大模型运行成本对比:GPT-3.5/4 vs. 开源托管
在过去的几个月里,生成式人工智能领域出现了许多令人兴奋的新进展。 ChatGPT 于 2022 年底发布,席卷了人工智能世界。 作为回应,各行业开始研究大型语言模型以及如何将其纳入其业务中。 然而,在医疗保健、金融和法律行业等敏感应用中,ChatGPT 等公共 API 的隐私一直是一个问题。
然而,最近 Falcon 和 LLaMA 等开源模型的创新使得从开源模型中获得类似 ChatGPT 的质量成为可能。 这些模型的好处是,与 ChatGPT 或 GPT-4 不同,模型权重适用于大多数商业用例。 通过在定制云提供商或本地基础设施上部署这些模型,隐私问题得到缓解——这意味着大型行业现在可以开始认真考虑将生成式人工智能的奇迹融入到他们的产品中!
那么让我们深入了解各种大型语言模型 (LLM) 的经济学!

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包
1、GPT-3.5/4 API 成本
ChatGPT API 按使用情况定价,1K 代币的费用为 0.002 美元。 每个令牌大约是一个单词的四分之三,单个请求中的令牌数量是提示 + 生成的输出令牌的总和。 假设您每天处理 1000 个小块文本,每个块都是一页文本,即 500 个单词或 667 个标记,并且输出的长度也是相同的长度(作为上限)。 这相当于每天 0.002 美元/1000x66721000= ~2.6 美元。 一点也不差!
但是,如果您每天处理一百万个此类文档,会发生什么情况? 那么每天就是 2,600 美元,或者每年大约 100 万美元! ChatGPT 从一个很酷的玩具变成了一项价值数百万美元的业务的一项主要开支(因此人们希望它是一项主要收入来源)!
OpenAI 还有其他更强大的模型,例如 ChatGPT 的 16K 上下文版本或更强大的 GPT-4 模型。 这里更大的上下文仅意味着您可以向法学硕士发送更多上下文,并要求其在较长的文档上完成诸如回答问题之类的任务。 以下是基于各种 OpenAI 模型的每天 1K 与 1M 请求的成本:

基于使用情况和 OpenAI 模型的年度成本
如您所见,低使用率的年成本从 1000 美元到 50000 美元不等,具体取决于型号。 或者对于高使用率,每年 100 万美元至 5600 万美元! 对于较低的使用率——我们认为 OpenAI API 模型是有意义的,因为它们的质量和成本效益。
但是,如果您的使用量超过 100 万美元,则即使您确实有多余的钱作为额外的零钱,您也需要认真考虑经济可行性。 有意义的是,如果你手边有多余的零钱,并且看到了LLM在你所在行业的价值,那就是将这些钱花在让你的组织发展成为特定领域LLM的行业领导者上,而不是花钱 纯粹是为了沉没成本。 相反,您可以使用它来自定义现有的开源模型,根据行业特定的数据对其进行微调,从而使您更具竞争力。
处理针对极长或大量文档提出问题的另一种方法是使用检索增强生成 (RAG)(请参阅这篇 Medium 文章)——这基本上相当于将数据存储在矢量数据库中的小块中——并使用矢量相似性 用于检索更有可能包含与您的需求相关的信息的文档块的指标。
另一种可能性是将钱花在 OpenAI API 成本上,但在如何处理 RAG 以及文档与 LLM 之间的复杂接口方面使自己成为创新者,例如这篇文章。
2、开源模型托管成本
如果您决定托管大型语言模型 - 主要成本与托管这些资源密集型 LLM 和每小时成本相关。 根据经验,在 GPU 内存中存储推理所需的 1B 参数 — 32 位浮点精度时需要 4 GB,16 位精度时需要 2 GB。 默认情况下,模型权重以较高的 32 位精度存储,但也有一些技术可以以 16 位(甚至 8 位)精度存储权重,从而将响应质量的损失降至最低。

GPU RAM 成本
因此,对于像 Falcon-7B 或 LLaMA2–7B 这样 16 位精度的 70 亿参数模型,这意味着您需要 14GB 的 GPU RAM。 它们适用于具有 16GB GPU 内存的 NVIDIA T4 GPU。 您可以看到 AWS 等典型云服务提供商的定价如下 - g4 实例均具有单个 T4 GPU,而 12X Large 则具有 4 个 GPU。 基本上,如果您想部署 7B 参数模型,则成本约为 2–3 美元/小时。 正如本博客中提到的 - 存在与发出的请求数量相关的成本,但这些成本通常低于端点成本。 粗略地说,1000 个请求的成本为 0.01 美元,100 万个请求的成本为 10 美元。

