1.27学习总结
今天做了些队列的题:
1.逛画展(单调队列)
2.打印队列 Printer Queue(优先队列)
3.[NOIP2010 提高组] 机器翻译(模拟队列)
4.求m区间内的最小值(单调队列板子题)
5.日志统计(滑动窗口,双指针)
总结一下:单调队列使用STL的deque进行模拟,也可以用数组和双指针(head,tail),有两种操作,删头和去尾,实现一个区间内单调增或减的队列,经典的例题是滑动窗口,在用单调队列做题时,尽量队列内存的是索引,而不是这个数据本身
优先队列(堆)可用于求区间最值,数据较大的时候容易TLE
逛画展https://www.luogu.com.cn/problem/P1638
题目描述
博览馆正在展出由世上最佳的 �m 位画家所画的图画。
游客在购买门票时必须说明两个数字,�a 和 �b,代表他要看展览中的第 �a 幅至第 �b 幅画(包含 �,�a,b)之间的所有图画,而门票的价钱就是一张图画一元。
Sept 希望入场后可以看到所有名师的图画。当然,他想最小化购买门票的价格。
请求出他购买门票时应选择的 �,�a,b,数据保证一定有解。
若存在多组解,输出 �a 最小的那组。
输入格式
第一行两个整数 �,�n,m,分别表示博览馆内的图画总数及这些图画是由多少位名师的画所绘画的。
第二行包含 �n 个整数 ��ai,代表画第 �i 幅画的名师的编号。
输出格式
一行两个整数 �,�a,b。
输入输出样例
输入 #1复制
12 5 2 5 3 1 3 2 4 1 1 5 4 3
输出 #1复制
2 7
说明/提示
数据规模与约定
- 对于 30%30% 的数据,有 �≤200n≤200,�≤20m≤20。
- 对于 60%60% 的数据,有 �≤105n≤105,�≤103m≤103。
- 对于
- 100%100% 的数据,有 1≤�≤1061≤n≤106,1≤��≤�≤2×1031≤ai≤m≤2×103。
- 思路:当还没有满足条件的时候一直入队,直到情况满足的时候,开始从头出队,直到情况未满足,找到所有可能的情况,并取出最小值
#include <bits/stdc++.h>
using namespace std;
int a[1000005];
int hash_count[20005];
int main()
{deque<int>q;int m,n;cin>>m>>n;int t=0;int min_length=m+2,l=0,r=m-1;for (int i=0;i<m;++i){cin>>a[i];if (hash_count[a[i]]==0)t++;hash_count[a[i]]++;q.push_back(i);while (t==n)//2 5 3 1 3 2 4 1 1 5 4 3{if (min_length>q.back()-q.front()){min_length=q.back()-q.front();l=q.front(),r=q.back();}hash_count[a[q.front()]]--;if (hash_count[a[q.front()]]==0)t--;q.pop_front();}}cout<<l+1<<" "<<r+1;
}求m区间内的最小值https://www.luogu.com.cn/problem/P1440
题目描述
一个含有 �n 项的数列,求出每一项前的 �m 个数到它这个区间内的最小值。若前面的数不足 �m 项则从第 11 个数开始,若前面没有数则输出 00。
输入格式
第一行两个整数,分别表示 �n,�m。
第二行,�n 个正整数,为所给定的数列 ��ai。
输出格式
�n 行,每行一个整数,第 �i 个数为序列中 ��ai 之前 �m 个数的最小值。
输入输出样例
输入 #1复制
6 2 7 8 1 4 3 2
输出 #1复制
0 7 7 1 1 3
说明/提示
对于 100%100% 的数据,保证 1≤�≤�≤2×1061≤m≤n≤2×106,1≤��≤3×1071≤ai≤3×107。
思路:模拟一个单调增的队列,队内没有的时候入队,有元素的时候判断,当前队尾元素是否小于将要入队的元素,如果不小于,那么队尾出队,直到找到一个小于的数或者队列空
#include <bits/stdc++.h>
using namespace std;
int a[2000005];
