神经网络的一些常规概念
epoch:是指所有样本数据在神经网络训练一次(单次epoch=(全部训练样本/batchsize)/iteration=1)或者(1个epoch=iteration数 × batchsize数)
batch-size:顾名思义就是批次大小,也就是一次训练选取的样本个数
iteration:1个iteration=1个正向通过+1个反向通过=使用batchsize个样本训练一次。
注意:每一次迭代得到的结果都会被作为下一次迭代的初始值。
在人工神经网络中,权重是相邻两层神经元之间的连接强度。权重的更新是通过反向传播算法实现的,主要步骤如下:
- 前向传播:输入数据从输入层向前传播,在各层被激活并加权,得到输出值。
- 计算损失:使用损失函数计算输出值和真实标签之间的差距,得到总体损失。
- 求导:使用链式法则计算损失相对于各层权重的偏导数。
- 权重更新:使用梯度下降法则更新各层权重,使损失最小化。
梯度下降法的概念:
梯度下降法的基本思想是通过不断迭代,找到函数的最小值点,从而得到最优的模型参数。在梯度下降法中,我们首先需要定义一个损失函数,该函数表示了模型的预测结果与实际结果之间的差距。然后,我们初始化一组模型参数,并计算损失函数关于这些参数的梯度,即损失函数在参数空间中的斜率。接着,我们沿着负梯度方向移动一定的步长,更新模型参数,直到损失函数的值收敛或达到预定的迭代次数。
下面介绍几种常见的梯度下降算法优化方法。
1. 批量梯度下降算法(Batch Gradient Descent)
批量梯度下降算法是最基本的梯度下降算法,它在每次迭代中使用所有的样本来计算梯度。虽然批量梯度下降算法的收敛速度比较慢,但是它的收敛结果比较稳定,因此在小数据集上表现良好。
2. 随机梯度下降算法(Stochastic Gradient Descent)
随机梯度下降算法是一种每次只使用一个样本来计算梯度的算法,因此它的收敛速度比批量梯度下降算法快很多。但是,由于它只使用一个样本来计算梯度,所以收敛结果可能会受到噪声的影响,因此它的收敛结果不够稳定。
3. 小批量梯度下降算法(Mini-Batch Gradient Descent)
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的一种算法。它在每次迭代中使用一部分样本来计算梯度,通常选择的样本数是几十或几百。小批量梯度下降算法的收敛速度比批量梯度下降算法快,而且比随机梯度下降算法更稳定。
4. 动量梯度下降算法(Momentum Gradient Descent)
动量梯度下降算法是一种基于动量的优化算法,它的核心思想是在更新参数的时候,将上一次的梯度方向加入到本次梯度方向中,从而加速收敛。动量梯度下降算法通常可以减少梯度震荡,从而加速收敛。
5. 自适应学习率梯度下降算法(Adaptive Learning Rate Gradient Descent)
自适应学习率梯度下降算法是一种自适应学习率的优化算法,它的核心思想是根据梯度的大小来调整学习率,从而提高算法的效率和稳定性。常见的自适应学习率梯度下降算法有Adagrad、Adadelta和Adam等。
在深度学习中,一般采用SGD训练(随机梯度下降),即每次训练在训练集中取batchsize个样本训练;
(1)经验总结:Batch_Size的正确选择是为了在内存效率和内存容量之间寻找最佳平衡
