HiveSQL题——聚合函数(sum/count/max/min/avg)
目录
一、窗口函数的知识点
1.1 窗户函数的定义
1.2 窗户函数的语法
1.3 窗口函数分类
聚合函数
排序函数
前后函数
头尾函数
1.4 聚合函数
二、实际案例
2.1 每个用户累积访问次数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 各直播间最大的同时在线人数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.3 历史至今每个小时内同时在线人数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.4 某个时间段、每个小时内同时在线人数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.5 学生各学科的成绩
0 问题描述
1 数据准备
2 数据分析
3 小结
一、窗口函数的知识点
1.1 窗户函数的定义
窗口函数可以拆分为【窗口+函数】。窗口函数官网指路:
LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundation![]() https://cwiki.apache.org/confluence/display/Hive/LanguageManual%20WindowingAndAnalytics
https://cwiki.apache.org/confluence/display/Hive/LanguageManual%20WindowingAndAnalytics
- 窗口:限定函数的计算范围(窗口函数:针对分组后的数据,从逻辑角度指定计算的范围,并没有从物理上真正的切分,只有group by 是物理分组,真正意义上的分组)
- 函数:计算逻辑
- 窗口函数的位置:跟sql里面聚合函数的位置一样,from -> join -> on -> where -> group by->select 后面的普通字段,窗口函数 -> having -> order by -> lmit 。 窗口函数不能跟聚合函数同时出现。聚合函数包括count、sum、 min、max、avg。
- sql 执行顺序:from -> join -> on -> where -> group by->select 后面的普通字段,聚合函数-> having -> order by -> limit
1.2 窗户函数的语法
<窗口函数>window_name over ( [partition by 字段...] [order by 字段...] [窗口子句] )
- window_name:给窗口指定一个别名。
- over:用来指定函数执行的窗口范围,如果后面括号中什么都不写,即over() ,意味着窗口包含满足where 条件的所有行,窗口函数基于所有行进行计算。
- 符号[] 代表:可选项; | : 代表二选一
- partition by 子句: 窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行。分组间互相独立。
- order by 子句:每个partition内部按照哪些字段进行排序,如果没有partition ,那就直接按照最大的窗口排序,且默认是按照升序(asc)排列。
- 窗口子句:显示声明范围(不写窗口子句的话,会有默认值)。常用的窗口子句如下:
rows between unbounded preceding and unbounded following; -- 上无边界到下无边界(一般用于求 总和)rows between unbounded preceding and current row; --上无边界到当前记录(累计值)rows between 1 preceding and current row; --从上一行到当前行rows between 1 preceding and 1 following; --从上一行到下一行rows between current row and 1 following; --从当前行到下一行ps: over()里面有order by子句,但没有窗口子句时 ,即: <窗口函数> over ( partition by 字段... order by 字段... ),此时窗口子句是有默认值的 --> rows between unbounded preceding and current row (上无边界到当前行)。
此时窗口函数语法:<窗口函数> over ( partition by 字段... order by 字段... ) 等价于
<窗口函数> over ( partition by 字段... order by 字段... rows between unbounded preceding and current row)
需要注意有个特殊情况:当order by 后面跟的某个字段是有重复行的时候, <窗口函数> over ( partition by 字段... order by 字段... ) 不写窗口子句的情况下,窗口子句的默认值是:range between unbounded preceding and current row(上无边界到当前相同行的最后一行)。
因此,遇到order by 后面跟的某个字段出现重复行,且需要计算【上无边界到当前行】,那就需要手动指定窗口子句 rows between unbounded preceding and current row ,偷懒省略窗口子句会出问题~
ps: 窗口函数的执行顺序是在where之后,所以如果where子句需要用窗口函数作为条件,需要多一层查询,在子查询外面进行。
【例如】求出登录记录出现间断的用户Id
selectid
from (selectid,login_date,lead(login_date, 1, '9999-12-31')over (partition by id order by login_date) next_login_date--窗口函数 lead(向后取n行)--lead(column1,n,default)over(partition by column2 order by column3) 查询当前行的后边第n行数据,如果没有就为nullfrom (--用户在同一天可能登录多次,需要去重selectid,date_format(`date`, 'yyyy-MM-dd') as login_datefrom user_loggroup by id, date_format(`date`, 'yyyy-MM-dd')) tmp1) tmp2
where datediff(next_login_date, login_date) >=2
group by id;1.3 窗口函数分类
哪些函数可以是窗口函数呢?(放在over关键字前面的)
sum(column) over (partition by .. order by .. 窗口子句);
count(column) over (partition by .. order by .. 窗口子句);
max(column) over (partition by .. order by .. 窗口子句);
min(column) over (partition by .. order by .. 窗口子句);
avg(column) over (partition by .. order by .. 窗口子句);ps : 高级聚合函数:
collect_list 收集并形成list集合,结果不去重;
collect_set 收集并形成set集合,结果去重;
举例:
--每个月的入职人数以及姓名select
month(replace(hiredate,'/','-')),count(*) as cnt,collect_list(name) as name_list
from employee
group by month(replace(hiredate,'/','-'));/*
输出结果
month cn name_list
4 2 ["宋青书","周芷若"]
6 1 ["黄蓉"]
7 1 ["郭靖"]
8 2 ["张无忌","杨过"]
9 2 ["赵敏","小龙女"]
*/-
排序函数
-- 顺序排序——1、2、3
row_number() over(partition by .. order by .. )-- 并列排序,跳过重复序号——1、1、3(横向加)
rank() over(partition by .. order by .. )-- 并列排序,不跳过重复序号——1、1、2(纵向加)
dense_rank() over(partition by .. order by .. )-
前后函数
-- 取得column列的前n行,如果存在则返回,如果不存在,返回默认值default
lag(column,n,default) over(partition by order by) as lag_test
-- 取得column列的后n行,如果存在则返回,如果不存在,返回默认值default
lead(column,n,default) over(partition by order by) as lead_test-
头尾函数
---当前窗口column列的第一个数值,如果有null值,则跳过
first_value(column,true) over (partition by ..order by.. 窗口子句) ---当前窗口column列的第一个数值,如果有null值,不跳过
first_value(column,false) over (partition by ..order by.. 窗口子句)--- 当前窗口column列的最后一个数值,如果有null值,则跳过
last_value(column,true) over (partition by ..order by.. 窗口子句) --- 当前窗口column列的最后一个数值,如果有null值,不跳过
last_value(column,false) over (partition by ..order by.. 窗口子句) 1.4 聚合函数
sum() /count() /max() /min() /avg() 函数,一般用于开窗求累积汇总值。
sum(column) over (partition by .. order by .. 窗口子句);
count(column) over (partition by .. order by .. 窗口子句);
max(column) over (partition by .. order by .. 窗口子句);
min(column) over (partition by .. order by .. 窗口子句);
avg(column) over (partition by .. order by .. 窗口子句);二、实际案例
2.1 每个用户累积访问次数
0 问题描述
统计每个用户累积访问次数
1 数据准备
create table if not exists table6
(userid string comment '用户id',visitdate string comment '访问时间',visitcount int comment '访问次数'
)comment '用户访问次数';2 数据分析
selectuserid,visit_date,vc1,--再求出用户历史至今的累积访问次数sum(vc1) over (partition by userid order by visit_date ) as vc2
from ( --先求出用户每个月的累积访问次数selectuserid,date_format(visitdate, 'yyyy-MM') as visit_date,sum(visitcount) as vc1from table6group by userid, date_format(visitdate, 'yyyy-MM')) tmp1;
3 小结
2.2 各直播间最大的同时在线人数
0 问题描述
根据直播间的用户访问记录,统计各直播间最大的同时在线人数。
1 数据准备
create table if not exists table7
(room_id int comment '直播间id',user_id int comment '用户id',login_time string comment '用户进入直播间时间',logout_time string comment '用户离开直播间时间'
)comment '直播间的用户访问记录';
INSERT overwrite table table7
VALUES (1,100,'2021-12-01 19:00:00', '2021-12-01 19:28:00'),(1,100,'2021-12-01 19:30:00', '2021-12-01 19:53:00'),(2,100,'2021-12-01 21:01:00', '2021-12-01 22:00:00'),(1,101,'2021-12-01 19:05:00', '2021-12-01 20:55:00'),(2,101,'2021-12-01 21:05:00', '2021-12-01 21:58:00'),(1,102,'2021-12-01 19:10:00', '2021-12-01 19:25:00'),(2,102,'2021-12-01 19:55:00', '2021-12-01 21:00:00'),(3,102,'2021-12-01 21:05:00', '2021-12-01 22:05:00'),(1,104,'2021-12-01 19:00:00', '2021-12-01 20:59:00'),(2,104,'2021-12-01 21:57:00', '2021-12-01 22:56:00'),(2,105,'2021-12-01 19:10:00', '2021-12-01 19:18:00'),(3,106,'2021-12-01 19:01:00', '2021-12-01 21:10:00');
2 数据分析
selectroom_id,max(num)
from (selectroom_id,sum(flag) over (partition by room_id order by dt) as numfrom (selectroom_id,user_id,login_time as dt,--对登入该直播间的人,标记 11 as flagfrom table7unionselectroom_id,user_id,logout_time as dt,--对退出该直播间的人,标记 -1-1 as flagfrom table7) tmp1) tmp2
--求出直播间最大的同时在线人数
group by room_id;3 小结
