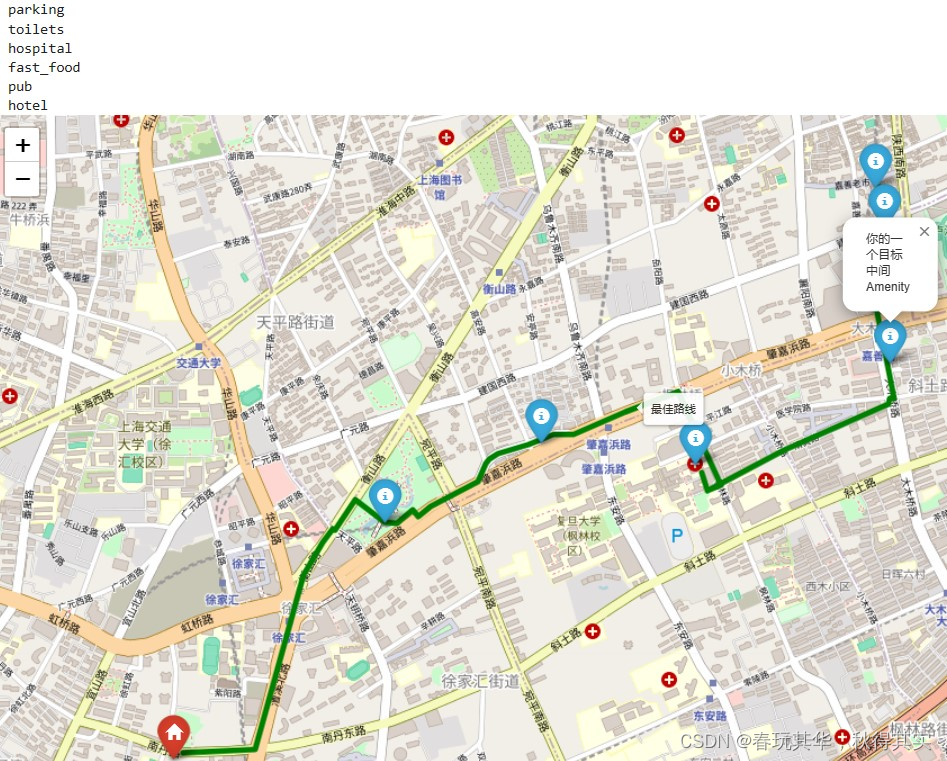
学校“数据结构”课程Project—扩展功能(自主设计)
目录 一、设想功能描述 想法缘起 目标功能 二、问题抽象 三、算法设计和优化 1. 易想的朴素搜索 / dp 搜索想法 动态规划(dp)想法 2. 思考与优化 四、算法实现 五、结果示例 附:使用的地图API 一、设想功能描述 想法缘起 OSM 导出…...
从0开始搭建若依微服务项目 RuoYi-Cloud(保姆式教程 一)
掌握陌生项目解读技巧 掌握若依(RuoYi-Cloud)框架 掌握SpringCloud Alibaba体系项目开发套路,结合我之前所有企业项目来学习就知道有多么简单。 一、框架介绍 1. 简介 一直想做一款后台管理系统,看了很多优秀的开源项目但是发现没有合适的。于是利用空…...
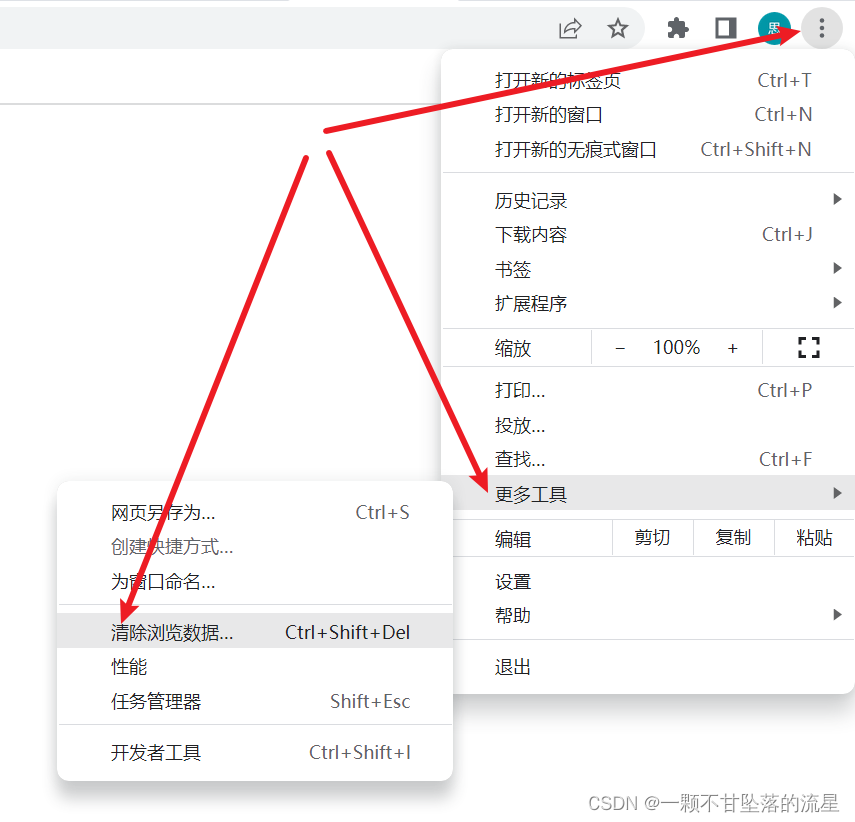
【Chrome】浏览器怎么清除缓存并强制刷新
文章目录 1、正常刷新:正常刷新网页,网页有缓存则采用缓存。 F5 或 刷新键2、强制刷新:忽略缓存刷新,重新下载资源不用缓存。 CtrlF5 或 ShiftF5 或 CtrlShiftR3、在浏览器的设置里面清除所有数据...

