《动手学深度学习(PyTorch版)》笔记5
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过,对于书上部分章节也做了整合。
Chapter5 Deep Learning Computation
5.1 Layers and Blocks
import torch
from torch import nn
from torch.nn import functional as Fnet = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))X = torch.rand(2, 20)#2行20列的张量,值为[0,1)内的随机数
#print(net(X))#自定义块
class MLP(nn.Module):# 用模型参数声明层,这里声明两个全连接层def __init__(self):# 调用MLP的父类Module的构造函数来执行必要的初始化。# 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍)super().__init__()self.hidden = nn.Linear(20, 256) # 隐藏层self.out = nn.Linear(256, 10) # 输出层# 定义模型的前向传播,即如何根据输入X返回所需的模型输出def forward(self, X):# 这里使用ReLU的函数版本,其在nn.functional模块中定义。return self.out(F.relu(self.hidden(X)))net = MLP()
print(net(X))#自定义顺序块
class MySequential(nn.Module):def __init__(self, *args):super().__init__()for idx, module in enumerate(args):#module是Module子类的一个实例,保存在'Module'类的成员变量_modules中。_module的类型是OrderedDictself._modules[str(idx)] = moduledef forward(self, X):# OrderedDict保证了按照成员添加的顺序遍历它们for block in self._modules.values():X = block(X)return Xnet = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
print(net(X))#自定义权重为常数的隐藏层
class FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()# 不计算梯度的随机权重参数。因此其在训练期间保持不变self.rand_weight = torch.rand((20, 20), requires_grad=False)self.linear = nn.Linear(20, 20)def forward(self, X):X = self.linear(X)# 使用创建的常量参数以及relu和mm函数X = F.relu(torch.mm(X, self.rand_weight) + 1)# 复用全连接层。这相当于两个全连接层共享参数X = self.linear(X)# 下面代码演示如何把代码集成到网络计算流程中while X.abs().sum() > 1:X /= 2return X.sum()net = FixedHiddenMLP()
print(net(X))#嵌套块
class NestMLP(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),nn.Linear(64, 32), nn.ReLU())self.linear = nn.Linear(32, 16)def forward(self, X):return self.linear(self.net(X))chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
print(chimera(X))
5.2 Parameter Management
import torch
from torch import nnnet = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
#print(net(X))#查看第二个全连接层的参数
print(net[2].state_dict())
print(type(net[2].bias))
print(net[2].bias)
print(net[2].bias.data)
print(net.state_dict()['2.bias'].data)#此行作用和上行相同#访问第一个全连接层的参数和访问所有层
print(*[(name, param.shape) for name, param in net[0].named_parameters()])
print(*[(name, param.shape) for name, param in net.named_parameters()])
#由于没有在nn.Sequential中明确指定ReLU层的权重和偏置,因此它们在输出中没有被显示#从嵌套块收集参数
def block1():return nn.Sequential(nn.Linear(4, 8), nn.ReLU(),nn.Linear(8, 4), nn.ReLU())def block2():net = nn.Sequential()for i in range(4):# 在这里嵌套net.add_module(f'block {i}', block1())return netrgnet = nn.Sequential(block2(), nn.Linear(4, 1))
print(rgnet(X))
print(rgnet)
print(rgnet[0][1][0].bias.data)#用内置函数进行参数初始化
def init_normal(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, mean=0, std=0.01)nn.init.zeros_(m.bias)
net.apply(init_normal)
print(net[0].weight.data[0], net[0].bias.data[0])def init_constant(m):if type(m) == nn.Linear:nn.init.constant_(m.weight, 1)#初始化参数为常数1nn.init.zeros_(m.bias)
net.apply(init_constant)
print(net[0].weight.data[0], net[0].bias.data[0])def init_xavier(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)
def init_42(m):if type(m) == nn.Linear:nn.init.constant_(m.weight, 42)net[0].apply(init_xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)##只有一层
在下面的例子中,我们使用以下的分布为任意权重参数 w w w定义初始化方法:
w ∼ { U ( 5 , 10 ) possibility= 1 4 0 possibility= 1 2 U ( − 10 , − 5 ) possibility= 1 4 \begin{aligned} w \sim \begin{cases} U(5, 10) & \text{ possibility=} \frac{1}{4} \\ 0 & \text{ possibility=} \frac{1}{2} \\ U(-10, -5) & \text{ possibility=} \frac{1}{4} \end{cases} \end{aligned} w∼⎩ ⎨ ⎧U(5,10)0U(−10,−5) possibility=41 possibility=21 possibility=41
def my_init(m):if type(m) == nn.Linear:print("Init", *[(name, param.shape)for name, param in m.named_parameters()][0])nn.init.uniform_(m.weight, -10, 10)m.weight.data *= m.weight.data.abs() >= 5net.apply(my_init)print(net[0].weight[:2])net[0].weight.data[:] += 1net[0].weight.data[0, 0] = 42print(net[0].weight.data[0])