相对于正常数据集,如果Batch_Size过小,训练数据就会非常难收敛,从而导underfitting。增大Batch_Size,相对处理速度加快。但是,增大Batch_Size,所需内存容量增加(epoch的次数需要增加以达到最好的结果)这就出现了矛盾。——因为当epoch增加以后,同样也会导致耗时增加从而速度下降。因此我们需要寻找最好的Batch_Size。
(2)适当的增加Batch_Size的优点:
1.通过并行化提高内存利用率。
2.单次epoch的迭代次数减少,提高运行速度。
3.适当的增加Batch_Size,梯度下降方向准确度增加,训练震动的幅度减小。
为什么我们必须要使用梯度下降法?
参考:一文全解梯度下降法_已知两组样本梯度下降-CSDN博客
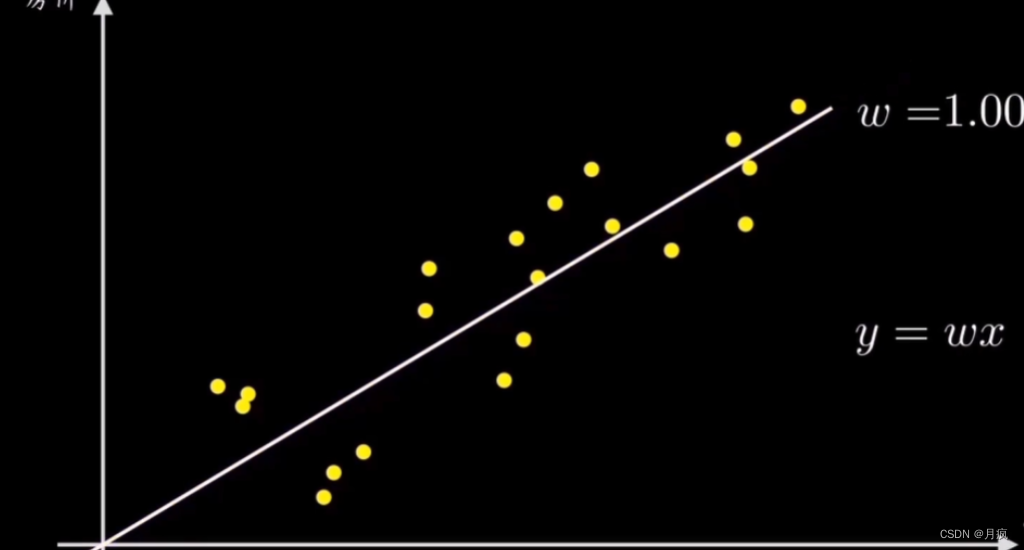
以线性回归问题为例说明这个流程:
过原点的直线 y=wx 就相当于线性回归问题中用于做预测的函数,y是房价,x是面积,每个样本代表不同面积的具体房价机器的任务就是想办法计算出一条最好的直线来拟合这些样本点数据,而直线的斜率w就可以简单控制直线,所以我们的目的是要求解出最能拟合数据分布的变量w
为了方便求解出最优参数w,我们引入了与这条直线相关的损失函数
我们通过预测函数和误差公式推导出损失函数,成功的将直线拟合样本点的过程映射到了一个损失函数上,并且它是个开口向上的抛物线图像,它是以参数w为自变量、误差或者损失值作为因变量的,见下图中的右侧图
因为我们的目标是拟合出最接近这些数据分布的直线,也就是找到使得误差代价最小的参数w,对应在右图的损失函数图像上就是它的最低点,这个不断寻找最低点的过程就是梯度下降要干的活。
我们先随机选取一个参数起始点,对应到曲线上的某个误差值,然后不断的沿着损失函数曲线陡峭程度最大的方向前进,就能更快更准的找到误差的最低点。
这个陡峭程度就是梯度,它是损失函数的导数,对于抛物线而言就是曲线的斜率
另外,因为梯度的方向是损失函数值增加最快的方向,负梯度是损失函数值下降最快的方向,所以我们其实是沿着梯度的反方向前往最低点。这就是为何叫梯度下降的原因
确定了损失函数值的下降方向以后,还需要考虑前进的步长,即学习率
学习率是步长超参数,人为选择,选择学习率时,步子太大即选择数值太大会反复横跳,步子太小会走得很慢浪费计算上面我们是用线性回归做预测函数的,实际情况中房价不仅与面积,还与城市、地段、政策等相关,那么预测函数就会是非线性甚至是曲面多维的各种复杂函数,对应的损失函数也可能是更复杂的,如
上面说了梯度下降的原理,但是实际我们很少直接使用梯度下降,因为我们每次计算梯度时要对每个损失函数求导,这个损失函数是对所有训练样本的平均损失,意味着每次计算梯度都要计算一遍所有样本,花费的时间成本太大了。现在深度学习默认使用的是小批量随机梯度下降方法来训练模型得到最优参数
另外,小批量batchsize也是个超参数, 它选择越小,对收敛越好,即模型拟合数据的越好;对了,上述那个例子中的直线或者说预测函数 y=wx 就可以看作是简单的预测模型,所以才总说训练模型的参数嘛
batchsize选择越小,产生的噪音越多,噪音对神经网络是有一定好处的,深度神经网络太复杂了,一定的噪音可以避免网络模型在训练的时候不会走偏;也就是说模型对各种噪音的容忍度越好,则模型的泛化性就越好,泛化性越好就能让模型更好预测其他新数据
当然,选择太小也不行,会浪费计算,时间成本高啊;batchsize选择太大会虽然导致收敛问题,但只要不是特别大,最后多花点时间还是能收敛的。小批量随机梯度下降中的‘随机’是随机采样的意思,批量大小都是提前定义好的;假如batchsize是128,那么随机从所有样本中采样128个读进内存用于训练