int main()
{int n,m;scanf("%d%d",&n,&m);deque<int>q;for (int i=0;i<n;++i){int x;scanf("%d",&x);a[i]=x;if (q.empty())printf("0\n");else printf("%d\n",a[q.front()]);while (!q.empty() && x<a[q.back()])q.pop_back();q.push_back(i);if (i-m==q.front())q.pop_front();}
}日志统计https://www.luogu.com.cn/problem/P8661
题目描述
小明维护着一个程序员论坛。现在他收集了一份“点赞”日志,日志共有 �N 行。其中每一行的格式是 ts id,表示在 ��ts 时刻编号 ��id 的帖子收到一个“赞”。
现在小明想统计有哪些帖子曾经是“热帖”。如果一个帖子曾在任意一个长度为 �D 的时间段内收到不少于 �K 个赞,小明就认为这个帖子曾是“热帖”。
具体来说,如果存在某个时刻 �T 满足该帖在 [�,�+�)[T,T+D) 这段时间内(注意是左闭右开区间)收到不少于 �K 个赞,该帖就曾是“热帖”。
给定日志,请你帮助小明统计出所有曾是“热帖”的帖子编号。
输入格式
第一行包含三个整数 �N、�D 和 �K。
以下 �N 行每行一条日志,包含两个整数 ��ts 和 ��id。
输出格式
按从小到大的顺序输出热帖 ��id。每个 ��id 一行。
输入输出样例
输入 #1复制
7 10 2 0 1 0 10 10 10 10 1 9 1 100 3 100 3
输出 #1复制
1 3
说明/提示
对于 50%50% 的数据,1≤�≤�≤10001≤K≤N≤1000。
对于 100%100% 的数据,1≤�≤�≤1051≤K≤N≤105,0≤��,��≤1050≤id,ts≤105。
思路:双指针+滑动窗口的做法,先按照时间排序。直到满足时间条件的时候,开始消除点赞数
#include <bits/stdc++.h>
using namespace std;
const int N=1e5+50;
struct Node{int time;int id;
};
struct Node a[N];
int nums[N];//记录每个id的点赞数
int flag[N];//记录是热评的
bool cmp(Node &a,Node &b)
{if (a.time!=b.time)return a.time<b.time;else if (a.time==b.time)return a.id<b.id;
}
int main()
{int n,d,k;cin>>n>>d>>k; for (int i=0;i<n;++i)cin>>a[i].time>>a[i].id;sort(a,a+n,cmp);for (int i=0,j=0;i<n;++i){nums[a[i].id]++;while (a[i].time-a[j].time>=d){nums[a[j].id]--;j++;}if (nums[a[i].id]>=k)flag[a[i].id]=1;}for (int i=0;i<N;++i){if (flag[i])cout<<i<<endl;}
}机器翻译https://www.luogu.com.cn/problem/P1540
题目描述
小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。
这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。对于每个英文单词,软件会先在内存中查找这个单词的中文含义,如果内存中有,软件就会用它进行翻译;如果内存中没有,软件就会在外存中的词典内查找,查出单词的中文含义然后翻译,并将这个单词和译义放入内存,以备后续的查找和翻译。
假设内存中有 �M 个单元,每单元能存放一个单词和译义。每当软件将一个新单词存入内存前,如果当前内存中已存入的单词数不超过 �−1M−1,软件会将新单词存入一个未使用的内存单元;若内存中已存入 �M 个单词,软件会清空最早进入内存的那个单词,腾出单元来,存放新单词。
假设一篇英语文章的长度为 �N 个单词。给定这篇待译文章,翻译软件需要去外存查找多少次词典?假设在翻译开始前,内存中没有任何单词。
