python爬虫爬取网站
流程:
1.指定url(获取网页的内容)
爬虫会向指定的URL发送HTTP请求,获取网页的HTML代码,然后解析HTML代码,提取出需要的信息,如文本、图片、链接等。爬虫请求URL的过程中,还可以设置请求头、请求参数、请求方法等,以便获取更精确的数据。通过爬虫请求URL,可以快速、自动地获取大量的数据,为后续的数据分析和处理提供基础。
2.发起请求(request)(向目标网站发送请求,获取网站上的数据)
通过发送请求,爬虫可以模拟浏览器的行为,访问网站上的各种资源,例如网页、图片、视频、音频等等。爬虫可以通过请求获取网站上的数据,然后对数据进行解析和处理,从而实现数据的抓取和提取。请求可以包含各种参数,例如请求的URL、请求的方法、请求的头部信息、请求的数据等等,这些参数可以根据需要进行设置,以便获取目标数据。
3.获取响应数据(页面源码)
4.存储数据
一、导入相关库(requests库)
安装:
pip install requests
导入:(requests:python的网络请求模块)
import requests返回值:
response.status_code : 状态码
response.url: 请求url
response.headers: 头部信息
response.cookies: cookie信息
response.text: 字符串形式网页源码
response.content: 字节流形式网页源码
二、相关的参数(url,headers)
带参数的请求:
- 百度搜索设置了反爬机制,如果判断请求方是爬虫而不是浏览器,则不返回结果
- 百度如何判断是爬虫还是浏览器在请求?
通过User-Agent(请求者身份标识)
获取:进入想要爬取的网站中点击F12
点击network,按下Ctr+r或者F5刷新,拉到页面的最上方叫research的文件,打开headers,
这里我们只需要到两个简单的参数,本次案例只是做一个简单的爬虫教程,其他参数暂时不考虑
| 参数 | 作用 |
| Request URL | 发送请求的网站地址,也就是图片所在的网址 |
| user-agent | 用来模拟浏览器对网站进行访问,避免被网站监测出非法访问 |


做参数代码的准备
url = "https://pic.netbian.com/uploads/allimg/210317/001935-16159115757f04.jpg"
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
三、向网站发出请求
response = requests.get(url=url,headers=headers)
print(response.text) # 打印请求成功的网页源码,和在网页右键查看源代码的内容一样的出现的网络源码可能会乱码
解决乱码:
- 修改response的encoding为utf-8,然后再进行写入
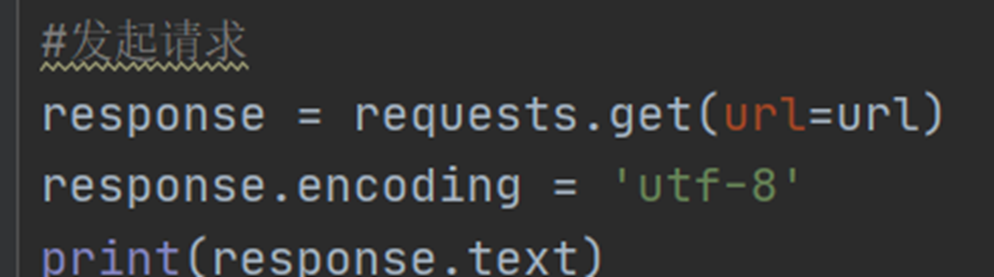

- 通过发送请求成功response,通过(apparent_encoding)获取该网页的编码格式,并对response解码
response.encoding=response.apparent_encoding
区别:
- 第一行代码 `response.encoding=response.apparent_encoding` 是使用 `response` 对象的 `apparent_encoding` 属性来自动检测编码,并将编码设置为检测到的编码。`apparent_encoding` 属性是根据 HTTP 头部、HTML 的 meta 标签等信息来猜测编码的,但并不一定准确。
- 第二行代码 `response.encoding='utf-8'` 是手动将编码设置为 UTF-8。这种方式适用于已知响应的编码方式,或者在使用第一种方式检测编码失败时手动指定编码。
- 第一种方式更加智能,但可能不够准确;第二种方式更加精确,但需要手动指定编码。
四、匹配(re库,正则表达式)
正则表达式:简单点说就是由用户制定一个规则,然后代码根据我们指定的所规则去指定内容里匹配出正确的内容
通过正则表达式把一个个图片的链接和名字给匹配出来,存放到一个列表中
import re
"""
. 表示除空格外任意字符(除\n外)
* 表示匹配字符零次或多次
? 表示匹配字符零次或一次
.*? 非贪婪匹配
"""
# src后面存放的是链接,alt后面是图片的名字
# 直接(.*?)也是可以可以直接获取到链接,但是会匹配到其他不是我们想要的图片
# 我们可以在前面图片信息看到链接都是/u····开头的,所以我们就设定限定条件(/u.*?)
#这样就能匹配到我们想要的
parr = re.compile('src="(/u.*?)".alt="(.*?)"')
image = re.findall(parr,response.text)
for content in image:print(content)解析html文件:
•导入lxml模块中的html功能
•使用html.fromstring函数将网页文本解析成html内容
这里举爬取豆瓣电影排行榜并解析其电影图片和电影名的例子来更好地学习爬虫的相关步骤
网址:https://movie.douban.com/chart

