Python编程-使用urllib进行网络爬虫常用内容梳理
Python编程-使用urllib进行网络爬虫常用内容梳理
使用urllib库进行基础网络请求
使用request发起网络请求
from urllib import request
from http.client import HTTPResponseresponse: HTTPResponse = request.urlopen(url="http://pkc/vul/sqli/sqli_str.php")
print(response.getcode())
print(response.read().decode('utf-8'))
HTTPResponse常见的属性与方法
| 方法/属性 | 描述 |
|---|---|
read(size=-1) | 读取并返回指定大小的响应体。如果未指定大小,将读取整个响应体。 |
readline(limit=-1) | 读取并返回响应体中的一行。如果未指定大小,将读取整行,参数用于指定字符数。 |
readlines() | 读取并返回响应体中的所有行。 |
getheader(name, default=None) | 返回指定头部名称的头部值。如果未找到,返回默认值。 |
getheaders() | 返回一个包含所有响应头部的列表。 |
status | 响应的状态码。例如,200 表示成功,404 表示未找到,等等。 |
version | HTTP 版本。通常是 “HTTP/1.0” 或 “HTTP/1.1”。 |
reason | 对状态码的短语性描述。例如,对于状态码 200,原因可能是 “OK”。 |
msg | 完整的 HTTP 响应消息,包括状态行和头部。 |
headers | 一个类似字典的对象,包含响应头的键值对。 |
geturl() | 返回实际请求的 URL。如果请求是重定向的结果,则返回最终 URL。 |
info() | 返回一个包含有关响应的信息的类似字典的对象。 |
getcode() | 返回响应的状态码,例如 200 表示成功。 |
urlopen的参数使用
def urlopen(url: str | Request,data: _DataType = None,timeout: float | None = ...,*,cafile: str | None = None,capath: str | None = None,cadefault: bool = False,context: SSLContext | None = None
) -> _UrlopenRet
data参数用于接收一个字节流对象,一旦指定了参数data,将会使得本次请求自动转化为post
from urllib import request
from http.client import HTTPResponsebytes_data: bytes = bytes('Hello, World!', 'utf-8')
response: HTTPResponse = request.urlopen(url="https://httpbin.org/post", data=bytes_data)
print(response.read().decode('utf-8'))
bytes类型的构造有两个参数,一个是字符串,一个是编码方式(可选)
我们对于上述代码可以在
https://httpbin.org/网站进行验证,在开始post测试后,上述代码将会输出我们的请求中的信息,我们将在控制台看到以下内容(截取了部分,减小篇幅):{ "args": {}, "data": "", "files": {}, "form": {"Hello, World!": "" },... }
- timeout参数用于指定请求的响应时间,超时将会抛出
URLError异常(该异常定义在urllib.error中),我们通常以下列语句测试
from urllib import request, error
from socket import timeout
from http.client import HTTPResponsebytes_data: bytes = bytes('Hello, World!', 'utf-8')
try:response: HTTPResponse = request.urlopen(url="https://httpbin.org/post", data=bytes_data, timeout=0.1)
except error.URLError as e:if isinstance(e.reason, timeout):print("A connection timeout occurred while accessing the target website")
else:print("Access target state code is: ", response.status)其他参数均与ca证书相关可待使用时进行探讨,其中的
cadefault已经弃用
- context参数:它必须是
ss1.SSLContext类型,用来指定SSL 设置。- capath参数:用来指定ca证书的路径
- cafile参数:用来指定ca证书文件
使用Request对象发起网络请求
相较于直接使用urlopen,使用Request对象的场景要更加常见,它提供了更加灵活的网络请求方式,我们来看Request的构造方法:
Request.__init__(url: str, data: _DataType = None, headers: MutableMapping[str, str] = {}, origin_req_host: str | None = None, unverifiable: bool = False, method: str | None = None) -> None
- url:需要请求的网站,是构造的必选参数,其他选项是可选的
- data:需要字节流类型,需要进行转换
- headers:用于定义请求头的字典,既可以在构造时进行添加,也可以在后续以
add_header方法添加 - origin_req_host:发起网络请求方的host
- unverifiable:通常在访问一个网站时,由于证书等原因无法验证连接的安全性,当这个值为False时会中止请求,如果说我们想要跳过验证,强行访问就可以修改其为True
- method:接受一个字符串,作为请求的类型指定,需要注意的是,这个必须要大写,否则将会引发
HTTPError错误
from urllib.request import Request, urlopen
from urllib.error import URLError
from socket import timeout
from http.client import HTTPResponseurl: str = 'https://httpbin.org/post'
bytes_data: bytes = bytes("zhi yin ni tai mei", encoding='utf-8')
headers: dict[str, str] = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ''(KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' }
request_object: Request = Request(url=url, data=bytes_data, headers=headers, method='POST')
try:response: HTTPResponse | None = urlopen(request_object, timeout=4)
except URLError as e:response = Noneif isinstance(e.reason, timeout):print("A connection timeout occurred while accessing the target website")
else:print("Access target state code is: ", response.status)
finally:if response:print(response.read().decode('utf-8'))
使用add_hearder添加字段
url: str = 'https://httpbin.org/post'
bytes_data: bytes = bytes("zhi yin ni tai mei", encoding='utf-8')
request_object: Request = Request(url=url, data=bytes_data, method='POST')
request_object.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ''(KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36')
使用Handler类与OpenerDirector
Handler类是一系列继承自request中的BaseHandler类,它们用于支持各种网络请求中的高级操作,常用的有以下几个:
| 处理器 | 描述 |
|---|---|
HTTPDefaultErrorHandler | 用于处理 HTTP 请求中的响应错误,即 HTTPError 类型的异常。 |
HTTPRedirectHandler | 用于处理请求中的各种重定向问题。 |
HTTPCookieProcessor | 用于专门处理 Cookies 问题。 |
ProxyHandler | 用于设置网络代理的管理。 |
HTTPPasswordMgr | 用于管理密码与用户名的表,通常与 HTTPBasicAuthHandler 配合使用。 |
HTTPBasicAuthHandler | 用于管理连接打开时可能需要的基本认证操作。 |
HTTPPasswordMgrWithDefaultRealm | 用于管理密码与用户名的表,同时允许默认域的设置。 |
OpenerDirector 是 urllib.request 模块中的一个类,用于处理 URL 请求的打开器。OpenerDirector 类提供了一个通用的接口,使得你可以通过添加不同的处理器来处理不同类型的 URL 请求
| 方法和异常 | 描述 |
|---|---|
add_handler(handler) | 添加一个处理器到打开器中。处理器是一个对象,定义了如何处理特定类型的 URL 请求。常见处理器包括 HTTPHandler、HTTPSHandler、FTPHandler 等。 |
open(url, data=None, timeout=<default>, cafile=None, capath=None, cadefault=False, context=None) | 打开指定的 URL。根据 URL 的协议选择合适的处理器来处理请求。 |
