Vim实战:使用 Vim实现图像分类任务(二)
文章目录
- 训练部分
- 导入项目使用的库
- 设置随机因子
- 设置全局参数
- 图像预处理与增强
- 读取数据
- 设置Loss
- 设置模型
- 设置优化器和学习率调整策略
- 设置混合精度,DP多卡,EMA
- 定义训练和验证函数
- 训练函数
- 验证函数
- 调用训练和验证方法
- 运行以及结果查看
- 测试
- 完整的代码
在上一篇文章中完成了前期的准备工作,见链接:
Vim实战:使用Vim实现图像分类任务(一)
前期的工作主要是数据的准备,安装库文件,数据增强方式的讲解,模型的介绍和实验效果等内容。接下来,这篇主要是讲解如何训练和测试
训练部分
完成上面的步骤后,就开始train脚本的编写,新建train.py
导入项目使用的库
在train.py导入
import json
import os
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from timm.utils import accuracy, AverageMeter, ModelEma
from sklearn.metrics import classification_report
from timm.data.mixup import Mixup
from timm.loss import SoftTargetCrossEntropy
from models.models_mamba import vim_tiny_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_rope_also_residual_with_cls_token
from torch.autograd import Variable
from torchvision import datasets
torch.backends.cudnn.benchmark = False
import warnings
warnings.filterwarnings("ignore")
os.environ['CUDA_VISIBLE_DEVICES']="0,1"
os.environ[‘CUDA_VISIBLE_DEVICES’]=“0,1” 选择显卡,index从0开始,比如一台机器上有8块显卡,我们打算使用前两块显卡训练,设置为“0,1”,同理如果打算使用第三块和第六块显卡训练,则设置为“2,5”。
设置随机因子
def seed_everything(seed=42):os.environ['PYHTONHASHSEED'] = str(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.backends.cudnn.deterministic = True
设置了固定的随机因子,再次训练的时候就可以保证图片的加载顺序不会发生变化。
设置全局参数
if __name__ == '__main__':#创建保存模型的文件夹file_dir = 'checkpoints/Vim/'if os.path.exists(file_dir):print('true')os.makedirs(file_dir,exist_ok=True)else:os.makedirs(file_dir)# 设置全局参数model_lr = 3e-4BATCH_SIZE = 16EPOCHS = 300DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')use_amp = True # 是否使用混合精度use_dp = True #是否开启dp方式的多卡训练classes = 12resume =NoneCLIP_GRAD = 5.0Best_ACC = 0 #记录最高得分use_ema=Truemodel_ema_decay=0.9998start_epoch=1seed=1seed_everything(seed)
创建一个名为 ‘checkpoints/Vim/’ 的文件夹,用于保存训练过程中的模型。如果该文件夹已经存在,则不会再次创建,否则会创建该文件夹。
设置训练模型的全局参数,包括学习率、批次大小、训练轮数、设备选择(是否使用 GPU)、是否使用混合精度、是否开启数据并行等。
注:建议使用GPU,CPU太慢了。
参数的详细解释:
model_lr:学习率,根据实际情况做调整。
BATCH_SIZE:batchsize,根据显卡的大小设置。
EPOCHS:epoch的个数,一般300够用。
use_amp:是否使用混合精度。
use_dp :是否开启dp方式的多卡训练?
classes:类别个数。
resume:再次训练的模型路径,如果不为None,则表示加载resume指向的模型继续训练。
CLIP_GRAD:梯度的最大范数,在梯度裁剪里设置。
Best_ACC:记录最高ACC得分。
use_ema:是否使用ema
model_ema_decay:
start_epoch:开始的epoch,默认是1,如果重新训练时,需要给start_epoch重新赋值。
SEED:随机因子,数值可以随意设定,但是设置后,不要随意更改,更改后,图片加载的顺序会改变,影响测试结果。
file_dir = 'checkpoints/Vim/'
这是存放Vim模型的路径。
图像预处理与增强
# 数据预处理7transform = transforms.Compose([transforms.RandomRotation(10),transforms.GaussianBlur(kernel_size=(5,5),sigma=(0.1, 3.0)),transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.3281186, 0.28937867, 0.20702125], std= [0.09407319, 0.09732835, 0.106712654])])transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.3281186, 0.28937867, 0.20702125], std= [0.09407319, 0.09732835, 0.106712654])])mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=classes)
数据处理和增强比较简单,加入了随机10度的旋转、高斯模糊、色彩饱和度明亮度的变化、Mixup等比较常用的增强手段,做了Resize和归一化。
transforms.Normalize(mean=[0.3281186, 0.28937867, 0.20702125], std= [0.09407319, 0.09732835, 0.106712654])
这里设置为计算mean和std。
