如何使用YOLOv8训练自己的模型
本文介绍如何用YOLO8训练自己的模型,我们开门见山,直接步入正题。
前言:用yolo8在自己的数据集上训练模型首先需要配置好YOLO8的环境,如果不会配置YOLO8环境可以参考本人主页的另一篇文章
提醒:使用GPU训练会大幅度加快训练,有英伟达GPU的一定要配置GPU训练环境,没有英伟达显卡的只能采用CPU训练,但是一般不建议。 (GPU、CPU训练环境的配置具体见上面的文章链接)
第一章节:准备好数据集
配置好YOLO8环境之后,需要准备好YOLO格式的数据集(也称txt格式),该数据集可以通过数据集标注软件 labelme、labelimg对图片进行拉框标注得到。经过标注软件标注好的yolo数据集的格式通常为:
class_id x y w h
class_id: 类别的id编号
x: 目标的中心点x坐标(横向) /图片总宽度
y: 目标的中心的y坐标(纵向) /图片总高度
w:目标框的宽度/图片总宽度
h: 目标框的高度/图片总高度
下图为一张图片按照yolo格式进行标注的txt标注文件

在进行训练之前,还需要对数据集进行划分,一般是按照7:2:1的比例划分训练集(train)、验证集(val)、测试集(test) 或者按照8:2的比例划分训练集与验证集。
提醒:用YOLO8训练自己的模型必须至少要把数据集划分出训练集与验证集,可以不划分测试集,训练集与验证集不可或缺,否则不能数据集进行模型训练。我这里只划分训练集与验证集,并且训练集与验证集应该是下面的目录结构
train
├── images
└── labelsval
├── images
└── labels
下面以葡萄叶片病虫害数据集为例,给出训练集、验证集目录结构的参考示例
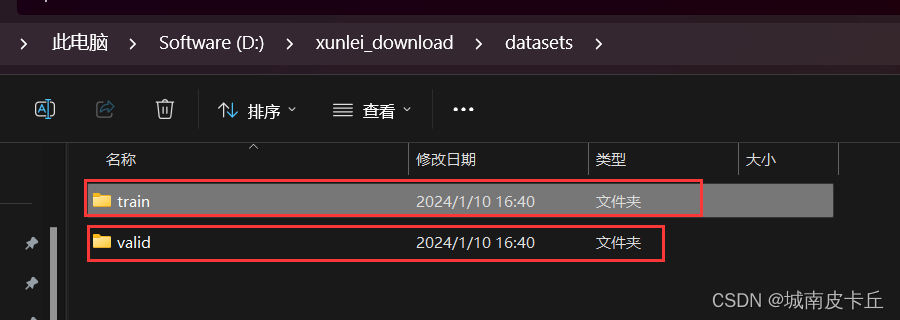