open(req, data=None, timeout=<default>, cafile=None, capath=None, cadefault=False, context=None) | 通过传递 Request 对象来打开 URL。Request 对象可以包含更多的请求信息,如请求头、请求方法等。 |
error = URLError(reason, request, code, hdrs, fp) | 当发生 URL 相关的错误时,抛出 URLError 异常。包含错误原因 (reason)、请求对象 (request)、错误代码 (code)、响应头 (hdrs) 和文件指针 (fp)。 |
设置密码管理处理器
from urllib.request import HTTPPasswordMgrWithDefaultRealm
from urllib.request import HTTPBasicAuthHandler
from urllib.request import build_opener
from urllib.error import URLError
from http.client import HTTPResponsedefault_username: str = 'username'
default_password: str = 'password'
user_define_url = 'https://httpbin.org/get' passwd_handler = HTTPPasswordMgrWithDefaultRealm()
passwd_handler.add_password(None, user_define_url, default_username, default_password)
auth_handler = HTTPBasicAuthHandler(passwd_handler)
opener = build_opener(auth_handler)try:res: HTTPResponse = opener.open(user_define_url)html_document = res.read().decode('utf-8')print(html_document)
except URLError as e:print(e.reason)
urllib的error模块用于管理请求中的异常,其中的reason用于输出异常的原因
为爬虫设置代理处理器
from urllib.request import ProxyHandler, build_opener
from urllib.error import URLError
from http.client import HTTPResponsedefault_username: str = 'username'
default_password: str = 'password'
user_define_url = 'https://httpbin.org/get'default_proxy: dict[str, str] = {'http': 'http://127.0.0.1:8080','https': 'http://127.0.0.1:8080'}
proxy_handler = ProxyHandler(default_proxy)
opener = build_opener(proxy_handler)
try:res: HTTPResponse = opener.open(user_define_url)html_document = res.read().decode('utf-8')print(html_document)
except URLError as e:print(e.reason)为cookies处理设置处理器
cookie处理与保存
from http.cookiejar import CookieJar
from urllib.request import HTTPCookieProcessor, build_openeruser_define_url: str = 'https://www.baidu.com'
user_url_cookies: CookieJar = CookieJar()
cookies_handler = HTTPCookieProcessor(user_url_cookies)
opener = build_opener(cookies_handler)response = opener.open(user_define_url)
for cookie_item in user_url_cookies:print(cookie_item.name, " ", cookie_item.value)
上述代码将输出访问百度时自动分配的cookies,我们还可以将内容保存在文件中:
from http.cookiejar import MozillaCookieJar
from urllib.request import HTTPCookieProcessor, build_openerdefault_cookie_file: str = 'temp_cookies.txt'
user_define_url: str = 'https://www.baidu.com'user_url_cookies: MozillaCookieJar = MozillaCookieJar(default_cookie_file)cookies_handler = HTTPCookieProcessor(user_url_cookies)
opener = build_opener(cookies_handler)
response = opener.open(user_define_url)
user_url_cookies.save(ignore_discard=True, ignore_expires=True)
with open(default_cookie_file, 'r') as file:file_lines: list[str] = file.readlines()for line in file_lines:print(line)
MozillaCookieJar是 Python 中http.cookiejar模块提供的一个类(继承自CookieJar),用于处理与 Mozilla 浏览器兼容的 cookie 存储和加载。通常会在它实例化时传入保存字段的文件名。http.cookiejar模块提供了用于处理 HTTP cookies 的通用框架,而MozillaCookieJar则是该框架的一个特定实现,与 Mozilla 浏览器的 cookie 存储格式兼容(还有一种是LWPCookieJar)。它的save方法有以下参数
filename: 指定保存 cookie 的文件名。可以是字符串,也可以是类文件对象。如果不提供此参数,将使用 CookieJar 实例在创建时指定的文件名。
cookie_jar.save(filename='cookies.txt')ignore_discard: 如果设置为
True,则即使 cookie 被标记为丢弃(discard),也会被保存。默认为False。cookie_jar.save(ignore_discard=True)ignore_expires: 如果设置为
True,则即使 cookie 过期,也会被保存。默认为False。cookie_jar.save(ignore_expires=True)这些参数允许你在保存 cookie 时有一定的灵活性。通常,你可以选择忽略已标记为丢弃的 cookie 或已过期的 cookie,以确保在下一次加载 cookie 时能够包括更多的信息。
如何使用已保存cookie
load 方法用于从文件中加载保存的 cookie 数据,并将其恢复到 CookieJar 实例中。参数 ignore_discard 和 ignore_expires 控制是否忽略已标记为丢弃或已过期的 cookie。这两个参数的默认值都是 False。
from http.cookiejar import MozillaCookieJar
from urllib.request import HTTPCookieProcessor, build_openerdefault_cookie_file: str = 'temp_cookies.txt'
user_define_url: str = 'https://www.baidu.com'user_url_cookies: MozillaCookieJar = MozillaCookieJar()
user_url_cookies.load(default_cookie_file, ignore_discard=True, ignore_expires=True)
cookies_handler = HTTPCookieProcessor(user_url_cookies)
opener = build_opener(cookies_handler)
response = opener.open(user_define_url)
print(response.status)
设置全局打开器
在 urllib 模块中,install_opener 方法是 urllib.request 模块中的一个函数,用于安装一个自定义的 URL 打开器(opener)作为全局默认的打开器。我们对代理处理器进行小小的修改,使他变为一个默认的全局处理器,这样会使得该程序中的请求默认使用该打开器(其他设置的打开器并不受影响):
from urllib.request import ProxyHandler, build_opener, urlopen, install_opener
from urllib.error import URLError
from http.client import HTTPResponsedefault_username: str = 'username'
default_password: str = 'password'
user_define_url = 'https://httpbin.org/get'default_proxy: dict[str, str] = {'http': 'http://127.0.0.1:8080','https': 'http://127.0.0.1:8080'}
proxy_handler = ProxyHandler(default_proxy)
global_opener = build_opener(proxy_handler)install_opener(opener=global_opener)try:res: HTTPResponse = urlopen(user_define_url)html_document = res.read().decode('utf-8')print(html_document)
except URLError as e:print(e.reason)使用urllib进行解析与编码