常用的激活函数:
(1)sigmoid
(2)tanh
(3)ReLU
(4)Leaky ReLU
(5)softmax
优化函数:
optimizer = keras.optimizer.SGD(lr=0.001, momentum=0.9)
动量优化
optimizer = keras.optimizer.SGD(lr=0.001, momentum=0.9, nesterov=True)
optimizer = keras.optimizer.RMSprop(lr=0.001, rho=0.9)
RMSProp算法通过只是累加最近迭代中的梯度(而不是自训练开始以来的所有梯度)
optimizer = keras.optimizer.Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
Adam代表自适应钜估计,结合了动量优化和RMSProp的思想:就像动量优化一样,它跟踪过去梯度的指数衰减平均值;想RMSProp一样,它跟踪过去平方梯度的指数衰减平均值。
相关文章:
神经网络的一些常规概念
epoch:是指所有样本数据在神经网络训练一次(单次epoch(全部训练样本/batchsize)/iteration1)或者(1个epochiteration数 batchsize数) batch-size:顾名思义就是批次大小,也就是一次训练选取的样…...
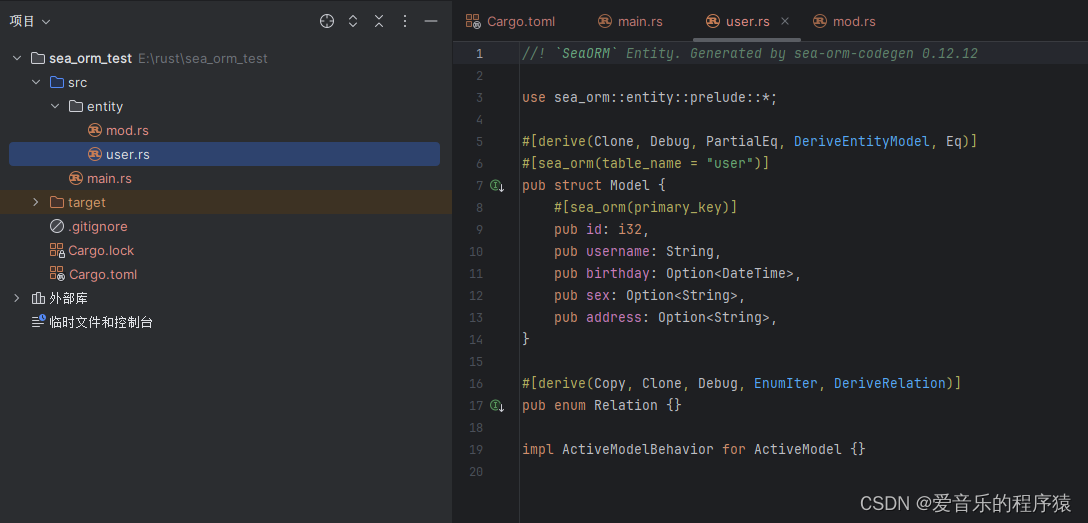
【从零开始的rust web开发之路 三】orm框架sea-orm入门使用教程
【从零开始的rust web开发之路 三】orm框架sea-orm入门使用教程 文章目录 前言一、引入依赖二、创建数据库连接简单链接连接选项开启日志调试 三、生成实体安装sea-orm-cli创建数据库表使用sea-orm-cli命令生成实体文件代码 四、增删改查实现新增数据主键查找条件查找查找用户名…...

