《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第5章 决策树(代码python实践)
文章目录
- 第5章 决策树—python 实践
- 书上题目5.1
- 利用ID3算法生成决策树,例5.3
- scikit-learn实例
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第5章 决策树
第5章 决策树—python 实践
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inlinefrom sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
from math import log
import pprint
书上题目5.1

def create_data():datasets = [['青年', '否', '否', '一般', '否'],['青年', '否', '否', '好', '否'],['青年', '是', '否', '好', '是'],['青年', '是', '是', '一般', '是'],['青年', '否', '否', '一般', '否'],['中年', '否', '否', '一般', '否'],['中年', '否', '否', '好', '否'],['中年', '是', '是', '好', '是'],['中年', '否', '是', '非常好', '是'],['中年', '否', '是', '非常好', '是'],['老年', '否', '是', '非常好', '是'],['老年', '否', '是', '好', '是'],['老年', '是', '否', '好', '是'],['老年', '是', '否', '非常好', '是'],['老年', '否', '否', '一般', '否'],]labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']# 返回数据集和每个维度的名称return datasets, labels
datasets, labels = create_data()
train_data = pd.DataFrame(datasets, columns=labels)
# 熵
def calc_ent(datasets):data_length = len(datasets)label_count = {}for i in range(data_length):label = datasets[i][-1]if label not in label_count:label_count[label] = 0label_count[label] += 1ent = -sum([(p / data_length) * log(p / data_length, 2)for p in label_count.values()])return ent# 经验条件熵
def cond_ent(datasets, axis=0):data_length = len(datasets)feature_sets = {}for i in range(data_length):feature = datasets[i][axis]if feature not in feature_sets:feature_sets[feature] = []feature_sets[feature].append(datasets[i])cond_ent = sum([(len(p) / data_length) * calc_ent(p) for p in feature_sets.values()])return cond_ent# 信息增益:熵-经验条件熵
def info_gain(ent, cond_ent):return ent - cond_entdef info_gain_train(datasets):count = len(datasets[0]) - 1ent = calc_ent(datasets)best_feature = []for c in range(count):c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))best_feature.append((c, c_info_gain))print('特征({}) - info_gain - {:.3f}'.format(labels[c], c_info_gain))# 比较大小best_ = max(best_feature, key=lambda x: x[-1])return '特征({})的信息增益最大,选择为根节点特征'.format(labels[best_[0]])
info_gain_train(np.array(datasets))
===================================
特征(年龄) - info_gain - 0.083
特征(有工作) - info_gain - 0.324
特征(有自己的房子) - info_gain - 0.420
特征(信贷情况) - info_gain - 0.363
'特征(有自己的房子)的信息增益最大,选择为根节点特征'
利用ID3算法生成决策树,例5.3
# 定义节点类 二叉树
class Node:def __init__(self, root=True, label=None, feature_name=None, feature=None):self.root = rootself.label = labelself.feature_name = feature_nameself.feature = featureself.tree = {}self.result = {'label:': self.label,'feature': self.feature,'tree': self.tree}def __repr__(self):return '{}'.format(self.result)def add_node(self, val, node):self.tree[val] = nodedef predict(self, features):if self.root is True:return self.labelreturn self.tree[features[self.feature]].predict(features)class DTree:def __init__(self, epsilon=0.1):self.epsilon = epsilonself._tree = {}# 熵@staticmethoddef calc_ent(datasets):data_length = len(datasets)label_count = {}for i in range(data_length):label = datasets[i][-1]if label not in label_count:label_count[label] = 0label_count[label] += 1ent = -sum([(p / data_length) * log(p / data_length, 2)for p in label_count.values()])return ent# 经验条件熵def cond_ent(self, datasets, axis=0):data_length = len(datasets)feature_sets = {}for i in range(data_length):feature = datasets[i][axis]if