【笔记】计算文件夹的大小
目标:遍历文件夹,计算文件夹下包含文件和文件夹的大小。将这些结果存入python自带的数据库。
用大模型帮我设计并实现。
Step1 创建一个测试用的目录结构
创建目录结构如下所示:
TestDirectory/
│
├── EmptyFolder/
│
├── SmallFiles/
│ ├── file1.txt (1 KB)
│ ├── file2.txt (2 KB)
│ └── file3.txt (3 KB)
│
├── LargeFiles/
│ ├── big_file1.bin (10 MB)
│ ├── big_file2.bin (20 MB)
│ └── big_file3.bin (30 MB)
│
└── NestedFolders/├── Subfolder1/│ ├── file4.txt (4 KB)│ ├── file5.txt (5 KB)│ └── EmptySubfolder1/│├── Subfolder2/│ ├── file6.txt (6 KB)│ └── EmptySubfolder2/│└── Subfolder3/├── file7.txt (7 KB)└── EmptySubfolder3/
import os
import shutildef create_test_directory(root_path):# 创建根目录os.makedirs(root_path, exist_ok=True)# 创建空目录empty_folder_path = os.path.join(root_path, 'EmptyFolder')os.makedirs(empty_folder_path, exist_ok=True)# 创建包含小文件的目录small_files_path = os.path.join(root_path, 'SmallFiles')os.makedirs(small_files_path, exist_ok=True)for i in range(1, 4):file_path = os.path.join(small_files_path, f'file{i}.txt')with open(file_path, 'w') as file:file.write('x' * (i * 1024)) # 生成大小为 i KB 的文件# 创建包含大文件的目录large_files_path = os.path.join(root_path, 'LargeFiles')os.makedirs(large_files_path, exist_ok=True)for i in range(1, 4):file_path = os.path.join(large_files_path, f'big_file{i}.bin')with open(file_path, 'wb') as file:file.write(os.urandom(i * 10 * 1024 * 1024)) # 生成大小为 i * 10 MB 的二进制文件# 创建多层次嵌套目录nested_folders_path = os.path.join(root_path, 'NestedFolders')os.makedirs(nested_folders_path, exist_ok=True)for i in range(1, 4):subfolder_path = os.path.join(nested_folders_path, f'Subfolder{i}')os.makedirs(subfolder_path, exist_ok=True)file_path = os.path.join(subfolder_path, f'file{i + 3}.txt')with open(file_path, 'w') as file:file.write('x' * ((i + 3) * 1024))empty_subfolder_path = os.path.join(subfolder_path, f'EmptySubfolder{i}')os.makedirs(empty_subfolder_path, exist_ok=True)
在os.makedirs函数中,exist_ok参数用于指定是否在目录已经存在的情况下忽略错误。
- 如果
exist_ok为True,无论目标目录是否存在,os.makedirs会执行,不会报错。 - 如果
exist_ok为False,并且目标目录已经存在,os.makedirs会引发一个FileExistsError异常。
exist_ok=True 允许函数在调用时多次执行,即使已经创建了目录结构,也不会引发错误。
Step2 遍历文件夹,计算文件夹大小
设计三个函数:
-
get_file_size(file_path)函数:- 输入:文件路径
file_path。 - 输出:返回该文件的大小(字节数),使用
os.path.getsize函数获取。
- 输入:文件路径
-
format_size(size_bytes)函数:- 输入:一个表示字节数的整数
size_bytes。 - 输出:返回格式化后的字符串,该字符串包含适当的单位(B、KB、MB、GB)以及转换后的大小值。该函数通过迭代循环,将字节数转换为合适的单位。
- 输入:一个表示字节数的整数
-
get_directory_size(directory_path)函数:- 输入:目录路径
directory_path。 - 输出:返回该目录及其子目录中所有文件的总大小。
- 思路:
- 使用
os.walk遍历目录,得到每个文件的路径。 - 对于每个文件,调用
get_file_size函数获取其大小,并累计到总大小。 - 对于每个子目录,递归调用
get_directory_size函数,将返回的子目录大小累加到总大小。 - 返回总大小。
- 使用
- 输入:目录路径
这样,通过这三个函数的协作,可以获取文件和目录的大小信息,并且通过 format_size 函数,可以将字节数格式化为易读的字符串。