使用urlparse进行url识别与分段
from urllib.parse import urlparsemy_define_url: str = 'http://www.example.com/index.php;default?username=xx&passwd=xxx#comment'
parse_res = urlparse(my_define_url)
print(parse_res)
""" 输出:ParseResult(scheme='http', netloc='www.example.com', path='/index.php', params='default'\, query='username=xx&passwd=xxx', fragment='comment')
"""
它实质上返回的是一个元组类型,urlparse有以下三个参数
- urlstring (必需): 要解析的URL字符串。这是唯一必需的参数,它包含要解析的完整URL。
- scheme: 指定默认的协议。如果URL字符串中没有显式指定协议(如 “http://” 或 “https://”),则使用此参数指定的协议。如果未提供,将从URL字符串中提取协议(如果存在)。
- allow_fragments: 控制是否解析URL中的片段标识符(fragment)。如果设置为
False,则片段标识符将被包含在路径中。默认为True,表示片段标识符将被从路径中分离
使用urlunparse进行url组建
urlunparse要求接受长度为6的可迭代对象,然后依次组建出url(注意不要搞错顺序):
from urllib.parse import urlunparsemy_url_subsection: tuple[str] = ('http', 'www.example.com', 'index.php', 'default','username=xx&passwd=xxx', 'comment')
parse_res = urlunparse(my_url_subsection)
print(parse_res)
""" 输出http://www.example.com/index.php;default?username=xx&passwd=xxx#comment
"""
使用urlsplit进行分割url
from urllib.parse import urlsplitmy_define_url: str = 'http://www.example.com/index.php;default?username=xx&passwd=xxx#comment'
parse_res = urlsplit(my_define_url)
print(parse_res)
""" 输出:SplitResult(scheme='http', netloc='www.example.com', path='/index.php;default'\, query='username=xx&passwd=xxx', fragment='comment')
"""
与urlparse类似,不过params被合并到了path,不过它实质上返回的也是元组类型
使用urlunsplit进行合并url
与urlunparse的区别是可迭代数据类型长度必须为5
from urllib.parse import urlunsplitmy_url_subsection: tuple[str] = ('http', 'www.example.com', 'index.php;default','username=xx&passwd=xxx', 'comment')
parse_res = urlunsplit(my_url_subsection)
print(parse_res)
""" 输出http://www.example.com/index.php;default?username=xx&passwd=xxx#comment
"""
使用urldecode进行数据编码
from urllib.parse import urlencodedata_dict: dict[str, str] = {'name': 'Super Kun Kun','content': 'The way you walk right in front of me makes me so excited'
}encode_data: str = urlencode(data_dict, encoding='utf-8')print(encode_data)
""" 输出:name=Super+Kun+Kun&content=The+way+you+walk+right+in+front+of+me+makes+me+so+excited
"""
使用urljoin进行合并url
urljion用来合并url,第一个参数作为基础url,第二参数作为新的url或相对url。如果是相对url,将会进行合并;如果是扩展url,urljoin将会进行比较scheme,netloc, path,如果出现不同,将会返回新的url。并且在合并过程中基础url中的params, query, fragment将会被丢弃
from urllib.parse import urljoinprint(urljoin('http://www.example.com', 'https://www.example.com'))
print(urljoin('http://www.example.com?submit=xxx', 'http://www.example.com/index.php'))
print(urljoin('http://www.example.com#submit', 'http://www.example.com/index.php'))
print(urljoin('http://www.example.com', '/index.php'))使用parse_qs将GET参数还原
from urllib.parse import parse_qsquery_data: str = 'username=xx&password=xxx'
print(parse_qs(query_data))
# 输出 {'username': ['xx'], 'password': ['xxx']}
使用parse_qsl将GET参数还原
from urllib.parse import parse_qslquery_data: str = 'username=xx&password=xxx'
print(parse_qsl(query_data))
# 输出 [('username', 'xx'), ('password', 'xxx')]
使用quote与unquote处理url中文字符
from urllib.parse import quote, unquoteprint(quote('你好世界'))
print(unquote('%E4%BD%A0%E5%A5%BD%E4%B8%96%E7%95%8C'))
# 输出 :
# %E4%BD%A0%E5%A5%BD%E4%B8%96%E7%95%8C
# 你好世界
处理解析robots文档
urllib中的robotparser模块用于解析robots文档,其中RobotFileParser专门用于解析,它只有一个参数,即目标url,以下是常用方法:
| 方法 | 描述 |
|---|---|
set_url() | 用来设置 robots.txt 文件的链接。如果在创建 RobotFileParser 对象时传人了链接,那么就不需要再使用这个方法设置了。 |
read() | 读取 robots.txt 文件并进行分析。注意,这个方法执行一个读取和分析操作,如果不调用这个方法,接下来的判断都会为 False,所以一定记得调用这个方法。这个方法不会返回任何内容,但是执行了读取操作。 |
parse() | 用来解析 robots.txt 文件,传人的参数是 robots.txt 某些行的内容,它会按照 robots.txt 的语法规则来分析这些内容。 |
can_fetch() | 该方法传人两个参数,第一个是 User-agent,第二个是要抓取的 URL。返回的内容是该搜索引擎是否可以抓取这个 URL,返回结果是 True 或 False。 |
mtime() | 返回的是上次抓取和分析 robots.txt 的时间,这对于长时间分析和抓取的搜索爬虫是很有必要的,你可能需要定期检查来抓取最新的 robots.txt。 |
modified() | 它同样对长时间分析和抓取的搜索爬虫很有帮助,将当前时间设置为上次抓取和分析 robots.txt 的时间。 |
一份可能的robots文档与语法解释:
# 不允许WebCrawler爬取网站
User-agent: WebCrawler
Disallow: /# Googlebot 可以访问所有页面,但不访问 /private/ 目录和 /restricted/ 页面
User-agent: Googlebot
Disallow: /private/
Disallow: /restricted/# Bingbot 只能访问 /public/ 目录和 /allowed-page.html 页面
User-agent: Bingbot
Allow: /public/
Allow: /allowed-page.html
Disallow: /# 限制特定爬虫 "BadBot" 只能访问 /public/ 目录
User-agent: BadBot
Allow: /public/
Disallow: /# 禁止所有爬虫访问 /admin/ 目录下的页面
User-agent: *
Disallow: /admin/# 定义爬虫的抓取间隔,每次抓取间隔至少为 5 秒
Crawl-delay: 5接下来我们在本地靶场进行测试:
from urllib.robotparser import RobotFileParserrobot_txt_parser: RobotFileParser = RobotFileParser()allow_agent: str = 'Googlebot'
disallow_agent: str = 'WebCrawler'
user_define_url: str = 'http://192.168.179.144'
default_url_robots: str = user_define_url + '/robots.txt'
robot_txt_parser.set_url(default_url_robots)
robot_txt_parser.read()
print(robot_txt_parser.can_fetch(allow_agent, user_define_url)) # 输出True
print(robot_txt_parser.can_fetch(disallow_agent, user_define_url)) # 输出False相关文章:

Python编程-使用urllib进行网络爬虫常用内容梳理
Python编程-使用urllib进行网络爬虫常用内容梳理 使用urllib库进行基础网络请求 使用request发起网络请求 from urllib import request from http.client import HTTPResponseresponse: HTTPResponse request.urlopen(url"http://pkc/vul/sqli/sqli_str.php") pr…...
01 Redis的特性+下载安装启动+Redis自动启动+客户端连接
1.1 NoSQL NoSQL(“non-relational”, “Not Only SQL”),泛指非关系型的数据库。 键值存储数据库 : 就像 Map 一样的 key-value 对。如Redis文档数据库 : NoSQL 与关系型数据的结合,最像关系…...

C++发起Https请求
Wininet库忽略Https证书 相信很多朋友使用C WINAPI开发的时候网络模块的时候遇到Https忽悠证书无效的情况下, 仍然希望获取结果下列代码便是忽略异常的Https CA证书,下面对原理进行简单的讲解首先, 需要设置Https忽略需要用到如下结果函数与参数Interne…...
哪款笔记软件支持电脑和手机互通数据?
上班族在日常工作中,随手记录工作笔记已成为司空见惯的场景。例如:从快节奏的会议记录到灵感迸发的创意;跟踪项目进展,记录每个阶段的成果、问题和下一步计划;记录、更新工作任务清单等,工作笔记承载了职场…...
部署PXE高效批量网络装机
部署PXE高效批量网络装机 因在Cisco3850核心交换机中已开启DHCP 服务,因此不需要在配置DHCP服务。如果您的网络环境中也已有DHCP服务,也不用再配置DHCP服务了,直接部署PXE相关服务即可。 找一台linux系统的服务器,这本次试验用的是…...
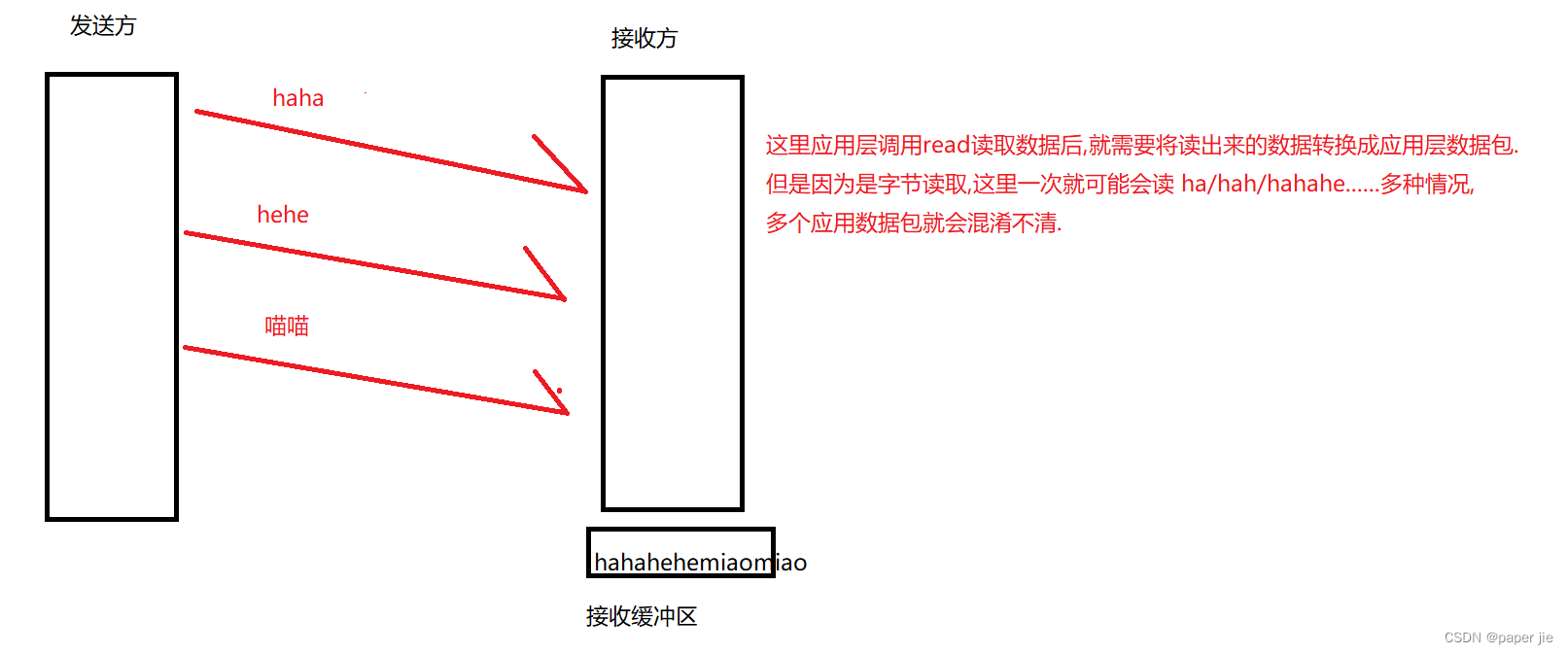
【JavaEE】UDP协议与TCP协议
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文于《JavaEE》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&…...