这里注意下Resize的大小,由于选用的FlashInternImage模型输入是224×224的大小,所以要Resize为224×224。
mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=classes)
定义了一个 Mixup 函数。Mixup 是一种在图像分类任务中常用的数据增强技术,它通过将两张图像以及其对应的标签进行线性组合来生成新的数据和标签。
读取数据
# 读取数据dataset_train = datasets.ImageFolder('data/train', transform=transform)dataset_test = datasets.ImageFolder("data/val", transform=transform_test)with open('class.txt', 'w') as file:file.write(str(dataset_train.class_to_idx))with open('class.json', 'w', encoding='utf-8') as file:file.write(json.dumps(dataset_train.class_to_idx))# 导入数据train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE,num_workers=8, shuffle=True,drop_last=True)test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
-
使用pytorch默认读取数据的方式,然后将dataset_train.class_to_idx打印出来,预测的时候要用到。
-
对于train_loader ,drop_last设置为True,因为使用了Mixup数据增强,必须保证每个batch里面的图片个数为偶数(不能为零),如果最后一个batch里面的图片为奇数,则会报错,所以舍弃最后batch的迭代,pin_memory设置为True,可以加快运行速度,num_workers多进程加载图像,不要超过CPU 的核数。
-
将dataset_train.class_to_idx保存到txt文件或者json文件中。
class_to_idx的结果:
{'Black-grass': 0, 'Charlock': 1, 'Cleavers': 2, 'Common Chickweed': 3, 'Common wheat': 4, 'Fat Hen': 5, 'Loose Silky-bent': 6, 'Maize': 7, 'Scentless Mayweed': 8, 'Shepherds Purse': 9, 'Small-flowered Cranesbill': 10, 'Sugar beet': 11}
设置Loss
# 实例化模型并且移动到GPUcriterion_train = SoftTargetCrossEntropy()criterion_val = torch.nn.CrossEntropyLoss()
设置loss函数,训练的loss为:SoftTargetCrossEntropy,验证的loss:nn.CrossEntropyLoss()。
设置模型
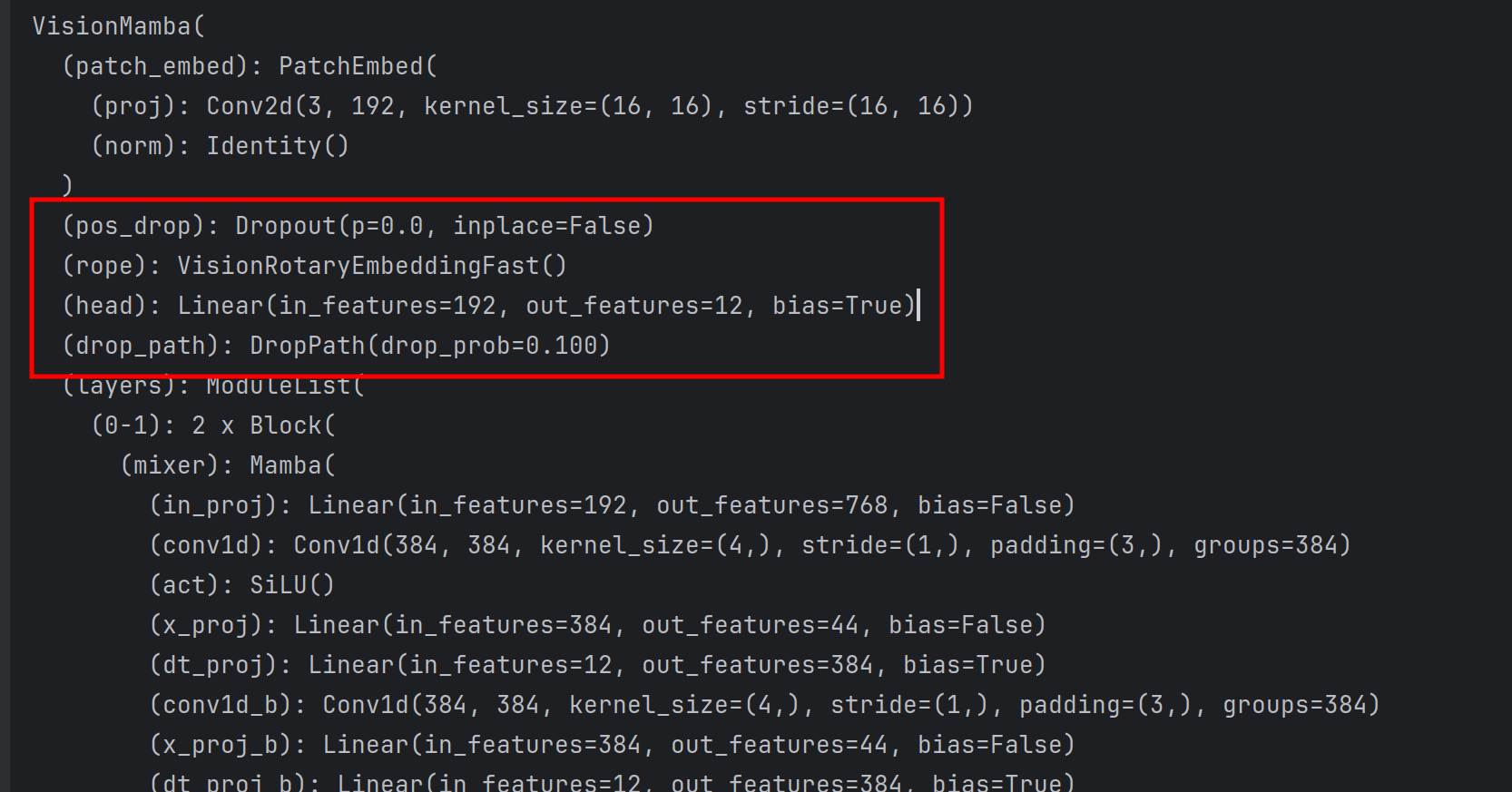
#设置模型model_ft = vim_tiny_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_rope_also_residual_with_cls_token(pretrained=True)num_freature=model_ft.head.in_featuresmodel_ft.head=nn.Linear(num_freature,classes)if resume:model=torch.load(resume)print(model['state_dict'].keys())model_ft.load_state_dict(model['state_dict'])Best_ACC=model['Best_ACC']start_epoch=model['epoch']+1model_ft.to(DEVICE)print(model_ft)
- 设置模型为vim_tiny_patch16_224_bimambav2_final_pool_mean_abs_pos_embed_rope_also,获取分类模块的in_features,然后,修改为数据集的类别,也就是classes。
- 如果resume设置为已经训练的模型的路径,则加载模型接着resume指向的模型接着训练,使用模型里的Best_ACC初始化Best_ACC,使用epoch参数初始化start_epoch。
- 如果模型输出是classes的长度,则表示修改正确了。
设置优化器和学习率调整策略
# 选择简单暴力的Adam优化器,学习率调低optimizer = optim.AdamW(model_ft.parameters(),lr=model_lr)cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)
- 优化器设置为adamW。
- 学习率调整策略选择为余弦退火。
设置混合精度,DP多卡,EMA
if use_amp:scaler = torch.cuda.amp.GradScaler()if torch.cuda.device_count() > 1 and use_dp:print("Let's use", torch.cuda.device_count(), "GPUs!")model_ft = torch.nn.DataParallel(model_ft)if use_ema:model_ema = ModelEma(model_ft,decay=model_ema_decay,device=DEVICE,resume=resume)else:model_ema=None
定义训练和验证函数
训练函数