#参数绑定#我们需要给共享层一个名称,以便可以引用它的参数shared = nn.Linear(8, 8)net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(),shared, nn.ReLU(),shared, nn.ReLU(),nn.Linear(8, 1))net(X)#检查参数是否相同print(net[2].weight.data[0] == net[4].weight.data[0])net[2].weight.data[0, 0] = 100#确保它们实际上是同一个对象,而不只是有相同的值print(net[2].weight.data[0] == net[4].weight.data[0])
注:在PyTorch中,模型的权重通常在实例化时就进行初始化,但有时候我们希望将权重的初始化推迟到模型第一次被调用的时候(比如有些模型的输入尺寸只有在实际输入数据时才能确定),这时候框架会自动使用延后初始化(deferred initialization)来解决这个问题。
5.3 Custom Layers
import torch
from torch import nn
from torch.nn import functional as Fnet = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))X = torch.rand(2, 20)#2行20列的张量,值为[0,1)内的随机数
#print(net(X))#自定义块
class MLP(nn.Module):# 用模型参数声明层,这里声明两个全连接层def __init__(self):# 调用MLP的父类Module的构造函数来执行必要的初始化。# 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍)super().__init__()self.hidden = nn.Linear(20, 256) # 隐藏层self.out = nn.Linear(256, 10) # 输出层# 定义模型的前向传播,即如何根据输入X返回所需的模型输出def forward(self, X):# 这里使用ReLU的函数版本,其在nn.functional模块中定义。return self.out(F.relu(self.hidden(X)))net = MLP()
print(net(X))#自定义顺序块
class MySequential(nn.Module):def __init__(self, *args):super().__init__()for idx, module in enumerate(args):#module是Module子类的一个实例,保存在'Module'类的成员变量_modules中。_module的类型是OrderedDictself._modules[str(idx)] = moduledef forward(self, X):# OrderedDict保证了按照成员添加的顺序遍历它们for block in self._modules.values():X = block(X)return Xnet = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
print(net(X))#自定义权重为常数的隐藏层
class FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()# 不计算梯度的随机权重参数。因此其在训练期间保持不变self.rand_weight = torch.rand((20, 20), requires_grad=False)self.linear = nn.Linear(20, 20)def forward(self, X):X = self.linear(X)# 使用创建的常量参数以及relu和mm函数X = F.relu(torch.mm(X, self.rand_weight) + 1)# 复用全连接层。这相当于两个全连接层共享参数X = self.linear(X)# 下面代码演示如何把代码集成到网络计算流程中while X.abs().sum() > 1:X /= 2return X.sum()net = FixedHiddenMLP()
print(net(X))#嵌套块
class NestMLP(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),nn.Linear(64, 32), nn.ReLU())self.linear = nn.Linear(32, 16)def forward(self, X):return self.linear(self.net(X))chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
print(chimera(X))#由于可能两个维度的计算结果都小于等于0,因此结果可能是tensor([[0.],[0.]])
5.4 File I/O
import torch
from torch import nn
from torch.nn import functional as Fx = torch.arange(4)
torch.save(x, 'x-file')
x2 = torch.load('x-file')
print(x2)y = torch.zeros(4)
torch.save([x, y],'x-files')
x2, y2 = torch.load('x-files')
print(x2, y2)mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
print(mydict2)class MLP(nn.Module):def __init__(self):super().__init__()self.hidden = nn.Linear(20, 256)self.output = nn.Linear(256, 10)def forward(self, x):return self.output(F.relu(self.hidden(x)))net = MLP()
X = torch.randn(size=(2, 20))
Y = net(X)torch.save(net.state_dict(), 'mlp.params')#保存模型参数
clone = MLP()
clone.load_state_dict(torch.load('mlp.params'))
print(clone.eval())
#clone.eval()的目的是切换到评估模式,以确保在加载完模型参数后,模型的行为与推断时一致。
#在训练模式下,某些层的行为可能会导致不同的输出,因此通过切换到评估模式来避免这种不一致性。
Y_clone = clone(X)
print(Y_clone)
print(Y_clone == Y)
5.5 GPU Management
import torch
from torch import nnprint(torch.device('cpu'), torch.device('cuda'), torch.device('cuda:1'))
print(torch.cuda.device_count())#查询可用gpu的数量def try_gpu(i=0): #@save"""如果存在,则返回gpu(i),否则返回cpu()"""if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')def try_all_gpus(): #@save"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""devices = [torch.device(f'cuda:{i}')for i in range(torch.cuda.device_count())]return devices if devices else [torch.device('cpu')]print(try_gpu(), try_gpu(10), try_all_gpus())x = torch.tensor([1, 2, 3])#张量是默认在CPU上创建的
print(x.device)
X = torch.ones(2, 3, device=try_gpu())
print(X)
Y = torch.rand(2, 3, device=try_gpu(1))
print(Y)Z = X.cuda(1)#在gpu(1)创建X的一个副本Z
print(Z)net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())#将模型参数放在GPU上
print(net(X))
print(net[0].weight.data.device)
相关文章:
》笔记5)
《动手学深度学习(PyTorch版)》笔记5
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过,…...