Leetcode—1828. 统计一个圆中点的数目【中等】
2024每日刷题(一零五) Leetcode—1828. 统计一个圆中点的数目 实现代码 class Solution { public:vector<int> countPoints(vector<vector<int>>& points, vector<vector<int>>& queries) {vector<int> a…...
)
新概念英语第二册(47)
New words and expressions】生词和短语(9) thirsty adj. 贪杯的 ghost n. 鬼魂 haunt v. (鬼)来访,闹鬼 block …...
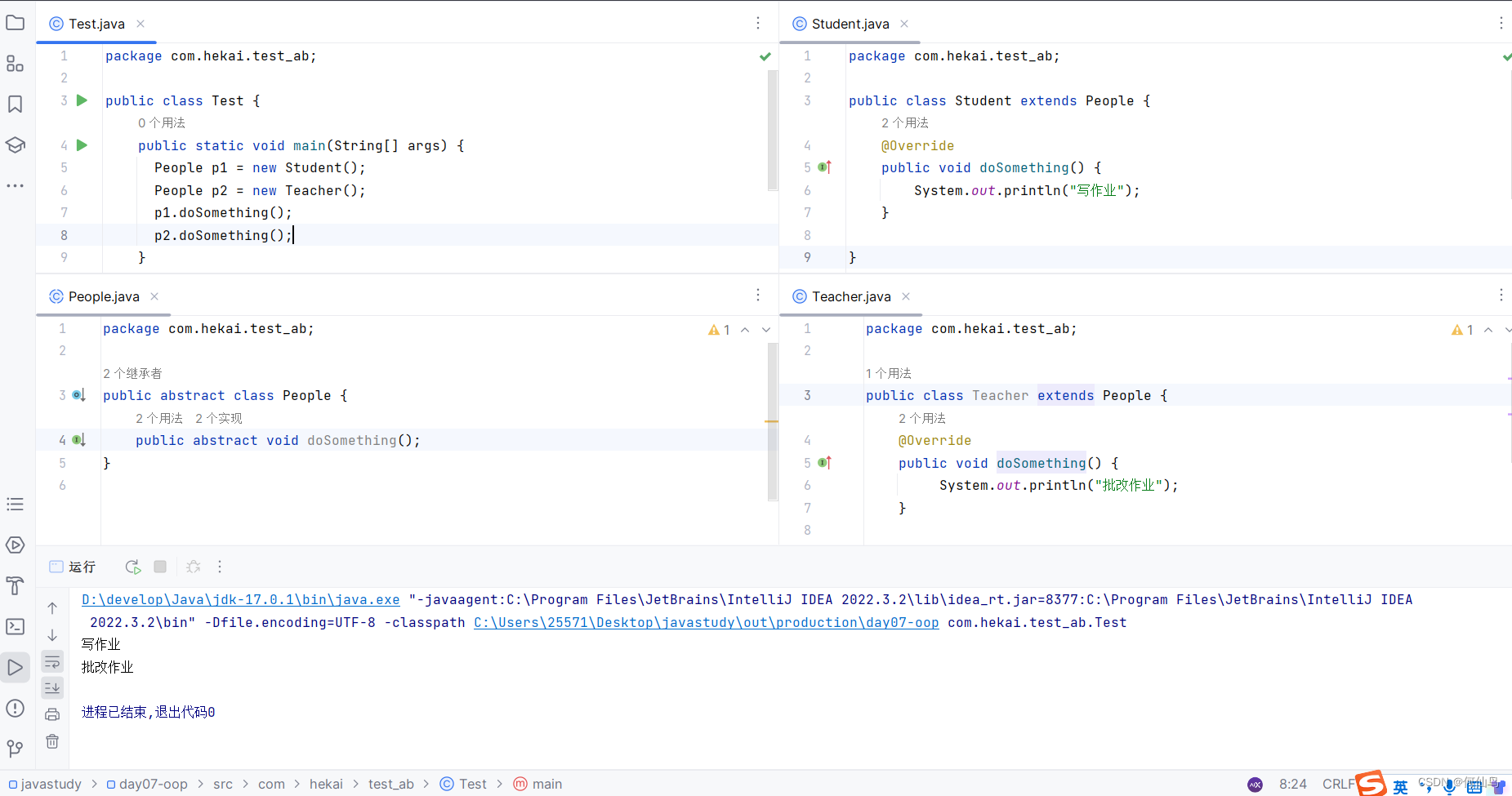
抽象类(Java)、模板方法设计模式
一、概念 在Java中有abstract关键字,就是抽象的意思,可用来修饰类和成员方法。 用abstract来修饰类,那这个类就是抽象类;修饰方法,那这个方法就是抽象方法。 修饰符 abstract class 类名{修饰符 abstract 返回值类型…...

