游戏中排行榜的后台实现
游戏中经常会有排行榜需求需要实现,例如常见的战力排行榜、积分排行榜等等。
排行榜一般会用到 Redis 来实现,原因是:
- Redis 基于内存操作,速度快
- Redis 提供了高效的有序集合 zset
例如创建一个名为 rank 的排行榜
# 为用户user1设置分数为1
> zadd rank 1 user1# 获取排行榜中全部用户的排名和分数(分数顺序排序)
> zrange rank 0 -1 withscores
1) "user1"
2) "1"
3) "user2"
4) "2"
5) "user3"
6) "3"# 获取排行榜中全部用户的排名和分数(分数倒序排序)
> zrevrange rank 0 -1 withscores
1) "user3"
2) "3"
3) "user2"
4) "2"
5) "user1"
6) "1"# 获取排行榜中排名前2的用户的排名和分数(分数倒序排序)
> zrevrange rank 0 1 withscores
1) "user3"
2) "3"
3) "user2"
4) "2"# 获取排行榜中用户user2的排名
> zrank rank user2
(integer) 1
纵然 redis 的速度很快,但是再加上网络请求的开销和单线程问题,也比不上应用内直接内存的速度,所以为了速度,一般会在游戏内缓存排行榜。获取排行榜时,优先从内存中获取,并定时从 redis 同步数据到内存。
下面是一个简单的例子,实现了获取排行榜信息和用户排名数据。
public class RankTest { @Data @AllArgsConstructor public static class UserRankInfo { private long userID; private int rank; private double score; } /** * 缓存的用户信息 */ private static final Map<Long, UserRankInfo> USER_RANK_INFO_MAP = new ConcurrentHashMap<>(); /** * 上次同步时间 */ private static int LAST_SYNC_TIME = 0; /** * 每隔多长时间从redis同步一次 */ private static final int SYNC_EVERY_SECOND = 60 * 10; /** * 获取排行榜 */ public Collection<UserRankInfo> getRankList() { if ((int) (System.currentTimeMillis() / 1000) > LAST_SYNC_TIME + SYNC_EVERY_SECOND) { syncUserRankInfoMap(); } return USER_RANK_INFO_MAP.values(); }private void syncUserRankInfoMap() { try (Jedis jedis = new Jedis("127.0.0.1", 6379);) { // 获取前50名的用户 Set<Tuple> tuples = jedis.zrevrangeWithScores("rank", 0, 49); putUserRankInfoMap(tuples); LAST_SYNC_TIME = (int) (System.currentTimeMillis() / 1000); } } private void putUserRankInfoMap(Set<Tuple> tuples) { USER_RANK_INFO_MAP.clear(); int rank = 0; for (Tuple tuple : tuples) { long userID = Long.parseLong(tuple.getElement()); UserRankInfo info = new UserRankInfo(userID, rank++, tuple.getScore()); USER_RANK_INFO_MAP.put(userID, info); } } /** * 获取用户排名信息 */ public UserRankInfo getUserRankInfo(long userID) { if ((int) (System.currentTimeMillis() / 1000) > LAST_SYNC_TIME + SYNC_EVERY_SECOND) { syncUserRankInfoMap(); } return USER_RANK_INFO_MAP.get(userID); } /** * 设置用户分数 */ public void setUserRankScore(long userID,double score){ try (Jedis jedis = new Jedis("127.0.0.1", 6379);) { jedis.zadd("rank", score, String.valueOf(userID)); // 获取前50名的用户 Set<Tuple> tuples = jedis.zrevrangeWithScores("rank", 0, 49); putUserRankInfoMap(tuples); LAST_SYNC_TIME = (int) (System.currentTimeMillis() / 1000); } }
}
开发中,上面的例子还存在不少问题:
- 因为 redis 操作比较耗时,所以一般都会放在异步线程中进行操作
- 缓存数据的更新不是原子的,一旦多个用户同时请求,可能会导致数据重复更新多次
- 相同的分数的用户的排名会按照用户名来排序
针对于问题 3,因为用户在相同分数的情况下, redis 只支持根据用户名的字典排序,并不支持自定义排序。但是这对玩家来说是不可接受的。一个解决办法让相同分数的玩家按照达成时间的判断,最先抵达的玩家排名最高。
我们可以使用(真实分数 + 时间戳倒数)作为排名分数,真实分数作为整数部分,时间戳倒数作为小数部分。
public void setUserRankScore(long userID,int score){ try (Jedis jedis = new Jedis("127.0.0.1", 6379);) { //因为毫秒时间戳最多有13位 double newScore=score+1000_000_000_000.0D/System.currentTimeMillis(); jedis.zadd("rank", newScore, String.valueOf(userID)); // 获取前50名的用户 Set<Tuple> tuples = jedis.zrevrangeWithScores("rank", 0, 49); putUserRankInfoMap(tuples); LAST_SYNC_TIME = (int) (System.currentTimeMillis() / 1000); }
}
参考:
- Redis sorted sets | Redis
- Redis实现排行榜及相同积分按时间排序 - 知乎
- Redis 浮点数累计实现-腾讯云开发者社区-腾讯云
相关文章:

游戏中排行榜的后台实现
游戏中经常会有排行榜需求需要实现,例如常见的战力排行榜、积分排行榜等等。 排行榜一般会用到 Redis 来实现,原因是: Redis 基于内存操作,速度快Redis 提供了高效的有序集合 zset 例如创建一个名为 rank 的排行榜 # 为用户use…...

《动手学深度学习(PyTorch版)》笔记3.1
Chapter3 Linear Neural Networks 3.1 Linear Regression 3.1.1 Basic Concepts 我们通常使用 n n n来表示数据集中的样本数。对索引为 i i i的样本,其输入表示为 x ( i ) [ x 1 ( i ) , x 2 ( i ) , . . . , x n ( i ) ] ⊤ \mathbf{x}^{(i)} [x_1^{(i)}, x_2…...
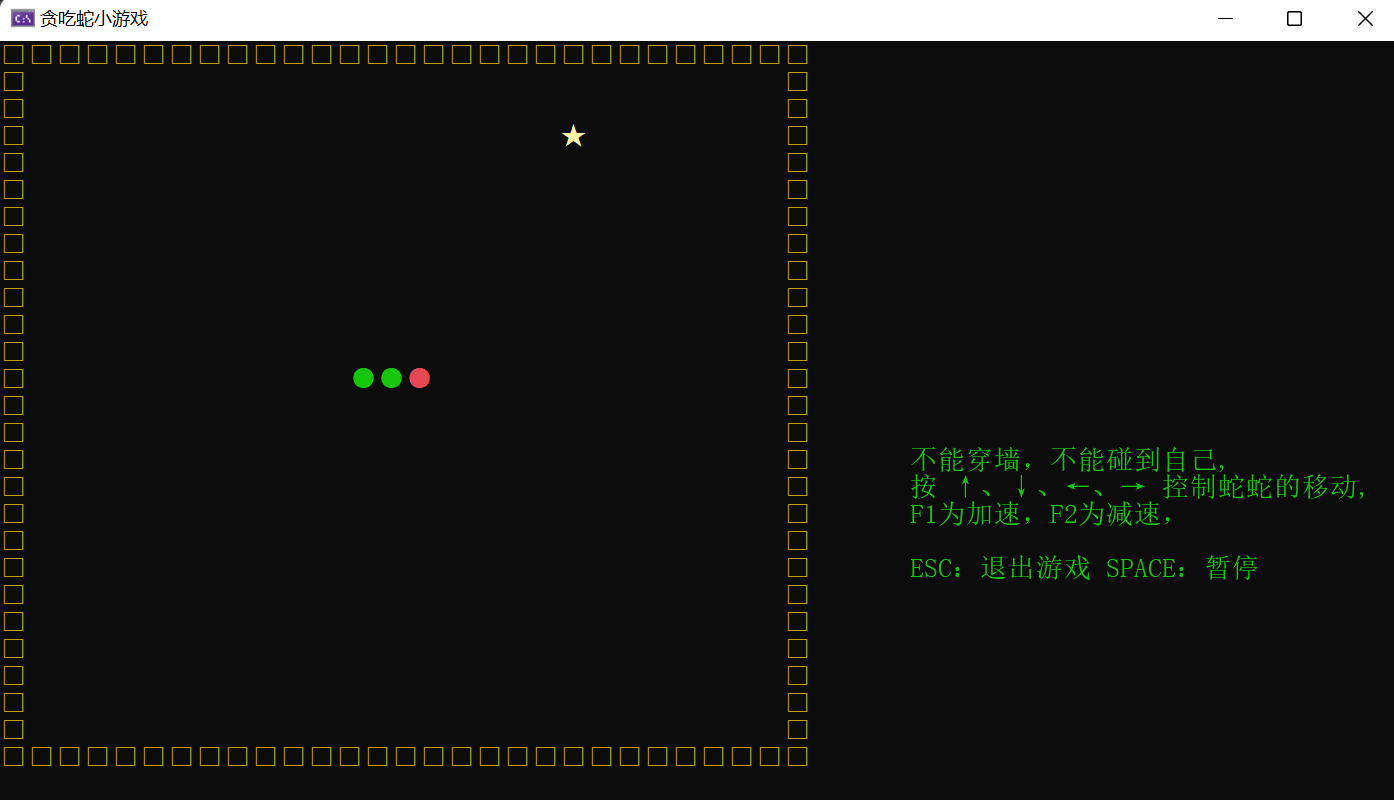
【贪吃蛇:C语言实现】