import osdef get_file_size(file_path):"""计算文件大小(字节数)"""return os.path.getsize(file_path)def format_size(size_bytes):"""将字节数格式化为人类可读的字符串"""for unit in ['B', 'KB', 'MB', 'GB', 'TB']:if size_bytes < 1024.0:breaksize_bytes /= 1024.0return f"{size_bytes:.2f} {unit}"def get_directory_size(directory_path):"""递归计算目录大小,包括目录中所有文件和子目录的大小"""total_size = 0for dirpath, dirnames, filenames in os.walk(directory_path):# 计算文件大小for filename in filenames:file_path = os.path.join(dirpath, filename)total_size += get_file_size(file_path)# 计算子目录大小for dirname in dirnames:subdirectory_path = os.path.join(dirpath, dirname)total_size += get_directory_size(subdirectory_path)return total_size
上面返回的total_size是字节数。
另外说一下,函数中用到的 print(f"xxxx") 中的 f"xxxx" 是一个 f-string,是一种字符串格式化的方式,是在字符串前加上 f 或 F 前缀的字符串字面值。它允许在字符串中嵌入表达式,这些表达式会在运行时求值,并将结果插入到字符串中。可以使用大括号 {} 括起表达式,这些表达式将在运行时被替换为相应的值。例如:
name = "秦汉唐"
age = 25
print(f"姓名: {name} \t年龄 {age}")
f-string 中的 {name} 和 {age} 会分别被替换为变量 name 和 age 的值。
在测试的时候(testRun.py中):
import os
import shutil
from folder_size_calculator import get_directory_size, format_size, get_file_sizeif __name__=="__main__":# 测试函数create_test_directory('TestDirectory')# 测试directory_path = "TestDirectory" # 替换为你的目录路径total_size = get_directory_size(directory_path)formatted_size = format_size(total_size)print(f" '{directory_path}' 文件夹大小为: {formatted_size}")
执行testRun.py,结果类似:
>python testRun.py'TestDirectory' 文件夹大小为: 120.07 MB
Step3 优化
回顾上面的计算文件夹大小的程序,可能有些可以改进的方向
- 异常问题: 目前的代码缺少对一些异常情况的处理,例如无法访问的文件或目录。
- 性能问题: 对于非常大的目录结构,递归遍历可能会导致重复计算,可能影响计算文件大小效率。
- 符号链接问题: 目前的程序不处理符号链接,可能会导致计算错误或无限循环。
- 文件类型判断和过滤问题: 目前程序对文件和目录的处理方式一样,没有区分文件类型。
- 异常处理问题
因为是对文件进行处理,所以通过增加文件处理异常:
try:# 尝试获取文件大小或目录列表# ...
except (PermissionError, OSError) as e:print(f"Error accessing file or directory: {e}")
except FileNotFoundError as e:print(f"File not found: {e}")
except Exception as e:print(f"An unexpected error occurred: {e}")
对 get_file_size 函数进行异常处理
def get_file_size(file_path):"""计算文件大小(字节数)"""try:size_bytes = os.path.getsize(file_path)return size_bytesexcept (PermissionError, FileNotFoundError) as e:print(f"访问文件出错: {e}")return 0except Exception as e:print(f"出现异常: {e}")return 0
对 get_directory_size 函数进行异常处理
def get_directory_size(directory_path):"""递归计算目录大小,包括目录中所有文件和子目录的大小"""total_size = 0try:for dirpath, dirnames, filenames in os.walk(directory_path):# 计算文件大小for filename in filenames:file_path = os.path.join(dirpath, filename)total_size += os.path.getsize(file_path)# 计算子目录大小for dirname in dirnames:subdirectory_path = os.path.join(dirpath, dirname)total_size += get_directory_size(subdirectory_path)except (PermissionError, FileNotFoundError) as e:print(f"访问文件异常: {e}")return 0 # 或者抛出其他异常except Exception as e:print(f"出现异常: {e}")return 0return total_size
- 性能问题
我想利用数据库存储已经处理过的文件和文件夹。最简单的方式,数据库就用python自带的数据库,边做便设置数据库格式。
相关文章:

【笔记】计算文件夹的大小
目标:遍历文件夹,计算文件夹下包含文件和文件夹的大小。将这些结果存入python自带的数据库。 用大模型帮我设计并实现。 Step1 创建一个测试用的目录结构 创建目录结构如下所示: TestDirectory/ │ ├── EmptyFolder/ │ ├── SmallF…...
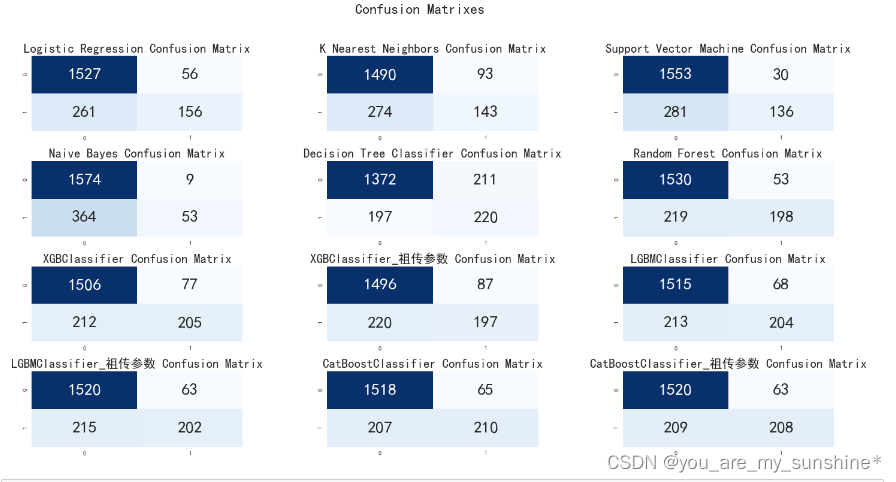
机器学习_常见算法比较模型效果(LR、KNN、SVM、NB、DT、RF、XGB、LGB、CAT)
文章目录 KNNSVM朴素贝叶斯决策树随机森林 KNN “近朱者赤,近墨者黑”可以说是 KNN 的工作原理。 整个计算过程分为三步: 计算待分类物体与其他物体之间的距离;统计距离最近的 K 个邻居;对于 K 个最近的邻居,它们属于…...