Machine Learning Service – Amazon SageMaker Pricing – AWS
较大的开源模型(如 Vicuna-33B 或 LLaMA-2-70b)比较小的模型表现更好 - 因此您可能会考虑部署这些较大的模型。 然而,为了拥有所需的 100-200 GB GPU 内存,这些技术更加昂贵,需要多个 GPU,并且成本约为 20 美元/小时。

https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
以下是更新后的成本,比较了开源模型和 OpenAI GPT 系列模型:

基于使用情况和 OpenAI/云托管模型的年度成本
值得注意的是,虽然上述成本用于内存和计算,但还需要考虑其他与云相关的基础设施的维护,以满足每秒/分钟的网络流量/请求。 其一,您可能需要多个带有负载均衡器的 GPU,以确保即使在大负载期间也能保持低延迟。 您可能需要根据您的使用案例考虑与可用性、减少停机时间、维护和监控相关的额外成本。
3、本地托管成本
本地托管是您希望完全隔离模型并在专用服务器上运行的地方。 为此,您需要购买 NVIDIA A10 或 A100 等高质量 GPU。 目前这些芯片短缺,A10(24GB GPU 内存)售价 3,000 美元,而 A100(40 GB 内存)售价 10-20,000 美元。
然而,有些公司提供像 Lambda Labs 这样的预构建产品,如下所示:
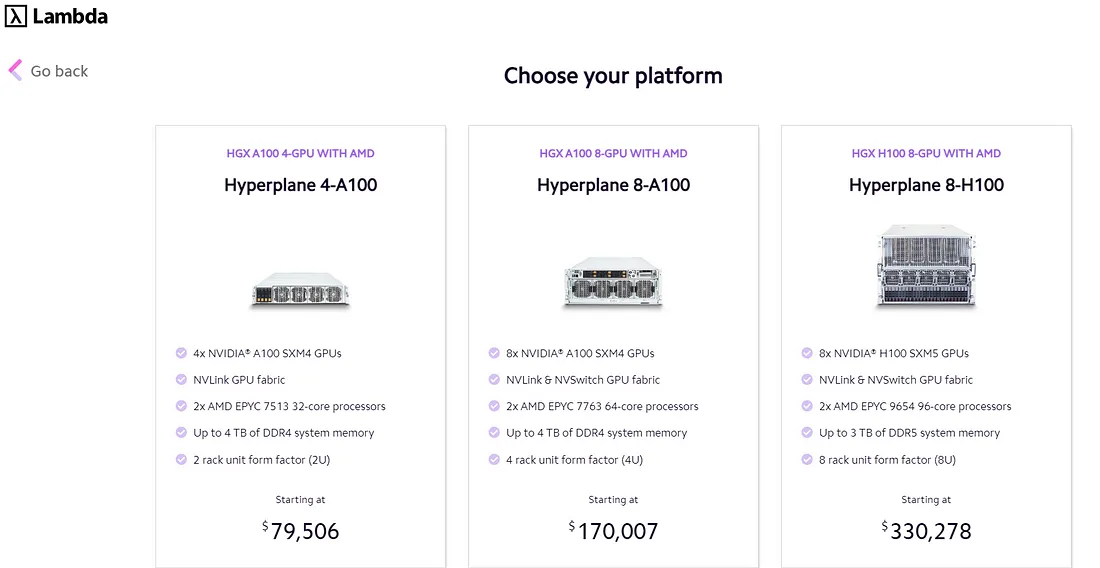
Lambda Labs NVIDIA GPU成本
与云托管模型中相同的延迟、可用性、维护和监控考虑因素也适用于本地托管。 但其中一个区别是,如果您希望在收到更多流量时开始扩展,那么使用云托管提供商意味着您可以虚拟地增加资源(当然要支付更多费用),但您无法在 - 场所,除非您实际购买更多基础设施,当然您现在负责正确设置一切以及维护。