SQL中limit的用法
在SQL中,LIMIT是一个用于限制返回结果行数的关键词。它可用于在查询结果中指定返回的行数,从而可以用于分页查询或限制结果集大小。 LIMIT关键词有两种常用的语法格式: LIMIT offset, count:该语法用于指定返回结果的起始位置和…...
vue3 [Vue warn]: Unhandled error during execution of scheduler flush
文章目录 前言一、报错截图二、排除问题思路相关问题 Vue3 优雅解决方法异步组件异同之处:好处:在使用异步组件时,有几个注意点: vue3 定义与使用异步组件 总结 前言 Bug 记录。开发环境运行正常,构建后时不时触发下面…...

【vue2源码】阶段一:Vue 初始化
文章目录 一、项目目录1、主目录2、打包入口 二、构造函数Vue的初始化1、创建 Vue 构造函数2、初始化内容分析2.1 initMixin2.2 stateMixin2.3 eventsMixin2.4 lifecycleMixin2.5 renderMixin 一、项目目录 源码版本:2.7.16 1、主目录 src |-- compiler # 包…...
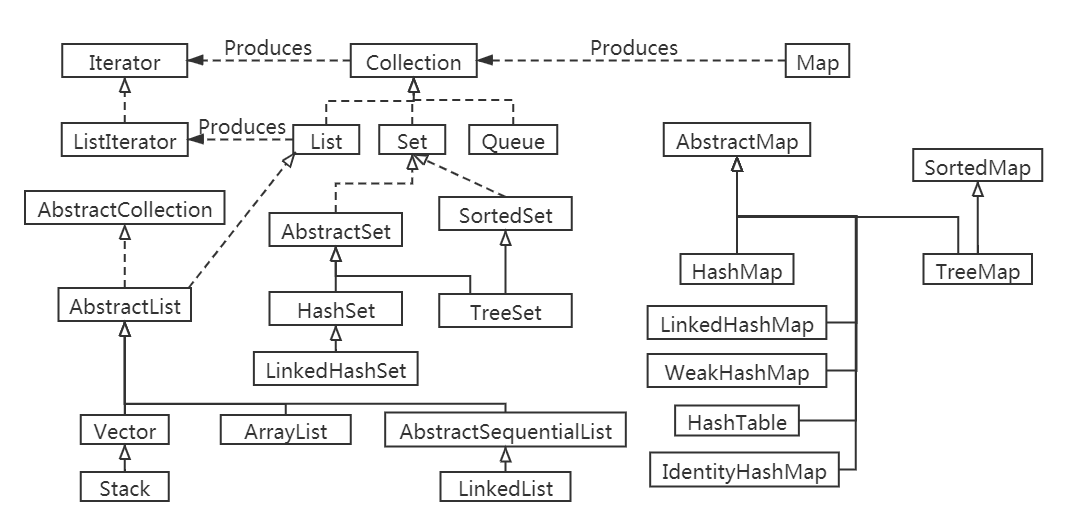
14.java集合
文章目录 概念Collection 接口概念示例 Iterator 迭代器基本操作:并发修改异常增强循环遍历数组:遍历集合:遍历字符串:限制 list接口ListIteratorArrayList创建 ArrayList:添加元素:获取元素:修…...
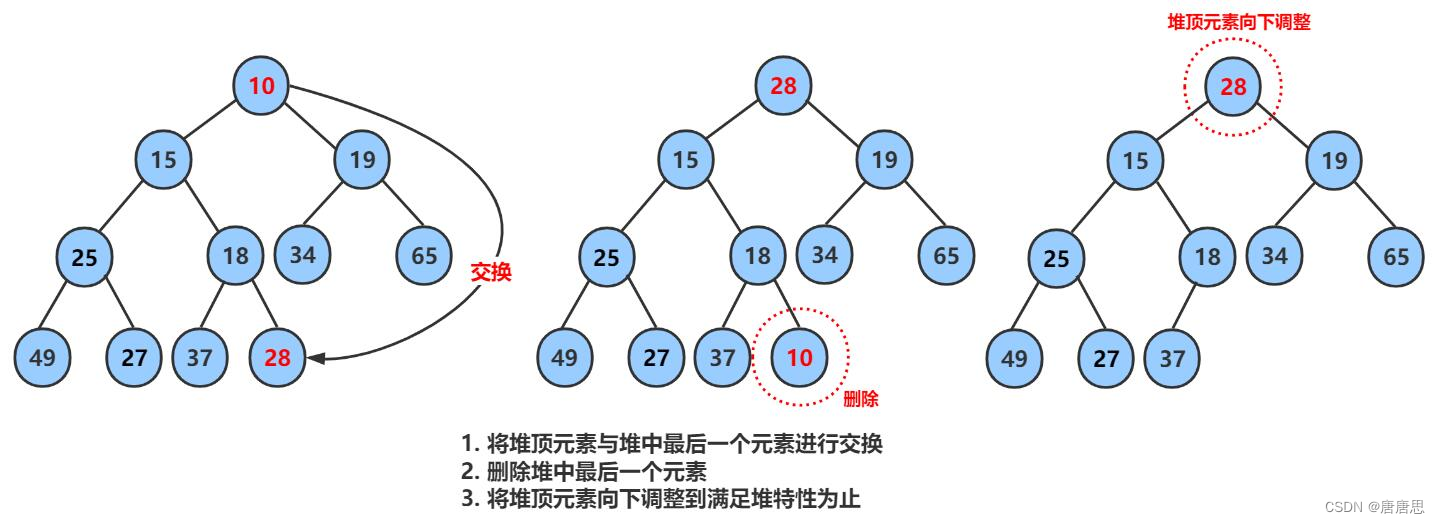
二叉树顺序结构堆实现
目录 Test.c测试代码 test1 test2 test3 🎇Test.c总代码 Heap.h头文件&函数声明 头文件 函数声明 🎇Heap.h总代码 Heap.c函数实现 ☁HeapInit初始化 ☁HeapDestroy销毁 ☁HeapPush插入数据 【1】插入数据 【2】向上调整Adjustup❗ …...