文章目录 前言1.了解Win32API相关知识1.1什么是Win32API1.2设置控制台的大小、名称1.3控制台上的光标1.4 GetStdHandle(获得控制台信息)1.5 SetConsoleCursorPosition(设置光标位置)1.6 GetConsoleCursorInfo(获得光标…...
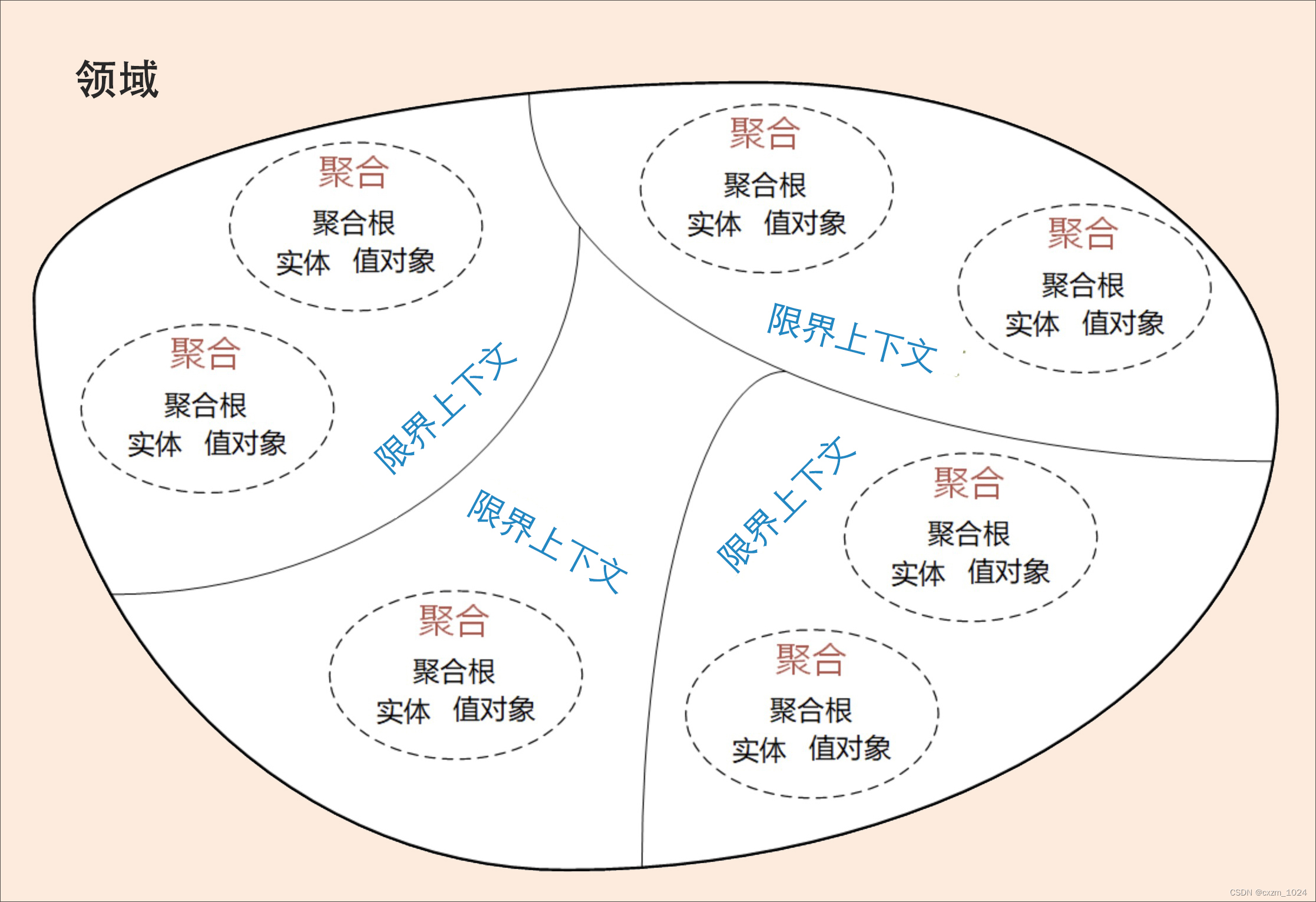
01.领域驱动设计:微服务设计为什么要选择DDD学习总结
目录 1、前言 2、软件架构模式的演进 3、微服务设计和拆分的困境 4、为什么 DDD适合微服务 5、DDD与微服务的关系 6、总结 1、前言 我们知道,微服务设计过程中往往会面临边界如何划定的问题,不同的人会根据自己对微服务的理 解而拆分出不同的微服…...
写静态页面——魅族导航_前端页面练习
0、效果: 1、html代码:: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><…...