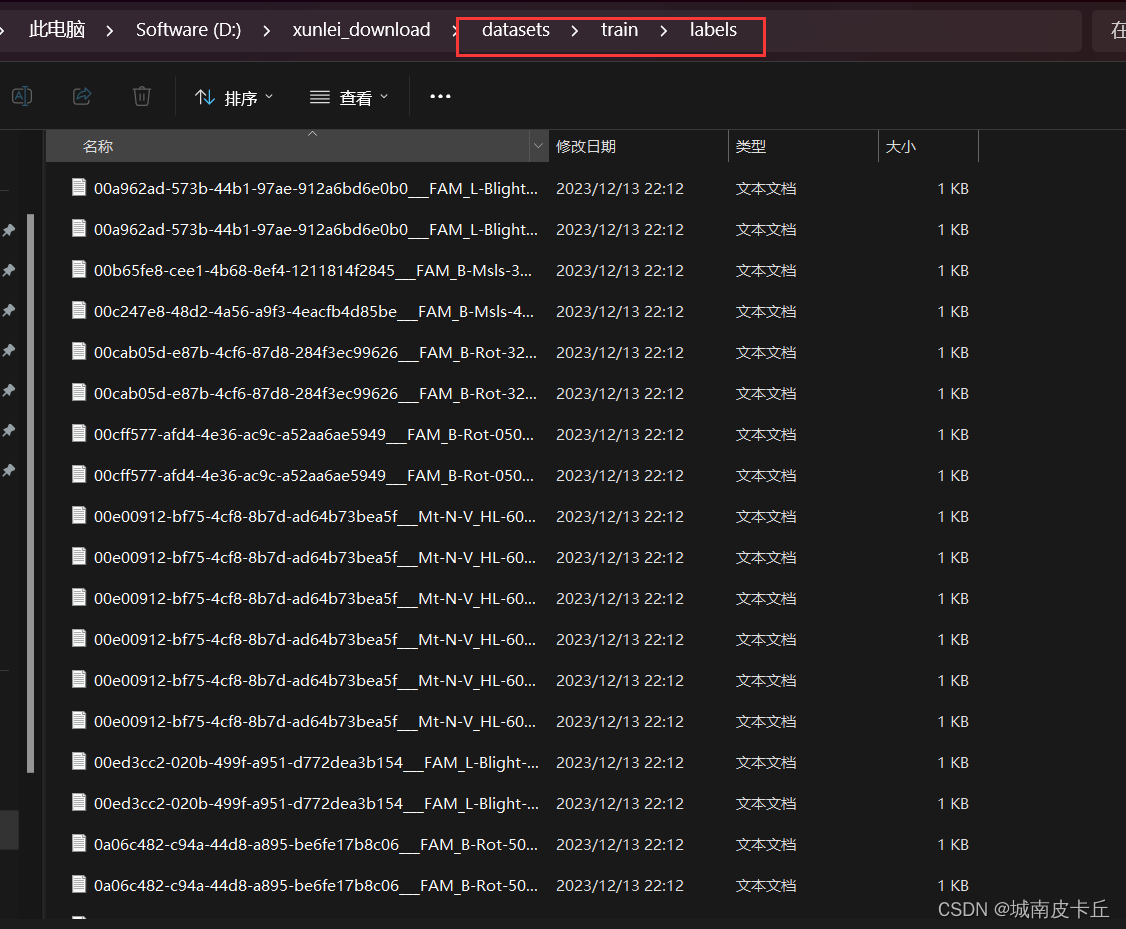


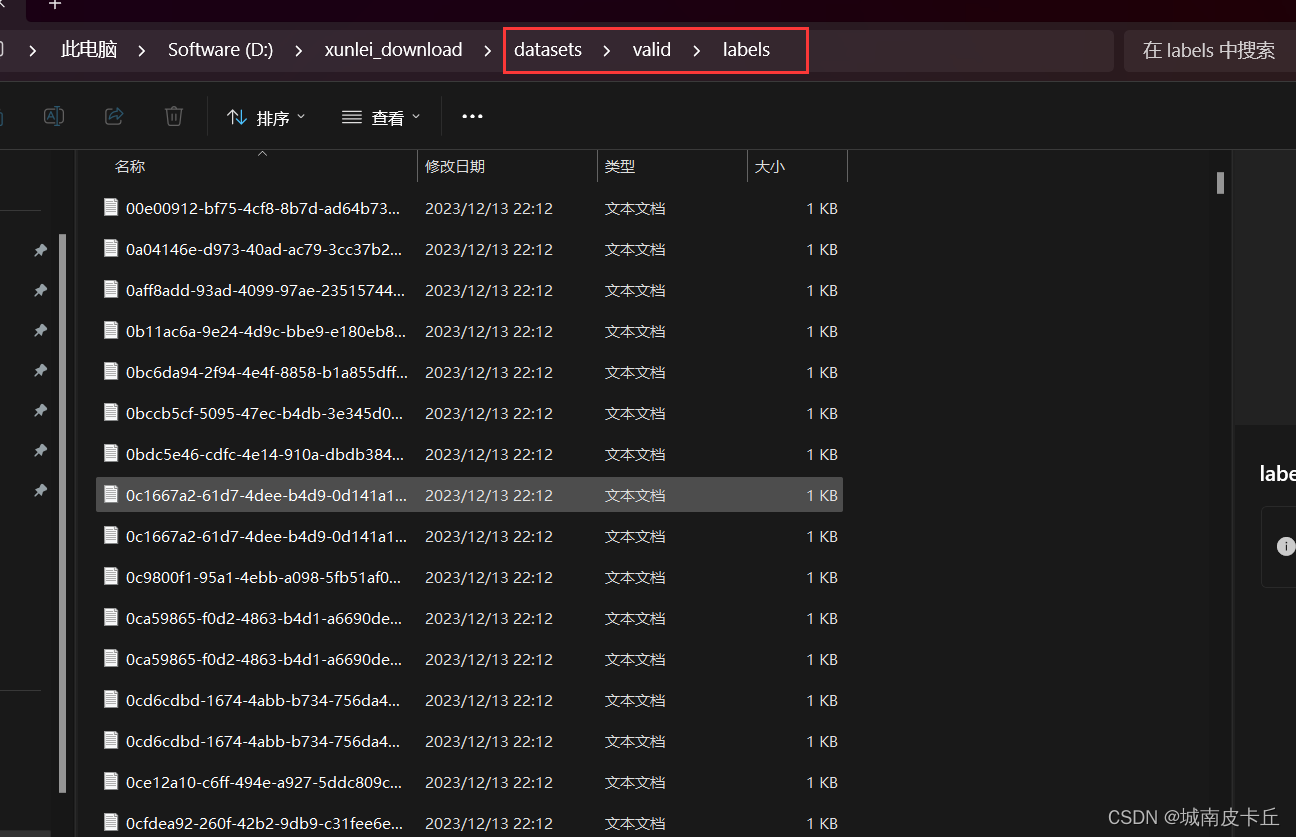
在训练之前,我们不仅要把数据集划分成训练集、验证集,还需要给出类别标签yaml文件,该文件是YOLO8在训练过程中所必须的。也就是说,一个完整的,可以直接用于模型训练的数据集应该具有以下目录结构:

data.yaml的内容如下图所示:
 其中train、val指定训练集与验证集的路径地址(最好写成绝对路径)
其中train、val指定训练集与验证集的路径地址(最好写成绝对路径)
nc代表该数据集有几个类别,我这里的葡萄叶片病虫害数据集有四个类别
names代表具体的类别名称。可以以数组的形式给出,但请注意类别名称需要以英文或数字呈现,不能含有任何特殊字符或者中文字符。
提醒:yaml文件是必须的,如果你拿到的数据集不含这个文件,那么你要按照上面的格式自己手动写了,书写时需要严格按照yaml文件的格式(冒号后面是有一个空格的)
第二章节:开始训练
搞深度学习,绝大部分都是在linux系统上进行炼丹的。考虑到有的读者可能对Linux不熟悉,本章节首先给出win系统训练教程,然后再给出linux系统训练步骤。
注意:在训练的过程中,有英伟达显卡的一定要用GPU训练,用CPU训练是特别缓慢的。
2.1 训练参数
训练方式有多种,可以通过py程序训练,也可以在命令行训练,我们这里以py程序训练为例:
无论是在win系统还是linux系统,训练的代码基本都是一致的,只有极个别参数会因为系统的不同出现差异。
from ultralytics import YOLO# 这里有三种训练方式,三种任选其一#第一种:根据yaml文件构建一个新模型进行训练,若对YOLO8网络进行了修改(比如添加了注意力机制)适合选用此种训练方式。但请注意这种训练方式是重头训练(一切参数都要自己训练),训练时间、资源消耗都是十分巨大的
model = YOLO('yolov8n.yaml') # build a new model from YAML#第二种:加载一个预训练模型,在此基础之前上对参数进行调整。这种方式是深度学习界最最主流的方式。由于大部分参数已经训练好,我们仅需根据数据集对模型的部分参数进行微调,因此训练时间最短,计算资源消耗最小。
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)#第三种:根据yaml文件构建一个新模型,然后将预训练模型的参数转移到新模型中,然后进行训练,对YOLO8网络进行改进的适合选用此种训练方式,而且训练时间不至于过长
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights# Train the model
#data参数指定数据集yaml文件(我这里data.yaml与train、val文件夹同目录)
#epochs指定训练多少轮
#imgsz指定图片大小
results = model.train(data='data.yaml', epochs=100, imgsz=640)model.train()函数可以指定的训练参数有很多,如下表所示:
| Key | Value | Description |
| model | None | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
| data | None | path to data file, i.e. coco128.yaml |
| epochs | 100 | number of epochs to train for |
| time | None | number of hours to train for, overrides epochs if supplied |
| patience | 50 | epochs to wait for no observable improvement for early stopping of training |
| batch | 16 | number of images per batch (-1 for AutoBatch) |