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch,model_ema):model.train()loss_meter = AverageMeter()acc1_meter = AverageMeter()acc5_meter = AverageMeter()total_num = len(train_loader.dataset)print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device, non_blocking=True), Variable(target).to(device,non_blocking=True)samples, targets = mixup_fn(data, target)output = model(samples)optimizer.zero_grad()if use_amp:with torch.cuda.amp.autocast():loss = torch.nan_to_num(criterion_train(output, targets))scaler.scale(loss).backward()torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_GRAD)# Unscales gradients and calls# or skips optimizer.step()scaler.step(optimizer)# Updates the scale for next iterationscaler.update()else:loss = criterion_train(output, targets)loss.backward()# torch.nn.utils.clip_grad_norm_(models.parameters(), CLIP_GRAD)optimizer.step()if model_ema is not None:model_ema.update(model)torch.cuda.synchronize()lr = optimizer.state_dict()['param_groups'][0]['lr']loss_meter.update(loss.item(), target.size(0))acc1, acc5 = accuracy(output, target, topk=(1, 5))loss_meter.update(loss.item(), target.size(0))acc1_meter.update(acc1.item(), target.size(0))acc5_meter.update(acc5.item(), target.size(0))if (batch_idx + 1) % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR:{:.9f}'.format(epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),100. * (batch_idx + 1) / len(train_loader), loss.item(), lr))ave_loss =loss_meter.avgacc = acc1_meter.avgprint('epoch:{}\tloss:{:.2f}\tacc:{:.2f}'.format(epoch, ave_loss, acc))return ave_loss, acc训练的主要步骤:
1、使用AverageMeter保存自定义变量,包括loss,ACC1,ACC5。
2、进入循环,将data和target放入device上,non_blocking设置为True。如果pin_memory=True的话,将数据放入GPU的时候,也应该把non_blocking打开,这样就只把数据放入GPU而不取出,访问时间会大大减少。
如果pin_memory=False时,则将non_blocking设置为False。
3、将数据输入mixup_fn生成mixup数据。
4、将第三部生成的mixup数据输入model,输出预测结果,然后再计算loss。
5、 optimizer.zero_grad() 梯度清零,把loss关于weight的导数变成0。
6、如果使用混合精度,则
- with torch.cuda.amp.autocast(),开启混合精度。
- 计算loss。torch.nan_to_num将输入中的NaN、正无穷大和负无穷大替换为NaN、posinf和neginf。默认情况下,nan会被替换为零,正无穷大会被替换为输入的dtype所能表示的最大有限值,负无穷大会被替换为输入的dtype所能表示的最小有限值。
- scaler.scale(loss).backward(),梯度放大。
- torch.nn.utils.clip_grad_norm_,梯度裁剪,放置梯度爆炸。
- scaler.step(optimizer) ,首先把梯度值unscale回来,如果梯度值不是inf或NaN,则调用optimizer.step()来更新权重,否则,忽略step调用,从而保证权重不更新。
- 更新下一次迭代的scaler。
否则,直接反向传播求梯度。torch.nn.utils.clip_grad_norm_函数执行梯度裁剪,防止梯度爆炸。
7、如果use_ema为True,则执行model_ema的updata函数,更新模型。
8、 torch.cuda.synchronize(),等待上面所有的操作执行完成。
9、接下来,更新loss,ACC1,ACC5的值。
等待一个epoch训练完成后,计算平均loss和平均acc
验证函数
# 验证过程
@torch.no_grad()
def val(model, device, test_loader):global Best_ACCmodel.eval()loss_meter = AverageMeter()acc1_meter = AverageMeter()acc5_meter = AverageMeter()total_num = len(test_loader.dataset)print(total_num, len(test_loader))val_list = []pred_list = []for data, target in test_loader:for t in target:val_list.append(t.data.item())data, target = data.to(device,non_blocking=True), target.to(device,non_blocking=True)output = model(data)loss = criterion_val(output, target)_, pred = torch.max(output.data, 1)for p in pred:pred_list.append(p.data.item())acc1, acc5 = accuracy(output, target, topk=(1, 5))loss_meter.update(loss.item(), target.size(0))acc1_meter.update(acc1.item(), target.size(0))acc5_meter.update(acc5.item(), target.size(0))acc = acc1_meter.avgprint('\nVal set: Average loss: {:.4f}\tAcc1:{:.3f}%\tAcc5:{:.3f}%\n'.format(loss_meter.avg, acc, acc5_meter.avg))if acc > Best_ACC:if isinstance(model, torch.nn.DataParallel):torch.save(model.module, file_dir + '/' + 'best.pth')else:torch.save(model, file_dir + '/' + 'best.pth')Best_ACC = accif isinstance(model, torch.nn.DataParallel):state = {'epoch': epoch,'state_dict': model.module.state_dict(),'Best_ACC':Best_ACC}if use_ema:state['state_dict_ema']=model.module.state_dict()torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')else:state = {'epoch': epoch,'state_dict': model.state_dict(),'Best_ACC': Best_ACC}if use_ema:state['state_dict_ema']=model.state_dict()torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')return val_list, pred_list, loss_meter.avg, acc验证集和训练集大致相似,主要步骤:
1、在val的函数上面添加@torch.no_grad(),作用:所有计算得出的tensor的requires_grad都自动设置为False。即使一个tensor(命名为x)的requires_grad = True,在with torch.no_grad计算,由x得到的新tensor(命名为w-标量)requires_grad也为False,且grad_fn也为None,即不会对w求导。
2、定义参数:
loss_meter: 测试的loss
acc1_meter:top1的ACC。
acc5_meter:top5的ACC。
total_num:总的验证集的数量。
val_list:验证集的label。
pred_list:预测的label。
3、进入循环,迭代test_loader:将label保存到val_list。
将data和target放入device上,non_blocking设置为True。
将data输入到model中,求出预测值,然后输入到loss函数中,求出loss。
调用torch.max函数,将预测值转为对应的label。
将输出的预测值的label存入pred_list。
调用accuracy函数计算ACC1和ACC5
更新loss_meter、acc1_meter、acc5_meter的参数。
4、本次epoch循环完成后,求得本次epoch的acc、loss。
5、接下来是保存模型的逻辑
如果ACC比Best_ACC高,则保存best模型
判断模型是否为DP方式训练的模型。如果是DP方式训练的模型,模型参数放在model.module,则需要保存model.module。
否则直接保存model。
注:保存best模型,我们采用保存整个模型的方式,这样保存的模型包含网络结构,在预测的时候,就不用再重新定义网络了。6、接下来保存每个epoch的模型。
判断模型是否为DP方式训练的模型。如果是DP方式训练的模型,模型参数放在model.module,则需要保存model.module.state_dict()。
新建个字典,放置Best_ACC、epoch和 model.module.state_dict()等参数。然后将这个字典保存。判断是否是使用EMA,如果使用,则还需要保存一份ema的权重。
否则,新建个字典,放置Best_ACC、epoch和 model.state_dict()等参数。然后将这个字典保存。判断是否是使用EMA,如果使用,则还需要保存一份ema的权重。注意:对于每个epoch的模型只保存了state_dict参数,没有保存整个模型文件。
调用训练和验证方法
# 训练与验证is_set_lr = Falselog_dir = {}train_loss_list, val_loss_list, train_acc_list, val_acc_list, epoch_list = [], [], [], [], []if resume and os.path.isfile(file_dir+"result.json"):with open(file_dir+'result.json', 'r', encoding='utf-8') as file:logs = json.load(file)train_acc_list = logs['train_acc']train_loss_list = logs['train_loss']val_acc_list = logs['val_acc']val_loss_list = logs['val_loss']epoch_list = logs['epoch_list']for epoch in range(start_epoch, EPOCHS + 1):epoch_list.append(epoch)log_dir['epoch_list'] = epoch_listtrain_loss, train_acc = train(model_ft, DEVICE, train_loader, optimizer, epoch,model_ema)train_loss_list.append(train_loss)train_acc_list.append(train_acc)log_dir['train_acc'] = train_acc_listlog_dir['train_loss'] = train_loss_listif use_ema:val_list, pred_list, val_loss, val_acc = val(model_ema.ema, DEVICE, test_loader)else:val_list, pred_list, val_loss, val_acc = val(model_ft, DEVICE, test_loader)val_loss_list.append(val_loss)val_acc_list.append(val_acc)log_dir['val_acc'] = val_acc_listlog_dir['val_loss'] = val_loss_listlog_dir['best_acc'] = Best_ACCwith open(file_dir + '/result.json', 'w', encoding='utf-8') as