Go 命令行解析 flag 包之快速上手
本篇文章是 Go 标准库 flag 包的快速上手篇。 概述 开发一个命令行工具,视复杂程度,一般要选择一个合适的命令行解析库,简单的需求用 Go 标准库 flag 就够了,flag 的使用非常简单。 当然,除了标准库 flag 外&#x…...
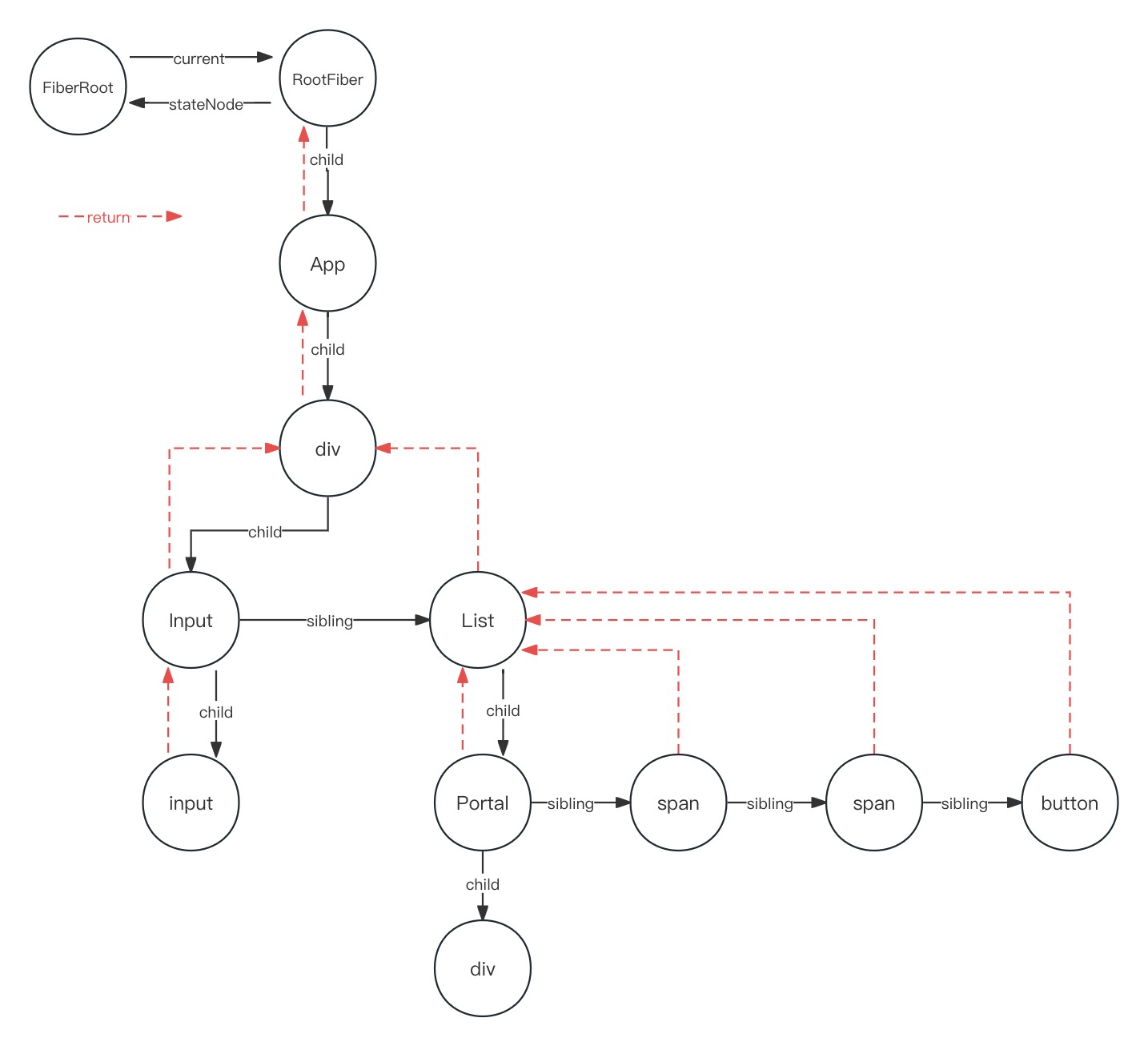
React16源码: React中commitAllHostEffects内部的commitDeletion的源码实现
commitDeletion 1 )概述 在 react commit 阶段的 commitRoot 第二个while循环中调用了 commitAllHostEffects,这个函数不仅仅处理了新增节点,更新节点最后一个操作,就是删除节点,就需要调用 commitDeletion࿰…...