| imgsz | 640 | size of input images as integer |
| save | True | save train checkpoints and predict results |
| save_period | -1 | Save checkpoint every x epochs (disabled if < 1) |
| cache | False | True/ram, disk or False. Use cache for data loading |
| device | None | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |
| workers | 8 | number of worker threads for data loading (per RANK if DDP) |
| project | None | project name |
| name | None | experiment name |
| exist_ok | False | whether to overwrite existing experiment |
| pretrained | True | (bool or str) whether to use a pretrained model (bool) or a model to load weights from (str) |
| optimizer | 'auto' | optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
| verbose | False | whether to print verbose output |
| seed | 0 | random seed for reproducibility |
| deterministic | True | whether to enable deterministic mode |
| single_cls | False | train multi-class data as single-class |
| rect | False | rectangular training with each batch collated for minimum padding |
| cos_lr | False | use cosine learning rate scheduler |
| close_mosaic | 10 | (int) disable mosaic augmentation for final epochs (0 to disable) |
| resume | False | resume training from last checkpoint |
| amp | True | Automatic Mixed Precision (AMP) training, choices=[True, False] |
| fraction | 1.0 | dataset fraction to train on (default is 1.0, all images in train set) |
| profile | False | profile ONNX and TensorRT speeds during training for loggers |
| freeze | None | (int or list, optional) freeze first n layers, or freeze list of layer indices during training |
| lr0 | 0.01 | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |
| lrf | 0.01 | final learning rate (lr0 * lrf) |
| momentum | 0.937 | SGD momentum/Adam beta1 |
| weight_decay | 0.0005 | optimizer weight decay 5e-4 |
| warmup_epochs | 3.0 | warmup epochs (fractions ok) |
| warmup_momentum | 0.8 | warmup initial momentum |
| warmup_bias_lr | 0.1 | warmup initial bias lr |
| box | 7.5 | box loss gain |
| cls | 0.5 | cls loss gain (scale with pixels) |
| dfl | 1.5 | dfl loss gain |
| pose | 12.0 | pose loss gain (pose-only) |
| kobj | 2.0 | keypoint obj loss gain (pose-only) |
| label_smoothing | 0.0 | label smoothing (fraction) |
| nbs | 64 | nominal batch size |
| overlap_mask | True | masks should overlap during training (segment train only) |
| mask_ratio | 4 | mask downsample ratio (segment train only) |
| dropout | 0.0 | use dropout regularization (classify train only) |
| val | True | validate/test during training |
| plots | False | save plots and images during train/val |
下面指出几个比较重要的训练参数
1. epochs
epochs: 训练的轮数。这个参数确定了模型将会被训练多少次,每一轮都遍历整个训练数据集。训练的轮数越多,模型对数据的学习就越充分,但也增加了训练时间。
选取策略
默认是100轮数。但一般对于新数据集,我们还不知道这个数据集学习的难易程度,可以加大轮数,例如300,来找到更佳性能。
2. patience
patience: 早停的等待轮数。在训练过程中,如果在一定的轮数内没有观察到模型性能的明显提升,就会停止训练。这个参数确定了等待的轮数,如果超过该轮数仍没有改进,则停止训练。
早停
早停能减少过拟合。过拟合(overfitting)指的是只能拟合训练数据, 但不能很好地拟合不包含在训练数据中的其他数据的状态。
3. batch
batch: 每个批次中的图像数量。在训练过程中,数据被分成多个批次进行处理,每个批次包含一定数量的图像。这个参数确定了每个批次中包含的图像数量。特殊的是,如果设置为**-1**,则会自动调整批次大小,至你的显卡能容纳的最多图像数量。
选取策略
一般认为batch越大越好。因为我们的batch越大我们选择的这个batch中的图片更有可能代表整个数据集的分布,从而帮助模型学习。但batch越大占用的显卡显存空间越多,所以还是有上限的。
4. imgsz
imgsz: 输入图像的尺寸。这个参数确定了输入图像的大小。可以指定一个整数值表示图像的边长,也可以指定宽度和高度的组合。例如640表示图像的宽度和高度均为640像素。
选取策略
如果数据集中存在大量小对象,增大输入图像的尺寸imgsz可以使得这些小对象从高分辨率中受益,更好的被检测出。