输入格式
共 22 行。每行中两个数之间用一个空格隔开。
第一行为两个正整数 �,�M,N,代表内存容量和文章的长度。
第二行为 �N 个非负整数,按照文章的顺序,每个数(大小不超过 10001000)代表一个英文单词。文章中两个单词是同一个单词,当且仅当它们对应的非负整数相同。
输出格式
一个整数,为软件需要查词典的次数。
输入输出样例
输入 #1复制
3 7 1 2 1 5 4 4 1
输出 #1复制
5
说明/提示
样例解释
整个查字典过程如下:每行表示一个单词的翻译,冒号前为本次翻译后的内存状况:
1:查找单词 1 并调入内存。1 2:查找单词 2 并调入内存。1 2:在内存中找到单词 1。1 2 5:查找单词 5 并调入内存。2 5 4:查找单词 4 并调入内存替代单词 1。2 5 4:在内存中找到单词 4。5 4 1:查找单词 1 并调入内存替代单词 2。
共计查了 55 次词典。
数据范围
- 对于 10%10% 的数据有 �=1M=1,�≤5N≤5;
- 对于 100%100% 的数据有 1≤�≤1001≤M≤100,1≤�≤10001≤N≤1000。
思路:队未满,开始入队,并且计数器要加1,队满开始出队和入队,计数器也加一
#include <bits/stdc++.h>
using namespace std;
int main()
{int m,n,cnt=0;cin>>m>>n;queue<int>q;//m是内存队列的长度最多等于m//这题主要难在找,用队列形成进去很简单int ans[1001];memset(ans,0,sizeof(ans));for (int i=0;i<n;++i){int x;cin>>x;if (ans[x]==0 && q.size()<m){q.push(x);ans[x]=1; cnt++;}else if (ans[x]==1)continue;else if (ans[x]==0 && q.size()==m){ans[q.front()]=0;q.pop(); ans[x]=1;q.push(x);cnt++;} }cout<<cnt;
}打印队列 Printer Queuehttps://www.luogu.com.cn/problem/UVA12100
学生会里只有一台打印机,但是有很多文件需要打印,因此打印任务不可避免地需要等待。有些打印任务比较急,有些不那么急,所以每个任务都有一个1~9间的优先级,优先级越高表示任务越急。
打印机的运作方式如下:首先从打印队列里取出一个任务J,如果队列里有比J更急的任务,则直接把J放到打印队列尾部,否则打印任务J(此时不会把它放回打印队列)。 输入打印队列中各个任务的优先级以及所关注的任务在队列中的位置(队首位置为0),输出该任务完成的时刻。所有任务都需要1分钟打印。例如,打印队列为{1,1,9,1,1,1},目前处于队首的任务最终完成时刻为5。
输入T 接下来T组数据 每组数据输入N,TOP。接下来N个数,TOP代表队列首
Translated by @HuangBo
输入输出样例
输入 #1复制
3 1 0 5 4 2 1 2 3 4 6 0 1 1 9 1 1 1
输出 #1复制
1 2 5
思路:用优先队列和普通队列存值,然后按照优先队列的出队顺序找到队列对应的值出队
#include <bits/stdc++.h>
using namespace std;
struct node{int x;int id;
}x2;
priority_queue<int>q;
queue<node>p;
int main()
{int t;cin>>t;while (t--){int m,n;cin>>m>>n;for (int i=0;i<m;++i){int l;cin>>l;q.push(l);p.push(node{l,i});}int tot=0;while (!q.empty()){int x1=q.top(); q.pop();while (x2=p.front(),x2.x!=x1){p.pop();p.push(x2); }p.pop();tot++;if (x2.id==n){cout<<tot<<endl;break;}}while (!p.empty())p.pop();while (!q.empty())q.pop();}
}相关文章:

1.27学习总结
今天做了些队列的题: 1.逛画展(单调队列) 2.打印队列 Printer Queue(优先队列) 3.[NOIP2010 提高组] 机器翻译(模拟队列) 4.求m区间内的最小值(单调队列板子题) 5.日志统计(滑动窗口,双指针) 总结一下&…...

【算法专题】二分查找(进阶)
📑前言 本文主要是二分查找(进阶)的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页放风讲故事 🌄每日…...

开源项目对于新用户和初学者适合哪些工作
目录 一、阅读和理解文档 二、报告问题 三、测试和验证修复 四、编写和更新文档 五、简单的代码更改和修复 六、参与社区讨论 开源项目对于新用户和初学者来说,提供了宝贵的学习和实践机会。以下是一些适合新用户和初学者参与的工作: 一、阅读和理…...

linux中配置文件目录为什么用etc来命名
在早期的 Unix 系统中,/etc 目录的名称确实来源于单词 “etcetera” 的缩写,最初意味着 “其他”,用来存放杂项或者不属于其他特定目录的文件。然而,随着时间的推移,/etc 目录的用途逐渐演变并专门化。 在现代的 Linux…...
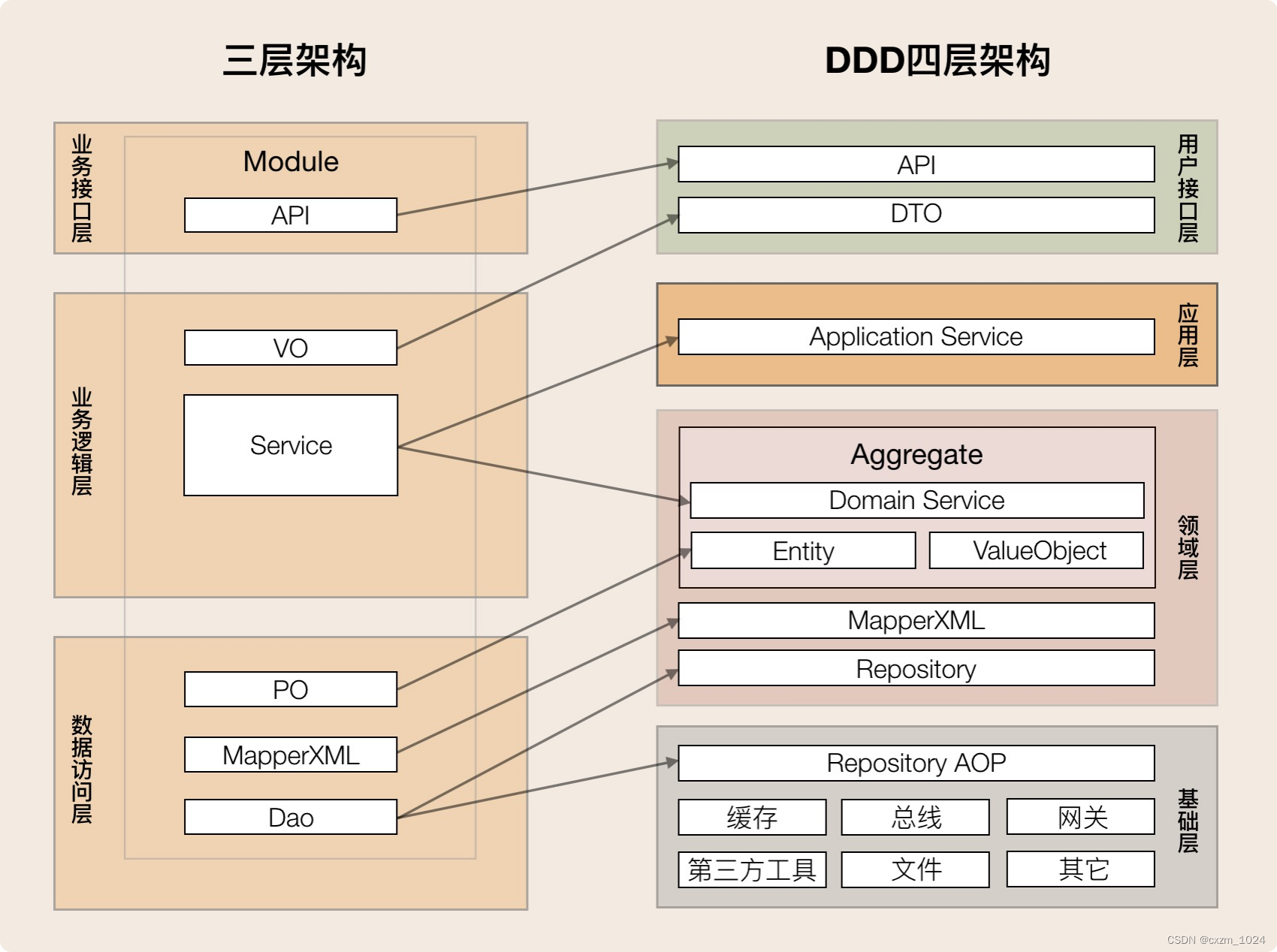
06.领域驱动设计:使用DDD分层架构,可以有效降低层与层之间的依赖
目录 1、概述 2、什么是DDD分层架构 1.用户接口层 2.应用层 3.领域层 4.基础层 3、DDD分层架构最重要的原则是什么 4、DDD分层架构如何推动架构演进 1.微服务架构的演进 2.微服务内服务的演进 5、三层架构如何演进到DDD分层架构 我们该怎样转向DDD分层架构 6、总结…...

HCIA-Datacom实验指导手册:3.2 实验二:生成树基础实验
HCIA-Datacom实验指导手册:3.2 实验二:生成树基础实验 一、实验介绍:二、实验拓扑:三、实验目的:四、配置步骤:步骤 1 掌握启用和禁用 STP/RSTP 的方法步骤 2 掌握修改交换机 STP 模式的方法步骤 3 掌握修改桥优先级,控制根桥选举的方法步骤 4 掌握修改端口优先级,控制…...