外包干了8个月,技术退步明显...
先说一下自己的情况,大专生,18年通过校招进入武汉某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落! 而我已经在一个企业干了四年的功能测…...
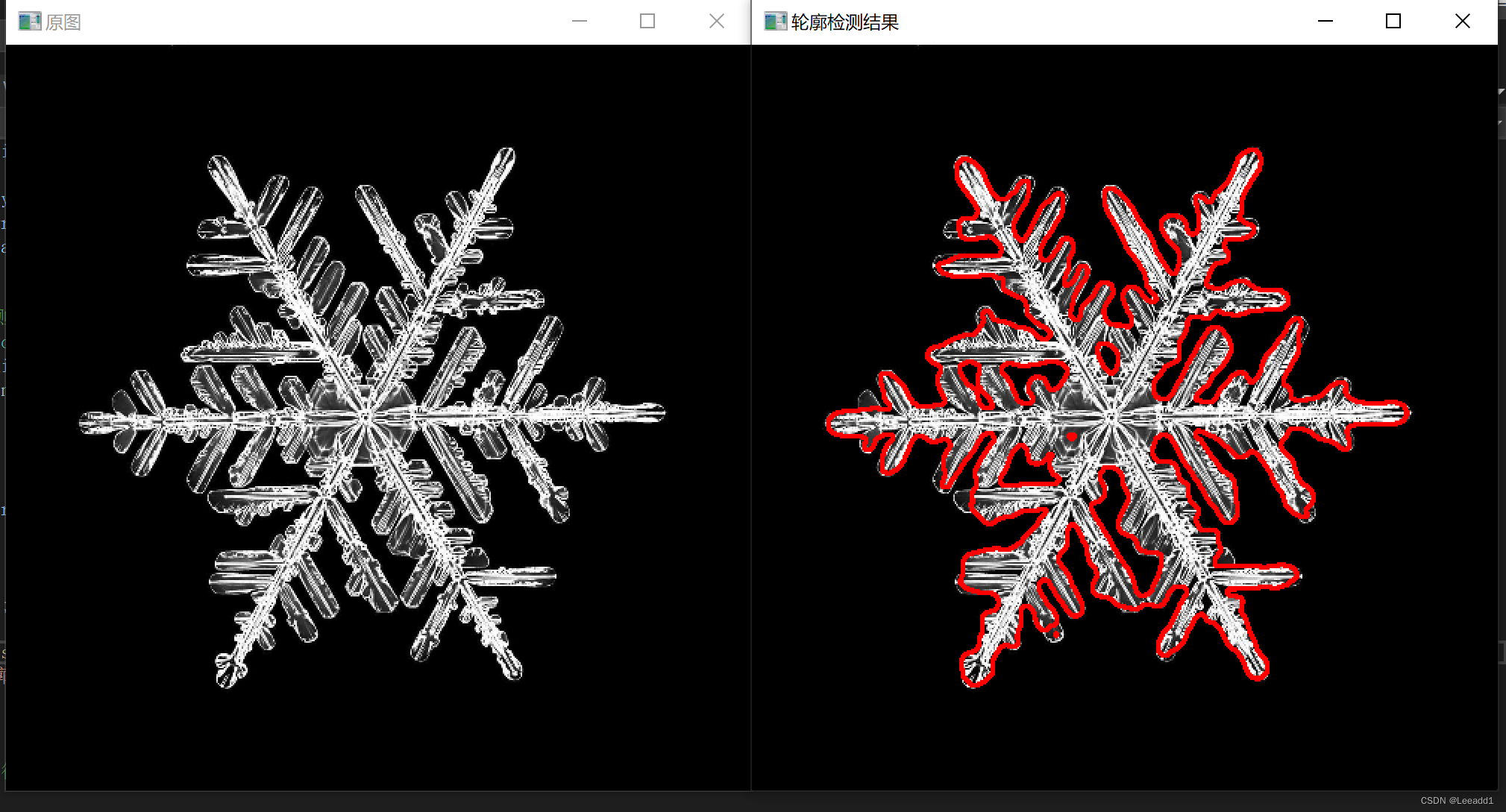
opencv#41 轮廓检测
轮廓概念介绍 通常我们使用二值化的图像进行轮廓检测,对轮廓以外到内进行数字命名,如下图,最外面的轮廓命名为0,向内部进行扩展,遇到黑色白色相交区域,就是一个新的轮廓,然后依次对轮廓进行编号…...
Websocket基本用法
1.Websocket介绍 WebSocket是基于TCP的一种新的网络协议。它实现了浏览器与服务器全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接,并进行双向数据传输。 应用场景: 视频弹幕网页聊天体育实况更新股票基金…...
node.js与express.js创建项目以及连接数据库
搭建项目 一、技术准备 node版本:16.16.0 二、安装node成功后,安装express,命令如下: npm install -g express 或者: npm install --locationglobal express 再安装express的命令工具: npm install --location…...