5. device
device: 训练运行的设备。该参数指定了模型训练所使用的设备,例如使用 GPU 运行可以指定为 cuda device=0,或者使用多个 GPU 运行可以指定为 device=0,1,2,3,如果没有可用的 GPU,可以指定为 device=cpu 使用 CPU 进行训练。
6. workers
workers: 数据加载时的工作线程数。在数据加载过程中,可以使用多个线程并行地加载数据,以提高数据读取速度。这个参数确定了加载数据时使用的线程数,具体的最佳值取决于硬件和数据集的大小。
windows系统注意设置为0!!!windows系统下需设置为0,否则会报错!!!
RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase。
这是因为在linux系统中可以使用多个子进程加载数据,而在windows系统中不能。
7. optimizer
optimizer: 选择要使用的优化器。优化器是深度学习中用于调整模型参数以最小化损失函数的算法。可以选择不同的优化器,如 ‘SGD’、‘Adam’、‘AdamW’、‘RMSProp’,根据任务需求选择适合的优化器。
2.2 在win系统中进行训练
在开始训练之前,文件参考目录如下:
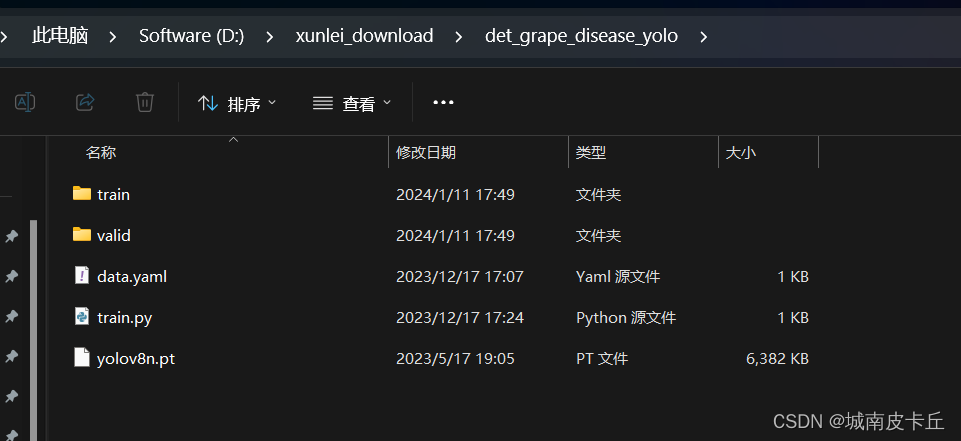
我这里直接加载yolovn8预训练模型进行训练,训练代码train.py内容如下:
from ultralytics import YOLO
model=YOLO('yolov8n.pt')
model.train(data='./data.yaml',imgsz=(640,640),workers=0,batch=32,epochs=60)需要注意的是,目录下最好提前下载好预训练模型(我这里是yolov8n.pt),如果没有提前下载好,运行train.py还是会ultralytics官网下载,由于外网的缘故,此时可能会出现网络问题。
紧接着,我们在anaconda中切换到提前已经配置好的yolo8环境,然后python命令运行train.py
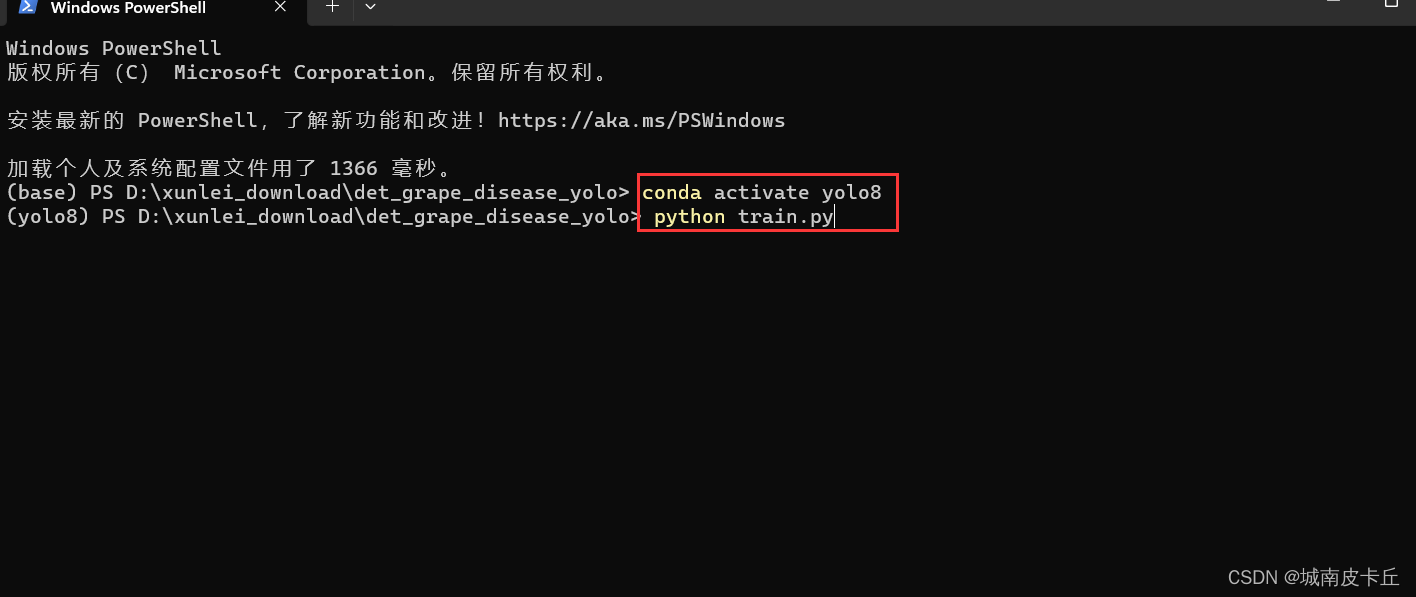
之后,控制台窗口会有一系列的日志输出
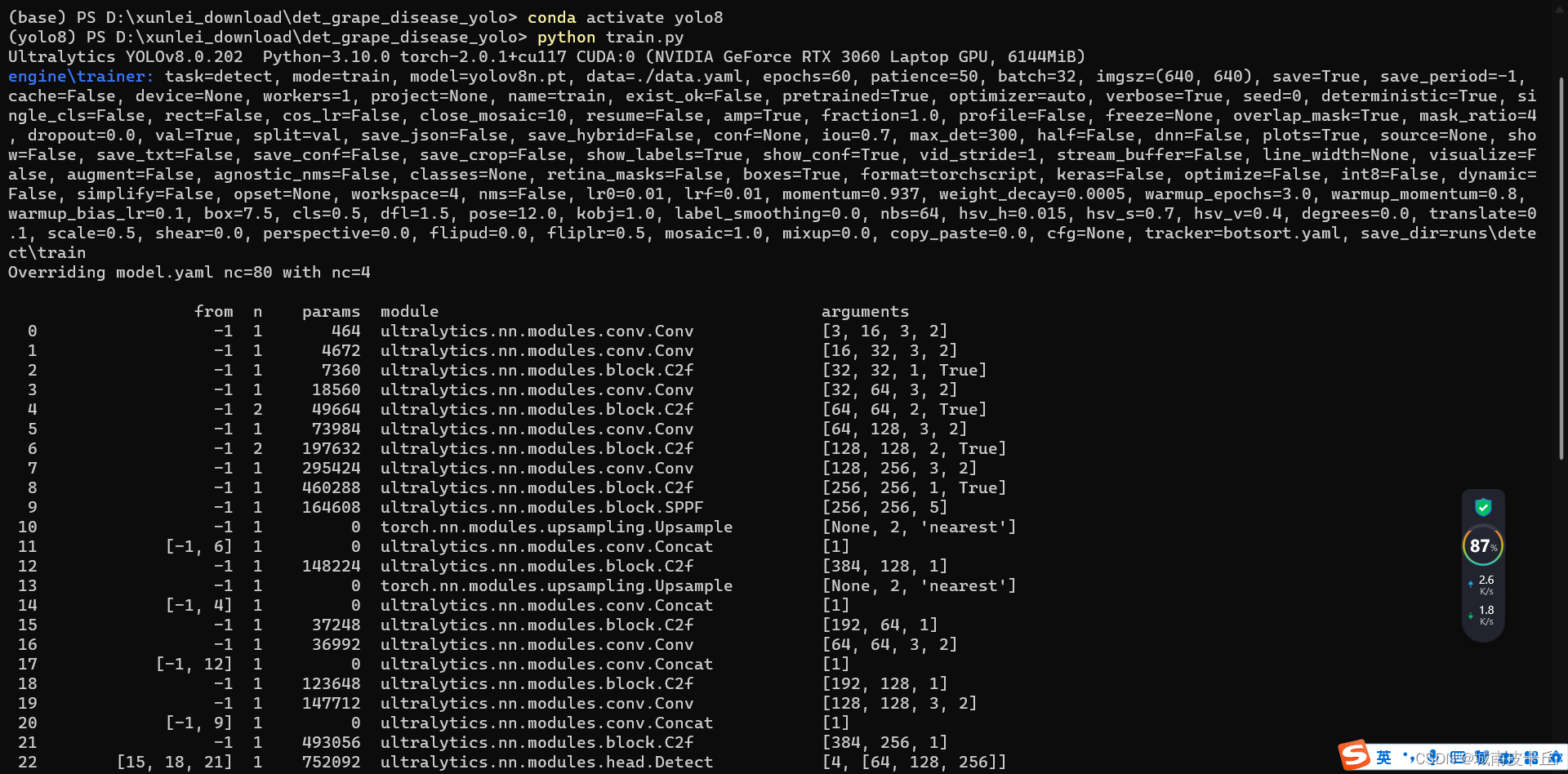
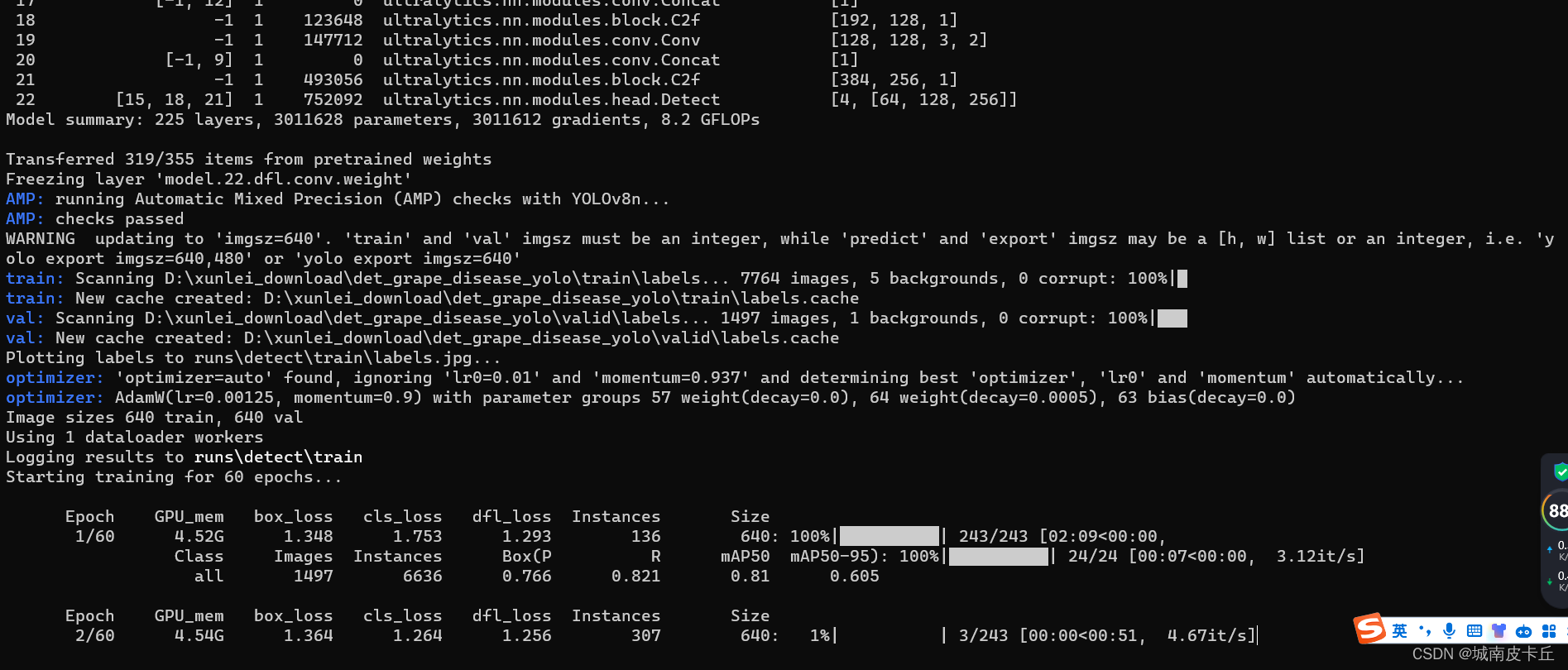
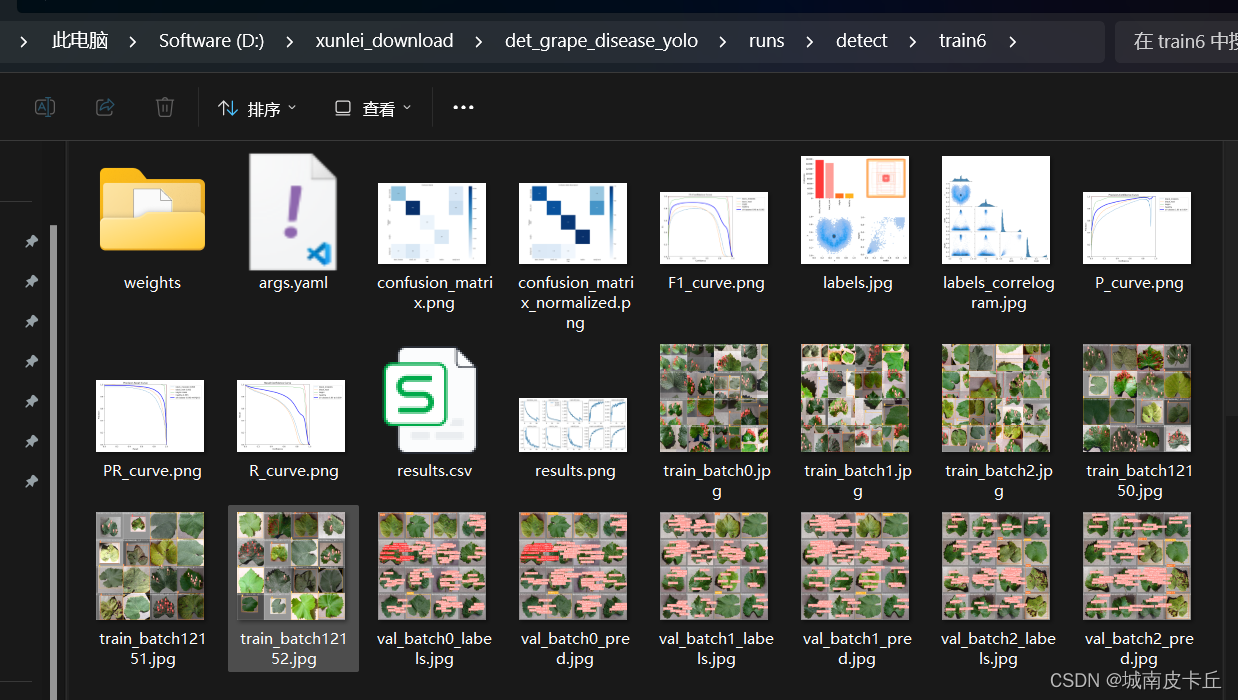
此时,训练成功。经过一段时间等待之后,在目录下的runs文件夹下会自动生成训练过程记录,包含模型权重、混淆矩阵、PR曲线、loss曲线等
2.3 在linux系统中进行训练
在linux系统中我们可以加大workers(数据加载时的工作线程数),从而加快训练速度,代码跟win系统基本保持一致:
from ultralytics import YOLO
model=YOLO('yolov8n.pt')
model.train(data='./data.yaml',imgsz=(640,640),workers=16,batch=32,epochs=60)值得注意的是,无论是在win系统中还是linux系统中,都要根据自己电脑、服务器的算力去选择合适的workers和batch,设置过小训练速度慢,设置过大,会out of memory.
相关文章:
如何使用YOLOv8训练自己的模型
本文介绍如何用YOLO8训练自己的模型,我们开门见山,直接步入正题。 前言:用yolo8在自己的数据集上训练模型首先需要配置好YOLO8的环境,如果不会配置YOLO8环境可以参考本人主页的另一篇文章 提醒:使用GPU训练会大幅度加…...