Android创建保存Excel文件
Android开发生成保存Excel文件,首先下载两个jar包。下载地址:Android读写Excel文件的两个jar包资源-CSDN文库 poi-3.12-android-a.jar poi-ooxml-schemas-3.12-20150511-a.jar 把jar包放在app的libs文件夹下,引用jar我一般都在build.gradle的…...

Selenium + Django + Echarts 实现亚马逊商品数据可视化爬虫项目
最近完成了1个爬虫项目,记录一下自己的心得。 项目功能简介 根据用户输入商品名称、类别名称,使用Selenium, BS4等技术每天定时抓取亚马逊商品数据,使用Pandas进行数据清洗后保存在MySql数据库中. 使用Django提供用户端功能,显…...
【深度学习】初识深度学习
初识深度学习 什么是深度学习 关系: #mermaid-svg-7QyNQ1BBaD6vmMVi {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-7QyNQ1BBaD6vmMVi .error-icon{fill:#552222;}#mermaid-svg-7QyNQ1BBaD6vmMVi .err…...

探索 Xind3 生态系统,解锁铭文资产的新玩法
铭文市场的兴起,不仅是新资产发行方案向市场的代表,更是新资产革命的代表。通过“公平启动”的方式,任何人都可以按照先到先得的原则“铸造”资产。虽然这看起来是意识形态上的新升级,但实际上最火的铭文风潮是由CEX引发的。 我们…...