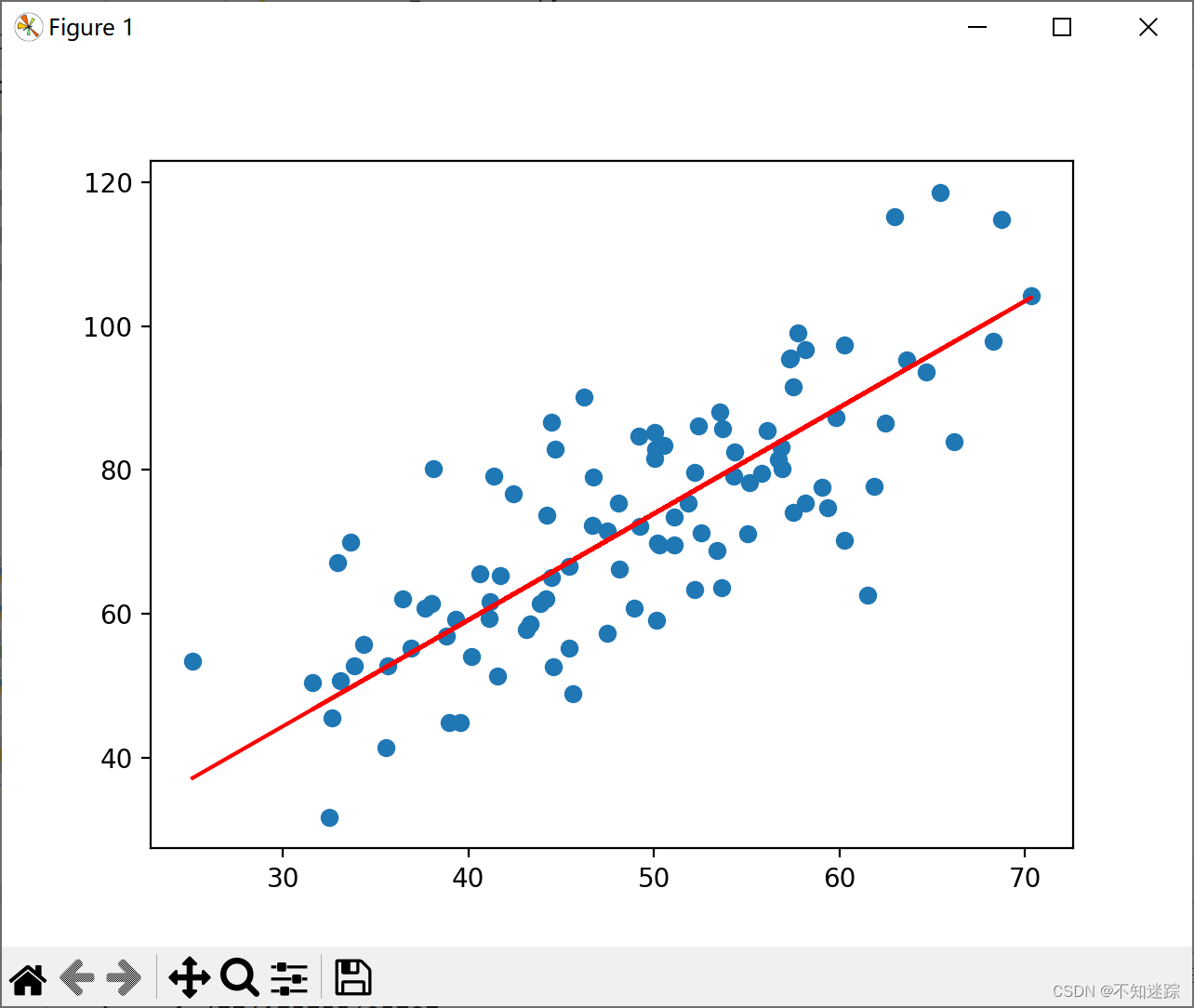
[机器学习]简单线性回归——梯度下降法
一.梯度下降法概念 2.代码实现 # 0. 引入依赖 import numpy as np import matplotlib.pyplot as plt# 1. 导入数据(data.csv) points np.genfromtxt(data.csv, delimiter,) points[0,0]# 提取points中的两列数据,分别作为x,y …...
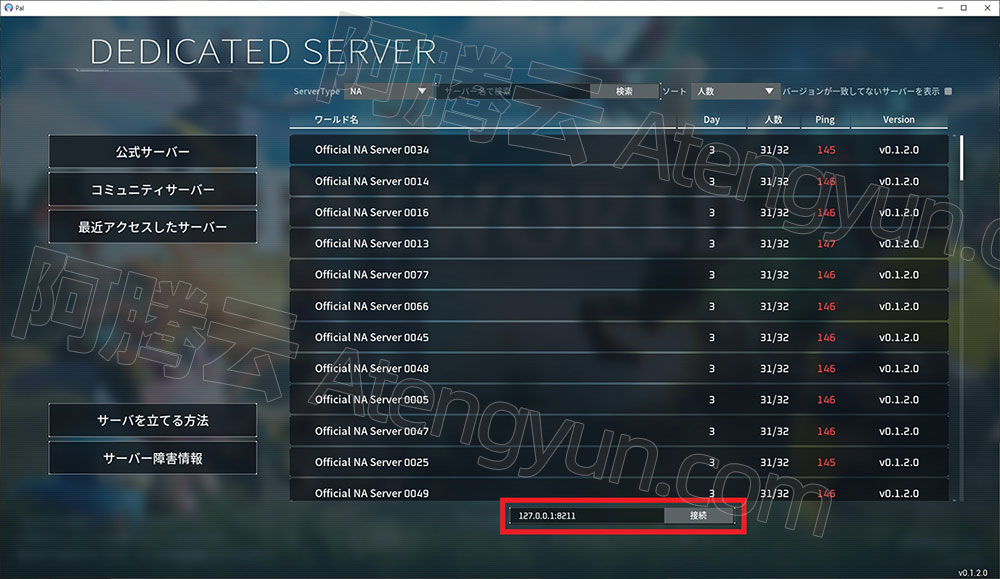
2024年搭建幻兽帕鲁服务器价格多少?如何自建Palworld?
