【极数系列】Flink集成DataSource读取集合数据(07)
文章目录
- 01 引言
- 02 简介概述
- 03 基于集合读取数据
- 3.1 集合创建数据流
- 3.2 迭代器创建数据流
- 3.3 给定对象创建数据流
- 3.4 迭代并行器创建数据流
- 3.5 基于时间间隔创建数据流
- 3.6 自定义数据流
- 04 源码实战demo
- 4.1 pom.xml依赖
- 4.2 创建集合数据流作业
- 4.3 运行结果日志
01 引言
源码地址,一键下载可用:https://gitee.com/shawsongyue/aurora.git
模块:aurora_flink
主类:FlinkListSourceJob(集合)
02 简介概述
1.Source 是Flink程序从中读取其输入数据的地方。你可以用 StreamExecutionEnvironment.addSource(sourceFunction) 将一个 source 关联到你的程序。2.Flink 自带了许多预先实现的 source functions,不过你仍然可以通过实现 SourceFunction 接口编写自定义的非并行 source。3.也可以通过实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 类编写自定义的并行 sources。
03 基于集合读取数据
3.1 集合创建数据流
fromCollection(Collection)函数
从 Java Java.util.Collection 创建数据流。集合中的所有元素必须属于同一类型
3.2 迭代器创建数据流
fromCollection(Iterator, Class)
从迭代器创建数据流。class 参数指定迭代器返回元素的数据类型。
3.3 给定对象创建数据流
fromElements(T ...)
从给定的对象序列中创建数据流。所有的对象必须属于同一类型。
3.4 迭代并行器创建数据流
注意!使用迭代器的时候对象必须是实现持久化的,否则报错,详情可以看我的另外一篇文章、
错误:org.apache.flink.api.common.InvalidProgramException: java.util.Arrays$ArrayItr@784c3487 is not serializable
fromParallelCollection(SplittableIterator, Class)
从迭代器并行创建数据流。class 参数指定迭代器返回元素的数据类型
3.5 基于时间间隔创建数据流
generateSequence
基于给定间隔内的数字序列并行生成数据流。
3.6 自定义数据流
addSource - 关联一个新的 source function。例如,你可以使用 addSource(new FlinkKafkaConsumer<>(...)) 来从 Apache Kafka 获取数据。更多详细信息见连接器。
04 源码实战demo
4.1 pom.xml依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.xsy</groupId><artifactId>aurora_flink</artifactId><version>1.0-SNAPSHOT</version><!--属性设置--><properties><!--java_JDK版本--><java.version>11</java.version><!--maven打包插件--><maven.plugin.version>3.8.1</maven.plugin.version><!--编译编码UTF-8--><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!--输出报告编码UTF-8--><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><!--json数据格式处理工具--><fastjson.version>1.2.75</fastjson.version><!--log4j版本--><log4j.version>2.17.1</log4j.version><!--flink版本--><flink.version>1.18.0</flink.version><!--scala版本--><scala.binary.version>2.11</scala.binary.version><!--log4j依赖--><log4j.version>2.17.1</log4j.version></properties><!--通用依赖--><dependencies><!-- json --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><!--================================集成外部依赖==========================================--><!--集成日志框架 start--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version></dependency><!--集成日志框架 end--></dependencies><!--编译打包--><build><finalName>${project.name}</finalName><!--资源文件打包--><resources><resource><directory>src/main/resources</directory></resource><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes></resource></resources><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>org.apache.flink:force-shading</exclude><exclude>org.google.code.flindbugs:jar305</exclude><exclude>org.slf4j:*</exclude><excluder>org.apache.logging.log4j:*</excluder></excludes></artifactSet><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>org.xsy.sevenhee.flink.TestStreamJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><!--插件统一管理--><pluginManagement><plugins><!