4、结束语
我们已经介绍了 3 种不同的选项来提高部署 LLM 的难度:使用 ChatGPT 等封闭式 LLM API、在私有云实例上托管以及本地托管。 如果您很高兴尝试 LLM,但才刚刚开始探索,我们建议您首先尝试使用 ChatGPT/GPT-4。 一旦您确定LLM是您的出路,您就可以探索其他选择 - 如果您有隐私问题,或者希望在短时间内为数百万客户提供服务,这可能更有意义 - 对于 ChatGPT,尤其是 GPT- 4个都挺贵的。 或者您可能想要开发一个超专业的行业特定的LLM,托管是第一步,之后您需要根据自定义数据微调模型。
我们还没有讨论的最后一个选择是LLM服务提供商,他们可以帮助公司找出在云/本地堆栈上运行的模型。 例如,Snowflake 推出了使用自定义数据训练LLM的服务。 Databricks 提供了类似的解决方案。
原文链接:大模型经济学 - BimAnt
相关文章:
大模型运行成本对比:GPT-3.5/4 vs. 开源托管
在过去的几个月里,生成式人工智能领域出现了许多令人兴奋的新进展。 ChatGPT 于 2022 年底发布,席卷了人工智能世界。 作为回应,各行业开始研究大型语言模型以及如何将其纳入其业务中。 然而,在医疗保健、金融和法律行业等敏感应用…...
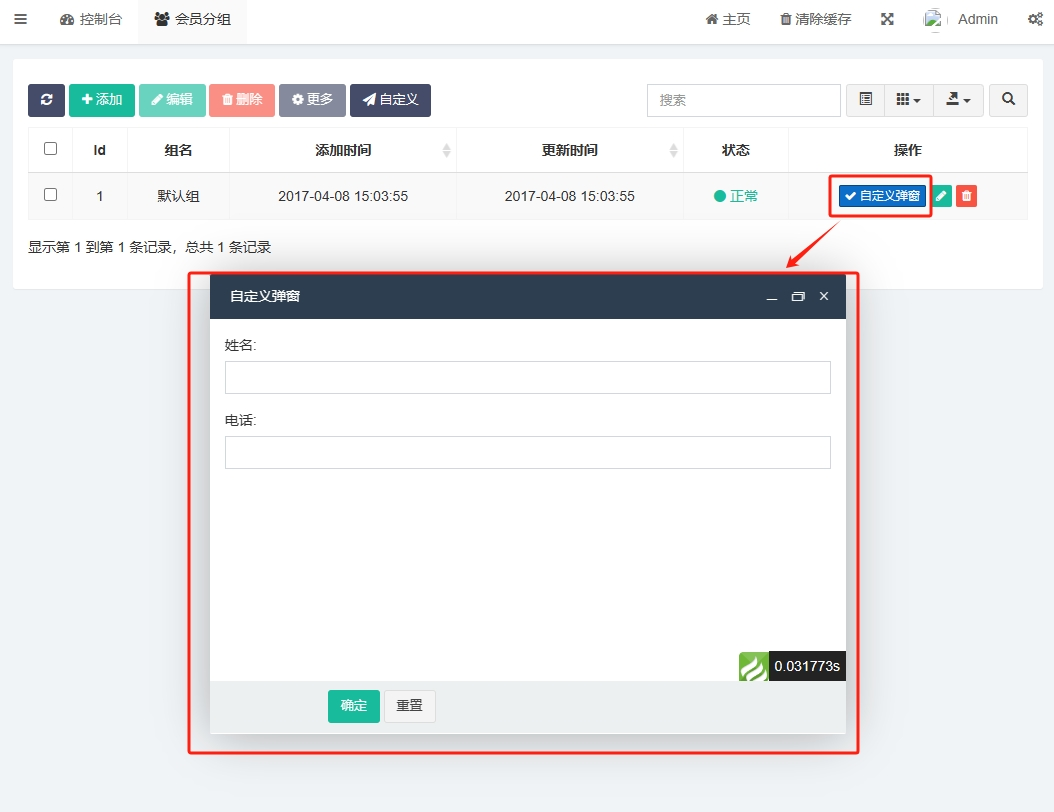
fastadmin后台自定义按钮和弹窗
工具栏自定义按钮-ajax请求 前端代码 1.在对应模块的模板文件index.html添加自定义按钮,注意按钮要添加id以绑定点击事件 <div class"panel panel-default panel-intro">{:build_heading()}<div class"panel-body"><div id&qu…...