【Delphi】IDE 工具栏错乱恢复
由于经常会在4K和2K显示器上切换Delphi开发环境(IDE),导致IDE工具栏错乱,咋样设置都无法恢复,后来看到红鱼儿的博客,说是通过操作注册表的方法,能解决,试了一下,果真好用,非常感谢分…...
)
自动化报告的前奏|使用python-pptx操作PPT(一)
自动化报告先从python-pptx开始 文章目录 1 python-pptx的基础属性1.1 新建幻灯片1.1.1 幻灯片布局的样式1.1.2 修改pptx模版大小1.1.3 指定模版生成1.1.4 创建幻灯片背景1.1.5 创建幻灯片备注信息1.1.6 设置幻灯片标题1.2 一些ppt元素/组件1.2.1 特殊符号1.2.2 placeholders1.…...

2024美赛数学建模D题思路+代码
文章目录 1 赛题思路2 美赛比赛日期和时间3 赛题类型4 美赛常见数模问题5 建模资料 1 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 2 美赛比赛日期和时间 比赛开始时间:北京时间2024年2月2日(周五ÿ…...
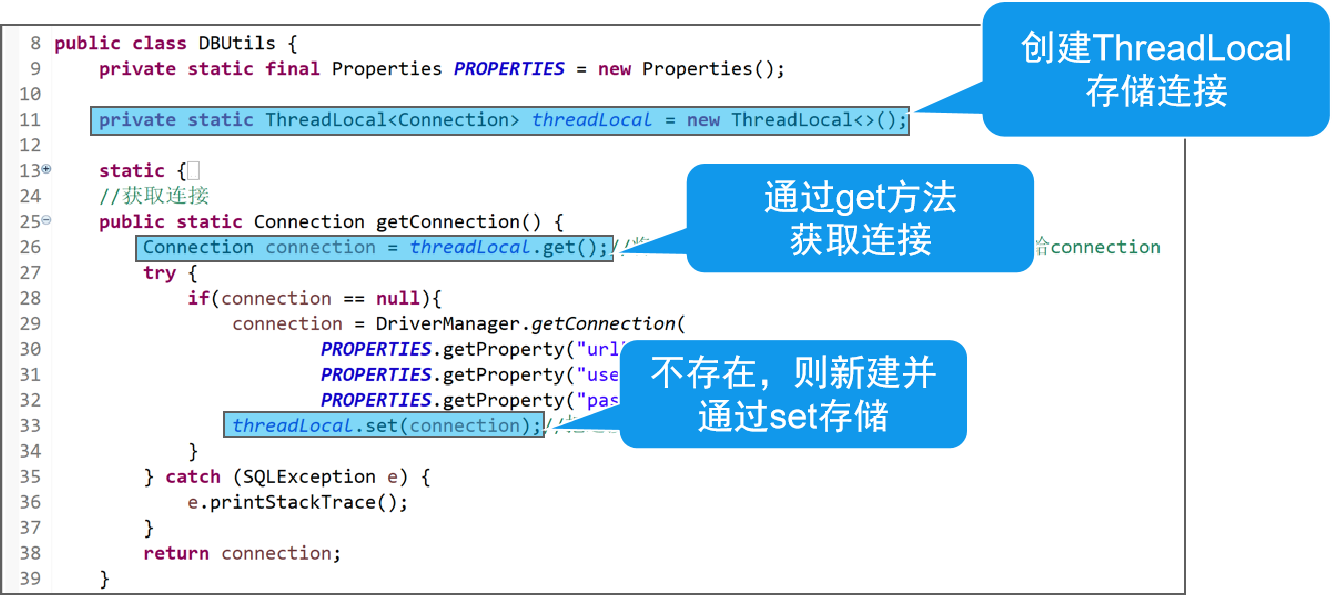
JDBC 结构优化2
JDBC 结构优化2 文章目录 JDBC 结构优化2结构优化2 - ATM系统(存,取,转,查)1 Service2 事务3 ThreadLocal4 事务的封装 结构优化2 - ATM系统(存,取,转,查) 1 Service 什么是业务? 代表用户完成的一个业务功能,可以由一个或多个DAO的调用组成。软件所提供的一个功…...