机器学习-逻辑回归【手撕】
逻辑回归 在模式识别问题中,所输出的结果是分类,比如是否是猫,这时候无法通过简单的线性回归来实现问题。同时,与线性回归不同的是,逻辑回归是一种名为回归的线性分类器,并常用于二分类,其本质…...

内网安全:NTLM-Relay
目录 NTLM认证过程以及攻击面 NTLM Relay攻击 NTLM攻击总结 实验环境说明 域横向移动:NTLM中继攻击 攻击条件 实战一:NTLM中继攻击-CS转发上线MSF 原理示意图 一. CS代理转发 二. MSF架设路由 三. 适用smb_relay模块进行中继攻击 域横向移动…...

Tensorflow2.0笔记 - tensor的padding和tile
本笔记记录tensor的填充和tile操作,对应tf.pad和tf.tile import tensorflow as tf import numpy as nptf.__version__#pad做填充 # tf.pad( tensor,paddings, modeCONSTANT,nameNone) #1维tensor填充 tensor tf.random.uniform([5], maxval10, dtypetf.int32) pri…...

多媒体测试资源
目录 简介自己整理的文件测试资源列表 简介 音视频测试时,需要许多源文件,这里整理了一些.会持续更新.当然可以使用ffmpeg转换获得需要的文件. 如果知道的这方面资源的,在评论区留言. 自己整理的文件 有视频,图片,音频. 链接:https://pan.baidu.com/s/1vatLmWk…...
Wordpress seo优化该怎么做?
Wordpress作为开源管理系统,目前已然是世界上最流行的cms之一,这不仅仅因为他开源,对用户友好,让任何人都能轻而易举的制作网站,更是因为这套程序对于搜索引擎非常友好,是做谷歌seo的不二之选 Wordpress作为…...
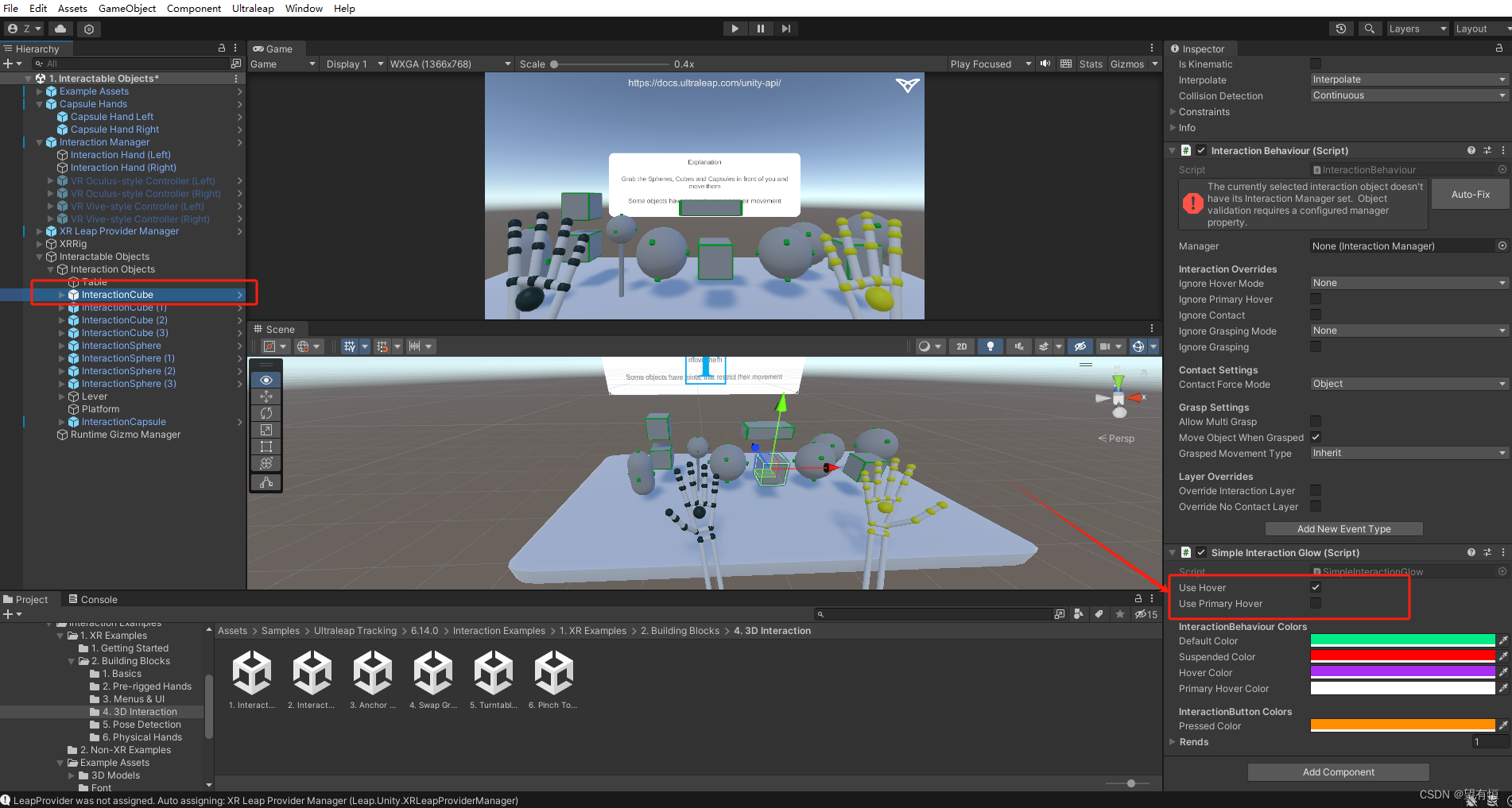
Ultraleap 3Di示例Interactable Objects组件分析
该示例代码位置如下: 分析如下: Hover Enabled:悬停功能,手放在这个模型上,会触发我们手放在这个模型上的悬停功能。此时当手靠近模型的时候,手的模型的颜色会发生改变,反之,则不会…...

Vue自定义成功弹窗H5实现类似于小程序的效果
效果图: <div class"father"><div class"success-box" v-if"isSuccess"><img src"../../assets/insure/success-logo.png" alt""><span>{{ successTitle }}</span></div> &…...

Linux之父:我们正在从C语言转向Rust
最近,Linus在“Torvalds 演讲:人工智能对编程的影响”:“我们正在从C语言转向Rust”。 网友讨论: Linus 选择 Rust 是因为,这是一个中长期解决方案,解决了 IT 世界中缺乏 C/C 人员的实际问题,所…...
C++ qt标题栏组件绘制
本博文源于笔者在学习C qt制作的标题栏组件,主要包含了,最小化,最大化,关闭。读者在看到这篇博文的时候,可以直接查看如何使用的,会使用了,然后进行复制粘贴源码部分即可。 问题来源 想要制作…...

Mysql运维篇(三) MySQL备份与恢复
一路走来,所有遇到的人,帮助过我的、伤害过我的都是朋友,没有一个是敌人。如有侵权,请留言,我及时删除! 一、物理备份与逻辑备份 1、物理备份:备份数据文件,转储数据库物理文件到某…...

数字图像处理(实践篇)二十七 Python-OpenCV 滑动条的使用
目录 1 涉及的函数 2 实践 1 涉及的函数 ⒈ setWindowProperty()用于设置GUI应用程序的属性 cv2.setWindowProperty(windowsName, prop_id, prop_value) 参数: ①...