《高性能MySQL》
文章目录 一、创建1. 磁盘1.1 页、扇区、寻道、寻址、硬盘性能 2. 行结构row_format2.1 Compact紧凑2.1.1 行溢出2.1.2 作用2.1.3 内容1-额外信息1、变长字段长度2、NULL值列表3、记录头信息 2.1.4 内容2-真实数据4、表中列的值5、transaction_id6、roll_point7、row_id 2.2 dy…...
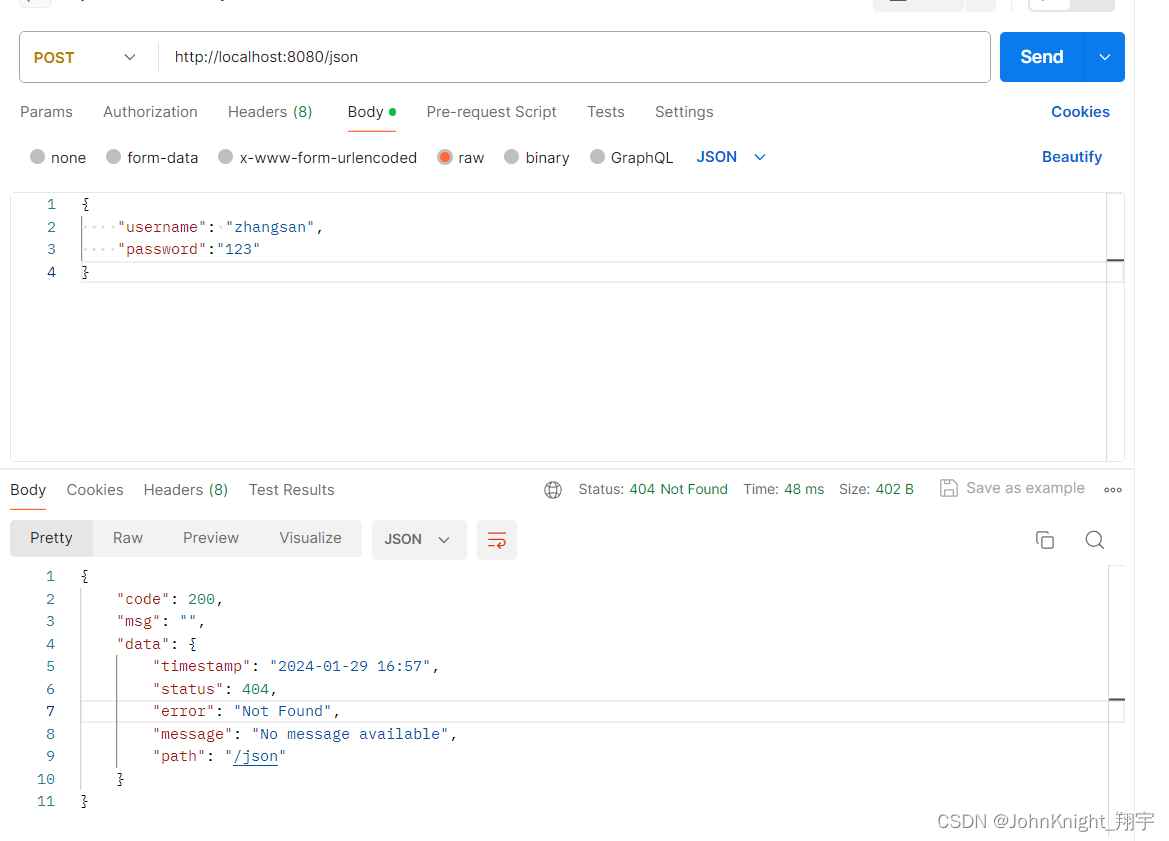
postman用法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、postman怎么使用json输出 总结 前言 提示:这里可以添加本文要记录的大概内容: 提示:以下是本篇文章正文内容࿰…...

MySQL之数据库DQL
文章目录 数据查询DQL基本查询运算符算数运算符比较运算符逻辑运算符位运算符 排序查询聚合查询分组查询分页查询INSERT INTO SELECT语句SELECT INTO FROM语句 数据查询DQL 数据库管理系统一个重要功能就是数据查询,数据查询不应只是简单返回数据库中存储的数据&am…...