要解析html文件,先安装lxml模块
命令:
pip install lxml- 导入lxml模块中的html功能
- 使用html.fromstring函数将网页文本解析成html内容
- esponse是爬虫获取的结果,也可以读本地存好的html文件
- 观察html文件,找到想收集的数据在什么样的标签里
- 例如要获取电影名字,通过观察,所有的电影名字都在<a class = "nbg">标签里



- 使用xpath函数定位到电影名字所在的标签(注意路径以//开头,指定class名称前要加@符号)
- 使用 /@属性名 获取标签内的某个属性值
- 注意:得到的结果必定是列表,即使只有一个元素

打印列表结果

然后用相同的方式,对电影的评分和图片进行爬取
#导入网络请求库
import requests,lxml,os
from lxml import html #用于解析html文件
url="https://movie.douban.com/chart"
headers={"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
}
response=requests.get(url=url,headers=headers)
response.encoding='utf-8'
content=html.fromstring(response.text) #将HTTP响应的文本内容转换为HTML文档对象,以便进行后续的HTML解析和处理
text=str(content)
f=open("douban.html",'w',encoding='utf-8') #打开html文件,以写入模式‘w’打开,指定编码格式为utf-8
f.write(response.text) #将爬取到的内容写入文件中
f.close()
import os
names=content.xpath('//a[@class="nbg"]/@title') #运用xpath函数解析html文件找到电影的名字存储到一个列表里面
print(names)
scores=content.xpath('//span[@class="rating_nums"]/text()')
print(scores)
pictures=content.xpath('//a[@class="nbg"]/img/@src') #这里存储的是图片的网址,并组成了一个列表
if not os.path.exists('pictures'): #创建一个文件夹os.mkdir('pictures')
for i in pictures: #便利每一张图片列表的元素resp=requests.get(url=i,headers=headers) #依次向每张图片发送get请求,获取响应信息name=i.split('/').pop() #以‘/’来分割,取图片网址的提取出最后一个斜杠后面的部分来作为名字with open('pictures/'+name,"wb")as f: #将图片名变为namef.write(resp.content) #将图片存入该目录
相关文章:
python爬虫爬取网站
流程: 1.指定url(获取网页的内容) 爬虫会向指定的URL发送HTTP请求,获取网页的HTML代码,然后解析HTML代码,提取出需要的信息,如文本、图片、链接等。爬虫请求URL的过程中,还可以设置请求头、请求参数、请求…...
c# Get方式调用WebAPI,WebService等接口
/// <summary> /// 利用WebRequest/WebResponse进行WebService调用的类 /// </summary> public class WebServiceHelper {//<webServices>// <protocols>// <add name"HttpGet"/>// <add name"HttpPost"/>// …...

银行数据仓库体系实践(11)--数据仓库开发管理系统及开发流程
数据仓库管理着整个银行或公司的数据,数据结构复杂,数据量庞大,任何一个数据字段的变化或错误都会引起数据错误,影响数据应用,同时业务的发展也带来系统不断升级,数据需求的不断增加,数据仓库需…...

微信小程序引导用户打开定位授权通用模版
在需要使用位置信息的页面(例如 onLoad 或 onShow 生命周期函数)中调用 wx.getSetting 方法检查用户是否已经授权地理位置权限: Page({onLoad: function() {wx.getSetting({success: res > {if (res.authSetting[scope.userLocation]) {/…...