QT中wchar_t类型如何输出
在Qt中,通常使用QString来处理字符串,而不是wchar_t。QString是Qt中用于处理Unicode字符串的类。如果你有wchar_t类型的字符串,你可以将其转换为QString进行输出。 以下是一个简单的例子: #include <QCoreApplication> #i…...
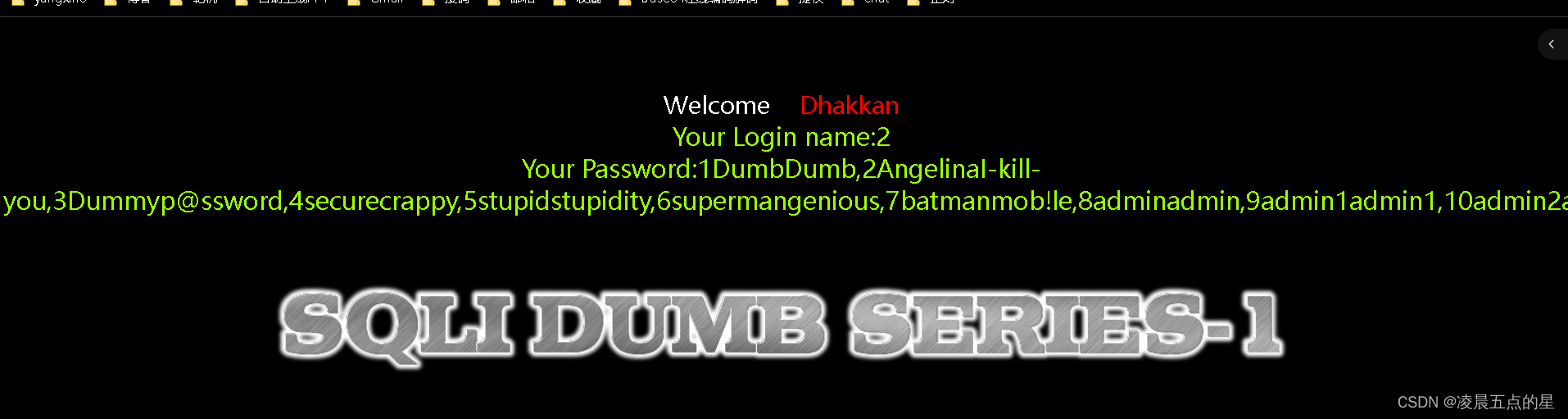
网络安全04-sql注入靶场第一关
目录 一、环境准备 1.1我们进入第一关也如图: 编辑 二、正式开始第一关讲述 2.1很明显它让我们在标签上输入一个ID,那我们就输入在链接后面加?id1 编辑 2.2链接后面加个单引号()查看返回的内容,127.0.0.1/sqli/less-1/?id1,id1 …...
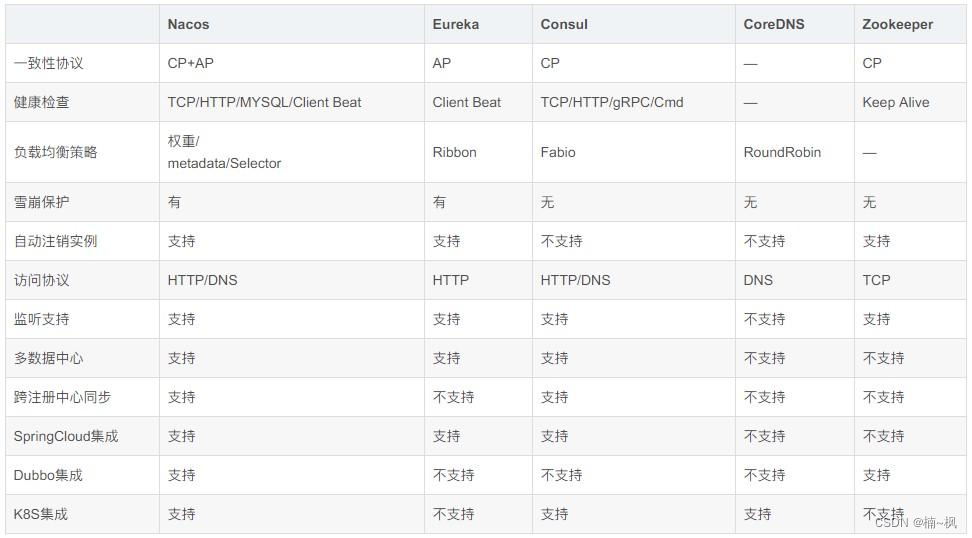
微服务理解篇
一 :架构演变 1 单体架构: 简单理解为一个服务涵盖所有需求功能2 垂直架构: 按照业务功能将单体架构拆分成小模块服务, 如:订单系统,用户系统,商品系统 ##缺点 引入分布式事务,分布式锁等,优点:模块解耦## 垂直拆分:根据业务层级拆分,比如商城的订单系统,用户系统,商品系统…...