《区块链简易速速上手小册》第9章:区块链的法律与监管(2024 最新版)
文章目录 9.1 法律框架和挑战9.1.1 基础知识9.1.2 主要案例:加密货币的监管9.1.3 拓展案例 1:跨国数据隐私和合规性9.1.4 拓展案例 2:智能合约的法律挑战 9.2 区块链的合规性问题9.2.1 基础知识9.2.2 主要案例:加密货币交易所的合…...
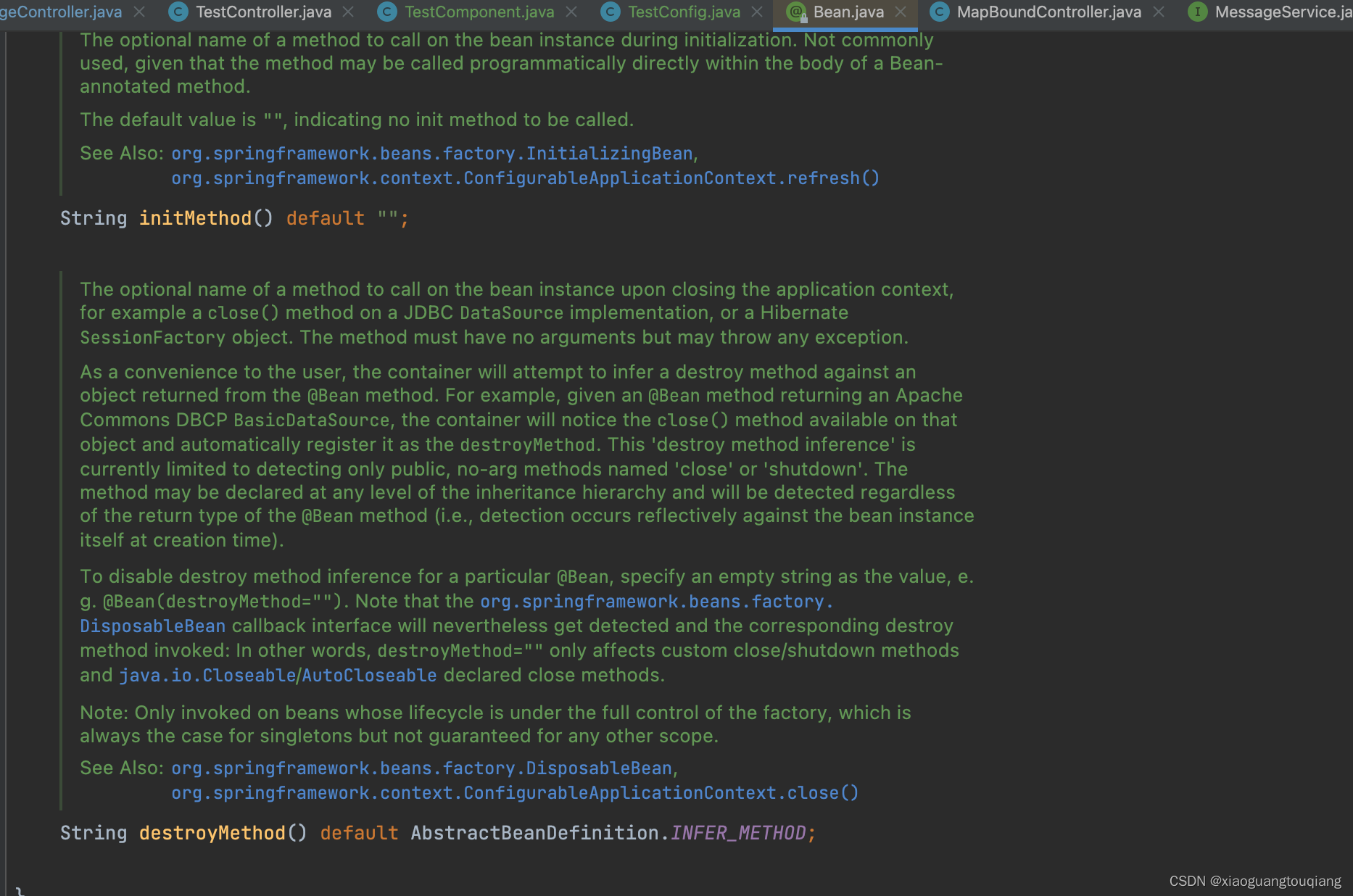
Spring Boot 中操作 Bean 的生命周期
1.InitializingBean和DisposableBean InitializingBean接口提供了afterPropertiesSet方法,用于在bean的属性设置好之后调用; DisposableBean接口提供了destroy方法,用于在bean销毁之后调用; public class TestComponent implem…...
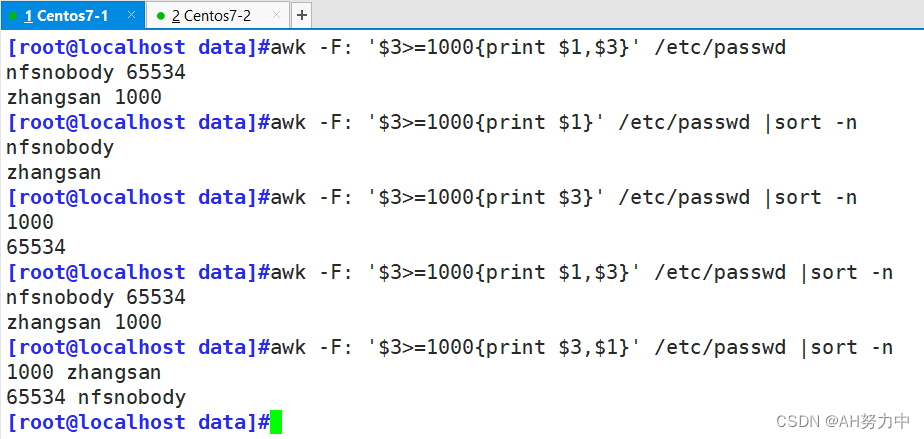
Linux ---- Shell编程三剑客之AWK
一、awk处理文本工具 1、awk概述 awk 是一种处理文本文件的语言,是一个强大的文本分析工具。AWK是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作。用来处理列。数据可以来自标准输入也可以是管道或文件。…...