WPF的ViewBox控件
在WPF中,ViewBox是一个用于缩放和调整其子元素大小的容器控件。它可以根据可用空间自动调整子元素的大小,以使其适应ViewBox的边界。这使得在不同尺寸的窗口或布局中保持元素的比例和缩放变得更加容易。 ViewBox具有以下重要属性: Stretch&…...
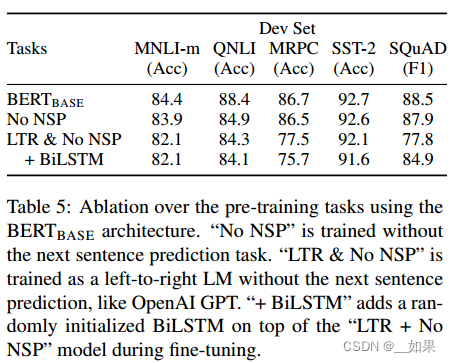
论文精读--BERT
不像视觉领域,在Bert出现之前的nlp领域还没有一个深的网络,使得能在大数据集上训练一个深的神经网络,并应用到很多nlp的任务上 Abstract We introduce a new language representation model called BERT, which stands for Bidirectional En…...

LeetCode第468题 - 验证IP地址
题目 编写一个函数来验证输入的字符串是否是有效的 IPv4 或 IPv6 地址。 IPv4 地址由十进制数和点来表示,每个地址包含4个十进制数,其范围为 0 - 255, 用(“.”)分割。比如,172.16.254.1; 同时,IPv4 地址内…...

淘宝API接口调用:案例分析与最佳实践
在电子商务迅猛发展的今天,淘宝作为中国最大的在线购物平台之一,为商家们提供了强大的数据分析和市场洞察工具——淘宝API。有效的API调用不仅可以提升商家的运营效率,还可以帮助商家更好地理解消费者需求、优化商品布局、提高用户满意度等。…...

中仕教育:事业单位考试考什么?
事业单位考试分为两个阶段,分别是笔试和面试,考试科目包括公共科目和专业科目两部分。 公共科目内容是公共基础知识、职业能力测试或申论。一种形式为:公共基础知识职业能力测试或职业能力测试申论。另一种形式为:公共基础申论。…...

python-自动化篇-运维-监控-简单实例-道出如何使⽤Python进⾏系统监控?
如何使⽤Python进⾏系统监控? 使⽤Python进⾏系统监控涉及以下⼀般步骤: 选择监控指标: ⾸先,确定希望监控的系统指标,这可以包括 CPU 利⽤率、内存使⽤情况、磁盘空间、⽹络流量、服务可⽤性等。选择监控⼯具&#x…...

网络安全科普:SSL证书保护我们的网上冲浪安全
当我们在线上愉快冲浪时,各类网站数不胜数,但是如何判定该站点是安全还是有风险呢? 当当当,SSL数字证书登场!! SSL证书也称为数字证书,是一种用于保护网站和用户之间通信安全的加密协议。由权…...

AOP复习
AOP AOP静态代理动态代理ProxyCGLIB AOP 面向切面编程 优点: 提高代码的可重用性业务代码编码更简洁业务代码维护更高效业务功能扩展更便捷 Joinpoint(连接点)就是方法Pointcut(切入点)就是挖掉共性功能的方法Advice(通知)就是共性功能,最终以一个方法的形式呈现Asp…...

解决 Required Integer parameter ‘uid‘ is not present
1.原因分析 后端没接收到uid可能是前端没传递uid也可能是前端传递了uid,但是传递方式与后端接收方式不匹配,导致没接收到更大的可能是因为后端请求方式错了。比如: 2.解决方案 先确定前端传参方式与后端请求方式是匹配的后端get请求的话…...

Qt/QML编程之路:ListView实现横排图片列表的示例(40)
ListView列表,在QML中使用非常多,排列一个行,一个列或者一个表格,都会用到ListView。 ListView显示从内置QML类型(如ListModel和XmlListModel)创建的模型中的数据,或在C++中定义的从QAbstractItemModel或QAbstract ListModel继承的自定义模型类中的数据。 ListView有一…...