该题的关键点在于:对每个用户进入/退出直播间的行为进行打标签,再利用sum()over聚合函数计算最终的数值。
2.3 历史至今每个小时内同时在线人数
由案例2.2 引申出来的案例 2.3和 案例2.4
0 问题描述
根据直播间用户访问记录,不限制时间段,统计历史至今的各直播间每个小时内的同时在线人数
1 数据准备
create table if not exists table7
(room_id int comment '直播间id',user_id int comment '用户id',login_time string comment '用户进入直播间时间',logout_time string comment '用户离开直播间时间'
)comment '直播间的用户访问记录';
INSERT overwrite table table7
VALUES (1,100,'2021-12-01 19:00:00', '2021-12-01 19:28:00'),(1,100,'2021-12-01 19:30:00', '2021-12-01 19:53:00'),(2,100,'2021-12-01 21:01:00', '2021-12-01 22:00:00'),(1,101,'2021-12-01 19:05:00', '2021-12-01 20:55:00'),(2,101,'2021-12-01 21:05:00', '2021-12-01 21:58:00'),(1,102,'2021-12-01 19:10:00', '2021-12-01 19:25:00'),(2,102,'2021-12-01 19:55:00', '2021-12-01 21:00:00'),(3,102,'2021-12-01 21:05:00', '2021-12-01 22:05:00'),(1,104,'2021-12-01 19:00:00', '2021-12-01 20:59:00'),(2,104,'2021-12-01 21:57:00', '2021-12-01 22:56:00'),(2,105,'2021-12-01 19:10:00', '2021-12-01 19:18:00'),(3,106,'2021-12-01 19:01:00', '2021-12-01 21:10:00');2 数据分析
完整代码如下:
with temp_data as (selectroom_id,user_id,login_time,logout_time,hour(login_time) as min_time,-- hour('2021-12-01 19:30:00') = 19hour(logout_time) as max_time,length(space(hour(logout_time) - hour(login_time))) as lg,split(space(hour(logout_time) - hour(login_time)), '') as disfrom table7
)selectroom_id,on_time,count(1) as cnt
from (select distinctroom_id,user_id,min_time,max_time,dis,dis_index,(min_time + dis_index) as on_timefrom temp_data lateral view posexplode(dis) n as dis_index,dis_dataorder by user_id,min_time,max_time,dis,dis_index) tmp1
group by room_id, on_time
order by room_id, on_time;代码拆解分析:
--以一条数据为例,room_id user_id login_time logout_time1 100 '2021-12-01 19:00:00' '2021-12-01 21:28:00'
(1)上述数据取时间hour(login_time) as min_time 、hour(logout_time)as max_time1(room_id),100(user_id),19(min_time),21(max_time)
(2)split(space(hour(logout_time) - hour(login_time)), '') 的结果:根据[21-19]=2,利用space函数生成长度是2的空格字符串,再用split拆分1(room_id),100(user_id),19(min_time),21(max_time),['','','']
(3)用posexplode经过转换增加行(列转行,炸裂),通过下角标index来获取 on_time时间,根据数组['','',''],得到index的取值是0,1,2炸裂得出下面三行数据(一行变三行)1(room_id),100(user_id),19(min_time),19 = 19+0 (on_time = min_time+index)1(room_id),100(user_id),19(min_time),20 = 19+1 (on_time = min_time+index)1(room_id),100(user_id),19(min_time),21 = 19+2 (on_time = min_time+index)炸裂的目的:将用户在线的时间段[19-21] 拆分成具体的小时,19,20,21;
(4)根据room_id,on_time进行分组,求出每个直播间分时段的在线人数 3 小结
上述代码中用到的函数有:
一、字符串函数1、空格字符串函数:space语法:space(int n)返回值:string说明:返回值是n的空格字符串举例:select length (space(10)) --> 10一般space函数和split函数结合使用:select split(space(3),''); --> ["","","",""]2、split函数(分割字符串)语法:split(string str,string pat)返回值:array说明:按照pat字符串分割str,会返回分割后的字符串数组举例:select split ('abcdf','c') from test; -> ["ab","df"]3、repeat:重复字符串语法:repeat(string A, int n)返回值:string说明:将字符串A重复n遍。举例:select repeat('123', 3); -> 123123123一般repeat函数和split函数结合使用:select split(repeat(',',4),','); --> ["","","","",""]二、炸裂函数explode 语法:lateral view explode(split(a,',')) tmp as new_column返回值:string说明:按照分隔符切割字符串,并将数组中内容炸裂成多行字符串举例:select student_score from test lateral view explode(split(student_score,','))