正则表达式 与文本三剑客(sed grep awk)
一,正则表达式 (一)正则表达式相关定义 1,正则表达式含义 REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意…...
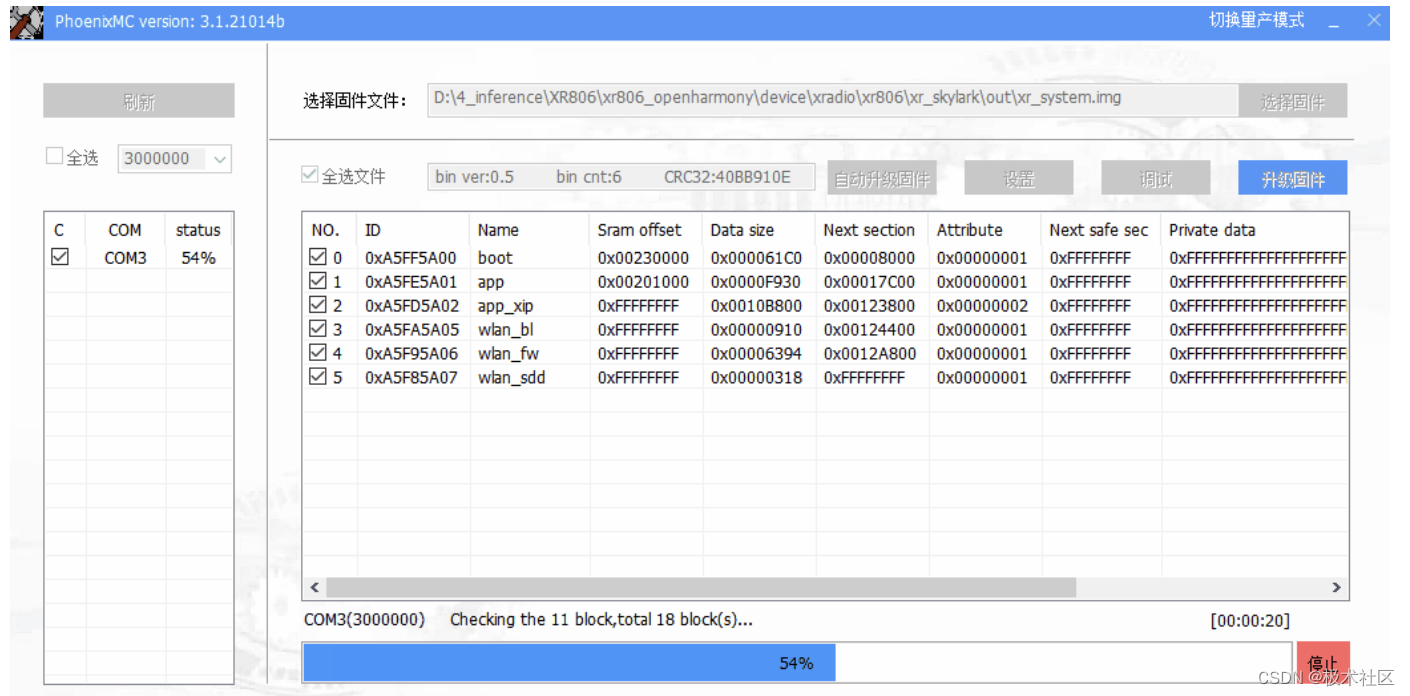
【XR806开发板试用】全志 XR806 OpenHarmony 鸿蒙系统固件烧录
大家好,我是极智视界,本教程详细记录了全志 XR806 OpenHarmony 鸿蒙系统固件烧录的方法。 在上一篇文章《【嵌入式AI】全志 XR806 OpenHarmony 鸿蒙系统固件编译》中咱们已经编译生成了系统镜像,这里把这个编译出来的镜像烧录到 XR806 板子里…...