JVM篇----第十篇
系列文章目录 文章目录 系列文章目录前言一、JAVA 强引用二、JAVA软引用三、JAVA弱引用四、JAVA虚引用五、分代收集算法前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧…...
DevSecOps 参考模型介绍
目录 一、参考模型概述 1.1 概述 二、参考模型分类 2.1 DevOps 组织型模型 2.1.1 DevOps 关键特性 2.1.1.1 模型特性图 2.1.1.2 特性讲解 2.1.1.2.1 自动化 2.1.1.2.2 多边协作 2.1.1.2.3 持续集成 2.1.1.2.4 配置管理 2.1.2 DevOps 生命周期 2.1.2.1 研发过程划分…...

什么是okhttp?
OkHttp简介: OkHttp 是一个开源的、高效的 HTTP 客户端库,由 Square 公司开发和维护。它为 Android 和 Java 应用程序提供了简单、强大、灵活的 HTTP 请求和响应的处理方式。OkHttp 的设计目标是使网络请求变得更加简单、快速、高效,并且支持…...
R语言基础学习-02 (此语言用途小众 用于数学 生物领域 基因分析)
变量 R 语言的有效的变量名称由字母,数字以及点号 . 或下划线 _ 组成。 变量名称以字母或点开头。 变量名是否正确原因var_name2.正确字符开头,并由字母、数字、下划线和点号组成var_name%错误% 是非法字符2var_name错误不能数字开头 .var_name, var.…...
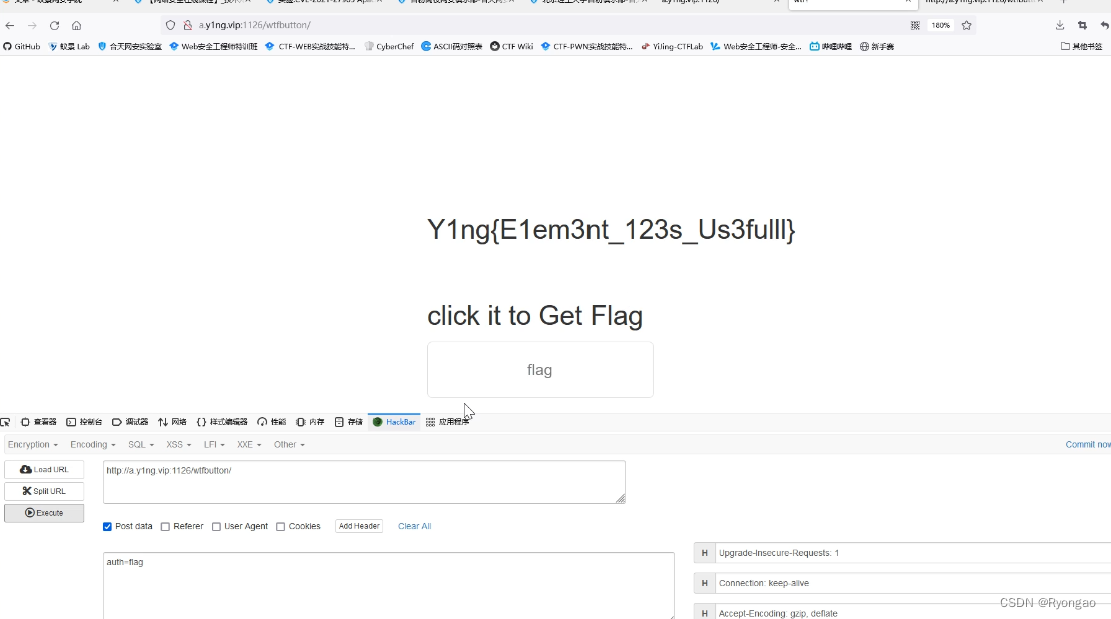
CTF-WEB的入门真题讲解
EzLogin 第一眼看到这个题目我想着用SQL注入 但是我们先看看具体的情况 我们随便输入admin和密码发现他提升密码不正确 我们查看源代码 发现有二个不一样的第一个是base64 意思I hava no sql 第二个可以看出来是16进制转化为weak通过发现是个弱口令 canyouaccess 如果…...
【C项目】顺序表
简介:本系列博客为C项目系列内容,通过代码来具体实现某个经典简单项目 适宜人群:已大体了解C语法同学 作者留言:本博客相关内容如需转载请注明出处,本人学疏才浅,难免存在些许错误,望留言指正 作…...
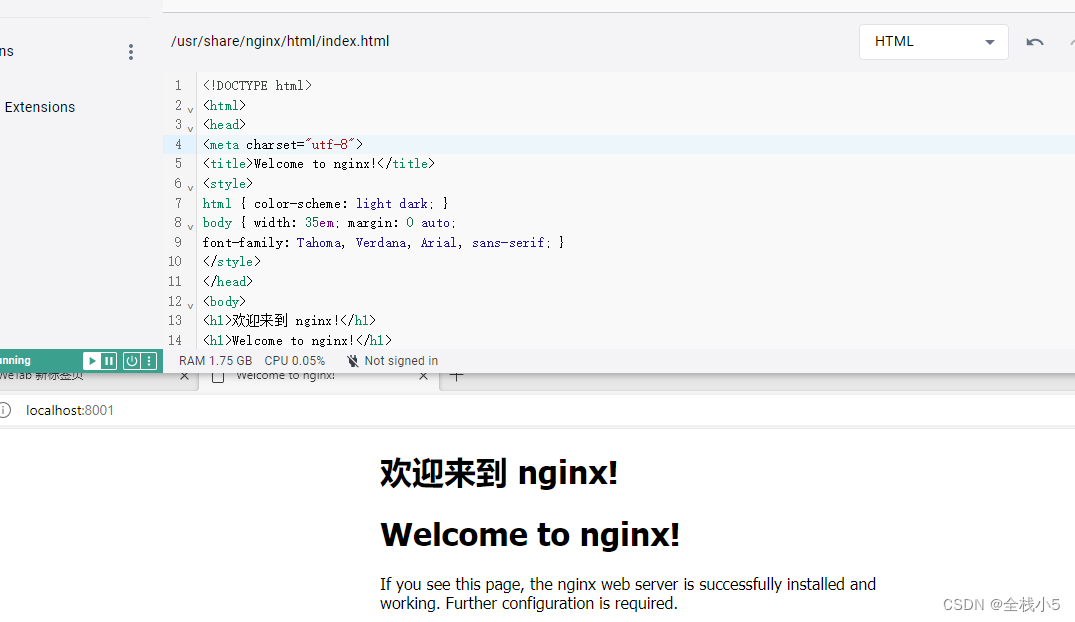
【Docker】在Windows下使用Docker Desktop创建nginx容器并访问默认网站
欢迎来到《小5讲堂》,大家好,我是全栈小5。 这是《Docker容器》序列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对…...