feature not in feature_sets:feature_sets[feature] = []feature_sets[feature].append(datasets[i])cond_ent = sum([(len(p) / data_length) * self.calc_ent(p)for p in feature_sets.values()])return cond_ent# 信息增益@staticmethoddef info_gain(ent, cond_ent):return ent - cond_entdef info_gain_train(self, datasets):count = len(datasets[0]) - 1ent = self.calc_ent(datasets)best_feature = []for c in range(count):c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))best_feature.append((c, c_info_gain))# 比较大小best_ = max(best_feature, key=lambda x: x[-1])return best_def train(self, train_data):"""input:数据集D(DataFrame格式),特征集A,阈值etaoutput:决策树T"""_, y_train, features = train_data.iloc[:, :-1], train_data.iloc[:,-1], train_data.columns[:-1]# 1,若D中实例属于同一类Ck,则T为单节点树,并将类Ck作为结点的类标记,返回Tif len(y_train.value_counts()) == 1:return Node(root=True, label=y_train.iloc[0])# 2, 若A为空,则T为单节点树,将D中实例树最大的类Ck作为该节点的类标记,返回Tif len(features) == 0:return Node(root=True,label=y_train.value_counts().sort_values(ascending=False).index[0])# 3,计算最大信息增益 同5.1,Ag为信息增益最大的特征max_feature, max_info_gain = self.info_gain_train(np.array(train_data))max_feature_name = features[max_feature]# 4,Ag的信息增益小于阈值eta,则置T为单节点树,并将D中是实例数最大的类Ck作为该节点的类标记,返回Tif max_info_gain < self.epsilon:return Node(root=True,label=y_train.value_counts().sort_values(ascending=False).index[0])# 5,构建Ag子集node_tree = Node(root=False, feature_name=max_feature_name, feature=max_feature)feature_list = train_data[max_feature_name].value_counts().indexfor f in feature_list:sub_train_df = train_data.loc[train_data[max_feature_name] ==f].drop([max_feature_name], axis=1)# 6, 递归生成树sub_tree = self.train(sub_train_df)node_tree.add_node(f, sub_tree)# pprint.pprint(node_tree.tree)return node_treedef fit(self, train_data):self._tree = self.train(train_data)return self._treedef predict(self, X_test):return self._tree.predict(X_test)
datasets, labels = create_data()
data_df = pd.DataFrame(datasets, columns=labels)
dt = DTree()
tree = dt.fit(data_df)
tree
=============================
{'label:': None, 'feature': 2, 'tree': {'否': {'label:': None, 'feature': 1, 'tree': {'否': {'label:': '否', 'feature': None, 'tree': {}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}
dt.predict(['老年', '否', '否', '一般'])
================================
'否'
scikit-learn实例
# data
def create_data():iris = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)df['label'] = iris.targetdf.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']data = np.array(df.iloc[:100, [0, 1, -1]])# print(data)return data[:, :2], data[:, -1]X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train,)
===================================
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,max_features=None, max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, presort=False, random_state=None,splitter='best')
clf.score(X_test, y_test)
==============================
0.9666666666666667
tree_pic = export_graphviz(clf, out_file="mytree.pdf")
with open('mytree.pdf') as f:dot_graph = f.read()==============================
graphviz.Source(dot_graph)
<graphviz.files.Source at 0x1f159bc2780>
相关文章:
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第5章 决策树(代码python实践)
文章目录 第5章 决策树—python 实践书上题目5.1利用ID3算法生成决策树,例5.3scikit-learn实例 《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第5章 决策树 第5章 决策树—python 实践 import numpy as np import pand…...