file:file.write(json.dumps(log_dir))print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))if epoch < 600:cosine_schedule.step()else:if not is_set_lr:for param_group in optimizer.param_groups:param_group["lr"] = 1e-6is_set_lr = Truefig = plt.figure(1)plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')# 显示图例plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')plt.legend(["Train Loss", "Val Loss"], loc="upper right")plt.xlabel(u'epoch')plt.ylabel(u'loss')plt.title('Model Loss ')plt.savefig(file_dir + "/loss.png")plt.close(1)fig2 = plt.figure(2)plt.plot(epoch_list, train_acc_list, 'r-', label=u'Train Acc')plt.plot(epoch_list, val_acc_list, 'b-', label=u'Val Acc')plt.legend(["Train Acc", "Val Acc"], loc="lower right")plt.title("Model Acc")plt.ylabel("acc")plt.xlabel("epoch")plt.savefig(file_dir + "/acc.png")plt.close(2)
调用训练函数和验证函数的主要步骤:
1、定义参数:
- is_set_lr,是否已经设置了学习率,当epoch大于一定的次数后,会将学习率设置到一定的值,并将其置为True。
- log_dir:记录log用的,将有用的信息保存到字典中,然后转为json保存起来。
- train_loss_list:保存每个epoch的训练loss。
- val_loss_list:保存每个epoch的验证loss。
- train_acc_list:保存每个epoch的训练acc。
- val_acc_list:保存么每个epoch的验证acc。
- epoch_list:存放每个epoch的值。
如果是接着上次的断点继续训练则读取log文件,然后把log取出来,赋值到对应的list上。
循环epoch1、调用train函数,得到 train_loss, train_acc,并将分别放入train_loss_list,train_acc_list,然后存入到logdir字典中。
2、调用验证函数,判断是否使用EMA?
如果使用EMA,则传入model_ema.ema,否则,传入model_ft。得到val_list, pred_list, val_loss, val_acc。将val_loss, val_acc分别放入val_loss_list和val_acc_list中,然后存入到logdir字典中。3、保存log。
4、打印本次的测试报告。
5、如果epoch大于600,将学习率设置为固定的1e-6。
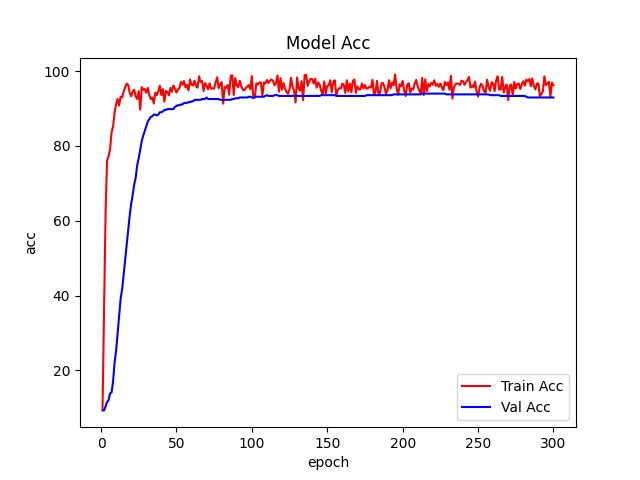
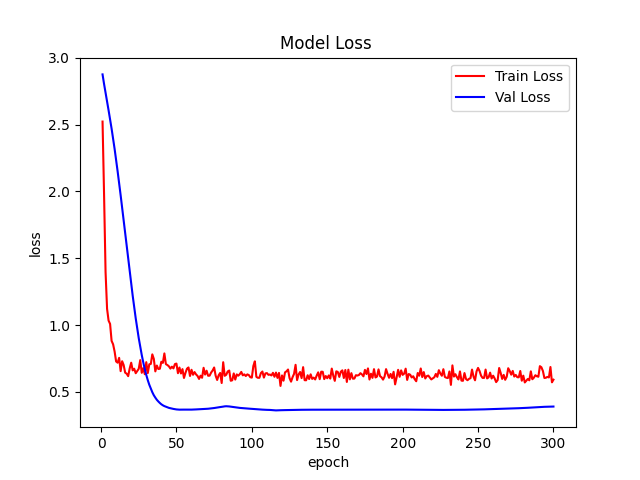
6、绘制loss曲线和acc曲线。
运行以及结果查看
完成上面的所有代码就可以开始运行了。点击右键,然后选择“run train.py”即可,运行结果如下:
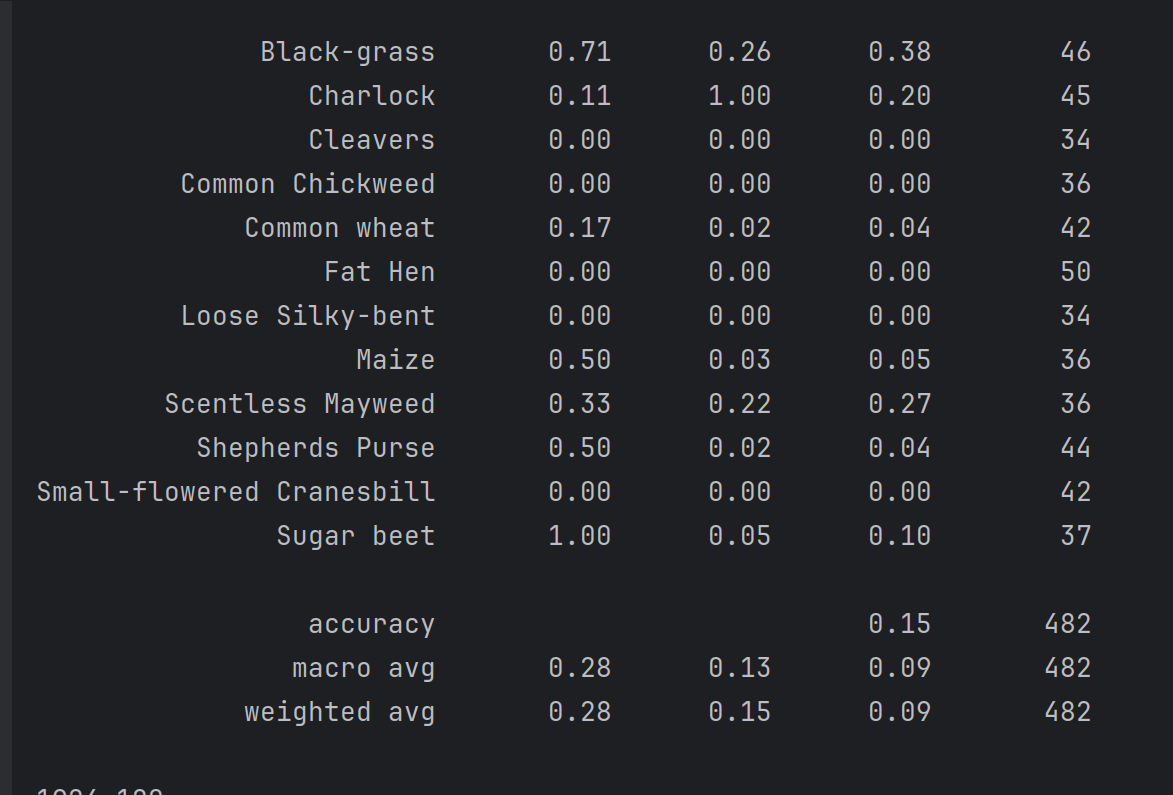
在每个epoch测试完成之后,打印验证集的acc、recall等指标。
Vim测试结果:
测试
测试,我们采用一种通用的方式。
测试集存放的目录如下图:
Vim_Demo
├─test
│ ├─1.jpg
│ ├─2.jpg
│ ├─3.jpg
│ ├ ......
└─test.py
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import osclasses = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed','Common wheat', 'Fat Hen', 'Loose Silky-bent','Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet')
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933])
])DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model=torch.load('checkpoints/Vim/best.pth')
model.eval()
model.to(DEVICE)
print(model)path = 'test/'
testList = os.listdir(path)
for file in testList:img = Image.open(path + file)img = transform_test(img)img.unsqueeze_(0)img = Variable(img).to(DEVICE)out = model(img)# Predict_, pred = torch.max(out.data, 1)print('Image Name:{},predict:{}'.format(file, classes[pred.data.item()]))测试的主要逻辑:
1、定义类别,这个类别的顺序和训练时的类别顺序对应,一定不要改变顺序!!!!
2、定义transforms,transforms和验证集的transforms一样即可,别做数据增强。
3、 torch.load加载model,然后将模型放在DEVICE里,
4、循环 读取图片并预测图片的类别,在这里注意,读取图片用PIL库的Image。不要用cv2,transforms不支持。循环里面的主要逻辑:
- 使用Image.open读取图片
- 使用transform_test对图片做归一化和标椎化。
- img.unsqueeze_(0) 增加一个维度,由(3,224,224)变为(1,3,224,224)
- Variable(img).to(DEVICE):将数据放入DEVICE中。
- model(img):执行预测。
- _, pred = torch.max(out.data, 1):获取预测值的最大下角标。
运行结果:

完整的代码
完整的代码:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/88794291
相关文章:
Vim实战:使用 Vim实现图像分类任务(二)
文章目录 训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整策略设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法 运行以及结果查看测试完整的代码 在上…...

学习MySQL ENUM数据类型
学习MySQL ENUM数据类型 ENUM是MySQL中的一个字符串对象,它允许从预定义的值列表中选择一个值。这种数据类型特别适用于值的数量有限且不太可能变化的情况。 定义ENUM类型 在定义ENUM类型时,你需要明确列出所有可能的字符串值。例如: CRE…...

88.合并两个有序数组
88.合并两个有序数组 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 **注意:**最…...

python查询xml类别
第一章 导包 import os from xml.etree.ElementTree import ElementTree第二章 存储类别 # 定义一个空集合用于存储类别 classes set()第三章 遍历所有XML文件 # 遍历指定目录下的所有XML文件 for filename in os.listdir(/home/li/PycharmProjects/Annotations):if filena…...

nginx配置及性能优化
1. 请简述nginx的工作原理? Nginx的工作原理基于事件驱动模型和异步非阻塞I/O处理机制。 具体来说,Nginx接收到客户端的请求后,会将该请求映射到配置文件中指定的location block。这个过程中,Nginx本身并不执行实际的工作&#…...
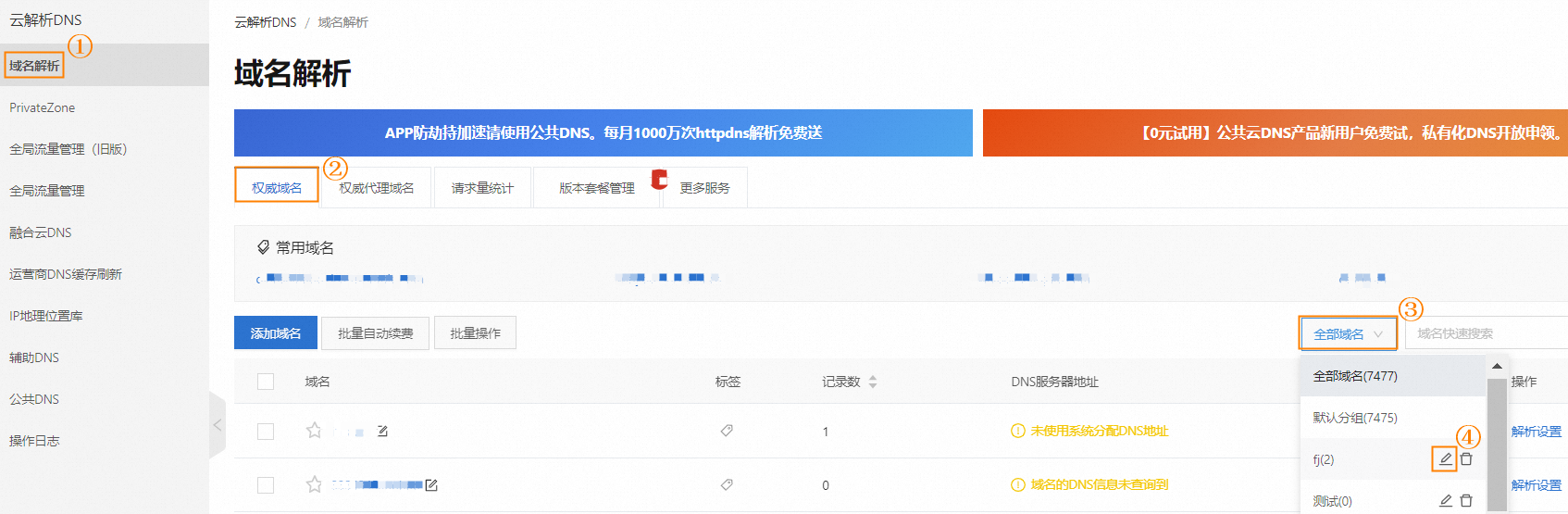
阿里云如何找回域名,进行添加或删除?
权威域名管理介绍说明,包含添加域名、删除域名、找回域名、域名分组等操作介绍。 一、添加域名 非阿里云注册域名或子域名如需使用云解析DNS,需要通过添加域名功能,将主域名或子域名添加到云解析控制台,才可以启用域名解析服务。…...
机器学习 低代码 ML:PyCaret 的使用
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...
前端入门第二天
目录 一、列表、表格、表单 二、列表(布局内容排列整齐的区域) 1.无序列表(不规定顺序) 2.有序列表(规定顺序) 3.定义列表(一个标题多个分类) 三、表格 1.表格结构标签 2.合并…...

Django实现富文本编辑器Ckeditor5图片上传功能
上一章我们已经为我们的博客继承了富文本编辑器Ckeditor5,虽然已经可以对文字进行排版处理,虽然已经可以通过插入图片的url地址来插入图片,但还无法通过本地上传图片,那么我们这个富文本编辑器就是不完整的,这一章我们将实现上传图片功能! Ckeditor5图片上传采用的是…...