详讲api网关之kong的基本概念及安装和使用(二)
consul的服务注册与发现 如果不知道consul的使用,可以点击上方链接,这是我写的关于consul的一篇文档。 upstreamconsul实现负载均衡 我们知道,配置upstream可以实现负载均衡,而consul实现了服务注册与发现,那么接下来…...
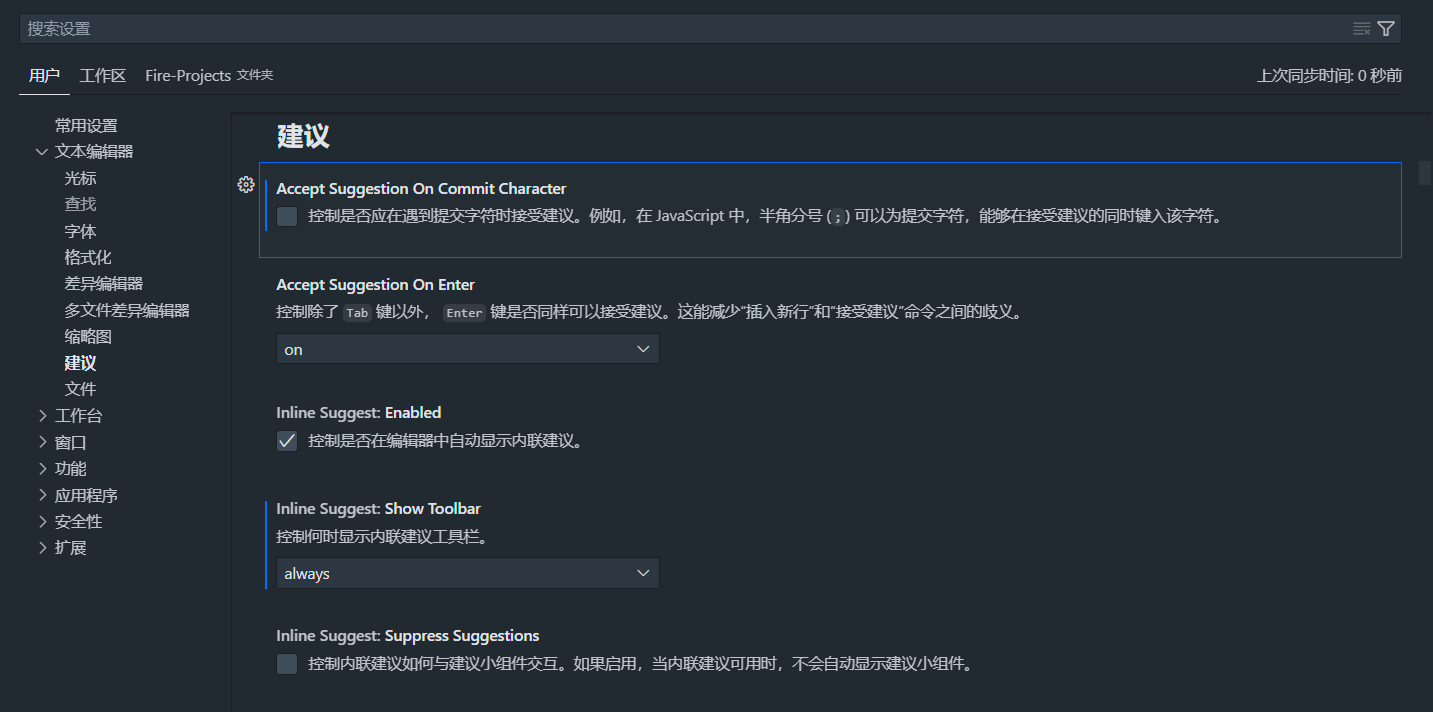
取消Vscode在输入符号时自动补全
取消Vscode在输入符号时自动补全 取消Vscode在输入符号时自动补全问题演示解决方法 取消Vscode在输入符号时自动补全 问题演示 在此状态下输入/会直接自动补全, 如下图 笔者想要达到的效果为可以正常输入/而不进行补全, 如下图 解决方法 在设置->文本编辑器->建议, 取消…...

