ClickHouse(22)ClickHouse集成HDFS表引擎详细解析
文章目录
- HDFS
- 用法
- 实施细节
- 配置
- 可选配置选项及其默认值的列表
- libhdfs3 支持的
- ClickHouse 额外的配置
- 限制
- Kerberos 支持
- 虚拟列
- 资料分享
- 系列文章
- clickhouse系列文章
- 知乎系列文章
HDFS
这个引擎提供了与Apache Hadoop生态系统的集成,允许通过ClickHouse管理HDFS上的数据。这个引擎提供了Hadoop的特定功能。
用法
ENGINE = HDFS(URI, format)
URI 参数是HDFS中整个文件的URI
format 参数指定一种可用的文件格式。执行SELECT查询时,格式必须支持输入,以及执行INSERT查询时,格式必须支持输出.路径部分URI可能包glob通配符。在这种情况下,表将是只读的。
clickhouse支持的format,文件格式:
| 格式 | 输入 | 输出 |
|---|---|---|
| [TabSeparated] | ✔ | ✔ |
| [TabSeparatedRaw] | ✔ | ✔ |
| [TabSeparatedWithNames] | ✔ | ✔ |
| [TabSeparatedWithNamesAndTypes] | ✔ | ✔ |
| [Template] | ✔ | ✔ |
| [TemplateIgnoreSpaces] | ✔ | ✗ |
| [CSV] | ✔ | ✔ |
| [CSVWithNames] | ✔ | ✔ |
| [CustomSeparated] | ✔ | ✔ |
| [Values] | ✔ | ✔ |
| [Vertical] | ✗ | ✔ |
| [JSON] | ✗ | ✔ |
| [JSONAsString] | ✔ | ✗ |
| [JSONStrings] | ✗ | ✔ |
| [JSONCompact] | ✗ | ✔ |
| [JSONCompactStrings] | ✗ | ✔ |
| [JSONEachRow] | ✔ | ✔ |
| [JSONEachRowWithProgress] | ✗ | ✔ |
| [JSONStringsEachRow] | ✔ | ✔ |
| [JSONStringsEachRowWithProgress] | ✗ | ✔ |
| [JSONCompactEachRow] | ✔ | ✔ |
| [JSONCompactEachRowWithNamesAndTypes] | ✔ | ✔ |
| [JSONCompactStringsEachRow] | ✔ | ✔ |
| [JSONCompactStringsEachRowWithNamesAndTypes] | ✔ | ✔ |
| [TSKV] | ✔ | ✔ |
| [Pretty] | ✗ | ✔ |
| [PrettyCompact] | ✗ | ✔ |
| [PrettyCompactMonoBlock] | ✗ | ✔ |
| [PrettyNoEscapes] | ✗ | ✔ |
| [PrettySpace] | ✗ | ✔ |
| [Protobuf] | ✔ | ✔ |
| [ProtobufSingle] | ✔ | ✔ |
| [Avro] | ✔ | ✔ |
| [AvroConfluent] | ✔ | ✗ |
| [Parquet] | ✔ | ✔ |
| [Arrow] | ✔ | ✔ |
| [ArrowStream] | ✔ | ✔ |
| [ORC] | ✔ | ✔ |
| [RowBinary] | ✔ | ✔ |
| [RowBinaryWithNamesAndTypes] | ✔ | ✔ |
| [Native] | ✔ | ✔ |
| [Null] | ✗ | ✔ |
| [XML] | ✗ | ✔ |
| [CapnProto] | ✔ | ✗ |
| [LineAsString] | ✔ | ✗ |
| [Regexp] | ✔ | ✗ |
| [RawBLOB] | ✔ | ✔ |
示例:
1. 设置 hdfs_engine_table 表:
CREATE TABLE hdfs_engine_table (name String, value UInt32) ENGINE=HDFS('hdfs://hdfs1:9000/other_storage', 'TSV')
2. 填充文件:
INSERT INTO hdfs_engine_table VALUES ('one', 1), ('two', 2), ('three', 3)
3. 查询数据:
SELECT * FROM hdfs_engine_table LIMIT 2
┌─name─┬─value─┐
│ one │ 1 │
│ two │ 2 │
└──────┴───────┘
实施细节
- 读取和写入可以并行
- 不支持:
ALTER和SELECT...SAMPLE操作。- 索引。
- 复制。
路径中的通配符