【C语言】epoll_wait / select
一、epoll_wait和select对比 1. 阻塞和非阻塞 在Linux C语言中进行socket编程时,epoll_wait 和 select 都是用于多路I/O复用的系统调用,但是它们的行为可以设置为阻塞和非阻塞模式,这取决于调用它们时所使用的参数。 让我们分别看看 epoll…...
Java 数据抓取
大家好我是苏麟 , 今天聊聊数据抓取 . 大家合理使用 注意,爬虫技术不能滥用,干万不要给别人的系统造成压力、不要侵犯他人权益! 数据抓取 实质上就是java程序模拟浏览器进行目标网站的访问,无论是请求目标服务器的接口还是请求目标网页内容…...
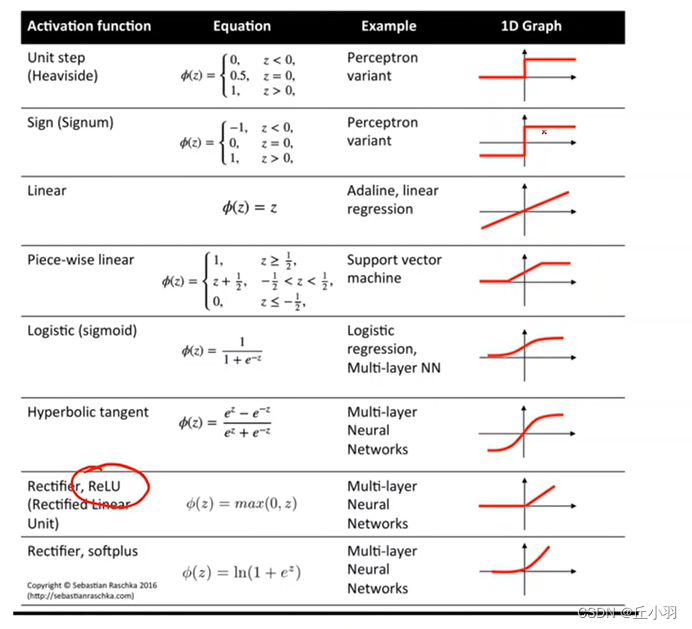
深度学习之处理多维特征的输入
我们首先来看一个糖尿病的数据集: 在数据集中,我们称每一行叫做sample,表示一个样本,称每一列是feature,也就是特征在数据库里面这就是一个关系表,每一行叫做记录,每一列叫做字段。 每一个样本都…...
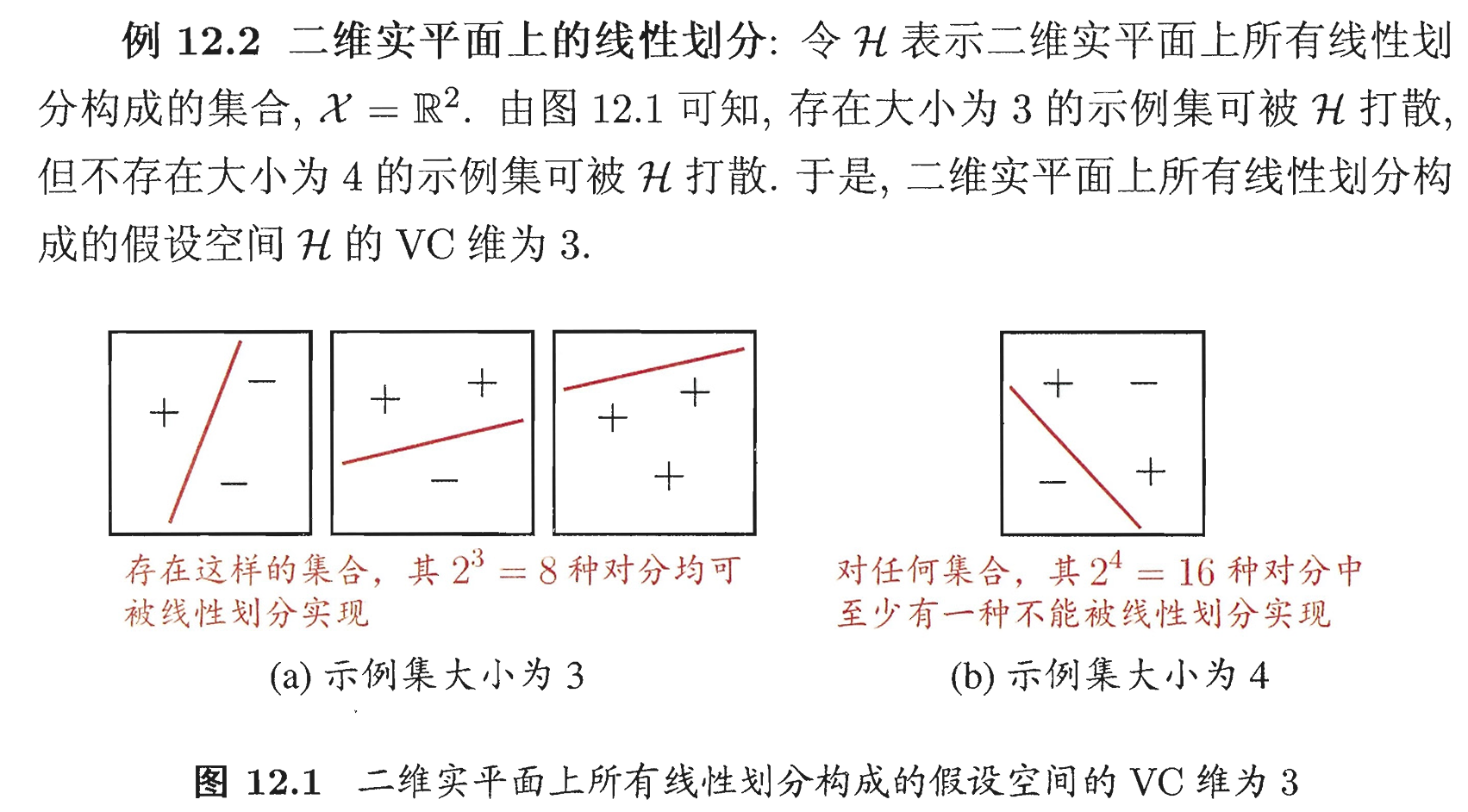
西瓜书读书笔记整理(十二) —— 第十二章 计算学习理论(下)
第十二章 计算学习理论(下) 12.4 VC 维(Vapnik-Chervonenkis dimension)12.4.1 什么是 VC 维12.4.2 增长函数(growth function)、对分(dichotomy)和打散(shattering&…...