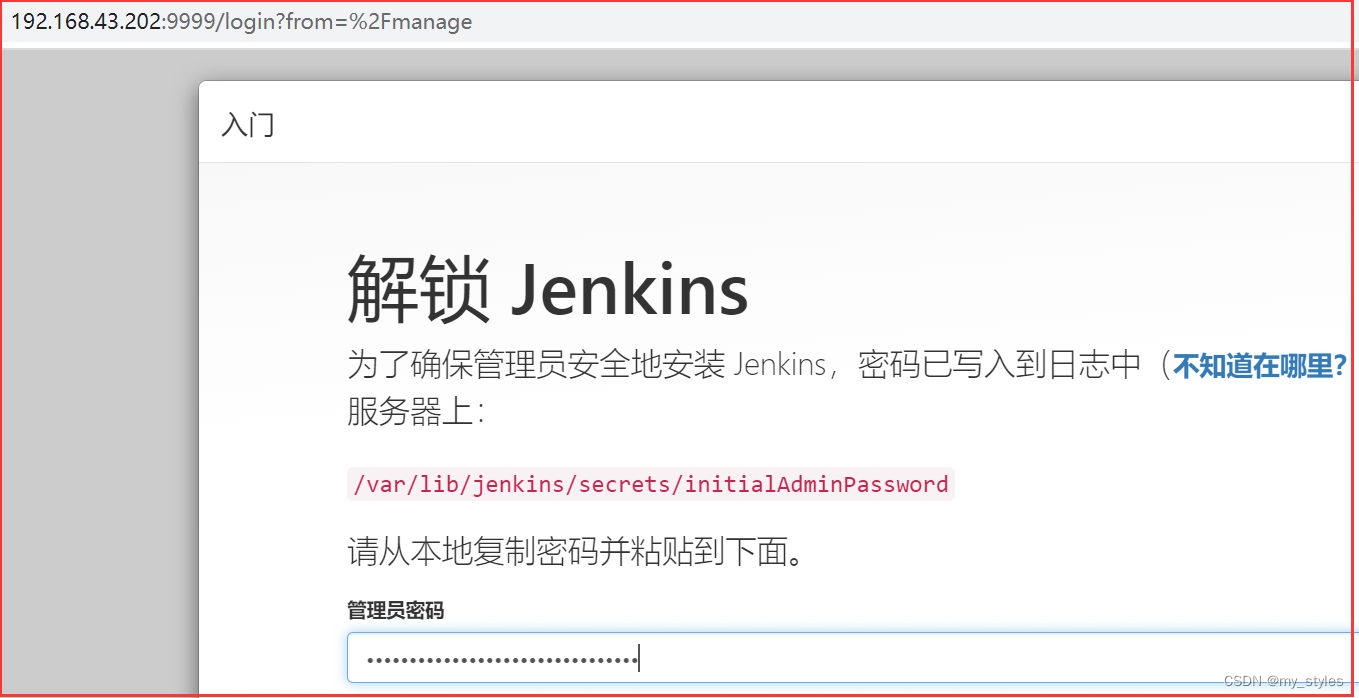
linux环境安装git、maven、jenkins等
重启 jenkins的命令: systemctl start jenkins 如果没有vim 命令 可以使用 yum install vim 安装 vim git 下载包地址 https://www.kernel.org/pub/software/scm/git/git-2.28.0.tar.gz 1.安装依赖环境: yum install -y curl-devel expat-devel ge…...