--maven打包插件--><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring.boot.version}</version><configuration><fork>true</fork><finalName>${project.build.finalName}</finalName></configuration><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin><!--编译打包插件--><plugin><artifactId>maven-compiler-plugin</artifactId><version>${maven.plugin.version}</version><configuration><source>${java.version}</source><target>${java.version}</target><encoding>UTF-8</encoding><compilerArgs><arg>-parameters</arg></compilerArgs></configuration></plugin></plugins></pluginManagement></build><!--配置Maven项目中需要使用的远程仓库--><repositories><repository><id>aliyun-repos</id><url>https://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><enabled>false</enabled></snapshots></repository></repositories><!--用来配置maven插件的远程仓库--><pluginRepositories><pluginRepository><id>aliyun-plugin</id><url>https://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><enabled>false</enabled></snapshots></pluginRepository></pluginRepositories></project>
4.2 创建集合数据流作业
注意:Flink根据集群撇嘴可能会启动多个并行度运行,可能导致数据重复处理,可以通过.setParallelism(1)设置为一个平行度运行即可
package com.aurora.source;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.NumberSequenceIterator;
import org.apache.flink.util.SplittableIterator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import javax.sql.DataSource;
import java.util.*;/*** @description flink的list集合source应用* @author 浅夏的猫* @datetime 23:03 2024/1/28
*/
public class FlinkListSourceJob {private static final Logger logger = LoggerFactory.getLogger(FlinkListSourceJob.class);public static void main(String[] args) throws Exception {//1.创建Flink运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2.设置Flink运行模式://STREAMING-流模式,BATCH-批模式,AUTOMATIC-自动模式(根据数据源的边界性来决定使用哪种模式)env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);List<String> list = Arrays.asList("测试", "开发", "运维");// 01 从集合创建数据流DataStreamSource<String> dataStreamSource_01 = env.fromCollection(list);// 02 从迭代器创建数据流,这里直接使用list的迭代器会报错,因为没有ArrayList没有进行持久化,需要深入了解的,可以看我的另外一篇文章
// DataStreamSource<String> dataStreamSource_02 = env.fromCollection(list.iterator(),String.class);// 03 从给定的对象序列中创建数据流DataStreamSource<String> dataStreamSource_03 = env.fromElements("测试", "开发", "运维");// 04 从迭代器并行创建数据流NumberSequenceIterator splittableIterator = new NumberSequenceIterator(1,10);DataStreamSource dataStreamSource_04=env.fromParallelCollection(splittableIterator,Long.TYPE);// 05 基于给定间隔内的数字序列并行生成数据流DataStreamSource<Long> dataStreamSource_05 = env.generateSequence(1, 10);//自定义数据流DataStreamSource<String> dataStreamSource_06 = env.addSource(new SourceFunction<String>() {@Overridepublic void run(SourceContext<String> sourceContext) throws Exception {//自定义你自己的数据来源for (int i = 0; i < 10; i++) {sourceContext.collect("测试数据" + i);}}@Overridepublic void cancel() {}});//5.输出打印dataStreamSource_01.print();
// dataStreamSource_02.print();dataStreamSource_03.print();dataStreamSource_04.print();dataStreamSource_05.print();dataStreamSource_06.print();//6.启动运行env.execute();}}4.3 运行结果日志