数据分析-Pandas如何用图把数据展示出来
数据分析-Pandas如何用图把数据展示出来 俗话说,一图胜千语,对人类而言一串数据很难立即洞察出什么,但如果展示图就能一眼看出来门道。数据整理后,如何画图,画出好的图在数据分析中成为关键的一环。 数据表ÿ…...
Logistics 逻辑回归概念
1. sigmoid函数 逻辑回归算法的拟合函数,叫做sigmoid函数: 函数图像如下(百度图片搜到的图): sigmoid函数是一个s形曲线,就像是阶跃函数的温和版,阶跃函数在0和1之间是突然的起跳,…...
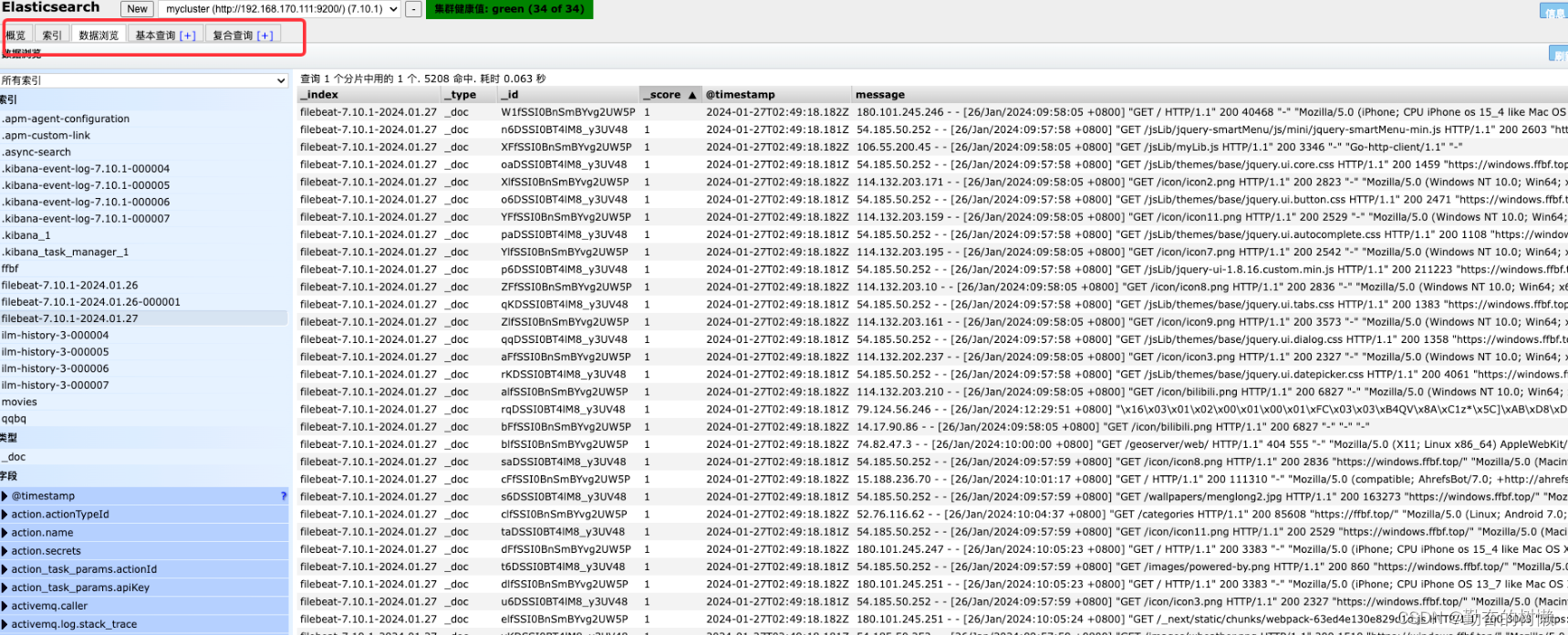
Elasticsearch安装Head图形插件
一、Google浏览器扩展插件方式 1.安装插件 进入谷歌浏览器应用商店搜索“Elasticsearch Head”,点击链接跳转 点击“添加至Chrome”按钮安装即可。 2.使用插件 在浏览器的插件列表多了个一个放大镜图标 点击“New”新建链接,输入es节点或集群地址。 连接成功 可以进行概括…...
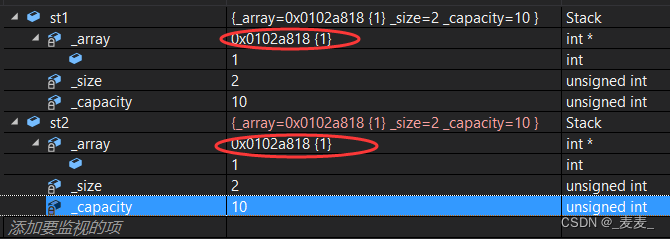
【C++】——类和对象(中)
一、前言 好久没有更新内容了,今天为大家带来类和对形中期的内容 ! 二、正文 1.this指针 1.1this指针的引入 class Date { public:void Init(int year, int month, int day){_year year;_month month;_day day;}void Print(){cout << _year …...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...