项目篇:基于TCP通信模型的外卖软件实现
一、基本成员及功能实现 本项目主要由服务器,消费者,商家,外卖员组成。基本的功能如下。 对所有人: 1、可以注册登录 2、可以修改个人信息 3、可以销户 商家: 1、注册时需要填写售卖商品信息 2、可以修改商品信…...

深入浅出 diffusion(2):pytorch 实现 diffusion 加噪过程
我在上篇博客深入浅出 diffusion(1):白话 diffusion 原理(无公式)中介绍了 diffusion 的一些基本原理,其中谈到了 diffusion 的加噪过程,本文用pytorch 实现下到底是怎么加噪的。 import torch…...
【软件测试】学习笔记-构建并执行 JMeter 脚本的正确姿势
有些团队在组建之初往往并没有配置性能测试人员,后来随着公司业务体量的上升,开始有了性能测试的需求,很多公司为了节约成本会在业务测试团队里选一些技术能力不错的同学进行性能测试,但这些同学也是摸着石头过河。他们会去网上寻…...
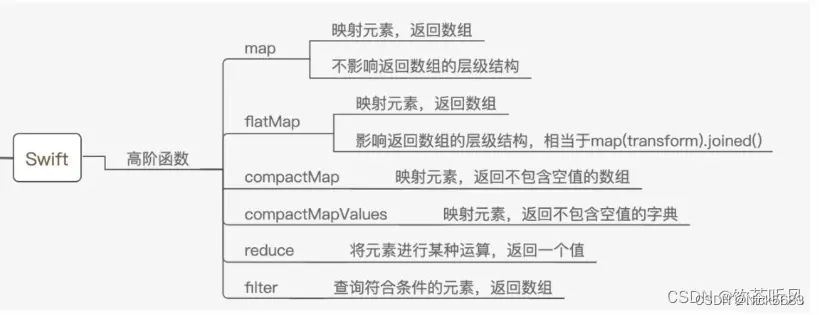
iOS 面试 Swift基础题
一、Swift 存储属性和计算属性比较: 存储型属性:用于存储一个常量或者变量 计算型属性: 计算性属性不直接存储值,而是用 get / set 来取值 和 赋值,可以操作其他属性的变化. 计算属性可以用于类、结构体和枚举,存储属性只能用于类和结构体。存储属性可…...