相关文章:
【极数系列】Flink集成DataSource读取集合数据(07)
文章目录 01 引言02 简介概述03 基于集合读取数据3.1 集合创建数据流3.2 迭代器创建数据流3.3 给定对象创建数据流3.4 迭代并行器创建数据流3.5 基于时间间隔创建数据流3.6 自定义数据流 04 源码实战demo4.1 pom.xml依赖4.2 创建集合数据流作业4.3 运行结果日志 01 引言 源码地…...

React hooks子组件暴露方法示例
说明 通常情况下,React 子组件使用父组件的方法或值通过props传递,反过来,父组件如果需要子组件的方法就需要子组件将自己的方法暴露出去。以下是一个实例: User.tsx import React, { FC, useEffect, useState, useRef } from …...

数据结构:大顶堆、小顶堆
堆是其中一种非常重要且实用的数据结构。堆可以用于实现优先队列,进行堆排序,以及解决各种与查找和排序相关的问题。本文将深入探讨两种常见的堆结构:大顶堆和小顶堆,并通过 C 语言展示如何实现和使用它们。 一、定义 堆是一种完…...

电加热热水器上架亚马逊美国站需要的UL174报告
电加热热水器上架亚马逊美国站需要的UL174报告 家用热水器出口美国需要办理UL174测试报告。 热水器就是指通过各种物理原理,在一定时间内使冷水温度升高变成热水的一种装置。分为制造冷气部分和制造热水部分。其实这两个部分又是紧密地联系在一起,密不可…...
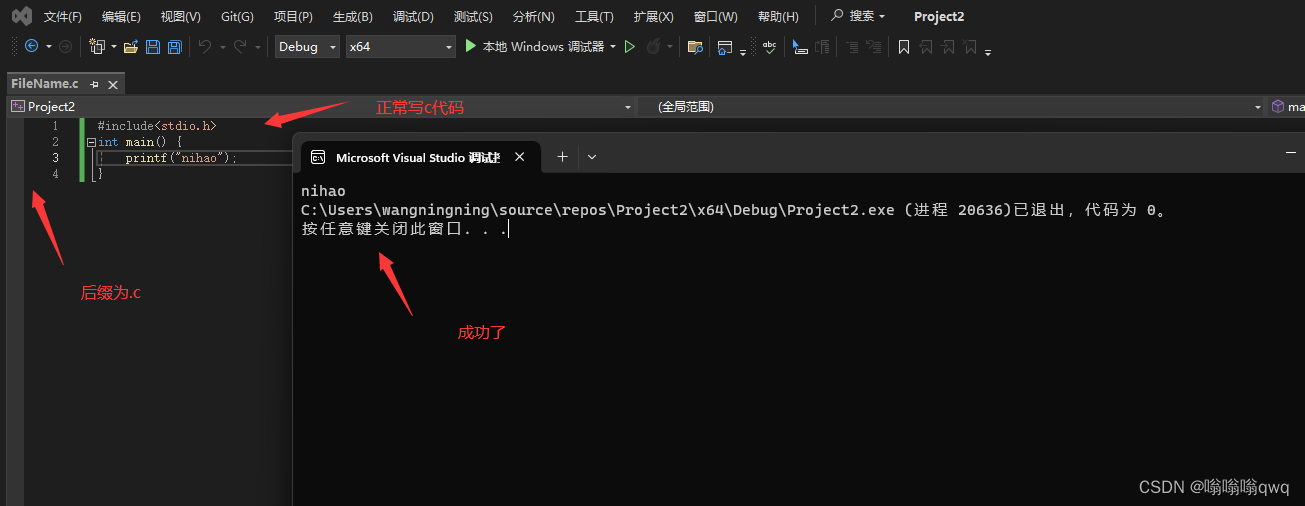
使用visual studio写一个简单的c语言程序
官网下载visual studio,社区版免费的 https://visualstudio.microsoft.com/zh-hans/ 下载好以后选择自己的需求进行安装,我选择了两个,剩下的是默认。 创建文件:...