【Tomcat与网络8】从源码看Tomcat的层次结构
在前面我们介绍了如何通过源码来启动Tomcat,本文我们就来看一下Tomcat是如何一步步启动的,以及在启动过程中,不同的组件是如何加载的。 一般,我们可以通过 Tomcat 的 /bin 目录下的脚本 startup.sh 来启动 Tomcat,如果…...

Java Agent Premain Agentmain
概念 premain是在jvm启动的时候类加载到虚拟机之前执行的 agentmain是可以在jvm启动后类已经加载到jvm中了,才去转换类。 这种方式会转换会有一些限制,比如不能增加或移除字段。 具体的做法,两者的实际做法是差不多的: premain 定义个静…...

Python实现设计模式-策略模式
策略模式是一种行为型设计模式,它定义了一系列算法或策略,并将它们封装成独立的类,使得它们可以相互替换,而不影响客户端的使用。 在策略模式中,算法或策略被封装在单独的策略类中,这些策略类实现了相同的…...
详解SpringCloud微服务技术栈:深入ElasticSearch(4)——ES集群
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习 🌌上期文章:详解SpringCloud微服务技术栈:深入ElasticSearch(3)——数据同步(酒店管理项目&a…...
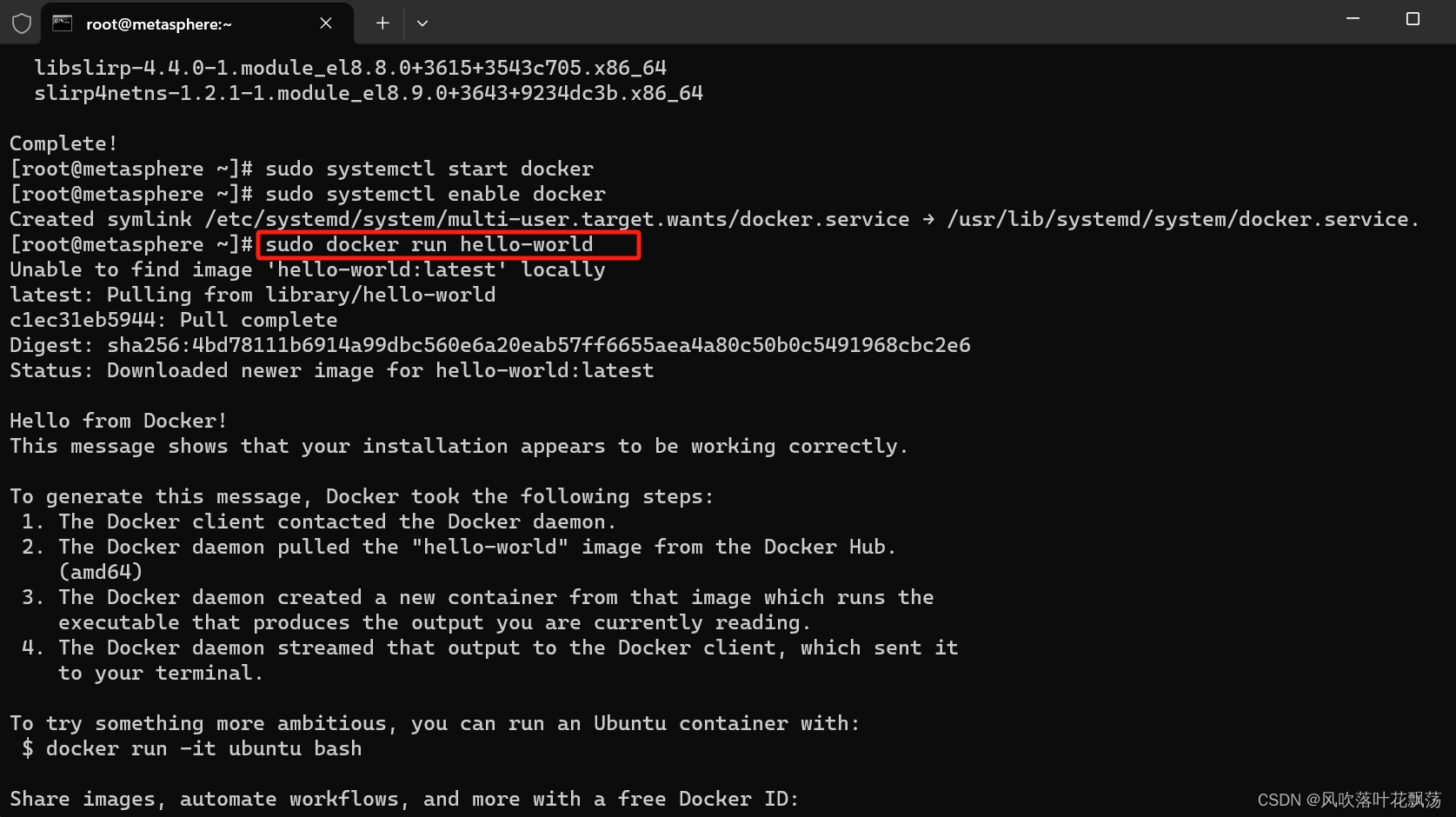
AlmaLinux上安装Docker
AlmaLinux上安装Docker 文章目录 AlmaLinux上安装Docker一、前言二、具体步骤1、Docker 下载更新系统包索引:添加Docker仓库:安装Docker引擎: 2、Docker服务启动启动Docker服务:设置Docker开机自启: 3、Docker 安装验证…...