多个路径组件可以具有 globs。 对于正在处理的文件应该存在并匹配到整个路径模式。 文件列表的确定是在 SELECT 的时候进行(而不是在 CREATE 的时候)。
*— 替代任何数量的任何字符,除了/以及空字符串。?— 代替任何单个字符.{some_string,another_string,yet_another_one}— 替代任何字符串'some_string', 'another_string', 'yet_another_one'.{N..M}— 替换 N 到 M 范围内的任何数字,包括两个边界的值.
示例
- 假设我们在 HDFS 上有几个 TSV 格式的文件,文件的 URI 如下:
- ‘hdfs://hdfs1:9000/some_dir/some_file_1’
- ‘hdfs://hdfs1:9000/some_dir/some_file_2’
- ‘hdfs://hdfs1:9000/some_dir/some_file_3’
- ‘hdfs://hdfs1:9000/another_dir/some_file_1’
- ‘hdfs://hdfs1:9000/another_dir/some_file_2’
- ‘hdfs://hdfs1:9000/another_dir/some_file_3’
- 有几种方法可以创建由所有六个文件组成的表:
CREATE TABLE table_with_range (name String, value UInt32) ENGINE = HDFS('hdfs://hdfs1:9000/{some,another}_dir/some_file_{1..3}', 'TSV')
另一种方式:
CREATE TABLE table_with_question_mark (name String, value UInt32) ENGINE = HDFS('hdfs://hdfs1:9000/{some,another}_dir/some_file_?', 'TSV')
表由两个目录中的所有文件组成(所有文件都应满足query中描述的格式和模式):
CREATE TABLE table_with_asterisk (name String, value UInt32) ENGINE = HDFS('hdfs://hdfs1:9000/{some,another}_dir/*', 'TSV')
注意:
如果文件列表包含带有前导零的数字范围,请单独使用带有大括号的构造或使用 `?`.
示例
创建具有名为文件的表 file000, file001, … , file999:
CREARE TABLE big_table (name String, value UInt32) ENGINE = HDFS('hdfs://hdfs1:9000/big_dir/file{0..9}{0..9}{0..9}', 'CSV')
配置
与 GraphiteMergeTree 类似,HDFS 引擎支持使用 ClickHouse 配置文件进行扩展配置。有两个配置键可以使用:全局 (hdfs) 和用户级别 (hdfs_*)。首先全局配置生效,然后用户级别配置生效 (如果用户级别配置存在) 。
<!-- HDFS 引擎类型的全局配置选项 --><hdfs><hadoop_kerberos_keytab>/tmp/keytab/clickhouse.keytab</hadoop_kerberos_keytab><hadoop_kerberos_principal>clickuser@TEST.CLICKHOUSE.TECH</hadoop_kerberos_principal><hadoop_security_authentication>kerberos</hadoop_security_authentication></hdfs><!-- 用户 "root" 的指定配置 --><hdfs_root><hadoop_kerberos_principal>root@TEST.CLICKHOUSE.TECH</hadoop_kerberos_principal></hdfs_root>
可选配置选项及其默认值的列表
libhdfs3 支持的
| 参数 | 默认值 |
| rpc_client_connect_tcpnodelay | true |
| dfs_client_read_shortcircuit | true |
| output_replace-datanode-on-failure | true |
| input_notretry-another-node | false |
| input_localread_mappedfile | true |
| dfs_client_use_legacy_blockreader_local | false |
| rpc_client_ping_interval | 10 * 1000 |
| rpc_client_connect_timeout | 600 * 1000 |
| rpc_client_read_timeout | 3600 * 1000 |