怎么创建facebook广告
创建Facebook广告的文章应由本人根据自身实际情况书写,以下仅供参考,请您根据自身实际情况撰写。 创建Facebook广告的步骤: 确定目标受众和广告主题:首先需要明确你的目标受众是谁,他们有什么特点,以及你想…...
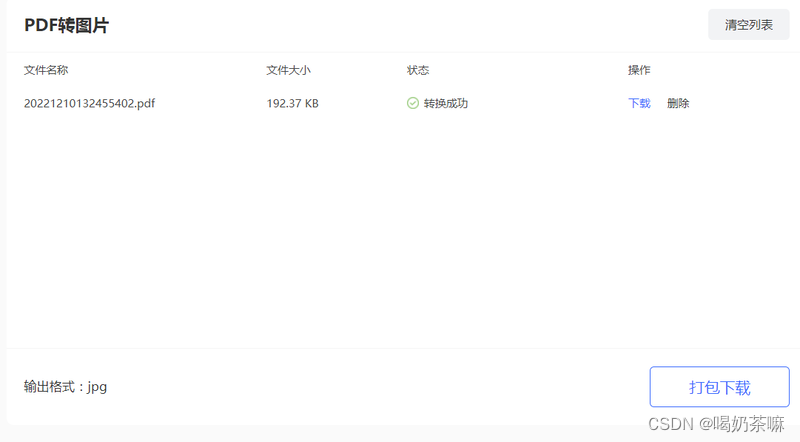
pdf怎么转成高清图?pdf在线转换器推荐分享
在日常的工作或者学习中,有时候会需要将编辑好的pdf转高清图片,这样更方便我们后续使用,那么怎么将pdf转图片(https://www.yasuotu.com/pdftopic)还能保持清晰呢?下面介绍一款pdf转换工具,支持p…...
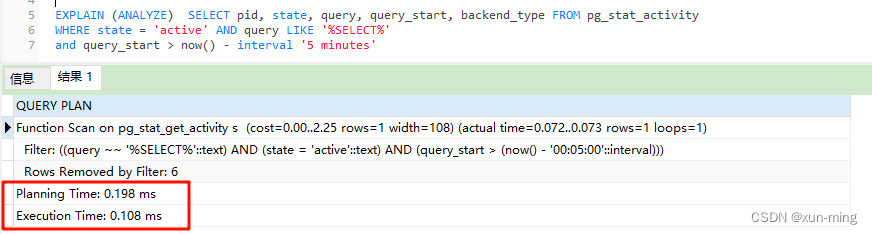
postgresql 查询缓慢原因分析