js有哪些内置对象?
在 JavaScript 中,内置对象可以分为三类:原始值的包装对象、构造函数和其他对象。这里列举一些常见的内置对象及其方法: 原始值的包装对象: String:字符串类型的包装对象,有 charAt、concat、indexOf、repl…...
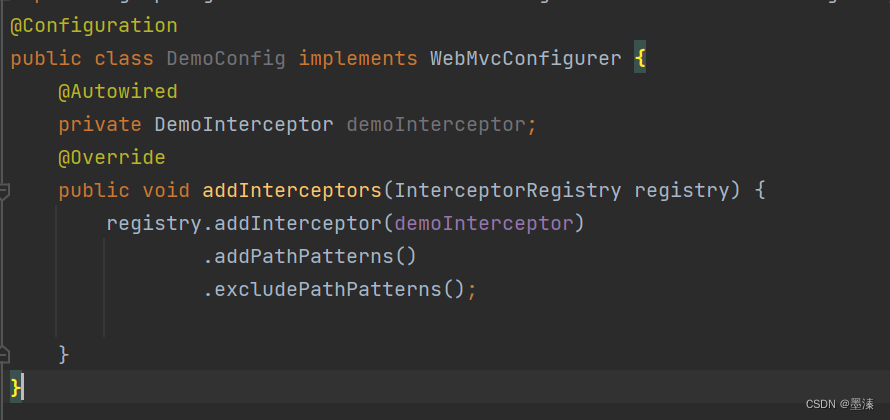
拦截器的简单使用
拦截器的简单使用 拦截器的使用创建拦截器preHandle 目标方法执行前执行postHandle 目标方法执行后执行afterCompletion 视图渲染后执行 拦截器使用场景返回值注册拦截器运用拦截器 拦截器的使用 创建拦截器 首先,我们需要创建一个拦截器器的类,并且需要继承自HandlerIntercep…...
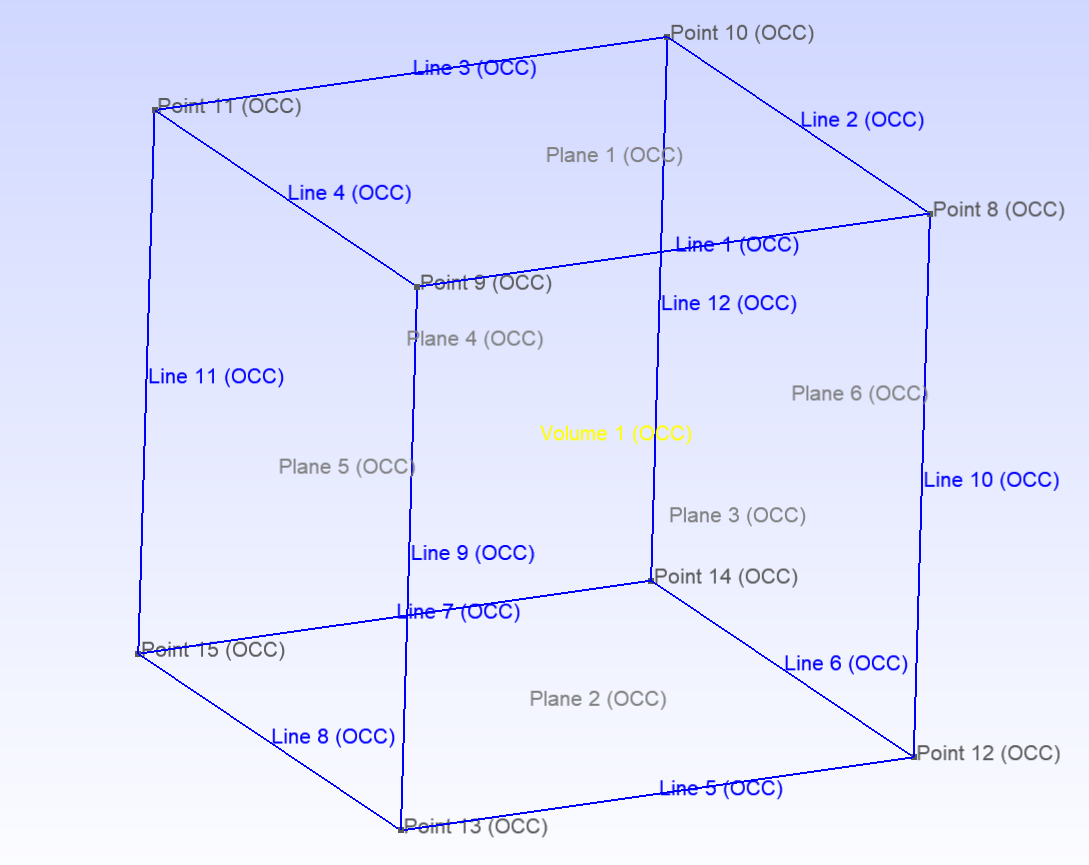
【gmsh源码阅读】OCC对象绑定tag及获取几何与网格映射关系
一、Tag是什么? gmsh中的几何模型相对于OCC的模型增加了id编号,也叫tag,在gmsh中可以显示出来。在gmsh中,点、线、面、体都有Tag,以方便对其查找定位查找。在OCC中TopoDS_Shape只有几何与拓扑结构,没有唯一…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...
)
Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践)
更多请点击: https://codechina.net 第一章:Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践) Lindy效应在自动化系统设计中揭示了一个关键洞察:越久经考验的实践,其未来预期寿命越长。Lindy多步…...

鼎讯AM-601光纤熔接机:交通通信建设与维护的可靠伙伴
在铁路、高速公路等交通基础设施的智能化建设中,稳定高效的光纤网络是指挥调度、安全监控等核心系统运行的生命线。鼎讯AM-601光纤熔接机,作为一款专为严苛环境设计的六马达便携式熔接设备,正成为保障这些关键通信链路畅通无阻的可靠选择。无…...

当卫星在天上“读懂”人间:ICLR 2025 论文深度解读师玉娇、昃向辉的CS2S
把一张卫星图变成一张街景照片,就像把一个俯视棋盘拼成一面看台——不仅要摆对每一枚棋子,还要看懂整场比赛想象这样一个场景:你在城市规划部门工作,需要快速生成某条街道在不同季节、不同天气条件下的真实渲染效果,以…...