tmp as student_scoreposexplode语法:lateral view posexploed(split(a,',')) tmp as pos,item 返回值:string说明:按照分隔符切割字符串,并将数组中内容炸裂成多行字符串(炸裂具备瞎下角标 0,1,2,3)举例:select student_name, student_score from testlateral view posexplode(split(student_name,',')) tmp1 as student_name_index,student_namelateral view posexplode(split(student_score,',')) tmp2 as student_score_index,student_scorewhere student_score_index = student_name_index2.4 某个时间段、每个小时内同时在线人数
0 问题描述
根据直播间用户访问记录,统计某个时间段的各直播间每个小时内的同时在线人数,假设时间段是['2021-12-01 19:00:00', '2021-12-01 23:00:00']
1 数据准备
create table if not exists table7
(room_id int comment '直播间id',user_id int comment '用户id',login_time string comment '用户进入直播间时间',logout_time string comment '用户离开直播间时间'
)comment '直播间的用户访问记录';
INSERT overwrite table table7
VALUES (1,100,'2021-12-01 19:00:00', '2021-12-01 19:28:00'),(1,100,'2021-12-01 19:30:00', '2021-12-01 19:53:00'),(2,100,'2021-12-01 21:01:00', '2021-12-01 22:00:00'),(1,101,'2021-12-01 19:05:00', '2021-12-01 20:55:00'),(2,101,'2021-12-01 21:05:00', '2021-12-01 21:58:00'),(1,102,'2021-12-01 19:10:00', '2021-12-01 19:25:00'),(2,102,'2021-12-01 19:55:00', '2021-12-01 21:00:00'),(3,102,'2021-12-01 21:05:00', '2021-12-01 22:05:00'),(1,104,'2021-12-01 19:00:00', '2021-12-01 20:59:00'),(2,104,'2021-12-01 21:57:00', '2021-12-01 22:56:00'),(2,105,'2021-12-01 19:10:00', '2021-12-01 19:18:00'),(3,106,'2021-12-01 19:01:00', '2021-12-01 21:10:00');2 数据分析
完整代码如下:
with temp_data1 as (selectroom_id,user_id,login_time,logout_time,hour(login_time) as min_time,hour(logout_time) as max_time,split(space(hour(logout_time) - hour(login_time)), '') as disfrom table7where login_time >= '2021-12-01 19:00:00'and login_time <= '2021-12-01 21:00:00'
)selectroom_id,on_time,count(1) as cnt
from (select distinctroom_id,user_id,min_time,max_time,dis_index,(min_time + dis_index) as on_timefrom temp_data1 lateral view posexplode(dis) n1 as dis_index, dis_dataorder by user_id,min_time,max_time,dis_index) tmp
group by room_id, on_time
order by room_id, on_time;
3 小结
解题思路与2.3一致,只需要限制下时间区间
2.5 学生各学科的成绩
0 问题描述
基于不同的窗口限定范围(窗口边界),统计各学生的学科成绩。
1 数据准备
create table if not exists table9
(name string comment '学生名称',subject string comment '学科',score int comment '分数'
)comment '学生分数';
INSERT overwrite table table9
VALUES ('a','数学',12),('b','数学',19),('c','数学',17),('d','数学',24),('a','英语',77),('c','英语',11),('d','英语',34),('a','语文',61);2 数据分析
selectname,subject,score,--1.全局聚合sum(score) over () as sum1,--2.根据学科分组,组内全局聚合sum(score) over (partition by subject) as sum2,--3.根据学科分组,根据分数排序,计算由起点到当前行的累积值sum(score) over (partition by subject order by score) as sum3,--4.根据学科分组,根据分数排序,计算由起点到当前行的累积值 (sum3跟sum4的结果是一样的)sum(score) over (partition by subject order by score rows between unbounded preceding and current row ) as sum4,--5.根据学科分组,根据分数排序,计算上一行到当前行的累积值sum(score) over (partition by subject order by score rows between 1 preceding and current row ) as sum5,--6.根据学科分组,根据分数排序,计算上一行到下一行的累积值sum(score) over (partition by subject order by score rows between 1 preceding and 1 following) as sum6,--7.根据学科分组,根据分数排序,计算当前行到后面所有行的累积值sum(score) over (partition by subject order by score rows between current row and unbounded following ) as sum7
from table9;3 小结
窗口函数 = 窗口+ 函数,解题时需要梳理清楚函数的计算范围。
相关文章:
HiveSQL题——聚合函数(sum/count/max/min/avg)
目录 一、窗口函数的知识点 1.1 窗户函数的定义 1.2 窗户函数的语法 1.3 窗口函数分类 聚合函数 排序函数 前后函数 头尾函数 1.4 聚合函数 二、实际案例 2.1 每个用户累积访问次数 0 问题描述 1 数据准备 2 数据分析 3 小结 2.2 各直播间最大的同时在线人数 …...