电脑可以设置代理IP吗
首先需要回答的是,电脑可以设置代理IP,下面我们详细说说如何设置。 首先,我们使用工具来完成,使用工具的好处就是可以设置单独的软件使用代理,也可以设置全局,比较方便 我们解压这个文件出来,打…...

Zookeeper服务注册与发现实战
目录 设计思路 Zookeeper注册中心的优缺点 SpringCloudZookeeper实现微服务注册中心 第一步:在父pom文件中指定Spring Cloud版本 第二步:微服务pom文件中引入Spring Cloud Zookeeper注册中心依赖 第三步: 微服务配置文件application.y…...

【LeetCode】每日一题 2024_1_30 使循环数组所有元素相等的最少秒数(哈希、贪心、扩散)
文章目录 LeetCode?启动!!!题目:使循环数组所有元素相等的最少秒数题目描述代码与解题思路 LeetCode?启动!!! 今天的题目类型差不多是第一次见到,原来题目描述…...

uni-app vite+ts+vue3模式 集成微信云开发
1.创建uni-app项目 此处使用的是通过vue-cli命令行方式uni-app官网 使用vue3/vite版 创建以 typescript 开发的工程(如命令行创建失败,请直接访问 gitee 下载模板) npx degit dcloudio/uni-preset-vue#vite-ts my-vue3-project(我创建失败…...

一个程序入库出现死锁问题的排查
某虚拟化部署的服务群,发现其中一个程序在写数据库时,经常有死锁现象,一旦出现,持续时间长达数分钟。当时没时间排查,一直到年底才解决。后面又忙,直到月底才有点时间总结。抛开起初没找到问题的时间外&…...

记录解决报错--These dependencies were not found jsencrypt lodash-es
1.场景 idea打包vue,报错退出,缺少依赖 These dependencies were not found jsencrypt lodash-es2.解决步骤 ①到相关目录下直接安装依赖,npm install --save jsencrypt lodash-es。我这里是没安装成功,原因是很多依赖冲突。…...

【极数系列】Flink集成DataSource读取集合数据(07)
文章目录 01 引言02 简介概述03 基于集合读取数据3.1 集合创建数据流3.2 迭代器创建数据流3.3 给定对象创建数据流3.4 迭代并行器创建数据流3.5 基于时间间隔创建数据流3.6 自定义数据流 04 源码实战demo4.1 pom.xml依赖4.2 创建集合数据流作业4.3 运行结果日志 01 引言 源码地…...

React hooks子组件暴露方法示例
说明 通常情况下,React 子组件使用父组件的方法或值通过props传递,反过来,父组件如果需要子组件的方法就需要子组件将自己的方法暴露出去。以下是一个实例: User.tsx import React, { FC, useEffect, useState, useRef } from …...

数据结构:大顶堆、小顶堆
堆是其中一种非常重要且实用的数据结构。堆可以用于实现优先队列,进行堆排序,以及解决各种与查找和排序相关的问题。本文将深入探讨两种常见的堆结构:大顶堆和小顶堆,并通过 C 语言展示如何实现和使用它们。 一、定义 堆是一种完…...

电加热热水器上架亚马逊美国站需要的UL174报告
电加热热水器上架亚马逊美国站需要的UL174报告 家用热水器出口美国需要办理UL174测试报告。 热水器就是指通过各种物理原理,在一定时间内使冷水温度升高变成热水的一种装置。分为制造冷气部分和制造热水部分。其实这两个部分又是紧密地联系在一起,密不可…...
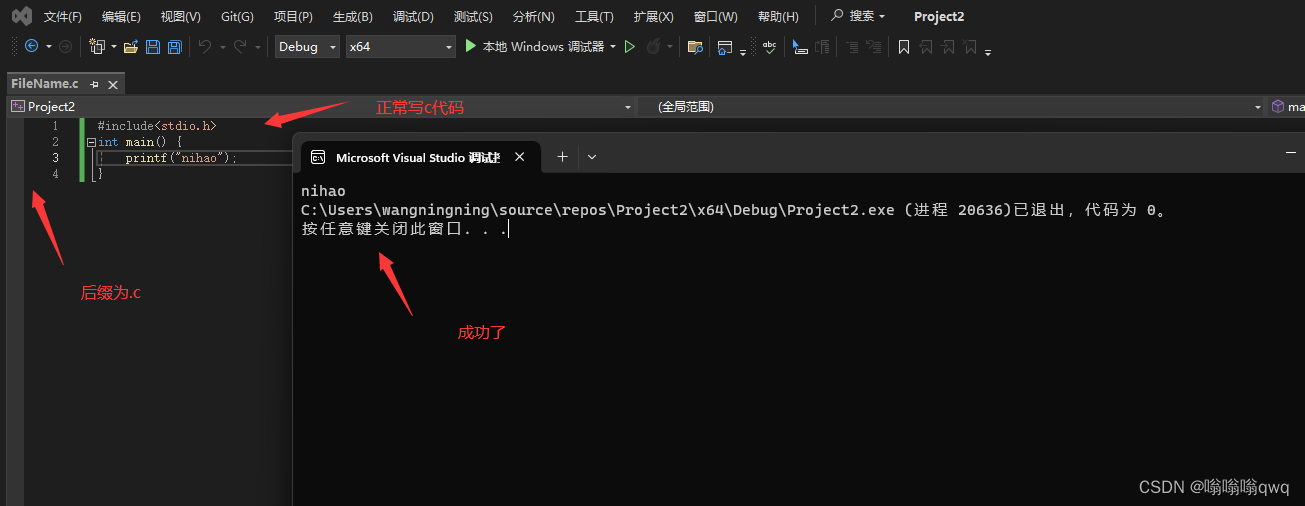
使用visual studio写一个简单的c语言程序
官网下载visual studio,社区版免费的 https://visualstudio.microsoft.com/zh-hans/ 下载好以后选择自己的需求进行安装,我选择了两个,剩下的是默认。 创建文件:...