Netty入门使用
为什么会有Netty? NIO 的类库和 API 繁杂,使用起来比较麻烦,需要熟练掌握 Selector、ServerSocketChannel、SocketChannel、ByteBuffer 等。开发工作量和难度都非常大,例如客户端面临断线重连、网络闪断、心跳处理、半包读写、网络拥塞和异…...
go并发编程-runtime、Channel与Goroutine
1. runtime包 1.1.1. runtime.Gosched() 让出CPU时间片,重新等待安排任务(大概意思就是本来计划的好好的周末出去烧烤,但是你妈让你去相亲,两种情况第一就是你相亲速度非常快,见面就黄不耽误你继续烧烤,第二种情况就是你相亲速度…...

HTTP概述
HTTP概述 HTTP(Hypertext Transfer Protocol)是一种用于传输超文本的应用层协议。它是在客户端和服务器之间进行通信的基础,常用于 Web 应用中。在 Java 后端开发中,HTTP 扮演着重要的角色。以下是Java 后端视角下的 HTTP 概述&a…...

ubuntu20配置mysql8
首先更新软件包索引运行 sudo apt update命令。然后运行 sudo apt install mysql-server安装MySQL服务器。 安装完成后,MySQL服务将作为systemd服务自动启动。你可以运行 sudo systemctl status mysql命令验证MySQL服务器是否正在运行。 连接MySQL 当MySQL安装…...
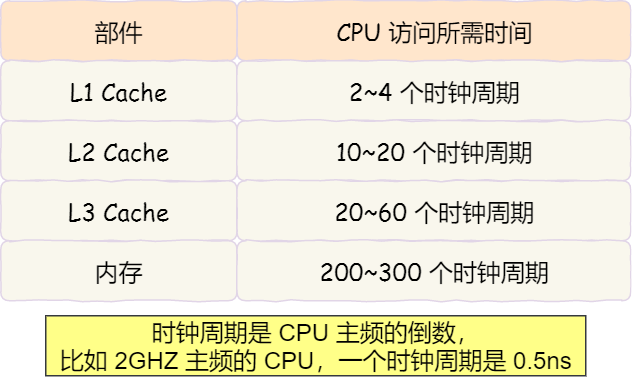
CPU-Cache结构查看