(七)for循环控制
文章目录 用法while的用法for的用法两者之间的联系可以相互等价用for改写while示例for和while的死循环怎么写for循环见怪不怪表达式1省略第一.三个表达式省略(for 改 while)全省略即死循环(上面已介绍) 用法 类比学习while语句 …...
ASP .NET Core Api 使用过滤器
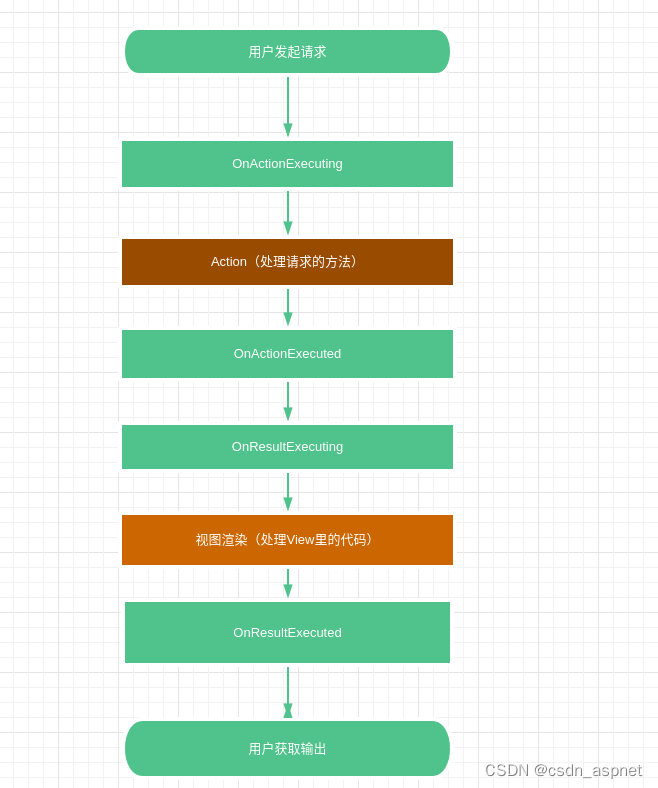
过滤器说明 过滤器与中间件很相似,过滤器(Filters)可在管道(pipeline)特定阶段(particular stage)前后执行操作。可以将过滤器视为拦截器(interceptors)。 过滤器级别范围…...
CodeGPT--(Visual )
GitCode - 开发者的代码家园 gitcode.com/ inscode.csdn.net/liujiaping/java_1706242128563/edit?openFileMain.java&editTypelite marketplace.visualstudio.com/items?itemNameCSDN.csdn-codegpt&spm1018.2226.3001.9836&extra%5Butm_source%5Dvip_chatgpt_c…...
1.Mybatis入门
目录 前言 1入门 1.1 入门程序实现 1.2 数据准备 编辑 1.3 配置Mybatis 1.4 编写SQL语句 1.5 单元测试 1.6 解决SQL警告与提示 2. JDBC介绍(了解) 2.1 介绍 2.2 代码 2.3 问题分析 2.4 技术对比 3. 数据库连接池 3.1 介绍 3.2 产品 4. lombok 4.1 介绍 4.…...
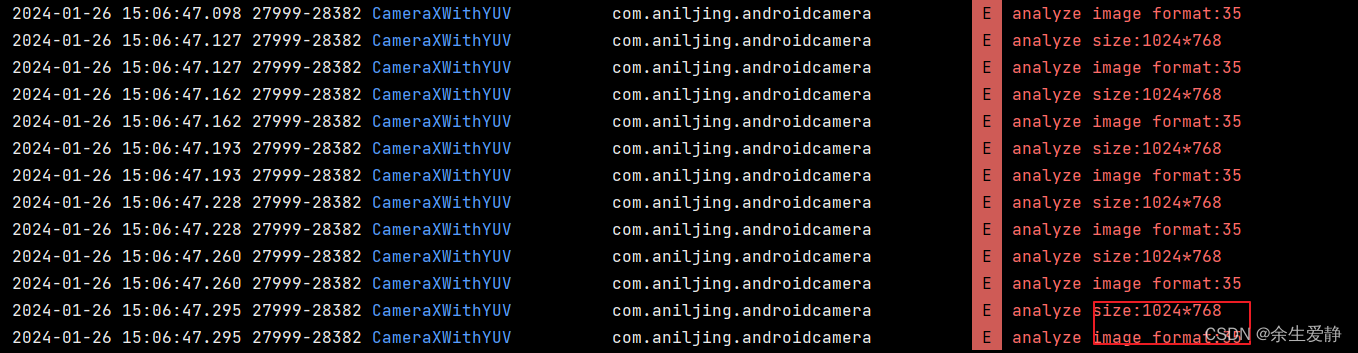
android camera系列(Camera1、Camera2、CameraX)的使用以及输出的图像格式
一、Camera 1.1、结合SurfaceView实现预览 1.1.1、布局 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:app"http://schemas.android.com/apk/res-au…...