熟悉MATLAB 环境
一、问题描述 熟悉MATLAB 环境。 二、实验目的 了解Matlab 的主要功能,熟悉Matlab 命令窗口及文件管理,Matlab 帮助系统。掌握命令行的输入及编辑,用户目录及搜索路径的配置。了解Matlab 数据的特点,熟悉Matlab 变量的命名规则&a…...
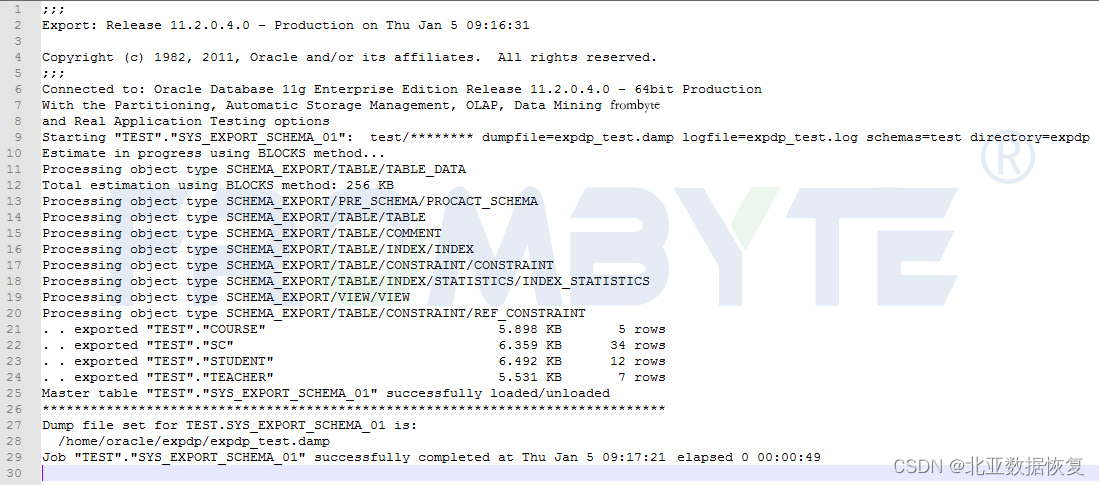
【数据库数据恢复】Oracle数据库ASM磁盘组数据恢复案例
oracle数据库故障&分析: oracle数据库ASM磁盘组掉线,ASM实例不能挂载。数据库管理员尝试修复数据库,但是没有成功。 oracle数据库数据恢复过程: 1、将oracle数据库所涉及磁盘以只读方式备份。后续的数据分析和数据恢复操作都…...
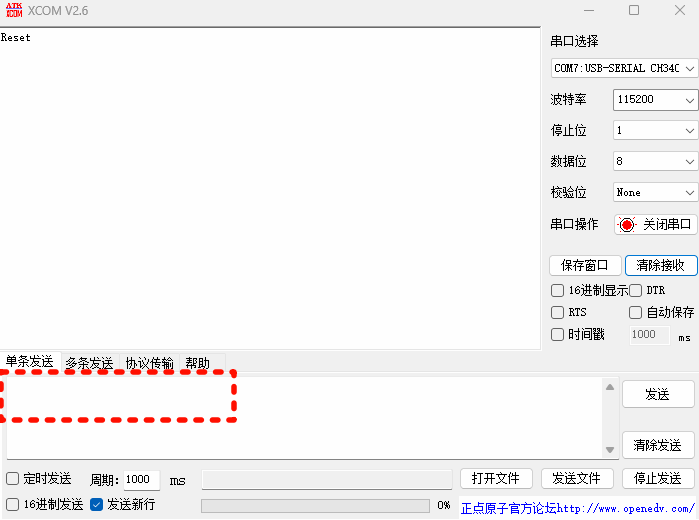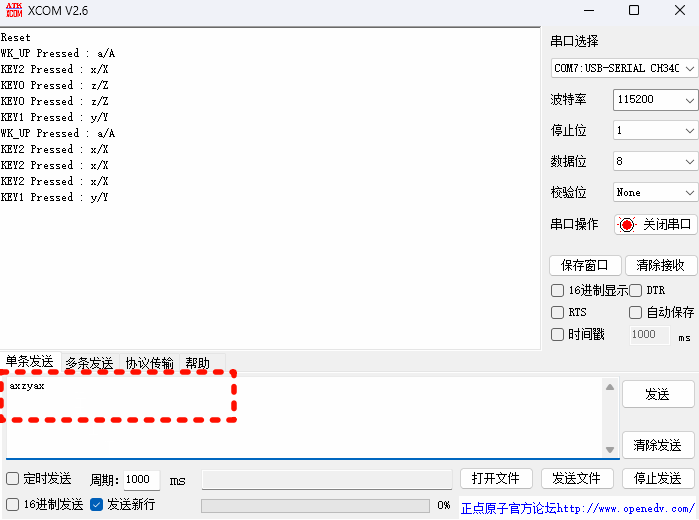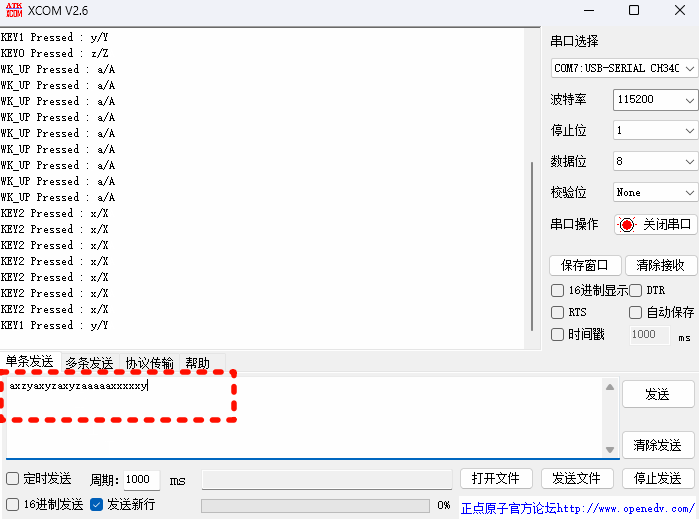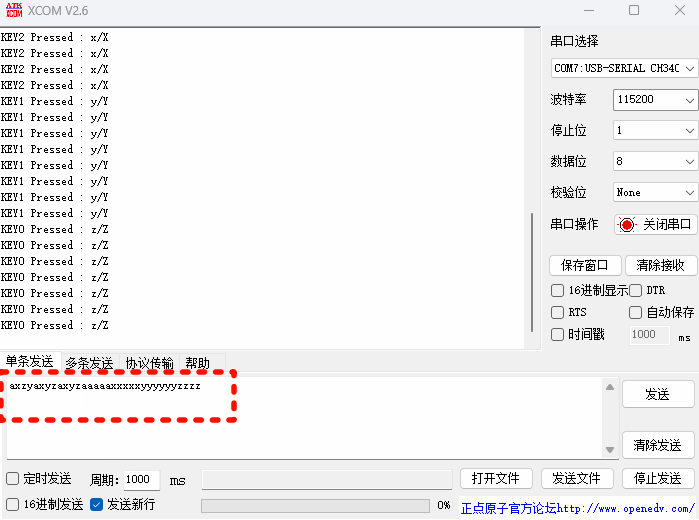
STM32CubeMX教程31 USB_DEVICE - HID外设_模拟键盘或鼠标
目录 1、准备材料 2、实验目标 3、模拟鼠标实验流程 3.0、前提知识 3.1、CubeMX相关配置 3.1.0、工程基本配置 3.1.1、时钟树配置 3.1.2、外设参数配置 3.1.3、外设中断配置 3.2、生成代码 3.2.0、配置Project Manager页面 3.2.1、设初始化调用流程 3.2.2、外设中…...