大模型相关术语
AGI(Artificial General Intelligence) 指通用人工智能,专注于研制像人一样思考、像人一样从事多种用途的机器。它与一般的特定领域智能(如机器视觉、语音识别等)相区分。 AIGC(AI-Generated Content&…...

数据库之九 流程控制、存储过程和函数
【零】数据准备 【1】创建用户信息表 (1)创建表 id:编号name:用户名sex:性别,默认男balance:余额register_time:注册时间 drop table if exists user; create table user( id in…...
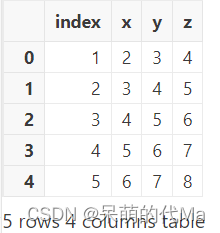
DolphinDB学习(2):增删改查数据表(分布式表的基本操作)
文章目录 创建数据表1. 创建数据表全流程2. 核心:创建table3. 在已有的数据表中追加新的数据 数据表自身的操作1. 查询有哪些数据表2. 删除某张数据表3. 修改数据表的名称 博客里只介绍最常见的分区表(createPartitionedTable)的创建方法&…...
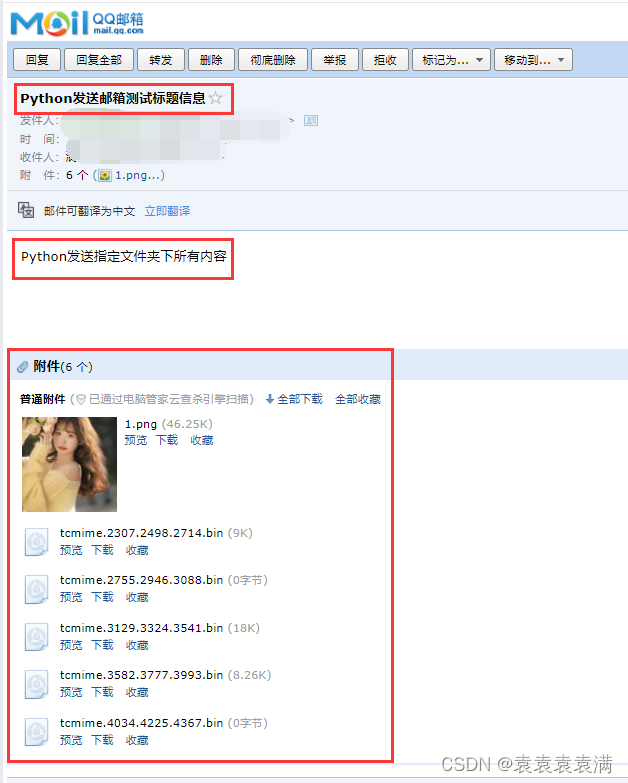
100天精通Python(实用脚本篇)——第114天:基于smtplib与email模块实现收发邮件(附上多个案例代码)
文章目录 专栏导读案例说明一、smtplib模块是什么?1.1 模块介绍1.2 SMTP参数说明1.3 SMTP常用方法 二、email模块是什么?1.1 模块介绍1.2 常用类说明 三、案例实战3.1 获取授权码3.2 代码步骤3.3 发送文本格式邮件3.4 发送图片格式邮件3.5 发送指定文件夹…...