| rpc_client_write_timeout | 3600 * 1000 |
| rpc_client_socekt_linger_timeout | -1 |
| rpc_client_connect_retry | 10 |
| rpc_client_timeout | 3600 * 1000 |
| dfs_default_replica | 3 |
| input_connect_timeout | 600 * 1000 |
| input_read_timeout | 3600 * 1000 |
| input_write_timeout | 3600 * 1000 |
| input_localread_default_buffersize | 1 * 1024 * 1024 |
| dfs_prefetchsize | 10 |
| input_read_getblockinfo_retry | 3 |
| input_localread_blockinfo_cachesize | 1000 |
| input_read_max_retry | 60 |
| output_default_chunksize | 512 |
| output_default_packetsize | 64 * 1024 |
| output_default_write_retry | 10 |
| output_connect_timeout | 600 * 1000 |
| output_read_timeout | 3600 * 1000 |
| output_write_timeout | 3600 * 1000 |
| output_close_timeout | 3600 * 1000 |
| output_packetpool_size | 1024 |
| output_heeartbeat_interval | 10 * 1000 |
| dfs_client_failover_max_attempts | 15 |
| dfs_client_read_shortcircuit_streams_cache_size | 256 |
| dfs_client_socketcache_expiryMsec | 3000 |
| dfs_client_socketcache_capacity | 16 |
| dfs_default_blocksize | 64 * 1024 * 1024 |
| dfs_default_uri | “hdfs://localhost:9000” |
| hadoop_security_authentication | “simple” |
| hadoop_security_kerberos_ticket_cache_path | “” |
| dfs_client_log_severity | “INFO” |
| dfs_domain_socket_path | “” |
HDFS 配置参考 也许会解释一些参数的含义.
ClickHouse 额外的配置
| 参数 | 默认值 |
|hadoop_kerberos_keytab | “” |
|hadoop_kerberos_principal | “” |
|hadoop_kerberos_kinit_command | kinit |
限制
- hadoop_security_kerberos_ticket_cache_path 只能在全局配置, 不能指定用户
Kerberos 支持
如果 hadoop_security_authentication 参数的值为 ‘kerberos’ ,ClickHouse 将通过 Kerberos 设施进行认证。
注意,由于 libhdfs3 的限制,只支持老式的方法。数据节点的安全通信无法由SASL保证 ( HADOOP_SECURE_DN_USER 是这种安全方法的一个可靠指标)。
如果指定了hadoop_kerberos_keytab, hadoop_kerberos_principal或者hadoop_kerberos_kinit_command,将会调用kinit工具.在此情况下,hadoop_kerberos_keytab和hadoop_kerberos_principal参数是必须配置的.kinit工具和 krb5 配置文件是必要的.
虚拟列
_path— 文件路径._file— 文件名.
资料分享
ClickHouse经典中文文档分享
系列文章
clickhouse系列文章
- ClickHouse(01)什么是ClickHouse,ClickHouse适用于什么场景
- ClickHouse(02)ClickHouse架构设计介绍概述与ClickHouse数据分片设计
- ClickHouse(03)ClickHouse怎么安装和部署
- ClickHouse(04)如何搭建ClickHouse集群
- ClickHouse(05)ClickHouse数据类型详解
- ClickHouse(06)ClickHouse建表语句DDL详细解析
- ClickHouse(07)ClickHouse数据库引擎解析