知道Wi-Fi名称和密码之后自动连接
这里写自定义目录标题 有Wi-Fi名称和密码自动连接Wi-Fi主Activity服务类 WIFIStateReceiver工具类 WIFIConnectionManager 有Wi-Fi名称和密码自动连接Wi-Fi 主Activity public class MainActivity extends AppCompatActivity implements View.OnClickListener{private static…...

本地搭建Plex私人影音网站并结合内网穿透实现公网远程访问
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
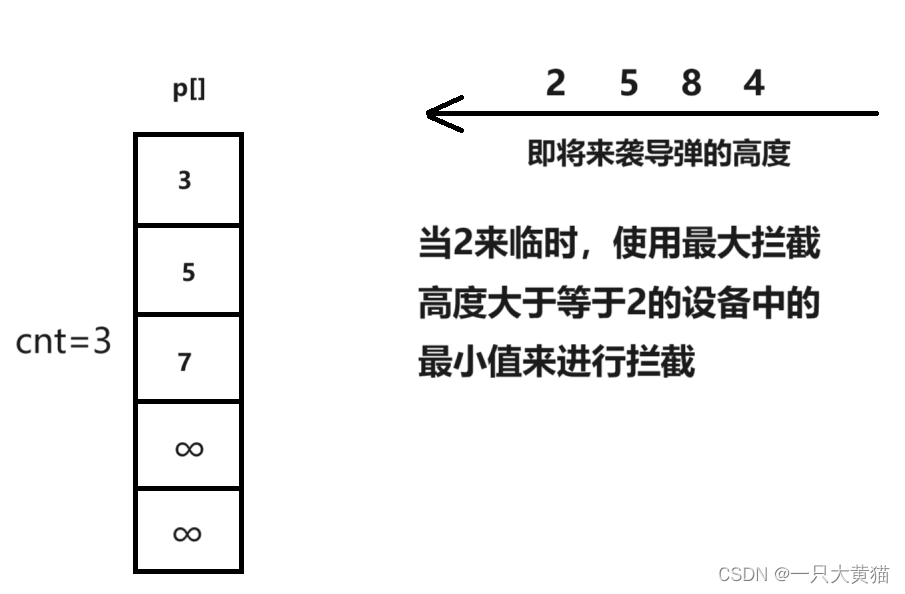
【算法】拦截导弹(线性DP)
题目 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统。 但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度,但是以后每一发炮弹都不能高于前一发的高度。 某天,雷达捕捉到敌国的导弹来袭。 由于该系…...
pr)
记 doris 加载压缩文件(lzo、snappy)pr
做了一个case,是doris支持加载lzo压缩文件。[improvement](load) Enable lzo & Remove dependency on Markus F.X.J. Oberhumers lzo library by HowardQin Pull Request #30573 apache/doris (github.com) 其实doris里已经支持了 lzo,这个case源…...