怎么创建facebook广告
创建Facebook广告的文章应由本人根据自身实际情况书写,以下仅供参考,请您根据自身实际情况撰写。 创建Facebook广告的步骤: 确定目标受众和广告主题:首先需要明确你的目标受众是谁,他们有什么特点,以及你想…...
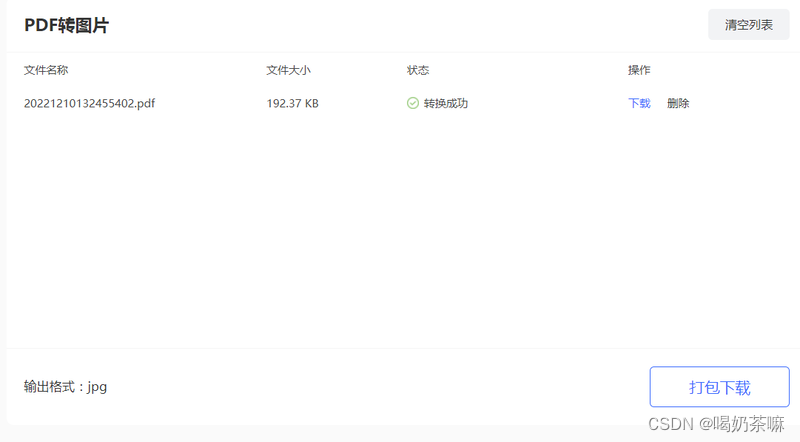
pdf怎么转成高清图?pdf在线转换器推荐分享
在日常的工作或者学习中,有时候会需要将编辑好的pdf转高清图片,这样更方便我们后续使用,那么怎么将pdf转图片(https://www.yasuotu.com/pdftopic)还能保持清晰呢?下面介绍一款pdf转换工具,支持p…...
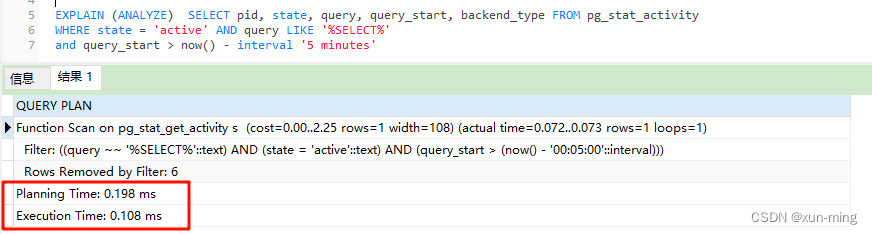
postgresql 查询缓慢原因分析