- ClickHouse(08)ClickHouse表引擎概况
- ClickHouse(09)ClickHouse合并树MergeTree家族表引擎之MergeTree详细解析
- ClickHouse(10)ClickHouse合并树MergeTree家族表引擎之ReplacingMergeTree详细解析
- ClickHouse(11)ClickHouse合并树MergeTree家族表引擎之SummingMergeTree详细解析
- ClickHouse(12)ClickHouse合并树MergeTree家族表引擎之AggregatingMergeTree详细解析
- ClickHouse(13)ClickHouse合并树MergeTree家族表引擎之CollapsingMergeTree详细解析
- ClickHouse(14)ClickHouse合并树MergeTree家族表引擎之VersionedCollapsingMergeTree详细解析
- ClickHouse(15)ClickHouse合并树MergeTree家族表引擎之GraphiteMergeTree详细解析
- ClickHouse(16)ClickHouse日志表引擎Log详细解析
- ClickHouse(17)ClickHouse集成JDBC表引擎详细解析
- ClickHouse(18)ClickHouse集成ODBC表引擎详细解析
- ClickHouse(19)ClickHouse集成Hive表引擎详细解析
- ClickHouse(20)ClickHouse集成PostgreSQL表引擎详细解析
- ClickHouse(21)ClickHouse集成Kafka表引擎详细解析
- ClickHouse(22)ClickHouse集成HDFS表引擎详细解析
知乎系列文章
- ClickHouse(01)什么是ClickHouse,ClickHouse适用于什么场景
- ClickHouse(02)ClickHouse架构设计介绍概述与ClickHouse数据分片设计
- ClickHouse(03)ClickHouse怎么安装和部署
- ClickHouse(04)如何搭建ClickHouse集群
- ClickHouse(05)ClickHouse数据类型详解
- ClickHouse(06)ClickHouse建表语句DDL详细解析
- ClickHouse(07)ClickHouse数据库引擎解析
- ClickHouse(08)ClickHouse表引擎概况
- ClickHouse(09)ClickHouse合并树MergeTree家族表引擎之MergeTree详细解析
- ClickHouse(10)ClickHouse合并树MergeTree家族表引擎之ReplacingMergeTree详细解析
- ClickHouse(11)ClickHouse合并树MergeTree家族表引擎之SummingMergeTree详细解析
- ClickHouse(12)ClickHouse合并树MergeTree家族表引擎之AggregatingMergeTree详细解析
- ClickHouse(13)ClickHouse合并树MergeTree家族表引擎之CollapsingMergeTree详细解析
- ClickHouse(14)ClickHouse合并树MergeTree家族表引擎之VersionedCollapsingMergeTree详细解析
- ClickHouse(15)ClickHouse合并树MergeTree家族表引擎之GraphiteMergeTree详细解析
- ClickHouse(16)ClickHouse日志引擎Log详细解析
- ClickHouse(17)ClickHouse集成JDBC表引擎详细解析
- ClickHouse(18)ClickHouse集成ODBC表引擎详细解析
- ClickHouse(19)ClickHouse集成Hive表引擎详细解析
- ClickHouse(21)ClickHouse集成Kafka表引擎详细解析
- ClickHouse(22)ClickHouse集成HDFS表引擎详细解析
相关文章:
ClickHouse集成HDFS表引擎详细解析)
ClickHouse(22)ClickHouse集成HDFS表引擎详细解析
文章目录 HDFS用法实施细节配置可选配置选项及其默认值的列表libhdfs3 支持的ClickHouse 额外的配置限制 Kerberos 支持虚拟列 资料分享系列文章clickhouse系列文章知乎系列文章 HDFS 这个引擎提供了与Apache Hadoop生态系统的集成,允许通过ClickHouse管理HDFS上的…...
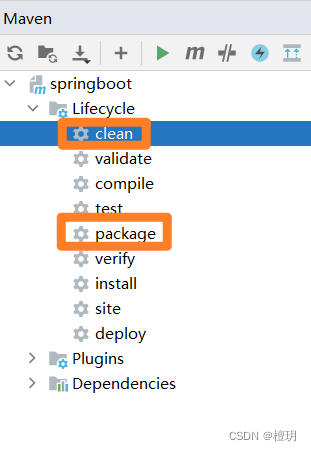
idea报错 :(java: 找不到符号)
java: 找不到符号 符号: 变量 adminService 位置: 类 com.example.controller.WebController 查到网上一个办法:因为项目是maven:先点clean在点package...