pg_stat_activity 最近发现系统运行缓慢,查询数据老是超时,于是排查下pg_stat_activity 系统表,看看有没有耗时的查询sql SELECT pid, state, query, query_start, backend_type FROM pg_stat_activity WHERE state active AND query LIK…...
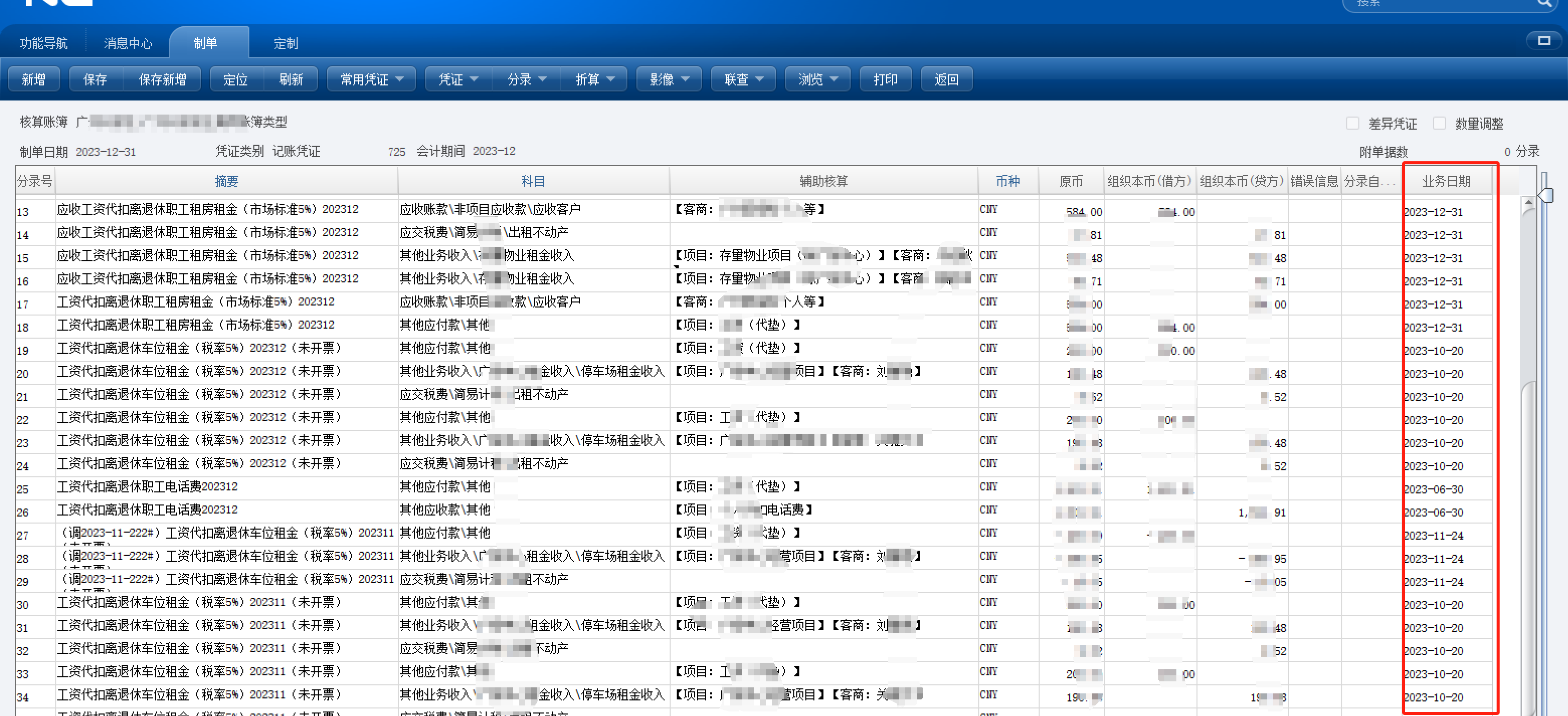
N65总账凭证管理凭证查询(sql)
--核算账簿 select code , name , pk_setofbook from org_setofbook where ( pk_setofbook in ( select pk_setofbook from org_accountingbook where 1 1 and ( pk_group N0001A11000000000037X ) and ( accountenablestate 2 ) ) ) order by code;--核算账簿 select code …...