live555搭建流式rtsp服务器
源代码已上传gitee 一、需求 live555源代码中的liveMediaServer是将本地文件作为源文件搭建rtsp服务器,我想用live555封装一个第三方库,接收流数据搭建Rtsp服务器;预想接口如下: class LiveRtspServer { public:/***brief构造一…...

Apache孵化器领路人与导师的职责
对于捐赠到 ASF 孵化器的项目来说, ASF 孵化器项目管理委员会(IPMC)的成员会扮演两个角色,一个 孵化器领路人(Champion),另外一个是孵化器导师(Mentor)。 本文源自 ALC …...
【C++中STL】set/multiset容器
set/multiset容器 Set基本概念set构造和赋值set的大小和交换set的插入和删除set查找和统计 set和multiset的区别pair对组两种创建方式 set容器排序 Set基本概念 所有元素都会在插入时自动被排序。 set/multist容器属于关联式容器,底层结构属于二叉树。 set不允许容…...

使用 create-react-app 创建 react 应用
一、创建项目并启动 第一步:全局安装:npm install -g create-react-app 第二步:切换到想创建项目的目录,使用命令create-react-app hello-react 第三步:进入项目目录,cd hello-react 第四步:启…...

obs-studio 源码学习 obs.h
obs.h 引用头文件介绍 c99defs.h:这个头文件提供了一些 C99 标准的定义和声明,包括一些常用的宏定义和类型定义,用于提高代码的可移植性和兼容性。 bmem.h:这个头文件提供了对内存分配和管理的功能,包括一些内存分配…...
C语言-指针的基本知识(上)
一、关于内存 存储器:存储数据器件 外存 外存又叫外部存储器,长期存放数据,掉电不丢失数据 常见的外存设备:硬盘、flash、rom、u盘、光盘、磁带 内存 内存又叫内部存储器,暂时存放数据,掉电数据…...

4核16G幻兽帕鲁服务器优惠价格表,阿里云和腾讯云报价
幻兽帕鲁服务器价格多少钱?4核16G服务器Palworld官方推荐配置,阿里云4核16G服务器32元1个月、96元3个月,腾讯云幻兽帕鲁服务器服务器4核16G14M带宽66元一个月、277元3个月,8核32G22M配置115元1个月、345元3个月,16核64…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...

3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南
3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

基于ESP8266与RGBDigit的Wi-Fi网络时钟:硬件设计、物联网集成与DIY实践
1. 项目概述:一个能感知环境的网络时钟如果你和我一样,对复古又带点科技感的显示设备没有抵抗力,同时又是个喜欢动手折腾的极客,那么这个项目绝对能让你在工作室或家里多一个既实用又炫酷的玩意儿。我说的就是这款基于RGBDigit数码…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...

从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式
从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发领域&am…...

三步解锁WeMod专业版:终极本地增强工具配置指南
三步解锁WeMod专业版:终极本地增强工具配置指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用烦恼吗…...