设计软件最重要的目标是可理解性?
当您设计一款软件时,设计时最重要的一点就是可理解性。安全性、性能和正确性都很重要,但它们次优于可理解性。 被误解的软件会产生Bug缺陷 如果软件的实施者和维护者对软件存在误解,那么软件最终就会出现缺陷。主要缺陷。这些缺陷有多种形式…...

酒店|酒店管理小程序|基于微信小程序的酒店管理系统设计与实现(源码+数据库+文档)
酒店管理小程序目录 目录 基于微信小程序的酒店管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、管理员模块的实现 (1) 用户信息管理 (2) 酒店管理员管理 (3) 房间信息管理 2、小程序序会员模块的实现 (1)系统首页 ࿰…...
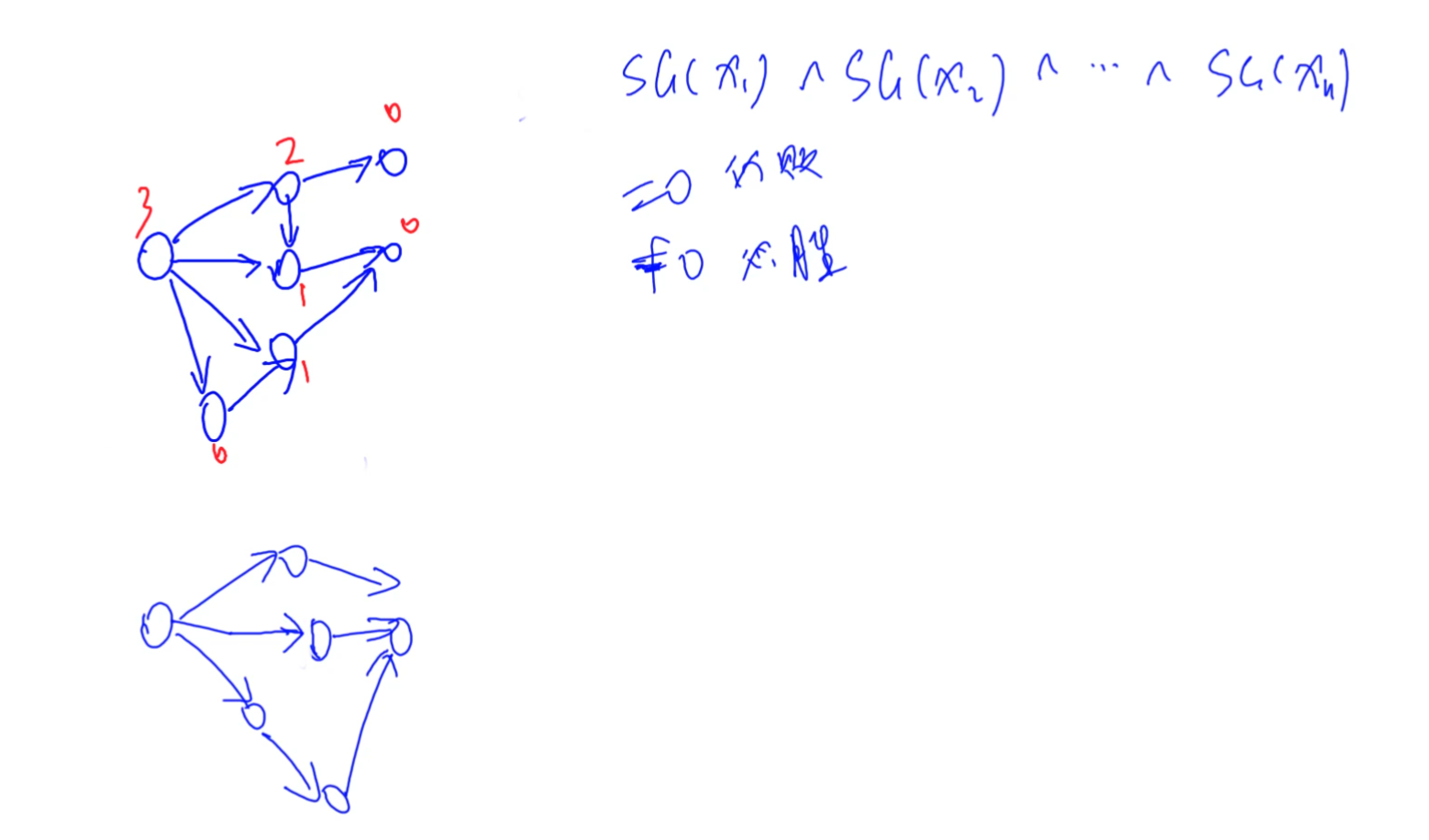
C++ 数论相关题目,博弈论,SG函数,集合-Nim游戏
给定 n 堆石子以及一个由 k 个不同正整数构成的数字集合 S 。 现在有两位玩家轮流操作,每次操作可以从任意一堆石子中拿取石子,每次拿取的石子数量必须包含于集合 S ,最后无法进行操作的人视为失败。 问如果两人都采用最优策略,…...