计算机是什么做的
背景 虽然我是科班出身的,但是上大学时候,对这些内容并不感兴趣,只是简单的进行做题,考试而已。并没有思考,为啥学计算机组成原理,模电数电,微机原理,单片机,操作系统啥…...
C++多线程1(复习向笔记)
创建线程以及相关函数 当用thread类创建线程对象绑定函数后,该线程在主线程执行时就已经自动开始执行了,join起到阻塞主线程的作用 #include <iostream> #include <thread> #include <string> using namespace std; //测试函数 void printStrin…...

代理IP在游戏中的作用有哪些?
游戏代理IP的作用是什么?IP代理软件相当于连接客户端和虚拟服务器的软件“中转站”,在我们向远程服务器提出需求后,代理服务器首先获得用户的请求,然后将服务请求转移到远程服务器,然后将远程服务器反馈的结果转移到客…...

SVN Previous operation has not finished; run ‘cleanup‘ if it was interrupted
SVN cleanup出现下面的提示: svn: E155017: Can’t install ‘*’ from pristine store, because no checksum is recorded for this file svn报错:“Previous operation has not finished; run ‘cleanup’ if it was interrupted“ 解决办法 当遇到…...
MATLAB知识点:MATLAB的文件管理
讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。 MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili 节选自第2章 上一章我们说过,MATLAB是一款非常强…...