ElementUI Form:Input 输入框
ElementUI安装与使用指南 Input 输入框 点击下载learnelementuispringboot项目源码 效果图 el-input.vue 页面效果图 项目里el-input.vue代码 <script> export default {name: el_input,data() {return {input: ,input1: ,input2: ,input3: ,input4: ,textarea: …...

Vue_Router_守卫
路由守卫:路由进行权限控制。 分为:全局守卫,独享守卫,组件内守卫。 全局守卫 //创建并暴露 路由器 const routernew Vrouter({mode:"hash"//"hash路径出现#但是兼容性强,history没有#兼容性差"…...

GDB调试技巧实战--自动化画出类关系图
1. 前言 上节我们在帖子《Modern C++利用工具快速理解std::tuple的实现原理》根据GDB的ptype命令快速的理解了std::tuple数据结构的实现,但是手动一个个打印,然后手动画出的UML图,这个过程明显可以自动化。 本文旨在写一个GDB python脚本把这个过程自动化。 本脚本也可以用…...

python使用Schedule
目录 一:使用场景: 二:参数 三:实例 "Schedule"在Python中通常指的是时间调度或任务计划。Python中有多个库可以用来处理时间调度和任务计划,其中最流行的是schedule库。 一&#x…...
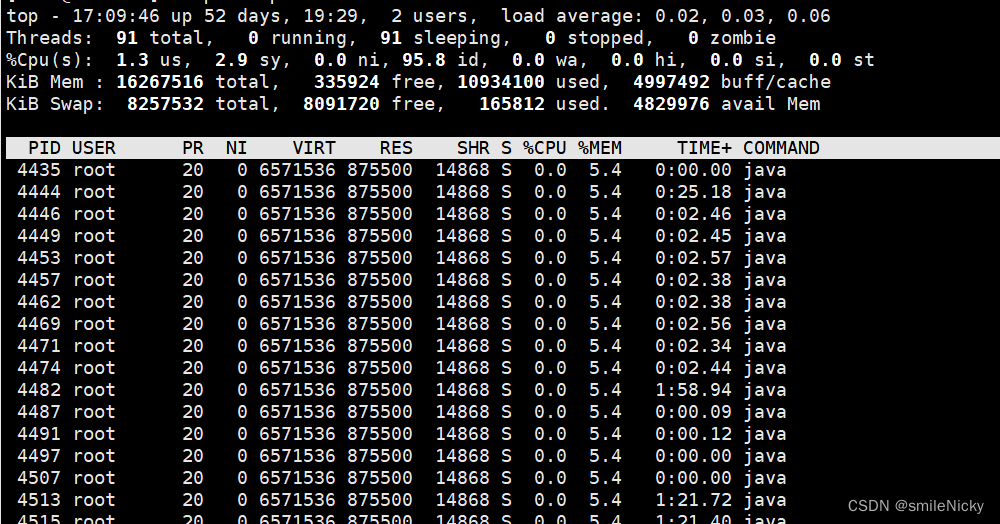
Linux系列之查看cpu、内存、磁盘使用情况
查看磁盘空间 df命令用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。使用df -h命令,加个-h参数是为了显示GB MB KB单位,这样更容易查看 Filesystem …...