参考【Ubuntu 查看 CPU 缓存】 本文主要介绍cpu的cache查看,以供读者能够理解该技术的定义、原理、应用。 🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:计算机杂记 🎀CSDN主页 发狂的小花…...
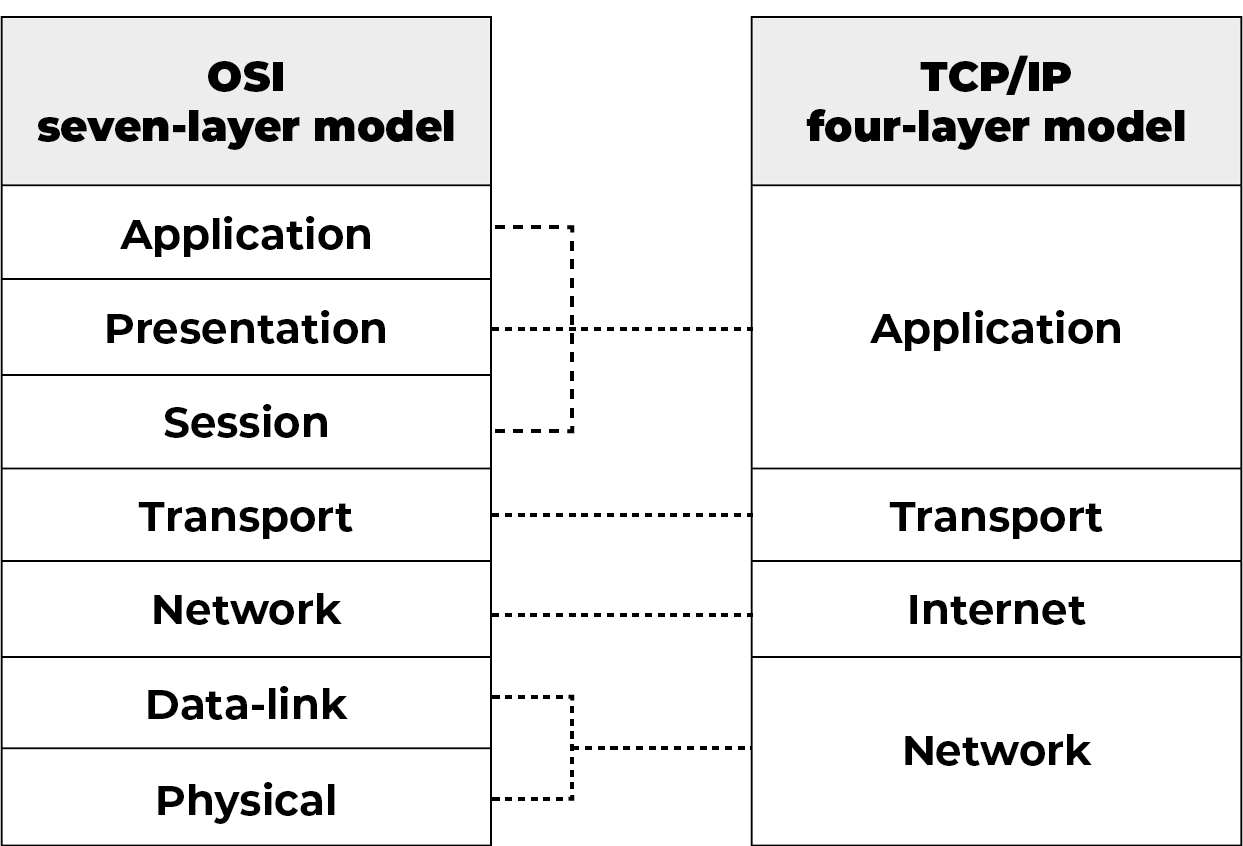
Wireshark网络协议分析 - Wireshark速览
在我的博客阅读本文 文章目录 1. 版本与平台2. 快速上手2.1. 选择网络接口进行捕获(Capture)2.2. 以Ping命令为例进行抓包分析2.3. 设置合适的过滤表达式2.4. 数据包详情2.5. TCP/IP 四层模型 3. 参考资料 1. 版本与平台 Wireshark是一个开源的网络数据…...

查看进程创建的所有线程
ps 在ps命令中,“-T”选项可以开启线程查看。下面的命令列出了由进程号为的进程创建的所有线程。 ps -T -p <pid>top op命令可以实时显示各个线程情况。要在top输出中开启线程查看,请调用top命令的“-H”选项,该选项会列出所有Linux…...
汽车软件开发模式的5个特点
汽车软件开发属于较为复杂的系统工程,经常让来自不同知识背景的工程师在观点交锋时出现分歧。在解决复杂性和对齐讨论基准时,可以通过勾勒出讨论对象最关键的几个特征来树立典型概念。本文旨在通过5个典型特点的抽取,来勾勒出汽车软件开发模式…...

双屏联动系统在展厅设计中的互动类型与效果
随着各项多媒体技术的快速发展,让展厅中的各类展项得到技术升级,其中作为电子设备中最基础的显示技术,不仅优化了内容的展示质量,还实现了更具互动性的创新技术,如双屏联动系统就是当前展厅设计中最常见的技术类型之一…...