初探分布式链路追踪
本篇文章,主要介绍应用如何正确使用日志系统,帮助用户从依赖、输出、清理、问题排查、报警等各方面全面掌握。 可观测性 可观察性不单是一套理论框架,而且并不强制具体的技术规格。其核心在于鼓励团队内化可观察性的理念,并确保由…...
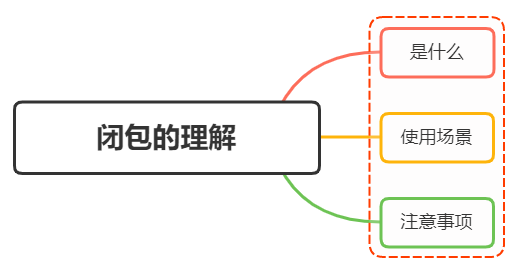
闭包的理解?闭包使用场景
说说你对闭包的理解?闭包使用场景 #一、是什么 一个函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起(或者说函数被引用包围),这样的组合就是闭包(closure&#…...

openssl3.2 - 帮助文档的整理
文章目录 openssl3.2 - 帮助文档的整理概述笔记整理后, 非空的文件夹如下整理后, 留下的有点用的文件列表如下备注END openssl3.2 - 帮助文档的整理 概述 openssl3.2源码工程编译安装完, 对于库的使用者, 有用的文档, 远不止安装的那些html. 用everything查找, 配合手工删除,…...
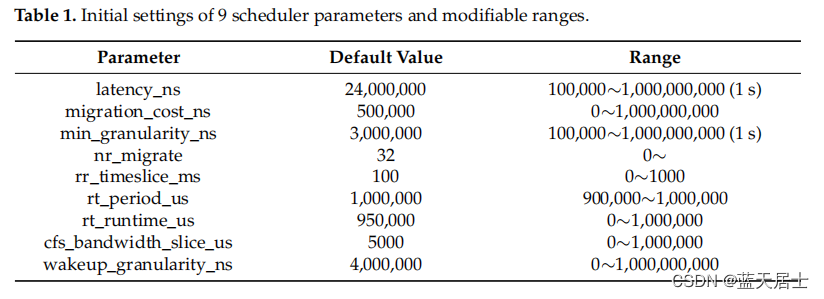
中移(苏州)软件技术有限公司面试问题与解答(5)—— Linux进程调度参数调优是如何通过代码实际完成的1
接前一篇文章:中移(苏州)软件技术有限公司面试问题与解答(0)—— 面试感悟与问题记录 本文对于中移(苏州)软件技术有限公司面试问题中的“(11)Linux进程调度参数调优是如…...

初识C语言·文件操作
目录 1 关于文件 i)文件的基本知识 ii)数据文件的分类 2 文件打开和关闭 i)流和标准流 ii)文件指针 iii)文件打开和关闭 3 文件的顺序读写 i) fgetc fputc ii) fgets fputs iii) fscanf fprintf iv) fwrite fread 4 对比一组函数 scanf/fscanf/sscanf/printf/fpri…...

跨境卖家:如何利用自养号测评抢占市场先机?
在当今的跨境电商领域,产品的销量和评价是影响产品在市场上的表现的关键因素。对于卖家而言,自行养号进行产品测评不仅有助于提升销量,更成为了他们在这个竞争激烈的市场中保持竞争力的必备策略。 相较于一些卖家仍然依赖于服务商进行测评&a…...

开发手札:Github Timeout 22
今天(2024.01.26日),提交github又出现了ssh connect timeout errorcode 22,不论是创建新的sshkey还是配置.ssh/config都没用。 偶然在知乎上看到了解决方案,只需要在host中添加: 140.82.113.4 githu…...

视频融合与空间计算先行者
视频融合与空间计算先行者 镜像视界(浙江)科技有限公司,以SpaceOS™空间操作系统为底座,开创“像素即坐标”的技术范式,是视频融合与空间计算领域的先行者 。 技术创新:全栈自研,定义行业标杆…...

荣耀出征官方下载地址|装备绑定与非绑定决策分析
认准奇迹mu:荣耀出征官方直营官网主站与认证入口体验正版游戏(资质可查,安全合规)《奇迹mu:荣耀出征》是合规申报的移动类型经典复刻怀旧奇迹mu手游,已经在《奇迹mu:荣耀出征》官网主站首发上线。游戏高度还…...

Unity编辑器Play模式状态保存与还原原理详解
1. 这个插件不是“自动存档”,而是 Unity 编辑器生命周期里的状态锚点你有没有在 Unity 编辑器里调试一个带复杂初始化逻辑的 MonoBehaviour,刚把 Inspector 里十几个字段调到理想值、挂好引用、连好事件,一按 Play,对象瞬间变空—…...

5分钟彻底掌握Windows驱动管理:DriverStore Explorer完全指南
5分钟彻底掌握Windows驱动管理:DriverStore Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现Windows系统盘空间持续减少,却找不到原因…...

Windows右键菜单终极清理指南:用ContextMenuManager告别杂乱,重获高效桌面
Windows右键菜单终极清理指南:用ContextMenuManager告别杂乱,重获高效桌面 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 还在为Windows…...

Ryujinx模拟器完整指南:在PC上免费畅玩Switch游戏的终极解决方案
Ryujinx模拟器完整指南:在PC上免费畅玩Switch游戏的终极解决方案 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 你是否曾经梦想在电脑上体验《塞尔达传说:王国…...

Tina Linux嵌入式开发实战:从系统架构到应用移植全解析
1. 项目概述如果你正在接触全志科技的Tina Linux平台,无论是作为软件开发工程师还是技术支持,面对一个全新的嵌入式Linux SDK,最头疼的莫过于如何快速上手,理清从环境搭建到系统定制的整个脉络。这份指南就是为你准备的。Tina Lin…...

不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变
不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变 💡 每次做 PPT 都在 Powerpoint 里拖来拖去,最后做出来还是那个味儿?Frontend Slides 让…...

岩土工程渗流问题之有限单元法--坝基渗流、围堰、土石坝自由面、黏土垫层防渗、污染土固化后渗控
第一天 有限元编程基础知识1.有限单元法基础简介(离散化、存储策略及方程解法、边界条件的处理)2.编程语言Fortran及编译工具Intel Visual Fortran(IVF)简介3.Fortran/Matlab/Julia等开源代码及程序库(geomlib/femlib)简介4.水工…...

NoFences:Windows桌面整理终极指南,5分钟打造高效工作空间
NoFences:Windows桌面整理终极指南,5分钟打造高效工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都要在混乱的Windows桌面上花费大…...