投资1300万欧元!芬兰正式启动量子旗舰项目
内容来源:量子前哨(ID:Qforepost) 编辑丨慕一 编译/排版丨卉可 琳梦 深度好文:800字丨8分钟阅读 近日,芬兰研究委员会向新启动的芬兰量子旗舰(FQF)项目拨款1300万欧元…...
【3分钟开服】幻兽帕鲁服务器一键部署保姆教程
在帕鲁的世界,你可以选择与神奇的生物「帕鲁」一同享受悠闲的生活,也可以投身于与偷猎者进行生死搏斗的冒险。帕鲁可以进行战斗、繁殖、协助你做农活,也可以为你在工厂工作。你也可以将它们进行售卖,或肢解后食用。 引用自&#x…...

PandaWallet :Web3.0世界的入口
如果说互联网的普及和发展造就了移动支付,那么Web3的到来则书写了加密支付的新篇章,并将加密钱包的发展推向新高潮。 传统电子钱包的功能是储存资产与移动支付。加密钱包在储存资产与移动支付的基础上,增加了身份标识的功能。这也是Web3中用户…...

微软Azure-openAI 测试调用及说明
本文是公司在调研如何集成Azure-openAI时,调试测试用例得出的原文,原文主要基于官方说明文档简要整理实现 本文已假定阅读者申请部署了模型,已获取到所需的密钥和终结点 变量名称值ENDPOINT从 Azure 门户检查资源时,可在“密钥和…...
java 图书管理系统 spring boot项目
java 图书管理系统ssm框架 spring boot项目 功能有管理员模块:图书管理,读者管理,借阅管理,登录,修改密码 读者端:可查看图书信息,借阅记录,登录,修改密码 技术&#…...
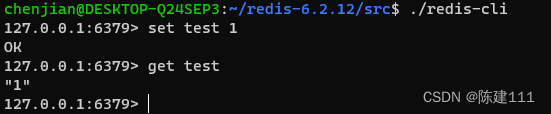
Ubuntu系统安装 Redis
环境准备 Ubuntu 系统版本:22.04.3Redis 版本:6.2.12 检查本地 make 环境 make -version若没有安装,则需要安装 sudo apt install make检查本地 gcc 环境 gcc -version若没有安装,则需要安装 sudo apt install gcc。 sudo a…...
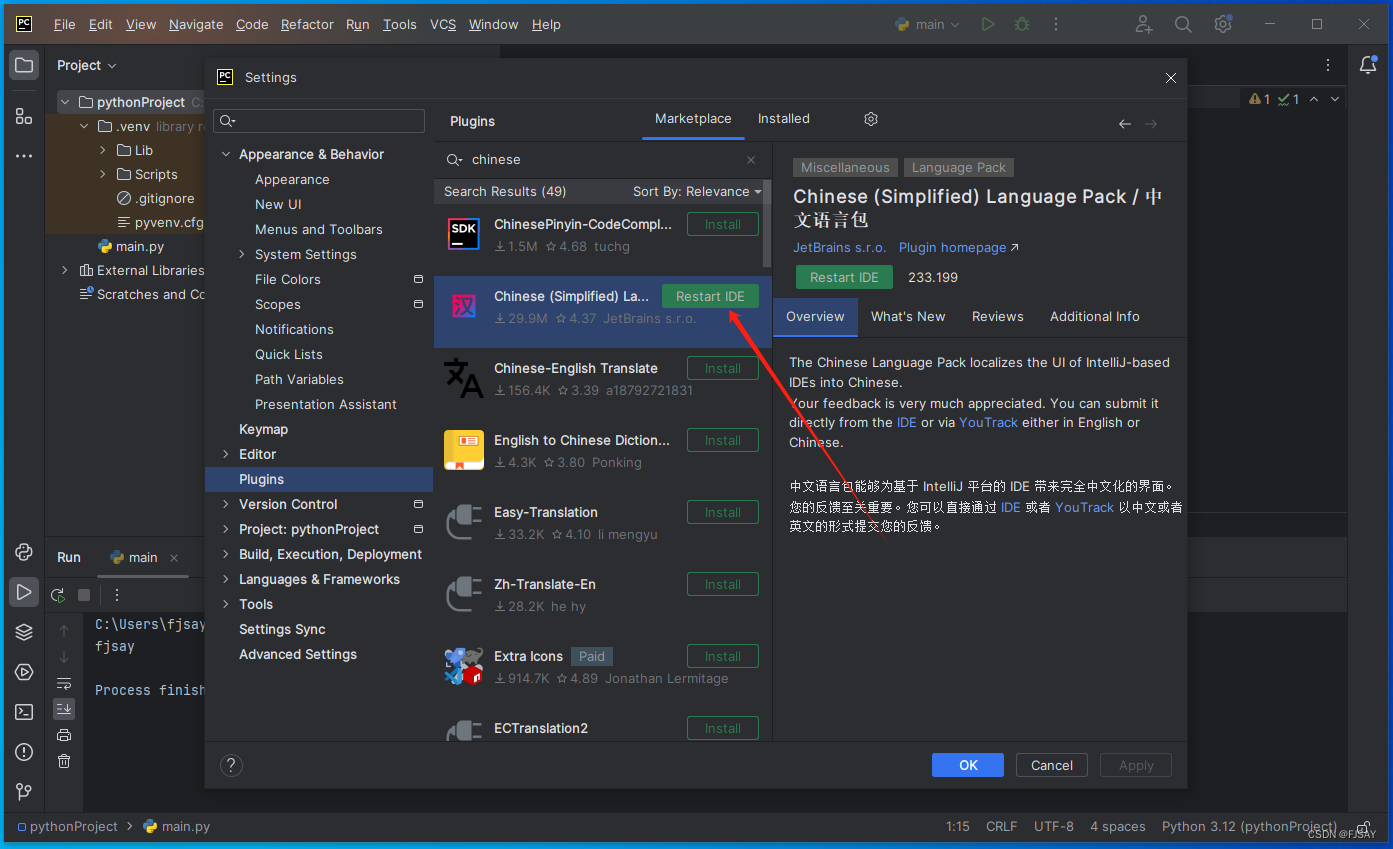
简单记录一下如何安装python以及pycharm(图文教程)(可供福建专升本理工类同学使用)
本教程主要给不懂计算机的或者刚刚开始学习python的同学(福建专升本理工类)&网友学习使用,基础操作,比较详细,其他问题等待补充! 安装Python 1.进入python官网(https://www.python.org/&a…...