RabbitMQ快速上手
首先他的需求实在什么地方。我美哟明显的感受到。 它给我的最大感受就是脱裤子放屁——多此一举,的感觉。 他将信息发送给服务端中间件。在由MQ服务器发送消息。 服务器会监听消息。 但是它不仅仅局限于削峰填谷和稳定发送信息的功能,它还有其他重要…...

SpringBoot activemq收发消息、配置及原理
SpringBoot集成消息处理框架 Spring framework提供了对JMS和AMQP消息框架的无缝集成,为Spring项目使用消息处理框架提供了极大的便利。 与Spring framework相比,Spring Boot更近了一步,通过auto-configuration机制实现了对jms及amqp主流框架…...

视频智能识别安全帽佩戴系统-工地安全帽佩戴识别算法---豌豆云
视频智能识别安全帽佩戴系统能够从繁杂的工地、煤矿、车间等场景下同时对多个目标是否戴安全帽穿反光衣进行实时识别。 当视频智能识别安全帽佩戴系统发现作业人员没有戴安全帽、穿反光衣或者戴安全带,系统会及时报警提醒,并抓拍存档。 视频智能识别安…...
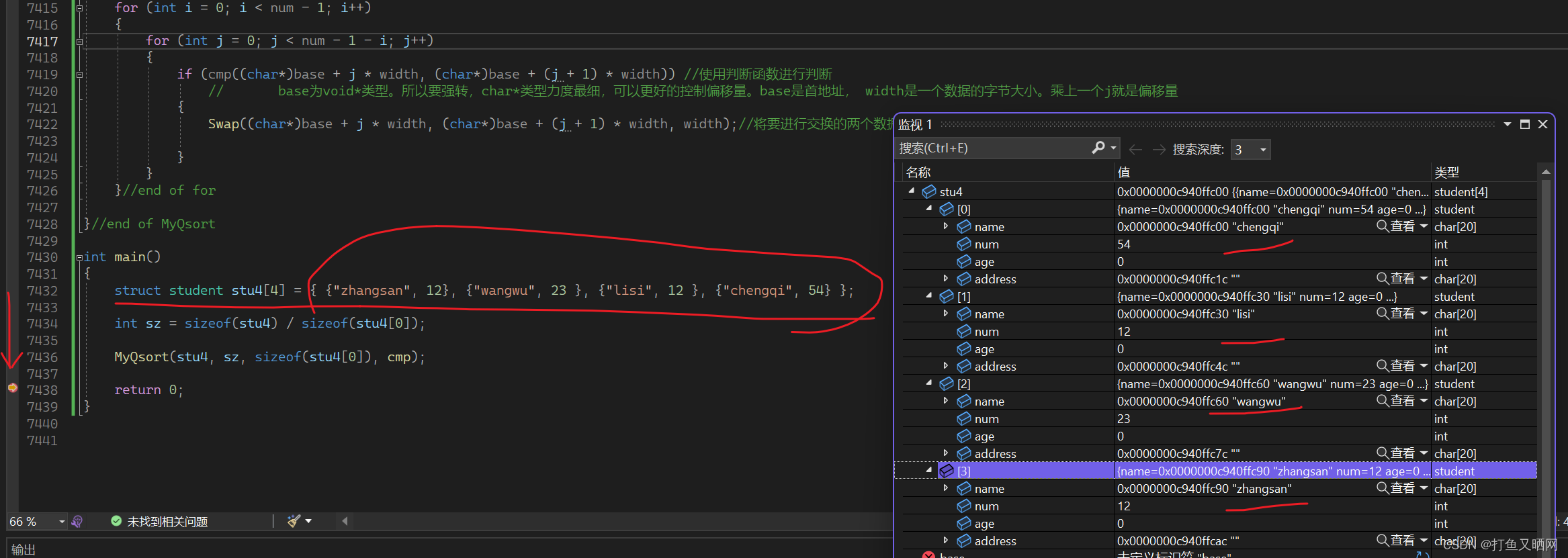
指针的深入理解(三)
这一节主要使用复习回调函数, 利用冒泡模拟实现qsort函数。 qsort 排序使用冒泡排序,主要难点在于运用元素个数和字节数以及基地址控制元素的比较: if里面使用了一个判断函数,qsort可以排序任意的数据,原因就是因为可…...

【Linux C | 网络编程】详细介绍 “三次握手(建立连接)、四次挥手(终止连接)、TCP状态”
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
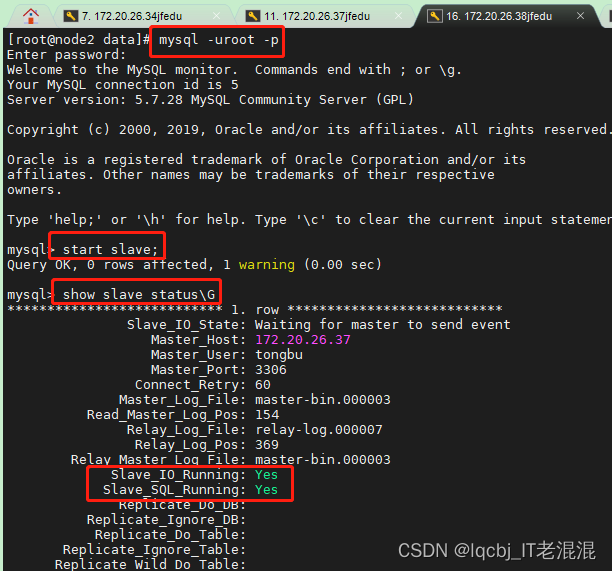
主从数据库MySQL服务重启步骤与注意事项
主从数据库MySQL服务重启步骤与注意事项 实验环境: 172.20.26.34 (主应用服务器) 172.20.26.26 (备应用服务器) 172.20.26.37 (主库服务器) 172.20.26.38 (从库服务器&…...

netlink学习
netlink是什么 netlink是Linux内核中的一种进程间通信(IPC)机制。它允许内核空间与用户空间之间,以及用户空间进程之间进行双向通信。 内核里的很多子系统使用netlink通信,包括网络管理(Routing,Netfilt…...

地理空间分析10——空间数据分析中的地理编码与Python
目录 写在开头1. 地理编码基础1.1 地理编码的基本原理1.1.1 坐标系统1.1.2 地名解析1.1.3 编码算法1.2 Python中使用地理编码的基础知识1.2.1 百度地图API1.2.2 高德地图API1.2.3 腾讯地图API1.3 Python中实现代码2. 逆地理编码2.1 利用Python进行逆地理编码2.1.1 获取高德地图…...