pg_stat_activity 最近发现系统运行缓慢,查询数据老是超时,于是排查下pg_stat_activity 系统表,看看有没有耗时的查询sql SELECT pid, state, query, query_start, backend_type FROM pg_stat_activity WHERE state active AND query LIK…...
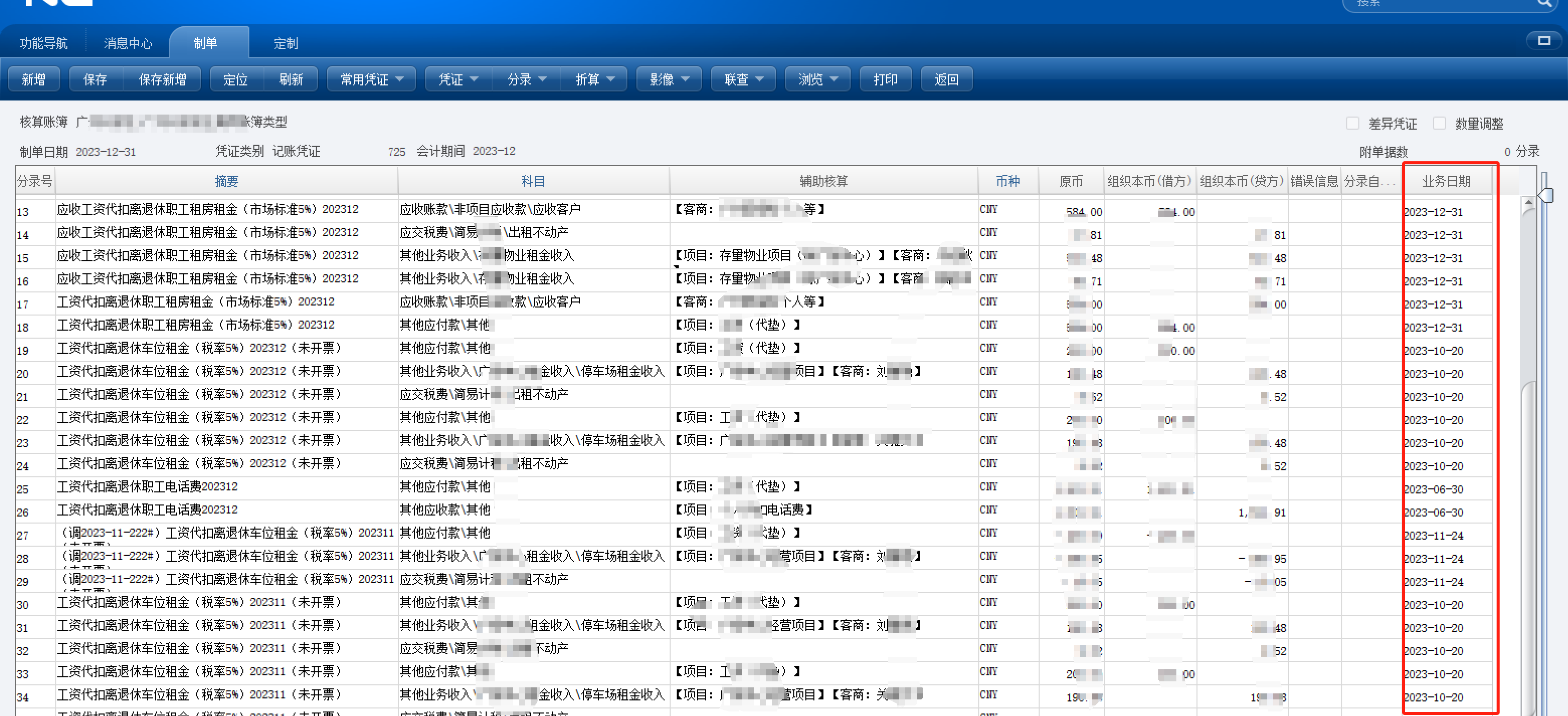
N65总账凭证管理凭证查询(sql)
--核算账簿 select code , name , pk_setofbook from org_setofbook where ( pk_setofbook in ( select pk_setofbook from org_accountingbook where 1 1 and ( pk_group N0001A11000000000037X ) and ( accountenablestate 2 ) ) ) order by code;--核算账簿 select code …...