自建幻兽帕鲁服务器租用价格表,2024阿里云推出专属幻兽帕鲁Palworld游戏优惠服务器,配置分为4核16G和4核32G服务器,4核16G配置32.25元/1个月、3M带宽96.75元/1个月、8核32G配置10M带宽90.60元/1个月,8核32G配置3个月271.80元。ECS…...
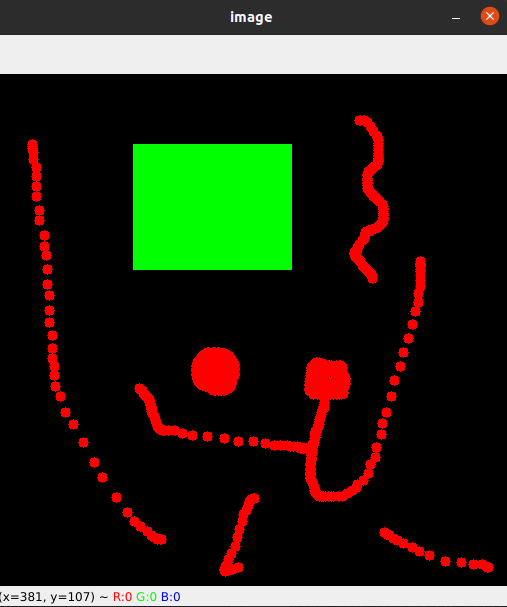
『OpenCV-Python|鼠标作画笔』
Opencv-Python教程链接:https://opencv-python-tutorials.readthedocs.io/ 本文主要介绍OpenCV-Python如何将鼠标作画笔绘制圆或者矩形。 示例一:图片上双击的位置绘制一个圆圈 首先创建一个鼠标事件回调函数,鼠标事件发生时就会被执行。鼠标…...