使用“快速开始”将数据传输到新的 iPhone 或 iPad
使用“快速开始”将数据传输到新的 iPhone 或 iPad 使用 iPhone 或 iPad 自动设置你的新 iOS 设备。 使用“快速开始”的过程会同时占用两台设备,因此请务必选择在几分钟内都不需要使用当前设备的时候进行设置。 确保你当前的设备已连接到无线局域网,并…...
复习提纲13)
计算机网络(第六版)复习提纲13
前同步码,七位1010交替出现,帧开始码:10101011 为什么没有帧结束?曼彻斯特码传播完成后,维持高电平,不再跳变,因此不必要设置帧结束。 3.无效的MAC帧 i.数据字段的长度与长度字段的值不一致&…...
)
RMAN 增量备份(Incremental Backup)
1、概念RMAN 增量备份是指 RMAN 只备份自上次备份以来发生过更改的数据块,而不是备份整个数据库的所有数据块。它是 Oracle 为解决大型数据库全量备份时间长、占用空间大的问题而设计的核心特性,也是现代企业级备份策略的基础。简单类比:全库…...

【收藏 2026 版】程序员零基础转 AI 应用赛道!不用深耕算法训练,靠现有编程功底轻松转行
当下 AI 技术全面普及,传统开发岗位竞争日趋激烈,不少程序员都想顺势切入人工智能领域。很多人觉得入行 AI 就得钻研复杂算法、上手大模型训练,门槛高到难以触碰。实则 2026 年 AI 应用开发门槛大幅降低,拥有基础编程能力…...
)
告别报错!手把手教你用Pycharm 2023.2 + Git搞定Manim社区版安装(附国内镜像源配置)
Manim社区版极速安装指南:PyCharm 2023.2与Git的完美协作方案 当数学可视化遇上Python开发神器PyCharm,Manim社区版的安装过程却常常成为新手的第一道门槛。不同于常规教程的线性步骤,我们将以"问题-解决"为主线,直击两…...

【 linux 】理解进程状态
目录 1.僵尸进程与孤儿进程 1.1 孤儿进程 1.2 僵尸进程(Z) 2.进程状态 3.进程退出与进程等待 3.1 进程退出 3.2 进程等待 3.2.1 wait和waitpid对比 3.3 WEXITSTATUS 和 WIFEXITED 1.僵尸进程与孤儿进程 1.1 孤儿进程 父进程结束了子进程还没有…...

Linux操作系统安装图文配置教程详细版
随着嵌入式的发展,Linux的知识是必须的一部分,下面就让我们进行Linux系统的安装过程演示:一、 Linux的安装在此博客中以红旗(Red Flag)Asianux Workstation 3为例进行描述,其他版本的Linux与此相似。 1.1 安…...

抖音小店搜索排名规则及优化方法
一、抖音商城搜索排名规则1.商品相关性:商品标题、关键词与用户搜索词的匹配程度是重要因素。精准匹配的商品会在搜索结果中更靠前展示。例如,用户搜索"夏季连衣裙”,标题中明确包含该关键词且商品属性也相符的连衣裙,会优先被展示。商品…...

电商预测性洞察:轻量模型实现秒级可执行决策
1. 项目概述:这不是“预测未来”,而是让电商决策从拍脑袋变成算出来“Predictive Insights for e-Commerce”——这个标题乍看像一句科技公司PPT里的漂亮话,但在我过去十年跑遍长三角、珠三角上百个中小电商品牌仓库、直播间和运营后台后&…...

DeepSeek / Qwen 大模型在昇腾上的推理优化实战
前言 把DeepSeek-V3和Qwen2.5-72B部署到昇腾910B集群上。客户说"GPU上跑得好好的,换昇腾应该也行吧"。结果第一天就被砸懵——同样的模型、同样的batch,昇腾上吞吐只有GPU的60%。不是算力不够,是我根本没搞清楚CANN的优化逻辑和CUD…...

如何用歌词滚动姬3分钟制作专业级LRC歌词:免费跨平台终极指南
如何用歌词滚动姬3分钟制作专业级LRC歌词:免费跨平台终极指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬是一款专为音乐爱好者设计的免费…...

免费AI搜索工具推荐2026,92%用户不知道的3个隐藏权限设置——关闭行为追踪、锁定模型版本、强制HTTPS直连
更多请点击: https://kaifayun.com 第一章:免费AI搜索工具推荐2026 2026年,开源与社区驱动的AI搜索工具生态迎来爆发式增长。得益于大语言模型轻量化部署、RAG(检索增强生成)架构普及,以及WebAssembly对客…...