拷贝构造函数的理解
1.拷贝构造函数与构造函数类似,当没有自定义拷贝构造函数的时候,编译器会定义一个拷贝构造函数。 当类对象没有初始化的时候,通过赋值运算符的形式,也是调用拷贝构造函数。 Test aa(100); Test bb aa;//调用拷贝构造函数Test …...
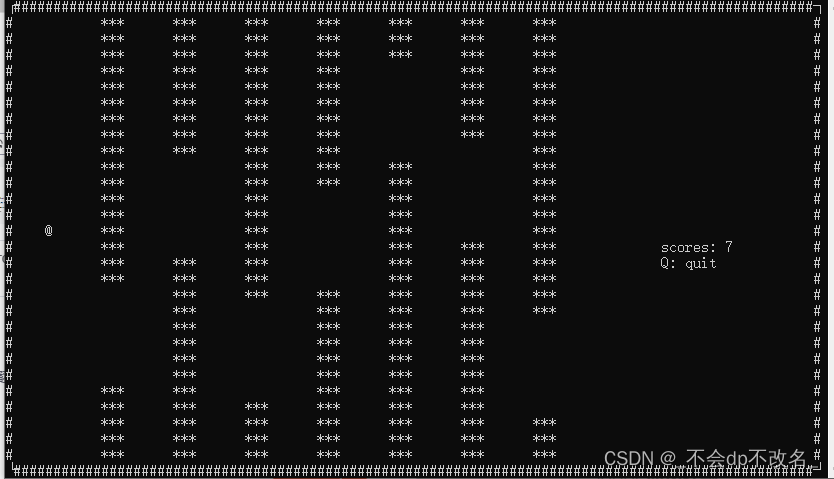
基于ncurse的floppy_bird小游戏
1. 需求分析 将运动分解为鸟的垂直运动和杆的左右运动。 2. 概要设计 2.1 鸟运动部分 2.2 杆的运动 3. 代码实现 #include <stdio.h> #include <ncurses.h>#include <stdlib.h> #include <time.h>int vx 0; int vy 1;int bird_r; int bird_c;int…...
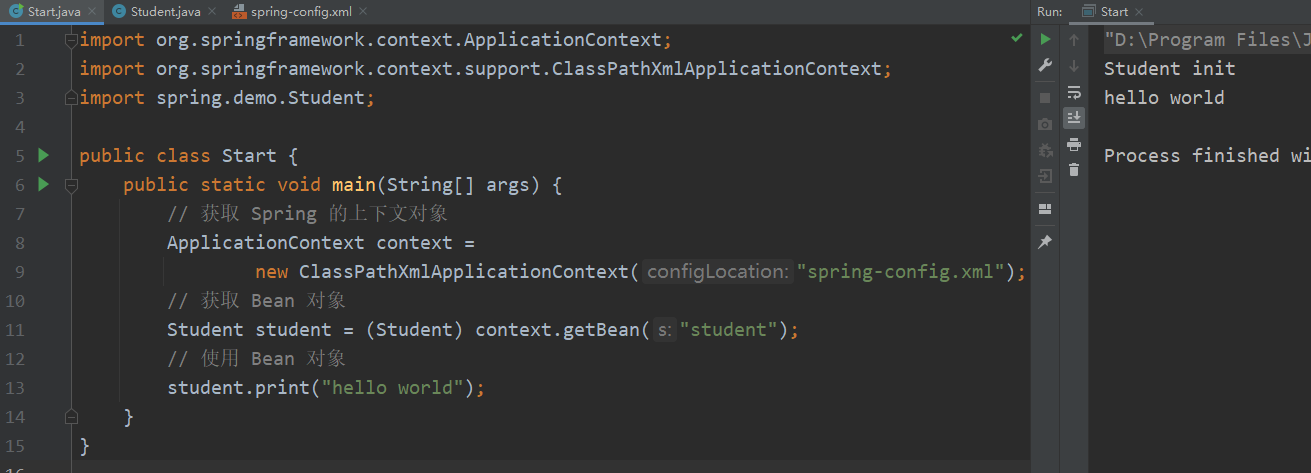
创建第一个 Spring 项目(IDEA社区版)
文章目录 创建 Spring 项目创建一个普通的 Maven 项目添加 Spring 依赖IDEA更换国内源 运行第一个 Spring 项目新建启动类存储 Bean 对象将Bean注册到Spring 获取并使用 Bean 对象 创建 Spring 项目 创建一个普通的 Maven 项目 首先创建一个普通的 Maven 项目 添加 Spring 依…...

VUE3动漫影视视频网站模板源码
文章目录 1.视频设计来源1.1 主界面1.2 动漫、电视剧、电影视频界面1.3 播放视频界面1.4 娱乐前线新闻界面1.5 关于我们界面 2.效果和源码2.1 动态效果2.2 源码结构 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/deta…...
Node.js-express
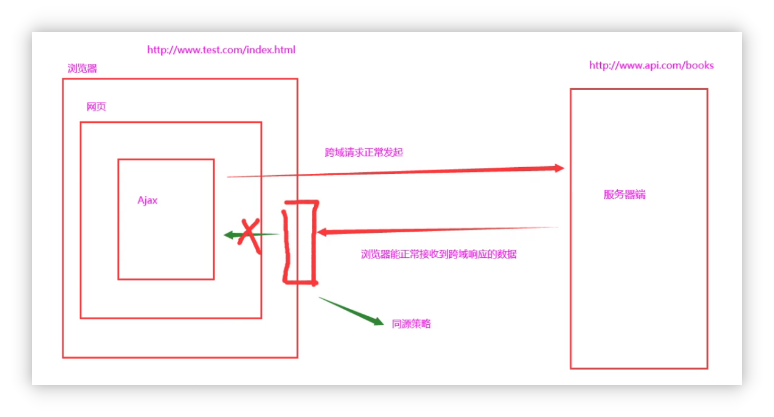
1.了解Ajax 1.1 什么是ajax Ajax的全称是Asynchronous Javascript And XML(异步Js和XML). 通俗的理解:在网页中利用XMLHttpRequest对象和服务器进行数据交互的方式,就是Ajax 1.2 为什么要学习Ajax 之前所学的技术,…...

心理学笔记——我们如何思考-思想、语言和手语
我们如何思考-思想、语言和手语 研究语言的理论:计算理论、认知神经学、进化论 当我们讨论语言时,指的是英语、中文、日语这样的语言系统 所有语言都共享一些深层且复杂的共性,最直观的就是每一种语言都能够有效地表达抽象概念——思想、物…...
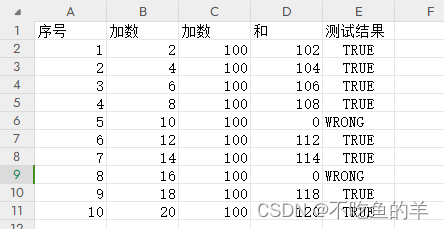
Matlab处理excel数据
我们新建个excel文档,用Matlab读取里面的内容,计算和判断里面的计算结果是否正确,并打印到另一个文档当中。 新建文档 新建输入文档,文件名TestExcel 编写脚本 [num,txt] xlsread(TestExcel.xlsx); SNcode num(:,1);%从序号中…...

某大厂关于Linux系统相关面试题
一、Linux系统和Shell 1、写一个sed命令,修改/tmp/input.txt文件的内容,要求:(1) 删除所有空行;(2) 在非空行前面加一个"AAA",在行尾加一个"BBB",即将内容为11111的一行改为࿱…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...