【C语言】socket编程接收问题
一、recv()函数接收到的返回值为0表示对端已经关闭 在TCP套接字编程中,通过recv()函数接收到的返回值为0通常表示对端已经关闭了套接字的发送部分。这是因为TCP是一个基于连接的协议,其中有定义明确的连接建立和终止流程;当对端调用close()或…...
GDAL之合并shp和geojson要素图层)
Python与ArcGIS系列(二十)GDAL之合并shp和geojson要素图层
目录 0 简述1 代码实现2 结果展示0 简述 Shp格式是GIS中非常重要的数据格式,主要在Arcgis中使用,但在进行很多基于网页的空间数据可视化时,通常只接受GeoJSON格式的数据,众所周知JSON是利用键值对+嵌套来表示数据的一种格式,以其轻量、易解析的优点,被广泛使用与各种领域…...

【DeepSeek企业级成本治理框架】:从Token粒度计费到FinOps闭环,阿里云/字节/美团都在用的4层管控模型
更多请点击: https://intelliparadigm.com 第一章:DeepSeek成本控制策略的演进逻辑与行业共识 DeepSeek作为聚焦大模型高效训练与推理的开源技术团队,其成本控制策略并非孤立的技术优化路径,而是深度耦合算力供给结构、模型架构演…...

显存直降68%、推理提速3.2倍,DeepSeek-V2量化部署方案全解析,仅限首批内测团队流出
更多请点击: https://codechina.net 第一章:DeepSeek-V2量化部署方案全景概览 DeepSeek-V2作为高性能开源大语言模型,在实际生产环境中面临显存占用高、推理延迟大等挑战。量化部署是实现低资源开销与高吞吐并存的关键路径,本章…...

Wonder3D:如何用一张照片在3分钟内创建专业3D模型?
Wonder3D:如何用一张照片在3分钟内创建专业3D模型? 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 你是否曾想过将一张普通的2D照片变成可…...

终极资源嗅探指南:猫抓浏览器扩展帮你轻松捕获网页媒体资源
终极资源嗅探指南:猫抓浏览器扩展帮你轻松捕获网页媒体资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在当今数字时代,…...

如何快速提升电脑性能:5个终极系统调优技巧指南
如何快速提升电脑性能:5个终极系统调优技巧指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 你是否遇到过这样的…...

WeChatExporter:告别数据焦虑,轻松备份你的微信聊天记忆
WeChatExporter:告别数据焦虑,轻松备份你的微信聊天记忆 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 在数字时代,微信聊天记录承载…...
)
从Python开发者视角,5分钟上手洛书编程语言(解释器1.7.0版)
从Python开发者视角,5分钟上手洛书编程语言(解释器1.7.0版)如果你已经熟悉Python,那么学习洛书编程语言会是一个有趣的体验。洛书作为一门支持中英文关键字的解释型语言,在设计哲学和语法细节上与Python有着诸多不同。…...

保姆级避坑指南:用Python处理泰坦尼克号数据时,90%新手都会犯的5个错误
保姆级避坑指南:用Python处理泰坦尼克号数据时,90%新手都会犯的5个错误泰坦尼克号数据集是Kaggle上最经典的机器学习入门项目之一,但看似简单的数据背后却暗藏无数新手陷阱。我曾辅导过数百名数据科学初学者,发现他们在处理这个数…...

B物理反常的全局拟合:有效场论与机器学习解析新物理信号
1. 项目概述:当B介子衰变“不听话”时,我们如何用数学语言寻找新物理?在粒子物理的精密前沿,标准模型(Standard Model, SM)一直是我们理解微观世界最成功的理论框架。然而,物理学家们从未停止过…...

C166链接器Error L101段冲突解决方案
1. 问题现象与背景解析当使用C166开发工具链进行项目链接时,开发者可能会遇到L166链接器报出的Error L101(Section Combination Error)。这个错误通常表现为链接过程中突然中断,并显示类似以下的错误信息:L166 LINKER …...