【深度学习】MNN ImageProcess处理图像顺序,逻辑,均值,方差
文章目录 介绍Opencv numpy等效的MNN处理 介绍 MNN ImageProcess处理图像是先reisze还是后resize,均值方差怎么处理,是什么通道顺序?这篇文章告诉你答案。 Opencv numpy 这段代码是一个图像预处理函数,用于对输入的图像进行一系…...

代码随想录算法训练营29期Day35|LeetCode 860,406,452
文档讲解:柠檬水找零 根据身高重建队列 用最小数量的箭引爆气球 860.柠檬水找零 题目链接:https://leetcode.cn/problems/lemonade-change/description/ 思路: 很简单,模拟即可。统计五美元、十美元和十五美元的个数。给五美元…...

20240130金融读报1分钟小得01
1、开放银行本质上是以用户需求为核心,以场景服务为切入点的共享平台金融模式,一定程度上加快了商业银行“隐形”和金融服务的无缝和泛在 2、利用自身优势进行差异化竞争,比如农信的客户面对面交流、全方位覆盖、政银紧密合作。针对劣势进行互…...

刷力扣题过程中发现的不熟的函数
C中不熟的函数 1.memset() 头文件:<string.h> void *memset(void *s,int c,unsigned long n); 为指针变量s所指的前n个字节的内存单元填充给定的int型数值c 如: int a[10]; memset(a,0,sizeof(a)); //将数组a中的数全部赋值为02.sort() &#…...

native2ascii命令详解
native2ascii命令详解 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将深入研究一个在Java开发中常用的命令——native2ascii,解析…...
什么是Vue Vue入门案例
一、什么是Vue 概念:Vue (读音 /vjuː/,类似于 view) 是一套 构建用户界面 的 渐进式 框架 Vue2官网:Vue.js 1.什么是构建用户界面 基于数据渲染出用户可以看到的界面 2.什么是渐进式 所谓渐进式就是循序渐进,不一定非得把V…...

【C/Python】GtkApplicationWindow
一、C语言 GtkApplicationWindow 是 GTK 库中用于创建应用程序主窗口的一个控件。 首先,需要确保环境安装了GTK开发库。然后,以下是一个简单的使用 GtkApplicationWindow 创建一个 GTK 应用程序的示例: #include <gtk/gtk.h>static …...

SpringBoot自定义全局事务
1.说明 关于EnableTransactionManagement注解,可加可不加,加注解保证规范性。 2.核心代码 /** * author: wangning * date: 2024/1/23 16:19 */ Aspect Configuration ConditionalOnClass({TransactionManager.class, TransactionFactory.class}) pub…...