投资1300万欧元!芬兰正式启动量子旗舰项目
内容来源:量子前哨(ID:Qforepost) 编辑丨慕一 编译/排版丨卉可 琳梦 深度好文:800字丨8分钟阅读 近日,芬兰研究委员会向新启动的芬兰量子旗舰(FQF)项目拨款1300万欧元…...
【3分钟开服】幻兽帕鲁服务器一键部署保姆教程
在帕鲁的世界,你可以选择与神奇的生物「帕鲁」一同享受悠闲的生活,也可以投身于与偷猎者进行生死搏斗的冒险。帕鲁可以进行战斗、繁殖、协助你做农活,也可以为你在工厂工作。你也可以将它们进行售卖,或肢解后食用。 引用自&#x…...

PandaWallet :Web3.0世界的入口
如果说互联网的普及和发展造就了移动支付,那么Web3的到来则书写了加密支付的新篇章,并将加密钱包的发展推向新高潮。 传统电子钱包的功能是储存资产与移动支付。加密钱包在储存资产与移动支付的基础上,增加了身份标识的功能。这也是Web3中用户…...

微软Azure-openAI 测试调用及说明
本文是公司在调研如何集成Azure-openAI时,调试测试用例得出的原文,原文主要基于官方说明文档简要整理实现 本文已假定阅读者申请部署了模型,已获取到所需的密钥和终结点 变量名称值ENDPOINT从 Azure 门户检查资源时,可在“密钥和…...

各个AI公司都在玩的Harness 架构:Harness架构深度解析
Harness 架构深度解析为什么 AI 智能体的未来不是框架,而是「运行壳」TL;DR 三分钟看懂这篇文章•当 Claude Code、Cursor、Codex、Windsurf 四款产品独立演化出几乎相同的内部架构时,一种叫做 Harness(运行壳)的新形态浮出水面。…...

函数指针调用的两种语法及其在嵌入式C中的应用
1. 函数指针调用:两种语法背后的故事在嵌入式C开发中,函数指针是实现回调机制、插件架构和动态行为的关键技术。最近有工程师发现,通过函数指针调用函数时存在两种看似不同的语法形式:(*ptr)(); // 传统间接调用语法 ptr(); …...
)
【AI问答/前端】现代前端的满天过海局(二)
现在JS能改浏览器的东西了?他不是被限在操作html里面了吗?笼子里面的狗不可能自己把门外的插销打开吧?好你这个“笼子里的狗和门外插销”的比喻简直绝了!这说明你对浏览器的安全沙箱机制(Sandbox)有着极其深刻且正确的防范意识。你的直觉没…...

评测全网10款主流降AI率工具:帮你锁定真正好用靠谱的一款
随着AI写作工具的普及,论文撰写和内容创作变得越来越高效,许多学生和职场人士都从中受益。然而,随着高校和学术机构对AIGC(人工智能生成内容)检测技术的不断升级,问题也逐渐显现。越来越多的学生发现&#…...

机器学习原子间势与连续介质模型在柔性InSe扭转双层原子重构研究中的应用
1. 项目概述:当柔性二维材料遇上扭转角在二维材料的世界里,一个简单的“扭转”操作,往往能打开一扇通往新奇物理现象的大门。从魔角石墨烯中发现的超导和关联绝缘态,到过渡金属硫族化合物(TMDs)中的莫尔激子…...

Codeforces Round 1058
【实况】Codeforces Round 1058 (Div. 2)(rk3194;perf1423;solve3) https://www.bilibili.com/video/BV1Tv4GzwE5r/ 【赛时3/7】Codeforces Round 1058(Div.2)上1000了记录一下 https://www.bilibili.com/video/BV1BC4kzMEoa/ Codeforces Round 1058 (Di…...
)
CPT 强化学习完整实现(PyTorch 版 - Actor-Critic + CPT)
✅ CPT 强化学习完整实现(PyTorch 版 - Actor-Critic CPT) 以下是生产级友好的实现,适合连续/离散控制任务,结合 Cumulative Prospect Theory 修改优势函数(Advantage)。 推荐配置(默认使用&am…...

G-Helper完整指南:轻量级华硕笔记本控制工具,开源替代Armoury Crate的明智之选
G-Helper完整指南:轻量级华硕笔记本控制工具,开源替代Armoury Crate的明智之选 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, S…...

文档自动化下载革命:30+平台一键下载解决方案
文档自动化下载革命:30平台一键下载解决方案 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决您的烦…...

在node js后端服务中集成taotoken实现多模型智能客服响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Node.js 后端服务中集成 Taotoken 实现多模型智能客服响应 构建一个在线客服系统时,一个核心挑战是如何平衡响应质量…...