学者观察 | 区块链技术理论研究与实践观察——中央财经大学朱建明
导语 当下区块链研究成果质量越来越高,技术应用越来越成熟。在现阶段的研究中存在哪些短板需要弥补,如何将研究成果转化为推动数字经济高质量发展的实际应用,区块链技术与其他新技术结合发展将带来哪些新的机遇? 中央财经大学朱…...
使用Promethues+Grafana监控Elasticsearch
PromethuesGrafana监控Elasticsearch 监控选用说明指标上报流程说明实现监控的步骤搭建elasticsearch-exporter服务搭建promethues和grafana服务 监控选用说明 虽然用Kibana来监控ES,能展示一些关键指标,但ES本身收集的指标并不全面,还需要在…...
研学活动报名平台源码开发方案
一、项目背景与目标 (一)项目背景 研学活动报名平台旨在为活动组织者提供方便快捷的研学活动管理工具,同时为用户提供全面的活动搜索、报名和支付等功能。通过该系统,活动组织者能够更好地管理活动报名信息,用户也可…...

一篇文章,彻底理解数据库操作语言:DDL、DML、DCL、TCL
最近与开发和运维讨论数据库账号及赋权问题时,发现大家对DDL和DML两个概念并不了解。于是写一篇文章,系统的整理一下在数据库领域中的DDL、DML、DQL、DCL的使用及区别。 通常,数据库SQL语言共分为四大类:数据定义语言DDL…...
Linux编辑器之vim的使用
文章目录 一、vim简介二、vim的基本概念三、vim的基本操作四、vim正常模式命令集移动光标删除文字复制替换撤销上一次操作更改跳至指定的行vim末行模式命令集列出行号跳到文件中的某一行查找字符保存文件离开vim 五、进阶vim玩法打开文件批量注释代码执行shell命令指定注释窗口…...
制作OpenSSH 9.6 for openEuler 22.03 LTS的rpm升级包
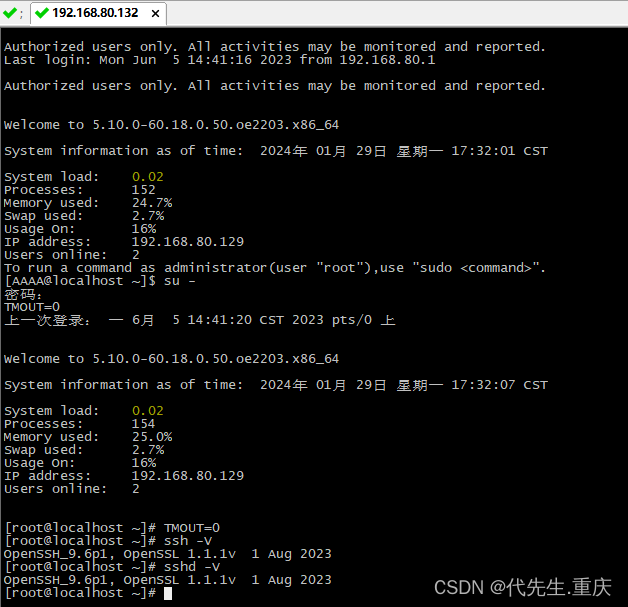
OpenSSH作为操作系统底层管理平台软件,需要保持更新以免遭受安全攻击,编译生成rpm包是生产环境中批量升级的最佳途径。本文在国产openEuler 22.03 LTS系统上完成OpenSSH 9.6的编译工作。 一、编译环境 1、准备环境 基于vmware workstation发布的x86虚…...