STM32F407移植OpenHarmony笔记5
继上一篇笔记,搭建好STM32的编译框架,编译出来的OHOS_Image.bin并不能跑不起来。 今天要在bsp里面添加一些代码,让程序能跑起来。 先从裸机点亮LED灯开始,准备以下3个文件:startup和system文件可以用OHOS官方代码。 /device/boar…...

点击其他区域隐藏弹出框效果
一般下拉框或者选择框,持久展示时会给用户显示的隐藏方式,如点击事件后。也可以添加隐式的隐藏方式,如点击弹出框之外的区域。 CSS方法-focus伪类 当触发的元素是可以focus,以输入框为例。 可以将弹出框出现的时机设置在input:…...

Python一些可能用的到的函数系列123 ATimer2-时间偏移
说明 之前确定了时间轴(千年历),以及时间的转换方法。其中时间轴的数据将会存储在集群,以及通过RedisOrMongo保存部分常用的数据。 本次讨论时间偏移的度量问题。 内容 1 两种形式 我们提到时间时,通常会有两种方…...

CANN-昇腾NPU长序列训练-128K上下文怎么不OOM
Llama 3 支持 128K 上下文长度。训练时 128K 序列的 Attention 显存是 O(N):128K 128K fp16 32GB 每层,32 层 1TB。显然放不下。FlashAttention 把显存从 O(N) 降到 O(N),但在训练场景下还有额外挑战。 FlashAttention 的显存节省 标准 At…...

2025年AI数字人行业现状:全国超99万家企业涌入,真正能落地的不到一成
当生成式AI的浪潮席卷各行各业,AI数字人成为最先跑出商业化落地速度的细分赛道。然而,在全国超99万家相关企业蜂拥而入的热闹背后,一个残酷的现实正在显现:绝大多数所谓的"AI数字人"不过是披着科技外衣的"会动的照…...

FactoryBluePrints:戴森球计划终极蓝图仓库,5步打造高效自动化工厂
FactoryBluePrints:戴森球计划终极蓝图仓库,5步打造高效自动化工厂 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 你是否曾在戴森球计划中花费数小…...

XZ62N,0.7uA静态电流,NMOS输出电压检测芯片
产品概述 这系列芯片是使用 CMOS 技术开发的高精度、低功耗、小封装电压检测芯片。检测电压在小温度漂移的情况下保持极高的精度。输出配置是N-channel open drai 输出。 产品特点 ● 封装:SOT23-3 ● 输出配置:N-channel open drain ● 工作电压&a…...

甲言Jiayan:5分钟掌握古汉语NLP终极解决方案
甲言Jiayan:5分钟掌握古汉语NLP终极解决方案 【免费下载链接】Jiayan 甲言,专注于古代汉语(古汉语/古文/文言文/文言)处理的NLP工具包,支持文言词库构建、分词、词性标注、断句和标点。Jiayan, the 1st NLP toolkit designed for Classical C…...

TrafficMonitor插件完整指南:让Windows任务栏变身全能监控中心
TrafficMonitor插件完整指南:让Windows任务栏变身全能监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为繁琐的系统监控工具而烦恼吗?每次需…...

AI Agent不是工具课,而是组织进化课:全球TOP5咨询公司正在用的7维培训成熟度评估框架
更多请点击: https://intelliparadigm.com 第一章:AI Agent不是工具课,而是组织进化课:全球TOP5咨询公司正在用的7维培训成熟度评估框架 当麦肯锡、BCG、贝恩、罗兰贝格与奥纬在2024年Q2同步升级其内部AI能力发展路线图时&#x…...

如何在C加加项目中快速接入Taotoken的多模型API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在C项目中快速接入Taotoken的多模型API服务 对于使用C进行开发的工程师而言,直接调用HTTP API是集成第三方服务最灵…...

为什么你的Gemini总在“浅层回答”?揭秘深度研究模式的3层激活机制与强制触发密钥
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini总在“浅层回答”? 当你反复向 Gemini 提问却只得到泛泛而谈、回避细节或机械复述提示词的答案时,问题往往不在模型本身,而在于**交互范式与上下文工…...

通过Taotoken的CLI工具一键配置开发环境与API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken的CLI工具一键配置开发环境与API密钥 对于需要接入多个大模型服务的开发团队而言,统一管理API密钥和端点配…...