【FINEBI】finebi中常用图表类型及其适用场景
柱状图(Bar Chart): 比较不同类别或组之间的数量差异:柱状图可以用于比较不同产品、地区、时间段等的销售额、市场份额等。 显示不同时间段的数据变化:通过绘制柱状图,可以观察到销售额、网站流量等随时间…...
Kaggle竞赛系列_SpaceshipTitanic金牌方案分析_数据分析
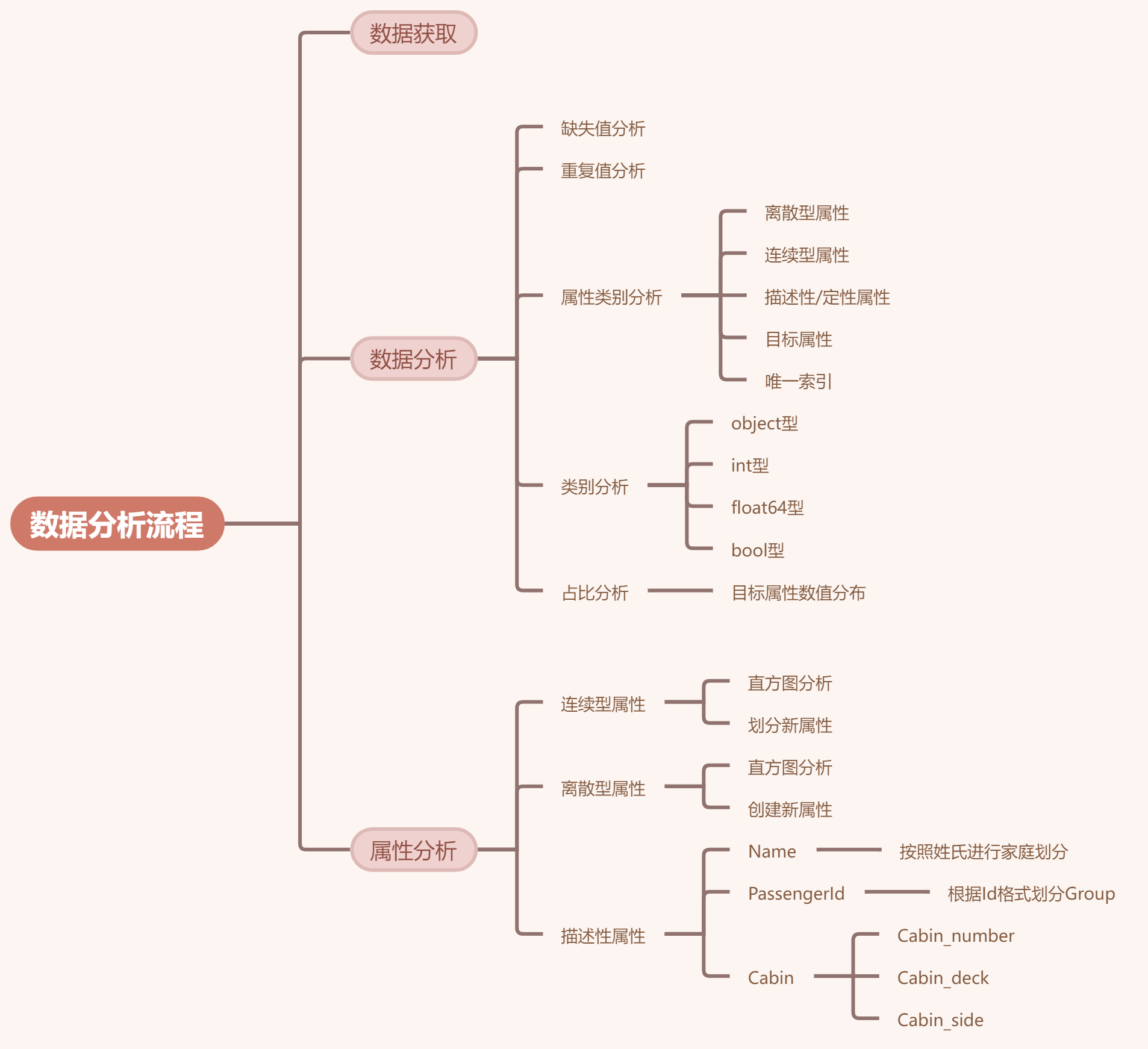
文章目录 【文章系列】【前言】【比赛简介】【正文】(一)数据获取(二)数据分析1. 缺失值2. 重复值3. 属性类型分析4. 类别分析5. 分析目标数值占比 (三)属性分析1. 对年龄Age分析(1)…...

Tortoise-tts Better speech synthesis through scaling——TTS论文阅读
笔记地址:https://flowus.cn/share/a79f6286-b48f-42be-8425-2b5d0880c648 【FlowUs 息流】tortoise 论文地址: Better speech synthesis through scaling Abstract: 自回归变换器和DDPM:自回归变换器(autoregressive transfo…...