浏览器内存泄漏排查指南
1、setTimeout执行原理 使用setInterval/setTimeOut遇到的坑 - 掘金 2、Chrome自带的Performance工具 当我们怀疑页面发生了内存泄漏的时候,可以先用Performance录制一段时间内页面的内存变化。 点击开始录制执行可能引起内存泄漏的操作点击停止录制 如果录制结束…...
ClickHouse集成HDFS表引擎详细解析)
ClickHouse(22)ClickHouse集成HDFS表引擎详细解析
文章目录 HDFS用法实施细节配置可选配置选项及其默认值的列表libhdfs3 支持的ClickHouse 额外的配置限制 Kerberos 支持虚拟列 资料分享系列文章clickhouse系列文章知乎系列文章 HDFS 这个引擎提供了与Apache Hadoop生态系统的集成,允许通过ClickHouse管理HDFS上的…...
idea报错 :(java: 找不到符号)
java: 找不到符号 符号: 变量 adminService 位置: 类 com.example.controller.WebController 查到网上一个办法:因为项目是maven:先点clean在点package...

设计软件最重要的目标是可理解性?
当您设计一款软件时,设计时最重要的一点就是可理解性。安全性、性能和正确性都很重要,但它们次优于可理解性。 被误解的软件会产生Bug缺陷 如果软件的实施者和维护者对软件存在误解,那么软件最终就会出现缺陷。主要缺陷。这些缺陷有多种形式…...
(回溯的使用))
今日算法(组合问题III)(回溯的使用)
题目描述找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:只使用数字 1 到 9每个数字 最多使用一次返回所有可能的有效组合的列表,列表不能包含相同的组合两次,组合可以以任何顺序返回核心思路:带双重剪枝的回溯…...

通过curl命令快速测试Taotoken的API连通性与返回
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken的API连通性与返回 在集成大模型服务时,直接使用curl命令进行API测试是一种高效且通用的…...

5分钟搞定Sunshine游戏串流:从安装到畅玩的完整指南
5分钟搞定Sunshine游戏串流:从安装到畅玩的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否想过在卧室的平板上玩书房里的3A大作?或者用手机…...

微信M4A文件打不开怎么办?m4a转MP3只需一招,小白也能操作
很多人会遇到这种情况:别人通过微信发来一段录音、会议音频、课程音频或者采访素材,文件后缀是.m4a,在微信里可能能播放,但保存到手机本地、发到电脑、导入剪辑软件或者复制到U盘后,就可能出现打不开、无法识别、格式不…...

摆脱论文困扰!盘点2026年断层领先的的降AI率平台
轻松降低论文AI率在2026年已不再是天方夜谭。最新推出的2026年降AI率平台,实测提速效果惊人,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,真正实现高效降AI率,助你轻松应对论文挑战。 一、全流程王者&…...

如何在3分钟内将视频压缩90%?免费开源神器CompressO完全指南
如何在3分钟内将视频压缩90%?免费开源神器CompressO完全指南 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/co/compr…...

MASA模组全家桶中文资源包:为中文玩家打造的无缝本地化体验终极指南
MASA模组全家桶中文资源包:为中文玩家打造的无缝本地化体验终极指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 你是否曾经在Minecraft中面对MASA模组复杂的英文界面感到…...

学术写作新纪元!2026一站式AI论文写作工具推荐指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

深度解析Reloaded-II架构:高级模组依赖管理与循环依赖解决方案
深度解析Reloaded-II架构:高级模组依赖管理与循环依赖解决方案 【免费下载链接】Reloaded-II Universal .NET Core Powered Modding Framework for any Native Game X86, X64. 项目地址: https://gitcode.com/gh_mirrors/re/Reloaded-II Reloaded-II作为一款…...

机器学习项目开发模式解析:从提交历史看规模、协作与演化规律
1. 项目概述:从代码提交中解码机器学习项目的真实工作流在机器学习项目的日常开发中,我们每天都在与Git打交道,提交代码、更新模型、调整参数。但你是否想过,这些看似随意的提交背后,是否隐藏着某种规律?一…...