DNS配置文件讲解
1. 概述 BIND:Berkeley Internet Name Domain ,伯克利因特网域名解析服务是一种全球使用最广泛的、 最高效的、最安全的域名解析服务程序 2. 安装软件 [rootserver ~]# yum install bind -y 3. bind服务中三个关键文件 /etc/named.conf : 主配置文件…...

142:vue+leaflet 加载tomtom地图(多种形式)
第142个 点击查看专栏目录 本示例介绍如何在vue+leaflet中添加tomtom地图,这里包含了多种形式,诸如中文标记、英文标记、白天地图、晚上地图、卫星影像图,高山海拔地形图等。 直接复制下面的 vue+leaflet源代码,操作2分钟即可运行实现效果 文章目录 示例效果配置方式示例…...

Android Mac电脑更改aar中的文件再打包
一 问题 要在Mac电脑上替换AAR中的文件并重新打包。 二 解决方案 1.解压AAR文件 将AAR文件重命名为.zip,并解压缩它,得到一个文件夹。 2.替换文件 在解压后的文件夹中找到您想替换的文件,将其替换为新文件。 3.重新打包 打开终端&…...

Jmeter脚本录制:抓取IOS手机请求包!
现在移动端的项目越来越多,今天给大家介绍一下,在IOS下Jmeter如何抓包。 1、电脑连上wifi; 2、Jmeter中配置“HTTP代理服务器” 1)启动Jmeter; 2)“测试计划”中添加“线程组”; 3)“测试计划”中添加“HTTP代理服务器”&#…...
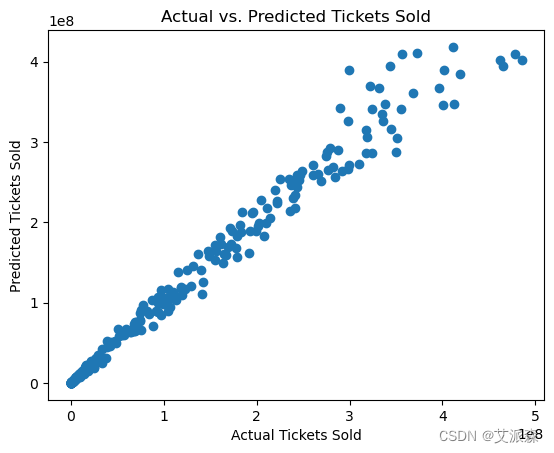
大数据分析案例-基于随机森林算法构建电影票房预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

关于Gitlab用户登录提示无限重定向循环ERR_TOO_MANY_REDIRECTS
#工作笔记# 查阅了网上所有相关的记录,都没有解决gitlab登录/users/sign_up/welcome提示ERR_TOO_MANY_REDIRECTS,好在最终解决了,记录在此。 先说下起因: github哼哼不想用了,原因太多,所以内部讨论用git…...
突破瓶颈,提升开发效率:Spring框架进阶与最佳实践-IOC
IOC相关内容 1.1 bean基础配置1.1.1 bean基础配置(id与class)1.1.2 bean的name属性步骤1:配置别名步骤2:根据名称容器中获取bean对象步骤3:运行程序 1.1.3 bean作用范围scope配置1.1.3.1 验证IOC容器中对象是否为单例验证思路具体实现 1.1.3.2 配置bean为非单例1.1.…...