关于如何利用ChatGPT提高编程效率的
自从去年ChatGPT3.5推出以后,这一年时间在编程过程中我也在慢慢熟悉人工智能的使用,目前来看即使是免费的ChatGPT3.5对于编程效率的提升也是有很大帮助的,虽然在使用过程中确实出现了一些问题,本文记录下我的一些心得体会和用法。…...

Excel VBA ——从MySQL数据库中导出一个报表-笔记
本文主要涉及: VBA中数据库连接参数改成从配置文件获取 VBA连接MySQL数据库 VBA读MySQL数据库 演示两种写入工作簿的代码实现系统环境: Windows 10 64bit Excel 365 64bit WAMP(3.2.2.2 64bit)集成的MariaDB版本为10.4.10&#…...

金融OCR领域实习日志(一)——OCR技术从0到1全面调研
一、OCR基础 任务要求: 工作原理 OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相)检查纸上打印的字符,经过检测暗、亮的模式肯定其形状,而后用…...
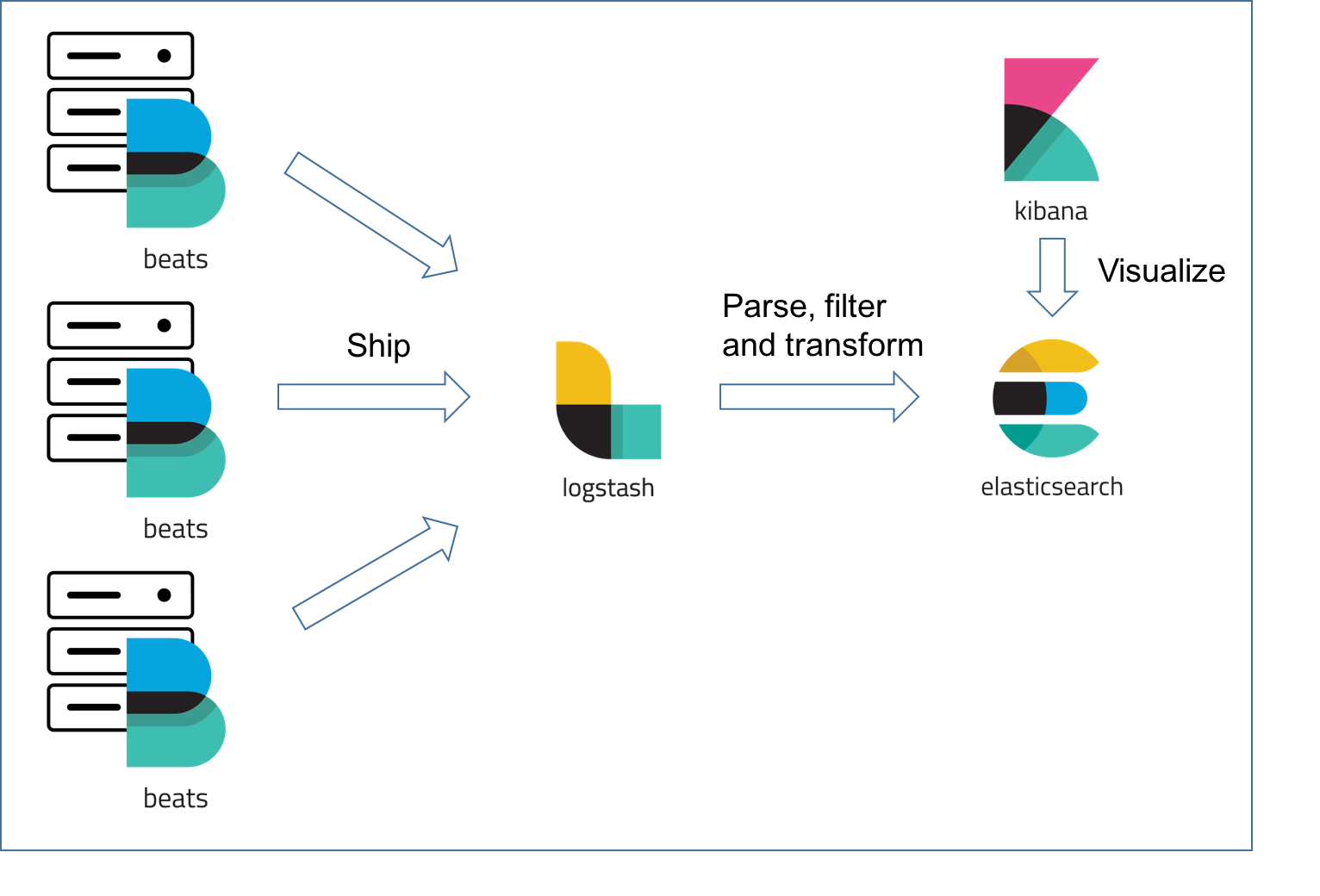
ELK日志解决方案
ELK日志解决方案 ELK套件日志系统应该是Elasticsearch使用最广泛的场景之一了,Elasticsearch支持海量数据的存储和查询,特别适合日志搜索场景。广泛使用的ELK套件(Elasticsearch、Logstash、Kibana)是日志系统最经典的案例,使用Logstash和Be…...