redisTemplate.opsForValue()
redisTemplate 在Spring Data Redis中,redisTemplate 是一个非常重要的组件,它为开发者提供了各种操作 Redis 的方法。对于 opsForValue() 方法,它是用来获取一个操作字符串值的操作对象。这意味着你可以使用它来执行各种字符串相关的操作…...
多线程事务如何回滚?
背景介绍 1,最近有一个大数据量插入的操作入库的业务场景,需要先做一些其他修改操作,然后在执行插入操作,由于插入数据可能会很多,用到多线程去拆分数据并行处理来提高响应时间,如果有一个线程执行失败&am…...

医院如何筛选安全合规的内外网文件交换系统?
医院内外网文件交换系统是专为医疗机构设计的,用于在内部网络(内网)和外部网络(外网)之间安全、高效地传输敏感医疗数据和文件的解决方案。这种系统对于保护患者隐私、遵守医疗数据保护法规以及确保医疗服务的连续性和…...

GHelper终极指南:像调音师一样掌控你的ROG笔记本散热系统
GHelper终极指南:像调音师一样掌控你的ROG笔记本散热系统 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

JMeter TPS真相:业务吞吐量 vs 采样均值的全栈解剖
1. 为什么TPS不是“点一下就出来的数字”,而是压测成败的命门刚接手公司电商大促前的压测任务时,我盯着JMeter报告里那个醒目的TPS(Transactions Per Second)数值,心里还觉得挺踏实——毕竟它看起来比“线程数”“响应…...
)
自动驾驶、机器人导航都在用:实战调参卡尔曼滤波的Q和R(Python/OpenCV示例)
自动驾驶与机器人导航中的卡尔曼滤波实战:Q和R参数调优指南卡尔曼滤波在状态估计领域就像一位不知疲倦的裁判,不断在系统预测和传感器测量之间寻找平衡点。而Q(过程噪声协方差)和R(测量噪声协方差)这两个关…...

条件期望与奇异值分解:概率论与矩阵分析中的最优逼近原理
1. 项目概述:连接概率与矩阵的数学桥梁在数据科学和机器学习的日常工作中,我们常常在两个看似独立的数学世界里穿梭:一个是处理不确定性和随机性的概率论,另一个是处理高维数据和线性结构的矩阵分析。很多从业者可能熟悉主成分分析…...

保姆级教程:为你的CentOS7服务器手动安装GNOME桌面,告别黑屏与鼠标箭头
从零构建CentOS7图形化工作站:GNOME桌面完整安装与深度优化指南当你第一次面对CentOS7漆黑的命令行界面时,那种茫然无措的感觉我深有体会。三年前接手公司第一台生产服务器时,我盯着闪烁的光标整整十分钟不敢敲下任何命令——毕竟在Ubuntu漂亮…...

Keil MDK许可证错误解决方案与调试技巧
1. 问题现象与背景解析 当使用Keil MDK进行嵌入式开发时,部分用户在编译或调试阶段会遇到"LICENSE: License Mapping Failed"的错误提示。这个报错通常出现在以下两种场景: 编译阶段:在Build Output窗口突然弹出红色错误提示&…...

数据科学家最后的护城河:AI Agent时代必须掌握的3类元能力——意图解析力、链路可观测性、反事实调试术
更多请点击: https://codechina.net 第一章:数据科学家最后的护城河:AI Agent时代必须掌握的3类元能力——意图解析力、链路可观测性、反事实调试术 当AI Agent开始自主拆解用户模糊请求、调度工具链、迭代验证假设时,传统建模技…...

逻辑可解释性:用SAT/SMT/MILP求解器为机器学习模型提供可验证的解释
1. 项目概述:当机器学习遇上形式化逻辑在机器学习模型日益渗透到医疗诊断、金融风控、自动驾驶等高风险决策领域的今天,一个核心的信任危机也随之而来:我们如何理解一个“黑箱”模型做出的判断?传统的可解释性方法,如L…...

1000个文件重命名,1秒完成!批量文件重命名软件
前言: 大家好,这里是惠众资料库, 在日常办公、资料归档、素材整理、摄影剪辑等各类场景中,用户会积累大量图片、文档、视频、音频、文件夹等各类文件。为了实现文件分类规整、统一命名规范、方便快速检索调用,文件重命…...

AI系列【仅供参考】:TRAE 支持自定义模型了,配置个 DeepSeek V4 试试
TRAE 支持自定义模型了,配置个 DeepSeek V4 试试TRAE 支持自定义模型了,配置个 DeepSeek V4 试试原因解决方案底下评论问题一:回答一:回答二:回答三:问题二:回答一:问题三࿱…...