单元测试工具JEST入门——纯函数的测试
单元测试工具JEST入门——纯函数的测试 什么是测试❓🙉 我只是开发而已?常见单元测试工具 🔧jest的使用👀 首先你得知道一个简单的例子🌰😨 Oops!出现了一些问题👏 高效的持续监听&a…...
Elasticsearch Windows版安装配置
Elasticsearch简介 Elasticsearch是一个开源的搜索文献的引擎,大概含义就是你通过Rest请求告诉它关键字,他给你返回对应的内容,就这么简单。 Elasticsearch封装了Lucene,Lucene是apache软件基金会一个开放源代码的全文检索引擎工…...
安装 vant-ui 实现底部导航栏 Tabbar
本例子使用vue3 介绍 vant-ui 地址:介绍 - Vant 4 (vant-ui.github.io) Vant 是一个轻量、可定制的移动端组件库 安装 通过 npm 安装: # Vue 3 项目,安装最新版 Vant npm i vant # Vue 2 项目,安装 Vant 2 npm i vantlatest-v…...
:openclaw agent 如何触发一次 Agent 运行?)
OpenClaw 源码解析(六):openclaw agent 如何触发一次 Agent 运行?
1. 本期要解决的问题 前几期我们已经从项目整体结构、CLI 命令体系、配置加载、Gateway 运行机制等角度理解了 OpenClaw 的基础框架。到了这一期,可以进一步进入 OpenClaw 最核心的使用动作:用户在终端中执行一条 openclaw agent --message "...&q…...

SuperCom串口调试工具终极指南:快速解决嵌入式开发中的通信难题
SuperCom串口调试工具终极指南:快速解决嵌入式开发中的通信难题 【免费下载链接】SuperCom SuperCom 是一款串口调试工具 项目地址: https://gitcode.com/gh_mirrors/su/SuperCom 想象一下这样的场景:你正在调试一个嵌入式设备,需要同…...

ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 [特殊字符]
ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 🚀 【免费下载链接】clojuredocs clojuredocs.org web app 项目地址: https://gitcode.com/gh_mirrors/cl/clojuredocs ClojureDocs作为社区驱动的Clojure文档网站,其性能优…...

3大核心模块+5步实战:用RPFM彻底改变《全面战争》模组开发体验
3大核心模块5步实战:用RPFM彻底改变《全面战争》模组开发体验 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: http…...

从Bing日志到学术基准:MS MARCO数据集的前世今生与你的信息检索实验
从Bing日志到学术基准:MS MARCO数据集的前世今生与你的信息检索实验 当你在深夜调试信息检索模型时,是否曾好奇过那些基准数据集背后的故事?MS MARCO——这个让无数研究者又爱又恨的数据集,最初只是Bing搜索引擎日志中的普通用户查…...

知其雄,守其雌,为天下谿,在 SAP Fiori Elements 开发里修一条能承载业务之水的溪谷
老子《道德经》第二十八章说,知其雄,守其雌,为天下谿。完整语境里,这句话后面还接着,为天下谿,常德不离,复归于婴儿。中国哲学书电子化计划收录的《道德经》第二十八章文本,也把这组句子放在知其白、守其黑,知其荣、守其辱这一连串对照之中,可见老子并不是简单赞美柔…...

戴森球计划终极蓝图指南:3000+工厂设计快速提升建造效率
戴森球计划终极蓝图指南:3000工厂设计快速提升建造效率 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 还在为《戴森球计划》中复杂的工厂布局而烦恼吗…...

Seraphine:英雄联盟玩家的5大核心功能终极助手,一键提升游戏体验
Seraphine:英雄联盟玩家的5大核心功能终极助手,一键提升游戏体验 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款专为《英雄联盟》玩家设计的智能游戏辅助工具…...

QMCDecode:终极QQ音乐格式解密指南,一键解放你的加密音乐库
QMCDecode:终极QQ音乐格式解密指南,一键解放你的加密音乐库 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...

微软365 OAuth令牌劫持:静默持久化攻击与防御实战
1. 这不是漏洞预警,而是一场正在发生的“静默接管”你有没有遇到过这样的情况:IT管理员在后台看到某个用户账户持续发起异常的Exchange Online PowerShell连接,但该用户坚称自己没操作;或者安全团队收到Azure AD登录日志告警&…...