西方网络安全人才培养的挑战及对策
文章目录 前言一、网络安全人才力量发展现状(一)注重从战略上重视网络安全人才培养和发展。(二)注重从多渠道多路径招募网络安全人才。(三)注重分层次分阶段系统规划网络安全人才培养模式。(四)注重通过实践锻炼进一步提升网络攻防实战能力。二、网络安全人才面临的形势…...

计算机网络之三次握手,四次挥手
TCP(传输控制协议)是一种面向连接的、可靠的传输层协议,用于在网络中的两个应用程序之间建立可靠的通信连接。TCP的核心特征之一是它使用“三次握手”过程来建立连接,以及“四次挥手”过程来终止连接。 三次握手(建立…...
)
【程序源代码】答题微信小程序(含源码)
关键字:答题,小程序,OCR, 题目识别,题库,练习,错题集,微信小程序,Vue项目名称:答题微信小程序答题小程序是面向学生群体打造的轻量化在线答题学习平台,基于微…...

别装Matlab了!用这个免费网站Desmos,5分钟搞定函数绘图和矩阵计算
告别笨重软件:用Desmos在线工具5分钟完成专业级数学计算数学计算和可视化是科研、工程和教学中不可或缺的环节。传统解决方案如Matlab、Mathematica虽然功能强大,但存在价格昂贵、安装包庞大、启动缓慢等问题。对于需要快速验证数学问题的用户来说&#…...
)
esp开发与应用(1602液晶显示屏)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】模块当中,有的是比较简单的,比如说蜂鸣器,尤其是有源蜂鸣器。大家可以把它想象成是一个gpio输出的喇叭ÿ…...
)
07-大模型智能体开发工程师:提示词工程(Prompt Engineering)
系列文章导航:AI系列文章导航目录-持续更新中 第07课:提示词工程(Prompt Engineering) 📝 本文摘要:本文系统讲解提示词工程的核心认知和方法论,包括六大设计原则(清晰明确、给出示例…...

Go语言内存泄漏:pprof与监控
Go语言内存泄漏:pprof与监控 1. 内存泄漏检测 go tool pprof http://localhost:6060/debug/pprof/heap2. 总结 定期使用pprof检测内存使用,及时发现泄漏。...

【SpringBoot+Elasticsearch 内容搜索系统实战】:架构设计与全流程实现
🔥你好我是fengxin_rou这是我的个人主页fengxin_rou的主页 ❄️欢迎查看我的专栏我的专栏 《Java后端学习》、《JAVASE基础》、《JUC并发》、《redis》、《JVM虚拟机》、《MYSQL》、《黑马点评》、《rabbitmq》、《JavaWebAI的talis学习系统》、《苍穹外卖》 目录…...

矩阵补全因果推断:破解贸易政策评估中的内生性与异质性难题
1. 项目概述:当因果推断遇上贸易政策评估的“硬骨头”做贸易政策评估的同行都知道,这事儿有多棘手。你想啊,一个国家签了个自由贸易协定(FTA),几年后出口额涨了,你怎么知道这增长里有多少是协定…...

漏洞研究工作流:从CVE追踪到实战提升的闭环方法论
1. 这不是“资源列表”,而是一套可落地的漏洞研究工作流很多人一看到“在线资源全攻略”就下意识点开收藏,然后扔进浏览器书签夹吃灰。我见过太多安全从业者——包括刚入行的蓝队新人、想补实战短板的渗透测试员、甚至部分做红队支撑的工程师——把CVE编…...

使用Taotoken CLI工具一键配置多开发环境与工具密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境与工具密钥 基础教程类,面向需要在不同机器或为不同工具(如OpenCl…...

终极指南:如何用roop-unleashed三分钟制作专业AI换脸视频
终极指南:如何用roop-unleashed三分钟制作专业AI换脸视频 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 你是否曾梦想过轻松制作专业级的AI换脸…...