嵌入式学习-驱动
嵌入式的一些基本概念 CPU与MCU的区别 CPU(中央处理器,central processing unit) 指集成了运算器、控制器、寄存器、高速缓存等功能模块的芯片,负责执行计算机程序指令的处理器。MCU(单片微型计算机或单片机,microco…...

系统架构17 - 软件工程(5)
软件工程 软件测试测试原则测试方法静态测试动态测试黑盒测试白盒测试灰盒测试自动化测试 测试阶段单元测试集成测试系统测试性能测试验收测试其它测试AB测试Web测试链接测试表单测试 测试用例设计黑盒测试用例白盒测试用例 调试 系统维护遗留系统系统转换转换方式数据转换与迁…...
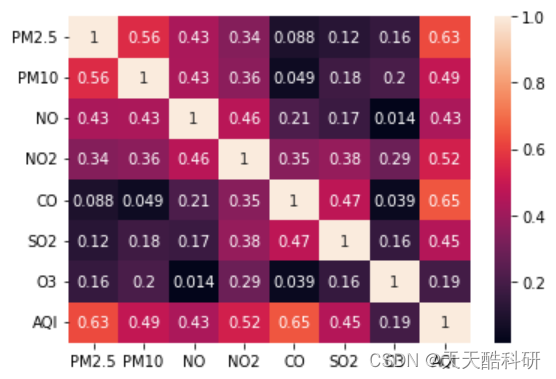
空气质量预测 | Python实现基于线性回归、Lasso回归、岭回归、决策树回归的空气质量预测模型
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 政府机构使用空气质量指数 (AQI) 向公众传达当前空气污染程度或预测空气污染程度。 随着 AQI 的上升,公共卫生风险也会增加。 不同国家有自己的空气质量指数,对应不同国家的空气质量标准。 对于空气质量预测,…...

MYSQL数据库基本操作-DQL-基本查询
一.概念 数据库管理系统一个重要功能就是数据查询。数据查询不应是简单返回数据库中存储的数据,还应该根据需要对数据进行筛选以及确定数据以什么样的格式显示。 MySQL提供了功能强大,灵活的语句来实现这些操作。 MySQL数据库使用select语句来查询数据…...

gdb 调试 - 在vscode图形化展示在远程的gdb debug过程
前言 本地机器的操作系统是windows,远程机器的操作系统是linux,开发在远程机器完成,本地只能通过ssh登录到远程。现在目的是要在本地进行图形化展示在远程的gdb debug过程。(注意这并不是gdb remote !!&am…...
Android 13.0 SystemUI下拉状态栏定制二 锁屏页面横竖屏时钟都居中功能实现二
1.前言 在13.0的系统rom定制化开发中,在关于systemui的锁屏页面功能定制中,由于在平板横屏锁屏功能中,时钟显示的很大,并且是在左旁边居中显示的, 由于需要和竖屏显示一样,所以就需要用到小时钟显示,然后同样需要居中,所以就来分析下相关的源码,来实现具体的功能 如图…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

免费抓包工具选型指南:Wireshark、Fiddler、mitmproxy、Charles实战对比
1. 抓包工具不是“黑科技”,而是网络世界的显微镜很多人第一次听说“抓包”,脑子里立刻浮现出黑客电影里满屏滚动的绿色代码、键盘敲得噼啪作响、三秒破解银行防火墙的画面。其实完全不是这样——抓包(Packet Capture)本质上就是把…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

基于PIC32单片机实现Android USB音频转SPDIF输出的DIY方案
1. 项目概述:为Android设备打造一个高保真SPDIF音频接口作为一名长期折腾嵌入式音频和家庭影院的玩家,我经常遇到一个痛点:手头那些性能不错的Android手机或平板,其内置的3.5mm耳机孔或者USB-C口的音频输出质量,在连接…...

JMeter实现RSA签名验签全流程实战
1. 为什么RSA加密接口测试总卡在“连通但失败”这一步? 你有没有遇到过这种情况:接口文档写得清清楚楚,Postman里填好URL、Header、Body,一发请求——返回 {"code":4001,"msg":"签名验证失败"} …...

Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南
Safe Exam Browser虚拟机绕过实战:深度解析与安全研究指南 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在数字化教育快速发展的今天&…...

C语言预处理指令全解析
第六章 预处理命令在c语言中,所有# 开头的指令,被称为预处理指令。gcc 编译预处理 所有的预处理指令,都要在这步处理完汇编编译连接#include包含头文件。 全局变量的声明,函数的声明, 自定义构造类型声明, …...