【Leetcode】2670. 找出不同元素数目差数组
文章目录 题目思路代码结果 题目 题目链接 给你一个下标从 0 开始的数组 nums ,数组长度为 n 。 nums 的 不同元素数目差 数组可以用一个长度为 n 的数组 diff 表示,其中 diff[i] 等于前缀 nums[0, …, i] 中不同元素的数目 减去 后缀 nums[i 1, …, …...
༺༽༾ཊ—Unity之-01-工厂方法模式—ཏ༿༼༻
首先创建一个项目, 在这个初始界面我们需要做一些准备工作, 建基础通用文件夹, 创建一个Plane 重置后 缩放100倍 加一个颜色, 任务:使用工厂方法模式 创建 飞船模型, 首先资源商店下载飞船模型,…...

line_buffer + window_buffer架构
一、line buffer + win buffer架构说明 1.在图像算法处理中,line buffer + window buffer架构是非常普通使用的架构; 2.本次针对3*3的滤波,给出两种处理架构的设计方案 二、方案一步骤 ap_uint<8> window_buffer[3][3]; ap_uint<8> line_buffer[2][COLS]; …...

EXCEL文件展示MLP的计算过程
MLP 实现步骤(共 5 步) 步骤 1:输入层数据准备 在表格中输入两个特征值 x1、x2,作为 MLP 的输入。本次使用:x10.5,x20.8步骤 2:设置网络参数(权重 偏置) 手动设置输入层…...

3个理由让你爱上VR-Reversal:在普通电脑上自由探索VR世界
3个理由让你爱上VR-Reversal:在普通电脑上自由探索VR世界 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh…...

Windows右键菜单终极管理指南:ContextMenuManager让你的电脑更高效
Windows右键菜单终极管理指南:ContextMenuManager让你的电脑更高效 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是日常操作中不可…...

构建企业内部知识问答Agent时如何借助Taotoken降低模型依赖风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建企业内部知识问答Agent时如何借助Taotoken降低模型依赖风险 应用场景类,企业在开发基于大模型的内部分析Agent时&a…...

Windows安卓应用安装器终极指南:告别模拟器,轻松在电脑上运行手机应用
Windows安卓应用安装器终极指南:告别模拟器,轻松在电脑上运行手机应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想在Windows电脑…...

【NotebookLM视频转文字实战指南】:20年AI工程师亲测的5大避坑技巧与98.7%准确率实现路径
更多请点击: https://intelliparadigm.com 第一章:NotebookLM视频转文字的核心原理与能力边界 NotebookLM 的视频转文字功能并非直接处理原始视频流,而是依赖 Google Cloud Speech-to-Text API 的增强版语音识别管道,并结合 YouT…...

FModel终极指南:3步快速掌握游戏资源提取与创作应用
FModel终极指南:3步快速掌握游戏资源提取与创作应用 【免费下载链接】FModel Unreal Engine Archives Explorer 项目地址: https://gitcode.com/gh_mirrors/fm/FModel 你是否曾想过提取游戏中的精美模型、纹理和音频,用于自己的创作项目ÿ…...

解密市场结构:Chanlun-Pro 如何将缠论理论转化为智能交易引擎
解密市场结构:Chanlun-Pro 如何将缠论理论转化为智能交易引擎 【免费下载链接】chanlun-pro 基于缠中说禅所讲缠论理论,以便量化分析市场行情的工具 项目地址: https://gitcode.com/gh_mirrors/ch/chanlun-pro 在瞬息万变的金融市场中,…...

ARM编译器符号排列机制解析与工程实践
1. ARM编译器符号排列机制深度解析在嵌入式开发中,全局常量的内存布局往往会对系统行为产生微妙影响。最近在将项目从ARMCC v5迁移到ARMCLANG v6时,我遇到了一个有趣的差异现象:相同源代码中的const数组,在两个工具链中竟然产生了…...